
基于轻量化网络MobileNetV2的航班延误预测模型
2022-06-23 02:45屈景怡刘畅
信号处理 2022年5期
屈景怡 刘畅
(中国民航大学天津市智能信号与图像处理重点实验室,天津 300300)
1 引言
随着我国经济水平的不断提高以及空中交通业的快速发展,民航领域旅客吞吐量屡创新高。根据民航局发布的2019年民航机场生产统计报告,我国乘客年吞吐量超过13 亿人次,较上年增长6.9%[1],空中交通运输量激增凸显了很多问题,其中航班延误问题尤其受大众关注。航班延误受恶劣天气、机场调度、空域限制等多方因素综合影响,从2019年全球机场准点率报告来看,国内排名前五的各大机场同国外各大型机场相比,准点率低约10%,平均延误时长高约10 分钟[2],由此可见我国航班延误问题相对较严重。
严重的航班延误将导致航班延误的波及致使机场瘫痪,若可以对航班延误进行预测,机场相关工作者则可视具体情况及时优化航班,降低延误风险。为此,各国学者开展了一些研究,采用的方法多为传统的机器学习算法,如支持向量机、决策树、贝叶斯网络、随机森林等算法[3-7]进行航班延误的原因分析和预测。这些方法一般应用于样本量小、特征属性少的数据,但是伴随着大数据的海量积累,特别是融合气象数据的航班数据集已经逐渐呈现出样本量大、维度高的特点,上述方法在这类大数据集上的效果欠佳。深度学习算法是处理海量数据比较理想的算法,近年来研究学者们也逐渐将其应用于航班延误预测问题中,如全连接网络、卷积神经网络、循环神经网络等算法[8-10]均使得航班延误预测的准确率有了很大提升,但由于网络层数较深、算法结构复杂使模型参数量和计算量非常大,致使模型只能部署在PC 端,且传统深度学习算法一直伴有参数冗余的问题,那么找寻一种算法体积、结构适合于移动端的神经网络尤为重要。
研究学者们在深度学习方面的轻量化方向已经做了多角度的尝试,如知识蒸馏、模型剪枝等方法[11-12]是在算法结构外部做尝试,前者是先训练出一个Net-T 网络,然后利用此网络蒸馏得到一个更小的Net-S 网络,以达到精简模型的效果;后者则通过对训练后的模型进行通道剪枝等操作精简模型。轻量化卷积神经网络是深度学习算法一个新兴的分支,将轻量化操作用于算法结构本身,重新设计网络结构,具有参数量少、计算量小、准确率高等优点。这种网络不仅可以在PC 端使用还可以直接部署在移动端,占用移动设备内存小、功耗低,无需远端服务器的调用,避免了因网络拥堵而造成传输结果的时延。例如ShuffleNet[13]神经网络使用分组卷积和通道混洗操作来减轻网络的冗余同时增强特征选择能力,EfficientNet[14]神经网络使用多维度混合的模型缩放方法来平衡提升模型性能的三个维度:模型深度、模型宽度以及图片分辨率进而使模型达到最优。SqueezeNet[15]神经网络利用大小为1 × 1 的卷积核代替部分3 × 3 卷积核,同时减少各卷积核的通道数以此达到降低参数量的目的。
MobileNetV2 神经网络[16]是轻量化卷积神经网络中的表现较为优秀的网络,模型重新定义卷积方式并创新性的提出倒残差模块,在保障准确率的同时有效降低网络计算量和参数存储空间,且已经在人脸识别[17]、图像分类[18]等方面取得了优秀的成果。为了满足可以在移动端进行航班延误预测的需求,本文提出一种基于MobileNetV2 轻量化神经网络的航班延误预测模型,并且针对真实的海量结构化航班数据集对模型参数进行调整,使得算法在参数量和计算量上尽可能少,并保障航班延误预测准确率,为后续移动端的部署提供了基础。
2 基于轻量化网络MobileNetV2 航班延误预测模型
基于轻量化MobileNetV2 的航班延误预测模型总体框图如图1所示,其主要由三部分组成:(1)融合气象数据的航班数据集的数据预处理。(2)输入数据集的特征提取。(3)航班延误等级的分类预测。
2.1 数据预处理
本文使用的数据集为中国民用航空华东地区空中交通管理局(Civil Aviation Administration China,CAAC)提供的2018年3月至2019年3月的航班数据集和自动气象观测系统(Automated Weather Observa⁃tion System,AWOS)观测的气象数据集,以及中国民用航空华北空管局提供的2019 年9 月至2020 年10月的航班数据集和对应的气象数据集。
华东空管局提供的原始数据集具体属性如下:
(1)航班数据集包含的特征属性主要有:航班号(FlightNum)、飞机尾翼号(TailNum)、二次雷达编码(RadarCoding)、计划起飞时间(CRSDepTime)、计划到达时间(CRSArrTime)、巡航速度(CruSpeed)、巡航高度(CruAltitude)、航迹(EstimateRoute)等22个属性。
(2)气象数据集包含的特征属性主要有:背景亮度平均值(01_35R_BGB_1_AVG)、气象光学视程平均值(01_35R_MOR_1_AVG)、风速平均值(01_35R_WS_2_AVG)、修正海压(01_35R_CSP)、温度(01_35_TP)、相对湿度(01_35R_RD)、场压(01_34L_FP)、道面温度(01_35R_PRE)等42个属性。
华北空管局提供的原始数据集具体属性如下:
(1)航班数据集包含的特征属性主要有:预计到达时间(ETA)、预计起飞时间(ETD)计划到达时间(STA)、计划起飞时间(STD)、航班号(Flight⁃Num)、应答机(Transponder)、航空公司(Airlines)、任务性质(TaskType)等26个属性。
(2)气象数据集包含的特征属性主要有:露点温度(Dewpoint)、温度(Temp)、机场修正海压(QNH AERODROME)、场压(QFE)、相对湿度(RH)、能见度(VISIK)、10 分钟光学视程(MOR_10M)、6 小时降雨量(6H_RAIN)、1 分钟跑到视程(RVR_1M)等46个属性。
数据预处理过程的步骤如下所示:
(1)数据清洗:将数据集中的空值、缺失值较多的属性、异常值、重复属性做删除处理,缺失值较少的属性做填充中值处理。
(2)数据融合:将航班数据集F中的属性计起时间、计落时间作为航班连接主键key_I;将气象数据M中的记录时间作为连接主键key_II,然后将两个数据集使用关联主键进行融合成为数据集R。考虑航班延误并非只受当前时刻的气象影响,所以本文融合10分钟气象数据,这样的融合方式可以增加数据特征,起到数据增强的效果。
(3)数据编码:融合后的数据集包含数值型和类别型两种类型的属性,对数值型数据使用Min-Max[19]归一化编码,类别型数据分为高基型类别型数据和低基类别型数据,通常类别型数据使用One-Hot[19]独热编码,但是对高基类别数据使用此编码时易造成维度爆炸,使得编码后的数据集过于稀疏,不能进行下一步的算法特征提取工作。由于本文使用的数据集中含有大量的高基类别数据,如航班号、尾翼号、机场编号等,因此本文对于类别型数据采用CatBoost[20]编码。
下面对于CatBoost 编码进行详细说明。Cat⁃Boost 编码是一种有监督的编码方式,假设数据集R=(r1,1,r2,2,...,rN,M)是包含有M个特征属性,N条样本的数据集,标签值用Yi表示,其中i表示分类的个数。则编码的具体步骤为:
Step1随机打乱数据集R,得到打乱后的数据集为σ=(σ1,σ2,...,σN)。
Step2计算先验概率P,如公式(1)所示。
其中NumY表示标签值的个数,表示标签值为Y=Yi的个数,所以先验概率P可以表示为标签值类别出现的概率。
Step3编码第n条数据第m个特征值计算公式如(2)所示。
CatBoost 编码的思想最终可以表示为相同类别值的样本的平均标签值,∂>0 为权重系数,P表示step2 中得到的先验概率,∂和P的加入可以防止在编码过程中产生过拟合现象。数据编码后得到数据集X。
(4)矩阵化:经过编码后的数据集在输入模型前要经过矩阵化的过程,以符合算法输入规范性,转换过程如图2 所示,其中编码后的数据集表示为X=(x1,1,x2,2,...,xN,M),N表示数据集的样本量,M表示数据含有的属性个数。矩阵化可以将每条数据从向量的表现形式转换为矩阵的表现形式,以此来满足轻量化卷积神经网络的输入要求。
2.2 特征提取
传统的卷积神经网络为了追求更高的准确率,一般会将模型结构设计的相对复杂、网络层数也相对较深,这就将模型限制在了PC 端。MobileNetV2神经网络[16]重新设计卷积神经网络的结构,将传统卷积拆分为深度型和逐点型两种卷积,有效降低了模型的计算复杂度,同时引入倒残差结构来提取更多特征,提高算法模型的准确率,基于轻量化网络MobileNetV2 的航班延误预测模型的网络配置如下表1所示。
根据表1的MobileNetV2结构配置表,其中输出矩阵通道数NK∈[1,32,16,24,32,64,96,160,320,1280,1280,5],倒残差模块重复次数N∈[1,2,3,4,3,3,1],扩展因子t是应用于倒残差模块中的提升维度的参数,它的取值为t∈[1,6,6,6,6,6,6],通道因子α为MobileNetV2特有的超参数,通过调节其大小可以改变整个网络各个层的输出矩阵通道数,以此可以达到快速改变模型大小的目的。
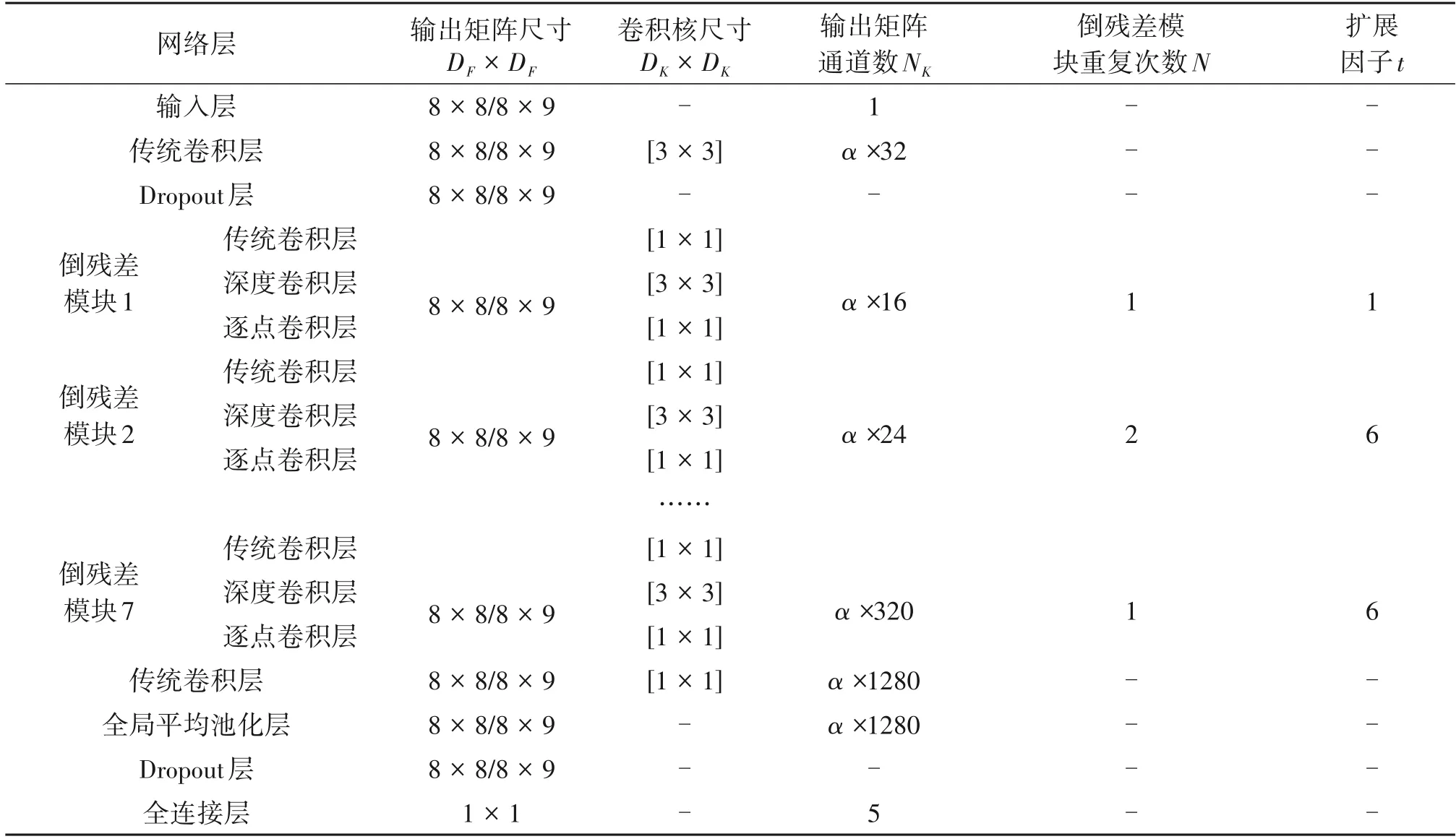
表1 MobileNetV2结构配置表Tab.1 The MobileNetV2 structure configuration table
2.2.1 深度可分离卷积
深度可分离卷积[16]是MobileNetV2 网络的核心部分,由深度卷积和逐点卷积组成,这样使得深度可分离卷积与传统卷积提取特征的方式产生了不同。传统卷积过程如图3 所示,假定卷积核K∈、输入特征矩阵,则要求卷积核通道数CK与输入特征矩阵通道数CF相等,经过一次传统卷积后的输出特征矩阵为,传统卷积可由公式(3)表示。其中K、L、C表示卷积核W的尺寸,“⊙”表示矩阵间的乘法。
假设输入特征矩阵尺寸为NF×DF×DF×CF,传统卷积核尺寸为NK×DK×DK×CK,深度可分离卷积中两种卷积核大小分别为CF×DK×DK× 1、NF× 1 × 1 ×CK,传统卷积的计算量F1和深度可分离卷积计算量F2分别为公式(7)、公式(8):
由此,可得深度可分离卷积相较于传统卷积减少的计算量计算公式(9),当卷积核的DK×DK×CK大小为3 × 3 ×CK时,深度可分离卷积的计算量会减少为原来的九分之一。
2.2.2 倒残差结构
倒残差结构是由ResNet[21]神经网络中的残差结构演变而来,不同于残差结构中先降维度后升维度的结构特点,倒残差结构采用先升维后降维的方式来构成模型的基本骨干网络,其可以形象地表示两边小、中间胖的沙漏形,结构如图5 所示,其由三部分组成:(1)扩展层使用1 × 1 卷积来提升输入特征矩阵的维度,以便保留更多的特征信息。(2)特征映射层使用3 × 3 卷积来提取输入矩阵的特征信息。(3)压缩层使用1 × 1 卷积,通过控制卷积核的个数来压缩输出特征矩阵的维度。后两层组成深度可分离卷积,整个结构不仅有效保留特征信息,还可以大幅度减少模型的参数量和计算量。
表2 给出了倒残差结构的计算步骤[16],深度可分离卷积内嵌在倒残差模块中,其中s代表卷积中的步长,扩展因子t在倒残差模块中起到改变输出矩阵维度的作用,多个倒残差串行构成了模型骨干网络。

表2 倒残差结构计算表Tab.2 Calculation table of inverted residuals
2.3 网络训练及分类预测
经过数据预处理后的数据集需要转换成张量的形式输入到模型中进行训练。表3给出了航班延误等级的划分,也是本文制作标签值的等级划分。模型最后采用全连接层以及Softmax 激活函数对航班进行延误等级分类,Softmax分类器将各个延误等级的概率表示出来,取概率值最大者作为一条数据的最终延误等级。由于本文最终输出的结果为航班延误等级,属于多分类模型,所以模型在训练期间采用交叉熵函数作为损失函数,如公式(10)所示。

表3 航班延误等级划分Tab.3 Classification of flight delays
其中H(y,)表示交叉熵函数,I表示分类模型中的分类个数,本文将航班延误等级分为5 类,所以I取值为5,表示网络预测值,y表示网络标签值,通过损失函数可以表征网络预测值与标签值y之间的相差程度,损失值越小,预测值与真实值越接近,准确率越高。
3 实验结果分析
本节首先介绍了实验使用的工作站硬件配置、软件平台以及实验的超参数配置。然后使用华东空管局提供的上海虹桥机场数据集和华北空管局提供的京津冀机场群数据集进行航班延误预测,从多角度验证了网络模型的有效性,最后对比了传统卷积神经网络的参数量、计算量以及准确率。
3.1 实验环境及参数配置
实验使用计算机配置为:处理器为英特尔至强Xeon E5-1620,CPU 频率为3.60 GHz;内 存16.00×4 GB;操作系统为Ubuntu16.04;图形加速器为GeForce GTX TITAN Xp;深度学习开发框架为Tensorflow 2.3.0。实验使用的上海虹桥机场数据集为301089 条,数据属性64 个,经过数据预处理后转换为8 × 8 的形式;京津冀机场群数据集为1650797 条,数据属性72 个,经过数据预处理后转换为8 × 9 的形式。训练集与验证集划分比例为9∶1。
航班延误预测神经网络模型超参数配置如下表4 所示,通道因子α为表1 处MobileNetV2 配置表中所提到的超参数。

表4 实验参数配置Tab.4 Experimental parameter
3.2 损失值和准确率
损失值和准确率是深度学习算法中的基本评估指标,可以反映算法模型的鲁棒性。损失值大小可以体现算法预测结果与真实结果的相差程度,损失值越小,预测准确度越高。准确率表示预测结果正确的样本量与总样本量的比值,公式为(11),在模型拟合度好时,验证集的准确率可以一定程度上反映模型的鲁棒性能,验证集准确率越高,模型鲁棒性越好。
基于上海虹桥机场和京津冀机场群数据集,表5给出了不同通道因子下MobileNetV2 的准确率和损失值大小,可知,随着通道因子α数值的增大,模型准确率逐渐增大,损失值逐渐降低,且在通道因子取值为0.75 和1 时,准确率和损失值变化较小,数值趋于稳定。

表5 不同通道因子的准确率对比Tab.5 Accuracy comparison of different width multiplier
图6、图7 分别给出了基于两个数据集的不同通道因子α下对应的损失值变化曲线图和准确率变化曲线图,从曲线的趋势来看,不同通道因子下损失值和准确率变化平缓下降,虹桥机场数据在训练轮次为300 时收敛,模型损失值和准确率变化趋于稳定,损失值最低为0.036 左右,准确率最高为99.07%;京津冀机场群数据在训练轮次为150 时收敛,模型损失值和准确率变化趋于稳定,损失值最低为0.184左右,准确率最高为96.03%。
3.3 算法复杂度
算法复杂度是轻量化卷积神经网络的重要评估指标,它可以体现算法在运行时对资源的消耗程度,算法复杂度越高模型占用设备内存越高。主要分为以下两个方面:(1)空间复杂度:算法结构越复杂,占用显存量越大,空间复杂度越高,一般用参数量Params 衡量。算法模型中单层卷积层和单层全连接层的参数量可近似表示为公式(12)、(13)。(2)时间复杂度:算法结构越复杂,模型训练和推理时间越长,时间复杂度越高,可用浮点运算次数FLOPs来衡量。算法模型中单层卷积层和单层全连接层的计算量可近似表示为公式(14)、(15)。
在公式(12)、(13)中PC、PQ分别表示单层卷积层的参数量和单层全连接层的参数量,DK表示当前层中的卷积核尺寸,CF表示当前层的输入特征通道数,NK表示当前层输出特征通道数,DF表示当前层的输入特征尺寸。其中公式(14)、(15)中FC、FQ分别表示单层卷积层的计算量和单层全连接层的计算量,1 表示全连接层输出特征尺寸,DF、CF、NK、DK与参数量计算公式中的含义相同。从上述公式中可以看出,模型参数量与输入数据属性个数无关,而模型计算量受输入数据属性个数影响。
因此,基于上海虹桥机场数据集,表6给出了不同通道因子α下模型的计算复杂度与预测准确率之间的关系,由表6 可知,随着通道因子的增大,模型的复杂度增加,准确率提升。但是在通道因子为0.75 和1.0 时,准确率没有因模型的复杂度增加有明显的提升,而且逐步趋于稳定,由此可以看出,两者不是简单的正相关关系,合适的模型复杂度可匹配得到较高的准确率,并且不同的移动端设备也可依据配置要求选择不同的模型。针对上海虹桥数据集,使用通道因子为0.75 时的MobileNetV2 算法网络可以得到相对较优的结果。

表6 不同通道因子的算法复杂度对比Tab.6 Comparison of the algorithm complexity of the different width multiplier
3.4 不同编码方法对准确率的影响
针对本文使用的复杂结构化数据,单一的编码方式已经不能满足需求,为验证本文使用的Min-Max 编码和CatBoost 编码的混合编码方式的有效性,本节基于上海虹桥机场数据集,利用Mobile⁃NetV2-0.75 模型,将Count 编码[22]、LabelEncoder 编码[23]、Catboost 编码进行对比,结果如表7 所示。这两种编码方式均可以处理类别型数据,Count 编码利用某一特征属性下各个取值的频次来代替对应的类别值,这样做的一个弊端是若某一特征下多个类别值频次相同,那么会有编码值相同的情况,不利于后续算法模型的有效特征提取。LabelEncoder编码的核心思想是将某一属性来的类别值转换成连续性的数值,这种编码方式使得原本没有顺序区别的类别值具有了大小属性,会对算法的特征提取工作带来影响。

表7 不同编码方法的准确率对比Tab.7 Accuracy comparison of different encoding methods
由表7 可知,三种编码方法中频次编码下的预测准确率最低为98.24%,本文使用的编码方法得到的准确率为99.07%,进而验证了本文使用的混合编码方式的有效性。
3.5 不同网络模型结果分析
在使用深度学习的方法处理基于海量的融合气象信息的航班数据集时,轻量化卷积神经网络Mo⁃bileNetV2相比与传统的卷积神经网络更具优势,为此,本文基于上海虹桥机场数据集和京津冀机场群数据集,将MobileNetV2-0.75 模型与传统的卷积神经网络ResNet、DenseNet[24]做对比,分别从参数量、计算量、准确率三个方面进行验证,结果如表8所示。

表8 不同模型的评价指标对比Tab.8 Evaluation index comparison of different models
从中可以看出,在虹桥机场数据集上,Mobile⁃NetV2-0.75 模型相较于另外两种模型,准确率分别提升了3.51%、4.13%,参数量分别降低了9.87Mil⁃lion、5.73Million,计算量分别降低了1388.82Mil⁃lion、457.78Million;在京津冀机场群数据集上,Mo⁃bileNetV2-0.75 模型相较于另外两种模型,准确率分别提升了1.70%、2.27%,参数量分别降低了9.87Million、5.73Million,计算量分别降低了1557.37Million、529.84Million。可以看出Mobile⁃NetV2-0.75 模型在上述三个方面的表现相对比较优秀,进一步验证了轻量化网络MobileNetV2 在航班延误预测上的有效性。
4 结论
本文在国内真实数据集的基础上,提出一种基于轻量化网络MobileNetV2 的航班延误预测模型,经过大量的实验分析验证了模型的有效性,得到的结论如下:
(1)在数据预处理部分,本文充分分析数据类型,使用Min-Max 编码和CatBoost 编码相结合的混合编码方式的混合编码方式对数据进行针对性编码,有利于后续算法的特征提取。
(2)相较于传统的卷积神经网络,本文提出的模型在航班延误预测中准确率、参数量、计算量等方面的表现都比较优秀,验证了本文轻量化网络在航班延误预测上应用的有效性。
综上,本文提出的基于轻量化网络Mobile⁃NetV2 的航班延误预测模型,可以实现对航班延误进行预测,并且轻量化的MobileNetV2 模型的计算效率更高、参数存储更少,有助于进一步将该模型部署在移动端。下一步的工作计划是在保障模型准确率的同时,进一步降低模型的参数量和计算量,并将其部署在移动端。
猜你喜欢
汽车实用技术(2022年11期)2022-06-20
小学生学习指导(中年级)(2021年12期)2021-12-30
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
