
面向高考历史科目试题的自动答题系统
2022-06-17 09:09韩先培
中文信息学报 2022年4期
边 宁,韩先培,何 苯,孙 乐
(1. 中国科学院大学 计算机科学与技术学院,北京 100049;2. 中国科学院 软件研究所 中文信息处理实验室,北京 100190)
0 引言
考试自动答题任务是指利用标准化考试环境对问答系统进行测试。普通高等学校招生全国统一考试(高考)是综合评估人类知识和能力水平的标准化考试。其中,历史科目部分的试题内容涉及广泛的历史知识,注重考察学生运用历史学思维方法的能力以及发现、分析和解决问题的能力,对自动答题系统提出了更高的要求。本文针对我国高考历史科目部分,构建能够作答高考历史试题的自动答题系统。本文使用真实高考历史试题对答题系统进行测试,从而更准确地评估答题系统具备的能力,并且能够在教育领域开展服务。
近年来,自动问答系统的研究取得了长足进展。构建自动问答系统的主要目的是满足真实用户的信息需求。与用户提出的问题相比,历史高考试题具有以下特点: ①历史高考试题的形式相对固定,包括选择题和简答题两种题型,其中简答题除问题之外,还带有一段与问题相关的文字材料; ②历史高考试题的目的是考察学生是否掌握历史学科的相关知识和能力,因此作答历史试题依赖大量历史知识。这对构建面向历史科目高考的自动答题系统提出了新的挑战。
在自动答题系统中融合知识的一个主要挑战是知识具有上下文相关性: 对于一个问题,在知识库存储的大量知识中,只有少数知识与回答该问题相关。例如,针对“雅典和罗马是西方古典文明的杰出代表,对后来西方的历史和文化影响深远,二者都有的政治制度是(答案: 司法陪审制)”这一题目,在知识库中能够找到大量与“雅典和罗马的政治制度”相关的知识,但是其中只有关于“司法陪审制”的知识对作答该题有效。
针对从大规模知识库中准确寻找问题相关的有效知识这一挑战,本文设计了一种结合知识检索与机器阅读理解的知识融合自动答题系统。与Watson[1]等基于流水线结构和语义解析的传统自动答题技术相比,本系统综合利用了知识检索技术的相关排序能力和机器阅读理解模型的知识定位能力,能够有效地发现与问题相关的知识,从而增强自动答题的效果。具体地,系统首先利用文本检索技术检索与问题相关的知识文本,然后利用机器阅读理解技术定位问题相关的知识片段,综合文本和相关知识进行答题。本文针对历史高考中的选择题和简答题的题型和答案特点,分别构建了答题系统。
本文使用高考历史科目真实试卷和模拟试卷,以及标准的历史科目高考真题数据集GH577[2]对本系统进行测试,自动评分和人工评分的结果说明了本系统的有效性。消融实验的结果说明了知识检索技术能够有效检索到问题相关的知识,并进一步验证了本系统设计的合理性。本文还对系统回答错误的原因进行了分析。
1 相关工作
1.1 基于文本知识的自动问答
基于知识的自动问答系统因其应用价值高,受到研究人员的广泛关注。与结构化知识库相比,文本知识更容易获取,形式更加灵活。基于文本知识的自动问答系统通常包括文本检索模块和机器阅读理解模块。Chen等人将机器阅读理解模型与基于词匹配的文档检索模块相结合,构建了开放域问答系统[3]。后续研究提出了基于低维稠密语义向量的文本检索模型,使用神经网络将问题和文本知识表示为语义空间内的向量,通过向量相似度更准确地计算问题与文本知识的语义匹配程度[4-5]。但是,由于问答数据通常不标注其所需知识的具体来源,该类文本检索模型往往缺少直接的训练数据,为检索模型的训练带来了困难。本文构建的自动答题系统包括检索模块和机器阅读理解模块,使用了无须训练数据的BM25检索模型,并针对历史科目试题和知识库的特点设计了检索词提取和检索结果重排序机制。
1.2 机器阅读理解
机器阅读理解(Machine Reading Comprehension,MRC)是问答任务的一种特殊形式。该任务要求计算机在阅读指定文档的基础上,根据文档的信息回答问题[6]。机器阅读理解模型是基于文本知识的问答系统的核心模块。机器阅读理解模型不仅能够匹配问题与文档的语义,还能够深层次地理解文档,并结合背景知识进行推理和总结。因此,本文选用机器阅读理解模型作为自动答题系统的核心模块之一,以增强系统理解和利用相关知识的能力。
目前主流的机器阅读理解模型基于神经网络构建。模型一般包括三个模块: 编码模块、问题-文档交互模块和解码模块[7]。编码模块将问题和文档分别转换成语义表示,问题-文档交互模块在语义空间中建模问题与文档的相互作用。近年来,BERT[8]等预训练语言模型取代了编码和问题-文档交互模块,仅需要在语言模型的输出之后增加一个任务特定的解码模块,并在阅读理解数据集上微调训练,即可取得极大的性能提升。基于预训练语言模型的机器阅读理解模型是目前的主流模型。解码模块根据语义表示预测答案。传统机器阅读理解模型主要关注答案抽取,即在文档中预测答案字符串的开始和结束位置[9]。本文使用基于BERT的阅读理解模型构建自动答题系统。本文在近期关于选择题阅读理解的研究[10]基础上,针对历史科目试题中的选择题和简答题题型特点,设计了计算候选答案概率的解码模块。
1.3 考试自动答题系统
自动答题系统面对的是为人类设计的考试试题,与自动问答相比,考试试题对综合运用知识进行推理的能力提出了更高的要求。2010年,IBM公司设计的Watson系统在知识竞赛电视节目中战胜了人类选手[1]。针对世界历史选择题任务[11-12],Wang等人构建了流水线结构的自动答题系统,包括问题分析、命题生成、选项打分等流程[13]。Hosseini等人将题目转换为结构化表示,作答小学数学试题[14]。陈志刚等人结合语言模型和隐语义分析,构建了面向初高中英语单选题的自动答题系统[15]。Wu等人利用机器阅读理解模型构建了医师资格考试自动答题系统[16]。在我国高考方面,Cheng等人提出基于信息检索的选择题答题方法,通过比对候选答案与百科文档的相关性选择答案,并使用历史科目试题进行测试[2]。本文基于机器阅读理解模型构建自动答题系统,利用阅读理解模型自动学习从文档中提取和利用相关知识的能力,增强自动答题的效果。
2 高考历史科目考试自动答题系统
本文结合文本检索技术与机器阅读理解模型,构建面向高考历史科目试题的自动答题系统,系统框架如图1所示。主要模块的功能如下所述。
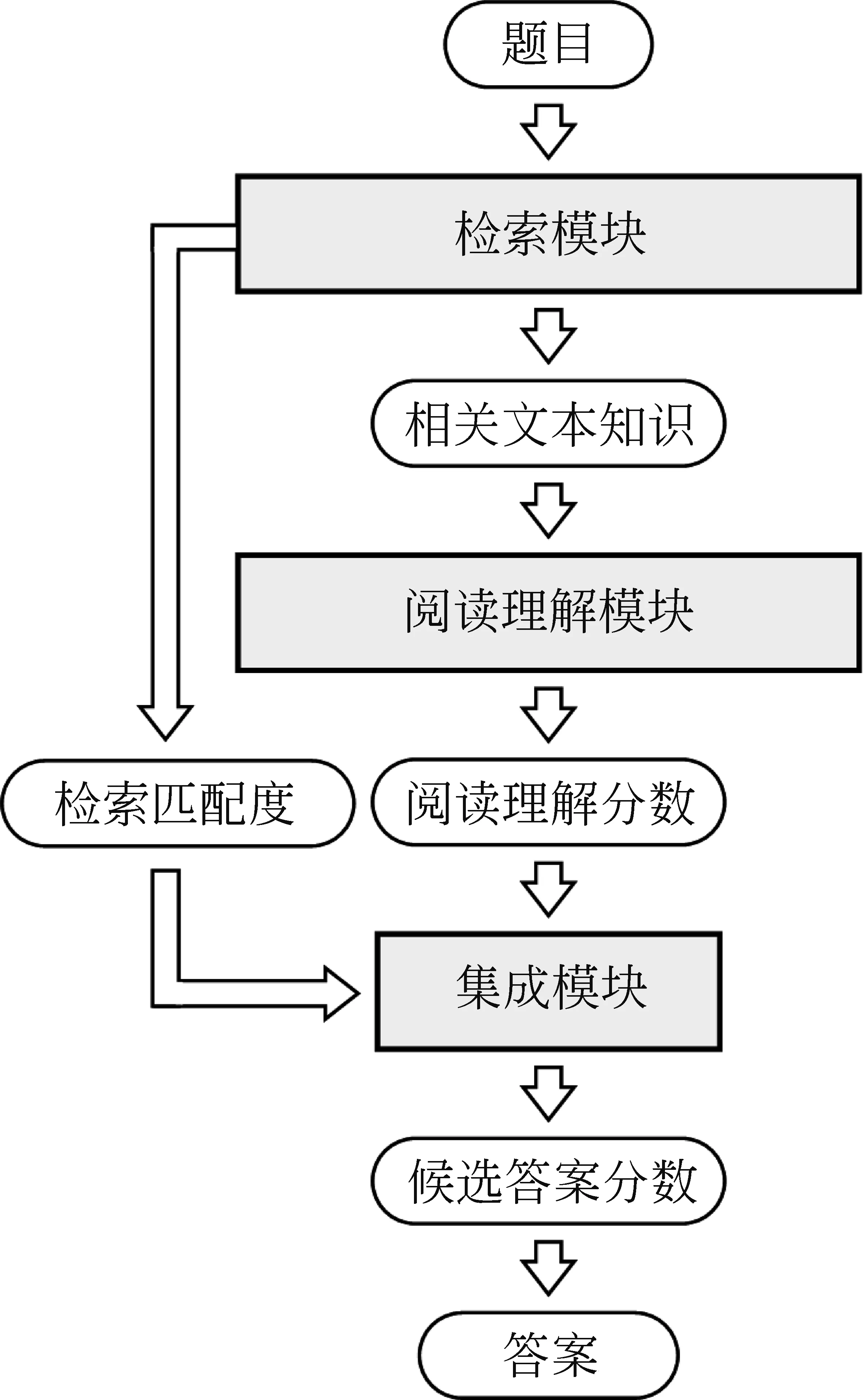
图1 面向高考历史科目试题的自动答题系统框架
(1)检索模块: 根据题目提供的信息,从知识语料库(包括教材文本和题库文本)中检索相关文本知识,将其作为机器阅读理解的阅读文档。
(2)阅读理解模块: 融合题目和阅读文档的信息,评估各候选答案的正确性,计算候选答案的分数(正确概率)。根据题目形式的不同,阅读理解模块分为选择题阅读理解模型和简答题阅读理解模型。
(3)集成模块: 综合阅读理解模块对各候选答案的分数和检索模型的检索匹配度,对各候选答案进行最终打分。
2.1 检索模块
检索模块的功能是根据问题和候选答案(对于选择题)或文本材料(对于简答题),检索与问题相关的文本知识,为阅读理解模型回答问题提供知识依据。
检索模块的框架如图2所示。对于选择题,检索模块针对每个候选答案输出一组检索结果及其检索匹配度,作为每个候选答案的支撑材料。对于简答题,检索模块输出与问题相关的知识句子,作为候选答案句子,供阅读理解模块挑选。
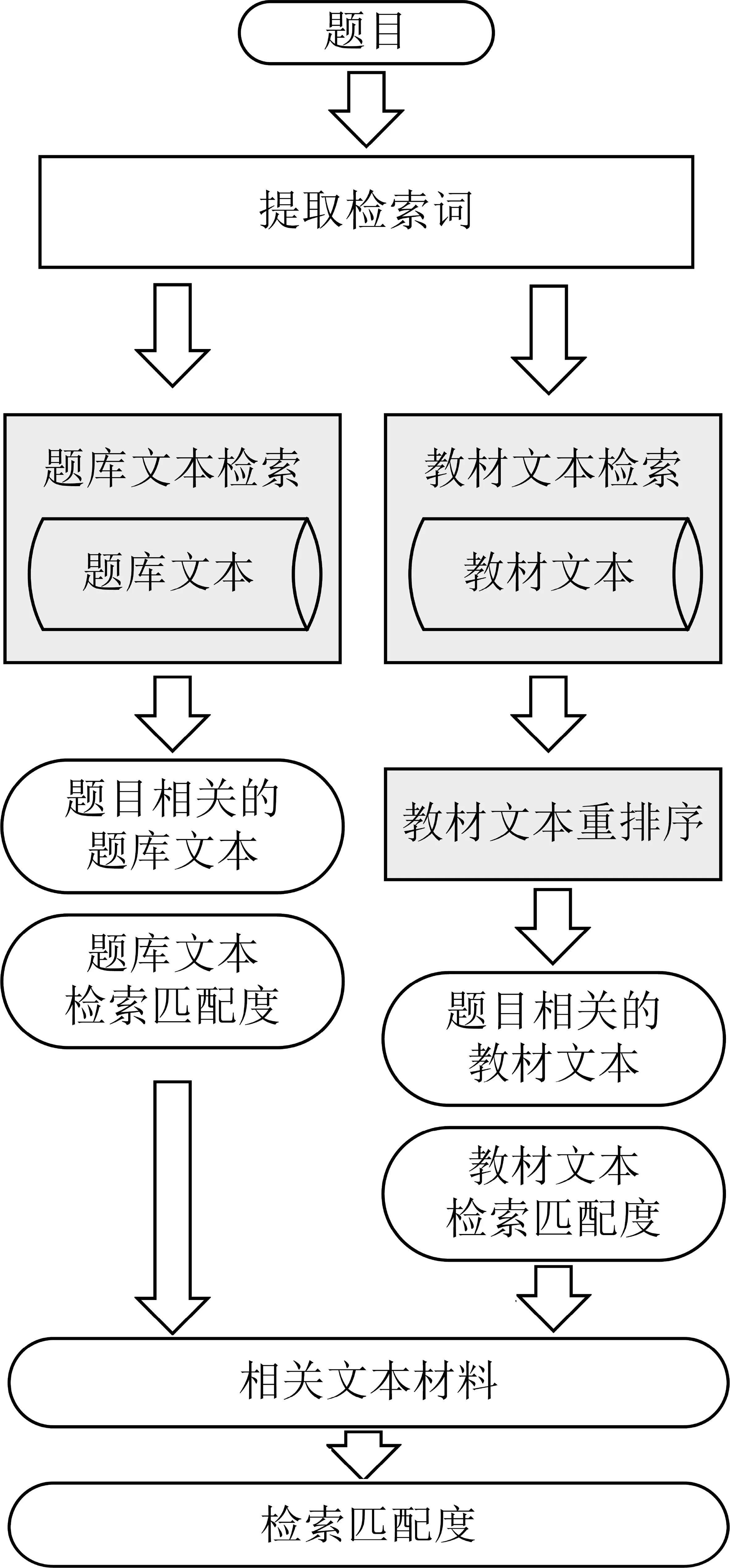
图2 检索模块框架
具体地,本文首先构建了高中历史知识语料库。为保证知识的准确性和对知识点的覆盖度,知识库由教材文档和练习题库组成。
为准确获取回答问题所需的知识,检索模块以句子为单位进行检索。历史教材等文本材料是对历史知识的概括和总结,往往一个句子表达一个完整的历史知识点,例如,“秦始皇首创的皇帝制度,一方面以皇位世袭显示了权力的不可转移,另一方面以皇权至上显示了地位的不可僭越,这是中国古代专制制度的重要特征。”作答历史题目依赖于具体、准确的历史知识点,例如,“皇帝制度的特征”,因此以句子为单位进行知识检索,能够准确地检索具体的历史知识,避免段落中无关信息的干扰。具体地,对于题库文本,检索模块将每一道题目及其正确答案视作一个句子;对于教材文本,检索模块根据标点符号对每个段落进行句子切分,并在每个句子的开头拼接其所在段落的第一个句子(通常是概括整段内容或观点的总起句),以保证句子上下文信息完整。
输入一道题目,检索模块第一步提取题目中的检索词: 首先使用带有用户词典的分词工具对题目进行分词,在去除停止词后,将剩余的词作为检索词。分词使用的用户词典为历史专有名词表。检索模块提取的检索词还包括题目中的实体词,实体词用于对检索结果进行进一步重排序。本文使用历史专有名词表进行实体词抽取。
随后,各检索模块使用BM25算法计算检索词与文本知识之间的匹配度。
题库文本检索模块以检索匹配度最高的N条文本作为题库文本检索结果。因为题库文本的质量较高,所以不使用重排序。
对于教材文本,采用检索-重排序的框架。首先,教材文本检索模块取匹配度最高的M条文本作为初步检索结果,进行重排序。重排序以题目中的实体词为检索词,使用BM25算法计算匹配度,取匹配度最高的前N条文本作为教材文本检索结果。使用实体词进行检索可以排除题目中无关词语的干扰,提高检索结果的精准性。
2.2 阅读理解模块
阅读理解模块根据问题和检索模块提供的文本知识,对每个候选答案打分。阅读理解模块基于目前先进的预训练语言模型BERT[8]构建。根据题目形式的不同,阅读理解模块分为选择题阅读理解模型和简答题阅读理解模型。
2.2.1 选择题阅读理解模型
对于选择题求解,模型需要根据检索模块提供的相关知识,计算四个候选答案的正确概率。选择题阅读理解模型框架如图3所示。
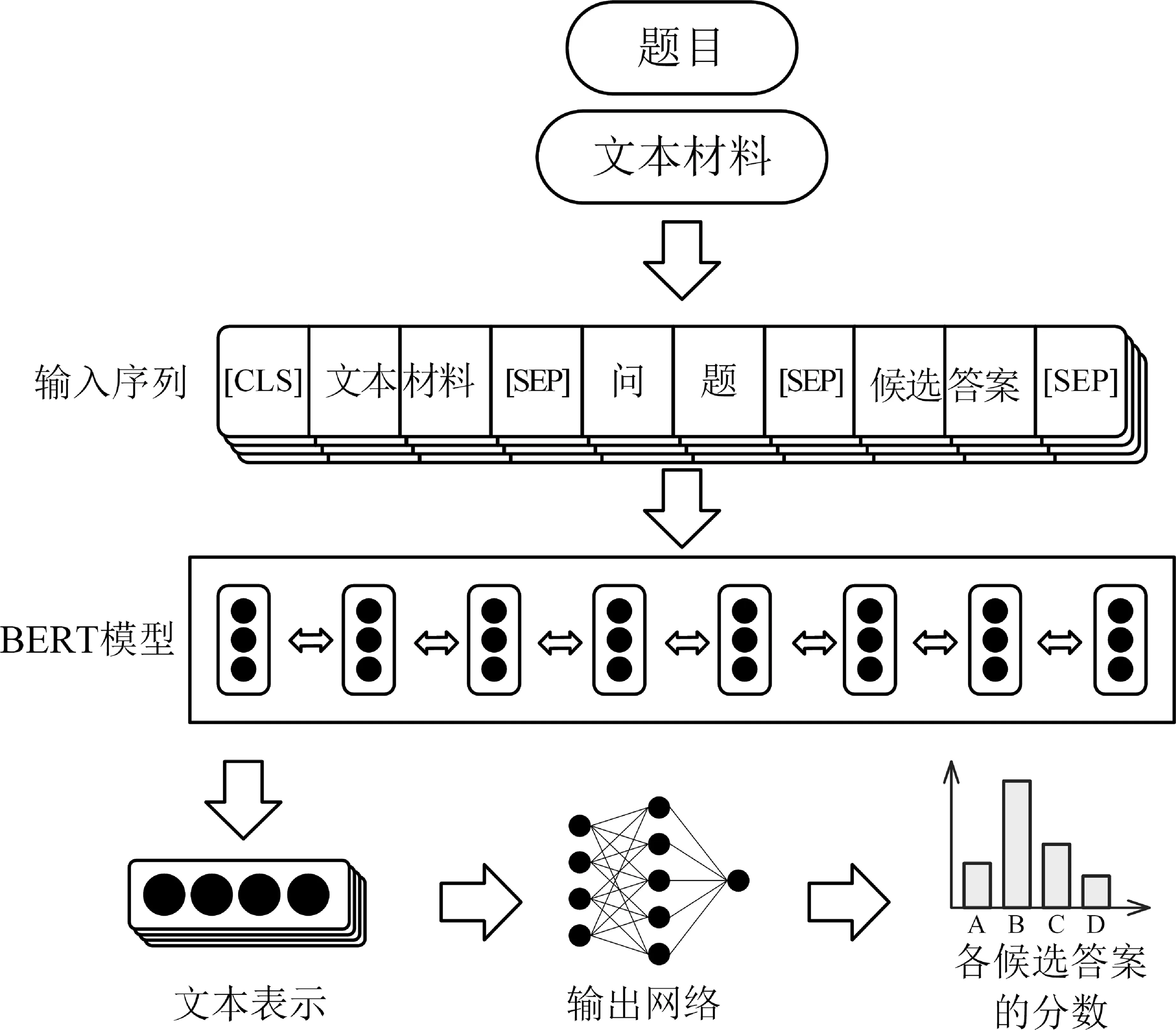
图3 选择题阅读理解模型框架
首先,选择题阅读理解模块的输入为各候选答案对应的文本序列。本文为每个候选答案构造一个输入序列,每个文本序列由“[CLS]+文本材料+[SEP]+问题+[SEP]+候选答案+[SEP]”组成。[CLS]字符是BERT模型的起始字符,[SEP]字符是BERT模型的分隔字符,用于分隔输入序列中的各个部分。
随后,预训练语言模型BERT对输入文本进行上下文建模,输出文本的语义表示。本模块中使用的语义表示由两部分拼接而成,包括起始字符“[CLS]”的向量表示和输入序列中各个字的表示向量的平均向量。
最后,阅读理解模块的输出网络根据文本表示向量,使用两层全连接神经网络计算每个候选答案的概率,即输出维度为1。输出网络隐含层维度为1 024,使用tanh()激活函数。各候选答案的概率使用Softmax归一化,并使用交叉熵损失函数进行模型训练。
2.2.2 简答题阅读理解模型
对于简答题求解,模型需要从检索模块提供的文本知识中选择能够回答问题的句子,组成答案。简答题阅读理解模型的输入为问题文本和各候选答案句子,输出为各句子能够回答问题的概率。简答题阅读理解模型框架如图4所示。
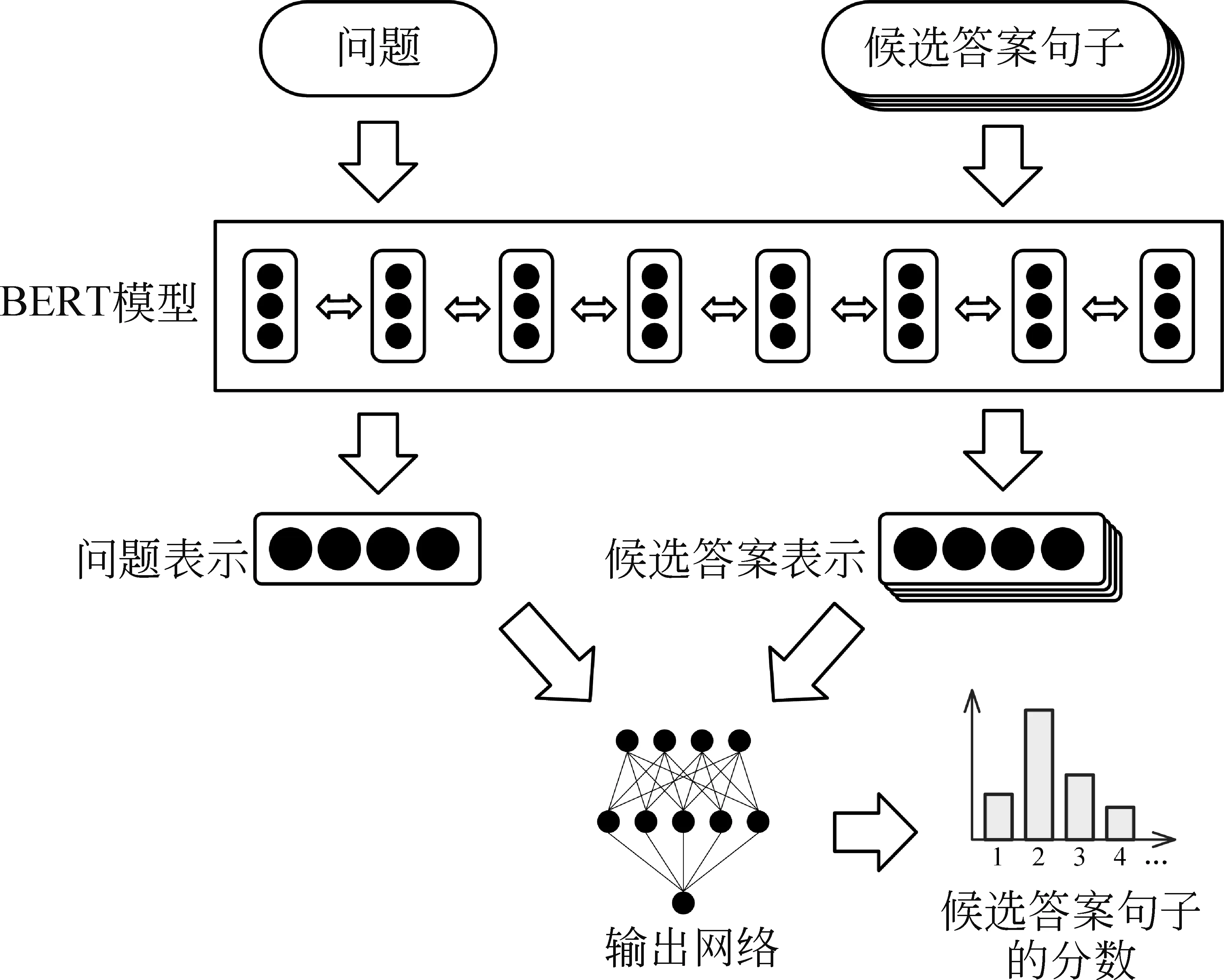
图4 简答题阅读理解模型框架
首先,预训练语言模型BERT对输入的问题文本和候选答案句子分别进行上下文建模,输出问题文本表示向量q和候选答案句子表示向量ai,其中i为候选答案句子的序号。
随后,使用由两层全连接神经网络组成的匹配网络计算每个候选答案句子与问题的匹配度,即候选句子成为问题答案的概率。神经网络的输入为concat(q,ai,|q-ai|),即三个向量的拼接。与选择题阅读理解模型的输出网络类似,简答题网络的输出维度为1,隐含层维度为512,使用tanh()激活函数。最后的输出层使用Sigmoid()激活函数将输出映射到0~1的范围内。
与选择题的训练数据中直接标注了正确答案不同,简答题训练数据的参考答案是人工编写的答案文本。这些答案文本往往无法在历史知识语料库中找到完全一致的句子。因此,为了获得高质量的简答题阅读理解模型训练数据,本文采取远距离监督的方法,根据人工编写的参考答案文本将检索得到的候选答案句子划分为正例集合和负例集合。
具体地,首先根据简答题问题和阅读文档,从语料库中检索一定数量的文本知识。然后,根据人工标注的参考答案与各文本知识的相关性,对文本知识排序。本文使用F1值衡量该相关性。取排序后文本知识条目的前25%作为正例,其余为负例。
为了进一步提高训练数据的质量,本文设计了检索词迭代扩展机制: 将人工标注的参考答案和正例文本知识中的实体词添加到检索词中,重新进行检索。该过程共迭代3轮。该机制有助于检索系统检索到与参考答案更相近的文本知识。
由于远距离监督得到的训练数据包含噪声,本文在模型训练时使用基于句子袋(bag of sentence)的训练方法。该方法常用于远距离监督关系抽取模型的训练[17]。在训练时,正例集合和负例集合同时输入模型。本文使用注意力机制将正例集合中的多个正例的向量表示整合为一个正例表示,对负例集合也做相同的整合。整合后的正例和负例表示输入匹配网络,计算其与问题的匹配度。模型的训练目标是最大化整合的正例表示的概率并最小化整合的负例表示的概率,如式(1)所示。
L=-(log(P+)+log(1-P-))
(1)
其中,P+和P-为正例和负例的概率。
2.3 集成模块
集成模块的作用是使阅读理解模块对各候选答案的分数与检索模块输出的检索匹配度互相补充,从而得到最终的候选答案概率。本模块将各模型输出的分数视作不同的特征,组合成各候选答案的特征向量。本模块使用两层全连接网络对候选答案的特征向量进行打分,分数使用Softmax做归一化处理,并使用交叉熵损失函数训练。
对于选择题,系统取概率最高的候选答案作为最终的答案。对于简答题,系统取文本知识中概率最高的前K个句子作为答案。
3 实验与分析
3.1 实验设置
高考历史科目考试题目形式: 本文使用北京市高考历史科目试题,试题由单项选择题和简答题两种题型组成。每道选择题包含4个选项,其中只有一个正确答案。简答题除问题之外,还提供了一段文本材料作为题目背景,通常要求结合文本材料的内容回答问题。
(1)训练数据: 本文共使用了约23万道中学历史练习题进行模型训练,包括约19万道选择题和约4万道简答题。
(2)测试数据: 本文以2016—2019年的4套北京高考历史科目试卷和由中学历史老师编制的两套历史科目模拟测试卷为测试题目,每套题目满分为100分。北京高考历史科目试卷每套包含选择题12题(共48分)、简答题5至6题(共52分)。历史模拟测试卷每套包含选择题15题(共48分)、简答题5题(共52分)。为了与现有的历史科目高考自动答题系统进行比较,本文还使用了标准的GH577历史科目高考数据集[2]开展测试,该数据集包含了577道真实的高考历史选择题。
(3)知识语料库: 包括题库文本和教材文本。题库文本由训练题库构造生成,其规则为“问题+正确答案”的字符串拼接,共约17万条文本。教材文本知识取自人民教育出版社出版的初高中历史统编教材、相关辅导书和中国百科大词典的历史部分。文本按照段落进行切分,共约19万条文本。
(4)系统评价: 对于历史试卷,本文使用答案得分作为自动答题系统的评价指标。对于选择题,本文根据标准答案进行自动打分。对于简答题,本文使用人工评价的答案分数,评价人员为教育行业从业人员。对于GH577数据集,本文使用答案正确率作为评价指标。
(5)对比系统: 本文对比了现有的历史科目高考答题系统,包括Cheng等人构建的历史科目考试自动答题系统[2]和Huang等人构建的JEEVES系统[18]。其中,JEEVES系统是目前性能最优的模型,包括联合训练的检索模型和阅读理解模型。本文使用Huang等人[18]对GH577数据集划分的开发集和测试集进行测试,各114题,而Cheng等人[2]的性能为全部577道题目上的正确率。
(6)系统参数设置: 对于选择题,检索模块输出匹配度最高的题库文本和教材文本各N=5条,其中教材文本检索的重排序阶段输入M=20条文本。对于简答题,检索模块输出匹配度最高的100条教材文本和100条题库文本。简答题答案在长度不超过2 500个字符的情况下选取尽可能多的前K个句子。
3.2 实验结果分析
本文在物理隔离、脱离互联网、无人工干预的环境下进行了实验。系统作答一套试卷所需时间约30分钟。
实验结果显示,本文构建的历史科目试题自动答题系统是有效的。表1展示了本文构建的高考历史科目考试自动答题系统在测试试卷上的得分情况。本系统在多个测试卷上都能取得大于60分的成绩,并且成绩稳定。在2018年北京市高考历史科目试卷上,本系统取得了69分的成绩,在6套试卷中得分最高。表2对比了本文构建的系统和现有的历史高考自动答题系统在GH577数据集上的答案正确率。与目前性能最优的JEEVES系统[18]相比,本文构建的系统获得了明显的性能提升。
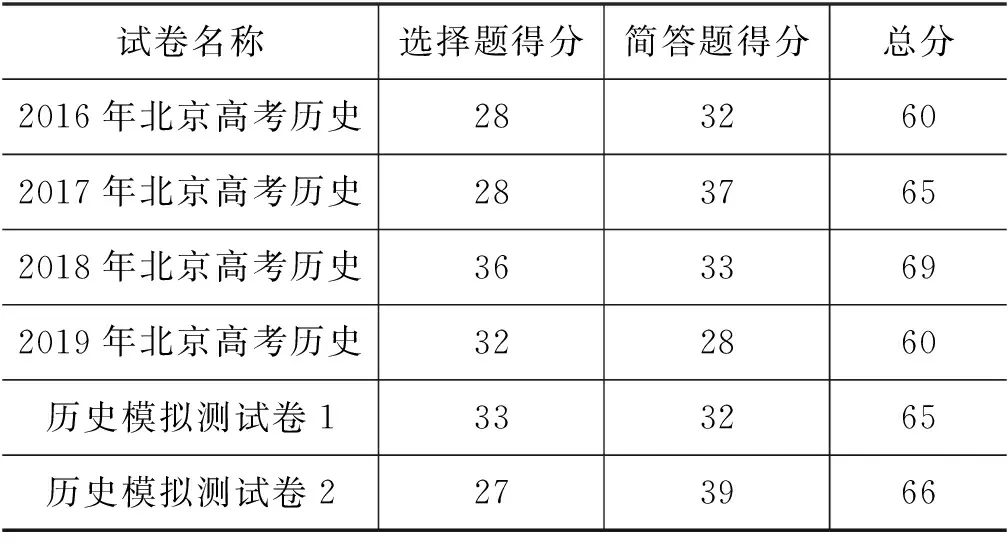
表1 高考历史科目考试自动答题系统得分
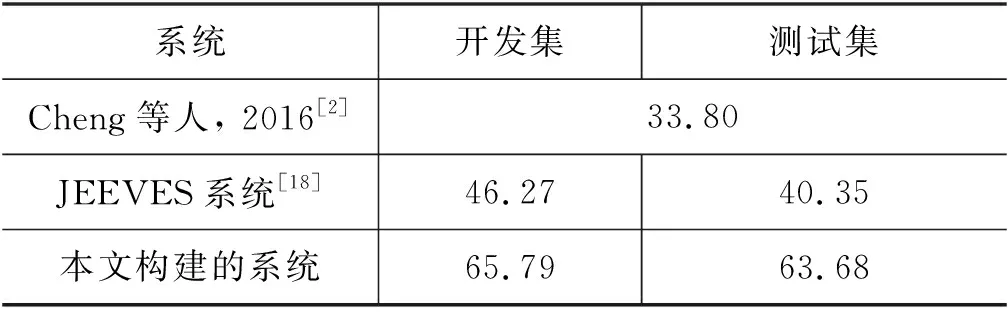
表2 高考历史科目考试自动答题系统在GH577数据集上的答案正确率 (单位: %)
消融实验的结果显示,知识检索模块能够有效检索问题相关的知识。表3展示了不同检索设置下的系统性能,以说明知识检索对答题系统的重要性。其中无检索指在阅读理解模块的输入中不使用任何文本知识,仅使用题目和候选答案作为模型输入。由表3可见,题库检索由于其文本质量高,对性能提升的作用较大。在6套测试试卷中,仅使用题库检索的答题系统在两套试卷上取得了与完整系统相同的答题性能,即题库文本可覆盖所需知识。而教材检索由于受到文本噪声影响,性能提升不明显。此外,这两种知识来源可有效互补,以获得更好的答题性能(即完整系统)。如表3所示,在3套试卷上,完整系统取得了比仅使用题库或教材检索更高的答题性能。
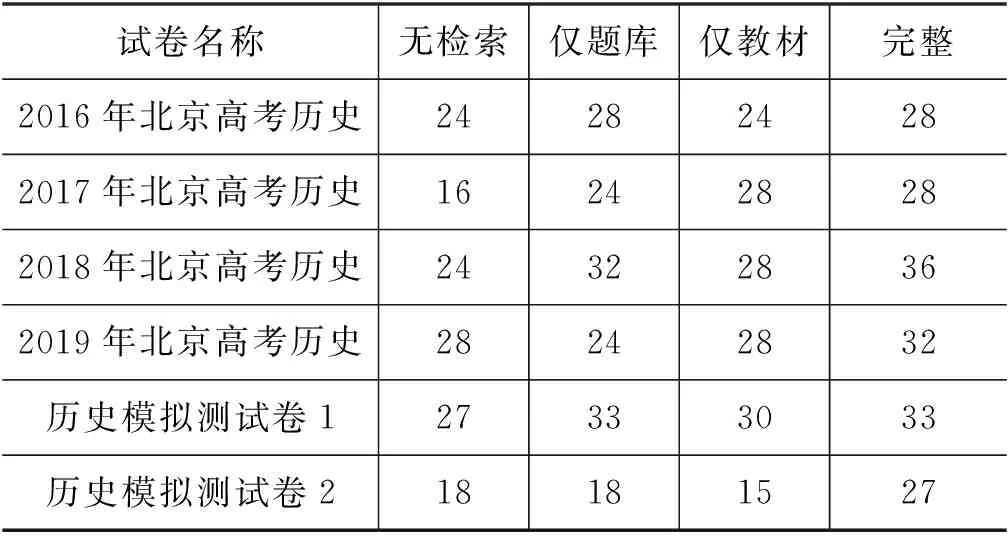
表3 检索模块对自动答题系统选择题得分的影响
上述实验结果说明,在自动答题系统中,高质量的相关知识起到了重要作用,并且本文设计的知识检索模块是有效的。
实验结果显示,以句子为单位进行知识检索是有效的。表4对比了以句子为单位、句子扩展和以段落为单位进行检索情况下的选择题答题性能。其中,句子扩展指在句子检索的基础上,对于包含分句(按逗号划分)数量少于阈值K的句子,拼接其前后句子,形成信息更丰富的句组进行检索。本文实验了K=2、3或4,拼接之前或之后句子的情况,表4中分数为其中最优结果。由实验结果可见,以扩展句组为单位的检索方式与以句子为单位检索的答题性能相同,说明在历史知识语料中,句子是一种完整、精准的检索单位。以句子为单位的检索可以更准确地检索具体的历史知识,避免段落中无关信息的干扰,因此其答题性能高于以段落为单位的检索。
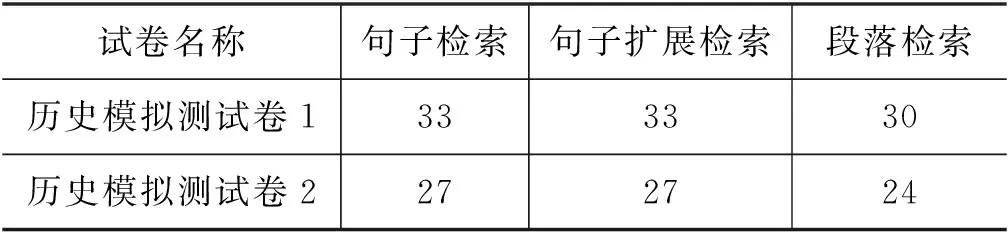
表4 检索粒度对自动答题系统选择题得分的影响
使用远距离监督训练简答题阅读理解模型是有效的。本文测试了不使用远距离监督,仅使用人工编写的参考答案训练简答题阅读理解模型。由表5可见,使用远距离监督的系统在历史模拟测试卷上的答题性能优于不使用远距离监督的系统。该实验说明使用远距离监督的方法能够有效标注检索得到的候选答案句子,从而训练简答题阅读理解模型,提高模型的答题性能。
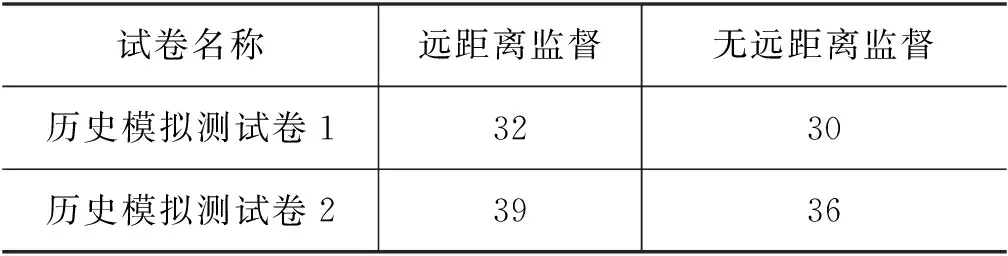
表5 简答题阅读理解模型远距离监督训练对自动答题系统简答题得分的影响
3.3 错误分析
通过分析本系统在历史试卷中回答错误的27道选择题,本文将系统回答错误的题目主要类型进行划分,各类型例题见表6。除表6所列出的错误类型和数量之外,另有3道回答错误的题目难以归入所划分的类型。

表6 回答错误的主要题目类型举例
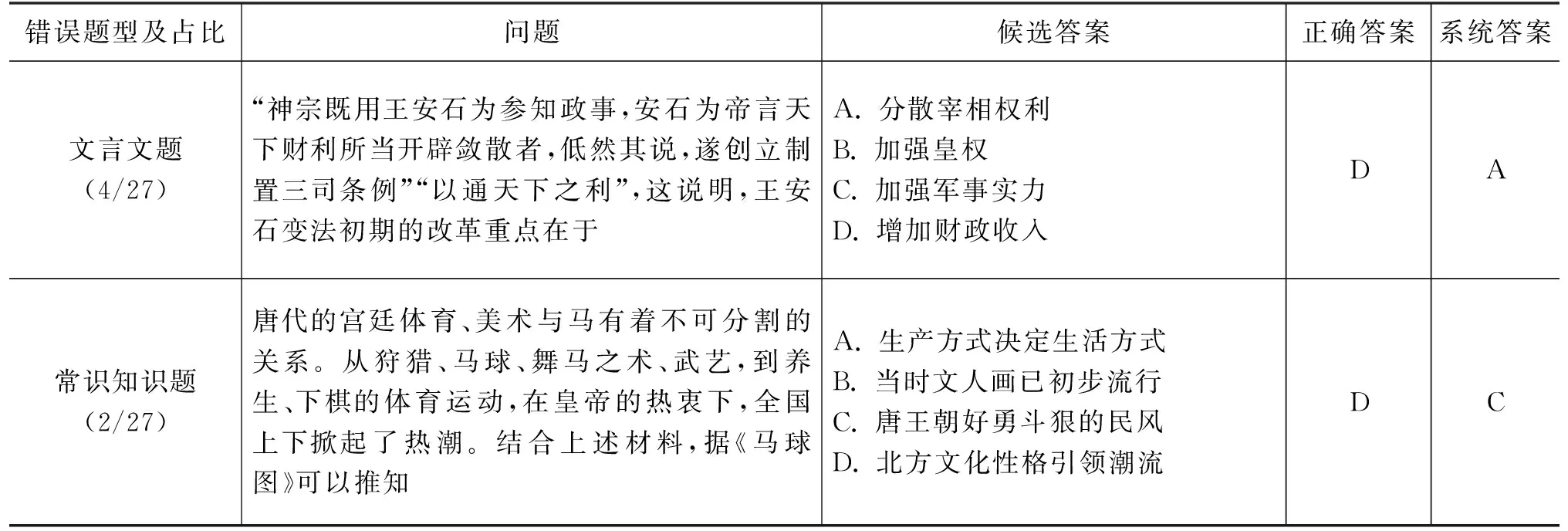
续表
(1) 复杂推理类问题,包括史实推理题和多步推理题。此类错误题目在27道错误题目中有12道。史实推理题需要模型从具体、多样的史实描述中提炼抽象的历史现象和结论,结合历史背景知识,做出正确的回答。此类题目要求模型具有抽象归纳的能力。
多步推理题需要模型进行复杂的多步推理。例如,表6中第2题,需要先推理出“此人”是“陈独秀”,再根据相关知识选出正确答案。由于训练数据只提供了答题的最终结果,缺少对推理所需的中间结果的标注,因此模型难以有效地学习多步推理的能力。
(2) 多模态、多语言类问题,包括图表题和文言文题。此类错误题目在27道错误题目中有10道。
图表题在同一个题目中同时包含自然语言模态和图像模态,因此需要对图像、地图、图表等数据进行语义理解和表示。图表与自然语言有很大的差异,难以在同一个机器阅读理解模型中进行建模。
文言文题通常需要结合现代汉语和文言文进行理解。文言文的句法和语义与现代汉语差异较大,需要分别进行建模。
(3) 依赖常识知识的问题。此类错误题目在27道错误题目中有两道。模型需要具备基本的历史、地理和生活常识知识。例如回答表6中第5题所需要的常识是“骑马是中国北方的习俗”。基于教材文档和练习题库构建的知识库难以覆盖这类常识知识。
4 结论
本文针对高考历史科目试题的自动答题任务,结合知识检索技术与机器阅读理解模型,构建了高考历史科目试题自动答题系统,并使用高考历史科目试题进行了实验。
实验结果显示,本文设计的高考历史科目自动答题系统是有效的。本系统在高考历史科目考试中的答题性能可达到60分以上(满分100分),并在GH577数据集上取得了优于基线系统的答案正确率。消融实验的结果验证了知识检索模块能够有效检索问题相关的知识。进一步的实验和分析说明了本系统设计的合理性。
经过错误分析,发现本系统还有一些不足: 本系统目前难以解决多模态、多语言类问题;部分题目依赖从具体描述到抽象概念的推理和多步推理,本系统使用的机器阅读理解模型在这方面能力较弱;本系统使用的知识语料库尚不完善,没有覆盖相关的历史、地理和生活常识知识。后续可以从图表和文言文题的针对性训练、增强推理能力和知识库构建等方面寻求解决方案。
猜你喜欢
数学小灵通(1-2年级)(2022年6期)2022-06-17
数学小灵通(1-2年级)(2022年5期)2022-06-01
数学小灵通(1-2年级)(2022年3期)2022-03-17
新世纪智能(数学备考)(2021年5期)2021-07-28
数学小灵通(1-2年级)(2021年3期)2021-04-13
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
中学生数理化(高中版.高考数学)(2020年5期)2020-06-02
试题与研究·教学论坛(2017年27期)2017-11-28
成长·读写月刊(2017年8期)2017-08-12
文理导航(2017年2期)2017-02-16
