
基于多关系网络的话题意见领袖挖掘
2022-06-16 02:32倪云鹏张燕平
数据采集与处理 2022年3期
段 震,倪云鹏,陈 洁,张燕平,赵 姝
(1.计算与信号处理教育部重点实验室,合肥 230601;2.安徽大学计算机科学与技术学院,合肥 230601;3.安徽省信息材料与智能传感重点实验室,合肥 230601)
引 言
社交网络在人们的日常生活中起着重要的作用。一些在线社区或网站,如博客、维基和论坛等,人们可以很容易地分享他们的想法和观点,使得信息传递变得越来越频繁;社交网络的意见领袖指的是在特定领域内有影响力的人,有很多人关注他/她的评论或想法。所谓信息的“两级传播”是指信息首先从信息源头传播给意见领袖[1],然后由意见领袖将信息传播给普通大众。在社会网络中挖掘意见领袖具有巨大的商业和政治价值,通过确定最有影响力的人即可引导舆论。此外,发现最有影响力的评论也可以了解舆论的来源。目前,意见领袖的挖掘算法主要从节点的结构和属性两个角度出发提取用户的相似度信息,从而设计更加符合真实意义的PageRank[2]转移概率矩阵。很多基于PageRank 改进的算法由于结合相关实际问题进行优化,相较于传统的PageRank,识别出的意见领袖更加精确。在社交网络中,用户间的交互行为已被证明是用户之间形成影响与被影响关系的一个重要因素,主要包括提及、点赞、转发和回复。这些交互行为说明了用户的紧密关系,因为它们明确地代表了用户对推文的反应,同时与推文的内容也具有强烈的相关性。例如,转发行为可以被认为是转发者向社交网络的用户发布其感兴趣的原始推文行为,从而潜在地增加原始推文的影响。在社交网络上,不同类型的交互行为都包含有用的信息,可以用来更好地衡量用户的影响力。
本文研究如何在社交网络中,通过用户的多种交互行为和话题偏好挖掘意见领袖。研究重点是如何使用用户交互行为和话题偏好来度量用户间的相似度,并据此设计转移概率矩阵,借助PageRank 算法衡量用户的社交影响力。受如今网络中节点表示成功应用的启发,本文将不同交互网络的节点嵌入到向量空间中,并定义节点的紧密关系,它度量了节点在不同交互网络下的相似度。通过节点在多关系网络上的紧密关系和节点的话题偏好,设计节点的转移概率矩阵,通过PageRank 算法为每个用户分配一个影响值,最终筛选出前top⁃k个用户作为意见领袖。在真实的Twitter 网络数据集上的实验结果表明,由于引入了多关系网络和节点的话题偏好,本文提出的方法相较于传统的基于单一结构的算法,取得了更好的意见领袖挖掘效果。
1 相关工作
在意见领袖挖掘算法中,已有的方法主要分为3 种:第1 种通过使用社交网络的拓扑结构(主要是节点的关注关系网络)来捕获节点相对于整个网络的中心位置信息,以此衡量节点的影响力;第2 种通过将节点的结构信息与节点自身的属性信息相结合,综合衡量节点的影响力;第3 种通过节点间的多元关系衡量节点的影响力。使用拓扑结构信息进行意见领袖挖掘已有不少研究工作,主要从节点的低阶结构和高阶结构出发。使用低阶结构主要是利用节点的低阶邻居信息计算节点的影响力,例如常见中心性指标:度中心性、紧密度中心性等。高阶结构反映节点对在高阶邻居上的紧密程度。Zhang 等[3]认为现有的研究主要集中在研究同阶邻居影响力,因此提出了一种新的结构影响力概念,研究了如何有效地从社交流中发现结构影响力模式。在微博数据集上的实验表明,与传统的影响模式挖掘算法相比,显著提高重要节点挖掘性能。Zhao 等[4]提出传统的PageRank 只使用基于边的关系,忽略了由模体捕获的高阶结构。Motif⁃based PageRank[5]在PageRank 基础上使用多节点模体来捕获网络中节点之间的高阶关系,并引入两种融合方法挖掘基于节点间高阶关系的意见领袖。但是上述工作只是基于单一的网络结构,并没有考虑到节点在不同网络结构上的紧密程度。
除考虑节点的结构信息之外,经研究证明[6⁃8],考虑节点的属性信息能够提高意见领袖挖掘的准确率,如节点的话题偏好信息等,由此很多研究者提出了基于话题的意见领袖挖掘算法。这类算法认为不同用户在不同话题下的影响力是不同的[6⁃12],其中心思想是将用户发布的文本内容按话题进行具体划分,再在每个话题下进行意见领袖挖掘。对于不同的话题分配不同的权重,最后将不同话题下的用户影响力得分加权求和得到用户的总体影响力。TwitterRank[9]是其中最具代表性的意见领袖挖掘算法,其核心思想是用户的关注关系很大程度上取决于话题偏好的相似性。然而,TwitterRank 忽略了用户之间的交互行为,只是基于单一的关注关系网络。除话题信息之外,社交网络中的用户有着各种属性信息,如粉丝数、发表推文数量、是否认证等,于是有研究者利用这些属性信息将社交网络用户群体进行分类[13⁃14],如意见领袖用户、结构洞用户和普通用户等,然而这类算法只是将群体进行分类,并未计算用户具体的影响力值。由于关注关系网络只度量了节点的单一结构关系,不足以说明用户间真实的紧密关系,因此有研究者考虑在多关系网络上考虑节点的紧密关系。文献[15]算法考虑了微博用户自身因素与多种互动行为,如用户的粉丝数、用户活跃度、用户信用度、用户互动系数以及微博可见率等,利用改进的PageRank 算法计算微博用户的影响力。文献[16]提出的EIRank 使用节点嵌入方法将多种类型的交互网络集成到嵌入空间中,然后定义一种新的紧密度度量方法,以量化基于交互行为的用户间亲密度,但并未考虑这些交互行为与话题信息的关联性,即交互行为受到话题信息的影响。传统的意见领袖挖掘仅考虑单一的网络结构,忽略了话题偏好和用户的多种交互行为对于节点重要性的评估,即没有有效利用用户的多种行为特征,如转发、提及、点赞和评论等行为,而这些行为特征同样具有话题相关性[17]。因此本文结合节点在多关系网络上的信息和节点的话题偏好信息,利用PageRank算法评估节点的重要性。
2 相关定义
2.1 社交网络
定义1社交网络G=(V,E)由1 组节点V和1 组边E组成,其中E⊆V×V。如果(m,n)∈E,则m,n间存在1 条边。如果(m,n)是有序的,则网络是有向的,否则是无向的。如果每条边都有不同的权重,则网络可以表示为G=(V,E,W),其中W为权重矩阵。
定义2关注关系网络是1 个有向社交网络,Gfollowing=(V,Efollowing),表示用户及其邻居的关注关系。如果用户m被用户n关注,则存在1 条边(m,n)∈Efollowing。
定义3多关系网络是1 个有向加权网络,Gi=(V,Ei,Wi),i表示用户间的交互类型,具体的交互类型包括转发、提及、回复、点赞。如果用户m、n存在交互行为,则存在1 条边(m,n)∈Ei;Wi表示用户间交互频率构成的矩阵。
2.2 加速属性网络嵌入
加速属性网络嵌入[18](Accelerated attributed network embedding,AANE)是一种属性网络表示学习算法,可以把嵌入工作同时交给多个子任务独立、同时间完成,大大地节省了时间。对比一般的网络嵌入方法,如LINE、Node2Vec、DeepWalk 等,AANE 算法在很多数据集上表现出了优越性。AANE 在分解结构信息矩阵的基础上,将属性信息也作为被分解的信息之一,使得矩阵分解能够同时受到结构信息和属性信息的约束,结构上距离相近结点的向量表示也应该接近,同时属性相似结点的向量表示也比较接近。并且,AANE 将最终的优化问题转化为2n个子优化问题,采用分布式优化方式将原任务分解为多个子任务,子任务互相独立,因此大大降低了时间复杂度。本文中使用节点的多关系网络,在各关系网络中节点的属性信息各不相同。因此,提取节点在不同交互网络上的属性信息之后,采用并行的方式使用AANE 提取多关系网络中节点的特征表示。
2.3 PageRank 算法
PageRank 是一种对网络中节点的重要性排序的算法,可以用来挖掘网络中的意见领袖。PageR⁃ank 为每个节点分配1 个初始排名(PR)值,其通常为1/N,其中N为节点的总数,通过节点的转移概率矩阵计算节点的影响力。经过若干次迭代,节点的PR值达到收敛状态。通常节点间的转移概率由节点的入度邻居数决定,对同一个节点的不同入度邻居,节点间的转移概率被均匀分配。然而对于不同用户之间,节点的紧密程度是不同的。因此,本文中节点间的转移概率由多关系网络上节点间的紧密关系和节点的话题偏好相似度共同决定。
3 本文方法
本文研究的问题是如何利用节点的话题偏好和多种交互网络信息来量化节点的社交影响力,即用户对邻居的影响不仅取决于用户间的话题相似度,而且取决于用户及其邻居有怎样的社交关系。本文的目标是设计一种统一的方法,利用节点的话题偏好(话题分布)和网络结构(交互网络信息)进行社交影响力排名,从而挖掘出top⁃k个意见领袖。
3.1 话题提取
对于用户话题偏好的提取,本文使用潜在狄利克雷分布[19](Latent Dirichlet allocation,LDA)模型。LDA 模型是一种无监督的机器学习算法,用于从大型文档集合中识别潜在的话题信息。它使用了1 个“单词袋”假设,将每个文档视为单词计数的向量。基于这个假设,每个文档在某些话题上被表示为文档⁃话题概率分布,而每个话题在多个单词上被表示为话题⁃词概率分布。对于每篇文档,话题的生成过程如下:(1)对每1 篇文档,从文档⁃话题分布中抽取1 个话题;(2)从上述被抽到的话题所对应的单词分布中抽取1 个单词;(3)重复上述过程直至遍历文档中的每1 个单词。
语料库中的每1 篇文档与预先给定T个话题的1 个多项分布相对应,将该多项分布记为θ。每个话题又与词汇表中的V个单词的1 个多项分布相对应,将这个多项分布记为φ。
为了提取用户的话题分布,本文将用户发布的推文作为文档。由于推文字数的限制,LDA 并不适合短文本话题建模[20],因此将每个用户发布的推文聚合到1 个大文档中。对用户的文档进行话题提取即对应用户的话题偏好提取,每个文档本质上对应于1 个用户。对所有用户的大文档进行训练得到的话题分布即对应用户的话题分布。
3.2 提取用户间紧密关系
本文提取用户紧密关系所使用的网络是节点间多种关系所形成的交互网络。直观上看,交互网络中边的权重是表示节点间紧密度的一种方法,但它不能度量未建立连接节点之间的关系,且用户的交互行为受各种因素的影响,每一种交互行为的影响因素各不相同[21]。因此将每一种交互行为的影响因素作为节点的属性,使用一种属性网络表示学习算法AANE,得到用户在多个交互网络上的向量表示,然后根据用户的向量表示得到交互网络中用户间的紧密关系。同EIRank 算法[16],本文定义了4 种向量空间:S={Retweet,Mention,Reply,Favorite},分别对应4 种交互网络,如图1 所示,其中权重表示用户之间交互的频率。因为节点间交互行为的影响因素各不相同,节点在各交互网络所具有的属性依具体交互网络而定。所使用到的属性包括节点的入度、节点的出度、发表的推文数量、节点粉丝数以及节点的话题偏好。经过AANE 得到各交互网络中节点的d维向量表示Vecretweet,Vecmention,Vecreply,Vecfavorite,然后计算节点在每个向量空间的距离
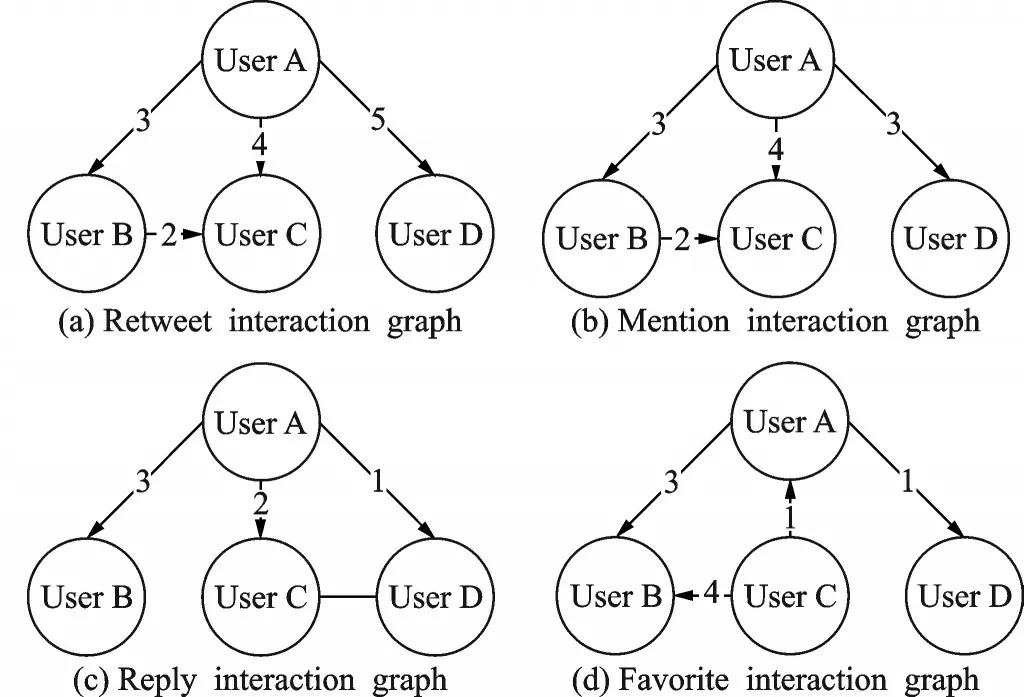
图1 4 种交互图样例Fig.1 Examples of four interaction graphs

式中p=(p1,p2,…,pd)和q=(q1,q2,…,qd)为节点p和q的d维向量。对于每个向量空间根据节点间的欧式距离定义节点间的紧密关系,即

式中S为整个向量空间。
得到节点在各交互网络上的紧密关系之后,计算节点间的全局紧密关系。然而不同的交互网络对于节点的重要性贡献是不同的,因此分配权重给不同的交互网络,权重为某一种交互行为频率和总交互频率的比值,即

式中:C(p,q)表示节点间的全局紧密关系;wi表示交互网络的权重,本文用到了4 种交互关系,因此这里设置为1/4。
除了考虑节点在不同交互网络的相似性,话题意见领袖还须考虑节点间话题偏好的相似性,即

式中simt(p,q)表示节点p、q在话题t上的相似度,DTpt表示在文档⁃话题矩阵DT中用户p对话题t的话题偏好。
3.3 话题意见领袖挖掘
基于PageRank 的改进算法主要思路是如何设计转移概率矩阵以描述用户间的紧密关系,以达到更精确的效果。从式(3,4)已得到节点间在各交互网络的紧密关系,然而节点在各话题下的影响力并不相同,因此设计节点在各话题下的转移概率矩阵为
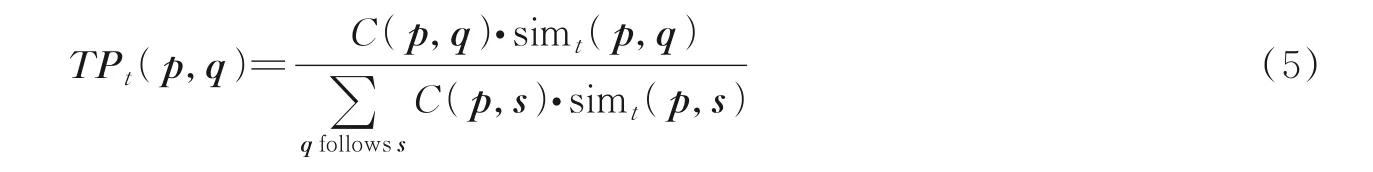
式中:用户p,q为相邻关系;s和q为关注关系;TPt为在话题t下的转移概率矩阵,TPt(p,q)越高,说明用户p受到用户q影响的概率就越高;计算节点在每个话题下的影响力大小
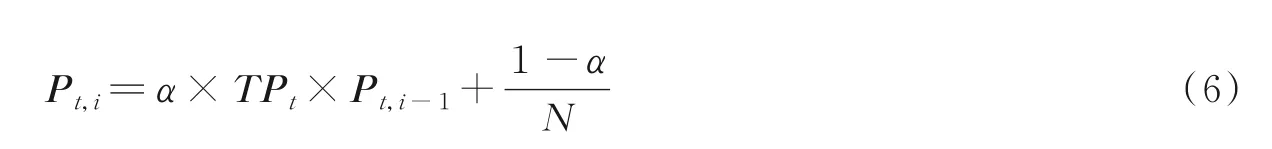
式中:Pt为在话题t下的影响力向量;α为阻尼系数;N为节点总数。
式(6)描述了节点在各话题下的影响力,通过聚合可以得到节点的综合影响力为

式中:P为节点的综合影响力向量;wt为分配给各话题影响力向量的权重。
为了挖掘top⁃k个话题意见领袖,本文给出一种基于PageRank 的影响力计算算法,如算法1 所示。
算法1多关系网络话题意见领袖挖掘
输入:关注关系网络,用户交互网络集合Gi
输出:top⁃k个话题意见领袖
①forGiinG:
②VecG=AANE(Gi);
③end for
④根据式(1~3)计算节点间的紧密关系;
⑤根据式(4~5)计算节点在每个话题下的转移概率矩阵;
⑥初始化每个用户的影响力值为1/N;/*N为节点个数*/
⑦fortin all_topics:
⑧根据式(6)计算每个话题下的影响力向量;
⑩根据式(7)计算节点的综合影响力向量,排序、筛选得到top⁃k个话题意见领袖。
4 实验及分析
4.1 数据集
实验所使用的数据集为公开数据集TIMME[22]。该数据集于2019 年3 月从Twitter 收集,包含585位美国政客以及他们的关注者及后续关注者信息。数据集包括3 个子集和1 个总数据集。在整个推文数据集中提取相应用户的推文信息,去除停用词、低频词之后形成话题模型所需文本。经过预处理,得到的数据集共计5 435 个节点,1 593 721 条边,5种交互关系和9 548 310 条推文。经处理后,数据集的信息如表1、2 所示。其中表2 具体展示了不同交互关系下的网络信息,包含了回复、转发、点赞、提及和关注关系,并将根据用户的所发文章提取了用户的话题偏好以及用户的属性信息,属性信息分别为具体交互网络下节点的出度、节点的入度、用户的粉丝数、所发文章数量以及话题偏好。

表1 数据集信息Table 1 Information of datasets

表2 多关系网络信息Table 2 Information of multi‑relational networks
4.2 实验结果
为了验证本文提出方法的有效性,本文选择以下常用的意见领袖挖掘算法作为对比:
(1)PageRank[2]:依据节点的关注关系度量节点的重要性。
(2)Motif⁃based PageRank[5]:提取节点间的高阶结构关系⁃模体(motif),并据此设计转移概率矩阵。
(3)TwitterRank[9]:经典的话题意见领袖挖掘算法。其核心思想是,用户的关注行为很大程度上取决于用户间话题偏好的相似度。
(4)EIRank[16]:使用Node2Vec[23]得到节点在多种交互网络上的向量表示,根据节点向量表示的相似度设计转移概率矩阵。
地产公司进行预算管理工作,其主要内容包括两个方面,分别是经营预算和财务预算。其中经营预算是依照房屋开发建设的整个过程进行的预算,又称为房产项目的全过程预算。在项目实施的不同阶段,预算工作的内容也不同,根据时间先后可以分为项目估算、项目概算以及项目预算。除此之外,还可以根据业务管理的内容对预算进行划分,如项目成本预算、排期预算等。账务预算同时包括资产,成本费用,利润预算等。
意见领袖挖掘通常使用影响力传播模型来对算法进行评估。本文使用的影响力传播模型是线性阈值模型如图2 所示。
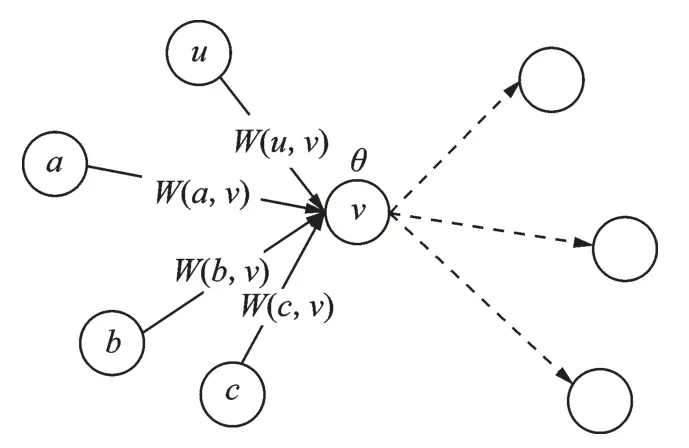
图2 线性阈值模型Fig.2 Linear threshold model
在线性阈值模型中,每条有向边(u,v)∈E上都有1 个权重W(u,v)∈[0,1],直观上W(u,v)反映了节点u在节点v的所有入度邻居中影响力的重要性占比。每个节点v还有一个激活阈值θ∈[0,1],一旦确定在传播中就不再改变。在s=0 时刻有且仅有种子集合中的节点被激活。当s≥1 时,每个未激活节点v都需要依据它所有已激活的入度邻居来判断是否被激活,激活的判断标准为入度邻居对当前节点的影响力线性加权和是否已达到当前节点的激活阈值。若是,则节点v在时刻s被激活;否则,节点v仍然保持未激活状态。当某一时刻不再有新的节点被激活时,传播过程结束。本文选取各算法结果集中前top⁃k个节点作为种子节点集,并设置节点的激活阈值,通过种子节点集最终激活的节点数量作为评价指标。
(1)用户在不同话题下的影响力各不相同,本节选取3 个话题,每个话题下5 个意见领袖作为种子节点,测试不同话题下意见领袖的影响力。TwitterRank 和MRTRank 的对比结果如表3 所示。根据表3,从激活的节点数量看,两个算法性能接近;从具体激活的节点来看,激活的节点并不相同,这是因为一个用户对另一个用户产生影响具有话题相关性,即一个用户很大程度上受到一个与他话题偏好相似的用户的影响。在话题1 中,意见领袖能够影响到的用户的话题偏好趋向于话题1,同理对于其他话题也是如此。
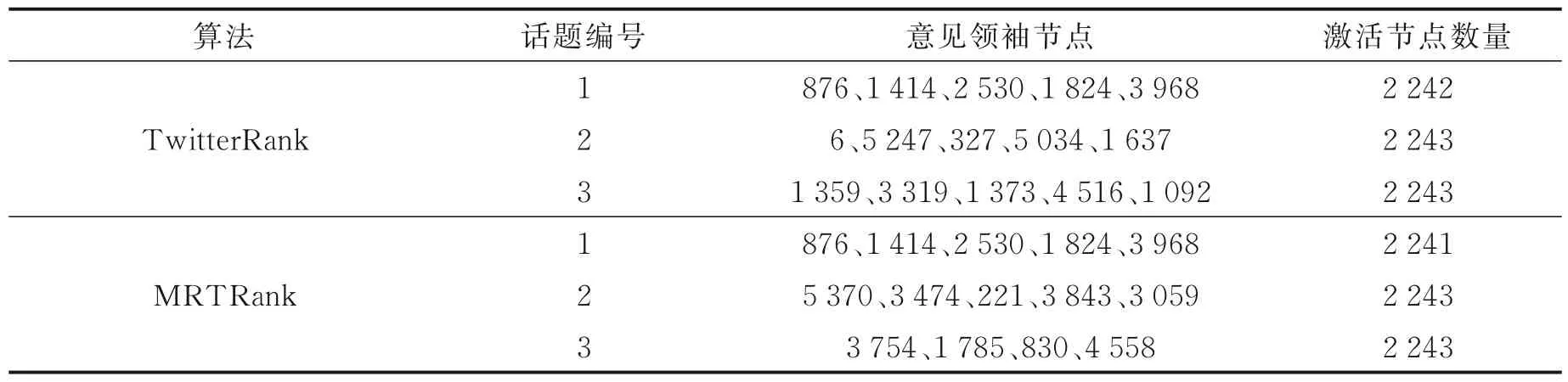
表3 部分算法结果对比Table 3 Comparison of partial algorithm results
(2)各方法激活节点数量如图3 所示。从图3 可以看出,当选取种子节点数在20 以内,各算法的最终激活的节点数量相差不多。这是因为各算法挖掘出的意见领袖大致相同,因此激活的节点数量相对一致。当选取种子节点数大于50 时,各算法表现出现差异。部分算法中种子节点集中仍有意见领袖,所以激活节点数量保持着上升趋势,然而有些算法种子节点集中包含普通节点,所以激活的节点数量没有明显的变化趋势。Motif⁃based PageRank 因为只考虑了单一的关注结构信息,没有考虑用户的多种交互关系以及用户的属性信息,随着种子数量的增多,相较于其他算法而言其激活的节点数量较少。EIRank 考虑了多种交互信息,因此结果相对较好。MRTRank 同时考虑了多种交互信息和话题偏好相似度,其结果与TwitterRank 基本一致。当选取的种子节点为2 000 时,除Motif⁃based PageRank 算法之外,其他算法的实验结果基本一致,这是因为当种子节点达到一定数量时,各算法挖掘出的意见领袖节点几乎都在种子节点集中,因此最终激活的种子数量大致相同。从整体上看MRTRank 和TwitterRank算法的表现力相差无几,两个算法都考虑了话题信息和用户的粉丝数量,研究这两个属性信息与用户的交互行为是否存在关联将是进一步的研究工作。

图3 各方法激活节点数量Fig.3 Number of activated nodes in each method
(3)对MRTRank 进行消融实验,结果如图4 所示。实验中主要考虑基于单一的关注关系网络、基于多种交互关系以及基于多种交互关系结合话题偏好相似度。图4 结果表明,随着种子节点的增多,基于单一关注关系的PageRank 算法效果较差,而PageRank 结合AANE 考虑了节点的多种交互关系,效果优于PageRank 算法。MRTRank 考虑节点多种关系并结合了节点间话题偏好相似度,效果最好。可以得出,除了用户的关注结构信息,用户的多种交互行为以及用户的话题偏好信息在意见领袖的挖掘中同样起到关键作用。
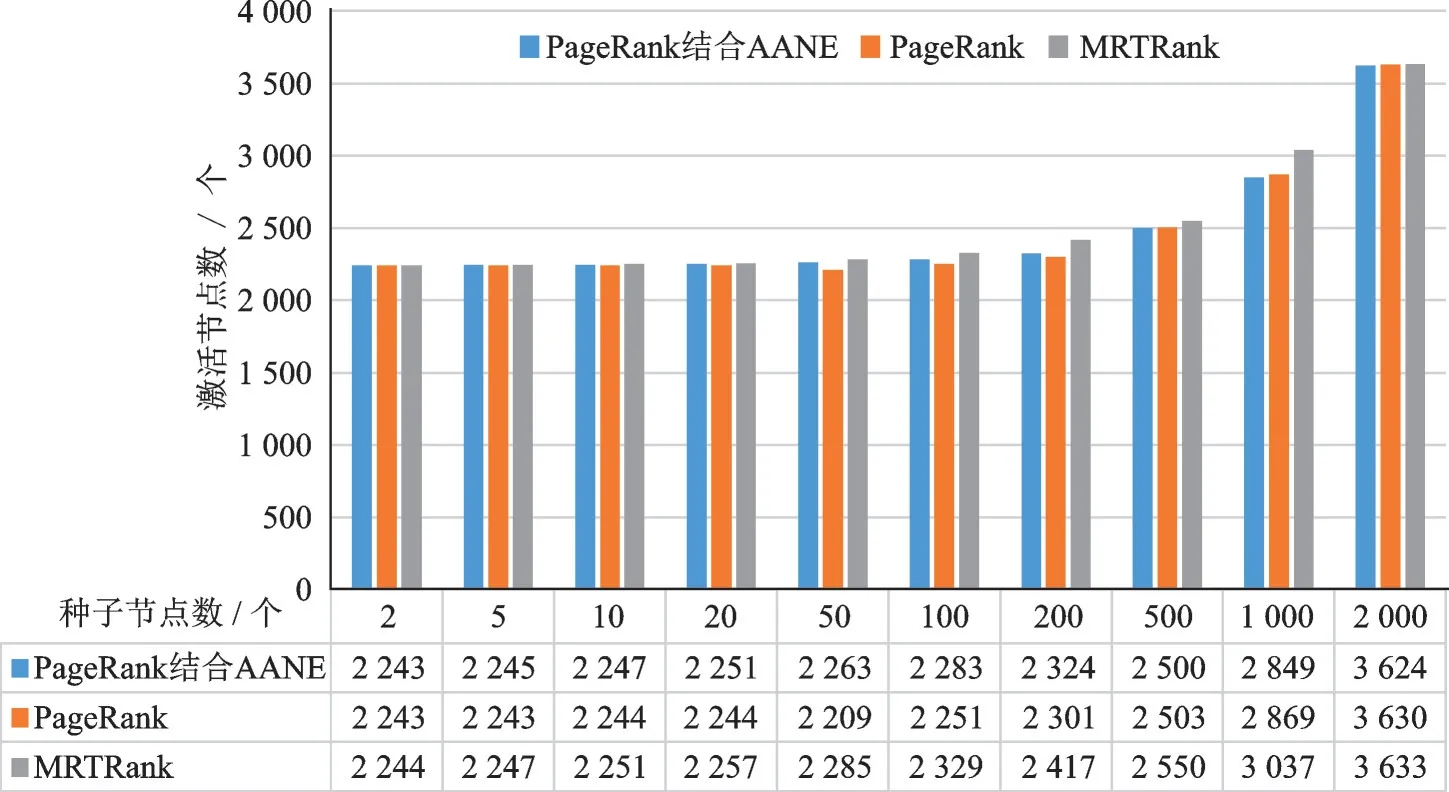
图4 消融实验结果Fig.4 Ablation experiment results
5 结束语
近年来,随着各种社交平台的兴起,人们之间的信息交流越来越频繁,使得意见领袖挖掘研究受到了广泛的关注。相对于传统的基于单一结构关系,本文所提出的方法将用户的话题偏好和多种交互关系相结合。首先收集用户的推文信息,并将用户推文合并成大文档,通过话题模型得到用户的话题偏好;其次构建4 种不同的交互网络,并提取用户在具体网络上的属性信息,通过属性网络表示学习的方式,得到节点的向量表示,据此设计节点间的紧密关系;最终根据节点的话题偏好和各交互网络上的紧密关系设计转移概率,借助PageRank 算法得到节点的影响力排名,选择top⁃k个影响力最大的节点作为意见领袖。在Twitter 数据集上的实验结果证明本文提出的方法优于传统的意见领袖挖掘算法。
猜你喜欢
黄河之声(2022年6期)2022-08-26
学苑创造·A版(2019年9期)2019-11-07
意林·全彩Color(2019年7期)2019-08-13
好日子(2019年4期)2019-05-11
学苑创造·A版(2019年2期)2019-02-19
NBA特刊(2018年14期)2018-08-13
当代陕西(2018年12期)2018-08-04
人大建设(2017年11期)2017-04-20
艺海(剧本创作)(2015年1期)2015-12-19
瞭望东方周刊(2015年12期)2015-04-14
