
基于集成支持向量机的控制图异常模式识别
2022-06-30 12:06:36张莹,褚娜
物流技术 2022年6期
张 莹,褚 娜
(1.武汉理工大学 物流工程学院,湖北 武汉 430063;2.港口物流技术与装备教育部工程研究中心,湖北 武汉 430063)
0 引言
在生产过程的质量管控中,控制图作为统计过程控制(SPC)的一种基本工具常被用来监控过程中的异常波动。传统控制图是通过图上的样本点数据是否超过上下控制限来判断过程是否异常,无法判断生产过程异常的原因,近来控制图模式识别的研究在质量管控中得到了很多学者的关注,它是通过识别异常数据自身的规律,进而根据专家知识库找到对应异常数据模式产生的原因,并寻找相应的纠正措施。例如港口的配煤,主要是由多品种的煤炭按照一定比例混合。将控制图模式识别运用于港口的配煤中,当发生异常时识别出异常原因,提醒操作人员及时调整异常工序,能够有效的降低生产成本,促进港口经济发展和环境效益提升。
关于控制图模式识别的研究,一般先利用小波变换对数据进行特征提取。然后选择合适的识别分类器进行控制图模式识别。在识别分类器的选择中,机器学习的方法被广泛应用于控制图模式识别中。Addeh,等提出蜜蜂算法对高数目径向基函数神经网络进行参数寻优,提高了泛化能力和网络识别精度。Zan,等提出一维卷积神经网络,该模型的识别精度、收敛速度和迭代时间明显优于传统的多层感知器模型。刘贝贝,等指出了概率神经网络的控制图模式识别性能主要取决于对平滑因子的设定,利用粒子群算法对平滑系数进行寻优。而神经网络对于小样本数据没有较好的泛化性,网络结构也相对复杂,易于过拟合。Cuentas,等提出由于支持向量机具有优异的泛化性能,在统计过程控制应用中取得了显著的效果。宋李俊,等提出了融合特征提取和支持向量机控制图异常模式识别方法,实验表明对于小样本也有较好的识别性能。Zhou,等提出了混合核函数的模糊支持向量机的方法,对比概率神经网络和多层感知网络等具有良好的性能。他们将该模型运用到连杆部件的生产中,表明该方法在实际应用中具有较好的效果。蒋兆,等提出了一种基于遗传算法对多核函数最小二乘支持向量机中参数进行优化的识别模型,利用仿真实验证明了该识别模型在小批量生产中具有应用价值。
另一方面,为了改善监测模型识别精度不高、容易陷入局部优化的问题,许多学者采用AdaBoost算法对多个支持向量机进行集成。Jin,等提出了基于Relief算法和AdaBoost-SVM的内部裂纹缺陷检测方法,对比常用分类器具有更好的识别性能和泛化能力。吕锋,等提出一种基于多重提升的荷尔蒙遗传SVM集成学习方法,并将其应用于网络故障诊断,提高故障分类准确率。Bhosle,等提出了混合邻近算法和径向基函数核支持向量机作为AdaBoost的弱分类器,识别乳房X线照片为良性或恶性,提高早期识别乳腺癌的效率。Zheng,等将AdaBoost-SVM方法应用到变换器功率晶体管的故障诊断,提高了故障诊断的精度。可以看出SVM作为AdaBoost的弱分类器,在故障诊断、图像识别等领域具有较强的应用价值,受到了学者们的普遍关注。但是AdaBoost集成算法中每个弱分类器的权重依赖于自身分类误差,并且一味地提高错误样本的权重,这些缺点降低了模型的识别率。
综合目前已有研究发现,AdaBoost和SVM结合的算法在模式识别领域已有研究,但在统计过程控制中,尤其针对控制图异常模式识别的研究中,还没有考虑将该算法引入进来。为了更好地对产品质量进行控制,本文采用AdaBoost-SVM 模型对控制图进行异常模式识别,为了提高质量检测效率,本文针对SVM 识别精度不高、容易陷入局部优化,AdaBoost 算法更新权重不足的问题,进一步提出了基于改进的AdaBoost-SVM 的控制图模式识别方法,并研究其监测效率。最后将该模型运用于港口配煤模拟实验中,对其关键质量特性进行监测,以提高煤炭质量,降低生产成本。
1 控制图模式识别
1.1 控制图原理

1.2 控制图模式分类
传统控制图通过判断样本点是否超过上下控制限来监测生产过程的状态,而对部分过程异常因素的监控灵敏度不高并且无法识别具体的异常模式。在实际生产过程中需要及时报警并快速地找出过程异常的原因,调整相应的工序,避免造成生产损失。由此可见,控制图异常模式识别对于生产制造企业产品的质量控制和诊断具有重要意义。美国西部电气公司总结了控制图模式(CCP)的相关概念,并对控制图模式的类型进行了探讨和分析。目前基于控制图模式识别诊断的研究,主要以6种基本模式为主,分别为:正常、周期、上升趋势、下降趋势、向上阶跃、向下阶跃模式。
2 基于AdaBoost-SVM的控制图异常模式识别模型构建
本文提出了基于AdaBoost-SVM的控制图异常模式识别,其主要步骤为数据预处理、参数优化和模式识别,如图1所示。在数据预处理时,先运用小波分析将监测到的数据进行小波分解和重构,消除噪音对抽样数据的影响;其次利用网格搜索和交叉验证法对SVM中的参数进行寻优;最后运用SVM作为AdaBoost的弱分类器,集成强分类器进行控制图异常模式识别。具体仿真步骤如下:
第一步:生成仿真数据。通过蒙特卡罗模拟生成六种控制图模式数据。
第二步:数据预处理。选择合适的小波函数,通过小波变化进行分解和系数重构,达到消除噪音的目的。
第三步:参数优化。利用网格搜索和交叉验证对SVM中的参数惩罚因子c和核参数g进行寻优。
其次,可以举一些优秀的“阿姨”的例子,展示给她们看,这个职业可以到达的高度和状态,为阿姨树立学习的榜样。可以将国内外家政服务人员的学习和教育经历展示给阿姨看,英国、菲律宾等家政培训课程和学员学习情况,都可介绍给阿姨看,目的是希望阿姨认识到,这个工作不像她们想象的那样简单,有很多方面可以做得更好,但必须经过艰苦的学习和自我改变。
第四步:模式识别。利用改进的AdaBoost-SVM模型进行控制图模式识别。
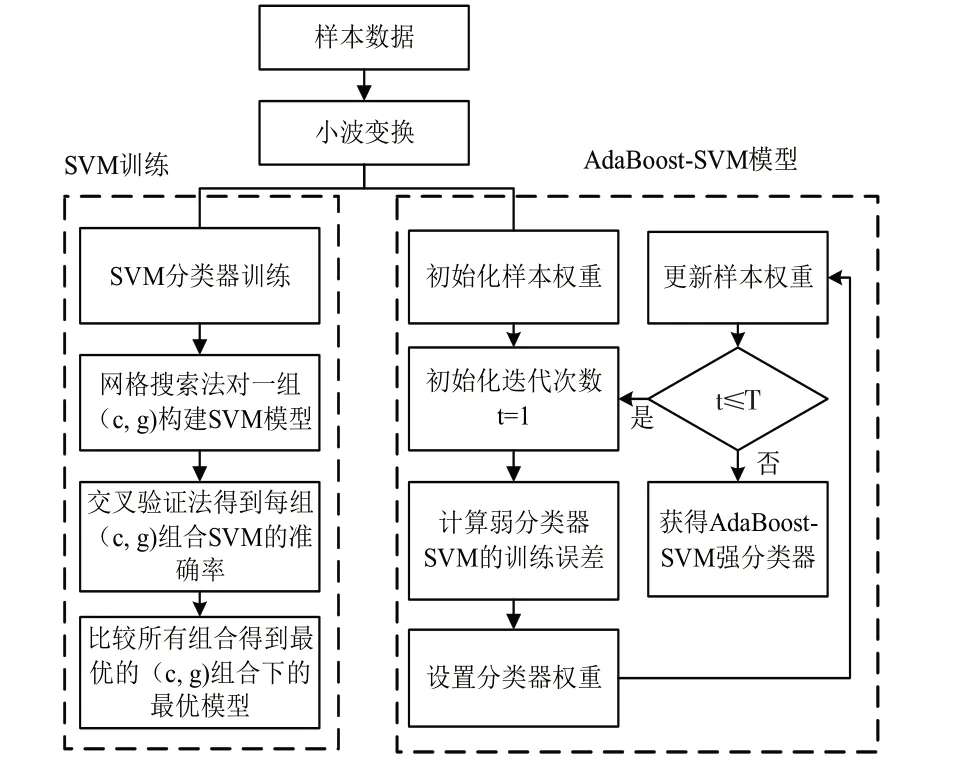
图1 基于改进的AdabBoost-SVM的控制图模式识别框架
2.1 基于交叉验证的SVM网格参数优化
在SVM 中,选择合适的核函数和参数值对SVM 的学习能力来说非常重要。径向基函数(RBF)作为核函数具有很强的学习能力,能够快速的解决非线性问题,在模式识别、故障诊断等许多问题的研究中表现出很好的性能。核参数g 和惩罚因子c 的选取对SVM 的性能影响较大。如果g 值选取不当,会出现“过学习”或“欠学习”现象;而惩罚因子c 越高,越容易过拟合,c 越小,越容易欠拟合。因此,本文将选择RBF 函数作为SVM 的核函数,采用网格搜索和交叉验证法寻找合适的惩罚因子和核参数。
交叉验证的基本思想是将数据集分割成N份,使用其中的1份作为测试集,剩余的N-1份作为训练集,并将训练好的模型用于测试集上。网格搜索的基本原理是将SVM中参数c和g分别划分一个区间范围,并计算出对应各参数变量值组合的准确率,逐一择优,以得到该区间内的最佳参数组合值。因此本文将利用交叉验证法检验每组(c,g)的准确率,具体步骤如下:
第一步:设置参数范围。取g=[-x,x],c=[-y,y],并设置步长为L。
第二步:采用k折交叉验证方法。将训练集划分为k份,选其中k-1份数据用于模型的训练,留下一份数据作为测试集。重复上述步骤k次,可得k次分类准确率,取其平均值作为该组参数(c,g)的分类准确率。
第三步:选取最优参数组合。遍历网格上所有的参数组合,选取分类准确率最大的一组参数组合。
2.2 基于改进的AdaBoost-SVM的识别模型
AdaBoost 算法的原理是在迭代过程中赋予多个弱分类器不同的权重,得到一个强分类器。传统的AdaBoost算法存在明显的不足,在迭代过程中对错误样本赋予较大的权重,正确样本赋予较小的权重,容易导致错误样本权重无限的增加,正确样本被忽视,影响样本训练效果。基于此不足,本文对AdaBoost算法进行改进:(1)更新弱分类器权重时,仅考虑弱分类器训练误差率,未考虑样本权重分布情况。R反应了样本权重分布情况,R越大说明被正确分类样本越多;反之说明被错误分类样本越多。加入k*exp(R),使R越小,弱分类器权重越小。(2)更新训练样本权重时,为了改善对错误样本的过度关注,加入l 调节因子,减少错误样本权重增长速度和正确样本权重减缓速度。本文提出的改进AdaBoost-SVM 识别模型,其具体的训练步骤如下:
}(x,y),(x,y),...,(x,y) ,其中x是样本特征向量,y是样本对应的类别标签,输入初始迭代次数t=1,总迭代次数T。
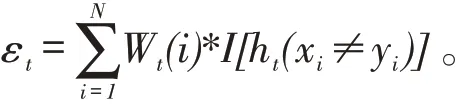

3 仿真实验
3.1 仿真数据
在实际生产中存在着噪声干扰,因此将随机因素作为噪声加入正常控制图模式中,各种异常因素加入相应的异常控制图模式中。为了更加贴合实际,提高分类模型的泛化能力,在每种控制图异常模式中设置不同程度的偏移,保证数据的多样性。对采用蒙特卡罗仿真产生的不同模式下的样本数据进行研究,详细的样本点数据公式描述如下:
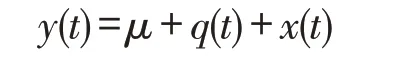
其中y(t)表示t时刻的工序质量值,q(t)表示t时刻的随机因素,x(t)表示t时刻的异常干扰因素。表1给出了控制图的六种模式以及相应的模式表达式,为了讨论方便,不失一般性,此处取μ=0、σ=1。本文一共生成1 080组数据(即6种模式,每种模式180组),每组数据包含10 个特征值,即一共生成1 080*10 的数据集。其中取720*10为训练集(每种模式120组);取360*10为测试集(每种模式60组)。各模式下的具体参数设置见表1。

表1 每种模式的参数设置
3.2 参数优化
为了更好地对控制图数据进行模式识别,利用小波分析进行特征提取,消除数据中包含的噪音,其方法是通过提取少量的数据来代表控制图模式数据中的数据变化趋势。本文采用db3小波函数来对控制图模式数据进行分解,将低频近似系数与小波重构数据的形状特征相结合,作为控制图模式数据的特征。将预处理好的数据,放入采用SVM作为改进的Ada-Boost弱分类器识别器的识别模型中,其中SVM的参数优化是通过网格搜索法和交叉验证法对惩罚因子c和核参数g进行参数寻优。方法如下:设置c和g的范围都是[2,2],对该范围内的参数进行网格搜索和5折交叉验证,得到最优的参数组合是[16,12.125 7],训练集的准确率为96.805 6%。
3.3 模式识别实验结果及分析
本文将用预处理好的数据,取每种模式的60组数据作为测试集,即一共生成360*10的测试集。设置对照试验,对比各种算法的识别性能:(1)BP神经网络的输入层神经元为10,隐含层个数为2。(2)采用参数优化后的SVM分类器进行模式识别。(3)采用方法一中的BP神经网络作为AdaBoost的弱分类器进行模式识别。(4)采用参数优化后的SVM分类器作为AdaBoost的弱分类器进行模式识别。(5)利用本文提出的改进后的AdaBoost-SVM进行模式识别。测试结果见表2。
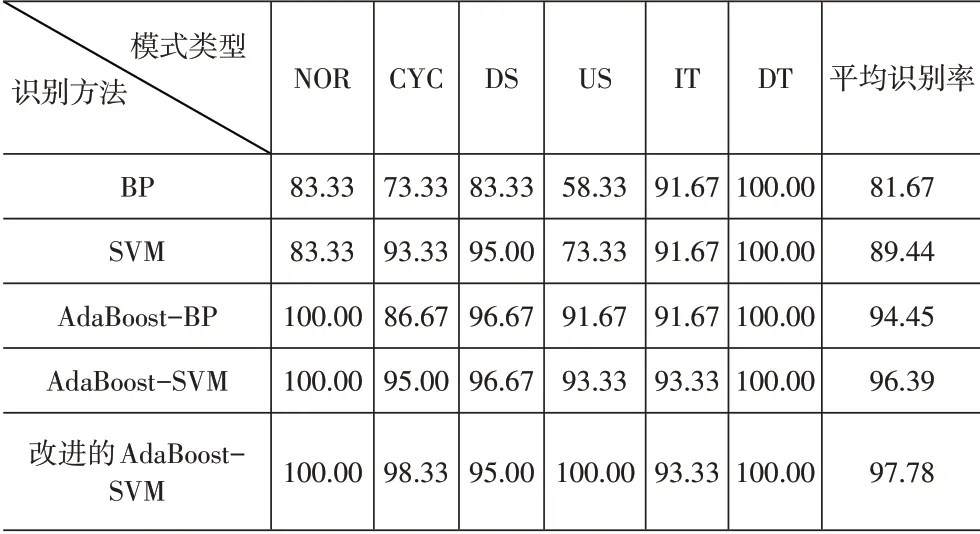
表2 每种识别方法的识别率(%)
对表2的结果分析如下:(1)BP神经网络对六种控制图模式的平均识别率为81.67%左右,而单独使用SVM的平均识别率为89.44%。相比于传统的BP神经网络分类方案,SVM训练的时间虽然比神经网络慢,但是其性能却表现得更好。
(2)对比单一分类器,集成分类器识别率更高。说明将多个弱分类器集成为强分类器,对提高控制图模式识别率有一定的价值。
(3)可以看出,使用改进后的AdaBoost-SVM集成分类器相比AdaBoost-SVM 集成分类器,每种模式的识别率得到了大大的提升。改进后的AdaBoost-SVM集成分类器平均识别率达到97.78%。
对比发现识别性能有明显的提高,综上所述,在控制图数据相同的情况下,对比单一的分类器和集成分类器,发现集成SVM算法对于控制图模式识别有一定的价值,本文进一步提出的改进AdaBoost-SVM 算法具有较高的准确率。
4 实验验证
4.1 实验设计
本文将AdaBoost-SVM控制图识别模型应用于物流港口配煤中。在散货码头物流装备实验室中进行模拟实验,假设需要生成的混配煤的物料比例为1:2,实验过程由斗轮取料机取料到各皮带机上运输,最后通过斗料机进行混合生成混煤。设置两条皮带机均以1m/s匀速运行,抽样检测5组60s内各皮带机上物料的质量,计算得到的各皮带运输机的瞬时流量作为配煤工艺的关键质量特性,采用均值控制图进行控制图模式识别。主要的监测流程是:将瞬时流量输入到本文的模型进行识别,判断配煤的过程状态。如果处于正常状态则继续生产;处于异常状态则进一步判断异常的模式,发出报警并根据专家知识库对应异常模式下的原因调整工序。
4.2 实验结果及分析
模拟实验中,人为的加入干扰因素导致各皮带机瞬时流量出现偏移。实验设置皮带机一在运输物料前,从第45个采样点开始,周期性的改变斗轮取料机取料量;在第20-26个采样点时,皮带机二前端放置一张纸片,改变此处皮带张力,使其出现向上阶跃异常模式。将采集的数据放入AdaBoost-SVM 模型中,进一步测试本文模型在实际生产环境中的可行性。如图2所示,对两个皮带机的瞬时流量绘制均值控制图,瞬时流量要求分别是W=(4±0.3)kg/s、Q=(8±0.3)kg/s。将采集到的数据点采用与仿真实验相同的窗口宽度(n=10)在控制图上移动取值,分别得到51和42个样本。将样本输入到训练好的模型中进行特征提取和模式识别,结果如图3所示。
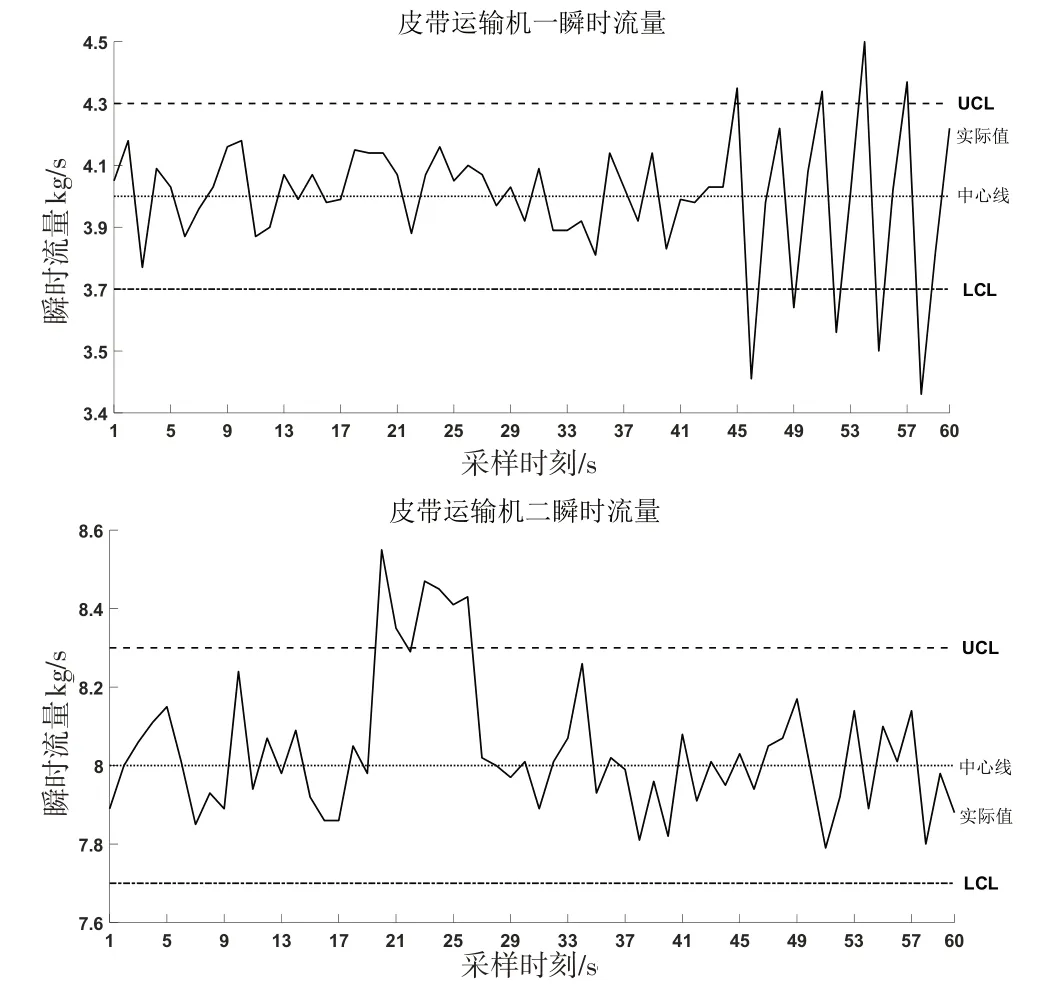
图2 皮带运输机瞬时流量控制图

图3 瞬时流量模式识别
将瞬时流量作为关键质量特性输入到控制图在线监测系统中。当皮带运输机一的控制图在第45个点监测到异常时,将其输入到改进的AdaBoost-SVM模型识别异常模式,运用模型识别出在49-60个点时为周期模式,此时识别模型的性能指标ARL=5;当皮带运输机二的控制图在第20个点监测到异常时,将其输入到改进的AdaBoost-SVM 模型识别异常模式,运用模型识别出在23-26个点时为向上阶跃模式,此时ARL=4。上述实验中ARL的值均小于质量管理体系手册中规定的25,识别性能较好,能及时报警,且识别异常模式与实际的实验设计相符。改进后的Ada-Boost-SVM模型识别与实际模拟实验情况吻合,由此可以说明,改进的AdaBoost-SVM 模型在实际生产过程中对监测到异常状态,并及时调整工艺规则和实施纠正预防措施都具有应用价值。
5 结语
通过对关键工序质量特性进行控制图异常模式识别,在线监测产品生产过程中的状态。本文主要通过小波分析对蒙特卡罗仿真数据进行数据预处理后,将处理好的数据放入参数优化后的SVM 中,最后将SVM作为AdaBoost的弱分类器进行模式识别。为了比较识别的效果,设置对照实验结果表明:对比单一使用SVM和BP神经网络,发现SVM相比BP神经网络具有较高的识别准确率;将单一分类器和集成分类器相比较,结果表明在每种模式下集成分类器具有更好的识别性能,平均识别率达到96%以上;改进后的AdaBoost-SVM分类器相比传统集成分类器,控制图模式识别率进一步提高,达到97.78%。最后通过对皮带机瞬时流量进行监测,得出的结果和实际的模拟实验相同,进一步证明了在实际生产中的应用价值。
猜你喜欢
计算机工程(2020年3期)2020-03-19 12:24:50
中国听力语言康复科学杂志(2019年3期)2019-06-24 09:51:20
中国交通信息化(2018年3期)2018-06-13 03:27:58
电子测试(2018年1期)2018-04-18 11:52:35
电子测试(2017年23期)2017-04-04 05:06:50
智能系统学报(2017年5期)2017-01-22 11:21:30
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中国交通信息化(2016年2期)2016-06-06 07:28:02
智能系统学报(2015年3期)2015-01-29 15:20:12
