
Exploring Image Generation for UAV Change Detection
2022-06-25 01:17XuanLiHaibinDuanYonglinTianandFeiYueWang
Xuan Li, Haibin Duan,, Yonglin Tian, and Fei-Yue Wang,
Abstract— Change detection (CD) is becoming indispensable for unmanned aerial vehicles (UAVs), especially in the domain of water landing, rescue and search. However, even the most advanced models require large amounts of data for model training and testing. Therefore, sufficient labeled images with different imaging conditions are needed. Inspired by computer graphics, we present a cloning method to simulate inland-water scene and collect an auto-labeled simulated dataset. The simulated dataset consists of six challenges to test the effects of dynamic background, weather, and noise on change detection models.Then, we propose an image translation framework that translates simulated images to synthetic images. This framework uses shared parameters (encoder and generator) and 22 × 22 receptive fields (discriminator) to generate realistic synthetic images as model training sets. The experimental results indicate that: 1)different imaging challenges affect the performance of change detection models; 2) compared with simulated images, synthetic images can effectively improve the accuracy of supervised models.
1. INTRODUCTION
CURRENTLY, unmanned aerial vehicles (UAVs) [1] are receiving more and more attention for their capabilities of water rescue [2], search, aerial observation [3], and surveillance [4]. Visual perception is an important part of UAVs to accomplish the above tasks, and change detection(CD) plays an essential role in visual perception. Image-based CD, also referred to as background subtraction, aims to predict the location of moving objects in an image. It is becoming an increasingly active area of research in computer vision community.
Accurate CD can filter redundant data, which is useful for object detection, object tracking, and recognition. There are two methods to improve the performance of CD. On the one hand, researchers design the structure of algorithms to enhance the UAV’s adaptability in complex environments. On the other hand, data augmentation can comprehensively test and optimize the parameters of algorithms. During the past decades, much work has been done to solve CD model performance under complex conditions. For instance, tradition algorithms use different features to perceive pixel state, including color [5]-[7], edge [8], texture [9], etc. Subsequently,the models [10], [11] based on deep convolutional neural networks (DCNN) are widely used to extract features automatically. Nonetheless, a DCNN model requires learning of specific parameters from pixel-level labeled images.However, manual annotation of every pixel is timeconsuming, cumbersome, and subjective. As described, there are two trends in the research of CD. 1) vision algorithms based on deep learning are widely discussed and studied;2) vision data is helpful for algorithm training and testing, but various difficulties are encountered in image data collection and annotation. Lots of works [12], [13] have demonstrated the strength of the virtual world on computer vision. In addition, some researchers use generative adversarial networks (GANs) to generate realistic images for CD research. For instance, Lebedevet al. [14] proposed an image synthesis method that use a GANs model to improve remote sensing CD performance. Niuet al. [15] presented a conditional GANs to generate homogeneous CD images, making the direct comparison feasible. Besides, Liet al. [16]introduced a deep translation based change detection network(DTCDN) for optical and synthetic aperture radar images. In this paper, we use Unity3D to create a simulated scene that automatically generates labeled simulated images. Then, a novel generative adversarial networks is proposed to translate simulated images into synthetic images. Finally, the experiments are conducted to verify the effectiveness of simulated and synthetic images in CD. The overall framework is illustrated in Fig. 1.
The main contributions of this work can be summarized as follows.
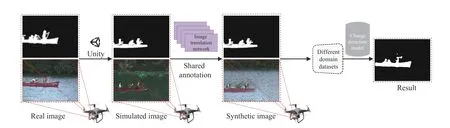
Fig. 1. The overall framework of the proposed method. In this paper, the simulated images denote to images with accurate labeling and multi-challenge generated by computer graphics platform, while the synthetic images denote to images generated by image translation model. Note: real, simulated and synthetic datasets are used to train or validate different change detection models. All generation datasets are available at: https://github.com/lx7555/Exploring-Inland-Water-Scene-Generation-for-Change-Detection-Analysis, which may have a large potential to benefit the change detection community in the future.
First, we use a novel cloning method to construct a simulated inland-water scene. In the simulated scenario, imaging challenges can be flexibly configured to obtain multichallenge sequences. Besides, all images are automatically labeled with an accurate ground truth for CD.
Second, we propose an image translation framework consisting of a variational autoencoder (VAE) and generative adversarial networks (GANs). The VAE (based deep convolutional networks) includes more global information conducive to style-translation of synthetic images. Besides,the GANs can map two domain images to the same semantic space. This method uses a cycle-consistency constraint and PatchGAN discriminator to achieve high-quality synthetic images.
Third, computational experiments are used to qualify the impact of multi-challenge sequences and synthetic datasets on CD. It is found that the simulated datasets’ diversity can quantitatively analyze UAV’s vision model performance.More importantly, the experimental results demonstrate that synthetic datasets can effectively improve deep learning-based detectors.
The rest of this paper is organized as follows. Related works will be reviewed in Section II. Section III provides the details of designing simulated scenes and image translation networks.Experimental results of different datasets are carried out in Section IV. We give the conclusion in Section V.
II. RELATED WORK
The models and datasets of CD have remained research hotspots for several years. In the remainder of this section, we review related works in detail.
A. Change Detection Models
The simplest of CD models is the FrameDifference method[17], which compares the current frame with previous frame(or background frame) to identify the state of pixels. However, this model can only determine the boundary information of moving objects. In order to enhance the robustness of models, Stauffer and Grimson [18] proposed a Gaussian mixture model (GMM) to represent the state of each pixel.However, the GMM framework can not adapt to a dynamic background in different scenes (illumination variations,camera jitter) and runs slowly. Subsequently, the nonparametric kernel density estimation (KDE) method [19] avoids delicate parameter estimation and uses a smooth probability density function to fit a time window of images. The GMM,KDE methods and their variants [20], [21] are multimodal techniques, which still play an important role in practical engineering. In 2014, a classical background subtraction model (visual background extractor, ViBe) was proposed [22].The ViBe model can meet real-time requirements and effectively deal with dynamic background, camera jitter and ghosting. In the traffic surveillance field, it is possible that multiple challenges coexist in a single scene. As stated in [23],[24], the research proposed effective multi-view learning methods to detect foreground objects from complex traffic environments. After that, St-Charles and Bilodeau [25]presented a background modeling and subtraction algorithm based on adaptive methods, named “local binary similarity segmenter (LOBSTER)”. This model integrates local binary similarity pattern (LBSP) feature components to deal with spatiotemporal variations for each pixel. In [26], the selfbalanced sensitivity segmenter (SuBSENSE) model uses spatiotemporal information, color and texture features, as well as pixel-level feedback to characterize local representations in pixel-level models. The SuBSENSE can be adjusted automatically for many different challenges (illumination variations, dynamic background motion).
Recent developments of deep learning-based CD methods have attracted much attention due to their impressive performance beyond classical methods. Braham and Van Droogenbroeck [10] used convolutional neural networks and a single grayscale background image to design background subtraction algorithms with spatial features. Furthermore,Babaeeet al. [11] presented a novel background subtraction algorithm based on convolutional neural networks for automatic feature learning and post-processing. Lim and Keles[27], [28] proposed a robust encoder-decoder structure CD model that could extract multi-scale features using only a few training examples. This was demonstrated in many studies where CD methods based on deep learning reproduce state-ofthe-art performance at the time.
B. Change Detection Datasets and Synthetic Datasets
As mentioned above, CD algorithms have developed from designing a sophisticated background model to automatic feature learning approaches. However, even the simplest method relies on labeled video sequences for modeling,training, and testing. In particular, the recent revolutionary results [29] of deep learning-based CD foreshadow the importance of image data. For instance, the PETS2001 dataset[30] allowed researchers to submit their detection results for evaluation against a set of applicable metrics. Liet al. [31]introduced a novel dataset with illumination changes and dynamic background, which consisted of 10 video sequences(image size 320 × 240 pixels). A good example is the CDnet2014 dataset [32], which consists of 11 video categories with 4 to 6 video sequences in each category. This dataset as a benchmark provides and contains typical challenges such as dynamic background, night videos, bad weather. A common disadvantage of the above datasets is collecting and labeling images manually, which is costly and error-prone.
With the development of computer graphics and virtual reality, it is possible to extract key information about objects from simulated scenes. For instance, the Virtual KITTI [12]and SYNTHIA [13] can be applied to different computer vision tasks (including object detection, tracking, semantic segmentation, etc.) in the field of autonomous driving.Besides, Tiburziet al. [33] used a chroma studio to record foreground objects to obtain pixel-level masks for 15 semisynthetic video sequences automatically. Brutzeret al. [34]introduced a simulated dataset with accurate ground truth annotations and shadow masks for driving scenes. This simulated data provided major challenges of CD to assess detectors. However, due to the bias between real images and simulated images, it not easy to get satisfactory results by learning from simulated images. In 2014, Goodfellowet al.[35] proposed the generative adversarial networks (GANs),which consists of a generator and a discriminator. The generator captures real data distribution and generates synthetic data, while the discriminator distinguishes them for authenticity. Given that fact, Shorten and Khoshgoftaar [36]believed that GANs are the most promising generative modeling technique for image generation. Frid-Adaret al.[37] used deep convolutional generative adversarial networks(DCGANs) to generate liver images and successfully improved the observation accuracy. Zhuet al. [38] proposed a framework using CycleGANs to overcome class imbalance, so this approach effectively improves emotion recognition. Gouet al. [39] presented a universal framework for generating synthetic images to help cascade regression models enhance the accuracy of pupil detection. However, image generation based on generative adversarial networks is mainly used for digital and emotion recognition research.
III. THE METHODS OF DATA GENERATION
Vision-based change detection in water scenes is a key functionality for UAVs. If properly annotated datasets are not available, current algorithms are not sufficient to produce reliable classifiers. Computer graphics and generative adversarial networks are applied in the computer vision field[40], [41], from which simulated images and synthetic images are derived. Due to the shortcomings of existing datasets, we first describe generation of simulated images in simulated scenes (Section III-A). Then, we propose an image translation framework for generating photo-realistic synthetic images(Section III-B). Finally, we construct multi-challenge sequences and high-quality training sequences using simulated images and synthetic images (Sections III-A and III-B).
A. Simulated Images Generated From Computer Graphics
1) Constructing Simulated Scene:Computer graphics have been developed as a viable approach to tackle the longstanding difficulty in visual perception and understanding of complex scenes. In this section, we construct a simulated scene based on real scenes. Specifically, the CDnet2014 consists of 11 categories of video challenges. We use a cloning method to build a simulated inland-water scenario using CDnet2014 datasets (dynamic background category,canoe sequence) as a reference. Considering that the simulated scenario is mainly used for UAV change detection, we divide this scenario into several modules: foreground objects,background models, and imaging challenges. To begin with,we use publicly available and self-designed models as foreground objects (boats, pedestrians), and configure their speed, angle, position, and posture as needed. Then, since background models are stationary or moving slowly, we manually set their position and state, making them similar in content to real scenes. Furthermore, different imaging challenges make it possible to quantitatively test models. In our simulated scene, the challenges considered include (but not limited to): wave height (i.e., low (1 m), medium (2 m),and high (3 m)), noise (i.e., Gaussian, salt and pepper), and illumination variations (from 12:00 am to 12:00 pm). Note that foreground objects and background models are distinguished by labeling information, and imaging challenges are mainly used to generate multi-challenge video sequences.
2) Generating Ground Truth Labels:The above steps preliminarily complete construction of simulated scenes. This part introduces automatic labeling process in detail. Accurate evaluation results of CD depend on pixel-level annotations.More importantly, deep learning-based models highlight the importance of labeled images. However, Kunduet al. [42]pointed out that it usually requires 30-60 minutes to label an image at the pixel-level. What is more, it is difficult and errorprone to manually label pixels near the foreground object boundaries. These facts suggest that we need to find a better way to replace the controversial manual approach. Therefore,we use Unity3D to solve this problem from the perspective of computer graphics. Computer graphics can easily obtain information about components (vertices, edges, polygons) of 3D models and transform them into binary ground truth images. The original image and binary ground truth image are rendered separately and output independently. In addition,three rules are employed empirically to ensure labeling quality:
i) There are four common classes (Static, Moving, Non-ROI(region of interest) and Unknown) that assign grayscale values of 0, 255, 85, and 170, respectively (as shown in Fig. 2).
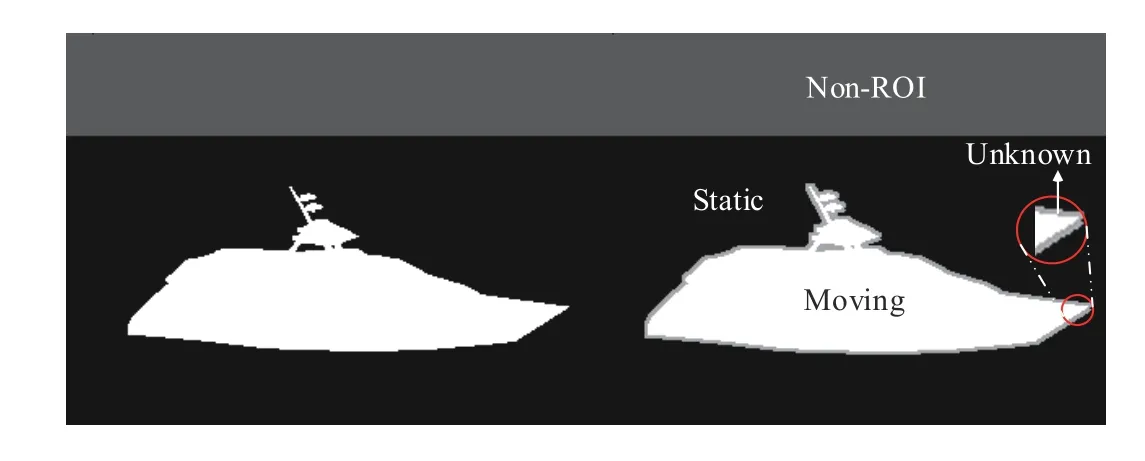
Fig. 2. Examples of 4-class ground truth annotation automatically generated by Unity3D. Note that Unknown border is represented by 16-neighborhood pixels. Best viewed with zooming.
ii) The Moving, Static, and Unknown classes are associated with pixels for obvious foreground objects, background models and unclear objects boundaries.
iii) The Non-ROI label is associated with unrelated areas,which helps some models complete evaluation and initialization.
3) Designing Simulated Multi-Challenge Sequences:In previous research, Goyetteet al. [32] defined canonical problems for CD, such as dynamic background, intermittent object motion, night video. Due to limitations of real sensors and complexity of real scenarios, these classic problems can not reflect all challenges of UAVs water missions. Based on Goyette’s work, we construct the following multi-challenge sequences using different imaging challenges in simulated scenario (as illustrated in Fig. 3). The height and FOV (field of view) parameters of simulated cameras are 1.5 meters and 90 degrees, respectively. Note: the simulated multi-challenge sequences consist of the following six challenges, each containing 1189 frames (the first 100 frames are labeled as Non-ROI for background model initialization).

Fig. 3. Sample images of simulated multi-challenge sequences. Top: basic(left), dynamic background (middle), and illumination variations (right);Bottom: bad weather (left), noise (middle), and more moving objects (right).
Basic:This is a basic inland-water scenario that includes general foreground objects (boats) and background challenges(rivers and trees).
Dynamic background: This sequence contains videos with dynamic backgrounds, including varying waves (low,medium, and high) and moving tree branches.
Illumination variations: This challenge changes illumination continuously over time until night. Therefore, the contrast between foreground and background is decreased. Here, we use directional parallel light to follow the movement of the sun from east to west.
Bad weather: This is a rain and fog sequence, with increased high gain level and low background/foreground contrast,resulting in more camouflage. The exponential decay method is used to generate simulated fog, while the particle system produces simulated rain.
Noise: The basic sequence adds some sensor noise(Gaussian noise (mean = 0, variance = 0.002), salt and pepper noise (probability = 0.01), mixed noise (Gaussian and salt)) to simulate real scenes, leading to uncertainty.
Moving objects: We add 9 boats with different appearances(aluminum fishing boat, bass boat, bay boat, etc), colors (red,yellow, black, etc.), and speeds (2-5 m/s) to basic sequence,which can fully test CD models.
B. Synthetic Images Generated From Generative Adversarial Networks
The main function of generative adversarial networks is used to narrow the distribution gap in different domains. In Section III-A we use a game engine to generate simulated images. However, building and editing simulated scenes can be still challenging and difficult to cover all gaps from real scenes. Here, we introduce an image generation network to turn the process of manual scene modeling into a model learning and inference problem. More importantly, synthetic images are expected to be used for model training. The overall architecture of the proposed method is shown in Fig. 4.divided into “ImageGAN” and “PatchGAN” due to different receptive fields. The “ImageGAN” has a global receptive field and more weight parameters, making it harder to train and leads to the poor image detail. An alternative approach is PatchGAN, which penalizes the structure at the scale of image patches. In the following, we take this approach to focus on more local style statistics.



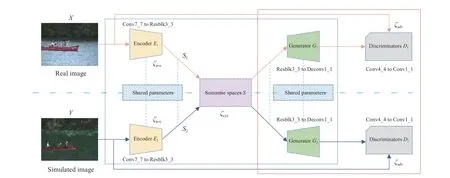
Fig. 4. The overall architecture of the proposed method. The real and simulated images are concurrently inputted into the two variational autoencoder models,whose part of parameters are shared with each other. For discriminators, the middle patch (22 × 22) provides a good balance between quality and flexibility.Therefore, this model can generate a high-quality synthetic image. In the proposed method, the layers from Conv1_1 to Conv5_3, Resblk3_3 to Deconv1_1 and Conv4_4 to Conv1_1 fit the function of encoders E1 and E 2 , generators G 1 and G 2, and discriminator D 1 and D 2, respectively.
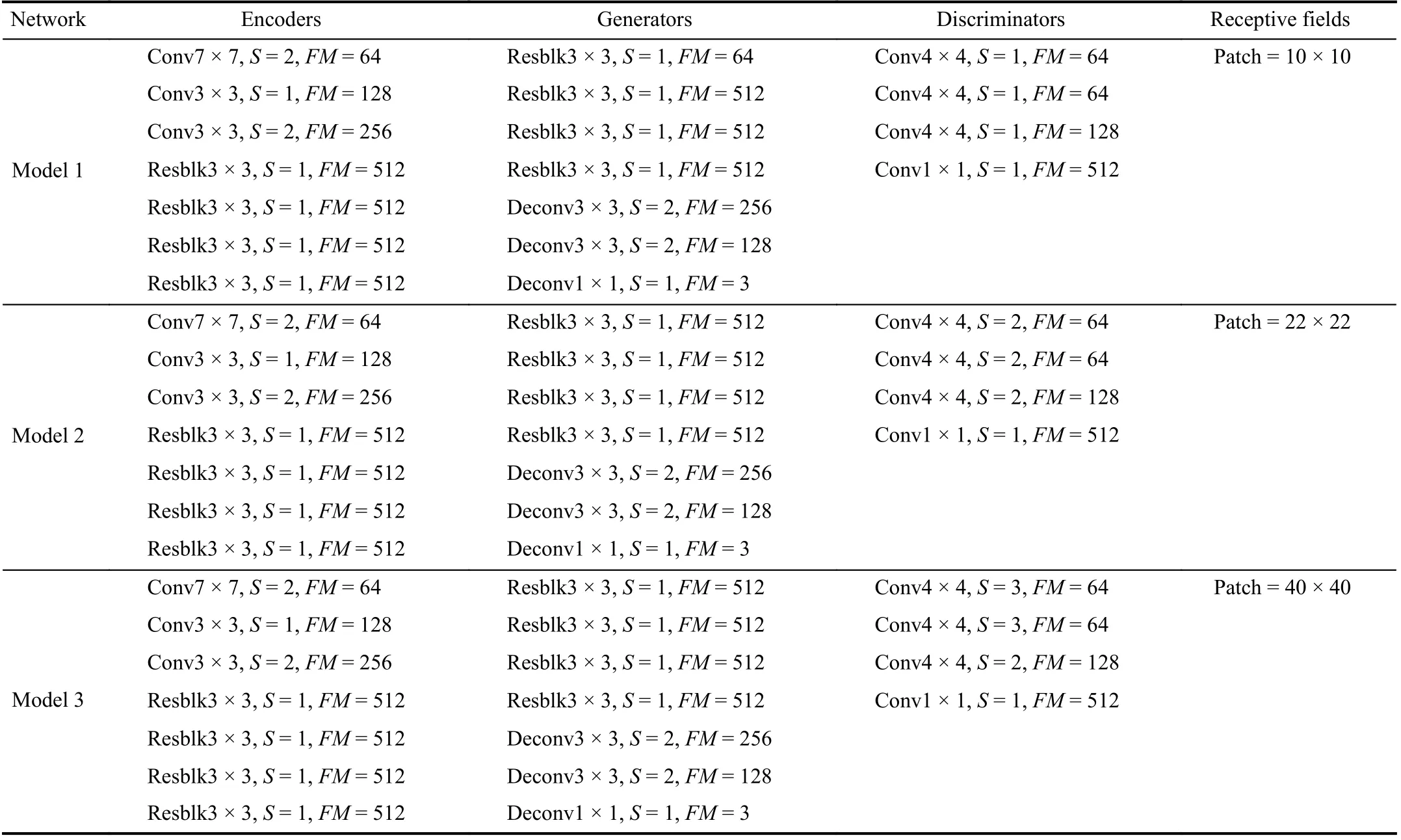
TABLE I THE IMAGE-GENERATION NETWORKS CONFIGURATIONS. THE PARAMETERS S AND FM ARE DENOTED AS STRIDE AND FEATURE MAPS
3) Constructing High-Quality Synthetic Sequence:In this paper, the image translation network is used to generate highquality synthetic sequences. Section III-B (Table I) lists all the variants of networks (Model 1, Model 2, and Model 3), which are distinguished by the size of receptive fields (patch sizes 40 × 40, 22 × 22 and 10 × 10). To be specific, we used 792 real images from the CDnet2014 canoe category and 792 from simulated multi-challenge sequences (basic) to train above three models. In the experiment, the number of three test datasets is the same. Then, three different models are tested on 1189 simulated samples to generate synthetic images. Fig. 5 illustrates synthetic results for all variants of image translation models. The results show that a smaller patch (10 × 10)increases the flexibility, and a larger patch (40 × 40) preserve a better structure. However, Model 1 and Model 3 have problems with boat generation (e.g., transparency and unclear details). By contrast, the middle patch (22 × 22) provides a good balance between quality and flexibility. Therefore, we decide to use Model 2 as a reference to generate a high-quality synthetic sequence (from simulated images (Basic sequence)to synthetic images).
IV. EXPERIMENTAL RESULTS
In Section III, we design simulated scenes and image translation model to generate a series of simulated and synthetic images for UAV change detection. In this section,real, simulated and synthetic datasets are used to train or validate different CD models. The rest of this section is organized as follows. First and foremost, we introduce a basic setup including datasets and measure criteria used in the experiment. Then, different simulated multi-challenge sequences are used to quantitatively analyze the impact on models performance. Furthermore, supervised CD models are trained and validated on simulated and synthetic datasets. Last but not least, we briefly summarize experimental results. The purpose of experiment is to verify the impact of different conditions on vision algorithms, and it also illustrates the importance of image generation on CD.
A. Experimental Setup
1) Datasets:To verify the utility of our simulated and synthetic dataset for CD, we select publicly available CDnet2014 datasets (Dynamic Background category, canoe sequence) as the real dataset benchmark. In order to quantitatively analyze CD models, we construct simulated multi-challenge sequences containing six challenges, including Basic, Dynamic background, Illumination variations, Bad weather, Noise, and More moving objects. In addition, we use an image translation model (Model 2) to generate synthetic sequences, which achieves a good balance between quality and structure. Therefore, the corresponding synthetic images are mainly used for the CD task based on DCNN. Examples of datasets used in experiments are shown in Fig. 6.

Fig. 5. Effect of different patch sizes for sim-to-real translations. Column 1: the input synthetic image. Column 2: the output of Model 1 (with patch sizes of 10 × 10). Column 3: the output of Model 2 (with patch sizes of 22 × 22). Column 4: the output of Model 3 (with patch sizes of 40 × 40).

Fig. 6. Examples of datasets used in experiments. Top: simulated image (left), real image (middle), and synthetic image (right); Bottom: simulated annotation(left), real annotation (middle), and synthetic annotation (right).
2) Change Detection Models and Measure Criteria:In this work, four widely used (unsupervised) CD models, including FrameDifference [17], ViBe [22], LOBSTER [25] and SuBSENSE [26], are conducted to verify the effectiveness of simulated sequences. In addition, we also investigate effects of synthetic images on supervised CD models (FgSegNet-v2[28] and MU-Net1 [43]). Before the experiment, we introduce three metrics for model evaluation.

B. Experiments for Change Detection Model Tested on Real,Simulated and Synthetic Datasets
According to computer graphics and generative adversarial networks, prior works have shown promising results in generating simulated and synthetic images. In this section, we use real, simulated and synthetic datasets to conduct relevant experiments. To be specific, four classical CD models (unsupervised) are used to verify the reliability and validity of simulated and synthetic datasets. These models are tested on real, synthetic and simulated datasets (Basic sequence),respectively. Table II lists the experimental results of CD.Compared with a real dataset (mean), the simulated results are similar in F-measure and Recall. However, there are great differences in the Precision metric, because simulated data has more background disturbance (water wave, shadow and moving tree branches). These challenges are irregular and camouflaged, resulting in poor performance of models. In addition, the synthetic results have the same F-measure as the simulated results, which benefits from the structural similarities between the two datasets. Since the objects in synthetic data are partially camouflaged and have an increased the gain level, the Precision metric is lower than other two datasets. Examples of results on real, simulated, and synthetic images using the LOBSTER and SuBSENSE models are illustrated in Fig. 7.
C. Experiments for Change Detection Model Tested on Simulated Multi-Challenge Sequences
The above experiments provide sufficient evidence that simulated data can be substituted for real data when evaluating CD models. In addition, the imaging diversity of simulated scenarios allows us to quantitatively analyze the performance of detectors under different challenges. There-
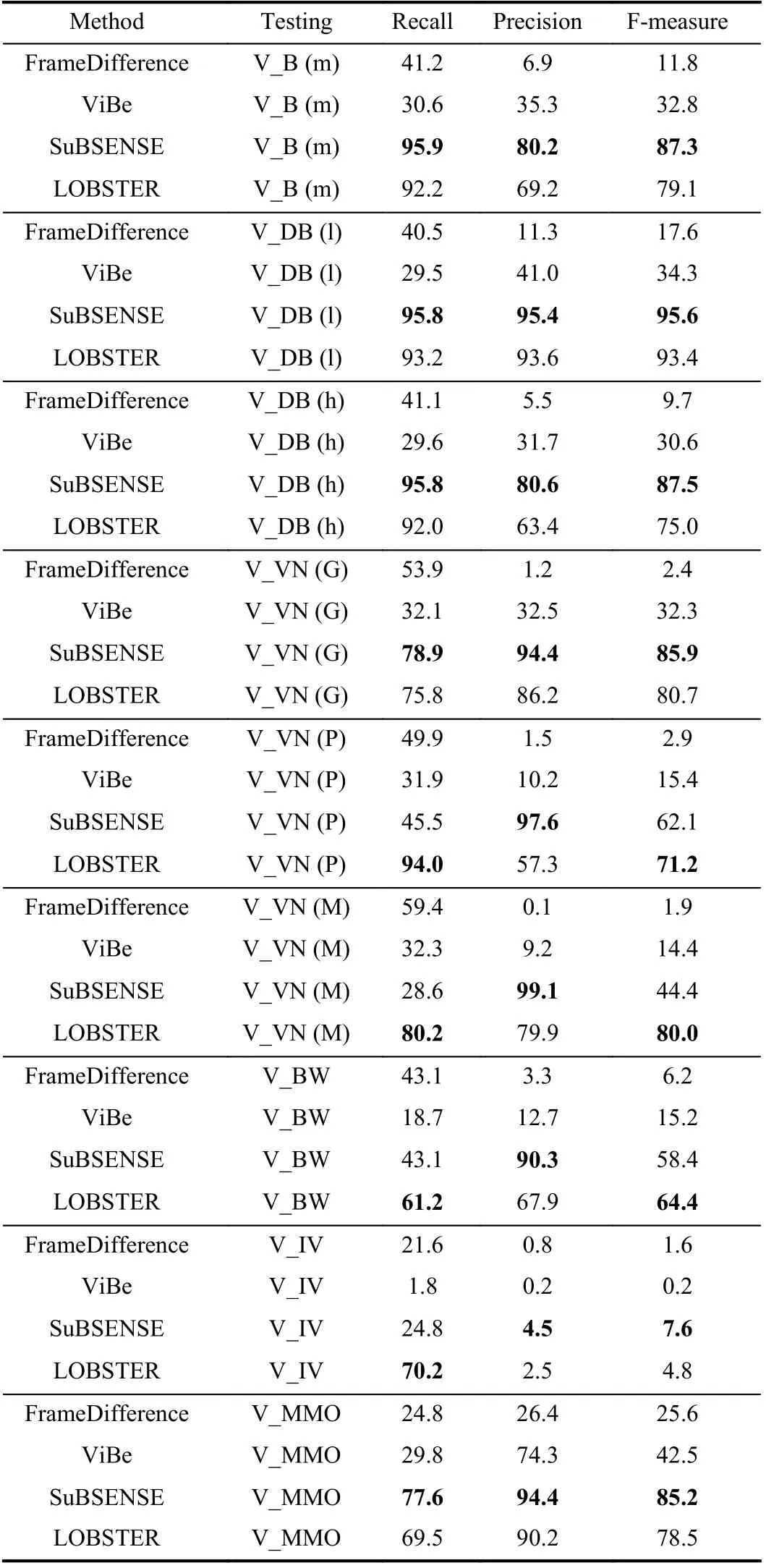
fore, we use the simulated multi-challenge sequences to test different CD models comprehensively. The simulated multichallenge sequences include: Basic, Dynamic background,Noise, Bad weather, Illumination variations, and More moving objects. It is worth noting that each specific sequence is also affected by other challenges, but one challenge is dominant. Quantitative results of different unsupervised CD models are shown in Table III. Besides, we visualize the experimental results on simulated multi-challenge sequences in Fig. 8. Next, we analyze the experimental results of each sequence in detail.
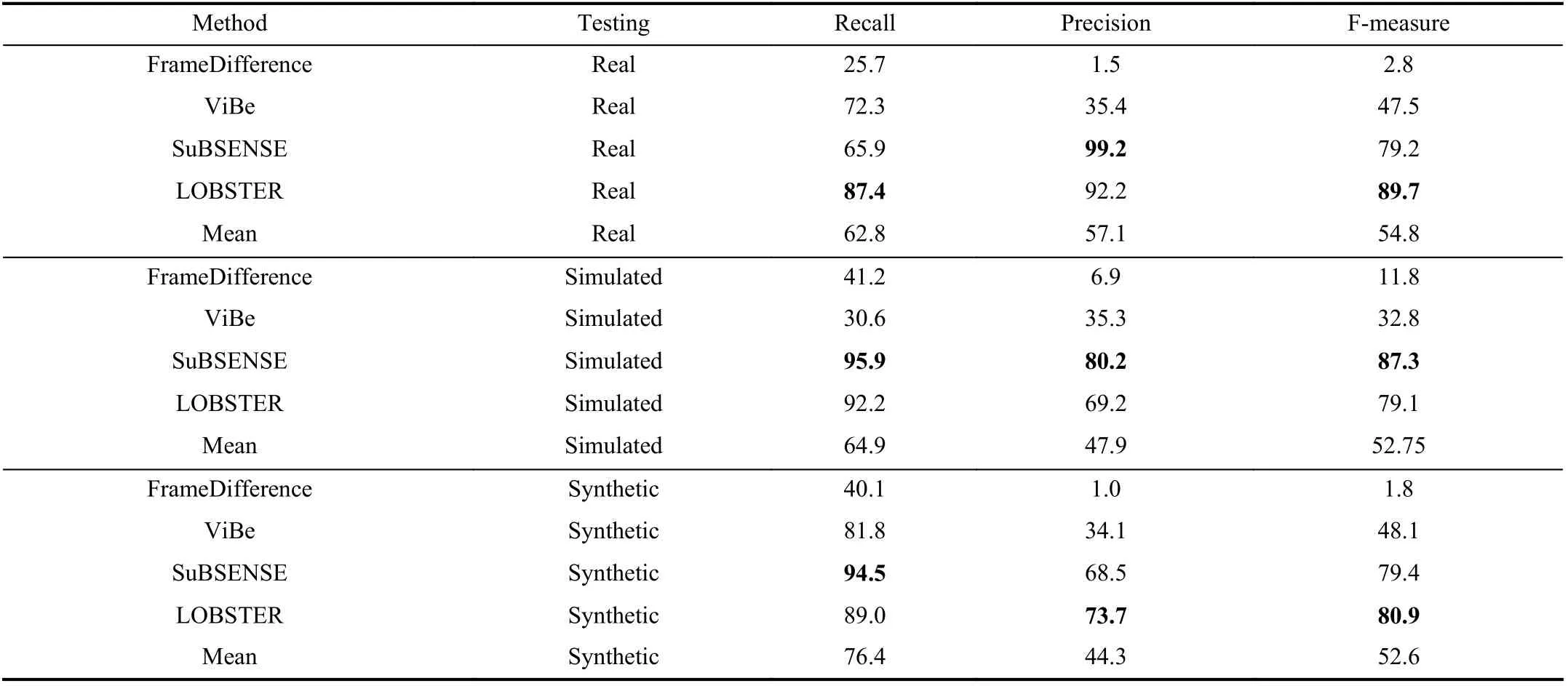
TABLE II THE EXPERIMENTAL RESULTS ON REAL, SIMULATED, AND SYNTHETIC DATASETS FOR CHANGE DETECTION(NOTATION: THE BOLD NUMBERS REPRESENT THE MAXIMUM METRIC IN DIFFERENT MODELS) (%)

Fig. 7. Examples of results on real, simulated and synthetic images using the LOBSTER and SuBSENSE models. Row 1: real input image (left), simulated input image (middle), and synthetic input image (right); Row 2: real annotation (left), simulated annotation (middle), and synthetic annotation; Row 3: results by the LOBSTER model; Row 4: results by the SuBSENSE model.
1) Video Basic (V_B)):The basic sequence provides a first impression of evaluating CD performance in a typical inlandwater scenario. It is difficult for the FrameDifference and ViBe to obtain satisfactory evaluation metrics in the basic sequence. Also remarkable is that LOBSTER has difficulty maintaining the tradeoff between Recall and Precision metrics, resulting in a low F-measure value. The SuBSENSE model keeps all metrics at a high level simultaneously in a basic sequence.
2) Video Dynamic Background (V_DB):The varying wave and moving tree branches determine the difficulty of the dynamic background sequence. In this section, we mainly adjust the wave height (low (l), medium (m), and high (h)) for experiment. As shown in Table III, the taller the wave height,the more adverse detection factors for each model, leading to a declining trend of performance metrics.
3) Video Noise (V_VN):Transmission and image compression can add noise to real images. In this comparative experiment, we introduce three kinds of noise for simulated images, including Gaussian noise (G), pepper and salt noise(P), and mixed noise (M). Compared with basic sequence results, most detection models do not provide suitable antinoise mechanisms. The SuBSENSE model is severely disturbed with the challenge of mixed noise. In contrast, the LOBSTER model exhibits good performance because the local binary pattern improves detection performance and stability.
4) Video Bad Weather (V_BW):This challenge is a basic sequence in rainy condition and low-visibility conditions.Without much surprise, the results of this experiment show quite low performance for all evaluated approaches. The results also show that LOBSTER has better adaptability in rainy conditions, while SuBSENSE performs better in the basic sequence (sunny). This is due to the former uses an adaptive approach that accurately captures foreground objects in bad weather.
5) Video Illumination Variations (V_IV):None of the testing methods can satisfactorily handle the challenge of illumination variations. There are two reasons for this phenomenon. On the one hand, the contrast between background and foreground objects is reduced; On the other hand, the foreground objects are easy to camouflage at night. Therefore,all detection models failed in this experiment.
6) Video More Moving Objects (V_MMO):The real scene consists of only one red canoe. It is well known that sample
Method Testing Recall Precision F-measure FrameDifference V_B (m) 41.2 6.9 11.8 ViBe V_B (m) 30.6 35.3 32.8 SuBSENSE V_B (m) 95.9 80.2 87.3 LOBSTER V_B (m) 92.2 69.2 79.1 FrameDifference V_DB (l) 40.5 11.3 17.6 ViBe V_DB (l) 29.5 41.0 34.3 SuBSENSE V_DB (l) 95.8 95.4 95.6 LOBSTER V_DB (l) 93.2 93.6 93.4 FrameDifference V_DB (h) 41.1 5.5 9.7 ViBe V_DB (h) 29.6 31.7 30.6 SuBSENSE V_DB (h) 95.8 80.6 87.5 LOBSTER V_DB (h) 92.0 63.4 75.0 FrameDifference V_VN (G) 53.9 1.2 2.4 ViBe V_VN (G) 32.1 32.5 32.3 SuBSENSE V_VN (G) 78.9 94.4 85.9 LOBSTER V_VN (G) 75.8 86.2 80.7 FrameDifference V_VN (P) 49.9 1.5 2.9 ViBe V_VN (P) 31.9 10.2 15.4 SuBSENSE V_VN (P) 45.5 97.6 62.1 LOBSTER V_VN (P) 94.0 57.3 71.2 FrameDifference V_VN (M) 59.4 0.1 1.9 ViBe V_VN (M) 32.3 9.2 14.4 SuBSENSE V_VN (M) 28.6 99.1 44.4 LOBSTER V_VN (M) 80.2 79.9 80.0 FrameDifference V_BW 43.1 3.3 6.2 ViBe V_BW 18.7 12.7 15.2 SuBSENSE V_BW 43.1 90.3 58.4 LOBSTER V_BW 61.2 67.9 64.4 FrameDifference V_IV 21.6 0.8 1.6 ViBe V_IV 1.8 0.2 0.2 SuBSENSE V_IV 24.8 4.5 7.6 LOBSTER V_IV 70.2 2.5 4.8 FrameDifference V_MMO 24.8 26.4 25.6 ViBe V_MMO 29.8 74.3 42.5 SuBSENSE V_MMO 77.6 94.4 85.2 LOBSTER V_MMO 69.5 90.2 78.5
TABLE III THE QUANTITATIVE RESULTS OF DIFFERENT UNSUPERVISED CHANGE DETECTION MODELS ON THE SIMULATED MULTICHALLENGE SEQUENCES (NOTATION: THE BOLD NUMBERS REPRESENT THE MAXIMUM METRIC IN THE SAME CHALLENGE SEQUENCE) (%)diversity is a key factor in model testing. Therefore, we take advantage of the simulated scenario by adding various foreground models to basic sequence. As shown in Table III,the metrics of simple models (FrameDifference and ViBe) are improved, while more advanced models’ (SuBSENSE and LOBSTER) performance are slightly disturbed. The results indicate that different detectors can be comprehensively investigated by the moving objects sequence.
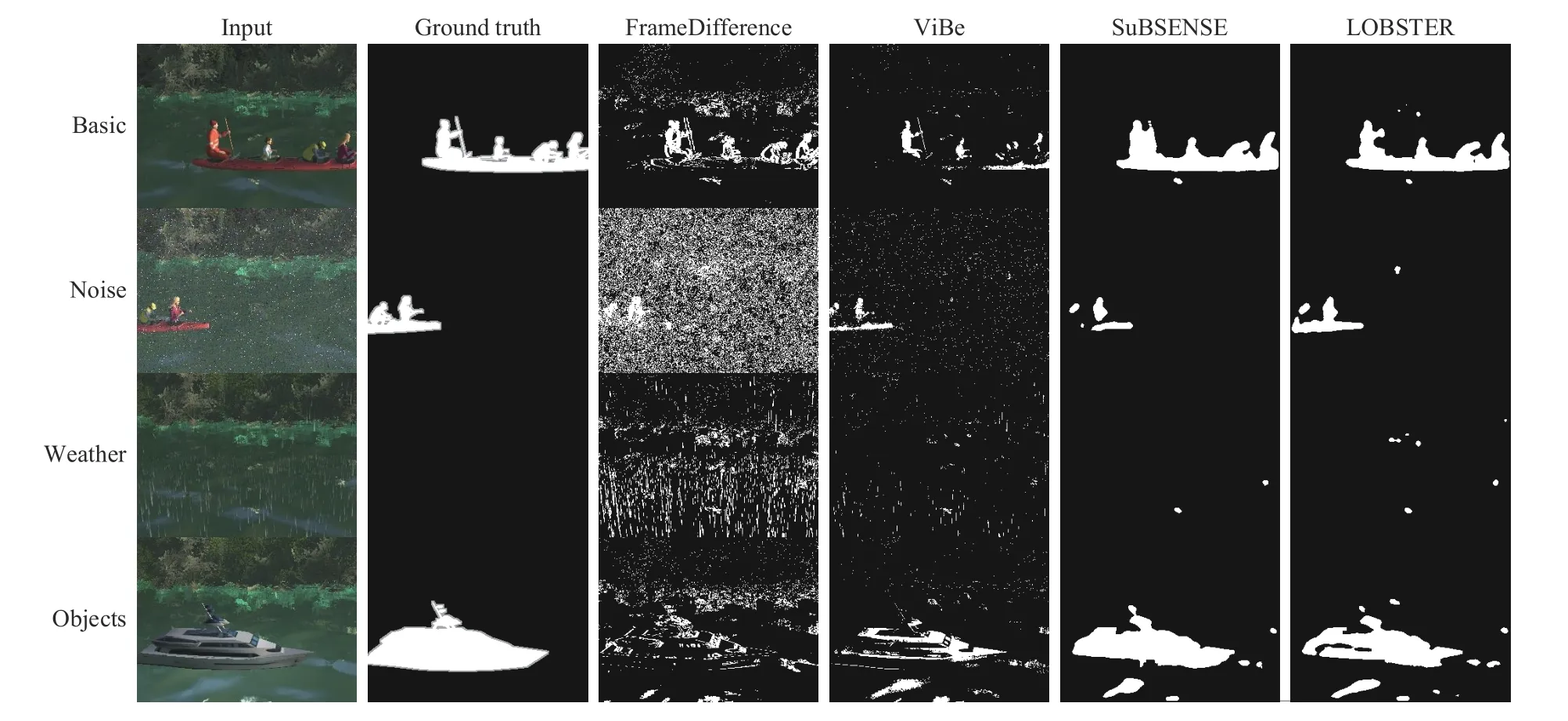
Fig. 8. Examples of change detection results on simulated multi-challenge sequences using different models. Column 1: input images; Column 2: ground truth; Column 3: change detection results by the FrameDifference model; Column 4: change detection results by the ViBe model; Column 5: change detection results by the SuBSENSE model; Column 6: change detection results by the LOBSTER model. Note that an unknown border is added around the foreground objects in the ground truth image, this protects evaluation metrics from being corrupted by motion blur. Best viewed with zooming.
D. Experiments for Change Detection Model Trained on Simulated and Synthetic Datasets
The above experiments use simulated data to test different unsupervised CD models. What is more, this paper proposes an image translation network to generate synthetic images.Next, we investigate the influence of training images in different domains on CD performance. For instance, 50 simulated or 50 synthetic images are randomly selected as benchmarks to train supervised CD models (FgSegNet-v2 [28]and MU-Net1 [43]). All models are tested on real CDnet2014 datasets (dynamic background category, canoe sequence,(1189 images)). The verification results of supervised CD models are illustrated in Table IV. It can be found that the models trained by synthetic images obtains better detection performance. For instance, the MU-Net1 model trained by synthetic images increased the F-measure metric by 48.5%.This demonstrates that our well-designed generative model can effectively reduce the gap between real and simulated images. Moreover, it also shows the practicability of synthetic data in CD research. However, the experimental results also suggest that the precision of the FgSegNet-v2 model trained by synthetic images is lower than simulated images. There are two reasons for this phenomenon. 1) The precision and recall are often in tension. That is, improving precision typically reduces recall and vice versa. 2) Due to domain shift issue,simulated images provide limited features (limited foreground objects are detected), so the trained model can not maintain recall while obtaining high precision metric.
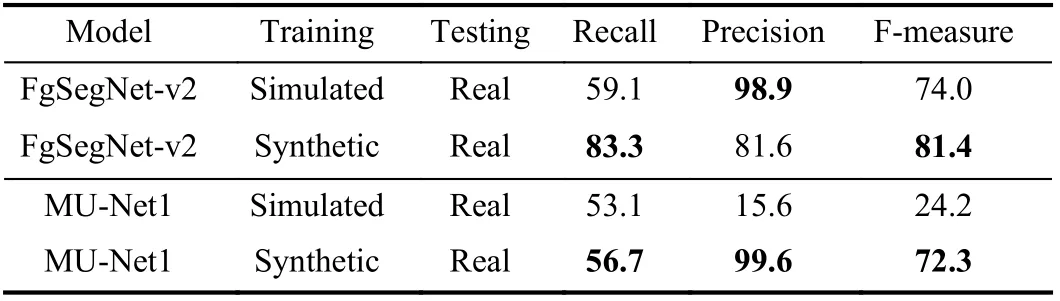
TABLE IV VERIFICATION RESULTS OF SUPERVISED CHANGE DETECTION MODELS TRAINED ON SIMULATED AND SYNTHETIC DATASETS (%)
E. Experiments for a Change Detection Model Trained on Real,Simulated and Synthetic Datasets
In fact, the influence of our proposed image generation approach in the real world is an important topic. Next, we investigate the effectiveness of different training images on CD model (MU-Net1) performance. We randomly select 50 real images from the canoe sequence as the training set and the rest of the 1139 images as testing set. In addition, we generate corresponding simulated images and synthetic images (based on 50 real images) as training sets. In this work, we utilize real, simulated and synthetic datasets to conduct experiments. The training datasets include “real images”, “real images + simulated images” and “real images +synthetic images”. It should be noted that the test results of real images are used as baseline. The experimental results are shown in Table V. The results illustrate that the models trained by real images + the newly generated images(simulated or synthetic) have better detection performance. In particular, the MU-Net1 model trained by “real+synthetic”images increased the F-measure metric by 6.5%. This demonstrates that our image generation approach can greatly improve the performance of CD detectors, which benefits from the small gap between the real and synthetic datasets.
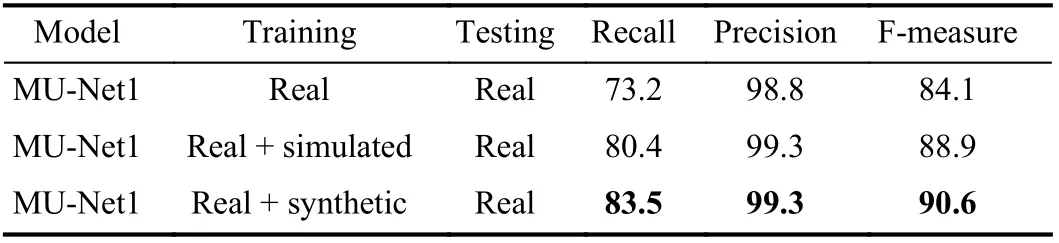
TABLE V PERFORMANCE OF MU-NET1 MODEL TRAINED ON REAL,SIMULATED AND SYNTHETIC DATASETS (%)
V. CONCLUSION
Based on the results detailed above, we use real, simulated and synthetic datasets to train and evaluate different CD models. Firstly, the four unsupervised CD models are tested on real and simulated datasets, respectively. Then, the simulated multi-challenge sequences are used to test different methods, which makes it possible to quantitatively analyze models under diversified imaging challenges. The experimental results show that the FrameDifference method can only detect edge information of moving objects. However, the Vibe and LOBSTER models can not speed up the absorption of ghost effects. By contrast, the SuBSENSE monitors both local model fidelity and segmentation noise. This feature allows it to quickly respond to intermittent dynamic object motion, so that it can be used in complex surveillance scenarios.However, there is dynamic interference and foreground object camouflage in the simulated data, which leads to a decrease in detection accuracy. For example, all evaluated approaches are affected by bad weather, resulting in reduced metrics. Finally,it can be found that the supervised models trained by synthetic images obtain better detection performance, which indicates the potential of image generation research.
This paper simulates a typical inland-water scenario and generates simulated multi-challenge sequences for testing the visual intelligence of UAVs. The simulated dataset contains six challenge sequences that effective and quantitatively analyze different CD models. Furthermore, we propose an image translation network, which consists of encoders and generators with shared parameters and discriminators with adjustable receptive fields. This method can narrow the gap between real and simulated images and synthesize photorealistic images. The experimental results prove that training with synthetic images can improve the performance of(supervised) models. However, none of these models provides good metrics under illumination variations and bad weather.Therefore, more work [44], [45] should be done to solve this key problem.
 IEEE/CAA Journal of Automatica Sinica2022年6期
IEEE/CAA Journal of Automatica Sinica2022年6期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Exponential Continuous Non-Parametric Neural Identifier With Predefined Convergence Velocity
- Wearable Robots for Human Underwater Movement Ability Enhancement: A Survey
- A Scalable Adaptive Approach to Multi-Vehicle Formation Control with Obstacle Avoidance
- Fuzzy Set-Membership Filtering for Discrete-Time Nonlinear Systems
- Distributed Fault-Tolerant Consensus Tracking of Multi-Agent Systems Under Cyber-Attacks
- Adaptive Control With Guaranteed Transient Behavior and Zero Steady-State Error for Systems With Time-Varying Parameters