
基于深度学习的虚拟试衣技术现状及其发展趋势
2022-06-25 01:48:06魏雪霞徐增波
东华大学学报(自然科学版) 2022年3期
魏雪霞, 赵 娟, 徐增波
(上海工程技术大学 纺织服装学院, 上海 201620)
虚拟试衣是一种可以帮助用户实现无需脱衣便可换装并查看穿着效果的技术手段,顾客用最短的时间快速浏览不同款式的服装以及观察试穿效果,增强购物体验,减少网购服装与预想效果不一样的顾虑,降低退货率,同时也能够避免实体店试衣的繁琐。虚拟试衣最早是以网页2 D虚拟替身类型出现的,主要对模特和服装的照片用PS(photoshop)软件进行简单处理,对网络带宽和终端设备要求较低,一般仅能提供虚拟替身正面与背面两组视角的试穿效果,精准度低且真实感较差。针对2 D虚拟试衣的种种不足,3 D虚拟试衣逐渐成为研究的重点和热点。3 D虚拟试衣根据用户所测得的人体三维数据,通过计算机建立三维人体模型并构建相应的服装衣片模型,创造一个虚拟的3 D试衣环境,在不接触服装实物的情况下,顾客根据自己的喜好方便快捷地更换服装,得到相应的着装立体效果模拟图[1],以便全方位地浏览试穿效果。国外关于3 D虚拟试衣的研究比较成熟,典型的有美国的Fitiquette、法国力克公司的E-Design系统、英国的Fits.me和Metail以及加拿大的My Virtual Model试衣网站。国内关于3 D虚拟试衣的研究还在探索阶段,2011年,我国出现了首个商业化的三维虚拟试衣系统——杭州森动数码科技发布的“3 D互动虚拟试衣间”,此后又出现了如上海试衣间信息科技有限公司研发的“好搭盒子”、上海魔购百货公司研发的“魔购百货”、北京优时尚科技有限责任公司推出的购搭APP等虚拟试衣软件,主要用于线上服装销售的虚拟体验,试衣网站有face72、41go、okbig、和炫三维试衣等。虽然3 D虚拟试衣的研究已成为一个热门话题,但是因其涉及三维人体建模技术、三维服装建模技术、虚拟试穿技术等,需要专业性极强的相关人员,并且部分设备的投入资金较大,对于普通用户和日常使用都是不现实的。
深度学习是机器学习算法研究中的一个新技术,主要是建立、模拟人脑进行分析学习的神经网络,成为各行业的研究热点,服装领域也不例外。利用深度学习生成模型解决虚拟试衣问题,主要是将虚拟试衣转化为条件图像生成问题,通过输入用户提供的个人照片以及想要知道穿着效果的服装模型图,运行神经网络进行训练,从而生成该用户穿着这款服装的效果图。Ronneberger[2]提出U-Net,主要采用全卷积神经网络对图像进行逐像素分类,在图像分割领域达到不错的效果。Lin等[3]提出一种多路径增强网络,使用残差连接可以将下采样中缺失的信息有效地融合进来,从而产生高分辨率的预测图像。Jetchev等[4]在时尚换装中引入有条件的类比生成对抗网络(the conditional analogy generative adversarial networks, CAGAN)。Han等[5]引入基于映像的虚拟试衣网络(VITON),使用形状上下文匹配算法将布料扭曲在目标人物上,并使用U-Net生成器学习图像合成。Wang等[6]提出基于图像的特征保留虚拟试衣网络(characteristic-preserving virtual try-on network, CP-VTON),引进了用于集合匹配的卷积神经网络架构。Pandey[7]提出Poly-GAN(generative adversarial networks)对网络进行简化尝试,使用一个网络完成变形和融合等任务。这种基于深度学习的虚拟试衣方法不使用任何3 D信息,可实现比较好的试穿结果,同时经济性较好,但存在生成的图片容易出现纹理丢失、身体部位丢失等问题,影响试衣结果等。尽管如此,基于深度学习的虚拟试衣已经引起了广泛的关注且研究意义重大,随着深度学习的不断发展以及成本的合理化,其在虚拟试衣中的深入应用成为大势所趋。
1 相关理论基础
1.1 深度学习简介
深度学习是机器学习研究中的一个新领域,其学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字、图像和声音等数据的解释有很大的帮助。深度学习的最终目标实现机器能够像人一样具有分析学习能力,即能够识别文字、图像和声音等数据[8]。根据深度学习结构、技术和应用领域不同,将深度学习架构分为无监督或生成式学习的深度架构、有监督学习的深度架构和混合深度架构。无监督或生成式学习的深度架构用于在没有目标类标签信息的情况下捕捉观测到的或可见数据的高阶相关性,常见的代表网络有深度波尔兹曼机、受限波尔兹曼机和广义除噪自编码器。有监督学习的深度架构直接提供用于模式分类目的的判别能力,描述可见数据条件下的后验分布。混合深度架构目标是判别式模型,往往以无监督或生成式学习的深度架构的结果作为重要辅助,常见的实现方式是通过优化和正则类别中的深度网络,或者通过使用判别式准则对第一个类别所述的生成式或无监督深度架构的参数进行估计。
1.2 深度学习网络模型
1.2.1 卷积神经网络(convolutional neural networks,CNN)
CNN是一类具有深度结构的前馈神经网络[9],是目前深度学习技术领域中具有代表性的神经网络之一,是最早应用于实践的深度学习网络。CNN考虑输入信号是图像的特点,参考生物视觉神经的接收域概念,采用稀疏连接、权值共享、池化等概念,成功弥补全连接模型在图像处理领域的不足。CNN包含输入层、卷积层、激活层、池化层和全连接层等5种类型的层次结构。最早出现的CNN是时间延迟网络和LeNet-5[10],其中,LeNet-5阐述图像中像素特征之间的相关性能够由参数共享的卷积操作所提取,同时使用卷积、下采样(池化)和非线性映射的组合结构,是当前流行的大多数深度图像识别网络的基础。
1.2.2 循环神经网络(recurrent neural network, RNN)
RNN是应用自然语言处理、语音识别、图像标注等序列数据处理的基本网络框架,包括Vector-to-Sequence、Sequence-to-Vector和Encoder-to-Decoder等3种网络结构。传统的神经网络模型的层与层之间一般是“全连接”,每层之间神经元是“无连接”,但RNN中当前单元的输出与之前步骤的输出也有关,具体表现形式为当前单元会对之前步骤的信息进行存储并应用于当前输出的计算。常用训练RNN的方法是BPTT (back propagation through time)算法,BPTT的中心思想与BP (back propagation)算法一样,沿着需要优化参数的负梯度方向不断寻找更优的点直至收敛。RNN在处理时间序列上距离较远的点时,涉及雅可比矩阵的多次相乘,会造成梯度消失或膨胀现象,为了解决该问题,提出了门限RNN,有漏单元通过设计连接间的权重系数,从而允许RNN积累距离较远节点之间的长期联系,而门限RNN则泛化了这种思想,允许在不同时刻改变该系数,且允许网络忘记当前已经累计的信息。门限RNN中最著名的是长短期记忆网络(long-short term memory, LSTM),只要关闭输入门,新输入信号就不会覆盖原输入信号,打开输出门后可使原输入信号产生作用,这些机制解决了很多普通RNN不能解决的问题。
1.2.3 生成对抗网络(generative adversarial networks, GAN)
GAN是图像合成中最流行的深层生成模型之一,包含一个生成模型和一个判别模型。生成模型捕捉样本数据的分布,判别模型是一个二元分类器,判别输入样本是真实样本还是生成的假样本,生成模型要尽可能迷惑判别模型,判别模型要尽可能区分生成模型生成的样本和真实样本,两个模型不断博弈优化,最终判别模型无法判别生成模型所生成图像的真假。GAN在图像去噪、图像超分辨率、图像补全、风格迁移等任务中取得了很好的效果。
1.3 深度学习优化算法
梯度下降(gradient descent, GD)法是最常用的优化神经网络的方法,分为批量梯度下降、随机梯度下降和小批量梯度下降。批量梯度下降法的每次更新都需要在整个数据集上求出所有的偏导数,因此其速度比较慢;随机梯度下降法的每次更新是对数据集中的一个样本求出罚函数,然后对其求相应的偏导数,可避免在较大数据集上的计算冗余,运行速度大大加快。调整随机梯度下降优化算法的学习速率可以提升性能并减少训练时间,常用的随机梯度下降优化算法有动量法、Nesterov梯度加速法、Adagrad法、Adadelta法、RMSprop法、适应性动量估计法等。还有另外一些改进随机梯度下降的策略如样本重排法、递进学习、批量标准化及早停等,其中批量标准化用得比较多,在反向传播过程中,权重问题会导致梯度偏移,批量标准化将这些梯度从异常值调整为正常值,并在小批量范围内通过标准化使其向共同的目标收敛,加快梯度求解的速度,即提升模型的收敛速度。小批量梯度下降法集合上述两种方法的优势,在每次更新中对n个样本构成的一批数据计算罚函数(n通常为50~256),并对相应的参数进行求导。
2 深度学习关键技术
2.1 姿态估计和人体解析
人体姿态估计可确定重要身体关节的精确位置,而人体解析(又称语义部分分割)的目的是将人体图像分割为多个具有细粒度语义的部分(如身体部位和衣服),并为图像内容提供更详细的解释说明。姿态估计和人体解析是人体图像分析的两个关键和相关的任务。关节式人体姿态通常使用一个单术语和图形结构或图形模型的组合建模,例如混合身体部位。随着DensePose[11]的引入,姿态估计问题被定义为使用标准卷积架构的回归问题,人体姿态估计的研究开始从经典方法转向深度网络。例如,Wei等[12]在CNN中引入身体部位间的空间相关性推理。Newell等[13]提出一个堆叠沙漏网络,通过重复池化向下和向上采样过程来学习空间分布。Cao等[14]提出一种基于关键点的人体姿态估计部分亲和场,计算出的人体姿势用18个关键点的坐标表示,为了利用它们的空间布局,每个关键点被进一步转换为一个热图,在关键点周围有一个11→11的邻域,在其他地方填充1和0,所有关键点的热图进一步叠加成18通道姿态的热图,该姿势识别流程已经成功应用在VITON和CP-VTON工作中。对于人体解析,以往的研究大多采用低水平的过分割、姿态估计和自底向上的假设,生成用于人体解析的构建模块。关于人体解析方法,大多利用CNN和递归神经网络提高特征表达能力,为了获取丰富的结构信息,将CNN和图模型(如条件随机场)结合起来。Chen等[15]将对象分割扩展到对象零件级分割,并发布了PASCAL PART数据集,其中包括人体的像素级零件注释。但上述这些方法很难直接利用基于关节点的姿势估计模型在像素预测中包含复杂的结构约束,为了使生成的解析结果在语义上与人的姿态一致,Liang等[16]收集一个新的数据集(look into person,LIP)进行人体分析和服装分割,提出一个无缝集成人工解析和姿态估计的统一框架(JPPNet)来探索高效的上下文建模,可以同时预测解析和姿态,并具有极高的质量,该框架网络使用一个共享残差网络来提取人体图像特征,后面接两个不同的网络来得到解析结果与姿态结果,在这两个结果后面分别接细化网络,从而进一步细化出更精确的结果。
2.2 服装变形
现有研究主要基于薄片样条(thin plate spline, TPS)变换实现一种可学习的图像匹配模型,并采用CNN实现对衣物形变的预测。TPS可以对表面进行柔性变形,简单而言,它要解决的问题就是如何把一张图片变形到另外一张图片上并使得相互对应的关键点重合。随着深度学习理论的提出,越来越多的CNN模型被提出。Rocco等[17]提出了用于几何匹配的CNN架构,用于估计两个输入图像之间几何变换的参数。首先,该框架用强大的可训练的CNN特征代替标准的局部特征,可以处理匹配图像之间的外观大变化;其次,开发了可训练的匹配和变换估计层,以稳健的方式处理有噪声和不正确的匹配。在CP-VTON工作中,通过定制的CNN提出一种新的可学习的TPS变换,引入几何匹配模块(geometric matching module, GMM),这是一个直接使用像素级损耗(L1)训练的端到端神经网络,能够很好地处理大型形状和姿态转换。GMM主要包括4个部分:两个分别用于提取人体表征和目标服装的高级特征网络;将两个高级特征组合为单个张量的相关层,作为回归网络的输入;用于预测空间变换参数(θ)的回归网络;模拟TPS变换进行服装变形。Dong等[18]受CP-VTON启发提出多姿态虚拟试衣网络(multi-pose guided virtual try-on network,MG-VTON),采用CNN学习变换参数,包括特征提取层、特征匹配层和变换参数估计层。
2.3 图像合成
图像合成一般采用GAN网络模型,受原始 GAN的启发,越来越多改进版GAN被提出并且在图像生成、图像修复、超分辨率成像等方面取得了令人瞩目的成果。Isola等[19]引用一个条件GAN框架来研究图像到图像的转换问题,将给定的输入图像转换为另一个具有不同表示的图像。Mirza等[20]提出CGAN(conditional generative adversarial nets),通过在生成器和判别器中加入条件来实现按条件生成数据。Zhu等[21]提出的CycleGAN使用两个生成器和两个判别器,并加入了循环一致性损失函数,可用于图像到图像的转换。Siarohin等[22]提出可变形的GAN,在生成对抗网络的生成器中引入可变形跳跃连接,尝试解决试衣时不同姿势之间的未对准问题。在MG-VTON中,引入一种深度扭曲生成对抗网络(Warp-GAN),将期望的服装外观扭曲到合成的人体解析图中,使用扭曲特征策略学习生成真实图像,该网络由生成器(Gwarp)和判别器(Dwarp)组成。在Warp-GAN中,预训练模型时使用感知损失来度量高级特征之间的距离,鼓励生成器合成高质量和真实感的图像。感知损失定义如式(1)所示。由于来自不同层判别器的不同尺度的特征映射增强了图像合成性能,因此应引入特征损失,如式(2)所示。此外,采用对抗性损失和损耗来提高性能,鼓励Gwarp从不同方面合成真实和自然的图像,如式(3)所示。
(1)
式中:Lperceptual为感知损失;I为地面真值图像;为生成图像;φi(I)为地面真值图像I在预训练网络Φ的第i(i=0,1,2,3,4)层特征映射;φi()为生成图像在预训练网络Φ的第i(i=0,1,2,3,4)层特征映射;αi为第i层的损失权重。
(2)
式中:Lfeature为特征损失;Fi(I)为地面真值图像I在训练后的Dwarp中第i(i=0,1,2)层特征映射;Fi()为生成图像在训练后的Dwarp中第i(i=0,1,2)层特征映射;γi为第i层L1损失的权重。
LGwarp=λ1Ladv+λ2Lperceptual+λ3Lfeature+λ4L1
(3)
式中:LGwarp为生成器损失;λi(i=1,2,3,4)为第i层相应损失的权重;Ladv为对抗性损失;L1为机器学习中常用的损失函数之一,用于最小化误差,该误差是真实值和预测值之间的所有绝对差之和。
3 深度学习技术应用
3.1 换装
3.1.1 根据输入服装图像改变原图模特着装

图1 VITON虚拟试衣结果[5]Fig.1 Virtual try-on results of VITON[5]
CP-VTON在VITON基础上进行改进,采用GMM和Try-On两个模块,能够将服装转换为适合目标人物的形状,并保留服装的纹理、标志、刺绣等细节。在GMM网络中,先对输入的标准待穿衣服图片(c)和人体特征信息(p)进行卷积以提取高维特征,然后通过一个相关层继续卷积输出一套变换参数(θ),使用这套参数对衣服图片(c)进行TPS变换,整个流程是端到端可学习的。在Try-On模块中用类U-Net网络,输入人体特征(p)和变形后的衣服图片(ĉ),输出一个组合掩码(M)和初步图片(Ir),然后使用掩码(M)对ĉ和Ir进行融合生成最终的试衣结果(Io)。试验证明,相比VITON,CP-VTON在服装细节保留方面做得更好,两者虚拟试衣效果对比如图2所示。

图2 VITON与CP-VTON虚拟试衣结果对比[6]Fig.2 Comparison of virtual try-on results of VITON and CP-VTON[6]
3.1.2 多姿态引导虚拟试穿网络
MG-VTON可以在输入图像中拟合所需的服装并对人体姿态进行处理,从而生成新的人体图像,效果如图3所示。MG-VTON是一个具有生成性、对抗性学习的多阶段框架,构建过程分为3个阶段:首先,合成目标图像的期望人体解析图,以匹配期望姿态和期望服装形状;其次,采用深度变形生成对抗网络(Warp-GAN),将期望的服装外观变形为合成的人体解析图,解决了输入人体姿态与期望人体姿态之间的错位问题;最后,通过细化渲染网络恢复衣服的纹理细节并删除一些伪影。MG-VTON为多姿态引导虚拟试穿任务构建了一个新数据集,涵盖了具有更多姿势和衣服多样性的人物图像。

图3 MG-VTON虚拟试穿结果[18]Fig.3 Virtual try-on results of MG-VTON[18]
3.1.3 根据输入模特图像替换原图模特着装
Raj等[23]提出一个新的基于深度学习的虚拟试衣网络SwapNet,即基于图像的服装转移,给定用户图像和穿着目标衣服的模特图像,其任务是合成穿着目标衣服的用户新图像。Wu等[24]提出一种创新的混合学习框架M2E-TON(M2E-try on net),即无监督学习和自监督学习结合姿态条件GAN,可以自动将想要的模特服装传输到目标人物的图像上,试穿效果如图4所示。首先, M2E-TON提出了一种基于密集姿态的人体姿态对齐网络将模型图像转换为目标人体姿态,通过自我监督的训练方法,利用同一个人在两种不同姿态下的图像来监督姿态对齐网络;在此基础上,提出了一种基于纹理细化网络的图像融合算法;最后,采用一个拟合网络将期望的模型服装传递给目标人群,拟合网络是一个编解码器网络,包括3个卷积层作为编码器,6个残差块用于特征学习,2个反卷积层和1个卷积层作为解码器。此外,M2E-TON还涉及一种带有姿态条件GAN的非配对联合训练策略,以解决高成本配对训练数据的需求(目标人需要理想的模型服装)问题。

图4 M2E-TON虚拟试衣结果[24]Fig.4 Virtual try-on results of M2E-TON[24]
3.2 服饰搭配
基于深度学习,利用图像和文本技术做深层抽取和表示,用深层网络学习搭配关系,在实际应用中取得了良好的效果。
3.2.1 根据模特图像上已有服装自动生成搭配的缺失部件
深度生成模型的最新突破为计算机视觉中众多的时尚应用打开了一扇新大门。Han等[25]提出FiNet,这是一个由形状生成网络和外观生成网络组成的两阶段生成网络,每个生成网络包含一个生成器以及两个相互作用的编码器,在第一个编码器学习隐空间表征时,通过第二个编码器的隐变量对其进行约束,第二个编码器的输入来自缺失的服装单品,两个编码器共同学习,这种方式使得两个生成网络都可以学习不同服装之间的高层级搭配兼容性信息,可以应用于具有搭配兼容性要求的时尚设计辅助工作和新时尚单品推荐任务,效果如图5所示。具体而言,形状生成网络的目的是学习一个映射,在将形状编码器的输出作为条件的情况下,该映射能够把有缺失的外形信息以及人体信息映射到一个完整的外形信息图,然后把这个信息图输入到外观生成网络中,生成与现有服装视觉兼容的新服装。
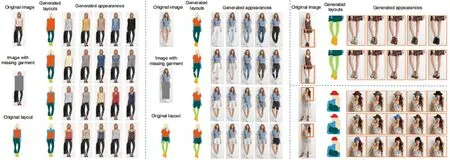
图5 FiNet效果图[25]Fig.5 Renderings of FiNet[25]
3.2.2 对模特图像上现有服装进行微调
Hsiao等[26]提出一种新颖的图像生成方法,称为Fashion ++,即通过最少的服装编辑建议对现有服装进行较小的更改,以提高其时尚性,更改可能需要卸下围巾、换上领口高的上衣或者把T恤塞进衬衫,如图6所示。Fashion ++模型由一个深度图像生成神经网络组成,该神经网络根据学习到的每件衣服的编码来学习合成衣服,潜在编码根据形状和纹理显式分解,从而分别允许对形状和颜色/图案/材料进行直接编辑。其主要思想是激活最大化方法,该方法基于梯度的优化图像高度激活神经网络中的目标神经,对来自深度图像生成网络的局部编码进行操作。
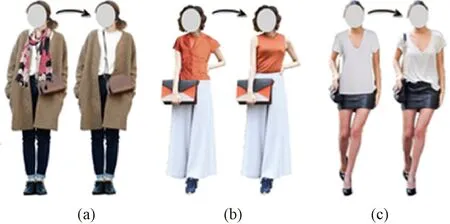
图6 Fashion ++的效果图[26]Fig.6 Renderings of Fashion ++[26]
3.2.3 时尚推荐
Li等[27]提出一个服装搭配评分系统,这是基于深度学习的多模态、多实例打分模型。该模型首先使用深度卷积网络的端到端视觉特征编码系统,可以将一件时尚服装作为输入,并预测用户的参与度水平;然后提出一个多模态深度学习框架,该框架利用图像、标题和类别中的上下文信息,为服装评分任务提供更可靠的解决方案。Han等[28]提出了通过一个端到端的框架来联合学习视觉语义嵌入和服饰物品之间的匹配性关系。首先采用Inception-V3 CNN模型作为特征提取器,将图像转换为特征向量;然后将服装项目视为一个具有特定顺序的序列,序列中的每个图像作为一个时间步长,搭配的每一件衣服就是一个时间点,在CNN模型的基础上利用一个具有512个隐藏单元的单层双向LSTM (Bi-LSTM)模型来预测集合中的下一个项目;最后训练一种视觉语义嵌入,在Bi-LSTM的训练过程中提供类别和属性信息,可以有效地学习服装的兼容性。Bracher等[29]提出Fashion DNA,这是一种时尚产品推荐算法,其将文章图像、标签和其他目录信息与客户响应结合起来,通过最大限度地减少深度神经网络的交叉熵损失,将精心策划的内容用于协同过滤,获取大量客户的销售记录,目的是通过向个别客户提供量身定制的建议来实现销售额最大化。由于顾客的兴趣和项目相关性会随着时间的推移而变化,Heinz等[30]提出基于RNN的个性化推荐模型,通过将LSTM元素引入Fashion DNA的网络来解决个性化推荐。
4 存在问题及发展趋势
目前基于深度学习的虚拟试衣技术研究已经取得很大进展,但仍存在以下问题:
(1)合成图像的分辨率(256像素×192像素)较低。首先,变形后的衣服和人体之间的错位区域会产生伪影,随着图像分辨率的增加,伪影变得明显;其次,现有方法中使用简单的U-Net不足以合成高分辨率图像中被遮挡的身体部位。
(2)现有基于深度学习的虚拟试衣技术大部分基于固定且简单的人体姿势,对多姿势的研究很少,但顾客往往希望从不同的角度或以不同的姿势看到自己的试衣效果。
(3)2 D非刚性变形算法的不足导致衣服的纹理容易过度变形。
(4)现有基于深度学习的虚拟试衣技术研究大多以干净的产品图像为基础,只有小部分研究以模特图像为基础,而且实现的虚拟试衣基本都是上装,用户无法自由选择要试穿哪一部分的衣服,这对面向真实场景应用的虚拟换装系统的实现带来极大的隐患与阻力。
针对上述虚拟试衣技术存在的问题,未来的研究可以分以下几个方面:
(1)基于深度学习的虚拟试衣系统可实现高分辨率(1 024像素×768像素)图像的合成,增加网络模块以删除未对齐区域中与衣服纹理无关的信息,同时使用衣服纹理填充未对齐区域,并通过特征级别的多尺度细化保留衣服的细节。改进算法并利用条件生成网络对变形后的服装图像进行组合,重新绘制被遮挡区域。
(2)基于深度学习的虚拟试衣系统可用于多姿势试穿场景,能够显示原始图像中看不到的颜色和纹理角度,用户能从不同的角度或以不同的姿势看到自己的试衣效果,并且服装上的标识、形状和文字等结构必须尽可能自然。
(3)将基于二维图像的高质量图像合成方法和基于三维模型的目标人体姿态变形方法结合起来,使用三维人体模型的二维到三维布料模型重建方法,无需三维服装模板,这样重建的服装模型能以自然的方式使衣服变形,并且保留良好的纹理细节。
(4)基于深度学习的虚拟试衣系统允许用户试穿任意模型图像中的衣服,而不局限于店内干净的服装产品图像,考虑加入交互式纹理控制机制,使用户可以自由选择想试穿的衣服(上衣、下装或整套)。
5 结 语
综合分析了基于深度学习的虚拟试衣技术的研究现状、关键技术、应用以及发展趋势,虽然目前对基于深度学习的虚拟试衣技术的研究还不够成熟,有待解决的技术难点仍然存在,需要在已有技术的基础上探索出更高效的新方法。但不可否认的是基于深度学习的虚拟试衣技术拥有广阔的市场前景,它将改变现有的试衣环境和传统的购物方式,成为服装实体店及网购中不可或缺的一部分。
猜你喜欢
趣味(作文与阅读)(2021年9期)2022-01-19 01:25:56
学生天地(2020年3期)2020-08-25 09:04:16
电子制作(2018年18期)2018-11-14 01:47:56
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
米娜·女性大世界(2016年9期)2016-12-02 19:05:42
股市动态分析(2015年20期)2015-09-10 20:40:44
中国连锁(2015年5期)2015-06-17 22:42:04
丝绸(2014年12期)2014-02-28 14:56:18
学苑创造·C版(2013年6期)2013-04-29 00:44:03
