
银行客户分类的数据特征选择方法与实证研究
2022-06-09 12:00:18段刚龙杨泽阳
计算机工程与应用 2022年11期
段刚龙,王 妍,马 鑫,杨泽阳
西安理工大学 经济与管理学院,西安 710054
随着信息化水平的提升和物联网(Internet of things,IoT)技术的快速发展,教育、通信、金融和医学等领域数据呈指数式增长,海量数据的累积标志着大数据时代的到来。金融大数据是大数据的重要板块,全国各大金融机构每年都会产生大量数据,一般金融机构每年产生结构化数据已超5 PB,非结构化数据超过15 PB,每次网上支付业务仅记录用户行为的数据量就达1 GB。数据内容涵盖金融产品数据、个人刷卡消费数据、客户基本信息数据、开户数据、客户各自信用数据等。其中的银行客户数据是金融大数据的重要组成部分,不仅包括受教育程度、婚姻状况、受教育年限等客户个人静态数据,还包含客户日均消费次数、日均消费金额、预期还款天数等消费行为的动态行为数据,包含了大量的有价值知识。研究者可通过统计分析或机器学习等方法挖掘数据集中潜在的规律、模式、经验或知识[1-3],辅助银行实现“以客户为中心”的精准营销、风险管控和核心竞争力提升。
但由于银行客户数据维度高、量级大和冗余特征多[4]的特点,为知识挖掘与发现带来了诸多挑战,降低了数据价值密度,影响客户分类模型效率,易产生维数灾难[5-6],而现有针对高维数据特征选择方法的相关研究主要集中于单一视角,并未将人类先验认知考虑在内,且很少有针对银行客户数据特征选择的系统性研究,因此,本研究以高维银行客户数据为研究对象,综合统计、机器学习、先验认知、多模态融合思想,对银行客户数据特征选择方法进行研究。
本研究的主要贡献如下:
(1)综合考虑现有与银行客户分类有关的研究成果以及真实银行客户数据特点,本文给出了一种可用于银行客户分类特征筛选研究的数据预处理方案,该方案共包括类型转换及离散化、缺失值填充和标准化三部分,能有效提升真实银行客户数据质量。
(2)鉴于单一特征筛选方法在不同场景下存在性能受限的问题,本文在多模态视角下,综合考虑主观特征选择方法和客观特征选择方法,提出了一种综合性的特征筛选方法。
(3)本文给出了一种较为系统且全面的银行客户分类特征选择效果评价方法,该方法包括定性评价与定量评价两部分。其中,定性评价主要对各特征选择方法的原理、适用条件和特征选择占比等指标进行比较分析;定量评价则是在不同特征选择方法的特征筛选结果之上比较不同银行客户分类模型的精确度(ac)、测试集精确度(tc)、查全率(tl)、查准率(pd)、召回率(rl)、F1-score(f1)以及模型训练成本(ct)共计7个指标。
(4)针对不同特征选择方法,本文设计并实行了一种包含4种特征选择方法、4种定性评价指标和7种定量评价指标的实验方案。实验结果表明,相较于单一特征选择方法,本文提出的特征选择方法更具多元性与全面性,能够为银行客户数据知识挖掘与发现提供参考。
1 研究现状
银行客户数据的核心价值在于构建用户画像,深度挖掘用户统计学信息、消费行为、社会关系和情景信息,为揭示用户行为特征并进行精准营销和风险管控等提供理论支持和现实依据[7-8]。目前,国内外学者已将其应用于加强渠道服务体系的建设[9]、客户信用风险评估[10]、重要基金客户识别[11]、小微金融客户续贷预测[12]和个人客户价值评价[13-14]等多项研究。随着信息技术发展,银行客户数据传输和存储成本大大降低,不仅数据体量逐年增大、数据类型增多,且数据维度提高,价值密度有所降低,这些变化在为银行客户数据应用提供充足“养分”的同时,也为知识挖掘与发现带来了巨大挑战。
国内外相关学者针对数据特征选择的相关研究,主要有两大类:统计学方法[15-16]和机器学习方法[17-23]。部分常见的具有代表性的特征选择方法及原理如表1所示。

表1 特征选择方法与原理Table 1 Method and principle of feature selection
基于统计的特征选择方法通过计算不同特征与目标属性之间的相似度或空间距离,按照排序结果从大到小对特征进行筛选,该种特征选择方式虽能对特征进行筛选且效率较高,但筛选效果较差,对数据预处理质量依赖较大,筛选后特征包含过多的冗余特征,从而影响最终的模型性能。相比之下,基于机器学习的特征选择方法的特征筛选能力更强,性能更优,因此被广泛应用于特征选择当中,依据特征中子集评价标准同后续算法的结合方式可分为:嵌入式(embedded)、过滤式(filter)和封装式(wrapper),算法通用性强,可快速去除大量不相关特征,但所选择特征的通用性较低且忽略了低贡献度特征,当改变算法,则需进行针对性的训练和测试,模型训练成本较高。
从国内外现有针对银行客户数据的应用以及高维度数据集特征选择方法的研究成果可见,研究大多集中于单一特征选择方法的应用与优化,筛选出的特征准确性还有提升空间,多角度综合性的银行客户数据降维方式特别是融合人先验认知的研究相对较少。因此,本研究旨在提出一种有效的银行客户数据挖掘方法,来降低数据特征冗余,提高银行客户分类的模型精度,降低训练成本和构建系统的主题模型。
2 高冗余银行客户数据特征选择方法
党的十八大以来,银行遵循“创新、协调、绿色、开放、共享”的发展理念,贯彻实施网络强国、大数据战略等一系列重点战略部署,积极推动银行信息化建设,稳步推进重要信息系统建设[24]。银行客户电子数据正是银行信息化进程中的典型产物。
银行客户数据不仅集成了每个客户的静态数据,还记录了客户的动态行为数据,形成了具有多个特征的高维数据集,银行则可通过以上客户数据对客户进行精准画像,及早发现待流失客户、高风险客户或高价值客户等,及时规避金融风险提升银行效益。然而,数据集中并非所有特征都与客户分类的目标密切有关,而是存在大量冗余特征,如:卡类型、币种代码和户籍所在地等,此类冗余特征会对模型结果产生较大影响,降低模型性能。因此,对高冗余银行数据进行挖掘前必须对数据特征进行筛选,降低数据维度。为提高银行客户分类模型性能,本文所制定的高冗余银行数据特征选择具体流程如图1所示。
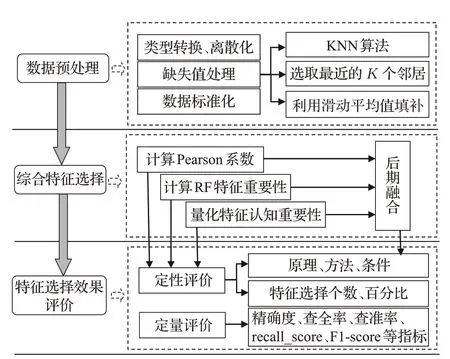
图1 高冗余银行客户数据特征选择流程图Fig.1 Flow chart for feature selection of high redundancy bank customer data
2.1 数据预处理
在实际情景中,特征值缺失的情况经常发生甚至是不可避免的。采集自银行信息系统的已整合有序原始数据同样也不例外,因人为因素或机械因素导致原始数据中存在较多缺失值,数据价值密度较低,对银行客户数据的挖掘与分析产生不利影响,因此,需要对原始数据缺失值进行填补,缺失值填充方式有三大类:删除、补齐和忽视。常用缺失值处理方法如表2所示。
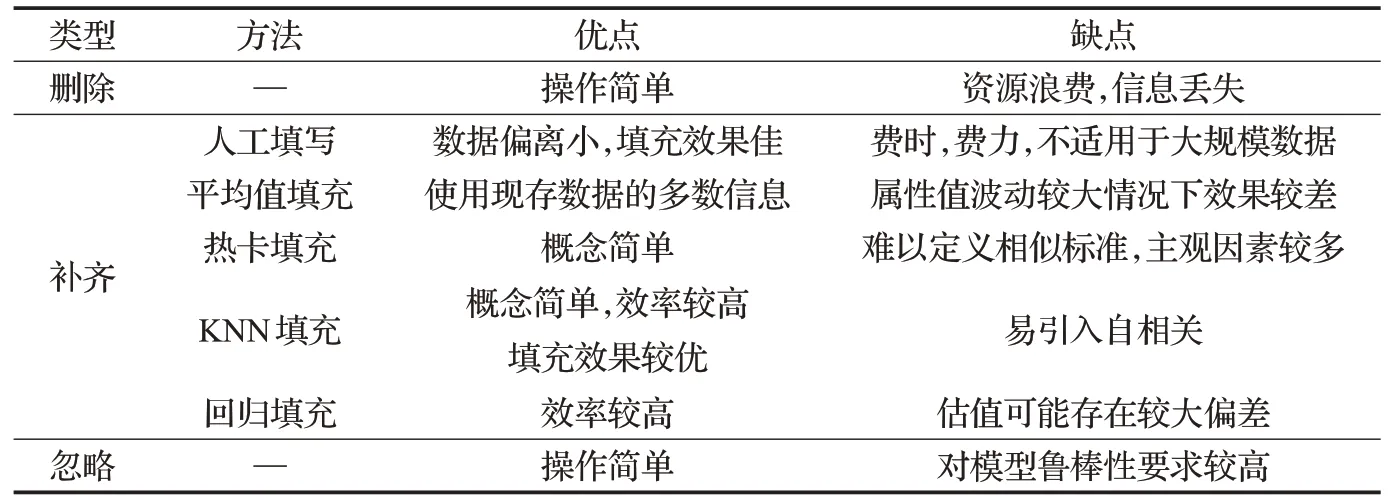
表2 缺失值处理方法及优缺点Table 2 Missing value processing methods and advantages and disadvantages
无论采用何种方式对缺失值进行填充,均无法避免主观因素对原始数据的影响,因此,本文综合考虑表2中各填充方法优缺点及银行客户数据缺失值分布较为集中特点,采用KNN算法对缺失值进行填充,但KNN计算的填充值为均值计算结果,对特征值的波动较为敏感,故采用滑动平均值替换算数平均值对缺失值进行填充,填充过程如图2所示。具体操作过程如下:
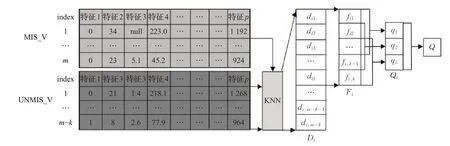
图2 缺失值填充过程Fig.2 Missing value filling process
(1)将含n个对象p个特征的原始数据划分为两部分:包含m个对象的缺失值数据集MIS_V和m-k个对象组成的非缺失值数据集UNMIS_V。
(2)分别计算MIS_V中的对象obj i到UNMIS_V中的各对象obj j的欧式距离d ij,并组成向量D i={d i1,di2,…,d ij,…,d i,m-k}。
(3)向量D i中各元素按从小到大排序,并选择前k个最小距离对应对象MINS-Vi的对应缺失值特征的特征值F i={f i1,f i2,…,f ik}。
(4)以步长s=3计算F中所有距离的滑动平均值Q作为填充值进行填充。
此外,由于现有的银行客户分类模型如决策树和CART&Tree等均为基于离散型数据的算法模型,有效的离散化能够降低模型的时间和空间开销,提高分类模型的性能与抗噪能力,鉴于离散化特征值相对连续型特征值更易理解,更趋向于知识层面的表达,还可有效屏蔽数据中的隐含缺陷,提升模型的普适性等原因,本文针对待离散化数据以距离d i进行等距离散化:
式中,f i为待离散化特征值,Li为当前离散化特征分段数,d i为分段距离。
2.2 综合特征选择
综合特征选择是银行客户分类数据特征选择方法的核心步骤,其综合不同视角的特征选择方法,将看似杂乱无章的数据映射为不同贡献度的若干特征,并从各视角互补角度出发融合特征贡献度,依据最终贡献度大小筛选原始数据中冗余特征,保留少数能精确反映数据全貌的特征,从低维数据中挖掘知识。综合特征选择共包含三部分:客观特征贡献度计算、主观量化特征认知和特征贡献度融合。前者包含基于统计的特征选择方法Pearson相关系数和基于机器学习的特征选择方法RF,后者则为考虑人为先验认知的特征筛选方法。
(1)基于Pearson相关系数的特征选择方法
Pearson相关系数(Pearson correlation coefficient,PCC)是用来衡量两个不同特征之间线性相关程度的统计量,在特征筛选领域是一种经典的基于统计的特征选择方式,计算的是待筛选特征与目标属性之间的线性相关关系。
皮尔森相关系数计算公式如下:
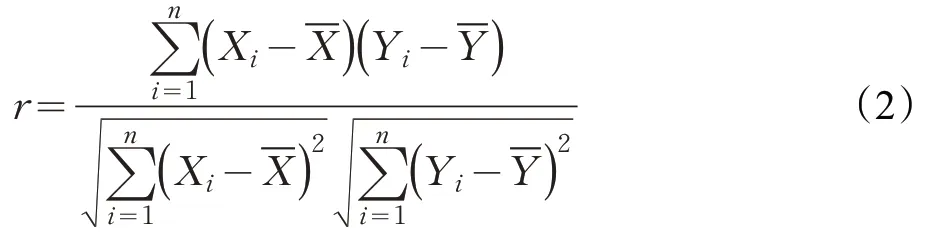
式中,Xi和Y i分别为特征X和Y具体取值,Xˉ和Yˉ分别为特征列X和Y的均值,r为相关系数值,n为样本量。当r的取值位于[-1,1]之间,若r>0,表明自变量特征X对目标属性Y存在正相关关系,即X与Y的值同向变化;若r<0,表明自变量特征X对目标属性Y存在负相关关系,即X与Y的值反向变化;若r=0,则表明两个特征之间并不存在线性相关关系,但并不能排除其他类型的相关关系。
同时,为使得主观特征贡献度和客观特征贡献度处于同一量纲,算法需要对相关系数进行归一化处理,其最终特征贡献度计算公式如下:

(2)基于随机森林的特征选择方法
随机森林(random forest,RF)作为新兴的、高度灵活的机器学习算法,拥有广泛的应用场景,既可以用来做市场营销模拟建模,统计客户来源、保留和流失,也可用来预测疾病风险和患病者的易感性。而RF模型具有一个十分重要的特征,即可计算单个特征的贡献度,因此常被用来进行特征的选择。
基于随机森林的特征选择计算过程如下:
①对原始数据集X进行随机有放回抽样形成袋内数据,未抽中数据形成袋外数据(OOB),即测试集数据。
②利用袋内数据构建RF模型。
③对于RF中每一棵决策树,使用相应的OOB数据计算袋外数据误差,记为errOOB1。
④随机于OOB所有样本特征x中加入噪声干扰,再次计算袋外数据误差,记为errOOB2。
⑤假设RF中共ω棵决策树,则数据集X中各特征的贡献度计算公式如下:
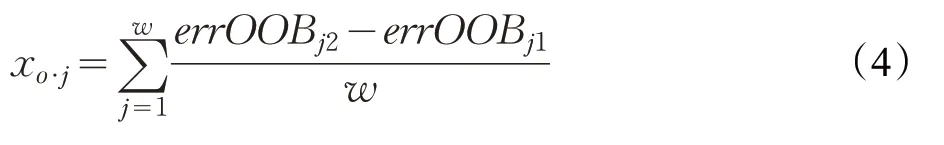
⑥特征贡献度经公式(3)进行归一化处理,可得特征贡献度向量X o=(xo·j)T。
(3)基于量化认知的特征选择方法
认知(cognition),或称为心理活动,描述的是知识的获取、存储、转换和使用。人的每一次获取信息、存储信息和使用信息的时候认知都会起作用[25-26]。人的认知活动通常包含自上而下和自下而上两个过程,是高效、准确且存在诸多局限的。以管理决策为例,当需调用某些信息来支持管理者做出正确决策时,其可在极短时间内从海量先验经验中抽取相关知识并进行加工,当然,这个认知过程或信息加工过程同样存在局限,即人的记忆力或信息处理能力是有限的,会依据先验认知或情感舍弃掉某些重要性程度较低的信息或知识,而这恰好与数据中冗余特征的筛选有着异曲同工之妙。
因此,将人类对银行客户细分数据特征贡献度的认知进行可视化,作为特征选择过程中的一个补充具有十分重要的意义。鉴于问卷调查作为一种数据采集方式,具有省时、省力、省钱及便于定量处理与分析等优点,本文采用问卷调查的方式对银行客户数据特征贡献度认知进行量化,问卷类型为“网络调查问卷”与“纸质问卷”相结合,每个特征即一个问题,问题备选项类型为二值封闭式选项,形式为选择式,问卷具体形式如图3。

图3 调查问卷Fig.3 Questionnaire
针对不同的数据集,问卷题目个数及问题均有所区别。记问卷数据集S i下共包含f1,f2,…,f p共p个特征和A1,A2,…,An共n个对象,其中对象A i对特征f j的认同度记为f ij(f ij∈[0 ,n] ),构造决策矩阵F=(f ij)n×p,然后对决策矩阵中各列进行标准化处理,变换方法如下:

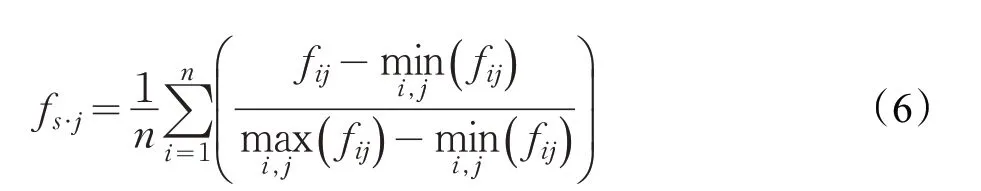
公式(5)、(6)中f s·j表示标准化处理之后的特征贡献度,公式(5)能够有效保持原有数值间的绝对差别,公式(6)将数据量纲处理后表示某个对象在整个特征向量中的相对排位和相对差别,但不能代表数据间的绝对差别。经标准化处理后,得到各特征的主观贡献度:
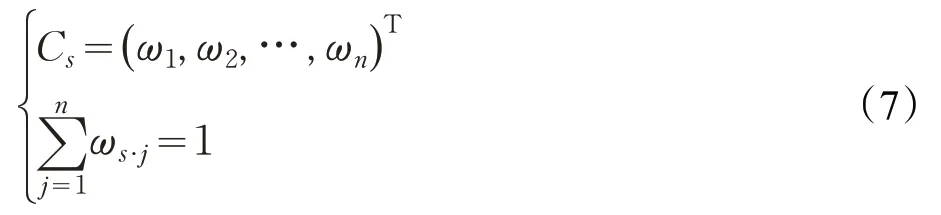
(4)基于多模态后期融合的特征选择方法
多模态数据融合是指通过利用多模态之间的互补性,剔除模态间的冗余性,从而学习到更好的特征表示。目前,多模态数据融合主要有三种融合方式:前期融合、后期融合和中间融合。鉴于后期融合相较于前期融合与中间融合具有简单、高效和易于理解等优势,因此本文借鉴后期融合思想对上述三种特征选择方法结果进行融合。
鉴于本文中客观特征贡献度计算与主观量化特征认知计算之间相互独立,因此,本文采用情感预测多模态后期融合中线性加权方式计算综合特征贡献度,该方式操作简单且应用广泛。主观量化特征认知特征贡献度向量为C s,客观特征贡献度为Pearson贡献度向量X o和RF贡献度向量C o,其综合特征贡献度如下:

式中,C w为综合特征贡献度向量,α和β分别为主观量化特征认知贡献度和客观特征贡献度系数,满足α+β=1且α,β∈[ ]0,1。当α=β,表示主客观同等重要;当α>β,表示主观量化特征认知贡献度重要性程度更高;当α<β,表明客观特征贡献度重要性程度更高。并将综合特征贡献度向量中每个元素C w·j与最小特征贡献度θ进行比较,大于θ的特征构成筛选特征向量R=(r1,r2,…,r z)T,其中z为筛选后特征个数。
2.3 特征选择效果评价
本文分别从定性与定量两个角度对银行客户数据特征选择效果进行评价。首先从定性角度对特征选择方法进行评价,主要针对特征选择方法的原理、特征选择个数、选择特征个数占原始数据总特征个数比重以及特征选择重合度对各方法进行横向对比评价。之后从定量评价角度对特征选择方法进行评价,通过特征选择后的数据集构建不同算法的银行客户分类模型,依据模型查准率(Precision)、召回率(Recall)、F1系数(F1-score)和模型训练成本(Cost)定量评价指标对不同算法模型下特征选择方法效果进行评价。定性与定量相结合的特征选择效果评价方法能够有效判断所选特征集合是否能够代表原始数据集特征,及是否能够选择出对目标贡献度较小的特征,综合评价不同特征选择方法对银行客户分类所产生的影响。
3 特征选择实证研究
基于经典数据挖掘框架、多属性决策理论、主观先验认知理论及多模态融合理论,结合现有银行客户分类研究主要采用单一特征选择方法现状以及客户有效分类对银行规避金融风险及提升效益等方面的显著作用,选取银行客户数据为研究对象,通过建立客户分类模型,从定性与定量角度综合评价特征选择方法的性能,探索银行客户数据价值为银行精准营销与风险规避提供决策支持,同时为银行客户提供个性化进行产品与服务。
3.1 研究准备
(1)数据来源
数据来源于网易数据分析项目,该项目承担单位为上海数局科技有限公司,该公司为国内合资企业,经营范围涉及电子商务、计算机科技、计算机软件开发、环保科技、生物科技等多个领域。项目涉及到的数据集以保护数据提供单位知识产权及个人的隐私为出发点,为相关数据使用工作者提供高保真数据集。本研究选择银行客户信用卡相关数据,数据内容共存储于客户信用记录表、申请客户信息表、拖欠历史记录表和消费历史记录表,整合后银行客户信用卡真实数据共计5 954条数据,每条数据包含28个特征,原始数据内容如表3所示,整合后数据特征构成如图4所示。
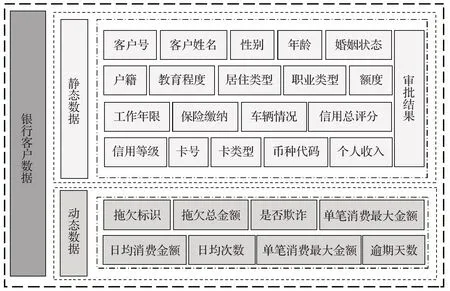
图4 银行客户数据属性构成Fig.4 Composition of bank customer data attributes

表3 原始数据内容及特征简介Table 3 Contents and characteristics of raw data
(2)实验条件
本实验模型训练单机硬件配置为Inter®Core™i3-3220 CPU@3.30 GHz 3.30 GHz核心处理器,4.00 GB RAM,500 GB常规硬盘,Inter®HD Graphics单显卡,软件平台为PyCharm集成开发环境,Windows 10企业版2016企业长期服务版,anaconda6 64 bit包管理工具。
3.2 研究方法
基于高维银行客户数据的特征选择方法实证流程,如图5所示。首先,将分散在不同业务系统中的银行客户数据进行整合并以信用等级为目标变量筛选出审核通过客户数据,并依据与银行客户分类相关的现有研究对于客户分类目标无明显贡献的特征,如:客户号、客户姓名、审批结果、卡号等,进行初步筛选形成较低纬度数据集。其次,由于机械因素或人为因素导致整合后数据集中存在较多缺失值、分类模型无法处理的非数值型数据和连续型数值数据,因此需要对初步特征筛选后的数据进行预处理,通过改进KNN方法对缺失值进行填充,Map映射对数值类型进行转换、公式(1)对连续型数据进行等距离散化及特征数值标准化。再次,对预处理后高质量数据集分别通过量化特征认知、Pearson相关系数、RF特征贡献度及多角度融合方法对特征进行选择,并分别生成筛选数据集。最后,基于筛选数据集分别构建不同算法分类模型,并就特征筛选效果进行定性与定量评价。
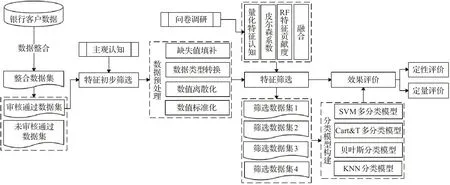
图5 高维银行客户数据特征选择方法研究流程Fig.5 Research process of customer data feature selection method in high dimension bank
3.3 特征选择结果
(1)基于Pearson相关系数的特征选择结果
通过公式(2)计算不同特征与目标变量之间的线性相关关系,依据相关系数绝对值是否非负对特征进行选择,选择特征包含:性别、年龄、教育程度、居住类型、工作年限、个人收入、保险缴纳、车辆情况、信用总评分、额度、拖欠标识、拖欠总金额、逾期天数和单笔消费最小金额共计14个特征,如表4所示,对应特征及数据生成筛选数据集2。
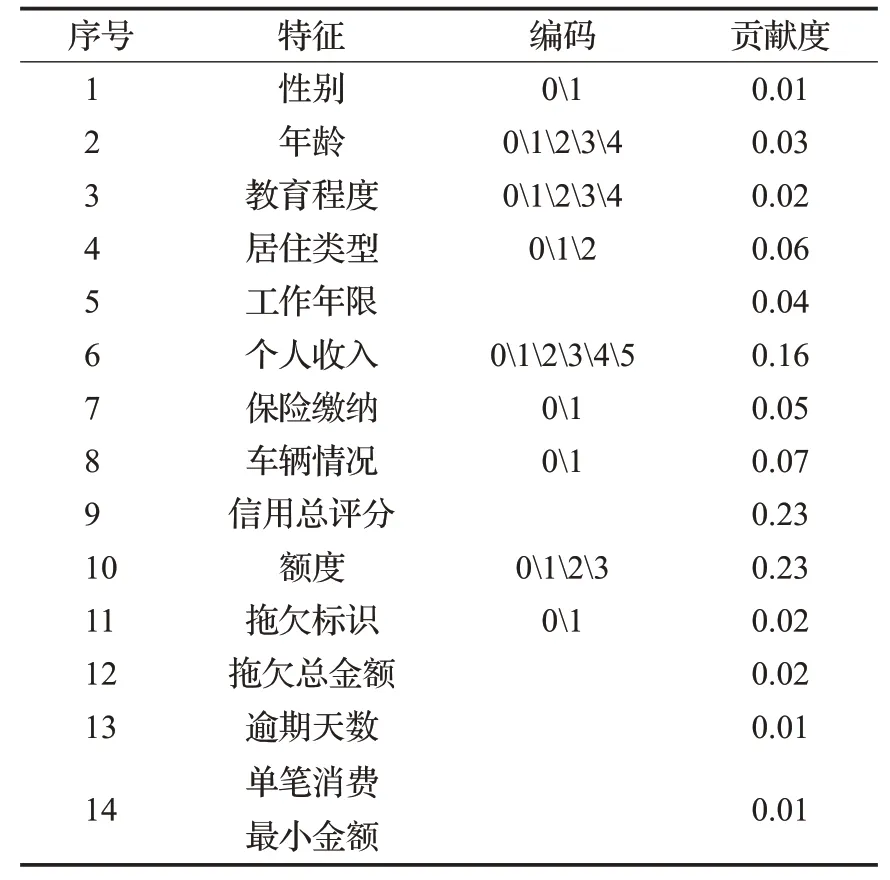
表4 Pearson系数特征选择结果Table 4 Pearson coefficient feature selection results
(2)基于RF特征贡献度的特征选择结果
基于预处理后高质量数据集,借助Pycharm集成开发环境,通过python中numpy、pandas等数据处理第三方库与sklearn机器学习库调用RandomForestRegressor函数接口构建RF模型,计算特征贡献度,并按特征贡献度大小,对特征进行筛选,具体函数如下所示:
RandomForestRegressor(n_estimators,criterion,max_leaf_nodes,random_state,n_job)
其中,参数n_estimators设定为整数值101,表示RF中建树的个数,同时为了防止“投票”过程中出现特征得票相同的情况,故设置为奇数;参数criterion表示RF内部决策树在进行分叉时依据哪个特征进行分裂的衡量标准,本文设定为Gini系数;参数max_leaf_nodes设定为整型参数16,表示种树的最大叶子节点数;参数random_state设置为整数1,表示随机种子,通过随机种子的设定能保证程序运行结果的可复现性;参数n_job表示模型训练函数fit与模型预测函数predict并行运行的作业数,无特殊要求,默认设定为1。最终选择的8个特征如表5中所示。
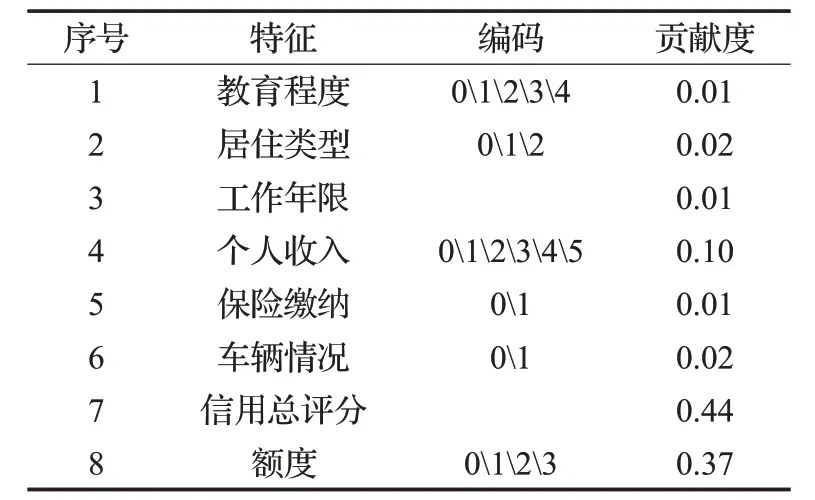
表5 RF特征选择结果Table 5 RF feature selection results
(3)基于量化特征认知的特征选择结果
基于量化特征认知的特征筛选方法通过问卷调查方式对无法定量测量的人类先验认知进量化,问卷形式如图3所示。问卷形式为“网络调查问卷(问卷星)”和“纸质问卷”相结合,共28个问题,问题均为二值单选题,共发放问卷160份,有效问卷98份,网络问卷52份,纸质问卷46份,其中超过50%问卷填写人为在校研究生、博士生、讲师或教授,问卷填写质量较高。
(4)基于多角度融合的特征选择结果
在多模态情感预测当中,综合考虑多个模态以及其他信息理论上来说可提高情感识别系统的性能,非恰当的融合方式不仅无法提升模型性能,而且有极大可能降低模型的性能[27-29]。现有的模型融合方式主要有前期融合、中期融合和后期融合,其中后期融合以其简单高效的特点被广泛应用于多模态情感预测领域。鉴于本文不同视角下对特征贡献度的计算是独立进行的,符合后期融合前提假设,因此本文通过线性加权方式对不同视角下的特征贡献度进行计算,计算过程如公式(8),其中α=0.28且β=0.72,最终筛选特征为:年龄、教育程度、居住类型、职业类别、工作年限、个人收入、保险缴纳、车辆情况、信用总评分、额度、拖欠总金额共计11个特征,如表6所示。

表6 多角度融合特征选择结果Table 6 Feature selection results of multi-angle fusion
3.4 特征选择效果评价
(1)定性评价
四种特征筛选方法的类型并不相同,Pearson相关系数(方法1)为基于统计的特征选择类型,RF(方法2)特征贡献度为基于机器学习的特征选择类型,量化特征认知(方法3)则为依据人类先验知识的一种特征选择类型,而本文提出的多视角融合的特征选择方法(方法4)则为考虑不同方法间互补性的一种特征选择类型。其中方法1是通过衡量待筛选特征与目标变量之间相似度大小的一种特征选择方式,该方法受数据预处理效果影响较大,共筛选出14个特征;方法2则通过公式(4)计算各特征贡献度,依据贡献度大小对特征进行选择,共筛选出8个特征,筛选效果较好,但模型针对性较低且训练成本较高;方法3则依据人类先验知识通过问卷调查方式对特征贡献度进行度量并选择特征,筛选效果对问卷填写人的知识背景和问卷填写质量要求较高,共筛选15个特征,特征筛选效果较差,本文分析该种现象产生的原因主要有两点:第一,直接采用属性名称作为问卷问题可能导致某些问卷填写人对问题无法把握,此时,人们更加倾向于认为该特征对目标属性具有贡献作用;第二,问卷填写人本身缺乏该领域的相关认知,导致问卷填写质量不高;本文提出的方法4从多角度出发,综合多种特征选择方法,优势互补,共选择11个特征,特征选择效果较好,预处理阶段对数据的缺失值填充考虑充分,训练成本较低,且有效降低了数据特征冗余,提升了筛选准确性。四种特征选择方法共选择特征包括教育程度、居住类型、工作年限、个人收入、保险缴纳、车辆情况、信用总评分、额度。综上可知,上述8个特征对目标属性的贡献程度较大。四种不同特征选择方法的比较结果如表7所示。

表7 特征选择结果对比Table 7 Comparison of feature selection results
(2)定量评价
分别基于未特征选择数据集与四种特征选择方法降维后的数据集构建SVM(S)、Cart&T(C)、贝叶斯(B)和KNN(K)银行客户分类模型。首先基于先验认知剔除较为明显的对目标属性无贡献的特征,并通过PyCharm编程对集合后数据进行预处理,生成utf-8格式数据文件raw_data.csv,并依据不同特征选择方法分别生成数据文件pearson.csv、rf.csv、people.csv和total.csv;其次,将数据集划分为训练集(70%)和测试集(30%),并在此基础之上分别构建上述4种算法的银行客户分类模型,分别计算依据不同特征选择方法所选择数据集构建分类模型的训练集精确度(ac)、测试集精确度(tc)、查全率(tl)、查准率(pd)、召回率(rl)、F1-score(f1)以及模型训练成本(ct),最终计算结果如表8所示。
由表8中的实验结果数据可知,未进行特征选择的高维数据集的各项评价指标均低于依据特征选择后数据构建的分类模型评价指标,表明特征选择能有效提升模型性能;从SVM分类模型可见,基于方法4数据集构建的客户分类模型各项指标均优于方法1和方法3模型性能指标,同时,在各项指标基本不变情况下,方法4的模型训练成本要较方法2低0.14 s;从Cart&T、贝叶斯分类器和KNN分类模型结果可见,基于不同筛选后数据集构建的分类模型性能基本一致但基于本文特征选择方法筛选后数据集构建的分类模型的训练成本相对更低。综合以上分析可知:首先,经过特征选择后的数据各项指标更为精确,可提升分类模型性能;其次,从分类模型角度考量时,本文提出的多视角综合方法所构建出的模型指标优于其他单一方法,且较其他方法而言训练成本较低,实际操作中易于实现。
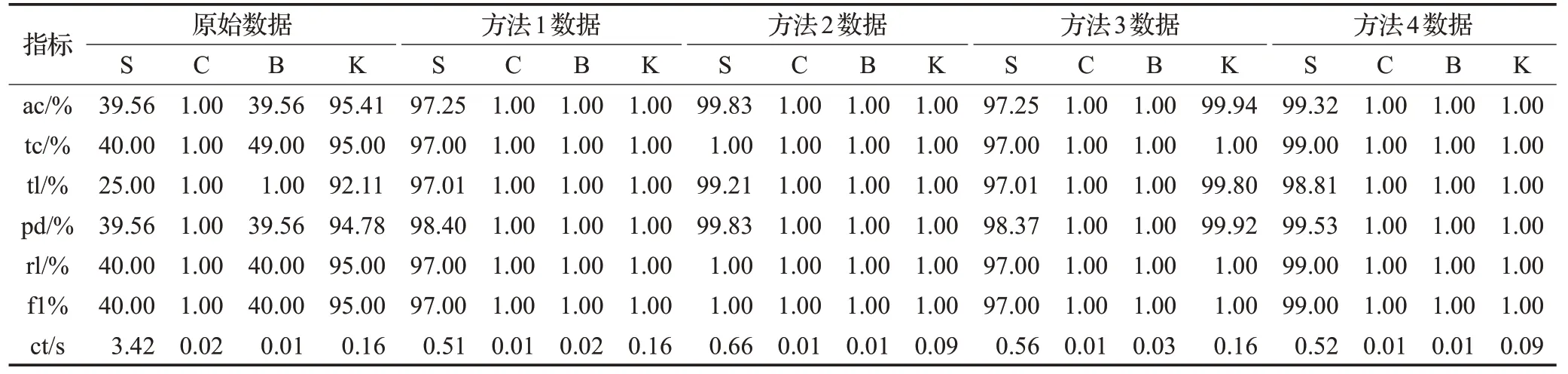
表8 特征选择结果对比Table 8 Comparison of feature selection results
3.5 研究结论
本研究提出的银行客户细分数据特征选择方法共包含三大部分:数据预处理、综合特征选择和特征选择效果评价。数据预处理是以相关预处理技术为基础,通过缺失值填补、异常值处理、数据类型转换和连续型数据离散化等操作,提高数据质量。其次分别基于统计、机器学习、先验认知和综合视角对预处理后数据集特征进行选择,其中,统计类型方法选择:Pearson相关系数,通过衡量特征与目标属性之间的相关性大小,对特征进行筛选;机器学习类型方法选择:RF特征贡献度,依据模型计算出的特征贡献度大小从小到大对特征进行筛选;先验认知类型方法选择:通过问卷调查方法量化不可直接测量的人类先验认知,通过最终问卷结果统计各特征对目标属性的贡献度,进而筛选特征;综合视角类型方法选择:考虑到不同方法之间存在的互补性,借鉴多模态情感预测后期融合思想,通过线性加权方式对上述方法计算结果进行线性加权计算。最后,基于不同筛选后数据集构建不同的客户分类模型,从定性与定量两个角度对特征选择效果进行评价。实验结果发现,未筛选特征的原始数据集构建模型性能较差,方法4特征筛选效果和模型个性评价指标较优。
4 结语
银行客户数据作为金融大数据的重要组成部分,包含了大量的有价值知识,对其进行有效挖掘可助力银行提升风险管控能力和客户满意度,但银行客户数据量之大、特征之多和价值密度之低等问题,限制了人们对银行客户数据蕴藏知识的有效挖掘。同时,现有的针对高维数据集的特征选择方法主要采用单一方式进行,并未考虑不同特征选择方法之间的互补性,另外,对人类先验认知的重视程度也远远不足。
本文提出的银行客户细分的数据特征选择方法综合考虑统计相关理论、机器学习相关理论、先验认知相关理论和多模态融合相关理论,按数据预处理、综合特征选择和特征选择效果评价策略对银行客户数据集特征进行选择。研究结果表明,本文所提特征选择方法能够有效对高维银行客户数据特征进行筛选,且筛选后特征维度较低,所构成的数据集能够有效表示原始数据集全貌,同时,基于本文所提特征选择方法特征选择后构成的数据集构建的分类模型性能,基本优于单一方法下构建的分类模型性能,不同类型下的特征选择方法可以实现有效互补,筛选出的对应特征数据集能有效提升模型性能。
本文创新点主要有:(1)结合银行客户数据自身特点,给出了一种包括类型转换及离散化,缺失值填充和标准化三部分的针对银行客户分类特征筛选的数据预处理方案,经过预处理后的数据质量得到显著提升;(2)结合认知心理学相关理论,通过问卷方式量化先验认知,并将其引入特征选择;(3)借鉴多模态情感预测思想,考虑到不同特征选择方法之间的互补性,综合主观特征选择方法和客观特征选择方法,通过后期融合线性加权方式对不同类型特征选择方法进行融合,实现方法互补;(4)提出的银行客户细分特征选择方法较前人研究更加系统全面,实证研究模型从单一数据、单一模型和多指标评价优化为单一数据、多模型和多评价指标,更具多元性,能为银行客户数据知识挖掘与价值发现提供参考。不足之处在于:不同角度特征选择方法所计算的特征贡献度系数需要人为调整,且系数设置合理与否将对模型性能产生较大影响;同时,考虑到数据采集成本等因素,未采集不同银行客户数据,对特征选择方法的适用性进行验证。
猜你喜欢
石河子大学学报(哲学社会科学版)(2019年3期)2019-07-27 01:33:48
中国生物医学工程学报(2019年4期)2019-07-16 08:04:10
中国建筑装饰装修(2017年1期)2017-02-13 09:05:07
电子制作(2017年23期)2017-02-02 07:17:06
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电力自动化设备(2015年4期)2015-09-28 02:42:54
创新作文·初中版(2015年1期)2015-03-11 23:57:54
创新作文·初中版(2014年5期)2014-07-18 20:23:30
振动工程学报(2014年4期)2014-03-01 01:15:41
计算机工程(2014年6期)2014-02-28 01:26:36
