
农业文本语义理解技术综述
2022-06-21 08:20吴华瑞王郝日钦黄素芳
农业机械学报 2022年5期
吴华瑞 郭 威 邓 颖 王郝日钦 韩 笑 黄素芳
(1.国家农业信息化工程技术研究中心, 北京 100097; 2.北京市农林科学院信息技术研究中心, 北京 100097;3.农业农村部数字乡村技术重点实验室, 北京 100097; 4.北京市农林科学院智能装备技术研究中心, 北京 100097;5.沧州市农林科学院, 沧州 061001)
0 引言
目前互联网农业知识资源平台众多、信息量巨大且更新迭代快,但涉农资源整合程度较低、农业服务过程的质量较差,普遍存在农业专家/知识/技术进村下乡访达不及时、科技资源匹配不精确、技术服务标准不统一的问题,致使农民通过信息化手段获取有效的农业知识困难。为提升农业知识服务的范围、质量和效率,通过人工智能面向农业赋能是有效的方法之一,特别是随着计算机算力的提升,自然语言处理技术得到了空前发展,其中语义理解技术在知识服务方面应用最为广泛,目前在法律[1]、医学[2]、旅游[3]、农业等垂直领域主要是通过构建领域语料库并针对具体任务组合或改进通用模型,实现分析及处理方法的迁移,在局部语料中得到可观的效果,并以智能问答、知识百科、信息检索等形式进行综合应用,在实际场景中得到验证。

图1 农业文本语义理解主要技术框架Fig.1 Framework of agricultural text semantic major technology
语义理解技术的发展分为3个阶段。第一阶段是基于规则的语义理解。主要是根据语言学理论建立语义生成的规则,描述各种语义成分及成分之间的结构关系和意义关系。发展至今,以专家系统为代表在农业知识服务领域已经取得了较显著成果[4-6],根据领域专家知识推理和判断,模拟人类决策过程,以解决农业生产复杂问题。但是基于规则产生的方法对知识需求量极大,增加了成本和复杂性,且难以根据知识更新而学习。第二阶段是基于统计学的语义理解。主要利用机器学习的思想通过计算的手段利用经验来改善计算系统自身性能,先由专家事先根据任务目标对文本进行标注,并将这些文本作为训练语料,让机器学习标注特征。其中K近邻、贝叶斯、支持向量机[7]、隐马尔科夫链在文本语义分类、命名实体识别方面取得较好的效果。第三阶段是基于神经网络的语义理解。深度学习本质上是一种特殊的机器学习,主要通过嵌套的概念层次来表示并实现巨大的功能灵活性,增加了运算层数,表现更为抽象,能够对语义数据进行表征学习,建立类似人脑的神经网络,模仿人脑的机制解释数据。特别随着LSTM[8]、Transformer、BERT等模型相继提出以及在农业领域的应用,加上迁移学习、知识蒸馏等学习方式与性能优化模型的熟化,将基于深度学习的语义理解推至一个新的高度。
在中英文语义理解任务中,二者最大的区别在于英文单词天然存在空格,可以非常容易的进行分词,而中文词间不存在区分符,且由多个字构成,所以中文文本的语义理解任务首先需要将文本进行分词。其次是词性差异,英文存在冠词和助动词,有助于语义的理解,因此,相较于英文,中文语义理解存在更大的难度。
农业领域语料的特殊性决定了面向农业知识时处理方法的差异,目前有关学者针对农业生产、加工、销售、技术服务等环节的知识服务开展了一系列的研究和应用,如基于知识图谱的农业品种、栽培、病虫害等知识百科,代替农业专家的智能问答机器人,农业标准化生产辅助决策系统等[9-15]。为了深入分析面向农业文本的语义理解技术和语义分析服务在农业领域当中的应用场景,如图1所示,本文对农业知识图谱、农业文本表示、农业文本分类等主要技术的发展加以总结和概括,对农业语料库、语义理解在农业领域的应用进行分析与阐述。
1 农业文本语义理解技术
农业文本语义理解技术从底层的农业知识存储、中间层的农业文本表示以及顶层的农业文本分类,实现了农业文本的人工智能理解全过程。其中,知识图谱是农业语义知识结构化智能存储的主要方式,通过对复杂的农业文本数据进行知识的抽取、融合、表示、推理,转化为全面表达领域知识信息的“实体-关系-实体”的三元组,实现知识的可视化表示。除此之外,还需要对人类的文字转化为计算机能够理解和计算的数据类型,则需要通过文本的表示技术,将文本数据通过词嵌入(Word embedding)方法在文本空间内进行向量化的表示。形成可计算的文本向量后,计算机将载有文本特征的向量映射到多个类别上的过程,即为文本分类。
1.1 农业知识图谱
知识图谱的本质是一种语义网络,它是一种实体-关系-实体的三元组表示形式,2012年由Google[16]提出,最初是通过其大规模的知识表达网络来优化搜索引擎,提高搜索质量以及用户使用体验。目前,随着人工智能技术的发展,众多的智能应用、智能服务相继涌现,知识图谱逐渐开始被应用于智能搜索、知识百科、智能问答、个性化推荐、辅助决策等方面。用户搜索不再通过简单的关键词模糊匹配,而是对用户搜索内容进行语义分析理解,推理用户的实际意图,使搜索结果更具有逻辑层次,更符合用户的意图。
农业大数据存在多源异构的特点,数据分散无序,知识图谱能够有效拼接知识碎片信息(图2),在农业大数据融合中起到关键的作用,但现有的知识图谱对知识的覆盖不完整,并且依赖人工进行大量数据的标注,使知识图谱在农业中的应用服务面临困难。

图2 农业知识图谱表示Fig.2 Demonstration of agricultural knowledge graph

图3 知识图谱技术路线图Fig.3 Technology roadmap of knowledge graph
如图3所示,农业知识来源主要包括表格、文本、数据库等。按照数据类型分为结构化数据、非结构化数据和半结构化数据。结构化的数据(表格、数据库等)可以直接用来构建知识图谱。非结构化的数据(文本、音频、视频、图像等)、半结构化数据则需要预先进行知识抽取,再经过知识融合,利用知识表示技术,构建可视化的知识图谱。除此之外,通过知识推理能够获得新的知识,对现有的知识图谱进行迭代更新,使知识图谱更加完善。农业领域知识图谱的研究主要集中在知识抽取、知识融合、知识表达、知识推理等方面。
1.1.1知识抽取
知识抽取是从不同来源、不同结构的数据中提取知识,形成结构化数据存入到知识图谱的过程。包含实体抽取、关系抽取、属性抽取3方面的内容,它可以克服农业领域数据存在存储的分散性和结构的不统一性问题,受到了越来越多的关注。早期的农业知识抽取[17]是基于规则的,需要具有专业知识的专家进行人工编写三要素的抽取规则,然后通过模式匹配的方式进行实体、关系、属性的挖掘,时间成本和人力成本巨大,且农业领域本体知识众多,本体之间关系复杂,不同时空条件下相同本体拥有各异的属性,导致人工编写实体抽取规则的可扩展性较差。
针对上述问题,多项研究提出了自动化和半自动化的农业领域知识抽取方法。BiLSTM是目前最主流的知识抽取模型,也是知识抽取冷启动的基础模型,加入CRF之后,利用其状态转移矩阵来约束错误的标签,可以使模型的F1值有明显的提升。宋林鹏等[18]提出基于神经网络的词向量+BiLSTM+CRF的农业实体提取方法,实验证明该方法具有更好的特征抽象能力和更高的农业实体识别精度,减少了对人工特征定义的依赖。
BiLSTM模型存在长序列前端语义稀释导致信息丢失,引入注意力机制,通过生成不同的语义向量,使注意力集中在问题的关键部位,忽略次要部分,可有效地解决问题。赵鹏飞等[19]提出在BiLSTM+CRF的基础上,通过注意力机制(Attention)获取不同语境下的实体标签,以构建农业实体识别模型,该研究解决了传统的农业命名实体识别方法对人工特征标注依赖性强、语义特征信息提取不全、实体名称不统一等问题。
BERT是采用Transformers进行特征提取的深度双向预训练语义理解模型,能进一步提升语义模型的效果。袁培森等[20]采用BERT模型对特征向量的训练实现了对水稻表型7类实体关系抽取。李悦[21]、吴赛赛等[22]将BERT与BiLSTM CRF相结合,进行结构化、非结构化数据的半自动知识抽取、知识融合,并运用Neo4j进行知识存储,实现了农业病虫害知识的抽取和知识图谱的可视化表达。
BERT+BiLSTM+CRF模型在农业知识抽取任务上取得了巨大的进展,但是由于网络结构庞大,参数众多,模型训练、运算耗时较长。李亮德等[23]结合知识蒸馏方法,以BERT-ALA+BiLSTM+CRF为教师模型,以BiLSTM+CRF为学生模型进行模型的蒸馏,进行农业实体抽取模型的训练,该方法解决了人工特征标注的低精确度问题,减少了深度神经网络复杂度和参数量,实现了低延迟、高精度的农业实体识别。
知识抽取对于农业知识图谱的构建具有重要的意义,同时也面临着巨大的挑战。近年来,预训练语言模型的性能得到很大程度的提升,加上深度迁移学习的发展,预训练模型到农业领域模型的迁移训练变得更加高效。随着注意力机制、Transformer、知识蒸馏等技术的提出,基于弱监督学习的农业知识智能抽取技术,得到了快速发展,已逐渐替代了基于规则的知识抽取方法,实现对语义特征、实体信息的高效提取。
1.1.2知识融合
知识融合是对不同数据源进行整合,使知识库、知识图谱的实体信息更加全面具体的技术,它包括了本体对齐、实体对齐、实体消歧、记录链接、本体匹配,其本质都是从多源信息中将相同的本体、实体进行融合。目前,国内外研究机构依据不同农产品、不同时空范围、不同生产加工流程,构建了大量的农业领域相关的知识图谱,而因为传统知识对齐等工作的人工投入成本巨大,因此始终未能形成统一的大规模农业知识图谱,亦未能实现对数据的有效利用。因此,自动、批量化的知识融合研究对于农业大数据的整合、数据资源的利用、农业决策模型的开发等具有重要的意义。实体链接是通过实体识别技术对文本中的实体进行检测,将其对应信息与知识图谱中对应实体进行链接,并加入到已有的知识图谱/知识库中,实现知识图谱智能融合的技术。夏迎春[24]在构建病虫害知识图谱的过程中,提出基于主题模型与实体链接算法(Entity linking algorithm based on topic model and graph, ELTMG),通过构建候选实体集、构建实体相关图、计算最优链接实体3个步骤进行知识库融合,在AGDISTIS算法的基础上F1值提升了5.2%,获得了更好的知识库融合的效果。创建大型知识库方面尚缺少跨库融合应用,大多研究仍在处理特定的小样本知识阶段。
现阶段,随着NLP技术的发展,知识融合在中文、英文等单语言的知识图谱中已获得了较好的应用成效,但在多语言的知识谱图融合上还有待研究和探索,成为未来知识融合的一个重要方向,将世界不同语言不同国家的开源知识库整合,打通语言限制,实现知识的世界范围共享。
1.1.3知识表示
要运用知识图谱中的信息,需要借助知识表示。农业知识表示的内容是农业生产经验、自然规律等,以本体为核心,以RDF三元组为框架,表达实体、标签、属性、关系等多层语义关系。农业上对知识表示开展了多项研究,主要采用逻辑表示法、框架表示法、语义网等方法进行农业知识的描述。
卢山[25]对产生式表示法、逻辑表示法、框架表示法、面向对象表示法、语义网表示法进行比对分析,结合玉米收获机割台设计知识的特点,采用本体描述语言OWL进行知识表示,实现了对玉米收割台知识间复杂关系清晰的形式化表达。张熔[26]通过对各种方法的对比分析,根据水稻领域知识的复杂特征,采用框架表示法实现了基于语义的水稻病虫害知识表示。苑超[27]通过Hadoop分布式计算框架运行水稻领域知识语义网,实现了云端的语义表达、查询和推理,具有快速准确的优势。
合理优化设计知识表示方案,能更好地表达关系复杂的多维度农业信息,能决定下游的知识推理和上游的知识获取的形式和难度。因此,知识表示对农业知识图谱的构建和应用都有至关重要的作用。
1.1.4知识推理
知识推理是通过已有知识推断出未知知识的过程。知识图谱中的推理主要针对实体关系进行推理,能够辅助推理出新的事实、新的关系、新的公理以及新的规则,并以此对知识图谱进行补全。知识推理主要基于逻辑规则、图结构、分布式表示、神经网络等方法。在农业领域,基于逻辑规则的农业知识推理研究较为普遍。
李雪梅[28]构建了农业科技信息资源本体,借助Jena推理机和推理规则,提出农业科技信息资源本体的语义推理框架,实现了农业信息资源的有效推理。杨金桂[29]通过Cloud-OWL构建云本体,对茶园气象知识进行表示,采用语义网规则语言SWRL构建推理规则,结合描述逻辑推理和语义推理进行农业云本体的语义推理,建立基于云本体农业知识服务,实现农业领域不确定性知识的高效复用。
目前,知识推理主要以提升规则挖掘效率和准确度为目标,农业领域大多数研究都采用基于规则的推理方法,而人工的规则制定对专家知识、人力及时间的消耗巨大,而随着深度网络技术的日益成熟,神经网络代替基于规则和图的推理将是未来研究的发展方向。
1.2 农业文本表示
文本表示是自然语言处理中的基础工作,文本表示的性能直接影响到整个自然语言处理系统的性能。文本向量化就是将文本表示成一系列能够表达文本语义的向量,是文本表示的一种重要方式。传统方法是通过构建语义词典,比较两个词拥有同义词或者上位词集的相似性来判断语义是否相似,常见的有WordNet[30]、Probase[31]等,但构建词典存在人力物力消耗巨大、覆盖范围有限、无法及时更新的问题,垂直领域构建难度过大,应用较少;独热表示法(One-hot representation)将单词表现成一个与词典大小一致的特征向量,将只有单词对应的位置设为1,其他位置均为0,由于该方法本质上是一个词袋模型,不考虑词与词之间的顺序,且存在特征离散稀疏问题,对噪声非常敏感;HARRIS[32]在1954年提出分布假说理论,说明出现在相同上下文的词语语义相似,并由FIRTH[33]在1957年进行了更加明确的阐述,词的语义由其上下文刻画,依据该假说的词向量表示分为基于矩阵的表示、基于聚类的表示和基于神经网络的表示。HINTON等[34]在1986年提出分布表示,通过训练将某种语言的每一个词映射到一个固定长度的短向量,根据词间距离判断语法、语义相似度。随着算力的提升,基于神经网络的深度学习技术在自然语言处理中逐渐占据主流,典型的包括C&W模型[35]、CBOW模型[36]、Skip-Gram模型、基于负采样的模型等。
在传统的基于机器学习的文本分类方法中,独热表示法是一种常用的文本表示方法。该方法将文本中的每个单词表示为一个向量,其维度是预处理后的文本中词汇的数量。但是,这种方法有明显的局限性。一方面,如果整体数据较大,词汇表中包含大量单词,则文本向量维数会过高,严重影响计算效率。另一方面,one-hot忽略了上下文的语义信息,造成了严重的信息丢失。为了克服上述缺陷,HINTON提出了词嵌入的概念。词嵌入是一种分布式表示。该方法的主要思想是将单词从高维空间映射到低维空间,解决了向量稀疏性问题。而映射到低维空间后,不同词对应的词向量之间的位置关系反映了它们的语境语义信息。为了更快、更有效地训练词嵌入,MIKOLOV提出了两种神经网络语言模型:CBOW和Skip-Gram。CBOW是根据上下文预测当前的单词,而Skip-Gram是根据当前的单词预测上下文。2017年,华盛顿大学团队开发了一种基于3层双向LSTM的语境嵌入模型ELMo,它具备捕获上下文信息的能力,比Word2Vec效果表现更加优秀。2018年,OpenAI开始使用Transformer构建嵌入模型,是谷歌开发的一种新的神经网络架构。Transformer完全基于注意力机制,大大提高了TPU上大规模模型训练的效率,第一个模型称为GPT。同年,谷歌开发了基于双向变压器的BERT。BERT使用33亿个单词进行训练,是目前最先进的嵌入模型。使用更大模型和更多训练数据的趋势仍在继续。OpenAI最新的GPT-3模型包含1 700亿个参数,谷歌的GShard包含6 000亿个参数。
近年,在农业领域常见的文本表示模型有TF-IDF、Word2Vec、BERT等。
1.2.1TF-IDF
词频-逆文件频率(Term frequency-inverse document frequency, TF-IDF)[37]是一种用于资讯检索与资讯探勘的常用加权技术,也是一种非常有效的特征提取算法。TF-IDF是一种统计方法,用以评估字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF方法可保留文本中具有代表性的低频词语,去除区分度低的高频词。
在农业文本处理领域,魏芳芳等[38]利用选择好的特征词进行 TF-IDF 权重计算建立相应的文本表示模型,用于衡量该特征词的重要程度。使用已经编号的类别和特征向量,对每个文档计算TF-IDF值,然后通过特征选择、特征项权值计算处理,最后采用SVM 算法获得农业文本分类器,实现了中文农业文本的精确自动分类,准确率达到了95.6%,召回率达到了96.4%。杜亚茹等[39]将浅层句法分析等语言学方法与TF-DIF和C-value等统计学方法相结合进行概念抽取;在分类关系抽取时,基于目标本体的已知一个分支,采用余弦距离计算概念与已知分支概念的语义距离,并结合概念之间的共现频度来确定层次及上下位关系。与目前中文本体的代表性方法相比,文中提出的方法在查全率和查准率方面有明显的提高。郑丽敏等[40]针对传统的 TF-IDF 没有考虑特征词对类间分布状况影响的问题,在 TF-IDF 中引入特征选择效果较好的卡方统计量(Chi-square, CHI)方法进行修正。利用改进的特征加权处理方法提高分类精度,使 FSE_ERE 方法在高质量的食品安全事件新闻文本中完成实体关系抽取工作。段青玲等[41]将 TF-IDF方法优化及改进,进行特征项权重计算。该方法不仅考虑特征词在整个语料集中的重要程度,而且考虑特征词在各个类别之间以及各个类别内的差异性。采用基于信息熵的方法对每个类别分别提取热词候选词,最后采用基于时间变化的方法进行候选词热度计算,根据候选词热度排序结果得到热词。该方法能够有效地提取农业热词,为不同农业用户群体发现和分析产业热点提供帮助。
TF-IDF的优点是简单快速,而且容易理解。缺点是有时候用词频来衡量文章中的一个词的重要性不够全面,有时候重要的词出现的可能不够多,而且这种计算无法体现位置信息,无法体现词在上下文的重要性。为了体现词的上下文结构,Word2Vec算法应运而生。
1.2.2Word2Vec
Word2Vec可以提供一个高效的实现,即架构连续字包(CBOW)和Skip-Gram来计算字的向量表示,这些表示可以用于语言中的各种任务处理。CBOW架构根据上下文预测当前单词,而Skip-Gram架构预测单词围绕当前给出的单词。Word2Vec在给定上下文中具有相似含义的单词显示出很近的距离,从而理解并向量化文档中单词的含义。图4为MIKOLOV提出的Word2Vec学习算法CBOW和Skip-Gram的模型架构。由输入层、投影层和输出层3部分组成,它们的输出过程不同。输入层接收W(t)={W(t-2),W(t-1),W(t+1),W(t+2)}作为参数,其中Wt表示单词。投影层对应于多维向量的数组,并存储多个向量的总和。输出层对应于从投影层输出向量结果的层。具体而言,CBOW类似于前馈神经网络语言模型(NNLM),并预测来自其他词向量的输出词。CBOW的基本原理是通过分析相邻单词来预测某个单词何时出现。CBOW的投影层将所有单词投影到同一位置,因此,所有单词的向量保持平均值并共享所有单词的位置。CBOW的结构展示了统一组织分布在数据集中的信息的优势。相反,Skip-Gram展示了一种从一个单词预测其他单词向量的结构。Skip-Gram的基本原理是预测某个单词周围出现的其他单词。Skip-Gram的投影层插入到输入层的单词周围的相邻单词。跳转图的结构显示了当新单词出现时矢量化的优势。根据MIKOLOV的研究,当数据量较大时,CBOW比Skip-Gram更快、更适合学习,而Skip-Gram在学习新单词时比CBOW表现出更好的性能。然而,其他比较CBOW和Skip-Gram性能的研究表明Skip-Gram的性能超过了CBOW。

图4 CBOW和Skip-Gram架构Fig.4 Framework of CBOW and Skip-Gram
在农业领域,研究者针对农业文本所具有的特性,使用Wod2Vec对农业文本进行向量化处理,王郝日钦等[42]根据水稻文本具备的特征,采用 Word2Vec 方法对文本数据进行处理与分析,能够有效地解决文本的高维性和稀疏性问题,并结合农业分词词典对文本数据进行向量化处理,然后使用注意力机制和密集连接的卷积神经网络提取文本特征,解决了农业问答社区中水稻提问数据快速自动分类的问题。赵明等[43]针对问答系统对用户问句的语义信息有较高要求的特点,首先利用Word2Vec 将句子中的词转换为具有语法、语义信息的词向量,利用训练得到的词向量和BIGRU神经网络进行问句分类模型的训练,实现了对番茄病虫害问句的快速自动分类。陈瑛等[44]采用Word2Vec中的Skip-Gram模型进行训练,得到每个词的向量表示,采用Lucene全文检索架构和长短期记忆神经网络(Long short-term memory,LSTM)构建了食品安全自动问答系统。金宁等[45]运用TF-IDF算法拓展文本特征,采用 Word2Vec方法的 Skip-Gram 模型训练分词结果,将中文词语转换为低维、连续的词向量。为进一步突出不同词语对问句含义的贡献程度,将词语的 TF-IDF值与Word2Vec词向量的乘积作为该词语的加权词向量。然后构建混合神经网络模型进行多粒度的特征提取,实现了农业问答社区中农业问句的精确快速分类。
1.2.3BERT
Word2Vec产生的词向量是静态的,不考虑上下文信息。而一些词语往往存在一词多义的现象,因此在文本向量化过程中需要的不仅仅是一个词到向量的映射,而应该学习一个考虑上下文的模型,BERT预训练模型相比于Word2Vec为代表的词嵌入方法,突出的进步就是更动态,能解决一词多义的现象。
BERT (Bidirectionalencoder representations from transformers)文本预训练模型作为文本向量化转化工具获得文本特征表示,既能获得文本语义特征,又能解决Word2Vec忽略一词多义的现象。BERT使用Transformer中的编码器作为特征提取器,这种方法对上下文有很好的利用,不需要像BiLSTM那样双向堆叠。配合MLM这样的降噪目标在大规模语料上进行训练,根据特定领域任务进行微调,具有良好的效果。
BERT是一种遮蔽语言模型,在获取词向量的过程中随机遮蔽一些词语,然后在预训练过程中在原始词汇的位置进行预测。对于BERT 模型的输入,每一个词语的表示都由词语向量、段向量和位置向量共同组成, 其中,标记[CLS]代表一个句子的开始,标记[SEP]代表一个句子的结束。如图5所示。

图5 BERT文本输入示例Fig.5 Demonstration of input text of BERT
在农业文本处理领域,研究者使用BERT模型在农业语料库上进行训练,取得了良好的效果。杨国峰等[46]对问句数据集进行预处理,分别构建双向长短期记忆自注意力网络分类模型、Transformer 分类模型和基于BERT的微调分类模型,并利用3种模型提取问句信息,进行问句分类模型的训练。实验结果表明采用基于 BERT 的微调常见作物病害问句分类模型,其分类准确率、精确率、召回率、精确率和召回率加权调和平均值分别高于双向长短期记忆自注意力网络模型和 Transformer 分类模型2~5个百分点。袁培森等[20]获取水稻表型组学数据,并进行标注和分类;随后,提取关系数据集中的词向量、位置向量及句子向量,基于双向转换编码表示模型(BERT)构建水稻表型组学关系抽取模型;最后,将BERT模型与卷积神经网络模型、分段卷积网络模型进行结果比较。结果表明,在3种关系抽取模型中,BERT模型表现更佳,精度达95.11%、F1 值为95.85%。王郝日钦等[47]为了解决问答社区中相同语义问句文本的快速自动检测,提出一种基于 BERT 的Attention-DenseBiGRU的农业问句相似度匹配模型。针对农业文本具备的特征,采用12层的中文 BERT 文本预训练模型对文本数据进行向量化处理,并与 Word2Vec、Glove、TF-IDF方法进行对比分析,得出 BERT 方法能够有效地解决农业文本的高维性和稀疏性问题,并且解决多义词在不同语境下具有不同含义的问题。
为减少不必要的算力消耗,扩展使用场景,以BERT为基础的轻量模型应运而生,包括利用知识蒸馏技术的DistilBERT[48]、AlBERT[49]和TINYBERT[50],通过减少预训练模型的参数降低模型的复杂度,在文本向量化可达到显著提高文本向量化的效果。
1.3 农业文本分类
文本分类主要包括文本特征的提取和分类模型的训练。在基于机器学习的文本分类方法中,特征提取和分类模型是两个完全独立的过程。传统的特征提取方法需要人工提取特征,提取过程复杂,准确率较低,经过优化和改进,研究者在传统的机器学习农业文本分类上取得了突破。魏芳芳等[38]通过构建农业行业关键词库、特征词选择和权重计算,构建SVM农业文本分类模型,模型准确率达96.5%。段青玲等[51]基于SVM对自动抓取的农业Web数据进行文本分类,实现了农业信息的自动采集和分类,分类准确率达到92.5%。杜若鹏等[52]在TF-IDF的基础上引入卡方检验值,通过特征词频因子修正,利用朴素贝叶斯算法进行农业科技文献文本分类,取得了94%的平均准确率。而与传统方法相比,基于深度学习的文本分类特征提取是通过多层复杂的人工神经网络特征提取得到的,可以达到更高的准确率、更快的训练速度和更强的解释性。
近年来,学者们已经将文本分类的重点从传统的机器学习转移到人工神经网络。人工神经网络能够从复杂的原始数据中提取抽象的层次特征,并具有很强的非线性映射能力。使用神经网络进行文本分类的优点之一是不需要在特征提取和选择上花费大量的时间,并且将单词的分布式表示作为特征输入到网络中。然后,神经网络可以自动提取有价值的信息用于文本分类任务。目前,基于深度学习的文本分类模型有很多,包括基于CNN的文本分类模型、基于RNN的文本分类模型以及基于注意机制的文本分类模型。
1.3.1基于CNN的文本分类模型
卷积神经网络是一种多层复杂的神经网络结构,在图像识别领域,WANG等[53]提出了基于深度CNN的CAPTCHA识别方法。PAN等[54]提出了一种基于CNN的食物识别算法。此外,PAN等[55]也将CNN与农产品相结合,提出了一种针对农产品的疾病监测系统。在文本分类领域,KIM[56]将CNN与自然语言相结合,提出了一种有效的文本分类方法。使用带有卷积层的CNN进行文本分类,并比较了不同的方法,如随机初始化、预处理词嵌入、静态输入矩阵和动态输入矩阵,最后得出静态输入矩阵分类效果最好的结论。KALCHBRENNER等[57]提出了一个类似的模型,称为动态卷积神经网络(Dynamic convolutional neural network, DCNN)。与KIM提出的CNN方法不同,DCNN包含5个卷积层和多个临时k-max池化层,k-max池化层从一系列卷积滤波器中提取k个顶点值,并确保输出长度是固定的。HUANG等[58]将字符级卷积网络进行中文的文本分类实证研究,证明了字符级卷积网络可以达到具有竞争力的分类效果。由于CNN和RNN在计算机视觉领域的结合已经取得了很好的效果,所以XIAO等[59]在句子分类方面将RNN和CNN结合,使用了一个5层的卷积网络提取高级文本特征,这些高级特征也被用作LSTM的输入。
在之前的文本分类中,CNN使用了一种简单的架构。由于浅层CNN只能在限制窗口大小的情况下提取局部特征,CONNEAU等[60]提出了一种深度的CNN来提取文本分类中的分层局部特征。它们的卷积层深度达到了29。该模型在8个免费的大规模数据集上实现了稳定的性能。这是第一次证明深度对卷积神经网络的性能有提升。类似地,JOHNSON等[61]提出了一种深度金字塔卷积神经网络(Deep pyramid convolutional neural network,DPCNN),该网络细致研究了单词级CNN的深度。这种新型的DPCNN结构能够有效地提取远程关联的特征,获得更多的全局信息。首先,该模型输入一句话到文本区域嵌入层,该层使用单词嵌入为句子中的每个单词生成向量表示。接下来是两个卷积块的叠加和一个快捷方式。他们将特征映射的数量固定为250个,内核大小固定为3个。利用预激活的Wσ(x)+b和身份映射的快捷连接使能深度网络训练。下采样可以有效地表示文本中更多的全局信息。在该模型中,下采样的步长为2。该方法利用无监督嵌入训练文本区域嵌入,提高了文本区域嵌入的精度,减少了训练时间。
然而,大多数基于CNN的方法使用固定的窗口大小,因此无法提取可变的n-gram特征。WANG等[62]提出了一种具有多尺度特征的密集连接CNN,提取可变n-gram特征用于文本分类。密集连接之所以能够在上下游卷积块之间创建快捷路径,是因为将较小尺度的特征组合成大尺度的特征,从而产生可变的n-gram特征。虽然基于CNN的方法在提取可变n-gram特征方面发挥了很大的优势,但它们只关注局部连续词序列,而忽略了语料库中的全局词共现信息。此外,CNN提取的局部语义特征也暴露出了其冗余性的缺点。YAO等[63]提出了一种用于文本分类的新型图卷积网络(Graph convolutional network, GCN)。GCN可以捕获文档和词的关系,以及全局词共现信息。
在农业领域,研究者们针对农业特定领域研究卷积神经网络在农业文本分类的应用,张明岳等[64]提出了一种基于卷积神经网络的农业问答情感极性特征抽取分析模型,结合农业分词字典,利用批规范后的卷积神经网络对数据集进行训练。实验结果表明,该方法能够准确识别测试样例集中的冗余队列,首次提出了一种农业文本二分类的解决方案。冯帅等[65]根据上述农业文本二分类的卷积神经网络模型,对卷积神经网络模型进行了优化,提出基于深度卷积神经网络的水稻知识文本分类方法,采用优选出的 4 层残差模块结构作为基本结构,使用胶囊网络(Capsule network,CapsNet)替代其池化层,设计了水稻知识文本分类模型,能够实现准确、高效的水稻知识文本分类。提出了一种水稻文本四分类的解决方案。金宁等[45]为了解决农业文本多分类问题,提出了一种农业文本十二分类的解决方案,利用双向门控循环单元神经网络获取输入词向量的上下文特征信息,构建多尺度并行卷积神经网络,进行多粒度的特征提取,实验结果表明,基于混合神经网络的短文本分类模型可以优化文本表示和文本特征提取,能够准确地对用户提问进行自动分类。
1.3.2基于RNN的文本分类模型
递归神经网络(RNN)将双向递归结构引入神经网络,解决了输入信息之间的相互关系问题。RNN在对文本序列进行顺序建模时具有很大的优势。文本分类的主要应用模型是双向递归神经网络(Bidirectional recursive neural network, BRNN),是由SOCHER等[66]提出的。双向递归结构假设当前输出与前面的信息和后面的信息相关,这些信息可以捕获全局的长期依赖关系。因此,RNN在文本分类方面具有多变量模型。长短期记忆网络(LSTM)是RNN的一种改进,可以解决长期依赖问题。LSTM通过门结构对cell状态进行删除或添加信息来更新每一层的隐藏状态。TANG等[67]提出了门控循环网络模型来学习句子的语义及其上下文关系,首先通过CNN或LSTM学习文本表示,然后利用门控循环神经网络结构,将句子的语义及其关系编码成文本表示。LAI等[68]设计了更复杂的网络结构,提出了一种递归卷积神经网络(RCNN),将RNN与CNN结合,使用双向LSTM来获取每个单词的上下文表示。
在农业领域,研究者针对农业特定领域研究循环神经网络在农业文本分类的应用,赵明等[69]为了对番茄病虫害智能问答系统用户问句进行高效分类,构建了基于Word2Vec和双向门控循环单元(Bi-directional gated recurrent unit,BIGRU)神经网络的番茄病虫害问句分类模型。针对问答系统对用户问句的语义信息有较高要求的特点,利用训练得到的词向量和BIGRU神经网络进行问句分类模型的训练。结果表明,在2 000条番茄病虫害数据集上,采用BIGRU的番茄病虫害问句分类模型,可以快速准确的进行番茄病害和番茄虫害的二分类。赵明等[70]为了对饮食文本信息高效分类,相比于上述文献的数据集,构建了48 000条饮食文本数据集,建立一种基于Word2Vec和长短期记忆网络的分类模型。由Word2Vec构建文本向量作为LSTM的初始输入,训练LSTM分类模型,自动提取特征,进行饮食宜、忌的文本分类。利用该方法能够高质量地对饮食文本自动分类,帮助人们有效地利用健康饮食信息。梁敬东等[71]构建一个基于Word2Vec和LSTM神经网络,包括输入层、嵌入层、LSTM 层、全连接层和输出层的句子相似度模型。构建的模型显著提升了句子相似度计算的准确率,基于该模型开发的水稻 FAQ 问答系统,能够准确匹配用户问题和水稻 FAQ 中的问题,帮助农户更好地解决水稻生产中遇到的问题。首次在农业文本领域,将深度学习模型与农业文本相似度进行结合。
1.3.3基于注意力机制的文本分类模型
CNN和RNN在文本分类任务中可以取得很好的结果,但它们的缺点是不够直观,可解释性不佳。因此研究者在上述架构的基础上加入了注意力机制。注意力机制是自然语言处理领域中常见的长期记忆机制模型。与CNN和RNN最大的不同是,基于注意力机制的方法可以直观地呈现每个单词对结果的贡献。DU等[72]提出了一种新的注意模式,将RNN和基于CNN的注意模型结合起来。该方法首先利用卷积运算获得注意力信号,每个注意力信号代表一个词上下文的局部语义信息;然后使用RNN来创建带有注意力信号的文本。一个词的注意力权重越高,它所包含的信息就越有价值,在文本构建过程中就越重要。ZHOU等[73]也提出了一种基于注意力的双向长短期记忆网络(Att-BLSTM)。该模型最大的优点是将神经网络注意机制与BILSTM相结合,捕捉句子中最重要的语义信息。MA等[74]提出了Global-local mutual attention (GLMA)模型,该模型优点是能够有效地捕获局部语义特征,有效地解决全局长期依赖关系。相互注意机制包括局部引导的全局注意和全局引导的局部注意。局部引导的全局注意保留全局长期依赖的有用信息,全局引导的局部注意提取最有用、信息量最大的局部语义特征。YANG等[75]也提出了基于RNN的分层注意网络(Hierarchical attention network, HAN)模型,可以解决文本长期依赖的问题。该模型在句子级和文档级增加了注意机制,对高度重要的内容分别表示不同的权重。它可以缓解RNN获取文档序列信息时的梯度消失问题。然而,HANs的训练速度要慢得多,因为它们利用了RNN。GAO等[76]提出了一种分层卷积注意力网络(Hierarchical convolutional attention network, HCAN),这是一种基于自注意力机制的结构,可以在RNN这样的长序列中捕获语义关系,也可以在文本分类任务中实现像CNN那样的快速和准确性能。实验还表明,基于自注意力机制的模型可以取代基于RNN的模型,在降低准确率的情况下减少训练时间。在农业领域,王郝日钦等[42]对卷积神经网络(CNN)上下游卷积块之间建立一条稠密的链接,并结合注意力机制(Attention),使文本中的关键词特征得以充分体现,使文本分类模型具有更好的文本特征提取精度,从而提高了分类精确率。
2 语料库
语料库的构建是所有语义分析处理的前提,大规模、高质量的语料以及知识库构建结构与可扩展性决定着语义理解技术面向农业领域任务能否实现和达到效果。
2.1 大规模通用语料库
通用型语料库体量庞大,在大型科技公司服务过程发挥重要作用,表1收录了常用的开源通用语料库信息,如基于知识工程构建的FreeBase,谷歌提出的知识图谱是该知识库典型应用,基于语义网构建的DBpedia,融合维基百科和专家知识;国内院校及科技公司构建了北京大学CCL语料库、哈尔滨工业大学同义词林、搜狗互联网语料库SogouT等。由于自然语言的表达方式相对一致,跨行业语料处理具有泛化性,在农业语义理解研究过程中,部分处理方式是基于大型语料库的处理而迁移获得,如:对农业文本分类、知识抽取等任务。
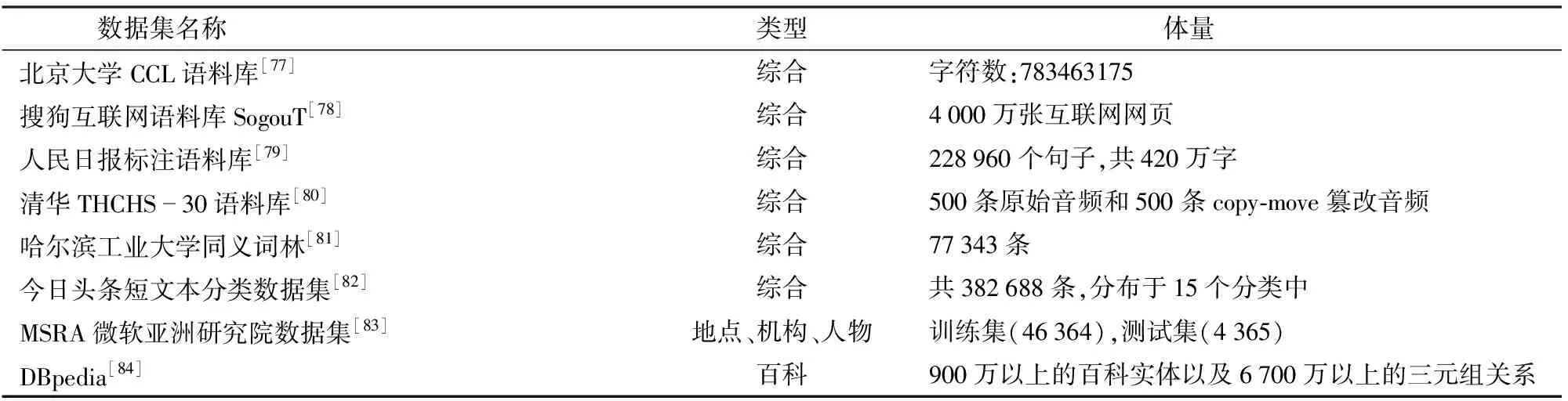
表1 自然语言语料信息Tab.1 Natural language corpus information
2.2 农业领域语料库
由于通用语料库中垂直领域文本数据量有限,针对性不强,大部分情况下无法解决农业特定领域的问题,影响语义服务的精确度。因此,农业科研工作者在问答系统构建、模型训练过程中,通常需要针对实际情况构建特定领域语料库,如表2所示,农业领域目前公开的有农作物品种、农作物病虫害、农业技术服务等类型的知识库。

表2 农业垂直领域语料Tab.2 Agricultural vertical corpus
随着深度学习领域的发展,图像、文本、视频等多媒体处理边界逐渐呈现模糊化的形式,学习模型也逐渐呈现多任务处理的形式,因此语料库构建逐渐从单一类型的语料向多模态发展,如图像-文字语料库、视频-文字语料库。
3 语义理解在农业领域应用
3.1 农业智能问答
20世纪90年代之后,随着互联网的发展,数据的获取变得简单,检索式的问答技术快速发展,基于逻辑推理、模板匹配、机器学习、数据冗余性的方法相继被提出,根据问句的浅层语义去检索答案。但是检索式的问答存在答案和问题需要存在共同关键词的局限性,随着百科类网站的兴起,高质量结构化的数据获取更加方便,大量知识库被建立起来,加上机器学习技术的兴起,推动了基于知识库的问答系统研究。在农业领域,智能研究起步较晚,2007年前后,才开始出现基于本体、知识库的农业智能问答的研究[91]。
知识库问答(Knowledge base question & answering, KBQA)是以自然语言的形式给出问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。基于知识库的农业智能问答是充分利用知识库中的数据解决问题的一项重要研究任务,其实现过程分为问题分析、文本信息检索、答案生成3个模块[92],基本架构如图6所示。

图6 基于知识库问答系统基本架构Fig.6 Framework of Q&A system based on knowledge base
随着知识图谱的提出和普及,越来越多的学者将注意力放到知识图谱的农业问答系统研究中,在本体层的基础上构建数据层,利用知识图谱将结构化和非结构化的数据进行数据抽取、融合,形成一种具有语义的知识库,更好地表达实体之间的关联性,实现实体间的上下文会话识别与推理,为智能问答的应用提供了新的知识管理途径。夏迎春[24]构建了基于 Neo4j数据库的农业病虫害知识图谱,提出基于主题模型与图的实体链接算法,并设计研发作物病虫害知识问答系统,实现了农业病虫害知识问答。为了丰富数据源,提高泛化性,吴茜[93]收集了农作物数据、农作物病害数据和农药产品数据,通过 Protégé 工具构建了农业知识图谱,然后提出多特征的条件随机场命名实体识别算法和基于双向长短期记忆网络的属性链接方法,实现了交互式农业知识问答系统。
农业知识图谱用于理解问题的深层语义信息,满足用户的精细化需求,对实现农业知识智能化服务、农业信息化发展有一定的意义,但对于语义复杂、开放性问题则难以准确回答用户。研究开放检索生成式问答方法,通过模型训练最终生成合适的答案,对于农业问答系统的答案自动生成具有重要指导意义。王郝日钦等[47]构建的基于BERT-Attention-DenseBiGRU的神经网络,采用中文BERT预训练模型对3万对农业问答数据进行训练,获得农业问句的向量化表示,并输入DenseBiGRU和协同注意力机制模型,提取不同粒度的农业文本特征,得到适用于农业文本相似度的神经网络参数,问答匹配精确率达到了97.2%,实现农业问句相似度的精确判断,满足了农业问答社区的需求。张明岳等[64]采用卷积神经网络模型对8 000条农业问句文本信息进行特征提取及分类,经过不断迭代的训练之后,得到了用于判断农业无效问句的神经网络参数。实现了农业问答文本特征抽取的任务,准确率达到了82.7%。金宁等[45]对12个类别的20 000条农业问句进行分类,采用TF-IDF与Word2Vec相结合的方法对农业问句进行向量化处理,然后构建了基于BiGRU与多尺度并行的卷积神经网络模型进一步提取农业问句语义特征,模型准确率达到了95.9%,实现了准确的农业问句分类,满足农技问答社区的需求。此外,WANG等[94]采用Albert+Match-LSTM农业问答语义分类匹配方法,通过注意力机制和卷积核引入使准确率达到96.9%,大大降低了模型时间复杂度。
3.2 农业语义检索
搜索引擎在互联网信息检索中发挥着主导地位,信息检索已成为从海量信息资源中获取知识并解决问题的主要途径。随着互联网上的信息指数级增长,农业信息也随之快速膨胀,传统的关键词匹配检索筛选信息不聚焦,搜索结果查全率低,排序依据不足。语义分析可以解析用户意图,突破关键词查询的局限性。因此,基于语义的检索方法已逐渐成为农业领域检索研究的热点。
现阶段,农业领域的语义检索主要是基于本体以及基于用户行为习惯两方面开展研究。基于本体的语义检索[95-99]在构建农业垂直领域本体库的基础上,标注本体信息,确定搜索词句和本体之间的相似、相关度,以此为据对候选搜索结果进行排序;基于用户行为的语义检索[100-102]在通过计算本体相似度的基础上加入了用户行为习惯、时间遗忘曲线等多维参数,对用户的搜索意图进行辅助定位,增加检索的准确率。特定本体库的优势在于能清晰表达领域知识的概念、结构、关系,形成具有一定结构化的数据字典工具,在这样的工具中进行检索可以使结果精度更高。要实现一个集成度高、覆盖面广、综合性强的农业全域检索方法或系统,需要构建一个大型的本体库,传统方法需要投入大量的专家资源进行人工标注和构建,难度较高,目前国内外尚未形成此类成果。因此,现阶段自动构建本体在农业领域成为研究热点,借鉴知识图谱中知识抽取相似技术,通过基于自然语言规则的模型,抽取、分析本体概念间的潜在关系,实现本体库的自动构建,但现在的研究成果离优良的理解性还有很大的差距,随着研究的不断深入,知识蒸馏、迁移学习、注意力机制、Transformer等技术的提出,这种现状有望得到改善。
3.3 农业管理决策
农业管理决策语义服务能够帮助农民收集和整合生产所需的信息,通过分析提供最佳的决策方案,为农民增收致富提供技术支持,有利于提高农业生产的产量和质量。传统的决策系统通常是人工录入条件和决策数据,将用户的条件因子与系统数据库中的条件进行匹配,选取对应最匹配的解决方案,而农业的地区化、多样化导致人工录入的数据耗时耗力,且覆盖面不全,难以满足广大农业生产者的需求。近年来,越来越多的学者将语义技术引入农业决策支持系统中,通过语义理解整合互联网、物联网数据以及已有专家系统、书籍中的生产管理信息,智能化匹配用户需求,生成个性化的精准生产管理决策方案。
现阶段面向农业管理决策语义服务的研究主要可以归纳为基于语义网和语义本体两类。语义网是互联网信息实时共享的最新发展,提供了一种通用机制,允许跨不同应用程序、企业和社区共享数据,孙想等[14]、NASEEM等[103]利用农业语义网技术,构建农业生产决策系统,克服农业多源异构数据整合困难,解决生成决策方案不准确的问题。另一方面,王艺等[104]、WANG等[105]、韩乐[106]通过构建语义本体,结合专家知识,利用农作物生长信息及气象因子,为管理人员提供综合信息服务和辅助型决策,实现异构、多源农业信息的整合,开发本地化的农业资源,为个体农户提供个性化、主动的信息决策服务,为种植业、养殖业等生产过程提供科学指导依据。不论是基于语义网还是语义本体,农业智能决策系统通过对农业文本的语义分析,形成适应复杂生产环境的农业生产管理决策模型,辅助农民决策及实时诊断调控,可以减少农业生产成本和环境污染,提高经济效益。
4 展望
语义理解技术已经广泛应用到农业知识服务领域,移动终端的广泛使用也提升了用户对农业问题精准答案的需求。在现有研究成果的基础上,总结农业语义理解研究领域的重点问题和发展趋势,认为该领域还存在如下具有挑战性的研究内容。
(1)针对农业数据源标准化程度低的问题,面向互联网数据、专家知识数据、农业百科数据等,建立农业语义数据表达方式统一化过滤机制,构建统一标准的知识库,从而解决数据爆炸、存储滥用等问题。
(2)农业文本信息的标注方式仍然以人工辅助标注为主,需要大量的监督,耗时费力,半监督或者无监督的模型成为主要发展方向之一。降低语义理解模型处理的复杂度,提升模型处理的效率,根据农业知识服务应用的实际情况,结合终端处理性能提供边缘计算或者经过蒸馏后的模型,提升模型的普适性,近而全面服务基层农业科技人员和农民。
(3)对于多模态语义处理问题,进一步研究集成图像-文本、视频-文本以及多模态组合内容的分析机制,通过统一维度的映射与模型构建,完成复杂语义的处理。
(4)农业知识库构建完毕,面向社会提供全天候实时服务,避免垃圾信息、违规信息的注入对知识库数据安全提出新的要求,其安全贯穿在模型训练、模型预测以及服务整个过程中,此外,知识的获取途径的版权问题需要同步考虑,通过系统规则以及法律约束的方式需并行实施,也可尝试利用区块链等防篡改技术。
(5)面向农业知识的跨区域服务,基于人工智能语义的翻译需求逐年提升,包括我国不同民族间的相互翻译、国际语言的翻译,其核心实现方式是通过系统化工程组合,将任务处理模型与翻译模型相互融合。
随着算力的提升、自然语言处理技术的发展及移动网络技术的快速升级,面向农业知识的智能化服务势必会有更加广阔的发展空间与应用价值。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
新城乡(2018年6期)2018-07-09
长江学术(2015年1期)2015-02-27
中国报道(2009年12期)2009-01-15
