
基于多通道注意力机制的图像超分辨率重建网络
2022-06-21 07:11张晔刘蓉刘明陈明
计算机应用 2022年5期
张晔,刘蓉,刘明,陈明
(1.华中师范大学 物理科学与技术学院,武汉 430079; 2.华中师范大学 计算机学院,武汉 430079)(∗通信作者电子邮箱lium@mail.ccnu.edu.cn)
基于多通道注意力机制的图像超分辨率重建网络
张晔1,刘蓉1,刘明2*,陈明1
(1.华中师范大学 物理科学与技术学院,武汉 430079; 2.华中师范大学 计算机学院,武汉 430079)(∗通信作者电子邮箱lium@mail.ccnu.edu.cn)
针对现有的图像超分辨率重建方法存在生成图像纹理扭曲、细节模糊等问题,提出了一种基于多通道注意力机制的图像超分辨率重建网络。首先,该网络中的纹理提取模块通过设计多通道注意力机制并结合一维卷积实现跨通道的信息交互,以关注重要特征信息;然后,该网络中的纹理恢复模块引入密集残差块来尽可能恢复部分高频纹理细节,从而提升模型性能并产生优质重建图像。所提网络不仅能够有效提升图像的视觉效果,而且在基准数据集CUFED5上的结果表明所提网络与经典的基于卷积神经网络的超分辨率重建(SRCNN)方法相比,峰值信噪比(PSNR)和结构相似度(SSIM)分别提升了1.76 dB和0.062。实验结果表明,所提网络可提高纹理迁移的准确性,并有效提升生成图像的质量。
图像超分辨率重建;纹理迁移;注意力机制;一维卷积;密集残差块
0 引言
图像超分辨率(Super-Resolution, SR)[1]重建是利用一组低质量、低分辨率(Low-Resolution, LR)图像来产生单幅高质量、高分辨率(High-Resolution, HR)且拥有自然和逼真纹理的图像,在监控设备、卫星图像和医学影像等领域都有着重要的应用价值。图像SR研究通常以两种模式进行,包括单图像超分辨率(Single Image Super-Resolution, SISR)[2]和基于参考的图像超分辨率(Reference-based image Super-Resolution,RefSR)[3]。随着深度学习的快速发展,以卷积神经网络为代表的学习法已经被广泛应用于图像超分辨中来构造高分辨率图像。Dong等[4]首先将三层卷积神经网络引入到图像SR中,提出了基于卷积神经网络的超分辨率重建(Super-Resolution using Convolutional Neural Network, SRCNN)方法,该网络通过非线性映射直接学习低分辨率图像与高分辨率图像间的关系,相较传统方法改进效果显著。Kim等[5]提出了一种通过递归监督和跳跃连接的深度递归卷积网络,该网络模型使用递归神经网络,并用更多的卷积层增加网络感受野。与此同时,由于注意力机制[6]在建模全局依赖关系以及降低无关图像域特征信息上表现出良好性能,注意力机制逐渐进入大众视野:Wang等[7]提出了一种残差注意力网络,使不同层注意力模块可以充分学习;Hu等[8]对特征通道间的相关性进行建模来强化重要特征;Lu等[9]通过通道注意机制自适应地调整通道特征。但传统SISR方法在HR图像降级到LR图像的过程中纹理遭到破坏,从而导致恢复出的图像模糊。
与传统SISR不同,RefSR通过提取参考(Reference, Ref)图像的纹理来补偿LR图像中丢失的细节,从而使生成的HR图像拥有更详细和逼真的纹理。例如,Zhang等[10]提出了一种基于神经纹理转移的超分辨率(Super-Resolution by Neural Texture Transfer, SRNTT)模型,SRNTT在特征空间中进行局部纹理匹配,然后通过深度模型将匹配的纹理转移到最终输出;Yang等[11]提出一种用于图像超分辨率的纹理迁移网络(Texture Transformer network for image Super-Resolution, TTSR),TTSR鼓励通过LR图像和Ref图像进行联合特征学习,通过注意力机制发现深层特征对应关系,以传递准确的纹理特征。然而,这些模型在恢复纹理过程中,会出现人脸扭曲、纹理恢复不真实等问题。
为解决上述问题,受文献[12]中的ECA(Efficient Channel Attention)注意力机制思想启发,本文提出了一种基于多通道注意力机制的图像超分辨网络(image Super-Resolution network by multi-Channel Attention,SRCA)。与当前大多数RefSR方法相比,SRCA可以更好地恢复图像细节。
本文的主要工作包括:
1)将多通道注意力机制与纹理搜索模块相结合,通过一维卷积实现局部跨通道的信息交互,对输入图像的每一个特征通道赋予不同的权重,关注提取更重要的特征信息,以利于特征重用。
2)纹理恢复模块引入密集残差块来提升模型的结构,去除密集残差块中的批量归一化层,并使用了残差缩放来恢复部分高频细节,产生优质的重建图像。
1 本文方法
1.1 网络结构
本文SRCA模型的网络结构如图1所示,由纹理提取模块、纹理搜索模块、纹理迁移模块、纹理恢复模块四部分构成。F(特征)表示提取特征图,Q(查询)、K(键)和V(值)表示纹理迁移网络内部注意力机制的三个基本元素,LR为输入图像,Ref、Ref↑↓分别为参考图像以及参考图像经过4倍双三次插值上下采样的图像,LR↑为输入图像经过4倍双三次插值上采样后的图像。Ref、Ref↑↓、LR↑三种图像作为输入,经过纹理提取模块进行特征提取[13],然后纹理搜索模块将提取出的图像特征进行定位,使参考图像纹理特征可以更精确地转移至输入图像中。定位后的纹理、分布位置与输入图像特征图一同输入至纹理迁移模块进行纹理整合形成纹理分布图,最终与纹理恢复模块的输出图像结合生成高分辨率图像。

图1 SRCA模型的网络结构Fig. 1 Network structure of SRCA model
1.2 纹理提取模块
纹理提取模块所提取出的特征质量对模型泛化能力有至关重要的影响。本文模型在VGG19网络[14]中加入多通道注意力机制(Efficient Channel Attention, ECA)来提升特征提取的效率与质量。在预先训练VGG19网络进行特征提取前添加多通道注意力机制,可以对每一个特征通道赋予不同权重来提升特征提取效果、增强表现力。
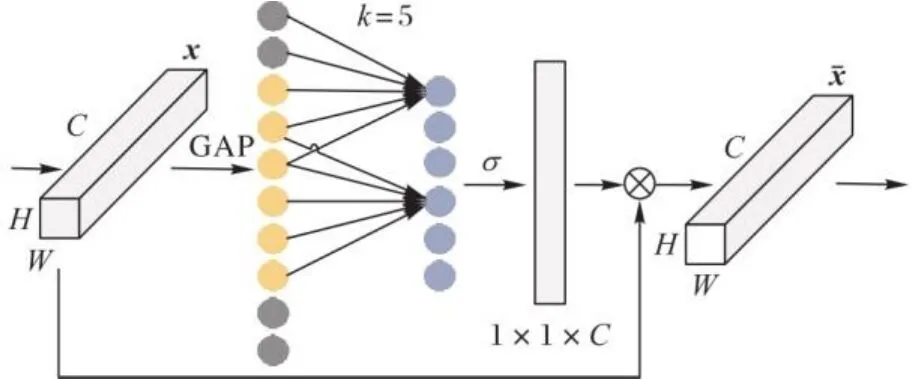
图2 多通道注意力机制结构Fig. 2 Multi-channel attention mechanism structure
VGG19网络中运用relu1_1、relu2_1和relu3_1作为多个比例的纹理编码器。为了加快匹配过程,本文仅在relu3_1层上进行匹配并将对应关系投影到relu2_1和relu1_1,这样可以在减小计算量的同时保证纹理迁移的准确性。K与Q表示仅提取Ref↑↓与LR↑图像的relu3_1层特征,V表示提取Ref图像relu1_1、relu2_1和relu3_1三个层上的特征。
1.3 纹理搜索模块
纹理搜索模块通过比对K、Q之间relu3_1层特征来确定输入图像与参考图像之间纹理的相关性。首先,将K、Q的输出作为输入,通过归一化内积来计算它们的相似性,如式(1)所示:
1.4 纹理迁移模块
纹理迁移模块将参考图像的HR纹理特征转换为LR图像的特征,提高纹理生成过程的准确性。该模块使用跨尺度集成方式进一步对纹理进行堆叠融合,将relu1_1、relu2_1和relu3_1三个层上对应的三种缩放比例(1×、2×、4×)纹理特征进行跨尺度特征融合,从而改善纹理扭曲等问题。利用为索引,针对提取转移HR纹理特征,如式(3)所示。表示每个位置的已转移纹理特征的置信度,最后将LR图像的HR纹理特征和LR特征进行合成,并将这些特征进一步按元素分别乘,以获得纹理迁移模块的输出。
1.5 纹理恢复模块
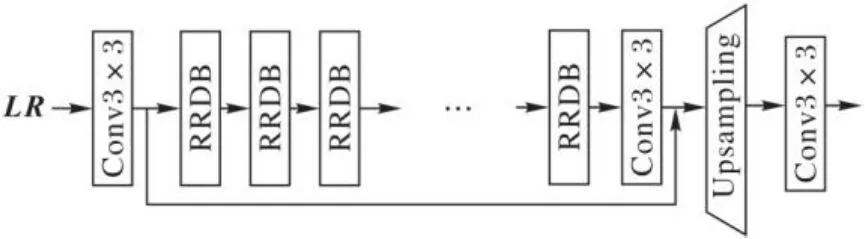
图3 纹理恢复模块Fig. 3 Texture recovery module
RRDB采用比SRGAN(Super-Resolution Generative Adversarial Network)原始残差块更深层和更复杂的结构。RRDB结构如图4所示,残余缩放参数为0.2。纹理恢复模块通过调整残余缩放参数,自适应调整融合纹理信息,使本文模型在纹理细节转移与高频细节生成方面得到有效改善。
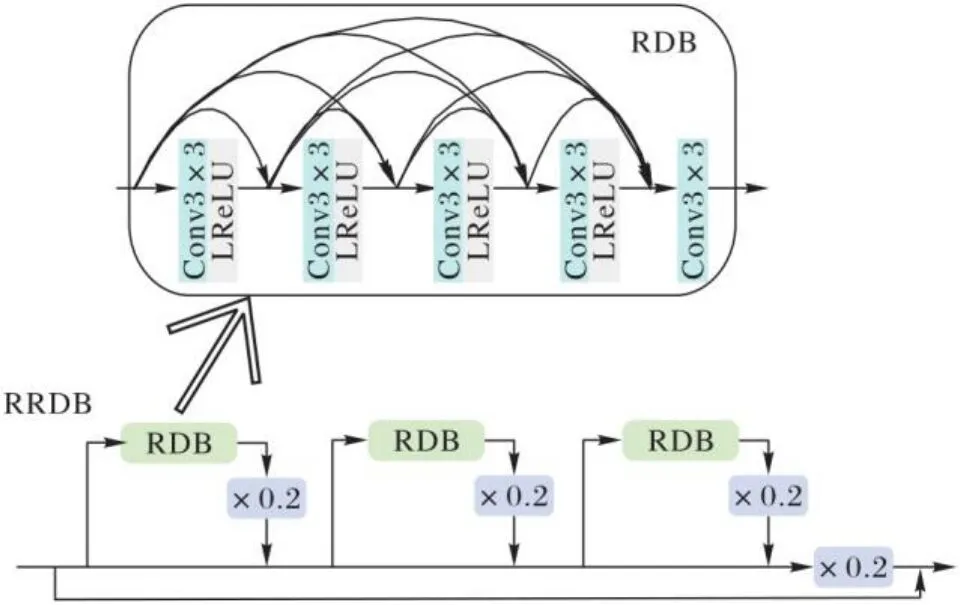
图4 RRDB模块Fig. 4 RRDB module
纹理恢复模块输出图像与纹理迁移模块输出图像相加即为本文模型最终输出图像,如式(4)所示:
1.6 损失函数
损失函数可以起到衡量模型性能优劣的作用。为了保留LR图像的空间结构、改善生成图像的视觉质量以及充分利用Ref图像的丰富纹理,本文用到重建损失、对抗损失与感性损失三种损失函数。重建损失在大多数的SR方法中都有用到,对抗损失与感性损失可以提升生成图像的视觉质量。
重建损失通常以均方误差(Mean Squared Error, MSE)衡量来提高峰值信噪比(Peak Signal-to-Noise Ratio, PSNR)。本文采用L1范数,与L2范数相比,L1范数可以使权值稀疏,方便特征提取,性能更敏锐,收敛快速。重建损失可以用式(5)表示:
其中:(C,H,W)是HR图像的大小;表示HR图像;表示生成的SR图像。
对抗损失可以显著提高生成图像的清晰度以及视觉质量,本文采用WGAN-GP(Wasserstein Generative Adversarial Network with Gradient Penalty)。WGAN-GP提出了梯度惩罚来解决训练过程中的梯度消失和梯度爆炸问题,并且比WGAN(Wasserstein Generative Adversarial Network)更快地收敛,能生成更高质量样本。对抗损失可以用式(6)~(7)表示:
感知损失已经被证明能够显著改善视觉质量,它通过比较对原始图像的卷积输出和生成图像的卷积输出来计算损失。本文的感知损失可以用式(8)表示:
2 实验与结果分析
本文所使用的平台是CentOS 7.4操作系统,双核Intel 2.2 GHz CPU,64 GB内存,Tesla V100 GPU,32 GB内存和4 TB硬盘,并在基于GPU版本的Pytorch 1.1.0深度学习框架下训练本文模型。在训练过程中,的权重系数分别设置为1、1E、1E,并采用Adam[15]对网络进行优化,设置批量数大小是9,设置学习率为1E。首先对网络进行了两轮预训练,其中仅应用了;然后,所有损失都需要再训练200轮。
2.1 数据集
为了测试本文模型是否具有可行性,在最近提出的RefSR数据集CUFED5[10]上训练与测试模型,其中:训练集包含了11 842对图片,每对分别由一张输入图像与一张参考图像组成;测试集包含126组图片,每组分别由一张HR图像和四张参考图像组成。为了对网络进行充分训练,本文用三种方式对训练数据进行增强:1)将图片旋转90°、180°和270°; 2)将图片水平、垂直翻转;3)将LR图像处理为像素,将Ref图像处理为像素。
为了评估SRCA在CUFED5数据集上的泛化能力,本文在CUFED5[10]、Sun80[16]、Urban100[17]和Manga109[18]数据集上均进行了模型测试。其中:Sun80数据集包含80个自然图像,每个图像都包含了多个参考图像与之配对;Urban100数据集包含了100张不带参考的建筑图像,由于建筑图像相似度较高,因此设置LR图像作为参考图像,以便进行纹理的搜索与转移;Manga109包含109张没有参考图像的漫画图像,所以在此数据集中随机抽取HR图像作为参考图像。
2.2 结果分析
为了评估本文模型的有效性,将本文的SRCA模型与其他最新的SISR和RefSR方法进行比较。SISR方法包括近年来在PSNR和结构相似度(Structural SIMilarity, SSIM)上均取得了最先进性能的SRCNN[4]、MDSR(Multi-scale Deep Super-Resolution system)[19]、RDN (Residual Dense Network)[20]、RCAN(Residual Channel Attention Network)[21]、SRGAN[22]、ENet(Efficient neural Network)[23]、ESRGAN(Enhanced SRGAN)[24]、RSRGAN(RankSRGAN)[25]。RefSR方法采用目前最先进的三种方法:CrossNet[26]、SRNTT[10]、TTSR[11],其性能远优于以前的RefSR方法。所有实验均按4倍比例放大系数来对LR和HR图像进行定量评估。为了公平比较每个模型性能的优劣,按照TTSR中的设置来训练所有方法。在测试过程中,对抗训练在SR方法中可以获得更好的视觉质量,但是相对来说会减小PSNR和SSIM。针对此问题,本文中训练了另外一个仅针对重建损耗进行优化的模型版本SRCA_rec,以更公平地比较PSNR和SSIM。
对SRCA进行了定量评估与定性评估,结果如表1所示。通过表1可以看出,SRCA在Urban100和Manga109数据集上具有最佳性能,在CUFED5、Sun80上SRCA可实现与最新模型相当的性能。在基准数据集CUFED5上的结果表明所提网络与经典的SRCNN方法相比,PSNR和SSIM分别提升了1.76 dB和0.062。
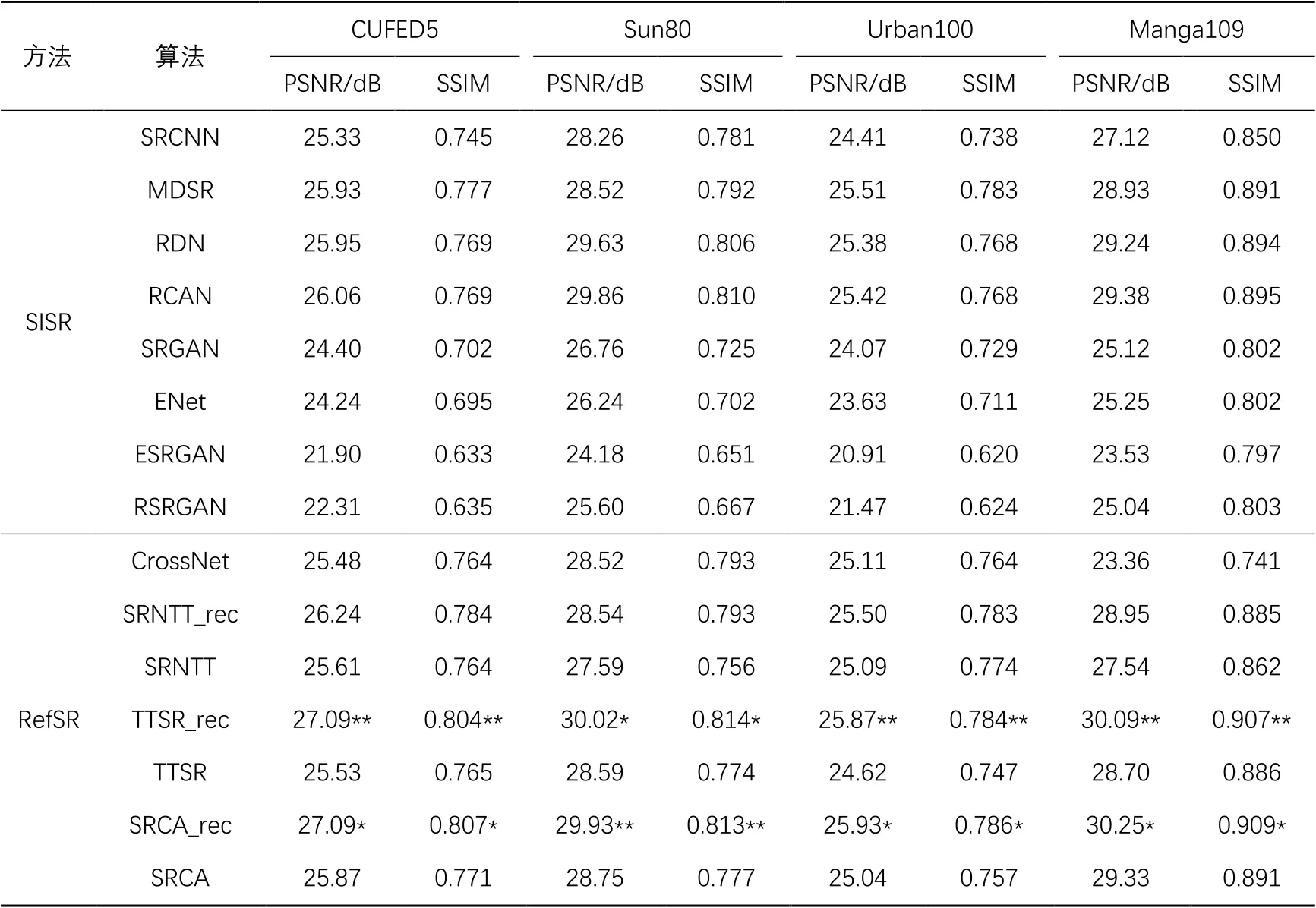
表1 在四个不同数据集上不同算法的PSNR/SSIM比较Tab. 1 PSNR/SSIM comparison of different algorithms on four different datasets
注:带“*”表示最高分,带“**”表示第二高分。
接下来,分别用SRCA、双三次插值法(Bicubic)、RDN、RCAN、SRNTT和TTSR对实际图片进行超分辨重建,结果如图5~6所示。
由图5~6可知,大多数重建方法容易出现伪影,如:图5(c)、图5(d)和图5(e)重建出的人脸图像很模糊,图5(f)与图5(g)重建出的人脸图像有严重伪影,纹理转移时定位不准确,图5(h)中本文模型重建出的图像细节纹理更真实,人脸轮廓更清晰。图6(d)、图6(e)和图6(f)重建出的图像很模糊,图6(g)重建出的效果优于前三者,但重建出的数字3边缘轮廓不清晰,细节恢复不真实。而本文模型重建图6(h)在线条细节上恢复真实度高,边缘轮廓更清晰自然。
SRCA恢复出的图片也具有较高的视觉质量,在Ref图像纹理搜索与转移方面可以更加准确,当Ref图像与LR图像的相似度不高时,SRCA模型仍然可以搜索出相对应的纹理并转移到SR图像中,从而使恢复出的图像更生动,如图7~8所示。

图5 在CUFED5:00004图像上放大4倍后不同模型重建结果对比Fig. 5 Reconstructed result comparison of different models on CUFED5:00004 image with magnification 4

图6 在CUFED5:00064图像上放大4倍后不同模型重建结果对比Fig. 6 Reconstructed result comparison of different models on CUFED5:00064 image with magnification 4

图7 在Sun80图像上放大4倍后不同模型重建结果对比Fig. 7 Reconstructed result comparison of different models on Sun80 image with magnification 4

图8 在Manga109图像上放大4倍后不同模型重建结果对比Fig. 8 Reconstructed result comparison of different models on Manga109 images with magnification 4
在图7中,图7(d)、图7(f)和图7(g)重建出的窗户线条模糊,图7(e)重建出的图像在视觉上有提升但是放大后的窗户玻璃边缘不清晰;本文模型重建的图7(h)窗户玻璃边缘清晰,观赏性强。在图8中,在人脸恢复方面,漫画中人脸眼睛部分细节较多,所以针对重建后的人脸图像右眼部分进行对比,相较于基准图片如图8(a)而言,图8(d)和图8(f)重建出的视觉效果不好,图8(e)放大后的眼睛轮廓不清晰,图8(g)恢复出的人眼中轮廓相较于基准图片而言不圆润且多出一块白斑。本文模型重建的图8(f)不仅在视觉上比其他模型重建效果好,而且放大后的人眼具有较为清晰的纹理且边缘锐利。
在模型训练性能方面将本文模型与TTSR进行了对比,实验结果如图9所示。图9展示的是两个网络训练200轮期间在的CUFED5验证集上的PSNR和SSIM比较,可以看出两个网络都呈现出增长趋势,但SRCA整体增长在TTSR之上,SRCA的平均PNSR与平均SSMI相较TTSR大约提升了0.12 dB与0.003 5,表明在训练次数相等的情况下SRCA具有更好的性能。
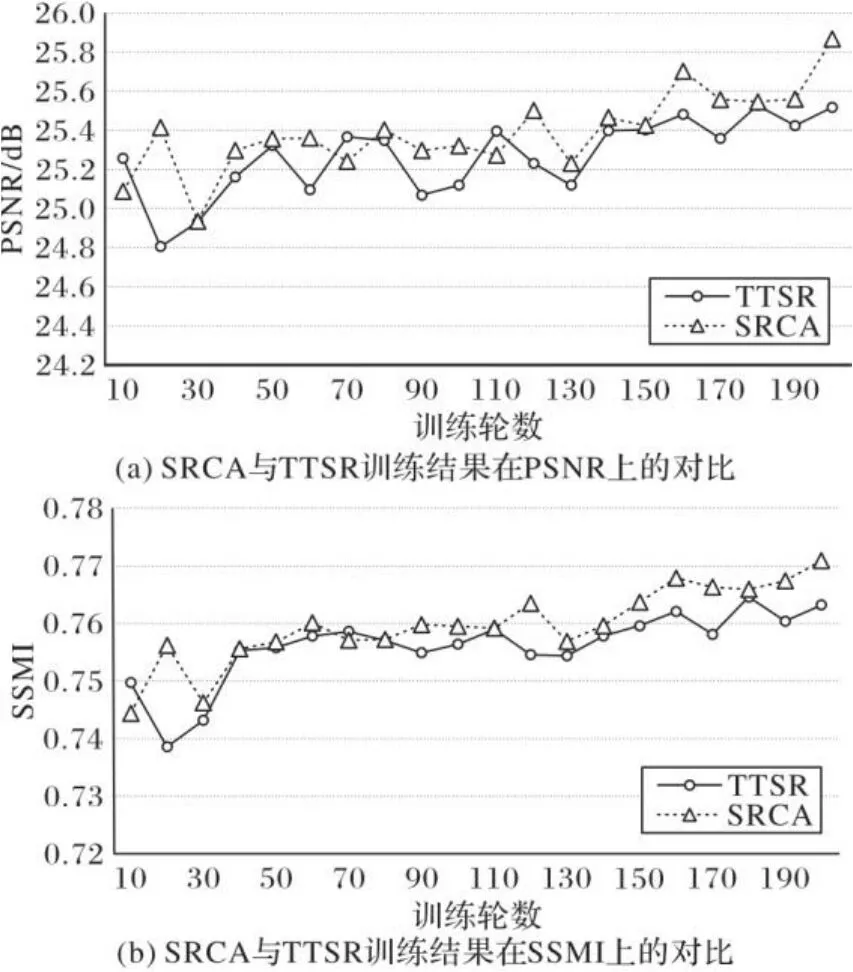
图9 SRCA与TTSR的训练结果对比Fig. 9 Training result comparison of SRCA and TTSR
3 结语
本文提出了一种新的基于参考的图像超分辨率重建网络来生成高质量图像。本文模型中多通道注意力的纹理提取模块通过对图像特征多通道关注并进行高频信息定位,提升模块对高频特征信息的选择能力;纹理迁移模块通过利用低分辨率图像与参考图像之间纹理的相关度,来对纹理进行高质量整合与迁移。实验结果表明,所提SRCA提高了纹理迁移的准确性与有效性,在定量评价与视觉质量上都有所优化,性能良好。
[1] FREEMAN W T, PASZTOR E C. Learning low-level vision [C]// Proceedings of the 1999 7th IEEE International Conference on Computer Vision. Piscataway: IEEE, 1999: 1182-1189.
[2] 苏秉华,金伟其,牛丽红,等.超分辨率图像复原及其进展[J].光学技术,2001,27(1):6-9.(SU B H, JIN W Q, NIU L H, et al. Super-resolution image restoration and progress [J]. Optical Technique, 2001, 27(1): 6-9.)
[3] FREEMAN W T, JONES T R, PASZTOR E C. Example-based super-resolution [J]. IEEE Computer Graphics and Applications, 2002, 22(2): 56-65.
[4] DONG C, LOY C C, HE K M, et al. Learning a deep convolutional network for image super-resolution [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8692. Cham: Springer, 2014: 184-199.
[5] KIM J, LEE J K, LEE K M. Deeply-recursive convolutional network for image super-resolution [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1637-1645.
[6] CAO C S, LIU X M, YANG Y, et al. Look and think twice: capturing top-down visual attention with feedback convolutional neural networks [C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway: IEEE, 2015: 2956-2964.
[7] WANG F, JIANG M Q, QIAN C, et al. Residual attention network for image classification [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2017: 6450-6458.
[8] HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141.
[9] LU Y, ZHOU Y, JIANG Z Q, et al. Channel attention and multi-level features fusion for single image super-resolution [C]// Proceedings of the 2018 IEEE International Conference on Visual Communications and Image Processing. Piscataway: IEEE, 2018: 1-4.
[10] ZHANG Z F, WANG Z W, LIN Z, et al. Image super-resolution by neural texture transfer [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2019: 7974-7983.
[11] YANG F Z, YANG H, FU J L, et al. Learning texture transformer network for image super-resolution [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 5790-5799.
[12] WANG Q L, WU B G, ZHU P F, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020:11531-11539.
[13] 赵荣椿,赵忠明,赵歆波.数字图像处理与分析[M].北京:清华大学出版社,2013:36-40.(ZHAO R C, ZHAO Z M, ZHAO X B. Digital Image Processing and Analysis [M]. Beijing:Tsinghua University Press, 2013: 36-40.)
[14] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2021-02-23].https://arxiv.org/pdf/1409.1556.pdf.
[15] KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2021-02-23]. https://arxiv.org/pdf/1412.6980.pdf.
[16] SUN L B, HAYS J. Super-resolution from internet-scale scene matching [C]// Proceedings of the 2012 IEEE International Conference on Computational Photography. Piscataway: IEEE, 2012: 1-12.
[17] HUANG J B, SINGH A, AHUJA N. Single image super-resolution from transformed self-exemplars [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 5197-5206.
[18] MATSUI Y, ITO K, ARAMAKI Y, et al. Sketch-based manga retrieval using Manga109 dataset [J]. Multimedia Tools and Applications, 2017, 76(20):21811-21838.
[19] LIM B, SON S, KIM H, et al. Enhanced deep residual networks for single image super-resolution [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops. Piscataway: IEEE, 2017: 1132-1140.
[20] ZHANG Y L, TIAN Y P, KONG Y, et al. Residual dense network for image super-resolution [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2018: 2472-2481.
[21] ZHANG Y L, LI K P, LI K, et al. Image super-resolution using very deep residual channel attention networks [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11211. Cham: Springer, 2018: 294-310.
[22] LEDIG C, THEIS L, HUSZÁR F, et al. Photo-realistic single image super-resolution using a generative adversarial network [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Piscataway: IEEE, 2017:105-114.
[23] PASZKE A, CHAURASIA A, KIM S, et al. ENet:a deep neural network architecture for real-time semantic segmentation [EB/OL]. [2021-02-23]. https://arxiv.org/pdf/1606.02147.pdf.
[24] WANG X T, YU K, WU S X, et al. ESRGAN: enhanced super-resolution generative adversarial networks [C]// Proceedings of the 2018 European Conference on Computer Vision, LNCS 11133. Cham: Springer, 2018:63-79.
[25] ZHANG W L, LIU Y H, DONG C, et al. RankSRGAN: generative adversarial networks with ranker for image super-resolution [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 3096-3105.
[26] ZHENG H T, JI M Q, WANG H Q, et al. CrossNet: an end-to-end reference-based super resolution network using cross-scale warping [C]// Proceedings of the2018 European Conference on Computer Vision, LNCS 11210. Cham: Springer, 2018: 87-104.
Image super-resolution reconstruction network based on multi-channel attention mechanism
ZHANG Ye1, LIU Rong1, LIU Ming2*, CHEN Ming1
(1.College of Physical Science and Technology,Central China Normal University,Wuhan Hubei430079,China;2.School of Computer Science,Central China Normal University,Wuhan Hubei430079,China)
The existing image super-resolution reconstruction methods are affected by texture distortion and details blurring of generated images. To address these problems, a new image super-resolution reconstruction network based on multi-channel attention mechanism was proposed. Firstly, in the texture extraction module of the proposed network, a multi-channel attention mechanism was designed to realize the cross-channel information interaction by combining one-dimensional convolution, thereby achieving the purpose of paying attention to important feature information. Then, in the texture recovery module of the proposed network, the dense residual blocks were introduced to recover part of high-frequency texture details as many as possible to improve the performance of model and generate high-quality reconstructed images. The proposed network is able to improve visual effects of reconstructed images effectively. Besides, the results on benchmark dataset CUFED5 show that the proposed network has achieved the 1.76 dB and 0.062 higher in Peak Signal-to-Noise Ratio (PSNR) and Structural SIMilarity (SSIM) compared with the classic Super-Resolution using Convolutional Neural Network (SRCNN) method. Experimental results show that the proposed network can increase the accuracy of texture migration, and effectively improve the quality of generated images.
image super-resolution reconstruction; texture transfer; attention mechanism; one-dimensional convolution; dense residual block
TP391.4
A
1001-9081(2022)05-1563-07
10.11772/j.issn.1001-9081.2021030498
2021⁃04⁃02;
2021⁃06⁃28;
2021⁃07⁃01。
国家社会科学基金资助项目(19BTQ005) 。
张晔(1997—),女,河北石家庄人,硕士研究生,主要研究方向:模式识别、智能信息处理; 刘蓉(1969—),女,湖南安化人,副教授,博士,主要研究方向:智能信息处理、模式识别; 刘明(1967—),男,湖北仙桃人,教授,博士,CCF会员,主要研究方向:物联网、计算机系统结构、智能信息处理及可视化; 陈明(1995—),男,湖北十堰人,硕士研究生,主要研究方向:模式识别、智能信息处理。
This work is partially supported by National Social Science Fund of China (19BTQ005).
ZHANG Ye, born in 1997, M. S. candidate. Her research interests include pattern recognition, intelligent information processing.
LIU Rong, born in 1969, Ph. D., associate professor. Her research interests include intelligent information processing, pattern recognition.
LIU Ming, born in 1967, Ph. D., professor. His research interests include internet of things, computer system structure, intelligent information processing and visualization.
CHEN Ming, born in 1995, M. S. candidate. His research interests include pattern recognition,intelligent information processing.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
河南科技(2021年35期)2021-04-25
上海师范大学学报·自然科学版(2019年5期)2019-12-13
保健与生活(2019年7期)2019-07-31
小资CHIC!ELEGANCE(2018年33期)2018-11-08
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
CHIP新电脑(2016年3期)2016-03-10
