
机器学习算法下水利工程风险因素关系分析
2022-06-21 09:05孙开畅冯继伟
水力发电 2022年1期
孙开畅,冯继伟
(三峡大学水利与环境学院,湖北 宜昌 443002)
0 引 言
水利工程事故具有特殊性、复杂性等特点,很难实现将水利工程事故发生概率降低为零,而研究水利工程事故一个重要方向就是找出影响水利工程的主要风险因素并确定风险因素之间的关联关系,它能够为水利工程预测机制、应急救援及物资调配提供数据分析及技术保障。水利工程风险分析研究是一套相对完整的体系,一般包括事故风险管理体系、事故风险分析体系、事故风险等级体系等,其中事故风险因素分析至关重要[1-3]。本文主要针对水利工程的风险因素进行多维因素关联研究,以期能够找出影响水利工程事故的关键因素,并确定各因素之间的关联关系。
目前已有不少数据的关联分析研究,Becker等[4]提出了CBR图网络模型,并将其运用到数据关联分析中,对特征数据进行了关联分析;马建斌等[5]将改进的Apriori算法运用到海事的事故数据关联分析中,对海事事故进行了因素分析,解析出了各个因素对海事的影响情况;黄钧晟等[6]以云计算平台为背景,利用数据关联算法对气象数据进行关联规则分析研究,找出了气象数据之间的潜在联系及规律,通过这些规律有效地对气象进行了预测,为海量气象数据挖掘提供了很好的技术支持;朱海等[7]利用Apriori算法建立了企业风险数据库和相关报表,对企业管理型风险实现了预警,最大程度地减少企业资产损失。
结合已有研究和水利工程特点,从风险因素的角度来考虑,部分风险因素数据并未存在完全明确的强逻辑关系,如何将这些风险因素数据联系起来,建立起完整的多维数据关系是解决水利工程事故风险关系的一个至关重要的环节。基于此,本文在上述研究的基础上结合水利工程的特点,将机器学习中的Apriori数据关联算法引入到水利工程风险因素多维关联分析中,以期能够描绘出水利工程多维因素关联关系,为应急救援及物资调配提供数据分析及技术保障支持,并完善水利工程的应急管理系统。
1 水利工程高危人为风险因素识别
水利工程事故涉及到很多的领域并且一般破坏性强、经济损失大、社会影响大。水利工程事故体系是一个复杂的风险系统,影响水利工程事故发生的因素众多,而这些特征因素又受到各种人为条件的限制,这使得整个水利工程安全风险体系具有复杂性、不确定性。为保障水利工程的安全,降低事故的影响,非常有必要对影响水利工程事故的人为风险因素进行识别和分析。
根据风险因素的模糊程度,可以将风险因素提取形式分为基于语言数据的因素值提取、基于已知因果关系的因素提取、基于主因素分析的数据因素提取等。本研究依据水利工程的风险分析现状,并结合实际的工程状况和国内学者对风险指标评价体系的研究现状,以人为因素分析与分类系统(HFACS)[8-9]作为风险因素分析的方法和工具,并对HFACS框架中的因素进行分类和细化处理,以适应水利工程的施工技术和安全管理等状况,通过删除和合并部分与水利工程不相吻合的因素,最终得到经过修订后的HFACS框架[1],如图1所示。

图1 风险体系框架
2 数据关联算法的引入
2.1 Apriori算法
Apriori算法[10-11]为一种计算数据频繁项集和因素多维关联规则的无监督学习算法,该算法以频繁项集性质为先验知识,可以从大规模的数据信息集合中计算出不同数据因素之间的关联规则。基于机器学习的Apriori算法有如下几个基本定义:项集、支持度、置信度、关联规则、频繁项集。
(1)项集。水利工程的事故风险项集主要指具体的工程事故案例,这些事故案例也是风险关系的具体表现形式。
(2)支持度。事故案例风险因素同时发生的概率,其中事故风险因素A对事故风险因素B的支持度表示为
support(A→B)=P(A∪B)
(1)
式中,P(A∪B)表示案例中风险因素A和B同时发生的概率。
(3)置信度(confidence)。数据因素关联规则关系的置信程度,能够表示因素风险之间产生的强关联规则,即
(2)
(3)关联规则(association rules)。风险关联关系的支持度和置信度都大于最小要求时的关联关系,即被挖掘的各个风险因素之间的关联关系。数据的关联规则挖掘一般分为两个过程:找出频繁项集和因素之间的强关联规则关系。频繁项集挖掘一般有如下原则[10-13]:①频繁因素项集连接原则。频繁项集k和Lk-1项集的自身连接产生候选k项集Ck,如果Lk-1中某两个的元素(项集)itemset1和itemset2的前(k-2)项是相同的,则表示itemset1和itemset2是可连接的。②剪枝原则。根据已有的先验性质,遍历整个因素事故库,计算中每个代确定的风险因素出现的次数,将风险因素出现的次数与最小支持度相比较,确定频繁因素项。③删除原则。基于压缩后的Ck,遍历整个水利工程风险数据库,对Ck中的每个风险因素进行计数,去除不满足最小支持度的风险因素项集。
2.2 Apriori算法实现
该算法是一种逐层迭代算法,即为利用k项来计算(k+1)的方法。过程如下:首先,通过扫描整个事故风险数据库,计算出每个案例中的风险因素的数据并收集满足最小支持度的风险项集,找出频繁1项集的风险项集的集合,这些风险因素构成了候选1项集的集合C1;然后从C1中删除不满足最小支持度的项集,从而获得频繁项集L1,使用L1找出频繁2项集的集合L2;以此类推,对整个风险因素事故数据库进行扫描,对Ck中的每个项进行计数,根据最小支持度的原则,从Ck中删除不满足的项,从而获得频繁k项集。
一旦找出了最终的频繁项集,就表明产生了强关联关系。对于每个频繁项集,如果

(3)
则输出s⟹(l-s),其中min_conf是最小置信度阈值。
3 事故风险因素多维关联分析
3.1 风险关联体系的建立
本研究以长江干流中的3个水利枢纽在2000年~2011年间的186起轻伤以上的事故数据为风险因素的研究对象[14],利用机器学习中的Apriori算法对数据的风险因素进行挖掘,针对于每一起事故,由专家来判断该事故中是否含有HFACS框架中的风险因素,若存在该风险因素,则该风险因素在该事故中的数据值为1,如不存在该因素,则该风险因素的数据值为0,取出其中10故案例风险数据结构表示表示,如表1所示。
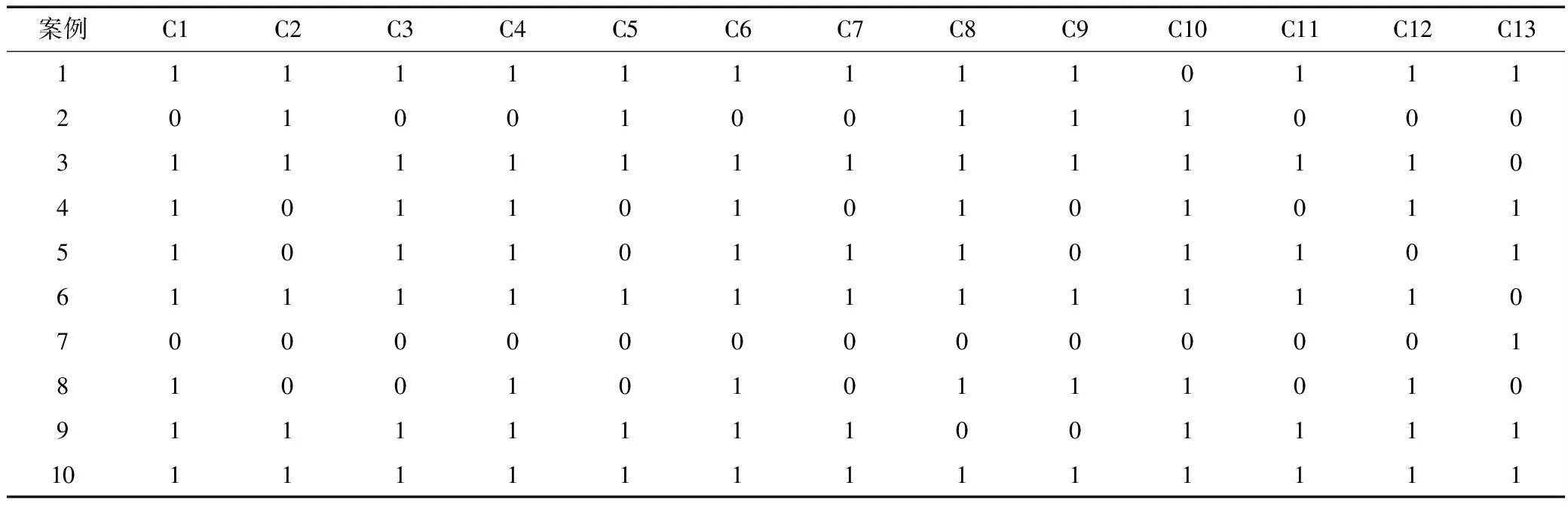
表1 事故风险因素
基于上述的186起事故的事故风险案例进行数据挖掘,可以得出各个风险因素之间的多维关联关系,为保证事故数据关系有较高的可信度及支持度,本研究中将事故因素关联关系的支持度取100%,置信度取100%,即在可信度为100%的情况下风险因素同时发生概率为100%,根据上述限制条件并方便事故风险因素之间的表达,取出风险因素关系进行计算。通过对上述的事故数据进行挖掘,利用关于数据关联的两个主要的过程,找出所有的频繁项集和找出事故案例因素之间的强关联规则关系,最终得到如表2所示水电工程事故案例人为因素的多维数据关联关系。

表2 多维关联关系
3.2 多维风险关联关系分析
将186起水利工程的事故案例库作为一个完整的风险事故案例集,事故数据的每一项信息构成一个项集,项集中任一个项目都是一个与水利工程风险相关的因素,本次数据挖掘试验对于水利工程的事故数据库进行数据挖掘,从挖掘关系进行分析,在置信度100%、支持度100%的情况下,可以得到如下的规则:
(1)单个维度的数据规则方面。安全生产教育对于技术人员的各个方面都非常重要,通过加强对人员的安全生产教育,可以解决人员素质问题、人员的操作违规、技能差错、直觉与决策差错等问题。因此,在水利工程的整个过程中要特别注重对于人员的安全生产教育,通过解决该风险因素能够有效地解决相关联的风险因素。人员素质因素对操作违规、技能差错、直觉与决策差错都要影响,并且对整个水利工程风险因素体系中的大部分因素都有联系。因此,安全生产教育和人员素质应被视为主要影响水利工程风险体系的核心问题,要预防事故的发生,需要着重解决这两点。
(2)多维度风险因素关联规则方面。人员素质和安全生产教育依然影响较大,此外,安全组织体系和安全管理程序也对班组管理有影响。
4 结 论
本文利用机器学习中的Apriori数据关联算法,对水利工程事故案例数据库进行数据挖掘,得出了风险因素的潜在多维关系,为水利工程事故风险分析提供了重要数据支持。基于事故案例库的数据分析,可知人员素质和安全生产教育对整个风险体系影响较大,同时,利用数据库可以计算出各风险因素之间的潜在关联关系。该计算方法可以弥补灰色与模糊理论只能处理少数据、贫信息分析的缺陷和单因素分析的不足。
猜你喜欢
辽宁大学学报(自然科学版)(2022年1期)2022-04-26
新世纪智能(数学备考)(2021年9期)2021-11-24
建材发展导向(2021年13期)2021-07-28
建材发展导向(2021年11期)2021-07-28
水利建设与管理(2020年5期)2020-06-18
水利规划与设计(2020年1期)2020-05-25
当代陕西(2019年15期)2019-09-02
计算机与数字工程(2018年10期)2018-10-23
学苑创造·A版(2018年11期)2018-02-01
计算机与数字工程(2017年2期)2017-03-02
