
偏态NLME和GLMM联合模型的贝叶斯推断
2022-06-09 01:52:24宁佳男段西发
太原科技大学学报 2022年3期
宁佳男,段西发
(太原科技大学 应用科学学院,太原 030024)
近年来,HIV动态模型可以让我们更容易了解到艾滋病毒感染的发病机制[1-4]。已有研究表明抗HIV治疗的有效性跟病毒的初始衰减率和CD4增加率有关,且两者之间关系较为复杂。已有大量模型用于两者关系的研究,包括:线性混合效应(Linear Mixed Effects Models,LME)模型,非线性混合效应(Non-linear Mixed Effects Models,NLME)模型[5-8]和广义线性混合效应(Generalized Linear Mixed Effects Models GLMM)模型[9-13]等。
通常情况下,采用LME和NLME进行联合建模。本文采用GLMM将传统线性模型中响应变量服从正态分布推广到指数族分布[14]。将GLMM和NLME联合建模来研究病毒载量和CD4之间的关系。在艾滋病毒临床试验中,病毒载量的变化是应用抗逆转录病毒治疗(ART)后疾病进展的重要指标,将其作为协变量,用NLME对其进行拟合,可以更好的解释在每个个体之间和个体内部存在的较大差异。 同时,在开始抗病毒治疗后,CD4细胞计数通常会恢复,可以很好的检测患者是否治愈,在临床上具有重要意义[15]。然而,研究中数据往往会出现以下的问题。
首先,病毒载量测量存在严重偏斜,图1给出了患者开始抗HIV治疗后的病毒载量取对数后的柱状图。可以看到该数据存在正偏态状况。采用偏态分布(SN)比对称正态分布适合对这样的数据进行建模。

图1 病毒载入量取对数的柱状图Fig.1 Bar chart ofLogarithm of virus loading amount
其次,观测数据会遭受检测限的限制(LOD),当病毒载量低于限定值(LOD)时发生左删失,如果忽略,可能会导致参数估计有偏差。 通常的做法是将低于检测限(log10(100)=2)的病毒载入量统一替换为log10(50)=1.69[16].图2给出了患者开始抗HIV治疗后的病毒载量轨迹。可以看到部分病毒载入量低于检测线。

图2 HIV病人的病毒载入量Fig.2 Virus loading amount of HIV patients
本文利用GLMM和NLME对协变量具有左删失、偏态误差和响应变量具有测量误差的HIV纵向数据进行联合建模,给出参数估计的贝叶斯方法。
1 模型
在本部分给出联合模型的一般形式。考虑两个纵向过程{(xi,yi),i=1,…,n},此处xi=(xi1,…,(xini)T,y=(yi1,…,yimi)T,注意xi和yi可以具有不同的测量位置,即ni≠mi.其中xi是连续的测量值,yi是离散的测量值。于是观测数据可以表示为{(xi,yi),i=1,…,n}.
1.1 协变量模型
对于具有非正态和左删失的协变量,通过对观测个体进行重复测量,得到非独立观测数据。为了更好的描述数据,采用如下非线性混合效应模型:
(1)
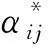
ai~N(0,A)ei~SNni,v(0,σ2Ini,δIi)
1.2 响应变量模型
对具有测量误差的离散纵向数据,采用广义线性混合效应模型进行建模。令yi=(yi1,yi2,…,yini)T为单个或者簇i内响应的ni个重复观测值。假设重复测量值yi1,yi2,…,yini服从指数族的分布。
广义混合效应模型(GLMM)如下:
(2)
此处的μij=E(yij|β,bi)为条件均值,g(·)为联结函数,xij为包含协变量的向量。β为固定参数效应,bi为随机效应,可以反应不同观测对象之间的异质性以及对同一观测对象的多次观测之间的相关性,B为协方差矩阵。这里假设随机效应bi与yi1,yi2,…,yini相互独立。
2 参数估计的贝叶斯推断
对于纵向数据,建立联合模型以后,利用联合似然函数对参数估计进行推断是必要的,但是联合似然函数推断的计算量巨大且会导致收敛问题[17]。因此本文使用基于MCMC算法的联合贝叶斯估计对参数进行估计,在样本很小的时候也可以使用真实的先验给出很可靠的结果。
考虑联合模型(1)和(2),令θ={α,β,σ2,A,B}表示所有未知参数的集合。f(·|·)和π(·)分别表示条件密度函数和先验密度函数。假定α,β,σ,A,B相互独立,即π(θ)=π(α)π(β)π(σ)π(A)π(B),为了进行贝叶斯估计,必须给出模型(1)和(2)中的未知参数的先验分布,设均值参数α,β服从正态先验分布,精度A-1,B-1,δ-2服从伽马分布(Gamma)和威沙特分布(Wishart):
α~N(0,∑α),β~N(0,∑β)
σ-2~G(w1,λ1),δ~N(0,r3)
A-1~W(∑A,r1),B-1~W(∑B,r2)
其中超参数w1,r1.r2,r3∑A,∑B,∑α,∑β已知,伽马分布G(w,λ)和威沙特分布W(v,∑)均值分别是wλ和v∑.在实际应用中,对于没有足够先验信息的,可以采用非信息先验分布。
在模型和参数先验分布确定以后,可以采用贝叶斯推断对未知参数求后验分布,基于观测数据{(xi,yi),i=1,…,n},θ的联合后验分布如下:
f(θ|D)∝L(D|θ)π(θ)
(3)
此处有
(4)
若任何先验分布都缺乏,可以选择先验π(θ)∝1,此时的贝叶斯相当于最大似然估计。
注意到(4)中的积分都是高维积分且没有解析解,而对解析解进行近似不太准确,因此,基于观测数据直接计算θ的后验分布是行不通的。作为替代,可用MCMC方法基于(4)使用Gibbs抽样器和Metropolis-Hasting(M-H)算法进行抽样,进而得到参数的贝叶斯估计。
为了避免计算(4)式的积分,从后验分布中对θ进行采样,引入潜在变量(a,b)≡{(ai,bi),i=1,…,n},各参数和随机效应的后验分布可表示为:
f(θ,a,b|D)∝f(yi|ai,bi,α,β)f(xi|ai,α,σ2)
f(ai|A)f(bi|B)π(α)π(β)π(σ2)π(A)π(B)
令α-表示θ中除α以外的其他参数,同样定义β-,σ-,A-和B-.为了运行Gibbs抽样,需要条件分布:
f(ai|yi,xi,bi,θ)∝f(yi|ai,bi,α,β)f(xi|ai,
α,σ2,δ)f(ai|A),i=1,…,n,
f(bi|yi,xi,ai,θ)∝f(yi|ai,bi,α,β)f(bi|B),
i=1,…,n,
f(σ2|D,a,b,δ-)∝f(xi|ai,α,σ2,δ)π(σ2)
f(δ|D,a,b,δ-)∝f(xi|ai,α,σ2,δ)π(δ)
f(A|D,a,b,A-)∝f(ai|A)π(A)
f(B|D,a,b,B-)∝f(bi|B)π(B)
此处
(5)
贝叶斯推理可以基于Gibbs抽样和M-H算法,利用Gibbs抽样从后验分布f(θ,a,b|D)中生成样本的描述如下。在第t次迭代时:




[5]样本δ2(t),A(t)和B(t)来自于(5)式中的分布。
在上面的Gibbs方法中,采用M-H算法更新α,β,ai,bi,i=1,…,n.从初始值(θ(0),a(0),b(0))开始,过一段时间后,从后验分布收集MCMC样本{(θ(m),a(m),b(m)),m=1,…,M}.然后,根据后验均值或分位数对未知参数进行统计推断。
3 实例分析
3.1 模型实现
在本节中,将使用NLME和GLMM联合模型来分析HIV数据集,包括46名接受了有效的抗逆转录病毒治疗的艾滋病毒感染者。在开始治疗后第0,2,7,10,14,21,28 d和第8,12,24,48周测量病毒载量。 在整个研究中记录了CD4细胞数目和病毒载入量。每位患者的观察次数从4到10不等。
对于协变量模型,采用的是NLME模型,该模型基于抗HIV治疗初期的病毒消除和产生过程。采用 AIC/BIC准则选择最佳模型参数,具体地,提出模型如下:
模型一:
模型二:
模型三:
上述三个模型AIC(BIC)值分别为:405.06(465.10),468.63(513.67),419.28(464.31).
因此,响应变量可由如下模型拟合:
(6)
xij是患者i在tij时刻的log10转化病毒载量,α0和α1是病毒基线P0,P1的对数变换。
对于CD4过程,由于缺乏基于生物的数学模型,CD4往往是经验建模。一种流行的方法是将CD4计数在200阈值处一分为二,因为此阈值是人类免疫系统的一个重要阶段[18]。采用200作为截止点,如果患者i在j时刻CD4计数大于200,则为“yij=1”,否则“yij=0”.采用 AIC/BIC准则选择最佳模型参数,具体地,提出模型如下:
模型四:
模型五:
模型六:
β0i=β0+b0i,β1i=β1+b1i,
β2i+β2+b2i,β3i=β3+b3i
上述三个模型AIC(BIC)值分别是274.61(309.05),276.15(314.41)和283.98(337.54)
因此,CD4可由如下模型拟合:
(7)

3.2 结果分析
本节中,使用了三种方法来估计模型参数并对其结果进行比较:本文所提及的联合贝叶斯方法(用JBA表示,针对联合模型(6)和(7)的贝叶斯方法)、朴素贝叶斯方法(针对模型(8)的贝叶斯方法,用NBA表示,该方法不考虑病毒载入量中的测量误差)及两步贝叶斯方法(用TSBA表示,贝叶斯框架下针对联合模型(6)和(7)的两步法)。

(8)
为进行贝叶斯推断,需要指定先验分布中超参数的值。为减少对先验信息的依赖,假定所有参数都服从弱先验分布。具体地,(1)设固定效应服从正态分布N(0;100) 并和总体参数向量α,β独立;(2)尺度参数σ2服从无信息的逆伽马分布,IG(0.01;0.01),该分布均值为1,方差为100;(3)方差协方差矩阵A,B的先验分布可取为逆威沙特(Inverse Wishart)分布IW(Ω1,ν1)和IW(Ω2,ν2),其中自由度ν1=3,ν2=3,Ω1和Ω2是主对角元素为1的对角矩阵。(4)偏度参数δ服从正态分布N(0,100).
利用WinBUGS[19]来实现MCMC抽样,通过如下两步迭代实现:(i)利用Gibbs抽样更新α,β,δ,σ,A,B;(ii)用M-H方法更新aibii=1,2,…,n.在对最终的MCMC样本收集完整后,可以用于对未知参数进行统计推断。得到感兴趣的后验均值和置信区间。对于贝叶斯建模方法和MCMC算法的实现问题,参见文献[20],其中包括超参数的选择,迭代MCMC算法,与M-H相关的密度函数的选择,敏感度分析及收敛性诊断。当在实际临床数据中采用MCMC程序时,可采用WinBUGS中标准工具(例如跟踪图)来评估生成样本收敛性。有效的方法是:在样本收敛后,得到一条长链,建议去掉初始的50 000次迭代,在接下来的300 000次迭代中30个MCMC抽样中选取一个,这样就得到10 000个用于统计推断的未知参数后验分布的样本。
表1和表2给出了基于联合贝叶斯方法(JBA)、两步贝叶斯方法(TSBA)和朴素贝叶斯方法(NBA)的模型参数估计(PM),对应的标准差(SD)和95%置信区间(LCI表示置信下限,UCI表示置信上限)。在联合模型中,各参数的估计结果大部分具有统计学显著性(因为95%置信区间不包含0).对于协变量的参数估计,可以得出两种联合模型方法(JBA和TSBA)没有太大差异。 但是TSBA相比于JBA方法有更小的标准偏差,这主要是由TSBA方法忽略了协变量的真值和其估计值之间的差异导致的。对于响应变量的参数估计,由于NBA方法忽略了测量误差,导致低估了响应变量效应(β1),同时也导致低估截距β0而高估时间效应(β2).

表 1 JBA、TSBA和NBA三种方法的部分参数后验估计Tab.1 Post-verified evaluation on partial parameters from JBA,TSBA and NBA methods

表2 JBA、TSBA和NBA三种方法的尺度参数估计Tab.2 Scale parameter estimation of JBA,TSBA and NBA methods
图3是基于JBA方法,随机选取4个病人,拟合协变量曲线。图中圆圈表明观察到的病毒载入量,直线为协变量的拟合曲线。从图4可以看出,JBA方法给出了类似的病毒载入量的拟合轨迹。
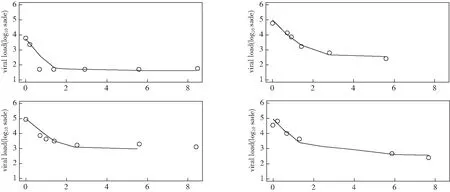
图3 对于协变量的拟合曲线Fig.3 Fit curve of covariants

图4 随机选择病人的JBA方法(点线)、TSBA方法(实现)和NBA方法(虚线)的病毒载量拟合曲线Fig.4 Viral load fitting curves of JBA method (dotted line),TSBA method (implementation) and NBA method (dotted line) for randomly selected patients
4 结论
本文利用广义线性混合效应和非线性混合效应模型来处理协变量左删失和偏态误差的HIV纵向数据。采用偏态分布替代正态分布解决偏态误差问题。对于左删失问题,采用常用的方法,将检测限以下的数据统一用log10(50)=1.69替代。采用该联合模型可以更好的解释艾滋病毒感染的发病机制,这在临床上很重要。实例分析表明相对于朴素贝叶斯方法(NBA)和两步贝叶斯(TSBA)方法,本文提出的贝叶斯方法(JBA)更加合适,给出的参数估计更加可靠。
对HIV数据,推理参数估计往往是依赖于数据的完整性,但是在实践中,由于药物的耐受性或者其他的问题导致收集的数据丢失,这种丢失的数据属于不可忽略的缺失数据,往往会导致有偏差的参数估计。然而,该问题超出了本文的范围,这可以作为下一步的研究问题。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19 13:26:28
昆明医科大学学报(2020年11期)2020-12-28 00:47:36
中西医结合肝病杂志(2020年2期)2020-10-27 02:18:30
工程数学学报(2020年3期)2020-07-06 07:38:40
长治学院学报(2019年2期)2019-07-24 07:14:04
雷达学报(2017年6期)2017-03-26 07:53:04
统计与决策(2017年2期)2017-03-20 15:25:22
数学物理学报(2016年5期)2016-08-24 07:38:48
系统工程与电子技术(2016年2期)2016-04-16 05:17:08
现代检验医学杂志(2015年4期)2015-02-06 02:02:08
