
一种应用位置预测的动态寻呼框架*
2022-06-28 06:52陈发堂张杰棠贾俊文
电讯技术 2022年6期
陈发堂,张杰棠,贾俊文
(重庆邮电大学 通信与信息工程学院,重庆 400065)
0 引 言
移动通信系统需要适当的机制对终端(User Equipment,UE)进行移动性管理,以便在有寻呼的时候能尽快地把消息传达给终端。移动性管理的典型流程包括位置更新和寻呼。随着移动通信的迅猛发展以及智能终端的普及,移动终端相关流程的信令开销大幅增加,管理移动通信中的信令消耗以防信道资源消耗殆尽极其重要,如何减少移动性管理中的信令消耗是一个值得研究的课题[1]。
由于寻呼区域中小区的数量越少则寻呼的开销也会减少,但是同时会增加位置更新的次数且会消耗终端更多的电量[2],因此有研究者通过最优化寻呼区域来权衡位置更新和寻呼这两个流程所消耗的信令[3]。文献[4-5]在采用非同时寻呼的方案的同时,作者意图为每个UE通过深度学习以及预测来定制化一个寻呼区域。这样的方法能有效减少寻呼信令的开销,但在训练阶段UE和核心网之间的沟通会导致更多的信令消耗,再者即使核心网的计算能力足够强大,但当终端的数目逐渐增多时训练所带来的计算量以及数据的存储量是核心网无法承受的,况且当预测失败的时候反而会造成更多的寻呼信令消耗。在文献[6]中作者通过海量数据分析用户行为来制定某些地点的跟踪区域,这种方法效率不高且只适用于某些场合。
在解决由于用户移动而出现的问题时,应用移动性预测是一种有效的方法[7]。在移动通信的移动性管理的方面,需要一个合适的框架来将这些新型的预测方法有机地融合起来。
本文简要描述了在传统的LTE系统中跟踪区域更新和寻呼的流程,在此基础上提出了一种移动性管理的框架,核心思想是通过预测UE的位置实现精准寻呼,从而减少终端被叫时寻呼信令的消耗。本文所提出的框架主要分为两个部分,分别为预测部分和回落部分。预测部分旨在使用基于深度学习与训练的算法来通过UE的历史信息来预测UE将来的位置,本文并没有使用具体的算法来实现预测部分的功能,而是提供了一个合理的方案来将这类算法融合到移动性管理的框架里面。此方案能将训练过程中庞大计算量卸载到终端上,减少核心网的运算负担。回落部分指的是当预测部分提供的预测错误的时候,启用回落机制来使系统继续正常运行。当预测失败时,UE再次进行预测需要一定的时间来收集所需要的信息。在这段真空期内,本文采用了一种动态寻呼的方式来处理寻呼,这种动态寻呼的方式在UE移动幅度不大的情况下能有效减少寻呼信令的消耗。
1 LTE移动性管理概述
在LTE系统中,移动性管理由非接入层中的移动性管理实体来负责[8],主要包括跟踪区域更新与寻呼(Paging)两个流程。如图1所示,一个基站覆盖的区域称为一个小区(Cell),每个小区拥有一个唯一的小区号。若干个邻近的小区组成一个跟踪区域(Tracking Area,TA),相应的每个跟踪区域也有唯一的识别号。若干个相邻的跟踪区域在一起进一步组成一个跟踪区域列表(Tracking Area List,TAL),两个跟踪区域列表允许有重合的部分,移动终端存储的跟踪区域列表中应该包含自身所在的跟踪区域。

图1 LTE移动性管理框架
在现行的LTE系统中,假如处于IDLE态(非接入层的空闲态)的UE离开当前存储的TAL时,UE会向核心网发起TAU过程,告知核心网新的位置并请求网络重新分配TAL。在本文的分析中,假设核心网分配跟踪区域列表按照“中心原则”来进行[9],即当移动用户离开当前跟踪区域列表时,所进入的跟踪区域为新的跟踪区域列表的中心,如图1所示,若UE从Cell 6离开TAL1,则在新的TAL 2中,Cell 7所在的TA 4为TAL 2的中心。
当有寻呼要传达给移动用户的时候,核心网要求移动用户所在的TAL里的所有小区都发送寻呼信令。这种寻呼方式能在没有任何关于UE的额外信息的情况下第一时间内寻呼到UE,但是因为UE只可能在TAL里的某一个小区内,所以大部分的寻呼信令是浪费了的。本文基于此提出了一种新的寻呼机制,在传统的马尔科夫的排队模型分析的基础上与当今新型预测方法有机结合,有效减少了IDLE态下移动性管理的寻呼信令开销。
2 动态移动性管理框架
2.1 动态寻呼模式
在有限的时间内,移动端的移动范围通常是不大的,如果核心网寻呼UE的时候直接令TAL内所有的小区都发寻呼信令,则会造成一定程度上的浪费。本文采用一种新的寻呼方式。
经过寻呼或者TAU之后核心网会确定UE所在的小区,本文称这个小区为相关小区。UE在此之后进入IDLE态并自由移动。如果UE离开当前TAL,则会发起一个TAU,此时相关小区会随之更新。核心网所知道的关于UE的位置信息有UE的相关小区和UE所在的TAL,假如UE的移动幅度不大,可以先直接在UE的相关小区进行寻呼,如果没有得到响应,紧接着在相关小区所在的TA的其他小区进行寻呼,如果仍然没有响应,则在当前TAL的其他TA的所有小区进行寻呼。
按照这个流程来进行寻呼,所需的信令数不会超过传统的方式,且有很大的概率会远小于传统的方式,从而能够有效减少信令的损耗。
2.2 预测模式
在本文中,预测的目的是当寻呼到达时能够准确地定位到UE所在的小区,如果预测正确的话,核心网只需发送一条寻呼信令即可完成寻呼过程,有效减少信令消耗。
本文采用的预测机制可分为两个部分,分别是UE侧的部分以及核心网侧的部分。在UE侧,UE需要收集用户的地理位置、时间等有助于进行预测分析的信息。地理位置可以由经度和纬度来表示,但是在LTE系统中,我们的预测只需要精确到小区层面,所以移动端收集地理信息时只需要收集小区ID即可,这样能使向核心网传达预测信息时的代价变小。
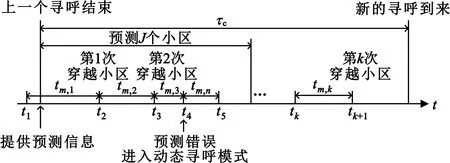
在收集到足够的信息之后,UE开始使用预定好的算法进行训练,训练完成后预测出一条UE可能会行进的路径,此路径包含J个小区,预测完成后把结果传达给核心网。在此之后,UE检测当前所在的真实位置与发送给核心网的预测位置是否一致,若一致,则代表预测正确,此时UE不用做任何处理;如果UE检测到所在小区与预测小区存在偏差,表明预测错误,此时UE发起TAU流程,告知核心网之前的预测作废,系统回落至上述的动态寻呼模式。
另一方面,核心网收到UE传来的预测信息之后开启预测模式,此时核心网只监听新的跟踪区域更新消息。当核心网处于预测模式时,如果核心网没收到UE发送的任何消息,核心网默认预测位置是正确的,此时核心网认为预测小区正是UE所在的小区;如果核心网收到了UE发的TAU,表明预测错误了,则在此之后移动性管理回到动态寻呼模式并认为最后一个预测正确的小区是相关小区。
在这个预测架构之下,信息获取和训练预测模型都是在UE侧完成的,在获取信息和训练的时候并不需要核心网的参与,这样复杂度较高的训练环节是由UE自主完成,这样做既能有效减少核心网的计算量,又能减少UE与核心网之间的信令交互。加上如今UE的芯片制程越来越小,这使得UE在拥有更强大的计算力的同时还可以节省一定的功耗,这种预测模式能有效地利用各方面的资源。
在这种模式之下,UE能够实时检测预测的结果是否准确,即使预测不准确也能回退到动态寻呼模式使整个流程正常进行。
3 建模与求解
本节根据前文所述的方案进行建模,使用一维随机行走模型作为分析基础,求出在上一个寻呼结束到下一个寻呼到来的一段时间内所消耗的寻呼信令的期望值。在本文的仿真分析中会把一维模型扩展成二维模型。
3.1 动态寻呼模式建模
根据前文所述模型,预测失败后会回落到动态寻呼模式,所以下面首先分析接连寻呼模式下的信令的期望值。如图2所示,移动端在上一个寻呼结束到下一个寻呼到来的时间间隔τc内进行自由活动。设一个TA内包含有Nc个小区,一个TAL内有Nt个TA。如图3所示,移动端以概率p向右边小区移动,以概率1-p向左边小区移动。根据分配TAL的“中心原则”,当移动端从TAL的最左边小区离开当前TAL时,会进入新的小区Nc⎣Nt/2」+1。同理,当移动端从TAL的最右边小区离开当前TAL,会进入小区Nc(⎣Nt/2」+1),根据图3中的状态转移图,易求得其平稳分布πi,i=0,1,2,…,NcNt。

图2 动态寻呼模式时间轴
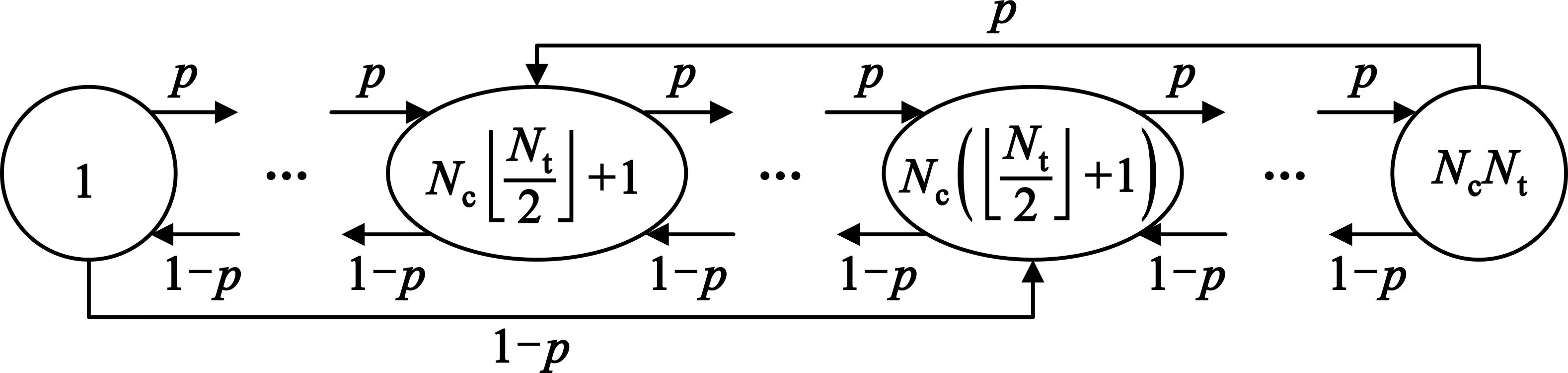
图3 TAL内小区状态转移图
假设τc服从参数为λc的指数分布。在τc内,移动端穿越了K个小区且进行了N次位置更新。设移动端在第i个小区的驻留时间tm,i服从均值为1/λm、方差为V的伽玛分布,根据文献[21],在τc内穿越k个小区的概率为
(1)
由于上一个寻呼结束时无法得知移动端处于TAL的哪一个小区内,所以需要先求出图3中马尔科夫链的平稳分布π=(π1,π2,…,πNcNt)。
π=πP。
(2)
式中:P为图3的转移概率矩阵。
接着开始求经过k次小区穿越和n次位置更新之后,移动端仍然驻留在相关小区的概率。此处先修改上述的马尔科夫链,如图4所示,在其左右两端分别增加一个吸收态,用来表示走出了当前的TAL。

图4 增加吸收态的状态转移图
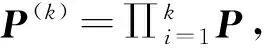
(3)
和
(4)
式(3)代表初始状态为i,在第k步的时候走到状态0(即在第k步从TAL左侧离开)的概率。同理,式(4)代表初始状态为i,在第k步的时候走到状态NcNt+1(即在第k步从TAL右侧离开)的概率。
继而可求得初始相关小区为i,穿越了k个小区并进行了n次位置更新后,移动端仍然处于相关小区的概率
(5)
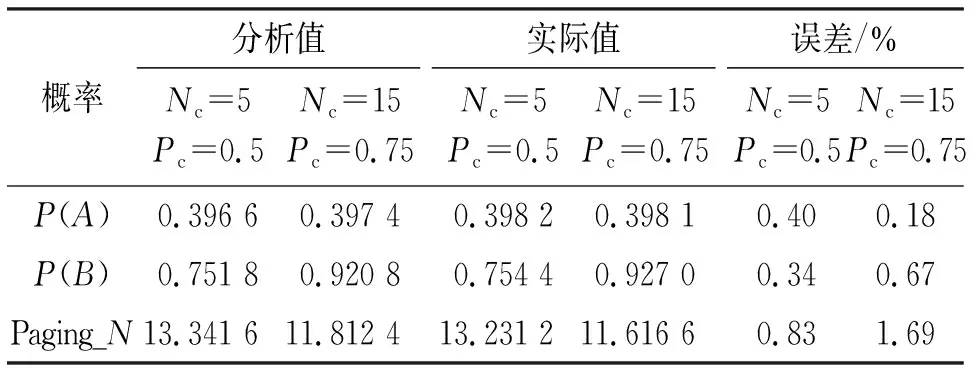
当k=0且n=0时,表明UE没有移动,必然在相关小区。k>0且n=0时表明移动端还未移出当前TAL,则仍然驻留在相关小区的概率即初始状态为i,结束状态也为i的k步转移概率。当k≥n≥1时,要考虑两种情况:第一种情况是如果UE在第j步从左侧离开TAL,则新的相关小区是Nc(⎣Nt/2」+1),子问题就变成了初始状态为Nc(⎣Nt/2」+1),穿越k-j个小区并执行了n-1次位置更新后,仍然驻留在相关小区的概率;如果UE从右侧离开TAL也同理,式(5)可用动态规划的方法来求解。由于不存在k 综上所述,当下一个寻呼到来的时候,移动端仍然处于相关小区的概率为 (6) 同理可得初始相关小区为i,穿越了k个小区并进行了n次位置更新后,移动端仍然处于相关小区所在的TA的概率 (7) 由此可以得到当下一个寻呼到来时移动端仍然处于相关小区所在的TA的概率为 (8) 所以,当一个寻呼到来时,所需的寻呼信令的期望值为 Paging_N=θc+(θc-θt)Nc+(1-θt)NcNt。 (9) 本小节在接连寻呼模型基础上,加入预测机制一起建模。如图5所示,本文假设移动端会提供J个预测值,如果J大于k,则τc内穿越的k个小区都是经过预测的。如果前j个预测正确(此时j小于k),第j+1个小区预测错误,则从第j+1个小区开始进入动态寻呼模式,此时穿越的小区个数为k-j,穿越的小区个数越少,有利于发挥动态寻呼模式的优势。如果k个小区全部预测正确,则只需要一条寻呼信令就能寻呼到UE。 图5 预测模式时间轴 若J小于k且前j个小区预测正确,第j+1个小区预测错误,则从第j+1个小区开始进入动态寻呼模式。如果J个小区全部预测正确,则从第j+1个小区开始进入动态寻呼模式。 (10) 令事件A为在上一个寻呼结束后,UE提供了J个路径预测值,当下一个寻呼到来时移动端仍然在相关小区;事件B为在上一个寻呼结束后,UE提供了J个路径预测值,当下一个寻呼到来时移动端仍然在相关小区所在的TA。可以推出,在上一个寻呼结束后,UE提供了路径预测,但是第j+1个小区预测错误的情况下,当下一个寻呼到来时移动端仍然在相关小区的概率 (11) 式(11)表明如果k小于等于j,则当下一个寻呼到来时,预测肯定正确,所以移动端仍然在相关小区的概率为1。如果k大于j,则表明穿越第j个小区以后进入动态寻呼模式,由于前j个小区是预测正确的,所以在动态寻呼模式中进行的步数为k-j,修改式(6)中相应的部分即可得出式(11)。 继而可得 (12) 同理可得 (13) 所以,在增加预测路径预测之后,下一个寻呼到来时所消耗的寻呼信令的期望值为 Paging_N=P(A)+(P(B)-P(A))Nc+(1-P(B))NcNt。 (14) 下面利用蒙特卡洛仿真方法进行仿真,仿真首先以式(2)求得的分布律生成一个随机数代表此次随机样本的初始相关小区,然后根据式(1)所求的分布律为基础生成一个随机数,代表此随机样本在τc内移动端穿越的小区数k。移动端的实际移动路线通过生成k个服从0~1之间均匀分布的随机数表示,一维情况下如果随机数小于0.5则代表向左移动,大于0.5则代表向右移动。同理,在二维随机行走模型的情况下,把区间[0,1]平均分成4份,分别代表上、下、左、右四个方向。在生成实际移动路线的同时,也会生成J个服从0~1之间均匀分布的随机数,代表J个路径预测的值,如果随机数大于1-pc,则代表预测正确,反之代表预测错误,其中pc代表的是每个预测小区正确的概率。之后只要不断的重复上述步骤并统计结果即可得到最后的仿真结果。 表1中的分析值是运用第3节中的公式计算出来的数值,实际值是通过蒙特卡洛仿真得出的,此处根据前文描述随机生成了50 000名用户的移动路径,然后模拟每个终端的移动过程来统计各数值。误差是由分析值减去实际值然后除以实际值得出的百分比。 表1 分析值与实际值比较 图6 小区数与预测成功率对寻呼信令数的影响 图7是在二维情况下用45×45的小区结构进行仿真的结果,可以看出此方法在一维情况下仿真结果和二维仿真结果的趋势是一致的,上述在一维情况下的发现也能够解释在二维仿真中出现的结果,因此本文剩下的仿真也着重分析一维仿真的结果。 图7 二维情况小区数与预测成功率对寻呼信令数的影响 图8 预测小区数对寻呼信令数的影响 图9 UE移动速率对寻呼信令数的影响 本文主要研究考虑减少移动通信中移动性管理过程中寻呼信令的消耗的问题,并通过仿真实验说明了本文提出的方案对于减少移动性管理过程中的信令消耗是可行的。同时相对于传统的寻呼方法,不是只单纯使用传统的马尔科夫排队模型来分析,在本方法中将预测模型加入到寻呼框架之内,可以有效减少移动性管理过程中的信令消耗。在本方法中信令指标的值是根据UE的移动情况实时累计得到的,该方案可有效解决大量寻呼信令消耗的问题。

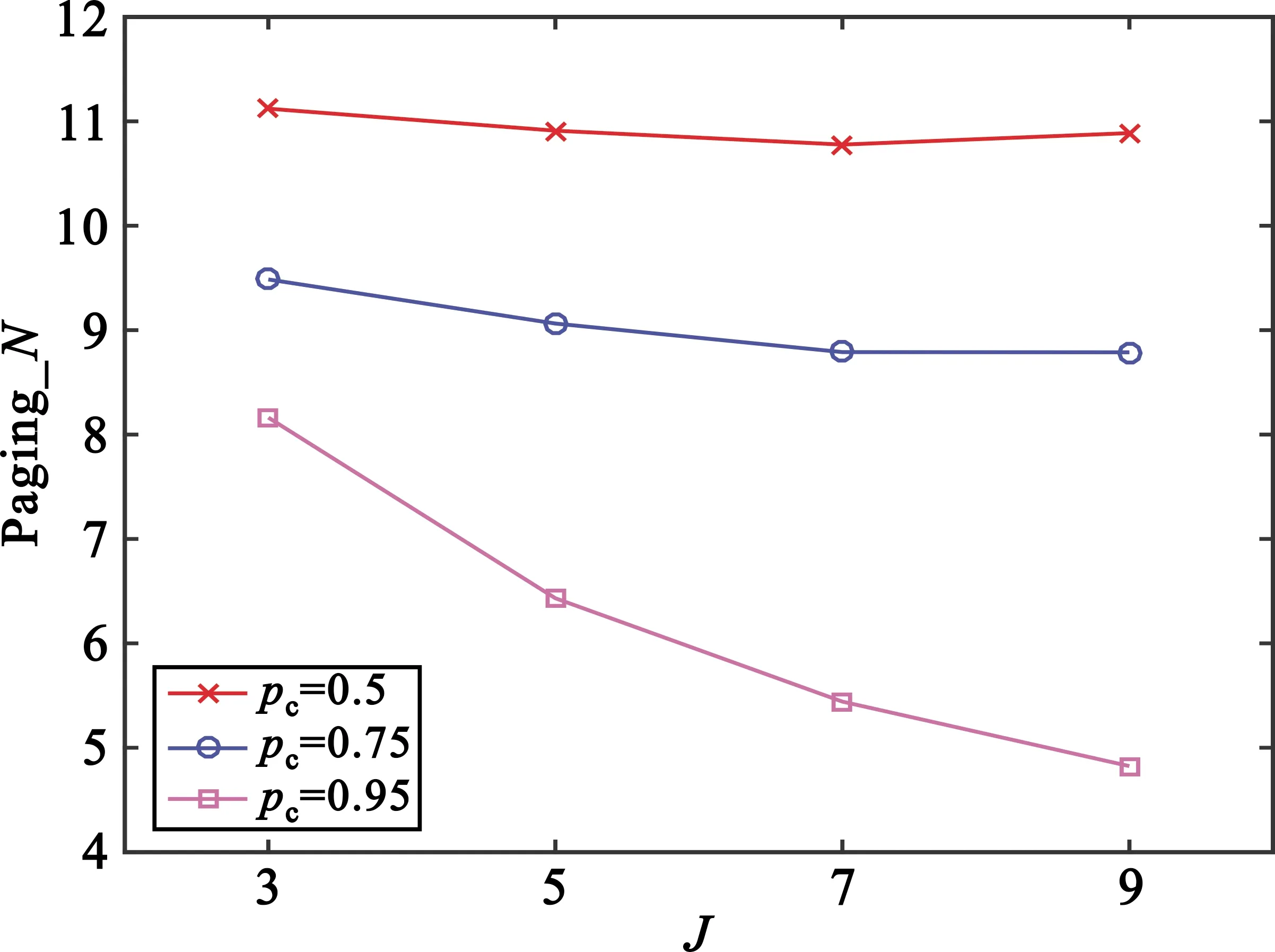
3.2 预测模式建模


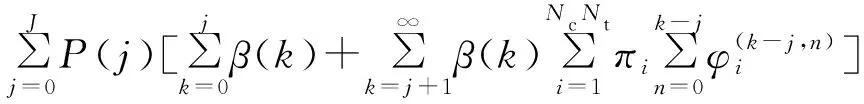
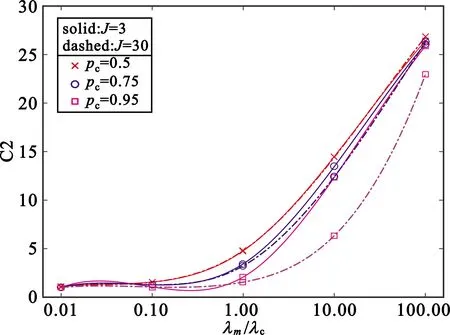
4 仿真与分析





5 结 论
猜你喜欢
中国信息化(2022年6期)2022-07-18
国际太空(2021年11期)2022-01-19
铁路通信信号工程技术(2019年10期)2019-11-06
铁道通信信号(2019年6期)2019-10-08
科技传播(2019年24期)2019-06-15
中国交通信息化(2019年2期)2019-03-25
中国计算机报(2019年46期)2019-01-13
消费导刊(2017年24期)2018-01-31
移动通信(2017年19期)2017-11-14
互联网天地(2016年2期)2016-05-04
