
基于轻量级网络和边缘校正的多聚焦图像融合方法
2022-07-01 03:19王卫国
现代电子技术 2022年13期
于 桐,郭 利,王卫国
(陆军工程大学石家庄校区,河北 石家庄 050003)
0 引 言
武器装备是部队战斗力的重要组成部分,是决定现代战争胜负的关键因素之一。随着军事实战化训练的逐步推进,我军的装备维修抢修需求也在持续提升,但新型装备结构复杂、技术先进,对其进行技术保障难度大、任务重、操作复杂,对部队维修条件和保障人员技术水平提出了更高要求,但现阶段基层部队维修力量不足,维修人员能力有限,需要远程技术专家支持,这就要求后方能够清晰全面地掌握维修现场情况,但在现代拍摄设备的成像条件下,相机光学镜头中的聚焦深度有限,很难捕获到维修场景所有组分的合适图像。
因此,需要将具有同一场景的不同焦距级别的多景深图像融合为一张清晰的全聚焦图像技术,以满足后续维修任务需要,此外,还应满足在维修现场辅助设备上能够实时、快速运行的要求。
在传统的图像融合研究中,按照融合策略划分,图像融合方法大致可分为两类:基于变换域方法和基于空间域方法。变换域方法主要以多尺度变换(MST)为主,根据特定的融合规则通过融合不同图像的多尺度表示实现融合,有拉普拉斯金字塔、小波变换、平稳小波分解、非下采样轮廓波变换(NSCT)和多尺度表示(MSR)等方法。变换域融合方法对特征识别能力较强,但算法繁琐、耗时较长。
空间域方法一般可以分为三类:基于像素的方法、基于图像块的方法和基于区域的方法。比较常见的是像素级图像融合,通常的做法是将两个或多个输入图像进行合并,以生成比源图像更具信息性的视觉感知融合图像,比较有代表性的有图像消光、引导滤波、密集尺度不变特征变换等,空间域融合相对于变换域融合更为简单快速,但其局限于无法对源图像进行特征层面的精确分割。
这些传统的融合方法依赖人工设计融合规则,对复杂场景通用性不强。为了解决这一问题,本文提出一种基于轻量级神经网络和边缘校正的多聚焦图像融合方法,经实验验证,该方法参数量少、模型体积小、收敛速度快,经过两个阶段的处理,图像细节保有度高,融合边界效果良好。
1 本文提出的多聚焦图像融合方法
本文提出的多聚焦图像融合方法基于空间域进行融合,第一级融合依托深度卷积神经网络对聚焦区域进行划分,生成初级决策图,第二级融合通过形态学运算对第一级的决策图进行边缘校正。
主要步骤为:
1)第一级融合将配准的同源图像划分为目标尺寸图像块后,通过改进的轻量级网络对图像块进行分类识别,判定为聚焦、散焦,重构成初步划分出聚焦区域的初级融合决策。
2)第二级融合使用图像梯度进行双阈值检测生成边缘矫正引导图。通过形态学手段对初级决策图进行边缘校正,获得最终决策图,与源图像进行融合重构,生成最终的多聚焦融合图像。
融合方法的整体流程图如图1所示。

图1 融合方法整体流程图
第一级融合能够通过改进的轻量级神经网络快速定位划分主聚焦区域和散焦区域,减少参数量,大幅提高运算速度,第二级融合能使融合边缘保持更多源图像的纹理细节,有效抑制了融合边界的各类问题。
2 基于轻量级神经网络的一级融合
2.1 轻量级神经网络
传统的深度神经网络一般通过提升特征通道数和卷积核数量的方式来提高网络的整体性能,但这种方式易出现参数冗余和模型较大等问题,例如传统的vgg16权重模型有490 MB,resnet权重模型有644 MB,这些网络模型过大,很难在移动端和嵌入式系统等设备中使用。
轻量级神经网络针对传统卷积运算单纯增加卷积核尺寸和数量的方式作出改进,设计更高效的卷积操作方式,使用更精巧的网络架构,实现在便携移动设备上的训练和应用。
通常的做法是将传统的卷积方式替换为深度可分离卷积(Depthwise Convolution),例如将传统4个深度为3的3×3的卷积核拆分为3个深度为1的3×3卷积核和4个深度为3的1×1卷积核,以降低整体计算量。
深度可分离卷积的计算量与传统卷积相比见以下公式,其中,D是卷积核尺寸,D是输入的尺寸,和为输入输出通道。
传统卷积计算量为:

深度可分离卷积计算量DW为:

两种卷积方式计算量对比:

普通卷积方式的运算量一般是深度可分离卷积操作运算量9倍以上。相比传统卷积神经网络,使用深度可分离卷积能保证在减少模型参数与运算量的同时,不降低网络深度和准确度。
2.2 改进的轻量级神经网络
MobileNetV2是谷歌公司于2018年在MobileNet基础上提出的一种轻量级神经网络,与原来传统轻量级网络不同,MobileNetV2在原有单纯使用深度可分离卷积的基础上增加了7组Bottleneck结构。
网络中的Bottleneck使用倒残差结构,通过增加信息维度来保证特征提取的精确性,每个倒残差结构含有三个层,如图2所示。

图2 倒残差结构示意图
三层分别为:
1)1×1卷积升维层“Expansion”Layer采用点卷积操作,将输入特征映射到高维信息域,以加强特征提取能力。
2)3×3深度可分离卷积层Depthwise Convolution,减少运算量。
3)1×1卷积降维层“Projection”Layer采用点卷积操作,将高维信息降至低维。
结构前两层选用ReLU6激活函数,ReLU6激活函数定义为:

ReLU6激活函数能够较高程度地保持高维特征信息,但会损失大量的低维特征信息,由于使用倒残差结构,最后一层输出的特征向量维度较低,所以在最后一层卷积层使用线性激活函数。
原始的MobileNetV2网络针对多分类任务需求配置了深层次的网络结构和大量输出通道,本文需要解决的多聚焦图像融合任务实质上是一个二分类问题,在实验中发现,原始网络在计算时产生大量冗余参数,影响计算速度,为了减少冗余参数、简化网络结构、提高收敛速度,本文在MobileNetV2网络基础上进行了改进,提出了一种改进的轻量级神经网络。该网络针对目标区域是否存在模糊特征,以判定聚焦或者散焦为目的,将输出通道配置为2,并对网络结构进行剪枝,在网络结构进行剪枝时发现,在配置4组Bottleneck结构时,能兼顾计算速度的提升和分类准确率的稳定,剪枝后的网络结构如图3所示。

图3 网络结构
网络结构参数见表1,其中,为宽度乘法器,是输出通道,是步长,是运算迭代次数。

表1 网络结构参数
改进后的轻量级网络与其他传统网络的运算效率对比如表2所示。
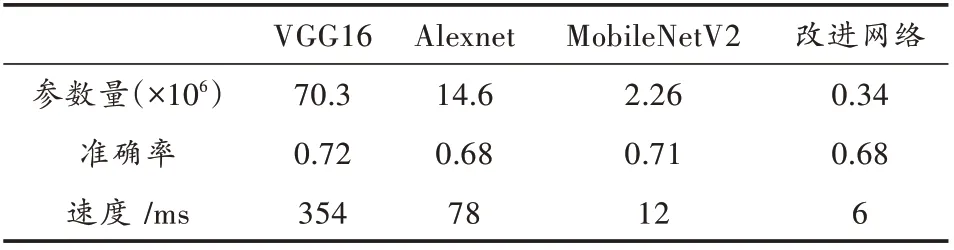
表2 改进网络的运算效率
训练网络时将聚焦图像标定为1,散焦图像标定为0,网络训练完成后,将同源多聚焦图像、分割为尺寸32×32的图像补丁,依次将图像补丁和图像补丁输入到训练好的网络模型中,网络输出标签0或1的值。

如图4所示,将输出值重构为一个矩阵,生成初级决策。

图4 初级决策生成流程图
3 基于边缘校正的二级融合
图像块级别补丁的网络训练模式导致了决策图融合边界块效应较为明显。为了解决这个问题,本阶段对初级决策进行边缘校正,以获得更精确的融合结果。
3.1 边缘校正算法
传统边缘检测算法一般使用Sobel算子,在实验中发现,单纯使用垂直和水平两个方向的算子,在散焦区域内,模糊特征的存在影响了检测的准确性,为此,本文提出一种改进的边缘校正算法。该算法在原有两个算子基础上增加两个对角线方向的斜向算子,并通过设置边缘梯度阈值,抑制散焦区域弱边缘,单独强化聚焦区域的真实边缘检测能力。
传统Sobel算子为:

增加的两个斜向算子为:

将图像转化为灰度图像,通过4个算子对源图像点(,)处像素值(,)及其8个邻域进行卷积可得4个方向的差分G,G,,:

总梯度的模(,)为:

合成的梯度方向(,)为:

在得到梯度后,使用双阈值检测图像边缘范围,设置最大阈值300(maxVal)和最小阈值100(minVal),超过maxVal判定为边缘,低于minVal的判定为非边缘,在maxVal与minVal之间的像素,通过比对8个邻域像素判定其是否属于边缘,如果邻域像素为强边缘像素,则将(,)点判定为真实边缘,得到边缘引导图。改进后的算法效果如图5所示。

图5 改进后算法效果
结果表明,改进后的算法能够抑制散焦区域弱边缘对真实边缘的影响,强化聚焦区域强边缘的检测能力。
3.2 最终融合决策
通过图像边缘作为引导对第一阶段决策进行约束,首先将引导图和初级决策图划分成16×16块区域,使用边缘引导图对初级决策图在每块区域内进行置换,f (,)为的区域块内点(,)处像素值,得到融合决策图:

对融合决策图进行形态学处理,过程如图6所示。

图6 边缘校正过程
第一步:使用开运算(卷积核设置为15)完成对锯齿边缘和缺损域的填充,清除孤立点;
第二步:分割最大连通域,划分出主聚焦区域;
第三步:使用闭运算(卷积核设置为15)清除孤立点,生成经过边缘校正后的最终决策图。
生成最终融合图像的过程如图7所示,决策表达表示为:

图7 最终融合图像

式中:为最终输出的融合图像;(,)是最终决策图;(,)和(,)分别表示原始图像和原始图像。
4 实验结果与对比
4.1 数据集及网络训练
理想的训练集可有效提高网络模型的泛化能力和分类精度。在传统多聚焦图像融合方法的数据集中,仅将高清原始图像标定为清晰,将经过高斯模糊处理的图像用作模糊版本。然而,在实际的多焦点图像中,聚焦区域的清晰度并不高,只是比散焦区域相对清晰一些,本文在原基础上设计了基于多版本模糊的数据集。
如图8所示,除原始图像外,其余5幅图像是经过高斯滤波处理的模糊图像,其标准差为2,滤镜大小为5,为模糊迭代次数,数据集由原始图像和=1,=2,…,=5形成5个不同的模糊版本。在本文中,选取cifar-10数据集中60 000张高质量图像作为训练集,图像尺寸为32×32,共产生360 000张图像补丁,将原始图像、=1、=2模糊图像标定为聚焦,其余标定为散焦,选择300 000张图像块作为训练集,60 000张图像块用作测试集。

图8 数据集制作
网络训练使用apply_gradients作为优化器,网络学习率设置为0.001,迭代次数设置为1 000,网络使用交叉熵作为损失函数。训练过程中损失值随迭代次数的变化如图9所示。

图9 神经网络训练过程损失值
4.2 主观效果评估
为了验证融合方法的有效性,在本节中选取5种具有代表性的MFIF方法与提出的方法进行比较,包括:非下采样轮廓波变换(NSCT)、传统引导滤波方法(GF)、基于多尺度加权梯度的方法(MSGF)、基于自适应稀疏表示(ASR)和卷积神经网络(CNN)。
为了比较各种MFIF方法的性能,使用20对来自开源数据集“Lytro”的同源图像进行实验,以验证本文提出的融合方法的有效性。选取部分示例,以展示各MFIF方法之间的差异。图10是“note”源图像对及通过不同方法和本文方法获得的融合结果,依次为源图像、源图像、NSCT、GF、ASR、MSGF、CNN和本文方法的输出融合图像。

图10 源图像及各类方法融合后的输出结果
将各种融合方法融合结果同源图像对比来看,可以看出各种传统方法还存在不同的缺点,NSCT方法降低了源图像的整体分辨率;GF方法在融合边缘处具有伪像;ASR方法降低了边界处的清晰度;MSGF方法的融合结果使图像整体对比度发生变化;CNN决策图的边缘存在锯齿状边缘,边界区域出现侵入型模糊。从本文方法的融合图像中可以看到融合的边界区域清晰度有明显提升,且无光晕和伪像。
为了更好地进行对比,将以上方法的融合图像与源图像进行了残差处理,得到的图像残差如图11所示。通过图11可以更加直观地看到各类方法的差异,相对于传统方法,本文方法在融合边缘的细节处理上具有明显优势。

图11 不同方法融合图像残差
4.3 定量指标评估
为了确保对融合性能的客观定量评价,本文采用通用的客观评价体系进行评估,图像融合指标分为四类:基于信息论、基于图像特征、基于图像结构相似性以及基于人类感知。在实验中,对于每个类别,采用在多焦点图像融合中广泛使用的4个指标进行评估。
1)标准化互信息
标准化互信息是一种基于信息论的图像融合计量指标,用于计量源图像与融合图像之间的互信息量。定义为:

式中:和代表源图像;代表和的融合图像;MI(,)和MI(,)代表源图像与融合图像的互信息;(),()和()分别是融合图像、和的熵。
2)图像特征指标
相位一致性度量是基于图像特征的计量指标,将源图像的相位一致性特征与融合图像进行比较。定义为:

式中:,和是源图像和融合图像之间的最大和最小矩;指数参数设置为===1。
3)结构相似性指标
是一种基于图像结构相似度(SSIM)的评价指标,用于评估保留源图像结构信息的级别。的定义为:

式中:SSIM(,|)表示通过和之间以滑动窗口方式计算映射;()为源图像局部方差计算显著性权重。
4)人类感知性指标
基于人类感知的度量,依据人类视觉系统模型的主要特征,将输入图像的对比度特征与融合图像进行比较。
定义为:

式中:Q(,)和Q(,)表示保留在融合图像中的源图像的对比度信息;加权因子λ(,)和λ(,)是两个源图像的显著图值。
表3列出了本文方法与其他5种融合方法在Lytro数据集上的融合图像平均得分,最高值以粗体显示。结果表明,在总体程度上,本文方法的融合效果更好。

表3 Lytro数据集各方法实验结果
5 结 论
本文针对野战条件下部队维修抢修,远程技术支持的视频图像传输在传输速度、实时性等方面的要求,设计了一种基于轻量级神经网络和边缘校正的多聚焦图像融合新方法。经融合实验验证,本文融合方法具有以下特点:
1)第一级融合使用改进的轻量级神经网络,减少了大量冗余参数,快速确定主聚焦区域,大幅提升了计算速度,保证采集、处理、传输的实时性,能够满足实际任务需要。
2)相对于其他传统方法依据分割结果直接重构图像,本文在第二级融合通过边缘检测算法生成引导图,使用形态学手段对初级决策进行校正后,有效克服了传统融合手段导致融合边界的各类问题。
3)本文的融合结果能够最大程度地保留源图像结构信息,融合图像更符合生物视觉机制,方便后方研判维修现场的情况,客观评价指标也验证了本文方法的有效性和优越性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
纺织科学研究(2021年9期)2021-10-14
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
北京航空航天大学学报(2018年1期)2018-04-20
通信产业报(2016年44期)2017-03-13
电视技术(2014年19期)2014-03-11
雕塑(1999年2期)1999-06-28
军事历史(1997年5期)1997-08-21
雕塑(1996年2期)1996-07-13
