
基于ALBERT-BGRU-CRF 的中文命名实体识别方法
2022-06-16 05:24李军怀陈苗苗王怀军崔颖安张爱华
计算机工程 2022年6期
李军怀,陈苗苗,王怀军,崔颖安,张爱华
(1.西安理工大学 计算机科学与工程学院,西安 710048;2.中铝萨帕特种铝材(重庆)有限公司,重庆 401326)
0 概述
命名实体识别(Named Entity Recognition,NER)是指从大量待处理文本中识别出人名、地名、组织机构名等具有特殊意义的一类名词,又称为实体抽取,是信息获取、知识图谱构建、问答系统、机器翻译、信息检索等任务的基础[1]。命名实体识别方法主要分为基于词典和规则、基于传统机器学习、结合深度学习和机器学习3 类。2016 年,XIE 等[2]提出结合人工编写规则和启发式算法的命名实体识别方法,实现了从大量非结构化文本中抽取公司名称。依赖规则的命名实体识别方法一方面对人力需求大,另一方面规则的不通用性导致方法泛化能力较差。在NER 任务中所应用的机器学习方法包括最大熵马尔可夫模型(Maximum Entropy Markov Models,MEMM)[3]、条件随机场(Conditional Random Field,CRF)[4]等。MEMM 条件概率统计采用建立联合概率的方式,局部归一化导致结果容易陷入局部最优。CRF 在统计全局概率、位置标记的同时利用内部特征和序列信息,解决了MEMM 容易陷入局部最优的问题。深度学习技术的广泛应用使得NER 任务几乎不再需要人工特征。2011年,COLLOBERT 等[5]提出基于神经网络的命名实体识别方法,该方法对每个单词给定固定大小窗口,而未考虑长距离词之间的信息。2016 年,CHIU 等[6]提出双向LSTM-CNNs 模型克服了神经网络的限制。同年,MA 等[7]将模型进一步优化为BiLSTM-CNNs-CRF,通过加入CRF 模块以减少错误标签序列的输出。
由于中文表述与英文表述有所区别,不存在空格、首字母大写等明确标识分词的符号并且存在实体嵌套、英文缩写、表述不规范等问题,因此给中文命名实体识别带来了巨大挑战。本文提出一种基于ALBERT-双向门控循环单元(Bidirectional Gated Recurrent Unit,BGRU)-CRF 的中文命名实体识别方法,在ALBERT 层对输入文本完成词嵌入获取动态词向量以解决一词多义的问题,在BGRU 层进一步学习长距离语义信息,在CRF 层进行解码并完成实体识别任务。
1 相关工作
1.1 预训练语言模型
预训练语言模型是已训练完成具有对应参数的深层网络结构,利用大规模无标注语料训练得到,通常作为一个模块应用于下游任务。
2013 年,MIKOLOV 等[8]提出用于表征文本的Word2Vec 词向量技术。Word2Vec 将词转化为向量,所提取特征是上下文无关的,对于下游任务的支撑作用有限。2018 年,PETERS 等[9]提出ELMo 预训练语言模型。ELMo 内部采用双向LSTM 有效捕捉上下文语义,提取文本深层特征,基于大量文本训练得到针对下游任务的通用语言模型,解决了静态词向量无法理解一词多义的问题。2019 年,DEVLIN等[10]提出的BERT 动态预训练语言模型成为自然语言处理领域的重要里程碑,其在多个典型下游任务中取得较好效果。同年,谷歌发布了BERT 的改进模型ALBERT[11],该模型参数更少且效果与BERT相当。本文方法基于ALBERT 预训练语言模型。
1.2 中文命名实体识别
中文命名实体识别任务的难点在于:1)区别于英文,不存在空格、首字母大写等明确标识分词的符号,增加了分词难度;2)表述多元化,常出现字母缩写、中英文交替等表述,其中英文描述会干扰中文命名实体识别。当前针对中文命名实体识别任务多数采用结合机器学习和深度学习的方法。
2016 年,刘玉娇等[12]采用深度学习的命名实体识别方法,通过卷积自编码器提取文本特征对中文微博语料库进行命名实体识别。2017 年,张海楠等[13]基于深度神经网络结合字特征和词特征,针对1998 人民日报标注语料库进行人名、地名和机构名识别,识别结果F1 值达到93.3%。2018 年:李雁群等[14]提出一种从中文维基百科条目中自动构建中文嵌套命名实体识别语料库的方法;JIA 等[15]使用深度神经网络与机器学习相结合的方法构建CNNBiLSTM-CRF 模型完成中文命名实体识别任务,在MSRA 数据集上F1 值达到90.95%;ZHANG 等[16]提出基于Lattice LSTM 模型的识别方法,在特征提取时利用字序列关系有效避免了分词错误的影响,该方法在微博、MSRA、OntoNotes 等数据集上F1 值均有所提升,在resume 数据集上F1 值达到94.46%;王蕾等[17]采用深度学习片段神经网络完成实体边界标注及分类,该方法在MSRA 数据集上总体F1 值达到90.44%。2019 年,石春丹等[18]提出基于BGRU-CRF的中文命名实体识别方法,充分利用潜在词特征和上下文信息,在MSRA 和OntoNotes 数据集上F1 值均有所提升。2020 年:赵丰等[19]基于CNN 和注意力机制提出基于局部注意力卷积的嵌入算法以降低中文命名实体识别任务对分词的依赖,该方法在MSRA、微博和军事文本数据集上F1 值均有所提升;李妮等[20]提出一种基于BERT 预训练语言模型结合IDCNN 和CRF 的方法,该方法在MSRA 数据集上F1值达到94.41%,且模型训练时间大幅缩短。
现有研究主要存在2 个问题:1)多数方法仅提取字符或词级别特征,而忽略长距离语义信息,导致无法提取文本语义信息;2)早期词嵌入工具生成静态词向量,导致无法处理一词多义的问题。针对以上2 个问题,本文提出一种基于ALBERT-BGRUCRF 模型的中文命名实体识别方法。该方法采用ALBERT 完成词嵌入以获取动态词向量,经过BGRU 学习上下文语义特征,并使用CRF 降低错误标签输出概率。
2 ALBERT-BGRU-CRF 模型
传统深度学习模型较多关注字符和词级别特征,而忽略长距离语义信息,导致无法提取语义信息和解决一词多义的问题。ALBERT 模型获取动态词向量解决了一词多义的问题,BGRU 捕捉双向语义使得模型更深层理解文本语义信息。本文构建的中文命名实体识别模型包括ALBERT 预训练语言模型、BGRU、CRF 等3 层,结构如图1 所示。
在ALBERT-BGRU-CRF 模型中,首先使用ALBERT 预训练语言模型对待处理文本进行编码完成词嵌入,获取动态词向量,然后采用BGRU 捕捉双向语义,最终将拼接后的向量输入至CRF 层并解码,得到实体标注信息,完成实体边界及分类识别。对于文本“教育部新出台”,经过模型识别,为“教”标注“B-ORG”标签表示组织机构名的首字,为“育”和“部”标注“I-ORG”标签表示组织机构名的其他字符,文本中其他非实体字符均标注“O”,识别结果为“教育部”是一个组织机构名。
2.1 ALBERT 层
预训练语言模型通常体量大,千万甚至亿级别的参数量给训练带来了较大困难。ALBERT 模型参数量远小于BERT 模型参数量。例如,在本文模型中所使用的albert_xlarge 参数量为60M,远小于bert_base 的参数量。ALBERT 主要在以下3 个方面做了改进:
1)嵌入向量参数因式分解
E表示词向量大小,H表示隐藏层大小,在BERT、XLNet、RoBERTa等预训练语言模型中E≡H,若E和H始终相等,提升隐藏层大小H,则词嵌入大小E也随之提升,参数规模为O(V×H)。ALBERT 采用因式分解的方法来降低参数量,在词嵌入后加入一个矩阵以完成维度变化,参数量从O(V×H)降低为O(V×E+E×H),当H≫E时参数量明显减少。
2)跨层参数共享
ALBERT 采用跨层共享参数的方式,示意图如图2 所示。
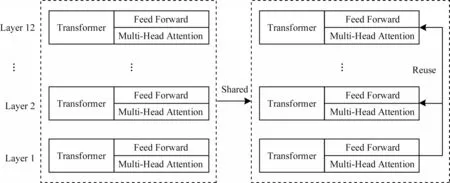
图2 跨层参数共享示意图Fig.2 Schematic diagram of cross-layer parameter sharing
一般地,Transformer 每一层(Layer)参数均是相互独立的,其中,多头自注意力层(Multi-Head Attention)和前馈神经网络层(Feed Forward)参数也是相互独立的,导致增加层数后参数量剧增。参数共享可采用仅跨层共享前馈神经网络参数,也可仅共享注意力层参数,ALBERT 模型则跨层共享(Shared)所有参数,相当于仅学习第一层参数,在其他所有层中重用(Reuse)该层参数,一方面减少了参数量,另一方面有效提升了模型稳定性。
3)句间连贯性预测
ALBERT 提出一种句间连贯性预测(Sentence-Order Prediction,SOP)方法,正样本表示与BERT 相同,是两个连贯的语句,负样本为原文中交换顺序的两个连贯句。SOP 中正负样本选自同一文档,仅关注句子之间的连贯性,避免主题影响,这使得模型在话语层面的学习具有更细粒度。
ALBERT-BGRU-CRF 模型将文本序列输入至ALBERT 进行编码,将ALBERT 模型词嵌入所得动态词向量作为BGRU 层的输入。
2.2 BGRU 层
门控循环单元(Gated Recurrent Unit,GRU)是新一代的循环神经网络(Recurrent Neural Network,RNN),与长短期记忆网络(Long Short-Term Memory,LSTM)类似,用以解决传统RNN 梯度消失和梯度爆炸问题。与LSTM 的区别在于,GRU 不再采用单元状态记录或传输信息,利用隐藏状态完成信息记录及传输。更新门和重置门控制GRU 单元最终输出信息,GRU 单元结构如图3 所示,其中,“+”表示加操作,“σ”表示Sigmoid 激活函数,“×”表示Hadamard 乘积,“tanh”表示Tanh 激活函数。
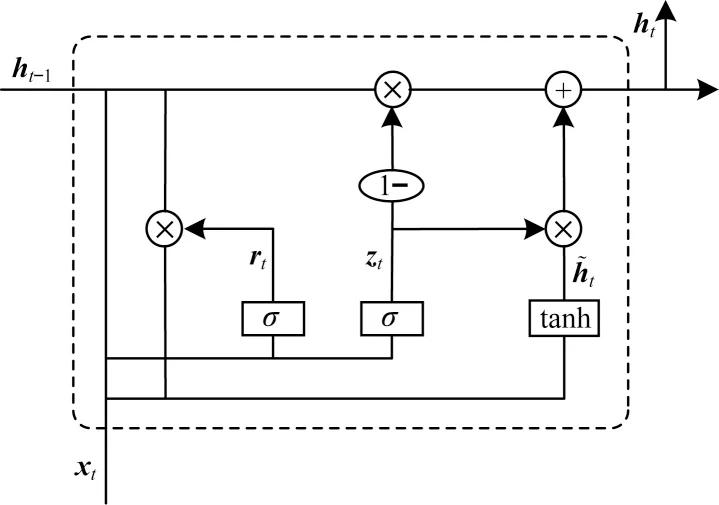
图3 GRU 单元结构Fig.3 Structure of GRU unit
GRU 参数更新计算公式如下:
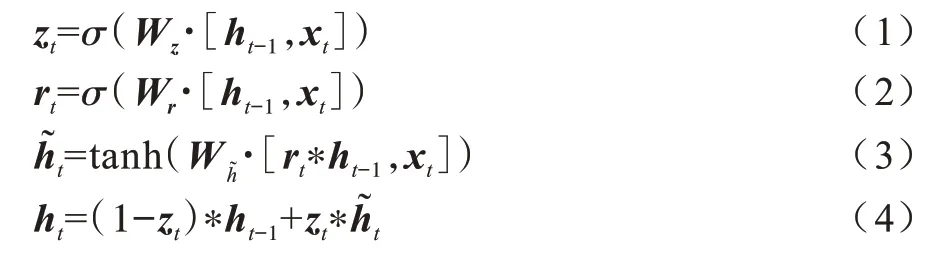
其中:zt为更新门的激活结果,以门控的形式控制信息的流入;xt为时间步t的输入向量;Wz为权重矩阵;ht-1表示保存时间步t-1 的信息;rt为重置门激活结果,计算过程同更新门类似;Wr为权重矩阵;表示当前时间步的记忆内容;ht表示当前时间步的最终记忆。
GRU 仅在一个方向上捕获信息。BGRU 用于提取上下文信息,是双向输入的GRU。文本序列正向输入至GRU 记录“过去信息”,文本序列反向输入至GRU 获取“将来信息”,对两者进行拼接合并以达到提取上下文信息的目的。
BGRU 层提取上下文信息得到更深层次的语义理解,获得发射分数矩阵输入至CRF 层。
2.3 CRF 层
CRF 是一种由输入序列预测输出序列的判别式模型,常见的条件随机场是指在线性链上特殊的条件随机场,线性链式条件随机场结构如图4 所示。
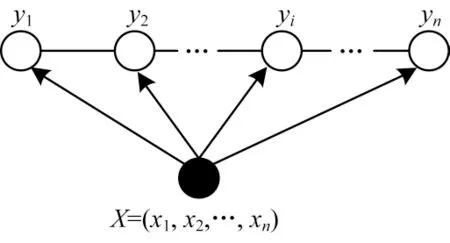
图4 线性链式条件随机场结构Fig.4 Structure of linear chain conditional random field
设两组随机变量X=(x1,x2,…,xn)和Y=(y1,y2,…,yn),线性链式条件随机场定义如下:
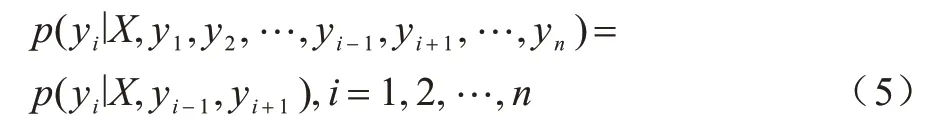
其中:X为观察状态;Y为隐藏状态。X和Y具有相同结构。
本文模型通过在CRF 中加入约束,以降低错误标签的输出概率。条件随机场判别计算过程如下:
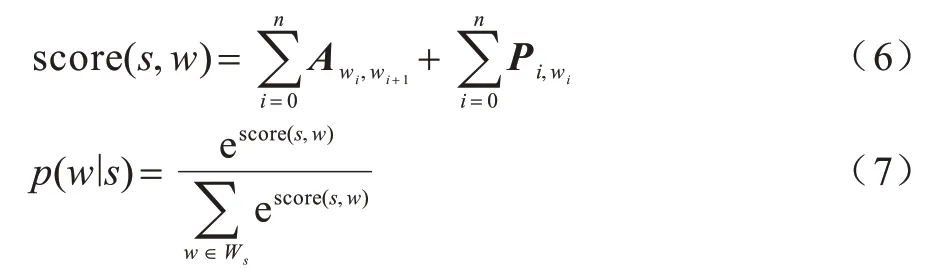
其中:score(s,w)表示综合评估分数;P表示从BGRU层得到的发射分数矩阵;A表示CRF 学习得到的转移矩阵;p(w∣s)表示输入序列与标签序列的对应概率;Ws表示所有可能的标签序列。
CRF 层结合BGRU 层输出的发射分数矩阵和学习得到的转移矩阵计算最终得分,得到输入序列与对应标签序列概率,通过维特比解码获得最优序列标注。


算法1 输入为文本序列,输出为标签序列。ALBERT 采用共享权值和分解矩阵的方式减少模型参数,有效降低了空间复杂度,BGRU 由于自身特殊的门单元设置,通常收敛速度更快,CRF 采用维特比算法完成预测任务,维特比算法利用动态规划求解最优路径降低复杂度。
3 实验与结果分析
3.1 数据集
实验使用微软亚洲研究院公开的MSRA[21]数据集,其中标注有人名(PER)、地名(LOC)、组织机构名(ORG)三类实体。在实验过程中,训练集包含20 864 句语料,验证集包含2 318 句语料,测试集包含4 636 句语料。
3.2 标注策略与评价指标
命名实体识别又称为序列标注,常用的标注策略包括BIO、BIOES、BMESO 等,本文实验过程中采用BIO 标注策略。对于文本中的实体,实体开始字符标注“B-Type”,实体其余字符标注“I-Type”,非实体字符标注“O”。
采用准确率(P)、召回率(R)和F1 值(F1)作为评价指标[22-23],其中,P表示正确识别的实体占全部识别出实体的比率,R表示正确识别的实体占应识别实体的比率,F1是结合了P和R的综合评价指标,具体计算过程如下:
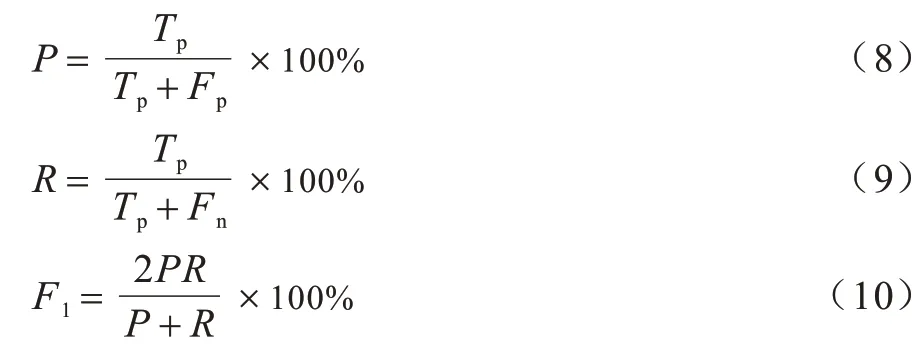
其中:Tp表示模型识别的正确实体数量;Fp表示模型识别的错误实体数量;Fn表示模型未识别出的实体数量。
3.3 实验环境与参数
实验训练过程的环境配置如表1 所示。
表1 实验环境配置Table 1 Experimental environment configuration
在训练过程中,使用Adam 优化器,输入文本最大长度为202,为防止过拟合设置Dropout 取0.5,具体参数设置如表2 所示。

表2 实验参数设置Table 2 Experimental parameter setting
3.4 实验结果对比
ALBERT-BGRU-CRF 模型在MSRA 数据集上的各类实体识别结果如表3 所示。
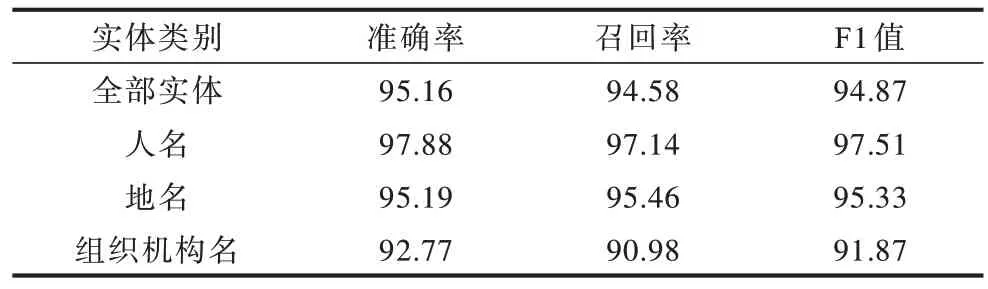
表3 命名实体识别结果Table 3 Named entity recognition results %
由表3 可知,本文方法在各类实体中均有较高的准确率,ALBERT-BGRU-CRF 模型结合上下文语义信息取得良好效果,针对人名的识别F1 值最高。ALBERT-BGRU-CRF 模型对于组织机构名的识别准确率、召回率偏低,主要原因为:1)存在组织机构名与地名歧义,例如句子“出席越秀艺苑和越秀书店开业典礼时”中“越秀艺苑”被标注为组织机构名,而模型识别其为地名,此类歧义表述导致识别率较低;2)组织机构名与地名存在大量嵌套,例如句子“陕西省铜川市商务局一位叫张宝玲的下岗女工在培训结束时”,其中“陕西省铜川市商务局”被标注为组织机构名,模型则识别“陕西省”为地名、“铜川市商务局”为组织机构名,此类嵌套描述也是影响模型准确率的原因之一。
为了验证ALBERT-BGRU-CRF 模型的有效性,设置对比实验。ALBERT-BGRU-CRF 模型与其他模型的命名实体识别结果对比如表4 所示。
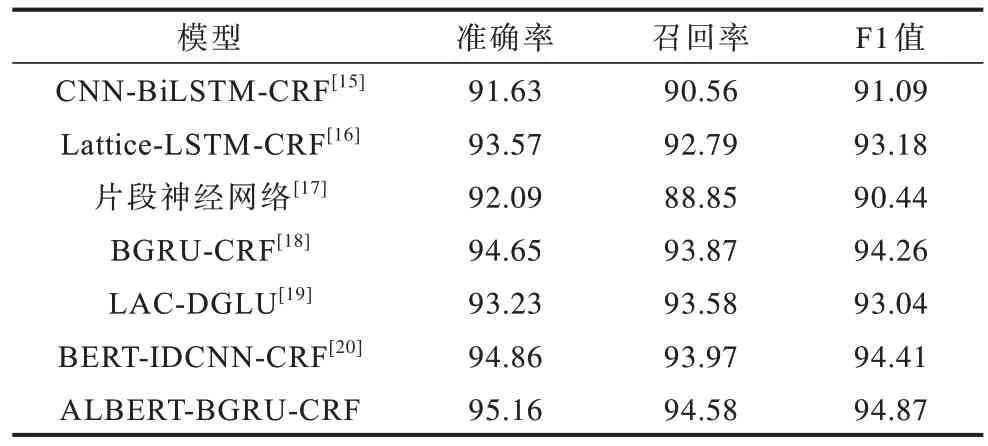
表4 不同模型命名实体识别结果对比Table 4 Comparison of named entity recognition results of different models %
由表4 可知:CNN-BiLSTM-CRF 模型、片段神经网络模型和Lattice-LSTM-CRF 模型与BERTIDCNN-CRF 模型对比发现,基于BERT 对文本进行词嵌入后识别效果更佳,本文模型采用ALBERT 完成词嵌入获取动态词向量,ALBERT 在保证识别效果的基础上参数量仅约为BERT 的1/2;Lattice-LSTM-CRF 模型与BGRU-CRF 模型对比发现,BGRU 通过对上下文语义更深层的理解有效提高了命名实体识别的F1 值;ALBERT-BGRU-CRF 模型相比于其他模型F1 值最高,相比于片段神经网络模型的F1 值提升了4.43 个百分点,相比于CNNBiLSTM-CRF 模型F1 值提升了3.78 个百分点。
4 结束语
本文提出一种用于中文命名实体识别的ALBERT-BGRU-CRF 模型,使用ALBERT 预训练语言模型对待处理文本进行编码完成词嵌入并获取动态词向量,解决了一词多义的问题,同时结合BGRU有效利用序列信息,使ALBERT-BGRU-CRF 模型能进一步理解上下文语义。实验结果表明,ALBERTBGRU-CRF 模型相比于传统命名实体识别模型准确率、召回率和F1 值均有所提升,并且在采用ALBERT 保留BERT 性能的同时,参数量仅约为BERT 的1/2,降低了模型训练过程中对内存等硬件设备的要求。由于ALBERT-BGRU-CRF 模型对于歧义实体和嵌套实体识别准确率较低,因此后续将从细化和完善实体标记规则以及更深层的语义学习等方面做进一步优化。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
高中生学习·高三版(2016年9期)2016-05-14
长江学术(2016年4期)2016-03-11
新高考·高二数学(2015年11期)2015-12-23
