
适用于非合作目标捕获的轻量级位姿估计网络
2022-06-16 05:24周青华何世琼
计算机工程 2022年6期
蒋 明,陈 雨,周青华,袁 媛,何世琼
(1.四川大学 电子信息学院,成都 610065;2.四川大学 空天科学与工程学院,成都 610065)
0 概述
随着人类开发太空进程的加快,大量卫星、火箭等航天器被发射到太空中执行各项任务,但由于航天器可能会面临意外故障、燃料耗尽等问题,导致这些航天器由合作目标转化成非合作目标,威胁着太空安全。因此,回收这些非合作目标具有维护空间安全及节约资源的现实意义[1]。研究人员提出在轨服务技术[2],利用空间特种机器人来完成在轨维修、清理空间碎片等高危险性空间任务,其中,非合作目标捕获是在轨服务技术的一项关键技术。在特种机器人对非合作目标实施在轨抓捕之前,需要对目标航天器进行识别与定位,为下一步捕获任务做准备。但是在太空环境中,相机对太阳光照等外界信息非常不敏感,且机器人面临的是未知的非结构化环境,传统的目标检测算法需要人为提取特征,泛化能力较差,在非合作目标检测任务上表现不佳。
自2012 年卷积神经网络CNN 被应用于图像处理领域并一举夺得ImageNet 图像识别比赛冠军之后[3],基于CNN 的目标检测算法进入了快速发展阶段。由于其具有自动提取特征、泛化能力强、稳定性好等优点,因此在非结构化环境中表现了巨大的优势。基于CNN 的目标检测算法大致可以分成2 大类型:第1 类是以区域推荐法获取不同尺寸的二阶段网络,其精度较高,但由于需要产生大量候选框,所以速度慢,实时性较差,主要代表算法有R-CNN[4]、Fast-RCNN[5]、Mask-RCNN[6]等;第2 类是一阶段网络,直接端到端进行预测,不需要区域推荐,直接回归产生物体的类别概率和位置信息,因此速度快,模型较小,但精度相对较低,代表性的算法有YOLO[7]、SSD[8]。
大部分空间非合作目标的运动规律是未知的,甚至很大可能是高速运动的,且均具有一定的非合作性。受机载处理器计算能力的限制,非合作目标的复杂识别算法无法在航天器上独立完成[9],图像处理算法的设计和实现面临着准确性、及时性和小型化的矛盾,因此对空间机器人非合作目标抓捕任务的目标检测算法准确性和实时性均提出了较高要求[10]。此外,传统的2D 目标检测只能得到空间位置,无法估计物体的姿态,不太适用于机械臂捕获操作。针对这些问题,YU 等[11]提出利用检测目标矩形框长宽比进行抓取姿态的粗略估计,但没有考虑目标物体位置对捕获姿态的影响,且估算姿态太过简单,很多估计情况不符合现实场景。
本文基于YOLO 设计一种YOLO-GhostECA 网络,通过GhostBottleneck 网络减少特征图冗余,并利用高效通道注意力模块ECA 提取核心特征图,从而在保持检测精度不下降的同时,提升检测速度及降低模型大小。此外,提出一种定性估计非合作目标抓取姿态的方法,以弥补传统2D 目标检测算法无法估计抓取姿态的缺陷。
1 轻量级目标检测识别
1.1 YOLOv5s 目标检测网络
由于YOLO 网络兼顾实时性和准确性,因此成为了工业界落地最好的目标检测网络之一,在这之后相继提出了YOLOv2[12]、YOLOv3[13]、YOLOv4[14]以及各种YOLO 网络的变种。GLENN 等[15]开发出的YOLOv5,成为YOLO 网络实现版本中最优秀的网络之一。YOLOv5s 网络由骨干网络、瓶颈层、检测层3 大模块组成,如图1 所示。

图1 YOLOv5s 网络模型结构Fig.1 Network model structure of YOLOv5s
骨干网络的主要作用是提取特征,由Focus[16]、CSPDarknet53[14]、SPP[17]组成。其中Focus 为切片操作,能够替换卷积操作,减少卷积所造成的特征信息损失。CSPDarknet53 主要进行网络特征提取,该网络由跨层局部连接CSP[18]构建而成,可以增加网络提取特征的能力,降低计算瓶颈和内存成本。SPP是空间特征金字塔池化结构,此结构能扩大感受野,实现局部和全局特征融合,丰富特征图的信息。
瓶颈层用来融合不同尺寸特征图及提取高层语义特征,由PANet网络组成。PANet网络可以将特征图自上而下以及自下而上进行特征融合,以减少信息损失[19]。
检测层将瓶颈层产生的高层语义特征用于分类和回归出物体的类别和位置,由YOLOv3Head[13]组成。YOLOv3Head 有3 个检测头,分别可以检测大、中、小物体,很好地克服了一阶段检测小物体精度低的缺点。
1.2 YOLO-GhostECA 轻量级目标检测网络
传统的深度卷积网络模型一般使用大量常规卷积对图像进行特征提取,但这需要消耗大量的算力。2020 年1 月,华为诺亚方舟实验室HAN 等[20]在观测常规卷积中间特征图时发现很多通道的特征图十分相似,这说明利用常规卷积提取出来的特征图在一定程度上是存在冗余的。他们猜想并不需要进行完整的卷积运算得到需要的特征图,而只需要用常规卷积去获取一部分特征图即可,因此提出了GhostNet 网络。该网络可以用更少的参数来生成更多特征,能够减少特征图冗余,从而达到减少网络模型大小和计算量的目的。GhostNet 网络的相关结构原理如图2 所示,其中,图2(b)的GhostBottleneck 由图2(a)的GhostModule 网络构成,GhostNet 网络由图2(b)的GhostBottleneck 网络构成。
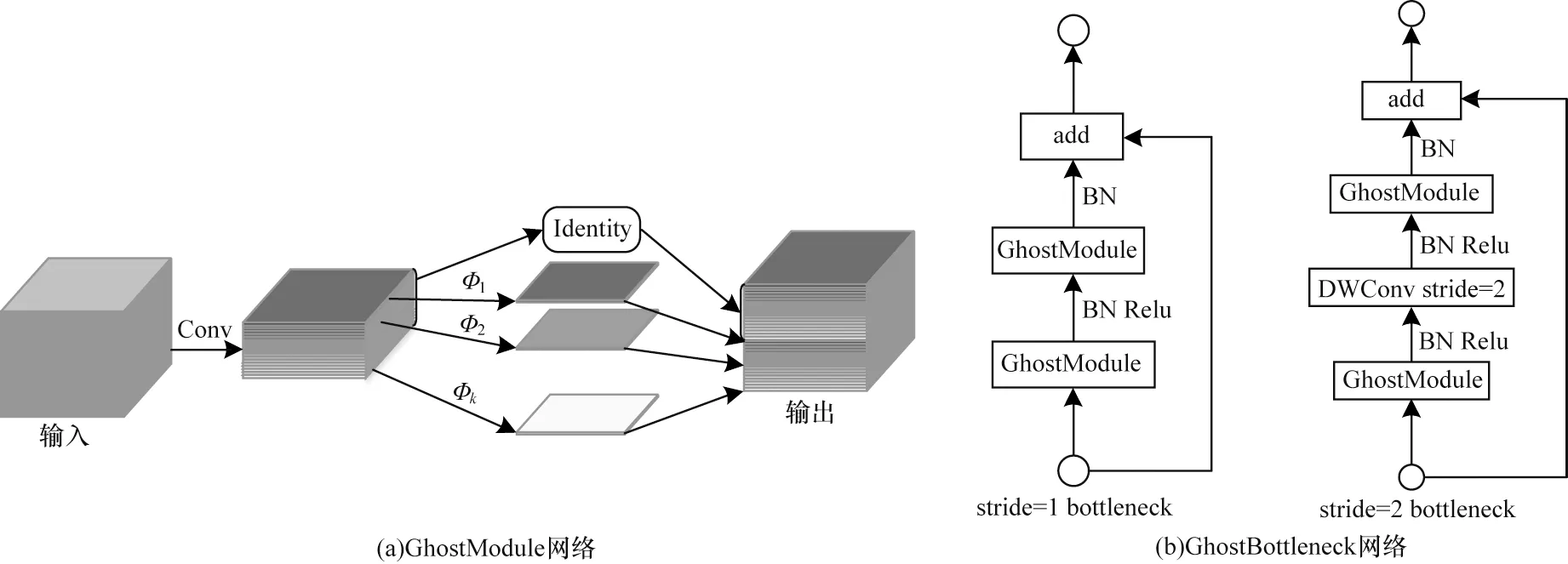
图2 GhostModule 网络及GhostBottleneck 网络的结构Fig.2 Network structure of GhostModule and GhostBottleneck
GhostModule 网络的具体实现原理如图2(a)所示,与常规卷积不同的是它只需要利用常规卷积运算得到半数通道的特征图,使用一系列廉价的线性运算对这半数通道的特征图进行处理,并生成幻影特征图,最后将生成的幻影特征图与原始卷积得到的半数通道特征图合并,构成与常规卷积相同通道数的特征图,此特征图可以近似于原始的完整特征图,但是计算量和参数量却减少了很多。此外,HAN等利用GhostModule 网络设计了图2(b)中2 种GhostBottleneck 网络结构,其中 stride=1 的GhostBottleneck 网络与步长为1 的CSPConv 网络效果相同,stride=2 的GhostBottleneck 与步长为2 的CSPConv 网络效果相同,因此GhostBottle 网络可以替换常规卷积在网络模型中进行特征提取。本文利用GhostBottleneck 网络替换CSPBottleneck 网络,并重新构建出了GhostDarknet 网络作为YOLO-Ghost的主干网络。为进一步提升精度,本文引入了高效通道注意力(Efficent Channel Attention,ECA)[21]模块,并将ECA 应用于PANet 网络中,形成具有注意力机制的PANet 网络,即ECA-PANet 结构。该结构能够加强特征融合,在获得更多想要的图像特征的同时,忽略不需要的特征,与其他通道注意力模块相比,ECA 模块可以在不引入多余参数进行计算的情况下,提升模型的精度。
以YOLOv5s 网络为基础,结合上述提出的几个新型模块构建出了新型轻量级目标检测网络YOLO-GhostECA,该网络可以利用少量的参数获取更多需要的特征图,其结构如图3 所示。
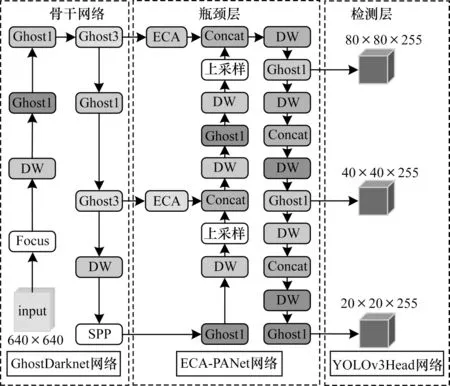
图3 YOLO-GhostECA 网络结构Fig.3 Network structure of YOLO-GhostECA
1.3 YOLO-GhostECA 网络的损失函数
原YOLOv5 中IoU 损失函数使用的是GIoUloss,但其只考虑到了重叠区域和非重叠区域,没有考虑矩形框对IoU 的影响。因此YOLO-GhostECA使用Complete-IoU(CIoU)[22]损失函数,该损失函数同时考虑到了矩形框的长宽比、目标与anchor 之间的距离、重叠率、尺度等因素,这可以进一步提高模型的性能,加快损失函数收敛。CIoU 损失函数如式(1)所示:

其中:α是权重函数。
计算方法如式(2)所示:

其中:υ是度量长宽比的相似性。
υ的计算公式如式(3)所示:

其中:ρ(b,bgt)代表计算预测框中心点b和真实框中心点bgt的欧氏距离;c表示能够同时包含预测框和真实框的最小闭包区间的对角线距离。
2 空间定位与姿态估计
2.1 空间定位
上述目标检测算法只能获得非合作目标在图像坐标系中的位置,但是机械臂抓取目标需要基于自身基座坐标系下的三维点信息。为完成抓取任务,还需建立相机成像模型,如图4 所示,其中:OcXcYcZc是相机坐标系;OpXpYp是图像坐标系;OwXwYwZw是世界坐标系;P(xw,yw,zw)是物体在世界坐标系下的坐标;P(u,v)是物体在像素坐标系下的坐标。
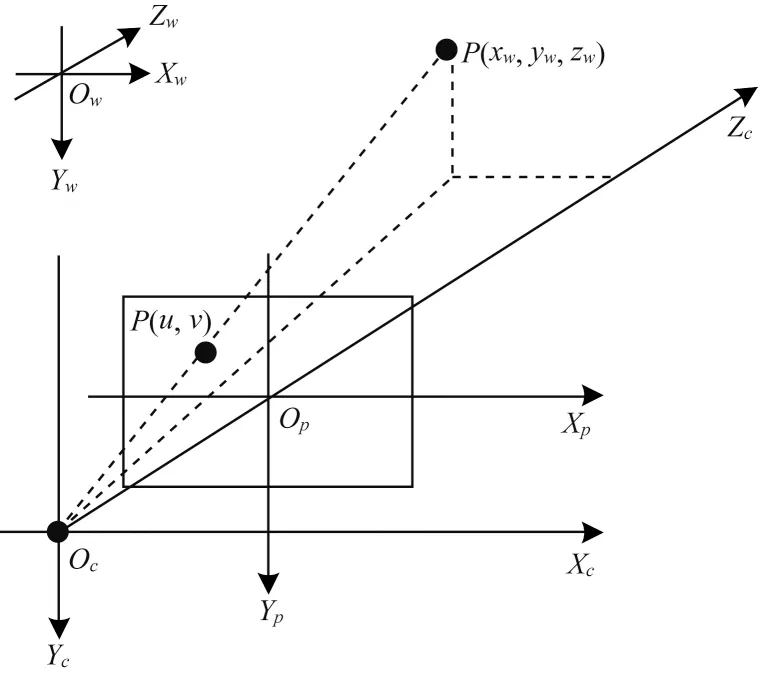
图4 相机成像模型Fig.4 Camera imaging model
借助相机成像模型可建立目标检测得到的二维图像坐标和机械臂抓取的三维世界坐标之间的映射关系,如式(4)所示:
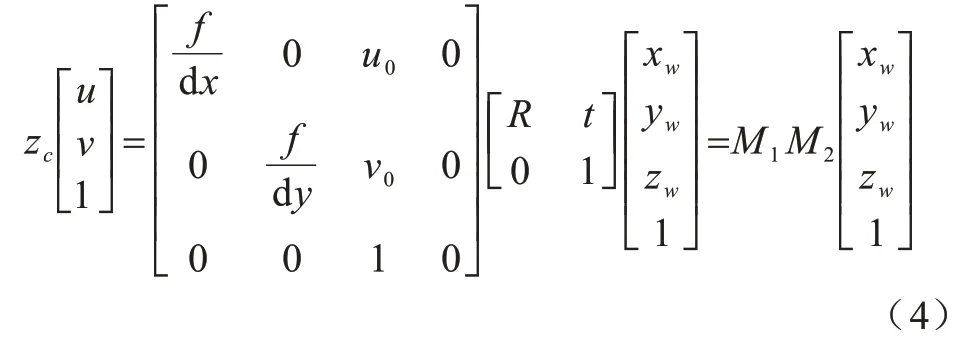
其中:M1是摄像机内部参数矩阵,用来将像素坐标转化到相机坐标系下,是一个由二维转三维的过程,可由相机标定张正友棋盘格标定法[23]得到;M2是摄像机外部参数矩阵,能够将相机坐标转化到世界坐标系下(本文的世界坐标系定义在机械臂的基础坐标系处),一般由手眼标定[24]得到;zc是深度值,由Intel Rense D435i 深度相机根据结构光与双目立体视觉融合的混合测距技术实时计算得到。当知道以上相关参数和目标检测得到的物体像素坐标后,即可使用式(4)完成对目标物体的空间定位。
2.2 姿态估计
空间定位可以得到目标物体的三维空间坐标,但为了合理引导机器人捕获目标物体,姿态估计是一个重要的过程。事实上,目标检测得到的结果数据中已经包含了一些物体的姿态信息,例如当物体呈现不同姿态时,其检测得到的矩形框尺寸比例将呈现不同的数值。为进一步利用目标检测的结果,本文提出一种通过目标检测得到的非合作目标信息(u,v,w,h,class)来粗略预估机械臂抓取姿态的新型方法。该方法将抓取姿态Φ大致分成了6 种,即中正抓姿态ΦA、中偏抓姿态ΦB、上抓姿态ΦC、下抓姿态ΦD、左抓姿态ΦE和右抓姿态ΦF。估算的6种抓取姿态的姿态参数如表1所示。

表1 6 种抓取姿态的相关参数(绕固定轴旋转)Table 1 6 parameters related to grasping attitude(rotating around a fixed axis) (°)
目标物体的抓取姿态Φ可以由式(5)和式(6)估计确定:
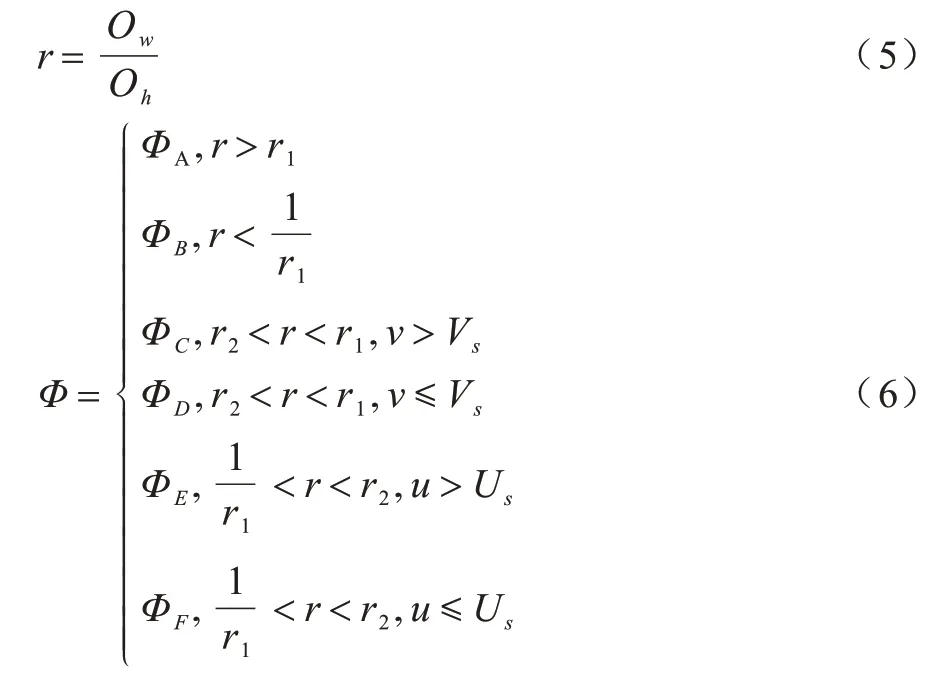
式(5)是计算矩形宽高比例的公式,其中:Ow为矩形框的宽;Oh为矩形框的高。式(6)是计算目标物体抓取姿态的公式,其中:u、v为目标检测得到的物体像素坐标;r1、r2为常数,可以根据实际物体class 的长宽比例进行粗略计算,多个物体即有多个值;Vs用来确定抓取的上下姿态;Us用来确定抓取的水平方向的姿态,这2 个参数可以将笛卡尔空间划分成4 个区域,根据目标检测像素点的位置可判定物体处在4 个区域中的位置,Us、Vs的值取决于相机与机械臂末端初始位置的空间几何关系,即机械臂在初始位置时在相机像素坐标系下的映射点坐标。
6 种抓取姿态的估计示意图如图5 所示。

图5 6 种抓取姿态的估计示意图Fig.5 Schematic diagram of estimation of six grasping postures
3 实验结果与分析
3.1 实验仿真系统
本文利用7 自由度机械臂等设备搭建了地面仿真实验平台。实验中先将航天器模型用细绳系紧,悬挂于空中,并将实验室的灯熄灭,只留1 个补光灯,给非合作目标补光,以此来模拟太空环境暗黑失重环境。实验仿真流程如图6 所示,先使用YOLOGhostECA 进行非合作目标识别,再根据目标检测结果使用第2 节的方法估计物体的位姿,最后将估计的目标物体位姿信息(x,y,z,W,P,R)传送给机械臂的控制器,机械臂控制器控制电机进行相应驱动,即可对目标物体进行捕获操作。本文所有实验均在表2 所示实验条件下进行。

图6 实验仿真流程Fig.6 Procedure of experimental simulation

表2 实验参数Table 2 Experimental parameters
3.2 非合作目标识别
非合作目标识别的具体步骤如下:
步骤1数据集的制作。由于目前没有非合作目标航天器的公有数据集,因此在实际中对太空环境黑暗且失重环境进行现实模拟,采集拍摄387 张多姿态多场景的航天器模型图片,并利用采集的图像数据进行联合训练,部分数据集如图7所示。

图7 非合作目标数据集示例Fig.7 Examples of non-cooperative target dataset
步骤2训练策略。实验中使用了多种训练策略来提升网络的性能。
1)anchor 大小。利用K-mean 聚类算法找出数据集中较好的9 个anchor 尺寸,有助于提高平均精度均值(mean Average Precision,mAP)。
2)超参数演进。利用基因遗传算法训练200 代,找到较好的超参数后,利用超参数演进得来的超参数对网络进行训练,使网络能够迅速得到全局最优解,让模型达到较好的效果。
3)学习率lr。利用类余弦退火进行学习率学习,减少陷入局部最优解的情况发生。
4)数据增强操作。在训练过程中对数据进行随机裁剪、放大等操作来增大数据集,使每一个epoch训练的图都不是同一张图,在数据集有限的情况下有效提高模型的泛化能力。
步骤3性能测试。通过上面的策略进行模型训练,完成后在模型大小、运行速度、模型参数量(即过程中梯度更新数量)、模型运算复杂度(即每秒浮点数运算次数)等多方面对网络模型性能进行分析评估,其结果如图8 所示。由图8(a)可知,YOLOv5-GhostECA 模型大小仅2.9 MB,相较于YOLOv5s 减少了80.4%。图8(b)显示YOLO-GhostECA 在GPU上运行时间仅2.7 ms,即帧率高达370 frame/s,GPU运行速度相对于YOLOv5s 提升了49.1%。图8(c)显示YOLOv5-GhostECA 模型在CPU 上的运行时间为320.6 ms,相对于YOLOv5s 的460 ms 来讲,运行时间减少了30.3%。图8(d)显示YOLO-GhostECA 的mAP 为0.896,依然保持在较高值,相对于YOLOv5s的mAP 仅下降了0.2%。由图8(e)可知YOLOv5s 的模型参数大小为7.468 MB,而YOLO-Ghost 和YO‐LO-GhostECA 均只有1.313 MB,新提出的YOLOGhost 相较于YOLOv5s 参数量减少了82.4%,而融合ECA 注意力机制的YOLO-GhostECA 参数量相比于YOLO-Ghost 保持不变。图8(f)所示为模型的运算复杂度,YOLOv5s 为17.5 GFLOPs,YOLO-Ghost 和YOLO-GhostECA 均为3.7 GFLOPs,可以看出YO‐LO-Ghost 相比于YOLOv5s 运算复杂度降低了78.9%,且融合的ECA 模块并没有增加运算复杂度。综上分析,本文提出的YOLO-GhostECA 模型在GhostDarknet 基础上结合高效通道注意力模块ECA的方法在保持精度的同时,使模型的参数量和运算复杂度均大幅降低,且减小了模型尺寸,提升了运行速度。

图8 不同模型的性能参数对比Fig.8 Comparison of performance parameters of different models
步骤4模型效果测试。利用训练好的YOLOGhostECA 进行非合作目标识别实验,实验结果如图9 所示。可以看出,该模型能够准确地识别和定位出非合作目标物体,且在多姿态多场景下,其预测准度分数均保持较高水平。

图9 本文网络模型测试结果Fig.9 Test results of network model in this paper
3.3 非合作目标位姿估计
先采集-20 张以上不同姿态的棋盘格图片,然后利用张正友棋盘格标定法[23]在Matlab 的cameracalib中进行标定得到相机内参。相应地采集40 张以上的RGB 图以及深度图,利用Tsai 方法[24]进行手眼标定得到相机外参。
利用标定的结果和YOLO-GhostECA 检测网络,通过第2 节提出的位姿估计方法进行非合作目标位姿估计,其中姿态估计公式(6)中的r1、r2通过分析非合作目标数据集得到,分别为3.0 和1.0,Vs、Us根据相机空间几何位置分别设定为320 和360。根据该位姿估计算法估计的位姿结果见表3。

表3 非合作目标位姿估计的结果Table 3 Results of pose estimation of non-cooperative targets
3.4 非合作目标捕获
将上述得到的位姿估计结果通过EtherCAT 发送给织女机械臂控制器,控制机械臂进行非合作目标捕获,捕获实验效果如图10 所示。

图10 非合作目标捕获的实验效果Fig.10 Experimental effect of capturing non-cooperative targets
由图10 可知,本文提出的位姿估计算法可以对非合作目标进行准确的空间定位和粗略的姿态估计,其位姿估计结果可以合理地引导机械臂对非合作目标进行捕获。
4 结束语
本文设计一种适用于非合作目标捕获的轻量级位姿估计网络,将深度学习YOLOv5 网络应用于空间非合作目标智能识别与捕获任务中,并基于GhostNet 网络设计GhostDarknet 骨干网络,减少冗余特征图的提取,在基本保持精度不变的情况下,减少网络模型大小,提高模型运算速度。此外,提出一种利用YOLO-GhostECA 检测结果来估计物体抓取位姿的方法,并通过深度相机Intel RealSense D435i、非合作目标缩小模型和7 自由度冗余机械臂搭建地面仿真实验平台。实验结果表明,该网络在非结构化环境中能很好地完成非合作目标捕获任务。下一步将通过扩充数据集提升网络的精度,并将训练好的网络部署到嵌入式设备中,对实时性和准确度进行验证。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
中国惯性技术学报(2020年4期)2020-12-14
学生天地(2020年3期)2020-08-25
浙江海洋大学学报(自然科学版)(2020年5期)2020-06-19
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电子技术与软件工程(2019年6期)2019-04-26
汽车观察(2018年9期)2018-10-23
科技与创新(2018年12期)2018-06-22
北京航空航天大学学报(2018年1期)2018-04-20
