
面向协作知识建构会话的智能观点分类研究——基于深度神经网络与会话分析的融合方法
2022-06-21 07:05:06马志强王文秋
现代教育技术 2022年6期
马志强 王文秋
面向协作知识建构会话的智能观点分类研究——基于深度神经网络与会话分析的融合方法
马志强 王文秋
(江南大学 江苏“互联网+教育”研究基地,江苏无锡 214100)
在面向知识建构的会话智能分析研究中,如何改善原有互动行为分析视角的局限,从会话观点的角度精准描述会话的语义特征以实现对会话进行自动分类,是研究者关注的核心问题。基于此,文章融合深度神经网络与会话分析方法,构建了包含相关度、纵深度、聚敛度三种会话分类特征的面向协作知识建构会话的智能观点分类框架,并设计包含六个环节的智能观点分类流程,引入到自然语言处理领域的BERT、TextCNN、Fasttext模型,从精确率、召回率、F1值、准确率四个指标对三种模型的会话分类特征进行比较,发现BERT模型在整体语义特征、单一会话类型的分类性能上均拥有更高的准确率。文章探索数智融合的会话分析框架与分析路径,证明了深度神经网络在协作知识建构会话智能量化分析中的可行性,有助于改善智能会话分析的质量与效率。
人工智能教育;学习分析;会话分析;知识建构;观点改进
一 研究现状
大数据、人工智能等新兴信息技术的进步,为教育评价带来了新的发展契机,不断推动教育评价向科学化、精准化、智能化的方向发展[1]。在复杂、真实的教育评价实践中,师生、生生之间的交流会话是实现教与学互动的关键手段,也是新兴技术赋能教学评价的重要着力点[2][3]。这是因为会话蕴含着复杂、动态的教学互动信息,能够体现个体或群体独特的思想意识、价值与立场,技术赋能的会话分析能够发展更具准确性与解释性的评测方法,来揭示会话隐含的教与学互动规律,并为教学改进提供充分依据[4]。
具体到协作知识建构教学中,会话是群体内部观点共享与意义协商的中介,对于理解多主体间的耦合作用关系和知识制品的形成发展过程具有重要价值[5]。协作知识建构会话分析是分析学习者协作知识建构过程与状态的重要方法,目前主要从会话过程、会话类别、会话质量三个角度开展。其中,会话过程分析将会话理解为群体成员观点共享、协商、升华等一系列认知参与活动,旨在分析其流程与关键环节[6];会话类别分析关注协作知识建构会话所达成的认知与社会性互动功能[7];会话质量分析从可读性、相关度、聚敛度、纵深度和探究度等维度,评价会话对于观点建构与意义协商的促进作用[8]。综合上述研究成果,可知目前面向协作知识建构的会话分析重于对会话特征进行定性描述,而缺乏对会话量化特征的定义,导致编码一致性较低,影响了分类算法的准确性,难以应用于大规模、伴随式的会话分析场景之中。
鉴于此,有研究者提出了面向协作知识建构会话智能化分析的基本路径,其实现的关键路径是从观点分类的角度精准描述会话的语义特征,揭示会话内容中持续的观点改进进程[9][10]。也有研究者认为,目前智能技术支持的协作知识建构会话分析实现的主要路径是将会话表示为相应交互行为的集合,将会话分析问题转化为行为单元及其相互关系分析[11]。此外,有研究者采用会话内容聚类、话题演化等方法,针对会话词语层级的含义进行分析,但词语层级的分析脱离了具体会话情境,忽略了会话语句中语义的功能指向[12];有研究者开始尝试基于自然语言处理中的观点分类方法,以观点制品为分析对象,开展智能观点分类研究[13]。自然语言处理的观点分类方法旨在识别会话内容中表达的观点和立场,主要通过传统机器学习模型与深度神经网络模型实现文本分类[14]。而相较于传统机器学习方法,深度神经网络基于对词语在不同情境中指向不同对象而表达出特定含义的理解,注重相邻词语之间的关联,在理解语义结构方面具有更好的性能[15]。有少数研究者对此进行了初步探索,如宋宇等[16]首先提出了面向知识建构的课堂对话编码体系,具体包含基础知识、个体表达、分析、归纳、推理与迁移、回应与拓展、认同、质疑、指导九大类,为会话类别赋予知识建构的内涵,并围绕以上编码体系,采用人工编码和机器学习相结合的方法对真实课堂中的协作知识建构会话文本进行分类,应用机器学习的方法创设了基于深度学习的行为类别自动序列标注模型CNN-BiLSTM,实现对话语文本的语义进行理解和自动识别,在会话类型识别方面取得了高于70%的准确率。然而,此研究会话数据来源于网络平台汇集的、以教师为中心的中小学课堂,无法代表真实的知识建构学习情境,此外,分类效果也需进一步优化。鉴于上述研究空缺,本研究融合深度神经网络与会话分析方法,围绕协作知识建构的观点改进过程,从相关度、纵深度、聚敛度三个会话语义特征,构建面向协作知识建构会话的智能观点分类框架,并提炼智能观点分类的基本路径,以实现从会话语义特征层面对会话类型进行精准识别[17]。
二 面向协作知识建构会话的智能观点分类框架
协作知识建构会话的核心功能是通过分享、协商观点、达成共识等环节进行观点改进,使知识建构过程与知识制品得以完成。因此,观点改进是知识建构会话的主要功能指向。同时,还存在支持观点改进过程的其他会话,包括协调任务的安排与进度、技术问题的交流与解决。此外,还包括极少数与知识建构任务无关联的会话,可能会影响观点改进的进度与效率。
基于此,本研究参考刘黄玲子等[18]提出的交互分析编码框架进行构建,以蒋纪平等[19]提出的知识建构观点分析框架指导观点改进会话的分类,并以Zhu[20]的知识建构交互分析框架中提出的信息检索与讨论性两大类问题来支撑其中的共享型观点分类,以Pena-Shaff等[21]的在线讨论知识建构过程评估框架中对冲突与支持的细致分类来支撑其中的协商型观点分类。此外,本研究还综合考虑了在线学习环境,为此提出技术型会话,最终从会话语义特征的角度对会话进行分类描述,以观点改进为核心,凝练出相关度、纵深度、聚敛度三种会话分类特征,并构建了面向协作知识建构会话的智能观点分类框架,如图1所示。
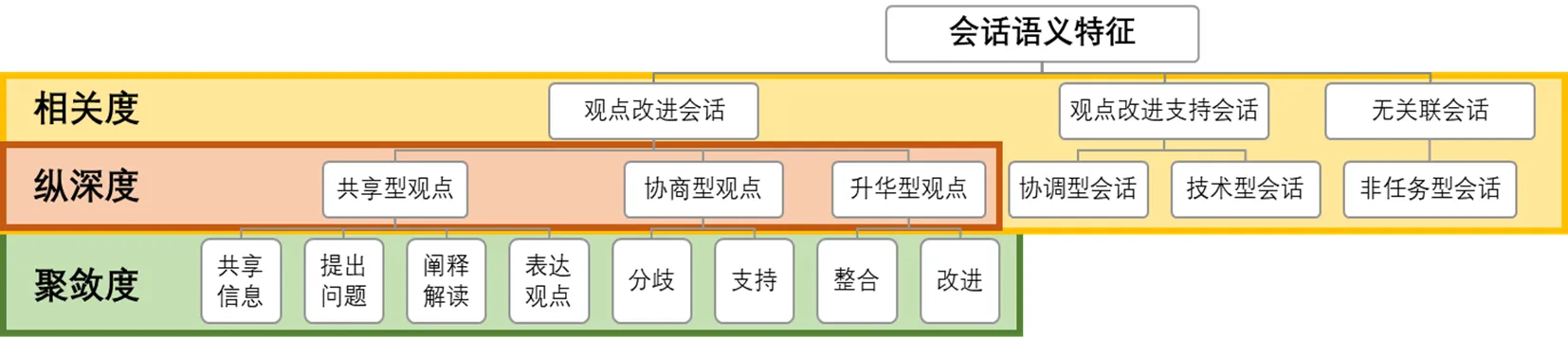
图1 面向协作知识建构会话的智能观点分类框架
本研究根据会话内容与观点改进的相关度,对协作知识建构会话进行第一层级分类。同时,观点改进会话本身存在阶段性的变化,为了对观点改进会话进行更深入的挖掘,因此本研究根据纵深度对观点改进会话进行第二层级分类。另外,不同观点改进深度的达成由多个观点类型推动,每一深度的多个观点类型属于并行关系,但存在逻辑顺序的差异,因此本研究根据聚敛度对观点改进三个深度的会话进一步分类。三种会话分类特征均以观点改进为核心,并逐步分解、逐层深入。
第一种会话分类特征是相关度,指会话内容与协作知识建构观点改进任务的相关程度,具体分为三个类目:①观点改进会话,是指与最终知识制品直接相关的会话观点,包括共享型观点、协商型观点、升华型观点。②观点改进支持会话,是指在知识建构过程中起到支持作用的会话,具体分为协调型会话、技术型会话两类。其中,协调型会话是指小组内部围绕小组任务进行计划、监督、协调而推动观点改进的会话;技术型会话则指小组排除技术因素的干扰,相互支持的会话——由于本研究采集的是基于在线同步协作知识建构会话,因此成员需要解决技术障碍完成会话交流。③无关联会话,是指过于简短且不包含明确观点或与协作知识建构任务无关的会话,与观点改进没有直接关联。
第二种会话分类特征是纵深度,用于区分观点改进会话的作用深度,将观点改进会话进行分类描述,具体分为三种观点:①共享型观点,是指成员之间的询问与解释,旨在对需要解决的任务与问题统一认知,并清楚掌握彼此观点的含义;②协商型观点是指在掌握彼此观点含义的基础上,对自己的观点进行维护和对他人的观点表明立场,旨在对任务拆解的问题方案达成初步一致;③升华型观点是指小组成员对已经达成的方案和观点进行梳理、汇总与优化,并对自身知识建构认知能力的提升情况进行反思。
第三种会话分类特征是聚敛度,针对观点改进会话进行细分,指观点围绕对应深度的聚敛程度。共享型观点对应的是共享信息、提出问题、阐释解读、表达观点。其中,共享信息是指组员之间对查阅资料内容的分享、对当前协作知识建构任务内容的说明、对已有研究成果的表述、对他人观点的转述等;提出问题是指对术语概念解释的请求、对任务问题的拆解;阐释解读是指对术语概念与观点含义的阐释、对任务问题的解读;表达观点则指对资料、他人观点的想法,以及对他人抛出的问题的回答。协商型观点对应的是分歧、支持。其中,分歧是指对他人观点的质疑、面对质疑的自我辩护;支持是指对他人观点表示赞同且表达自己赞成的理由。而升华型观点对应的是整合、改进。其中,整合是指小组成员对当前知识建构成果的汇总;改进是指对协作知识建构成果进行完善与修改,以完成最终的知识制品。
三 面向协作知识建构会话的智能观点分类流程
智能观点分类的基本流程旨在依照智能观点分类框架,实现自动化的观点分类,主要分为六个环节(如图2所示):①第一个环节是分类框架构建。框架用于描述知识建构会话基于语义特征的功能指向。②第二个环节是数据采集与清洗。以录音形式对各小组会话进行采集,通过机器转录与人工清洗,最终以一系列具有完整语义的会话作为分类对象。③第三个环节是特征提取与标注。编码者按照会话观点分类框架,考虑会话内容表达的语义特征,对数据进行编码。④第四个环节是分类模型训练,以编码完成的数据作为数据集,采用预先选择的三个模型进行观点分类训练。⑤第五个环节是模型效果评价。使用精确率、召回率、F1值、准确率四个指标作为模型分类效果的评价依据,并对比分析各模型的分类性能。⑥第六个环节是分类模型优化。针对分类效果,通过数据增强、组合模型等方式进行分类方法优化。本研究以实践案例形式对具体环节进行说明,第一个环节采用上述第一部分提出的面向协作知识建构会话的智能观点分类框架,下文对第二个、第三、第四个环节进行重点分析,第五环节将在第三部分具体描述,第六环节将在讨论部分进行初步探索。
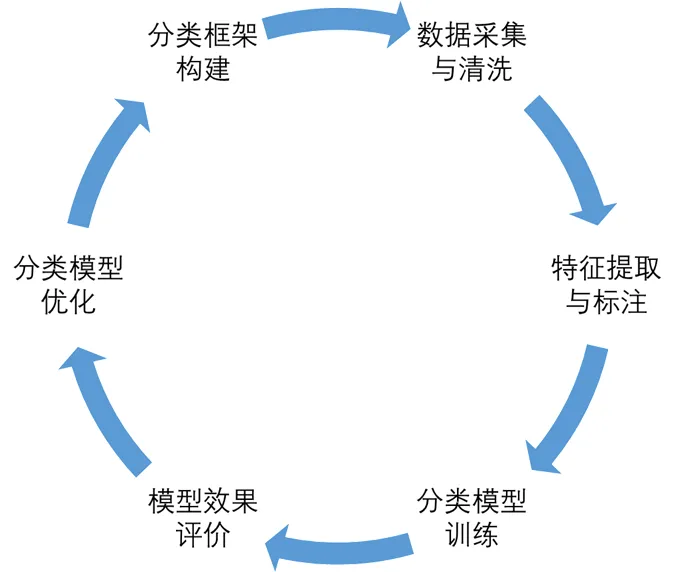
图2 智能观点分类流程图
1 数据采集与清洗
本研究的数据来源于2020年~2021年新冠肺炎疫情防控期间江苏省无锡市J大学人文学院教育技术学专业开设的“教育技术研究方法”课程。该课程以小组协作的形式开展,每组4~5人开展协作知识建构活动[22]。首先,小组成员围绕“技术支持的协作学习”主题,对小组选择的研究议题开展分析与论证。同时,各小组组长通过录音,对小组协作知识建构会话数据(包含实时在线会话数据、实时面对面会话数据等)进行采集。随后,研究者按照时间顺序对各小组会话录音进行整理后,通过机器转录获得录音文本。最后,研究者对录音文本进行人工校对,对口语化数据的表述逻辑、叠词、口头禅等进行适当的增加、删除、替换、交换等清洗操作,清洗操作案例如表1所示。通过对数据的清洗操作,本研究最终整理出有效会话数据6933条。
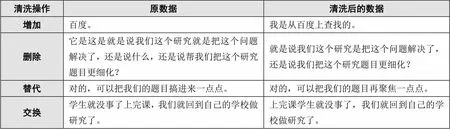
表1 清洗操作案例
2 特征提取与标注
在本研究中,编码者按照已构建的智能观点分类框架进行编码,在编码过程中提取观点改进会话内容的语义特征,以实现对特征的量化描述。从会话数据中随机选择5%的文本,由本研究团队的两名成员分别进行编码。编码结束后,计算编码者间一致性系数(Cohen’s Kappa),得到相关度编码一致性达到0.89、纵深度编码一致性达到0.89、聚敛度编码一致性达到0.89,说明编码结果的信度可以接受。随后,两名编码者协商存在分歧的编码,明确各指标含义,直至达成一致意见。最后,照此方式完成剩余数据的编码。
编码完成后的每一条数据都对应三种会话语义特征,而完成编码的数据将用于三种模型的训练。本研究从总数据集中取出20%作为测试集来评估模型预测效果,剩余的80%数据作为训练集。模型通过对训练集会话语义特征与语法的提取,调整参数使模型反映现实,进而预测未来或其他未知的信息,而测试集用来评估模型预测性能。数据集中各会话分布情况如表2所示。
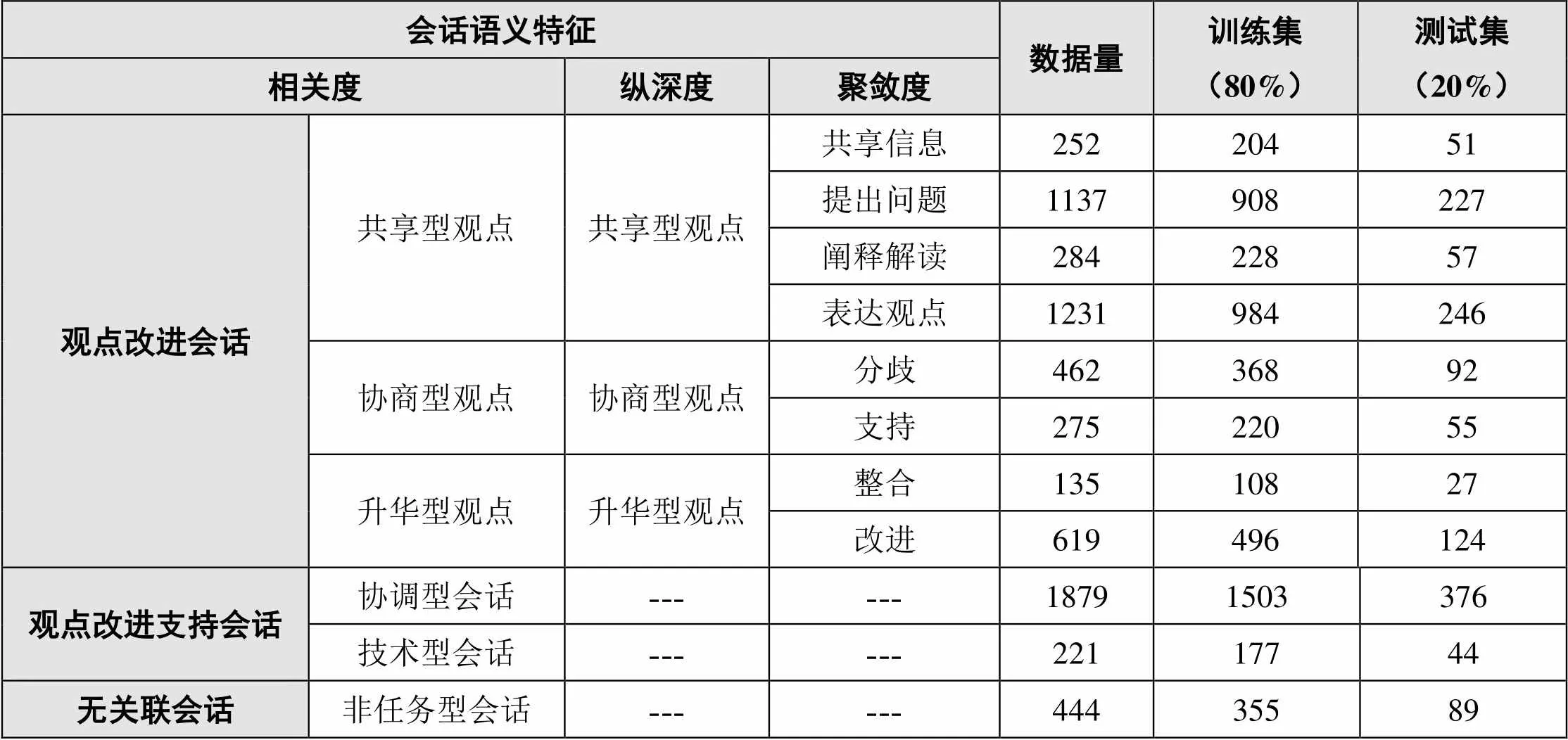
表2 数据集中各会话分布情况
3 分类模型训练
本研究选择了在自然语言处理领域中表现较为优异的BERT、TextCNN、Fasttext三种模型算法来进行训练。其中BERT是Google在2018年提出的NLP预训练模型,在NLP领域的11个方向都取得了优秀成果[23]。TextCNN模型是由Kim在2014年提出的一种深层前馈神经网络模型,其将卷积神经网络应用到文本分类任务,验证了TextCNN在文本分类问题上有更加卓越的表现[24]。Fasttext是Facebook开源的一个词向量与文本分类工具,属于概率语言模型,典型应用场景是“带监督的文本分类问题”,其性能可比肩深度学习算法且速度更快[25]。
值得注意的是,三种模型在特征提取方式、所基于的数据集方面存在差异。分类模型的主要作用,就是通过特征提取掌握字符的构造特征。BERT模型主要使用多层Transformer结构,该结构使用Attention机制对输入的向量进行特征提取与计算权重,识别出更能代表会话语义的词向量,并赋予其更大的权重[26];TextCNN模型利用卷积实现特征的提取,对文本浅层词语级特征的抽取能力很强[27];而Fasttext利用n-gram进行特征的提取,对字符级特征的抽取能力很强[28]。此外,数据的样本数量在训练模型时十分重要。根据大数定律,样本数量越多时,频率越接近于概率;而样本数量很少时,模型的准确率就相对比较低。三个模型中,只有BERT模型利用了极大量的网络数据进行了预训练,使预训练模型已经学会了中文的语义表达与语法结构,并在此基础上基于本地语料库对模型的参数进行了微调,本地语料库存储着本研究采集到的协作知识建构这一特定领域的会话数据,可能会提高模型识别的准确性。而其他两个模型只根据本地数据库对模型进行了训练。
四 数据分析结果
本研究使用精确率(Precision)、召回率(Recall)、F1值(F1-score)和准确率(Accuracy),作为协作知识建构会话观点分类效果的评价指标。精确率表示每一类别中被预测为正类的样本中实际正类的比例;召回率表示每一类别中所有正类样本中被预测为正类的比例;而F1值表示在调和精确率和召回率之后,对分类器性能的综合评判,可以代表各个类别的分类准确率;准确率代表的是分类器的整体准确率[29]。F1值和准确率是评价分类器性能的核心指标。
1 相关度分析结果
对相关度而言,三种模型训练分类结果比较如表3所示,可以看出:BERT模型的整体准确率为85%,高于其他两个模型;其次是Fasttext模型,准确率为81%;最后是TextCNN模型,准确率为77%;同时,BERT模型的F1值相较于其他两个模型更高。此外,从纵向视角即具体会话类型上各模型的表现来看,BERT模型在6个会话类型的F1值均明显高于TextCNN模型、Fasttext模型;而Fasttext模型在大部分类别上高于TextCNN模型,仅在协商型观点、非任务型会话的F1值与TextCNN模型持平。而从横向视角即每个模型对6个会话类型的分类表现来看,BERT模型中5个会话类型的F1值均高于80%,其中3个会话类型的F1值接近甚至大于90%,仅协商型观点的分类表现上较差;而TextCNN模型与Fasttext模型中均存在多个会话类型的F1值低于80%的情况。由此可见,BERT模型在分类模型整体表现、单一会话类型分类性能上均优于TextCNN模型和Fasttext模型。
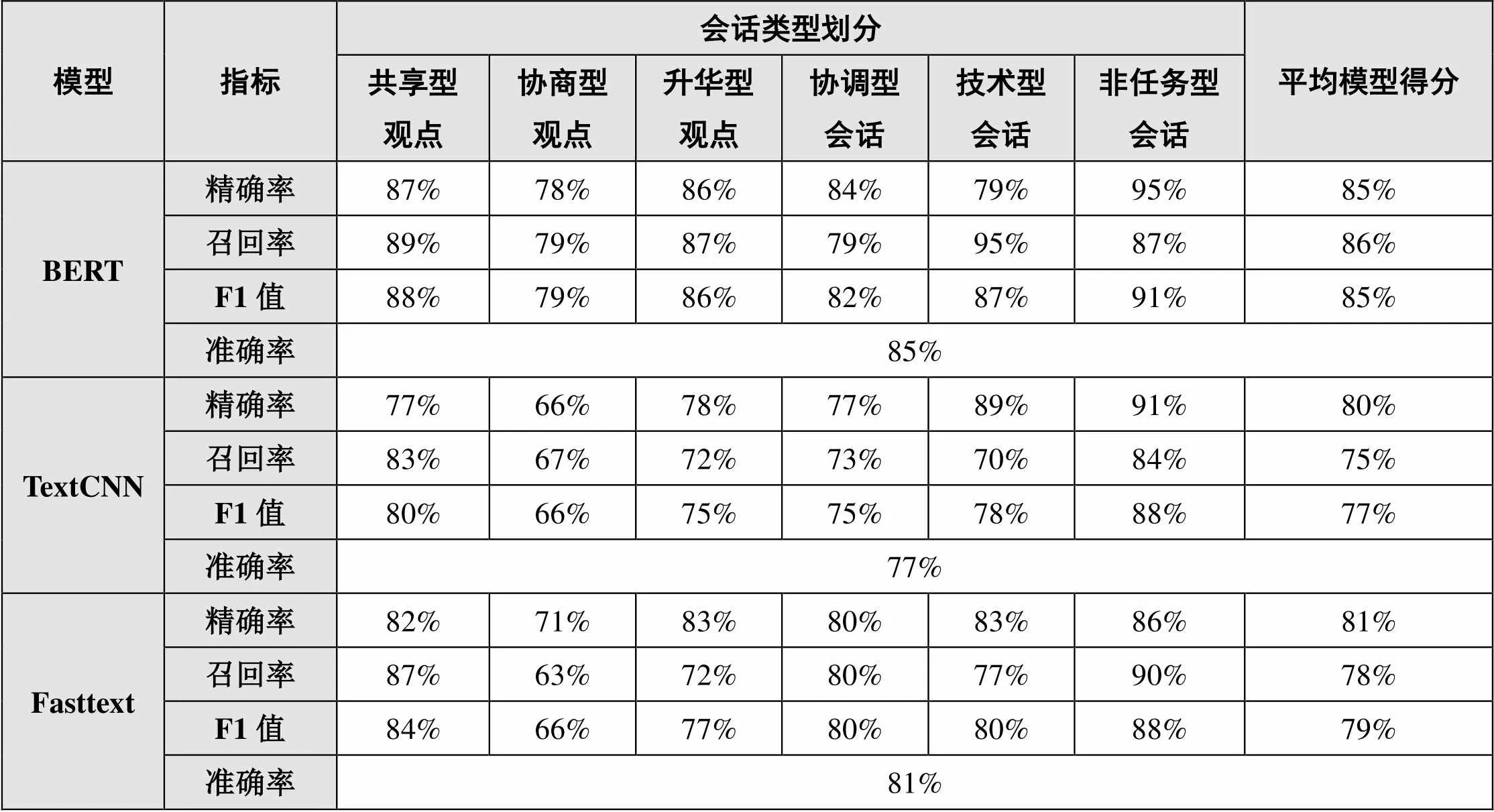
表3 相关度三种模型训练分类结果比较
2 纵深度分析结果
对纵深度而言,三种模型训练分类结果比较如表4所示,可以看出:BERT模型的整体准确率为87%,高于其他两个模型;其次是Fasttext模型,准确率为80%;最后是TextCNN模型,准确率为79%。同时,BERT模型的F1值相较于其他两个模型更高。此外,从纵向视角即具体会话观点类型上各模型的表现来看,BERT模型在4个会话观点类型的F1值均明显高于TextCNN模型、Fasttext模型,Fasttext模型在共享型观点、无纵深度会话上的F1值高于TextCNN模型,而在协商型观点、升华型观点上的F1值略低于TextCNN模型。从横向视角即每个模型对4个会话观点类型的分类表现来看,BERT模型中3个会话观点类型的F1值均高于85%,仅协商型观点的分类表现上较差,而TextCNN模型、Fasttext模型均存在在协商型观点与升华型观点两个类型上F1值较低的情况。由此可见,BERT模型在分类模型整体表现、单一会话类型分类性能上均优于TextCNN模型和Fasttext模型。
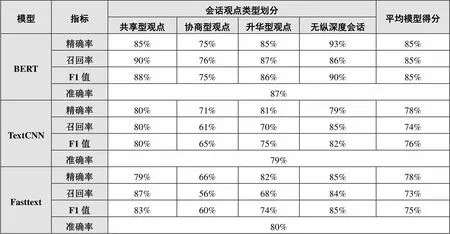
表4 纵深度三种模型训练分类结果比较
3 聚敛度分析结果
对聚敛度而言,三种模型训练分类结果比较如表5所示,可以看出:BERT模型的整体准确率为83%,高于其他两个模型;其次是Fasttext模型,准确率为76%;最后是TextCNN模型,准确率为69%。同时,BERT模型的F1值相较于其他两个模型更高。此外,从纵向视角即具体会话观点类型上各模型的表现来看,BERT模型在9个会话观点类型的F1值均高于TextCNN模型、Fasttext模型;Fasttext模型在提出问题、阐释解读、表达观点、分歧、无聚敛度会话5个会话观点类型的F1值高于TextCNN模型,而在共享信息、整合、改进3个会话观点类型的F1值略低于TextCNN模型,仅在支持的F1值与TextCNN模型持平。而从横向视角即每个模型对9个会话观点类型的分类表现来看,BERT模型在7个会话观点类型的F1值均高于70%,其中3个会话观点类型的F1值甚至高于85%;但在共享信息、阐释解读两个会话观点类型的分类表现上较差,低于70%。由此可见,BERT模型在分类模型整体表现、单一会话类型分类性能上均优于TextCNN模型和Fasttext模型。
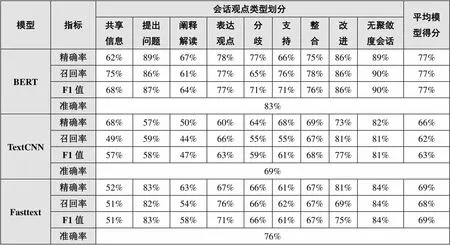
表5 聚敛度三种模型训练分类结果比较
五 讨论
本研究针对会话分析,建立了相关度、纵深度、聚敛度三个特征相结合的智能观点分类框架。相对于已有会话分类框架从行为表现角度分析,忽略了对会话内容的语义特征及其功能指向的描述[30][31];重在刻画会话的认知特征,忽略了知识建构中大量存在的非认知会话内容[32][33]。同时本研究采用观点改进为核心的功能指向来描述会话的语义特征,兼顾考虑认知与非认知会话,并详细定义会话的特征,满足依据观点进行会话自动分类场景的基本需求。
本研究选取了两个经典深度神经网络以及一个可以与深度神经网络准确率相媲美的模型,探索深度神经网络这类模型在知识建构会话智能分类上的可行性。结果表明,BERT模型相较于Fasttext与TextCNN存在一定的优势,更适合协作知识建构会话的智能观点分类。BERT模型通过多层特征转换将非结构化数据变成更高层级、更抽象的表示,从而实现对数据的类别预测与识别,其本身算法结构更具优势。另外,BERT模型基于庞大的预训练数据库,分类的质量与效率较高。为了进一步提升分类准确率,本研究还选择采用数据增强方法,在对原数据分词的基础上,通过同义词替换、随机插入或删除、交换实现数据量快速扩充[34]。研究结果显示,上述增强方法并未显著提升分类的准确率,原因可能是协作知识建构会话中的词语及其顺序携带了重要的语义与句法信息,单纯进行同义词替换、交换等很可能改变原有术语及语义,导致增加了无效数据,对机器学习产生了干扰,因此没有能够对分类的准确性产生足够影响。
而本研究建立的会话智能观点分类流程融合深度神经网络与会话分析方法,建立了包含六个环节的循环模型。会话分析主要体现在流程的前三个环节,深度神经网络主要体现在流程的后四个环节。其中第三个环节特征提取与标注是深度神经网络与人工会话分析融合的关键衔接环节。编码者根据智能观点分类框架提取出会话中的特征,从而完成编码标注。而模型利用人工已编码的数据,提取并学习到每一个会话类型中应用的语义特征,从而顺利完成训练。
六 总结与展望
本研究将会话分析与深度神经网络方法融合,从会话分析模型、分析过程以及分析算法角度探索了面向协作知识建构的智能观点分类方法。未来针对分类框架,可对非认知会话进行更加细致、清晰的描述,以提升方法对非认知会话内容分类的准确性。此外,在分类模型训练上,还要考虑会话前后语境的作用,通过组合模型,建立句与句之间的关联,增强机器对语义的进一步理解,提高分类的准确率,并挖掘会话在话题层级的语义特征[35]。最后,研究者可以尝试将智能观点分类模型嵌入教学平台,前设置知识建构会话实时转录功能获得数据,后设置模型预测功能导出分类结果数据,实现对知识建构会话内容的伴随式分析。
[1]胡小勇,孙硕,杨文杰,等.人工智能赋能教育高质量发展:需求、愿景与路径[J].现代教育技术,2022,(1):5-15.
[2]郑旭东,吴秀圆.教育研究取向转变进程中的会话分析:真实场景下教学研究的一种工具性支持[J].电化教育研究,2015,(1):18-22.
[3][16][33]宋宇,邬宝娴,郝天永.面向知识建构的课堂对话规律探析[J].电化教育研究,2021,(3):111-119.
[4]凌建侯.话语的对话性——巴赫金研究概说[J].外语教学与研究,2000,(3):176-181、239.
[5][10][19]蒋纪平,胡金艳,张义兵.知识建构学习社区中“观点改进”的发展轨迹研究[J].电化教育研究,2019,(2):21-29.
[6]Gunawardena C N, Lowe C A, Anderson T. Analysis of a global online debate and the development of an interaction analysis model for examining social construction of knowledge in computer conferencing[J]. Journal of Educational Computing Research, 1997,(4):397-431.
[7]Fransen J, Weinberger A, Kirschner P. Team effectiveness and team development in CSCL[J]. Educational Psychologist, 2013,(1):9-24.
[8][9][13]王丽英,张义兵.融合知识建构和机器学习的观点质量评价[J].现代教育技术,2020,(11):62-69.
[11]胡金艳,蒋纪平,陈羽洁,等.知识建构社区中观点改进的机理研究:知识进化的视角[J].电化教育研究,2021,(5):47-54.
[12]Hayati H, Chanaa A, Idrissi M K, et al. Doc2Vec &Naïve Bayes: Learners’ cognitive presence assessment through asynchronous online discussion TQ transcripts[J]. International Journal of Emerging Technologies in Learning, 2019,(8):70-81.
[14]吴春叶.基于半监督学习的观点挖掘算法的研究与实现[D].北京:北京邮电大学,2019:7.
[15]Liu G, Guo J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification[J]. Neurocomputing, 2019,(337):325-338.
[17]李舟军,范宇,吴贤杰.面向自然语言处理的预训练技术研究综述[J].计算机科学,2020,(3):162-173.
[18]刘黄玲子,朱伶俐,陈义勤,等.基于交互分析的协同知识建构的研究[J].开放教育研究,2005,(2):31-37.
[20]Zhu E. Meaning negotiation, knowledge construction, and mentoring in a distance learning course[A]. Proceedings of Selected Research and Development Presentations at the 1996 National Convention of the Association for Educational Communications and Technology[C]. Indeanapolis: Available from ERIC Documents, 1996:821-844.
[21]Pena-Shaff J B, Nicholls C. Analyzing student interactions and meaning construction in computer bulletin board discussions[J]. Computers & Education, 2004,(3):243-265.
[22]张义兵.知识建构:新教育公平视野下教与学的变革[M].南京:南京师范大学出版社,2018:90-91.
[23][26]Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[OL].
[24]Kim Y. Convolutional neural networks for sentence classification[OL].
[25]Rospocher M. Explicit song lyrics detection with subword-enriched word embeddings-ScienceDirect[J]. Expert Systems with Applications, 2021,(163):113749.
[27][29]甄园宜,郑兰琴.基于深度神经网络的在线协作学习交互文本分类方法[J].现代远程教育研究,2020,(3):104-112.
[28]Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[OL].
[30]郑勤华,郭利明.人机协同的敏捷教育建模及实践应用[J].现代远程教育研究,2021,(4):43-50.
[31]马志强.从相互依赖到协同认知——信息化环境下的协作学习研究[M].北京:中国社会科学出版社,2019:223-231.
[32]马志强,郭文欣,王萌.面向协作知识建构会话内容的智能挖掘分析[J].现代远距离教育,2022,(1):3-13.
[34]Sun X, He J. A novel approach to generate a large scale of supervised data for short text sentiment analysis[J]. Multimedia Tools Appl, 2020,(79):5439-5459.
[35]马志强.社会认知互动的多维刻画:协作学习投入理论构建与实践探索[M].北京:中国社会科学出版社,2021:156-158.
Research on Intelligent Viewpoint Classification for Collaborative Knowledge Construction Discourse——Based on the Fusion Method of Deep Neural Network and Discourse Analysis
MA Zhi-qiang WANG Wen-qiu
In the research of discourse intelligence analysis for knowledge construction, how to improve the limitations of the original interactive behavior analysis perspective, and accurately describe the semantic features of discourse from the discourse perspective, so as to realize automatic classification of discourse is the core concern of researchers. Based on this, fused with the deep neural network and discourse analysis method, an intelligent viewpoint classification framework for collaborative knowledge construction discourse was constructed, which contained three discourse classification features of relevance, depth, and convergence. Meanwhile, an intelligent viewpoint classification process consisting of six steps was designed, and further the process was introduced into the BERT, TextCNN, and Fasttext models of natural language processing, and the discourse classification characteristics of the three models were compared in terms of four indicators, namely precision, recall, F1-score, and accuracy. It was found that the BERT model has higher accuracy in overall semantic features and classification performance of single discourse type. This paper explored the analysis framework and analysis path of discourse analysis of the fusion of data and intelligence, which proved the feasibility of the deep neural network in the intelligence quantitative analysis of collaborative knowledge construction discourse, and was helpful for improving the quality and efficiency of intelligent discourse analysis.
artificial intelligence education; learning analysis; discourse analysis; knowledge construction; viewpoint improvement

G40-057
A
1009—8097(2022)06—0005—10
10.3969/j.issn.1009-8097.2022.06.001
马志强,博士,教授,研究方向为计算机支持的协作学习、学习分析与评价的研究,邮箱为mzq1213@jiangnan.edu.cn。
2022年1月20日
编辑:小时
猜你喜欢
作文成功之路·小学版(2019年8期)2019-09-18 01:12:04
军营文化天地(2018年1期)2018-08-15 00:44:08
读者(2017年14期)2017-06-27 12:27:06
疯狂英语(双语世界)(2017年4期)2017-04-28 09:10:37
海外华文教育(2016年3期)2017-01-20 08:22:18
读写算(下)(2016年9期)2016-02-27 08:46:31
电子工业专用设备(2015年4期)2015-05-26 09:10:39
营销界(2015年22期)2015-02-28 22:05:04
清风(2014年10期)2014-09-08 13:11:04
山西大同大学学报(社会科学版)(2014年5期)2014-01-23 01:30:51
