
超大型三维场景分布式渲染系统体系结构与技术研究
2022-06-21 04:19李昆昆于春雨卢石磊李文博
科技创新与应用 2022年17期
郭 阳,李昆昆,于春雨,卢石磊,李文博,刘 甜
(青岛理工大学 复杂网络与可视化研究所,山东 青岛 266520)
分布式渲染是将分布式计算和实时渲染结合,实现大体量模型的绘制与渲染,利用多GPU累积能力协同处理渲染任务,实现单PC机无法达到的快速绘制与渲染效果。实时渲染流程中最为关键的阶段是几何处理和光栅化。STEVEN和MICHAEL等[1]人针对三维模型实时绘制和渲染提出Sort分类策略,将分布式渲染分为了Sort-first、Sort-middle和Sort-last三种方式,Sort-first将图元数据在几何处理之前进行归属判断,Sort-middle将图元数据在几何处理和光栅化之间进行归属判断,Sort-last由于以无序状态通过了几何处理和光栅化,因此不再需要归属判断,直接在显示系统上进行图像合成。
分布式渲染的实现取决于多渲染节点的系统构建,系统体系结构的设计将直接影响渲染效率[2]。本文设计一种新的体系结构实现超大型三维场景的Sortfirst和Sort-last分布式渲染。
1 传统主从体系结构
传统的分布式渲染系统体系结构为主从(Master-Slave)结构,其结构模型较为简单,整个执行过程中任务量最大的绘制与渲染由从节点完成,并且根据任务量的需求大小或者用户要求决定从节点的数量,实现系统的扩展性。主从结构的劣势在于主节点职责过多,极易影响系统渲染效率;模型的计算渲染和图像合成为串行关系,在从节点计算渲染时,主节点处于空闲状态。
孙昭等[3]基于主从结构实现了一种按场景内容分布的渲染系统,Master节点负责系统的管理和用户的交互结果显示,Slave节点负责子场景的渲染,该方式提升了场景渲染的整体时间。彭敏峰[4]提出将多任务并行图形绘制系统节点分为三类:负责几何运算的应用节点、执行OpenGL指令的服务节点和负责与用户交互的控制节点,该结构实现了多节点的并行计算和绘制,绘制结果可以多个屏幕显示。汤敏[5]将分布式渲染的体系结构改进为Master-Slave-Collector,在主从结构中加入了Collector节点,通过添加任务池和结果池的方法实现系统的负载均衡。路石[6]在基于高性能并行可视化服务器上实现了多个系统内部节点,扩充了系统中的节点角色,使系统逻辑更加清晰,但容易造成多个节点之间数据的往复传输,从而增加由于网络传输所带来的时间消耗。
2 服务节点+主渲染节点+从渲染节点结构
2.1 系统节点角色
基于主从结构,为减少主节点的任务压力,并且在从节点渲染时,主节点不处于空闲状态,增加第三类系统角色,该角色承载主节点中的部分任务模块,减轻主节点任务量。系统角色为:服务节点、主渲染节点和从渲染节点。服务节点任务包含:系统环境部署、任务计算;主渲染节点任务包含:主渲染循环维护、用户交互和事件处理(根据渲染需求,判断系统是否进行图像合成);从渲染节点任务包含:被动渲染执行。
2.2 系统工作流程
本文设计的系统体系结构工作流程如下:渲染任务执行时由服务节点的环境资源部署开始,系统中的其他节点都会接收到来自服务节点的部署方案,此时实现所有节点角色的划分。服务节点开始部署渲染任务,首先根据渲染节点数量分配任务量到其他节点中,各渲染节点接受命令加载场景并开始渲染。渲染节点的工作大致相同,经过清除、绘制、交换等,最后进行显示。在此期间,主节点还会接收新的事件命令,并提交到服务节点,此时服务节点一并计算,进行新的任务划分,开始下一帧的渲染循环。
2.3 并行机制
在渲染中引入并行机制,在不改变单帧串行关系的情况下,使得多帧的渲染实现并行处理,以此实现多节点的分布式任务处理,减少单节点的渲染计算量,还可以实现流水线加速效果。
当采用并行机制执行任务时,假设全部在理想情况下,任务分配、渲染执行、数据传输和图像合成时间相等,忽略其他操作的时间,则理论上N帧的加速比可达到4N/(N+3)。在实际执行过程中,模型绘制与渲染和图像合成的时间会远远大于图像数据传输的时间,因此无法达到理想效果。并且当流水线内部包含的模块操作越多时,其渲染执行和图像合成的时间差越大,当从节点渲染第k帧时,此时的图像合成显示的是k-2帧,因此在负责图像合成的主渲染节点中需进行缓存处理。
2.4 子任务划分
在Sort-first渲染方式中,子任务根据屏幕2D图像的物理位置进行划分,因此子任务划分可通过基于视锥体的图元分割实现,通过视锥体计算可以得出裁剪掉外部图元[7],还可以得到投影到二维屏幕上的矩阵。
首先选择三维坐标系,采用OpenGL右手坐标系,X轴向前,Y轴向上,Z轴向右。以2个子视锥体为例,进行坐标和透视投影矩阵计算。视锥体切分如图1所示。
通过设置视锥体的fovy、Width、Height、zNear、zFar参数可以得出视锥体中的l、r、t、b、n和这几f个变量值,再推导出视锥体透视投影矩阵。得到透视投影矩阵之后,便可以根据用户自定义属性切分视锥体,得到若干个子视锥体和它们各自的透视投影矩阵。
在切分视锥体为2个子视锥体时,变换相应的变量便可获得子视锥体的投影矩阵,例如当r=0时,即可得到左二分之一子视锥体;当l=0时,可得到右二分之一的子视锥体,当得到二分之一子视锥体后,重复上面的过程,可得到三分之一或四分之一视锥体,当赋值为0时为均分。
在分配渲染任务时,需根据模型变换和新事件处理对子任务不断进行划分,需进行负载均衡处理,通过在视锥体内部建立包围盒的方式判断子视锥体内部顶点的数量是否趋于平衡,若某个子视锥体存在的顶点过多,则重新分配,使子视锥体内部的顶点数量尽量保持一致,使渲染节点的任务量基本一致,渲染时间保持平衡。
3 实验测试
实验采用5台PC机组成分布式渲染系统,其中服务节点和主渲染节点各1台,从渲染节点3台,因此可进行四分模型的渲染划分。
3.1 模型用例
本文选取500米口径球面射电望远镜(FAST)模型作为测试用例,课题组已完成FAST模型的建模工作[8-11],如图2所示。
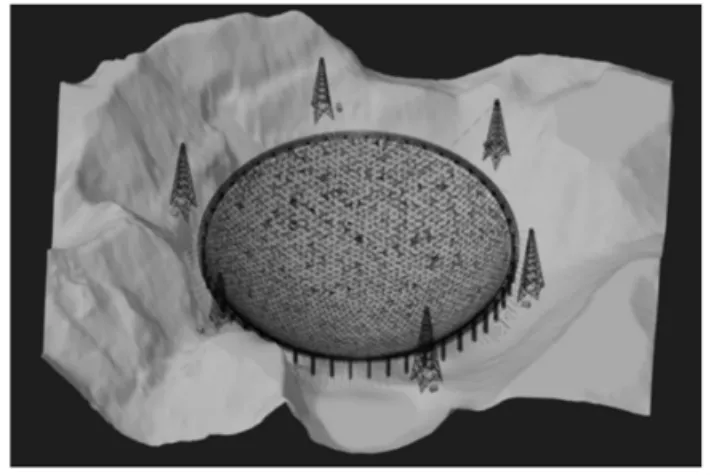
图2 FAST模型
FAST各部件模型在经过整合并且添加上其他体量较小的模型之后,整体模型体量已超过千万级,见表1。
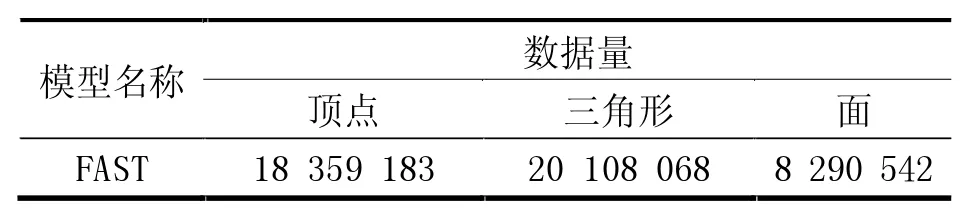
表1 FAST整体模型体量
3.2 测试结果
实验测试中采取两种方式验证本文设计的系统体系结构,一是Sort-first渲染及最终图像不在主渲染节点合成的方式,该方式使用2.4节设计的划分策略完成2D图像分割;二是Sort-last渲染及最终图像在主渲染节点合成的方式,该方式直接将模型数据范围进行划分,各渲染节点占据等比例的模型数据。
3.2.1 Sort-first图像不合成方式
根据子任务划分方式,进行视锥体的切分,将视锥体分为若干个不同的子视锥体,所有子视锥体渲染任务部署到不同的渲染节点中执行渲染操作。如图3所示,主渲染节点和3个从渲染节点各占1/4的模型渲染任务,并通过视口的位置变换实现显示拼接。
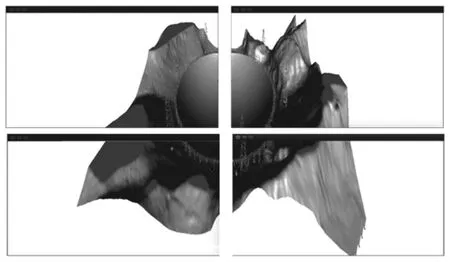
图3 四分FAST模型图像不合成
3.2.2 Sort-last图像合成方式
在该渲染方式中,没有进行基于视锥体的划分,按照模型比例大小实现任务的分配,例如在四分模型中,将模型数据大小等分为4份,4个渲染节点各占1/4,并且由于Sort-last渲染实现的是模型的部分区域,无法进行显示拼接,因此在主渲染节点进行图像合成,在渲染窗口中直接输出整体模型图案,如图4所示。

图4 四分FAST模型图像合成
3.3 结果分析
在渲染节点数量分别是1~4的情况下,采集执行1 000次渲染循环耗用的时间,其中包含图像不合成和图像合成两种情况,如图5所示。
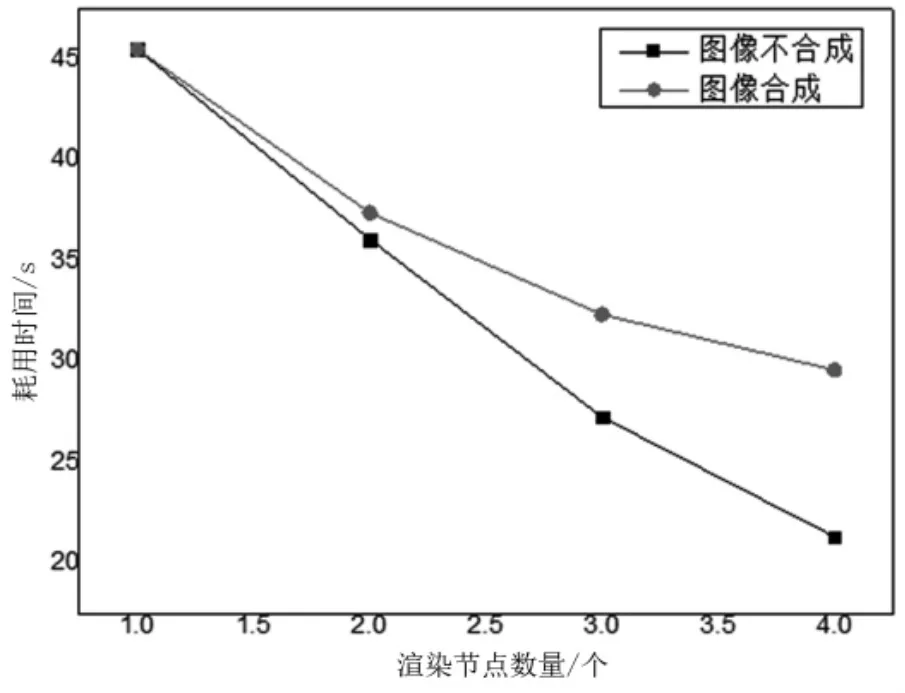
图5 渲染耗时对比
当增加渲染节点时,1 000帧的渲染耗时持续减少,绘制和渲染流畅度逐渐提升。当增加到4个渲染节点时,其渲染帧率也从22 fps分别增加到了47 fps和33 fps,能够满足实时渲染要求,验证了本文设计的分布式渲染系统体系结构的有效性。
在图像的合成中,由于增加了图像数据的传输和合成,因此在渲染耗时上,高于不合成的方式,并且在渲染节点逐渐增加的情况下,网络传输和合成耗时逐渐增多。
4 结束语
本文提出一种基于服务节点+主渲染节点+从渲染节点的分布式渲染系统体系结构,将任务执行过程中与渲染工作无关的模块分离到服务节点中,使其承担系统管理工作,与渲染相关的模块任务全部分配给渲染节点,并尽量使主节点与从节点的任务量趋于一致。以中国天眼FAST三维模型作为测试用例,测试结果表明,在保证实时渲染流畅度的前提下,本系统能够有效减少三维模型的整体渲染时间,提高渲染效率。
猜你喜欢
小猕猴智力画刊(2020年5期)2020-06-01
童话世界(2019年17期)2019-07-04
物理实验(2019年4期)2019-05-07
童话世界(2018年17期)2018-07-30
系统工程与电子技术(2016年4期)2016-08-24
现代防御技术(2016年1期)2016-06-01
系统工程与电子技术(2016年2期)2016-04-16
海军航空大学学报(2015年1期)2015-11-11
空间控制技术与应用(2015年4期)2015-06-05
中国卫生(2014年9期)2014-11-12
