
基于mBagging的随机森林*
2022-06-16 14:49:32郑金萍刘赵发胡珍珍李泽南刘汉明汪廷华胡声洲
赣南师范大学学报 2022年3期
郑金萍,刘赵发,胡珍珍,李泽南,黎 姿,刘汉明,汪廷华,胡声洲
(赣南师范大学 数学与计算机科学学院,江西 赣州 341000)
1 引言
集成学习(Ensemble Learning)克服了单个模型或者某一组参数的模型分类效果不够理想的不足,通过训练多个基学习器并对结果加以集成,达到了提高模型的稳健性和分类精度的效果[1].随机森林(Random Forest, RF)[2]便是典型的集成案例,利用Bagging[3]的组合方法,将多棵决策树组合成森林,随机森林具有训练模型泛化能力强、对部分特征缺失的容忍度高、训练高度并行化而适用于大数据集等特点,使其得到了迅速的发展,应用领域包括医学、管理学、经济学等.在经济管理方面最突出的是对客户流失的预测[4],而医学更多的是对疾病的风险的预测以及病患者的易感性[5].利用Bagging对决策树的集成,随机森林提高了决策树分类器的分类精度与稳健性[2],但Bagging在面对大数据挖掘时存在算法时间较长等不足[6-7].
Liu等基于Bagging 算法原有的良好性能提出一种改进的Bagging 组合方法mBagging( modified Bagging)[6-7],并通过以最大信息系数(Maximal Information Coefficeint, MIC)[8]作为基学习器进行组合,应用于全基因组关联研究(Genome-wide Association Study, GWAS)进行了仿真实验,结果表明mBagging 的算法时间仅为Bagging的 20%、统计功效提高了15% ,同时假阳率也降为Bagging的69%[6-7]明显优于作为对比算法的PLINK[9]、BEAM[10]和BoNB[11].本文采用全基因组SNP仿真数据集的实验表明,与传统随机森林相比,改进的随机森林在GWAS中获得了更低的OOB (out-of-bag)袋外错误率和更快的运算速度.
2 mBagging 原理
在预测能力方面,组合分类器普遍优于单个分类器,在神经网络集成[12]、随机森林[2]和选择性集成[13]等方法中已经得到验证.mBagging与Bagging的不同主要体现在对原训练集的重抽样过程,mBagging抽样设置袋内数据集(训练集)远小于袋外数据集(测试集)个数,没有采用传统Bagging的袋内数据集与袋外数据集一一对应的做法.研究表明Bagging的计算复杂度仅与数据集个数有关[7].mBagging的思想可以用下式表示[6-7]:
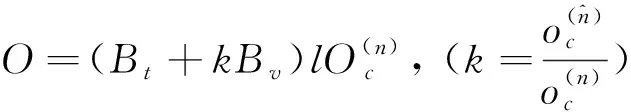
(1)


3 数据与方法
3.1 数据
参考已有工作[6,14]的GWAS研究中复杂疾病风险SNP(Single Nucleotide Polymorphism)的挖掘,利用PLINK工具集生成了实验仿真数据集.数据集中对照与病例样本各1 000个,并设置了1 980个疾病无关SNP和20个疾病风险SNP.
3.2 决策树
决策树[15]是一种有代表性的机器学习分类算法,它通过训练好的决策树模型中的树形结构节点与待分类的输入数据作匹配分析(以进行类别预测).它主要应用于离散型数据挖掘,能够在没有先验知识的情况下提取数据中蕴含的规则, 比神经网络等方法更具解释性,是一种非线性模型却具有简单、高效的优良性能[15].但决策树存在易过拟合等缺点[15],通过Bagging组合决策树的随机森林,改善了这一问题,进而提高了其分类性能.
3.3 袋外数据分类错误率与特征变量重要性评估
随机森林可以在内部进行评估[2],误差的无偏估计只需要基于一个独立的测试集,这是它优于决策树的一大特点. 一般来说,随机森林度量特征重要性分为利用基尼指数计算节点不纯度减少和OOB袋外错误率表示的平均准确率减少的两种方法[2].基尼指数计算节点不纯度减少具有更高的稳定性[16],但对具有高基数的数字特征和分类特征有倾向性,并且对于具有相关的特征,只会选择其中之一而忽略其它(可能得到有偏差的结论)[17].OOB袋外错误率表示的平均准确率减少应用范围更加广泛,能够衡量变量单独分类能力以及变量间相互作用分类能力[18],但当分类数据不平衡时,会严重低估相关预测变量的重要性[19].
4 实验结果
根据Liu等采用的比例Bt/Bv≈1/20,仿真实验中对mBagging的Bt和Bv分别取值为20和400,同时设置两组Bagging抽样Bt=Bv=400、Bt=Bv=20作为对照组,用于对比实验[14].
实验利用MATLAB实现Bagging、mBagging组合决策树的随机森林算法.
4.1 OBB袋外错误率
分别对经典的随机森林设置Bt=Bv=400、Bt=Bv=20两种重抽样数,与基于mBagging的随机森林进行对比实验,采用OOB袋外错误率作为重要性度量.3种方法的平均OOB袋外错误率如图1所示.结果显示基于mBagging的随机森林的平均OOB袋外错误率是两种经典的随机森林的平均.
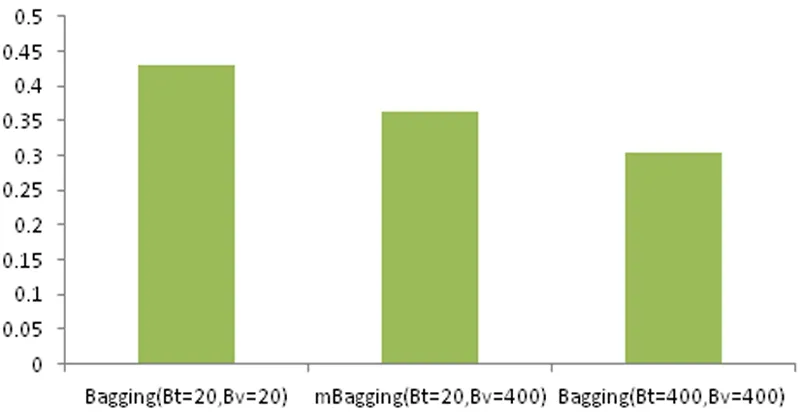
图1 基于Bagging与mBaggging的随机森林平均OOB袋外错误率
4.2 算法运行时间
实验硬件平台是Intel Core i3-4170 CPU(3.70 GHz) 、4 GB内存、集成显卡,软件平台Windows 7 x86(单线程).实验得到3种随机森林方法的算法运行时间见表1.

表1 算法时间(a)(ms/数据集)
4.3 特征变量重要性排列
除OOB袋外错误率外,我们还采用基尼指数计算节点不纯度减少得到各个特征变量的重要性(即SNP与疾病的相关性).表2显示了Bt=Bv=20和Bt=Bv=400的两种经典随机森林与基于mBagging的随机森林对风险SNP正确识别个数,同时可得到对风险SNP判断准确率分别是80%、95%以及90%.

表2 前20个疾病风险SNP判断正确数
5 讨论
图1显示,抽样次数为20的经典随机森林平均OOB袋外错误率远大于抽样次数为400的经典随机森林(0.43 vs. 0.30,平均0.37),基于mBagging的随机森林则处于它们之间(0.36,相当于前两者的平均);从表1容易得到,基于mBagging的随机森林的算法时间是两种经典随机森林均值的53.09%.另外,由表2得到的风险SNP准确率可知,基于mBagging的随机森林比两种经典随机森林的均值提高了3%.这些实验结果表明,与经典随机森林相比,基于mBagging随机森林的平均OOB袋外错误率相当,但算法时间可以得到明显的减少,算法准确率也有提高,总体优于经典随机森林.
基于mBagging的随机森林通过调整自举抽样过程中训练集与测试集的个数,在保证算法错误率与准确率不劣于经典随机森林的前提下,大大缩短了算法时间,为组合方法应用于大数据挖掘提供了新的借鉴.
猜你喜欢
中国卫生统计(2023年5期)2023-11-30 01:40:14
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
中国交通信息化(2018年5期)2018-08-21 03:37:40
教师·中(2017年3期)2017-04-20 21:49:49
试题与研究·教学论坛(2016年27期)2016-08-11 14:57:08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
