
面向分拣的改进型YOLOv3生活物品检测方法*
2022-06-28 01:26:32刘文玉彭晋民吴炳龙游通飞
传感器与微系统 2022年6期
刘文玉, 彭晋民, 吴炳龙, 游通飞
(福建工程学院 机械与汽车工程学院,福建 福州 350118)
0 引 言
随着人类对机器视觉功能需求的不断增长,在生活场景图像中获取可用信息有着极其重要的研究价值。超市货物经过分拣后放入指定的货架,或家庭中选取所需用品可以通过机器人借助相关先进技术代替人工来完成,而分拣物品的首要任务是先检测识别物品,生活物品的检测在家庭和超市服务等方面都有着重要的作用。
目前物品检测主要存在种类繁多、大小不一和检测难度大等挑战。面对这些挑战,人们花费大量精力运用卷积神经网络[1,2]处理图像并取得了一些显著进展。王昌龙等人[3]提出了一种双通道卷积神经网络实现对南瓜叶片病害的识别。郑志强等人[4]用Densenet[5]改进YOLOv3[6]在遥感飞机图像识别方面能够达到96 %的检测精度。显而易见,深度学习在目标识别领域应用范围之广。
在生活物品检测方面,物品大小、种类和颜色方面在生活中存在很大的差异。面对此种情形,本文基于YOLOv3检测算法提出一种检测生活物品的方法,将YOLOv3原算法中的残差块替换成残差密集块,采用5个尺度检测,并引入空洞卷积。改进后的YOLOv3算法在COCO数据集和自制数据集上进行预训练,达到初步识别出生活物品的同时提高网络的泛化性能。
1 YOLOv3算法与总体网络结构设计
YOLOv3网络运用回归的方法来提取特征,实现端到端的物体检测,无需像R-CNN 系列目标检测算法一样生成大量的候选窗口,YOLOv3对输入图像进行目标检测是通过采用单个神经网络实现的。该算法不仅可以保证比较高的准确率,还可以快速完成图像中物体的检测,更加适合用于现场应用环境。YOLOv3网络检测过程中会呈现多个预测框及每个预测框的置信度,剔除置信度低的预测框并通过非极大值抑制算法最终定位物体位置。
若要完成输入图像的目标检测,每个网格需要预测出边界框和条件类别概率,输出边界框中是否包含目标及边界框准确度的置信度信息。 每个边界框对应的类别置信度Confidence计算如式(1)所示
(1)


(2)
在多尺度预测方面,YOLOv3利用残差网络来提取图像中物体的特征,虽然检测精度与速度目前取得了平衡,但对于一些中等或较小尺寸的物体,YOLOv3还达不到理想的检测效果,会出现误检、漏检的问题。
改进后总体网络架构如图 1 所示,该算法是一个直接预测生活物品位置和类别的多目标检测算法,主网络结构是深度残差密集网络。针对 YOLOv3 特征图尺度偏大、准确度低的问题,改进后的算法在主网络之后又增加了2个卷积层和5个卷积层共同构建成含有5个不同尺度卷积层的特征金字塔,与主网络进行融合,形成深度融合的生活物品检测模型。改进后的算法可以防止物品的错检和漏检,显著提高物品的检测精度。
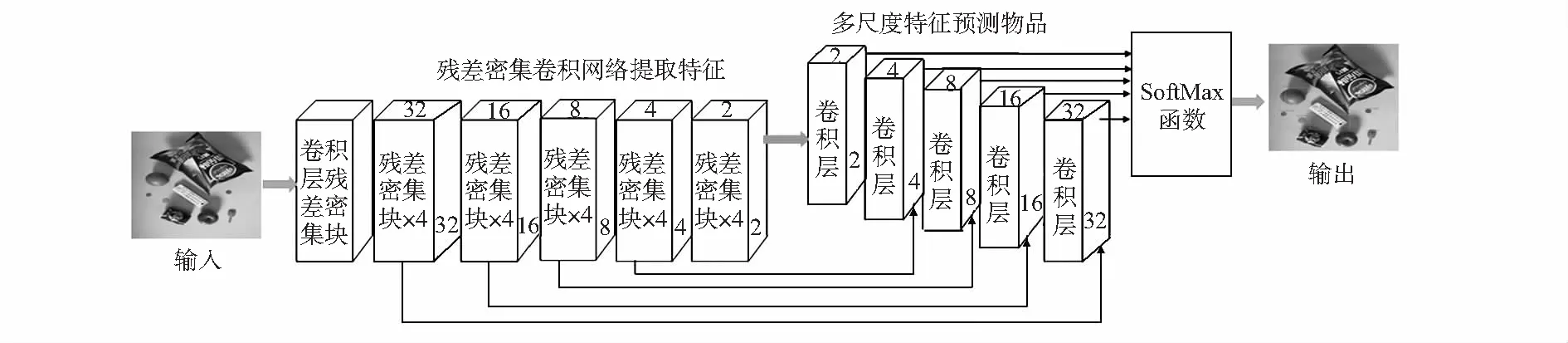
图1 提出的生活物品检测方法结构
2 基于YOLOv3算法的改进方法
2.1 残差密集卷积网络
深度学习网络中密集块[7,8]不仅可以使网络训练过程中梯度消失问题得以减轻,还能够更有效地利用特征图,随着网络层数的增加,残差块具有不易退化的特点,借鉴密集块和残差块的的优势,采用密集块和残差块相结合,如图2所示,两者信息相互融合来可以达到更好地检测效果,该网络通过连续记忆机制从前面的网络中获取图像信息,经过处理后把处理结果传入下一个残差密集块中,局部密集连接起到充分利用所有层的效果,经过局部特征的融合,自适应地保留积累的特征信息。
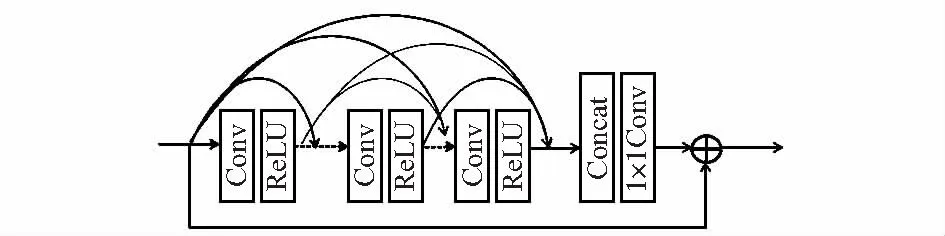
图2 残差密集块网络结构
改进的网络利用残差密集块替换YOLOv3网络中的残差块的设计思想,利用残差密集卷积网络提取生活物品的特征,将残差密集卷积块中提取的特征图与相应尺度卷积层提取的特征图进行信息融合,最终的物品分类由SoftMax分类器完成。
2.2 空洞卷积
为了更好地避免目标检测网络在训练过程中出现漏检和错误检测的现象,提出在特征提取时引入空调卷积。空洞卷积可以扩大特征图的视野范围,将空洞注入到卷积核中,在图3中可以观察到,空洞卷积可以达到扩大感受野的效果;同时,在卷积的过程中获得了各个尺度的全局信息。在网络中增添空洞卷积的扩张率,分别在各个尺度对应的特征图中加入对应的rate,即在第1~5个特征提取图上分别加入1,2,4,4,4倍的rate,让小物体的特征更加明显。

图3 传统卷积运算与空洞卷积运算
2.3 多尺度检测改进
YOLOv3利用高层特征的深层次语义信息,并通过引入特征图金字塔网络(FPN)[9],上采样融合不同层的特征,通过三种不同尺度的特征层来检测物体。针对生活中的物品大小不一的情况,对YOLOv3中的尺度检测模块进行改进,采用5个尺度检测,为目标物体配置更为准确的锚点框。采集到的生活物品图像数据中所有目标标注通过K-means聚类[10~12]确定锚点框的大小,K-means聚类函数为
D(A,B)=1-RIOU(A,B)
(3)
式中A为物体边界框的大小,B为物体边界框的中心,RIOU(A,B)为交并比。
通过K-means聚类确定的先验框参数,并利用残差密集相连5个已经过上采样相应倍数尺度检测的特征层,尺度检测层融合了不同层获得的物体特征,各个尺度特征层的信息流动性提高。多尺度检测模块如图4所示,其中2×,4×,8×和16×依次代表步长为2,4,8,16的上采样。
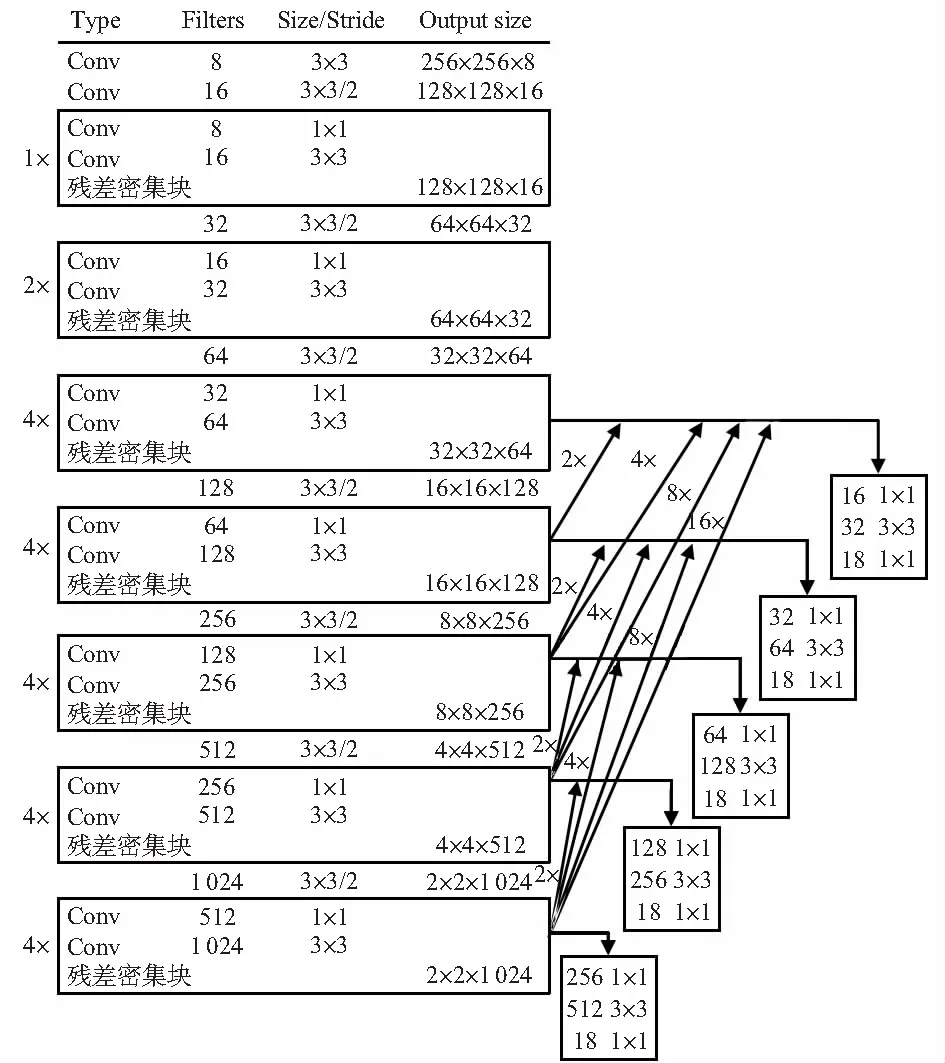
图4 多尺度检测模块
3 实验对比与分析
3.1 图像数据采集与处理
实验采用Kinect v2传感器作为生活物品图像数据的采集设备,图像分辨率为1 920像素×1 080像素。采集时从正视、俯视2个角度对生活中的物品进行图像采集。图像数据中包含单个和多个物品的图像,共采集图像3 306张。其中,仅含单个物品的图像623张、包含多种物品的图像有2 683张,利用图像标注软件LabelImg对图像进行目标位置及类别的标注,采集的各类生活物品图像按照6︰2︰2的比例分配训练集、测试集和验证集。
为使最终的训练结果有较好的泛化性能,对训练集进行水平翻转、垂直翻转、旋转180°、随机缩放宽高比例、随机裁剪、亮度变化和饱和度变化的数据增强处理。
3.2 实验结果与分析
为评价所提出的方法对生活物品识别的性能优劣,使用平均精度(average precision,AP)作为生活物品检测的评价指标。在得到物品的精度(precision,Pr)和召回(recall,Re)率后即可计算AP,计算公式如下
(4)
(5)
(6)
式中TP为将某类物品正确预测为某类物品的个数,FP为将非某类物品预测为某类物品的个数,FN为将某类物品错误预测为不是某类物品的个数,AP为某类物品的平均精度。
Faster R-CNN,SSD,YOLOv3和改进的算法在数据集上进行50 万次的训练,每个权重都会得到图像的检测框文件,四种算法的AP对比结果如图5所示。

图5 四种算法AP对比结果
折线图中横坐标为训练次数,每个算法每5万次标记一个点。可以明显观察到,改进后的算法在测试中整体好于其他三种算法。
YOLOv3算法分别在COCO,COCO+自制数据集两种数据集上进行训练和测试,随机抽取300张图像的实验结果如表1所示。

表1 数据集对应训练结果 %
从表1观察到,在COCO+自制数据集上训练得到的精度明显优于COCO数据集,自制数据集更贴近生活物品原有的特征,可以提高YOLOv3算法在生活物品方面的识别能力。
改进后的YOLOv3算法与原YOLOv3算法、Faster R-CNN[13]和SSD[14]算法在COCO数据集和自制的测试集上进行实验,从测试集中随机筛选出300张来统计结果,结果如表2所示。

表2 四种算法性能对比 %
由表2可知:改进后的YOLOv3算法在精度指标AP上均超过其他算法,达到了91.96 %,具有优异的检测性能。在50万次训练中得到的AP比原算法提高了5 %左右;精确度略低是由于其检测到更多的物品同时产生了更多的误检目标;但在召回率这一项就明显高于其他方法,是所有算法里漏检最少的。最后的AP很好地反映了算法的优劣,足以说明改进后的方法效果好,并且在检测时间上每张图片花费大约0.043 s,优于 YOLOv3的检测速度。
取50万次中AP最高的权重文件对应测试图像进行对比得到部分对比结果如图6所示。图中可以看到,Faster R-CNN算法的检测效果较差,存在明显漏检现象。SSD算法虽然检测速度上有一定优势,但存在检测框偏大的问题。YOLOv3的检测效果虽不错,但仍然出现了少数的漏检情况。改进后的算法在的较大目标物品的检测准确率几乎为100 %,对小目标物品的检测精度也明显好于其他方法,没有受到任何干扰,这是其他几种方法都没有做到的。这说明改进后的算法获取到了更多且更深层次的特征信息,在检测目标的大小上有着良好的适应性。

图6 四种算法对应检测结果
4 结 论
在YOLOv3算法模型基础上,从网络模型、多尺度检测方面对原算法进行改进和优化以用于生活物品的检测。采用自制的生活物品数据集训练网络模型,改进后的算法与Faster R-CNN,SSD以及YOLOv3等算法进行对比实验。实验结果表明:改进后的算法检测精度能够达到91.96 %,较原算法提高5 %,并优于其他算法,具有优异的检测效果,能够满足生活物品识别分类的要求,在家庭和超市中的物品分拣等方面有广阔的应用前景。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31 08:33:14
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
疯狂英语·初中天地(2021年11期)2021-02-16 00:38:58
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
自动化学报(2019年6期)2019-07-23 01:18:32
少年漫画(艺术创想)(2019年2期)2019-06-06 07:47:02
太空探索(2016年5期)2016-07-12 15:17:55
小天使·一年级语数英综合(2015年8期)2015-07-06 06:23:32
河南科技(2015年8期)2015-03-11 16:23:52
