
多级注意力传播驱动的生成式图像修复方法
2022-06-18 10:37曹承瑞刘微容史长宏张浩琛
自动化学报 2022年5期
曹承瑞 刘微容 史长宏 张浩琛
图像修复是指对图像中缺失或损坏区域进行修复重建的过程,它是计算机视觉技术领域的重点研究内容之一,其在图像编辑、图像渲染等诸多领域具有重要实用价值[1−8].如何在图像破损区域合成与现有上下文区域结构语义一致、内容准确、细节丰富的局部图像信息,是图像修复方法需要解决的难点问题.
根据所利用特征级别的不同,现有图像修复方法可分为两大类:1)利用低级非语义特征的方法;2)利用高级语义特征的方法.其中,利用低级非语义特征的图像修复方法为传统的图像修复方法,通常基于扩散或图像块匹配机制将非破损区域的低级特征 “粘贴”到破损区域.此类方法对特定的图像缺损类型有着优秀的修复效果.例如基于扩散的方法将图像信息从破损区域边界往内部进行传播,可以有效地修复 “抓痕”这样的细小破损.基于图像块匹配的方法在背景修复方面性能强大,并广泛应用于商用软件中.然而,此类利用低级非语义特征的图像修复方案无法对破损区域的上下文进行深入理解,即无法获取图像的高级语义特征,使得此类方法对高度模式化的图像(比如人脸)无法实现很好的修复效果.
利用高级语义特征的方法,从大规模数据中学习高级语义特征,大大提升了修复性能.其中,基于生成式对抗网络GANs[9](Generative adversarial nets)的方法已成为图像修复领域的主流.基于GANs的方法将图像修复问题转化为基于条件生成对抗网络[10]的条件生成问题.此类方法通常以破损图像与标定破损区域的掩码作为条件输入,采用自动编码器网络作为生成器来重建缺损区域的内容,并结合判别器网络以对抗方式训练,最终得到完整的图像输出.为有效地综合利用图像上下文区域的特征,GL[11](Globally and locally consistent image completion)引入级联扩张卷积,并将其集成到自动编码器网络的 “瓶颈区”.虽然扩张卷积可以在一定程度上将远距离特征纳入其感受野中,以达到综合利用远距离特征的目标;但是扩张卷积有较大的空穴区域,以规则对称的网格方式采样图像特征,从而造成远距离重点区域特征被忽略.MC[1](Multi-column convolutional),CA[2](Contextual attention)
以及CI[12](Contextual-based inpainting)等方案采用单级上下文注意力方案,计算图像上下文的语义相似度,显式地从破损图像的未破损区域中借取有意义的图像表达,缓解了远距离特征无法有效利用的问题.
然而,以上这些方法通常无法为场景复杂图像的缺损区域生成结构合理、细节丰富的内容.如图1(b)所示,修复结果图像中明显存在整体性或局部性结构错乱,此外生成图像还存在语义特征重建不够细致的问题,即对图像语义(比如人脸图像的眼睛、鼻子等部分)重建比较模糊.

图1 当前图像修复方法所存在的结构和细节问题展示Fig.1 The structure and detail issues encountered in current image inpainting method
如图2 所示为当前主流图像修复方案通常采用的自动编码器生成网络.缺损图像经过编码器编码得到浅层特征,将浅层特征送入 “瓶颈区”进行特征提取,然后再由解码器解码为完整图像.我们通过研究发现此类自动编码器结构存在非常严重的特征传递受阻问题,其 “瓶颈区”高级特征的截面过大(一般为64×64 像素大小).大截面特征使得扩张卷积与单级注意力特征匹配等方案[2,11−12]无法充分获取结构与细节特征,同时阻碍了结构和细节特征在网络中传播,从而导致了修复结果中出现结构错乱和语义对象模糊等现象.
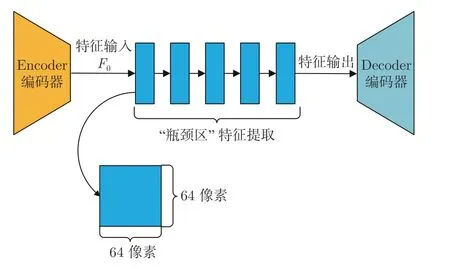
图2 常规自动编码器Fig.2 Conventional autoencoder
如图3 所示,针对特征传递受阻问题,我们对自动编码器结构中的 “瓶颈区”网络部分进行以下两步改进:第1 步,多级特征压缩.将编码器与解码器之间的 “瓶颈网络”中大小为h×w×c像素的高级特征分别按照0、2、4、8 压缩率进行缩放,构建多级压缩特征,即F0、Fc2、Fc4和Fc8.越高压缩率的特征,其尺度越小.若按照特征尺度大小对多级压缩特征进行排列,其结果为F0>Fc2>Fc4>Fc8.多级压缩特征在特征表达方面是互补的,越小尺度的特征中有着越小的结构特征空间,网络更容易从中搜索出有意义的结构表达,但是越小尺度特征越缺乏细节信息;与之相反,越大尺度特征中虽然在结构表达能力上更弱,却有着越丰富的细节特征,网络更容易从中搜索出有意义的细节表达.因此,大小尺度特征之间的这种互补性为第2 步,即多级注意力传播,提供了巨大潜力.多级注意力传播可以充分利用不同压缩特征对不同特征(结构/细节)表达方面的优势.具体来说,我们分别对各级压缩特征Fc8、Fc4、Fc2和F0依次执行注意力匹配与替换,得到注意力特征;并依据从小尺度到大尺度的顺序对注意力特征进行分级传播.如图3 所示注意力特征A8与压缩特征Fc4结合,将小尺度注意力特征传播至更高尺度.其后注意力特征A4再以相同的过程传播至A2和A0.由于前一级注意力特征匹配替换的结果总比后一级有更准确的结构表达;后一级紧凑的压缩特征总比前一级有更多的细节特征.因此,多级注意力的传播方案可以促使网络在多个尺度下既保持图像结构准确,又不断地丰富细节.相比当前基于单级注意力的图像修复方案[1−2,12],我们的多级方案可以得到更加丰富的深度特征.
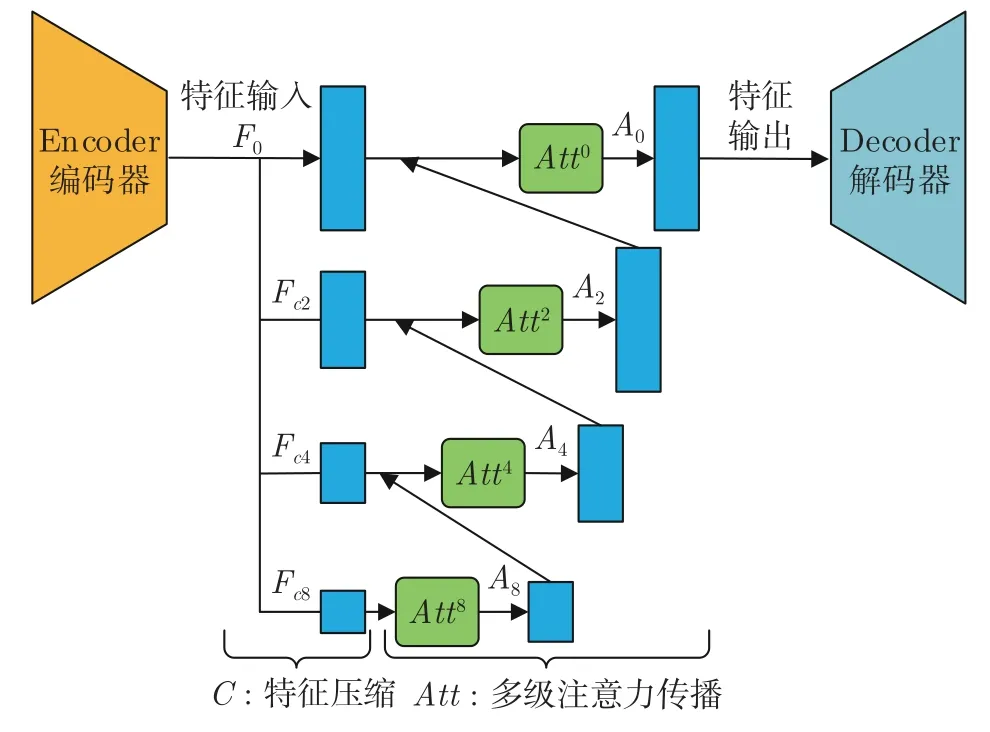
图3 多级注意力特征传播自动编码器Fig.3 Multi-scale attention propagation driven autoencoder
同时,与当前主流方法中由 “粗”到 “细”的多阶段方案不同,我们期望在一个阶段内实现细粒度图像重建.为此,我们还提出了一种复合粒度判别器网络对图像修复过程进行全局语义约束与非特定局部密集约束.其中,全局语义约束由全局判别器实现,该判别器的输出为一个评价图像整体真实度得分的值;非特定局部密集约束由局部密集判别器实现,“非特定局部”与 “密集”体现在我们的局部密集判别器所执行的是对图像内多个相互重叠的局部区域进行密集地判别.因此,这种密集局部判别方式非常适合处理不规则破损情况下的修复任务.
在包括人脸、建筑立面和自然图像在内的多个数据集上进行的大量实验表明,本文所提出的多级注意力传播驱动的生成式图像修复方法所生成的图像修复结果比现有方法拥有更高的图像质量.
综上所述,本文的贡献如下:1)提出了一种端到端的图像修复模型,该模型通过对全分辨率的图像上下文进行编码,将提取的高级特征压缩为多尺度紧凑特征,并依据尺度大小顺序驱动紧凑特征进行多级注意力特征传播,实现了包括结构和细节在内的高级特征在网络中的充分传播.2)提出了一种复合粒度判别器,对图像进行全局语义约束与非特定局部密集约束,使得图像修复在单个前向过程中同时实现高质量的细粒度重建.
1 相关工作概述
1.1 传统图像修复方法
利用图像级低级非语义特征的传统图像修复方法[7,13−18]可分为两类:基于扩散的方法和基于图像块的方法.基于扩散的方法利用距离场等机制将图像信息从相邻像素传播到目标区域,对于图像的小面积或类抓痕的窄缺损区域有着非常有效的修复效果.当缺损区域面积过大或纹理变化很大时,它们通常会生成明显的视觉伪影.基于图像块的方法首先用于纹理合成,然后扩展到图像修复.与基于扩散的方法相比,基于图像块的方法能够修复场景更复杂的图像.通常,基于图像块的方法采用迭代方式,从同一图像的非缺损区域或外部图像库中采样相似的信息来填补缺损区域.由于必须计算每个目标-源对的相似度分数,因此此类方法需要大量的计算和内存开销.PatchMatch[3]是一种典型的基于图像块的方法,它通过快速最近邻域算法解决了这个问题,极大地加快了传统算法的速度,取得了较高质量的修复效果.基于图像块的方法假设修复区域的纹理可以在图像的其他区域找到,然而这种假设未必时时成立,因此限制了该方法的应用范围;此外,由于缺乏对图像的高层语义理解,基于图像块的方法无法为人脸等高度模式化破损图像重建出语义合理的结果.因此,无论基于扩散还是基于图像块的传统修复方法,均不具备感知图像高级语义的能力.
1.2 基于深度学习的图像修复方法
近年来,基于深度学习的图像修复方法从大规模数据中学习高级语义表示,大大提高了修复效果.Context Encoder[19]是最早用于语义图像修复的深度学习方法之一.它采用自动编码器结构,通过最大限度地降低像素级重建损失和对抗损失,实现了对128×128 图像中心区域存在的64×64 矩形缺损区域的修复.编码器将带有破损区域的图像映射到高级特征空间,该特征空间用于解码器重构完整的输出图像.然而,由于通道维全连通层的信息瓶颈以及对图像局部区域缺乏约束,该方法输出图像的重建区域往往出现明显的视觉伪影.Iizuka 等[11]通过减少下行采样层的数量,用一系列膨胀卷积层代替通道全连接层,在一定程度上解决了上下文编码器的信息瓶颈问题.同时,Iizuka 等[11]还引入了一种局部判别器来提高图像的质量.然而,这种方法需要复杂的后处理步骤,如泊松混合,以增强孔边界附近的颜色一致性.Yang 等[12]和Yu 等[2]将粗到细的卷积网络配置方案引入到了图像修复中.该方案在第1 步使用深度卷积神经网络实现对破损区域的粗略估计.进而,在第2 步的深度卷积网络中,利用注意力机制或特征块交换操作,搜索图像上下文中最相似的特征块并替换缺失区域内的特征块,从而得到细化的输出结果.然而,这两种方案在不规则破损区域修复上并没有很好的泛化能力.Wang 等[1]提出了一种用于图像修复的多列生成网络,设计了置信值驱动的重建损失,并采用了隐式多样马尔科夫随机场(Implicit diversified Markov random field,ID-MRF) 正则化方案来增强局部细节.它在矩形和不规则掩码上都取得了很好的效果.Liu 等[20]在图像修复中引入部分卷积,对卷积进行了掩盖和重新归一化,仅利用非破损区域的有效像素,有效地解决了基于卷积所带来的色差、模糊等伪影问题.
2 多级注意力传播网络
如图4 所示,我们提出的多级注意力传播网络由两部分组成:(a)多级注意力传播生成器G,(b)复合判别器D.多级注意力传播网络生成器是针对图像修复任务改进的自动编码器,通过编码过程、多级注意力传播过程与解码过程重建图像的破损区域.复合判别器网络D通过将G生成的图像判别为 “假”来惩罚G,从而促进G生成真实图.我们将从破损图像到完整图像的学习过程描述为一个映射函数,该映射函数将破损图像流形z映射到完整图像流形x.为了简化符号,我们还将使用这些符号来表示它们各自网络的功能映射.
2.1 多级注意力传播网络生成器
如图4 所示,我们的多级注意力传播生成器G主要由特征提取网络、多级注意力传播网络、上采样网络等3个子网络构成.设Iinput=z和Ioutput=G(z)为多级注意力传播网络生成器的输入和输出.在浅层特征提取阶段,提取浅层特征F−1:

图4 多级注意力传播网络整体框架Fig.4 The framework of multistage attention propagation network
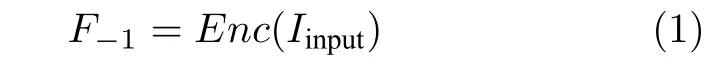
其中Enc(·) 为编码器网络.该网络的编码器首先进行平坦卷积,然后采用下采样与卷积操作对受损图像进行压缩编码.
其次,将提取的有用局部特征F−1进行特征细化:
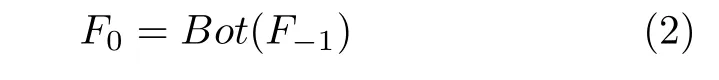
其中Bot(·) 为由4 层扩张卷积级联组成的 “瓶颈区”网络,卷积核尺寸为3×3,膨胀率分别为2、4、8、16.
接下来,进行多级注意力传播.注意力多级传播的第一步是将细化后的高级特征缩放为多级压缩特征:
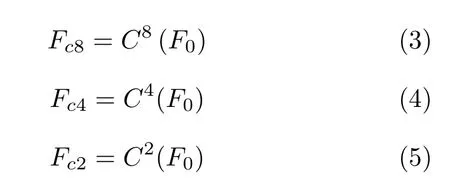
其中Cn(·) 为特征缩放操作,n为缩放率,表示特征尺寸缩放为原来的1/n.
随后,对压缩特征进行基于注意力的多级特征匹配与传播,以小尺度结果引导后续处理:
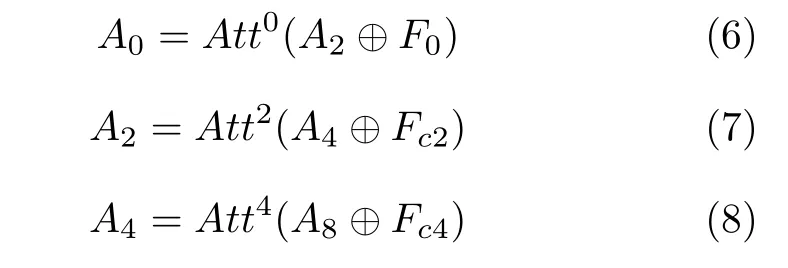

其中⊕表示通道维叠加,Attl(·) 为在压缩率为l的特征上进行的匹配替换与传播操作,更多细节将在第3.2 节中给出.
最终,经过多级注意力特征配替换与传播后,采用上采样网络将高级特征映射转化为完整的输出图像:
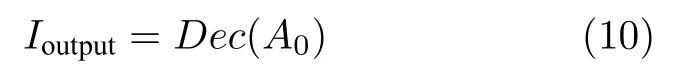
其中Dec(·) 为解码器网络,对特征A0进行两次上采样得到完整的重建图像.
2.2 基于注意力的特征匹配与传播
我们采用当前最先进的注意力特征匹配方案[2,12,21].注意力通常是通过计算缺失区域内外的图像块或特征块之间的相似度来获得的.因此可以将缺失区域外的相关特征进行转移,即通过相似度关系将图像上下文的图像块/特征块加权复制到缺失区域内部.图5 所示,Attl(·) 首先从压缩特征Fc中学习区域亲和力,即从Fc中提取特征块并计算破损区域内部特征块和外部特征块之间的余弦相似性:
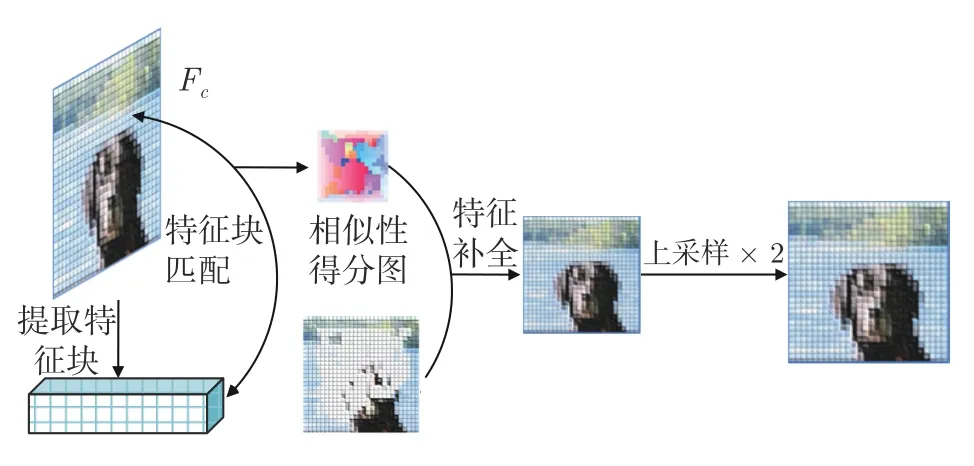
图5 注意力特征匹配与传播Fig.5 Flowchart of attention feature matching and propagation

从高级特征图中获取注意分值后,采用基于注意分值加权的上下文填充相似特征块中的破损区域:

2.3 复合判别器网络
作为生成网络的补充,复合判别器网络D用于判断G生成的图像是否足够真实.在图像修复中,高质量的图像不仅取决于图像的整体特征,还取决于图像局部对象的特征.不同于全局与局部判别器来分别约束全局与局部破损区域,我们设计了复合判别器来实现全局语义约束与非特定局部密集约束.
如图4(b)所示,全局语义约束与非特定局部密集约束分别由全局判别器D1与非特定局部密集判别器D2来实现.全局判别器由卷积层与全连接层构成,输出为一个评价图像整体真实度得分的值.非特定局部密集判别器类似Patch-GAN[22]结构,由5个的步长卷积(内核大小为5,步长为2)进行叠加构成.输入由图像和掩模通道组成,输出为形状为Rh×w×c的三维特征图,其中h、w、c分别表示通道的高度、宽度和数量.然后,我们将判别器的损失直接应用到判别器最后一层特征图的每个元素上,形成针对输入图像局部不同位置的数量为h×w×c的生成对抗网络.复合判别器网络中全局判别器与非特定局部密集判别器在功能方面为相互补充的.全局判别器针对全局的约束,促使生成的图像破损区域与非破损区域在全局层面实现自然过渡;而非特定局部密集判别器对图像内多个局部区域进行密集的有重叠的判别,使得图像局部拥有丰富的细节纹理.
3 损失函数
损失函数由三部分组成:1)对抗损失Ladv;2)特征匹配损失Lmatch; 3)重构损失Lrec.整体的目标函数可以表示为:
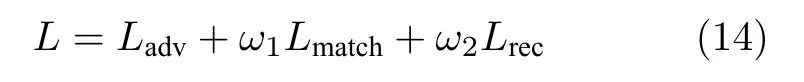
其中损失项的平衡参数ω1=1、ω2=1 000.
3.1 生成对抗损失Ladv
我们方法采用改进的Wasserstein GAN[23],对抗损失同时应用于网络G和网络D,最终影响生成网络G对破损图像的重构过程.复合判别器网络D的输出值代表生成网络G的输出图像与真实图像的相似程度,被用来惩罚并促使生成网络G生成更真实图像.我们的复合判别器网络D由D1和D2组成.对抗性损失可以表示为:

3.2 特征匹配损失Lmatch
特征匹配损失Lmatch用来比较判别器中间层的激活映射,迫使生成器生成与真实图像相似的特征表示,从而稳定训练过程,这类似于感知损失[24−26].不同于感知损失比较从预先训练的VGG 网络获取到来自真值图像与输出图像的激活映射,特征匹配损失比较的是判别器中间层激活映射.我们定义特征匹配损失Lmatch为:

其中L为判别器的最终卷积层,Ni为第i个激活层的元素个数,D1(i) 为判别器D1第i层的激活映射,D2(i)为判别器D2第i层的激活映射.
3.3 重建损失Lrec
图像修复不仅要保证修复好的图像具有语义真实感,而且要对图像进行像素级精确重建.因此,对于像素级重建过程,我们定义了L1 重建损失:
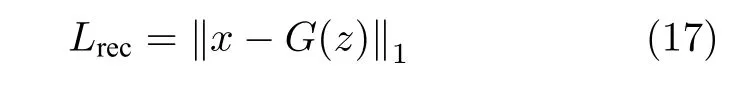
4 实验
4.1 数据集
我们使用3个面向于图像修复任务的国际公认通用图像数据集来验证我们的模型(数据集分割如表1 所示).
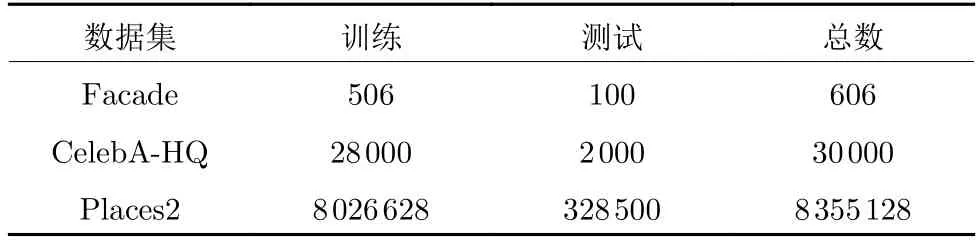
表1 3个数据集的训练和测试分割Table 1 Training and test splits on three datasets
–Places2[27]数据集:MIT 发布的数据集,包含超过800 万张来自365个场景的图像.
–CELEBA-HQ[28]数据集:来自CelebA 的高质量人脸数据集.
–Facade[29]数据集:世界各地不同城市建筑立面集合.
4.2 实验设置
在Windows 10 系统上使用Python 开发编译了本文所提出方法的程序代码.编译测试所用的深度学习平台软件配置为TensorFlow v1.8、CUDNN v7.0 和CUDA v9.0;核心硬件配置为Intel 8 700 3.20 GHz 的CPU,12G NVIDIA TITAN XP 的GPU.我们使用Adam 优化器对批量大小为6 的模型进行训练,beta1 与beta2 分别设定为0 和0.9.在模型训练初始阶段的学习率设置为1×10−4,随后再使用1×10−5学习率对模型进行微调.在模型训练过程中,训练集中的全部图像均被缩放至256×256大小.训练好的模型可在CPU 及GPU 上运行,不论缺损面积大小,修复过程在Intel(R) Core(R) CPU上平均运行时间为1.5 秒,在NVIDIA(R) TITAN XP GPU 上平均运行时间为0.2 秒.本文中全部实验结果都是从训练好的模型中直接输出的,未进行任何后期处理.
4.3 对比模型
我们将与以下经典主流方案进行比较:
–PatchMatch (PM)[3]:一种典型的基于图像块的方法,从周围环境复制类似的图像块.
–CA[2]:一个两阶段的图像修复模型,利用了高层次的上下文注意特征.
–MC[1]:为图像修复模型设计了一个置信值驱动的重建损失,并采用了隐式多样马尔可夫随机场正则化来增强局部细节.
5 结果与验证
5.1 实验结果
我们将本文方法与第4.3 节中当前经典主流方案分别进行了定性和定量分析,以证明本文方法的优越性.
定性比较.图6、图7 和图8 分别展示了我们的方法在Places2、Facade 和CelebA-HQ 数据集上和对比方法之间的对比结果.在大多数情况下,我们的图像修复结果比对比方法在结构重建方面表现得更准确合理.与其他方法相比,我们提出的方法在细节纹理重建上表现得更加细致.

图6 Places2 数据集上的结果比较Fig.6 Comparisons on the test images from Places2 dataset

图7 Facade 数据集上的结果比较Fig.7 Comparisons on the test image from Facade dataset

图8 CelebA-HQ 数据集上的结果比较Fig.8 Comparisons on the test image from CelebA-HQ dataset
定量比较.我们使用PSNR、SSIM 和平均L1损失等指标来客观衡量修复结果的质量.其中,PSNR和SSIM 可以大致反映模型重构原始图像内容的能力,为人类的视觉感知提供了良好的近似.平均L1损失直接测量重建图像与真值图像之间的L1 距离,是一个非常实用的图像质量评估指标.如表2 所示,我们的方法在Places2、CelebA-HQ 和Facade 数据集中取得了最优的结果,其中SSIM、PSNR 是最高的,平均L1 损失是最低的.
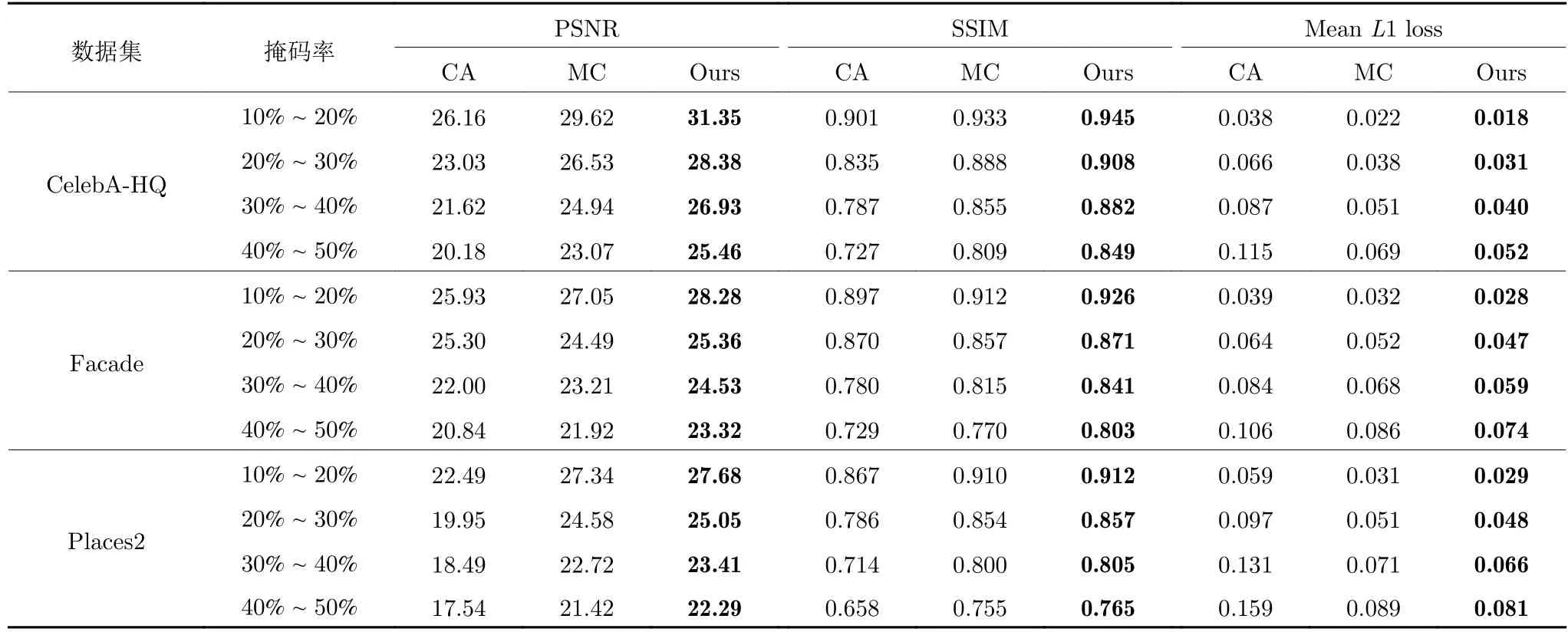
表2 CelebA-HQ、Facade 和Places2 数据集上的定量对比Table 2 Quantitative comparisons on CelebA-HQ,Facade and Places2
5.2 方案有效性分析
我们在建筑立面数据集上分别进行了两个分解实验来验证我们所提出方案的有效性.为了更清楚地展示实验结果,所有的实验均为矩形中心掩码情况下的图像修复结果.
1) 多级注意力传播的有效性
图9(a)为输入图像,图9(b)为有注意力传播时的图像修复结果,图9(c)为无注意力传播时的图像修复结果,图9(d)为原图.具体来说,这次试验参与对比的分别为本文提出方案的结果与本文方案除去多级注意力传播时的结果.可以看出在多级注意力传播的帮助下本文所提出的方案有着更准确的结构重建能力.

图9 有/无注意力传播时的图像修复结果Fig.9 Results with/without attention propagation
2) 复合判别器网络的有效性
如图10(a)为输入图像,图10(b)为有复合判别器时的图像修复结果,图10(c)为无复合判别器时的图像修复结果,图10(d)为原图.可以看出在复合粒度判别器的帮助下本文所提出的方案有着更细腻的细节重建能力.

图10 有/无复合判别器时的图像修复结果Fig.10 Results with/without compound discriminator
5.3 组件研究
为验证多级注意力机制以及复合粒度判别器网络的有效性,我们以平均L1 损失为性能参考(平均L1 损失越小性能越好),进行了对比定量研究,结果如表3 所示.其中,Att0 至Att8 为注意力组件,Single-D为单全局判别器,Cg-D为本文所提出的复合粒度判别器.

表3 组件有效性研究Table 3 Effectiveness study on each component
从表3 中我们可以看出,多级注意力传播可以在很大程度上提升网络性能,同时由于复合粒度判别器对全局语义与非特定局部的密集约束,网络性能得到了进一步提升.
5.4 泛化应用研究
为进一步验证我们方法的泛化能力,我们还通过对所提出模型进行对象移除实际应用研究.
如图11 所示,在示例(a)中,我们尝试删除人脸图像中的眼镜.我们可以看到本文方法都成功地删除了眼镜,并在眼镜区域重建出了清晰自然的人眼.在示例(b)中,我们的模型将面部大面积区域移除,并重建出合理的结果.值得注意的是,示例(a)与示例(b)人脸图像均不是正视前方,而在训练过程中,整个训练集中的非正视前方图像只占据少数,这从侧面说明了本文方法具有良好的泛化能力.更多的成功移除特定对象,重建出高品质的结果见示例(c)、(d)、(e)、(f).

图11 在Facade、CelebA-HQ 和Places2 数据集上的实例研究结果Fig.11 Case study on Facade,CelebA-HQ and Places2
6 总结
本文提出了一种基于层级注意力传播的图像修复网络.为解决图像修复结果中的结构错乱与语义对象模糊问题,我们提出将编码器编码的高级语义特征进行多尺度压缩和多层级注意力特征传播,以实现包括结构和细节在内的高级特征的充分利用.同时,为实现在一个阶段内完成粗粒度与细粒度图像的同步重建,我们提出了一种复合粒度判别器网络对图像修复过程进行全局语义约束与非特定局部密集约束.大量实验表明,与经典主流方法相比,我们提出的方法可以产生更高质量的修复结果.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
网络安全与数据管理(2022年1期)2022-08-29
小雪花·成长指南(2022年1期)2022-04-09
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
甘肃教育(2020年22期)2020-04-13
第二课堂(课外活动版)(2016年2期)2016-10-21
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
