
基于TextCNN的文本情感分类系统
2022-06-21 10:08张浩然谢云熙张艳荣
哈尔滨商业大学学报(自然科学版) 2022年3期
张浩然,谢云熙,张艳荣
(1.哈尔滨商业大学 计算机与信息工程学院, 哈尔滨 150028;2.哈尔滨商业大学 黑龙江省电子商务与信息处理重点实验室, 哈尔滨 150028)
近年来,随着电商技术的不断成熟,网购规模的日益庞大,消费者们开始使用在线网购取代线下门店购物,线上购物虽然对于消费者来说更方便快捷,但不同于线下企业可以直接获得消费者当下的购物体验,而要在消费者收货之后将购物体验发表在相关平台后才能获得,这样就导致企业无法直观的获取用户消费偏好意愿作为参考来改善企业自身,提高消费者购物满意度.所以对于消费者发表的在线评论进行分类分析等是十分有必要的.但是对于如今信息量爆炸的时代,用户网购后在线评论数据量十分庞大,很难通过人工手动分类来为在线评论打上好差评标签,故而需要将机器学习方法应用到文本情感分类中,即自然语言处理[1],来对用户在线评论文本进行情感分类,为评论打上标签做进一步的分析预测,通过这些分类分析可以给商家提供更多建议提高企业自身,也能给消费者带来更好的消费体验,更符合消费者网购需求,并提升企业口碑.
目前越来越多的企业平台,包括各种软件下载后等都会向用户弹出请求评论页面,方便获取用户体验反馈评论,来提升企业或软件自身,说明越来越多的商家注重到用户在线评论的重要性,也表明对在线评论的分类需求会越来越多,不仅有利于向商家提供建议,对于消费者来说也可以根据他人发表评论获取商品信息来选择购物.
企业平台后台收集到的评论文本是相当庞大的数据集,尤其是一些大的平台,人工手动打标签分类效率低且容易出错,故可以开发一个系统,输入一条评论文本或者上传一个数据集文件,可测出其情感倾向来为之分类打标签,并且将结果显示在前端反馈给用户,同时可以将用户所测试的数据保存到数据库中,方便以后获取更多数据集来训练分类器模型,以提高分类器模型的准确率.使用这样的系统大大提高了将在线评论情感分类效率,还可以通过不断调试选取合适的模型参数,或选取更优质的数据集,或加大训练集数量,或选取更合适的模型框架来提高分类器的准确率,这样对于在线评论文本情感分类结果也会更准确.若想对文本进行进一步分析等操作的前提就是获取到准确的分类文本,所以开发这样的分类测评系统还是很有必要的.
对于商务企业者来说就更加有必要用到这样的系统对消费者的在线评论文本进行情感分类,根据好评了解消费者的购物偏好意愿,给出更符合消费者心意的推荐;根据差评作出相应改进策略,改善被消费者所指差的地方,提升商务企业的品质口碑.
1 国内外研究现状
文本情感分类是文本分类中的一个重要分支,也叫观点挖掘,换言之,文本的情感分类就是对带有情感色彩的文本进行主观性分析、处理、归纳和推理的过程[2].在线评论(Online Reviews)是指网上购物的消费者在相应的购物网站上购买物品后对购买的产品发表含有个人观点的消费体验[3].与此同时,在线评论依托互联网平台广泛参与的大众性特点,网上在线评论与其他传统信息传媒相比,在增强消费者对企业的信任、提高消费者的购买意愿等方面迅速成为备受国内外研究人员关注的热点[4].文本情感分析研究的方法分为三类: 基于情感词典的方法、基于传统机器学习的方法、基于深度学习的方法[5].
文本情感分析是自然语言处理的主要研究方向之一,近年来越来越多的研究人员倾向于使用卷积神经网络来解决文本情感分析问题,并获得了很好的实验效果[6].在2010年,Mikolov等[7]在Google上发表Word2vec工具,该工具可以够将单词表示为空间词向量,后来建立了一个基于RNN的语言模型,该模型通过上下文信息可以更好的获得最终结果.2014年,Kim[8]首次在多数据集的与训练词向量的基础上,使用卷积神经网络对文本进行分类,取得了比其他深度学习模型更高的准确率.Kalchbrenner等[9]针对具有两层卷积层和池化层的CNN模型,提出了一种动态K-max池化策略,得到每个卷积核中最大的K个特征值,自动构造句子的向量表示,可以处理任意长的句子.Hua等[10]通过使用词性标注、词嵌入word embedding等方法,使用多种类型的池卷积神经网络对句子建模,在卷积池和句子表征方面,采用局部相似度计算来提高性能.
近年来伴随着深度学习的迅速发展,卷积神经网络CNN成为了深度学习的主流算法之一应用于多处领域[11].最初应用于图像识别视觉处理方面,后来也被应用于文本分类自然语言处理方面,并在此方面的应用研究有良好的效果.2018年罗帆等[12]提出一种多层网络H-RNN-CNN,将RNN和CNN结合起来处理中文文本情感分类任务,实验结果表明,该方法对多类数据集都具有良好的效果.2019年杜永萍等[13]提出一种基于CNN-LSTM模型的短文情感分类方法,采用卷积神经网络CNN提取短文本的语义特征,引入长短时记忆神经网络模型LSTM对短文本进行情感倾向预测,与传统的机器学习分类模型相比,该方法检验效果提升显著.
总之就目前深度学习的各个模型,如循环神经网络RNN、卷积神经网络CNN等[14],各类的神经网络已经越来越多的被应用于文本分类情感分析的方面,且效果性能等都明显不错.本文选择使用深度学习的模型,结合Word2vec与CNN应用于文本Text之上做文本情感分类系统.
2 基于TextCNN模型的文本分类研究
2.1 Word2vec词向量方法
在了解Word2vec时先来了解一些其他相关的概念.文本表示,将非结构化数据、不可计算的文本转换为结构化数据、可计算的向量,即转换为计算机可以识别的数据信息[15],如独热编码、整数编码、词嵌入(有两种主流算法:Word2vec和Glove)等等.在词嵌入被开创之前,一般应用one-hot独热编码来处理,这一编码方式简单易理解,有多少个词向量中就有多少列,只有一列为1其余全为0,为1的一列用来区分代表一个词.看起来简单,但只要文本稍一增长,向量同时也会跟着增长,且该序列中只有一个1其余均为0.这样导致该编码方式缺点过于明显,其一不适合长文本含有多个词的,向量过于稀疏且维度过高,带来维度灾难[16],且这样的编码方式存储效率低下,同时还有另一缺点,该编码方式无法表示词与词之间的关系.同理整数编码也和独热编码一样有类似的缺点.而词嵌入相较于上述两种编码方式有更多的优点:1)该方式不会像独热编码一样维度很长,转而通过低维度的向量来表示文本;2)文本中相近词意的在空间上距离也较为相近;3)该编码方式普遍适用性强,用途广泛[17].
本系统所采用的是word embedding算法的其中一种Word2vec,2013年谷歌发明开创的一套词嵌入工具.Word2vec有两种训练模式:1)是CBOW(Continuous Bag-of-Words Model,连续词袋模型),通过上下文来预测当前词,适用小型训练数据;2)是Skip-gram(Continuous Skip-gram Model,连续跳字模型),通过当前词来预测上下文,适合训练大型的数据.上述两者的结构如图1所示.
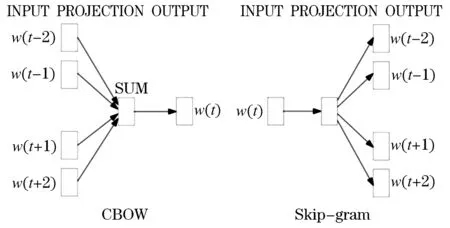
图1 Word2Vec两种训练模型的结构图Figure 1 The structure of the two training models of Word2Vec
由于上述两者训练模型计算量太大,尤其是使用到梯度下降算法时更是会由于求导等不断的加大计算量开销,所以提出两种近似训练法来优化上述两种模型,提高速度减少计算量开销.分别是:负采样(Negative Sample)和层序Softmax(Hierarchical Softmax).Word2vec要比之前的词嵌入方法效果更佳[18],因为其所依赖的模型会考虑上下文关系,且大大减小了词向量维度,速度更快.并且Word2vec适用于各种自然语言处理应用中,有着很强的通用性,其计算词语相似度的效果准确率还是很不错的.Word2vec并非无缺点,但针对本系统采用Word2vec已足够.
本实验分类器模型是结合Word2vec和TextCNN模型实现的[19],因为结合Word2vec工具处理过后的模型准确率会更高.本实验采用Word2vec工具训练数据集分词得到相应的词向量,设置参数词向量维度、上下文最大距离、最小词频等,训练完成后保存好该模型.部分训练后的Word2vec词向量如表1所示.
本实验没有采用CNN模型自带的embedding嵌入层,而是采用word2vec训练的词向量自定义word embedding权重矩阵作CNN模型的嵌入层[20],这样训练出来的分类器模型准确率会更高.
2.2 基于TextCNN模型的分类器方法
本实验所训练TextCNN模型是将CNN模型应用于文本Text之上.CNN结构组成层包括三种:卷积层Convolutional layer、池化层Pooling layer、全连接层Fully Connected layer.卷积层由卷积核filters以及激活函数组成,超参数有卷积核个数、卷积核维度大小、步长stride、padding模式和激活函数的类型选择等[21].选择最大池化还是平均池化,超参数窗口大小等.全连接层即是类似神经网络的单元层,当前单元层的每一个单元都必须和上一个层的每一个单元全部相连接,才能叫做全连接层,也要设置相关的超参数,神经元数量、激活函数等[22].CNN的一个示例如图2所示.其结构描述如下:输入层(X)、卷积层(Relu)、最大池化层、卷积层(Relu)、全连接层(Relu)、全连接层(softmax)、输出层(Y)[23].
该分类器模型若想设计完成,需得先采用Word2vec工具来训练得到相应的词向量,再结合基于Text的CNN模型来设计.系统课题实现的是对在线评论文本的分类,此前已阐述如何将文本转换为计算机可识别的数字序列及Word2vec训练的词向量,之后将CNN模型应用于文本Text分类之中,设计多个不同size的kernel来提取文本关键信息如利用捕捉最强特征[24],来设计实现TextCNN分类器.如图3所示,描述了TextCNN模型的整个流程,本图中对文本进行卷积,卷积核不横向移动而下移(类似N-gram提取关键信息),共有2、3、4三种步长,每个步长有两个卷积核(现实训练卷积核数目可能更多),经卷积后对得到的向量在进行最大池化,再作全连接层,最后得到文本特征,完成分类.
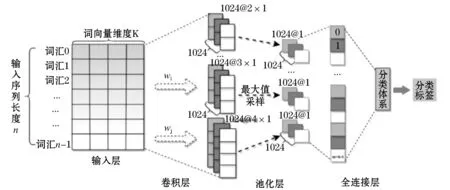
图3 TextCNN模型分类的流程Figure 3 The process of TextCNN model classification
分类器模型没有采用CNN自带的默认的embedding嵌入层,而是采用word2vec训练的词向量自定义embedding的训练权重矩阵,作词嵌入层,这样相比模型的准确率会更高分类效果会更佳.再使用keras框架提供的Sequential顺序模型来实现多个网络层的堆叠,keras实现很多层,如core核心层、卷积层、最大池化层等多种网络层构[25],可以使用add()方法将各个层往模型中添加.本系统训练的分类器步骤如下:
1)添加使用word2vec工具训练后的word embedding作嵌入层.
2)添加卷积层,即文本一维卷积.并选取相应合理的超参,如卷积核数目、步长、padding填充方式、激活函数类型等.
3)添加最大池化层,设置相应超参数.
4)添加卷积层.
5)利用flatten将多维的数据扁平化拉长.
6)为了防止模型过拟合,设置随即的30%的训练集数据不去参与训练.
7)添加全连接层设置相应参数如激活函数类型、神经元的数量等.
8)设置20%的随即数据不参与训练.
9)添加全连接层,激活函数设置为softMax,设置units参数为2表示二分类.
至此添加的网络层与图3所示的CNN示例一致,从理论到训练模型的实践即如此.接下来通过compile配置模型训练之前的学习过程,设置参数损失函数loss为categorical_crossentropy最小化目标函数,优化器optimizer为Adam,并设置相应参数在训练时把模型精确度输出出来,最后用fit函数开始训练模型,训练的两个数据参数分别是之前几节提到过的,x是中文评论文本转换为的数字序列,y是将标签类别转换为的独热编码序列(因为标签只有两类很少,所以用独热编码很方便合理),batch_size设置一次训练条数,设置迭代次数epochs,设置训练集中20%的数据为验证集.最后保存模型h5格式,之后调用模型直接调用即可,无需调用一次需重新训练一次.
将采用Word2vec工具训练得到的词向量,word embedding作训练权重矩阵,作为TextCNN分类器模型的词嵌入层,取代CNN模型默认的embedding层.接着再利用顺序模型逐层添加卷积层、池化层、全连接层等,训练TextCNN模型,其中本分类器模型训练设置参数迭代次数为6,至此分类器模型的训练已经完成.
3 实验结果与分析
3.1 数据集预处理
3.1.1 评论文本预处理
要想实现该分类器模型;1)需要对数据集进行预处理,对数据集中的每条语句进行中文分词(导入jieba中文分词库来进行精准分词lcut)[26],去掉其中标点符号,以及去停用词等,最终得到每条评论语句相应的分词列表,即提取出每条评论语句的关键词;2)采用Tokenizer对数据集中所有分词进行编码,分词词频越大,则编号越小;3)得到数据集的字典后,将数据集中的每条文本数据(每条评论文本对应的分词列表)转换为第二步所得到的编码数字特征;4)先规定最长文本数据长度,再截长补短使得所有样本的长度一致.经过这四步处理的评论文本数据才可以作为模型训练的数据[27].过程如图4所示.
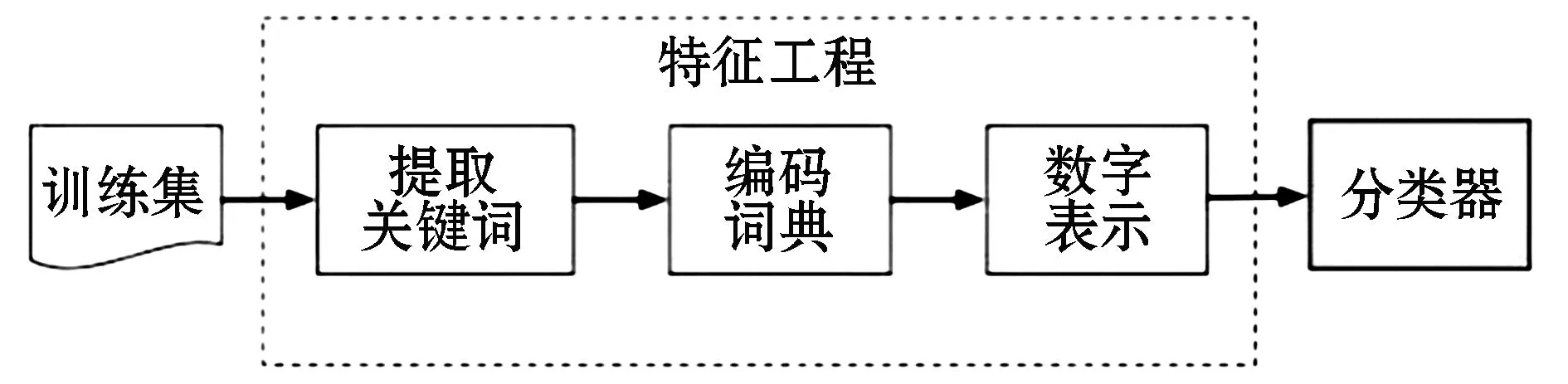
图4 文本预处理过程Figure 4 Text preprocessing process
3.1.2 评论标签预处理
本实验数据集的评论标签只有两类,Positive正面评论以及Negative负面评论.由于标签只有简单的两类,所以利用one-hot独热编码处理标签数据是最高效简洁的.处理结果即为Positive对应转变为[0. 1.],Negative转变为[1. 0.].经过此处理的评论标签数据才可以作为模型训练的数据[28].
3.2 实验数据
本实验的评论语料来自CSDN博客的博主收集整理并公开发布在博客中的中文购物评论,其中包括训练集40 000多条,测试集3 000多条.对每一条评论人工标注其情感倾向标签,有积极评论(Positive)和消极评论(Negative)两类标签.打好标签后,将数据集随机进行打乱以保证模型训练效果更好.部分实验数据如表2所示.

表2 部分实验数据Table 2 Part of the experimental data
3.3 评论情感分类结果及分析
1)基于上述研究方法获得评论情感分类结果,部分测试集评论及分类结果如表3所示.

表3 部分评论及分类结果Table 3 Part of comments and classification results
2)评价指标
本文采用准确率(Accuracy)、损失(Loss)两个指标作为模型的测评指标,如公式(1)和(2)所示:
准确率跟正类负类没多大关系,表示在预测结果中,正确预测的数量 / 样本总数,公式为:
(1)
损失函数采用交叉熵损失函数(categorical_crossentropy)公式为:
(2)
3)评论情感分类结果及分析
本文所采用的模型效果优劣通过训练过程中不断迭代时训练集、验证集的准确率及损失值所展示,如表4所示;以及检验在测试集数据上的损失值及准确率来判定,如表5所示.
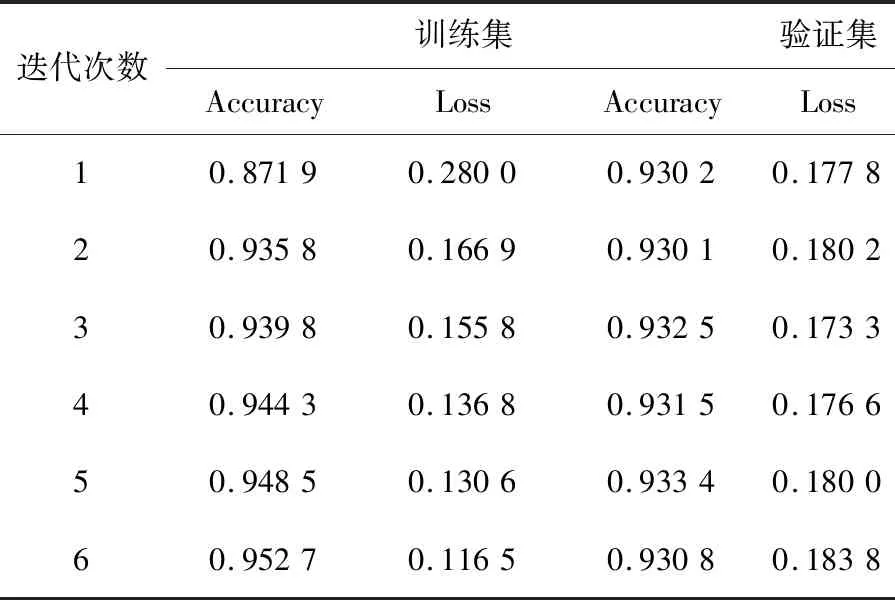
表4 训练过程中训练集、验证集数据的准确率及损失值Table 4 Accuracy and loss values of training set and validation set data during training

表5 测试集数据上测评的准确率及损失值Table 5 The accuracy and loss value of the evaluation on the test set data
从表4模型训练过程输出训练集与验证集的准确率以及损失值来看,每次迭代准确率基本在0.9以上,说明模型的准确率是较高的,该模型训练效果是不错的.再从表5在测试集数据上的准确率与损失值来看模型优劣,对比训练集验和证集的相应值基本保持在统一范围内,也说明该模型的训练效果是较为不错的,准确率也基本稳定与0.9以上.
数据表格的形式测评分析不如图像显示直观,故作折线图,以折线图的形式直观的显示本实验所用训练集和验证集集的准确率与损失值对比.如图5所示,通过对图5的分析,可以发现,虽然模型的准确率基本在0.92以上,损失值基本在0.17以下,但训练集与验证集相比出入是略有差别的,所以本分类器模型也并不是极佳,还有待提升,提高模型准确率,降低模型损失,优化模型.
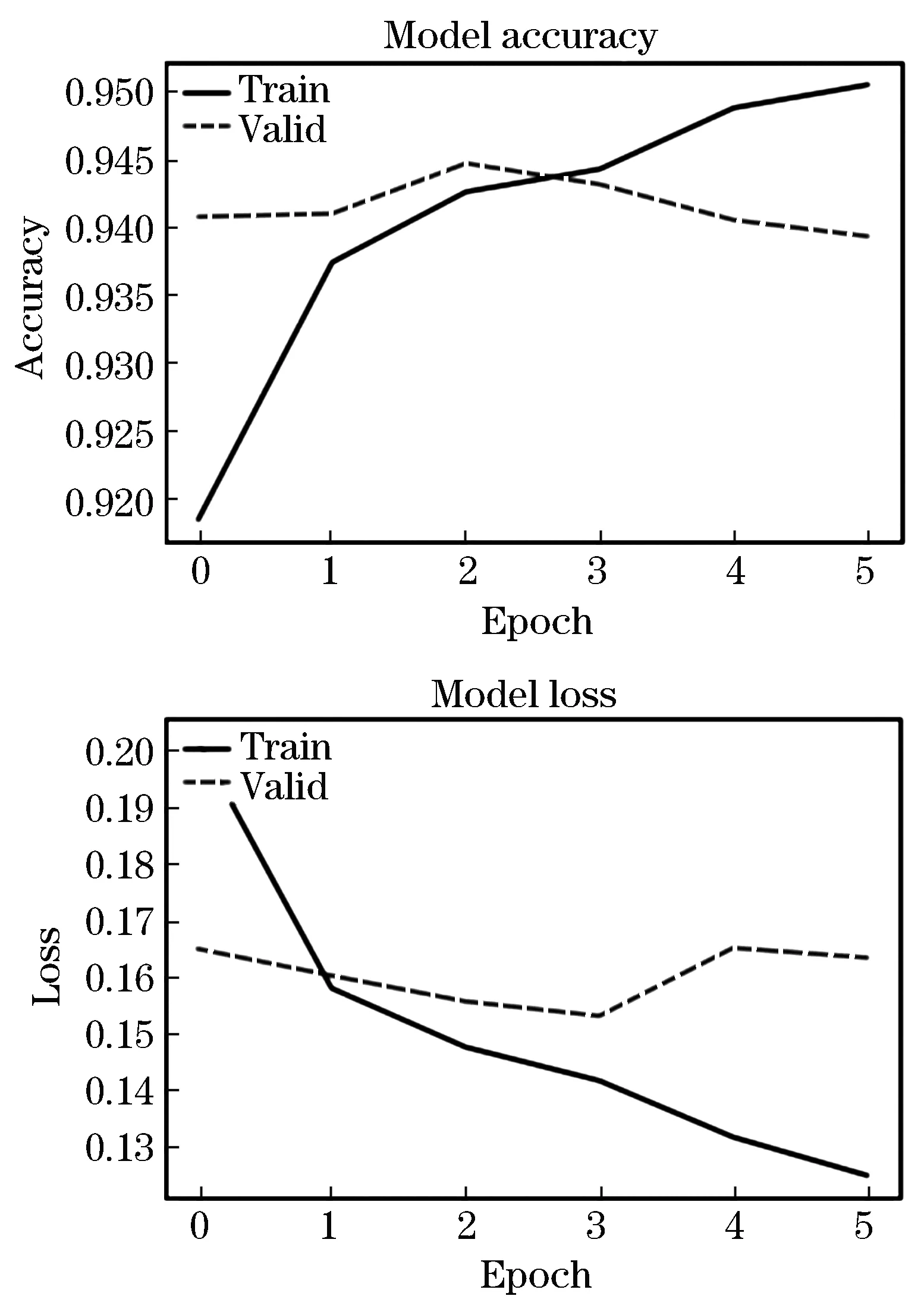
图5 模型准确率与损失Figure 5 Line chart of model accuracy and loss
基于TextCNN做出的文本情感分类系统部分效果如图6.

图6 系统部分效果展示Figure 6 Part of the system effect display
4 结 语
本文是基于TextCNN的文本情感分类模型,采用Word2vec和TextCNN模型结合来设计情感分类模型,相较于仅使用CNN模型实现的分类器而言,使用Word2vec工具训练处理后的词向量,再采用TextCNN模型训练得到的分类器模型,其准确率会更高、效果更佳.模型的训练需要大量的数据集来支持,若训练集太小则模型的准确率及效果可能会很差.本系统使用互联网公开发表在GitHub上的数据集来训练模型,训练集数据约40 000条,测试集约3 000条.由于数据集较大,经过不断调试设置合理的模型参数,分类器的准确率较高,基本在0.9以上.模型在测试集上测评的准确率为0.94,说明分类器模型的泛化能力较好.训练模型完成之后将其保存成h5文件格式,后续可以使用直接调用该模型,否则每调用一次模型就需重新训练一次,耗时耗力.
本文中模型仍然存在许多不足之处,从本文情感分类模型训练过程和对模型结果的测评分析可以看出,该模型损失值较大且准确率并非很高,分类结果也并非完全准确不会出错.说明该模型还是有很多需要改进的地方,可以继续调试选取更适合的参数来训练模型,也可以寻取更优质的数据集来训练模型,又或者是考虑选取其他神经网络模型来训练分类器模型.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
计算机系统应用(2021年2期)2021-02-23
