
分解多空洞深度卷积的轻量级图像语义分割
2022-06-09 01:52宣明慧张荣国李富萍
太原科技大学学报 2022年3期
宣明慧,张荣国,李富萍,赵 建,胡 静
(太原科技大学计算机科学与技术学院,太原 030024)
计算机视觉是非常热门的一个研究领域,其中图像识别[1]是为图像赋予语义含义,而语义分割则是为图像中的每个像素点赋予语义含义。
FCN[2]在分类的基础上,去掉最后的全连接层,对每个像素点属于哪一个语义标签产生预测概率,将图像分类问题转换成了像素点分类问题,是深度学习技术在图像语义分割任务上的开端。文献[3]对中间层特征图进行切分,对切分后的特征图上采样后继续提取特征,提高了对中间特征层的复用。上述模型虽然一定程度上提升了分割精度,但却产生了较大的参数量和计算量。
DeepLab V2[4]提出了空洞空间卷积池化金字塔(ASPP),并引入了条件随机场,条件随机场和马尔可夫随机场都是典型的基于统计的图像分割算法,文献[5]就是引入了马尔可夫随机场解决图像分割问题。Xception[6]提出了深度可分离卷积,实现了通道和空间区域的独立运算,减少了参数量,提升了计算速度,Mobilenet V2[7]则是通过引入深度可分离卷积实现了模型的轻量型。
Inception V3[8]通过对卷积操作的分解进一步降低了参数量和计算量,FDDWNET[9]将分解卷积、深度可分离卷积以及空洞卷积进行结合,提出了分解空洞深层卷积。ADSCNet[10]在空洞卷积和分解卷积的基础上结合密集连接实现了实时性,同时FC-DenseNet56[11]也采用密集连接方式对各级别的特征进行融合。从上面的工作可以看出,深度可分离卷积和分解卷积相较于标准卷积来说具有更少的参数量和计算量。
综上所述,本文提出了分解多空洞深度卷积的轻量级语义分割模型,将空洞卷积和深度可分离卷积、分解卷积进行结合。
本文的主要贡献:
(1)用金字塔结构提取特征,在深度卷积过程中对空洞卷积进行分解,降低参数量和计算量;
(2)对不同阶段的特征图进行融合,利用子像素卷积进行上采样,改善图像语义分割精度;
(3)在没有预处理模型的前提下,参数量和计算量都相对较低,同时语义分割精度得以提升。
1 相关工作
空洞卷积池化金字塔(ASPP):空洞卷积是在标准卷积的每个参数间插入0,在保证标准卷积参数量不变的基础上,扩大感受野,使每个卷积核获取更大范围信息,避免了池化层带来的空间位置信息丢失问题。DeepLab V2便利用空洞卷积池化金字塔模型提取多尺度的特征信息。
深度可分离卷积:深度可分离卷积分为Depthwise过程和Pointwise过程,实现了通道和空间的独立,Depthwise过程对每个通道提取特征,Pointwise过程对通道上的像素点提取特征,两个过程相当于一个标准卷积操作,但相对于标准卷积操作,减少了参数量。Mobilenet系列则是引入了深度可分离卷积,实现了推理的实时性。
分解卷积:分解卷积是将卷积分解为多个卷积,如将5*5的卷积分解为两个3*3的卷积,将3*3的卷积分解成3*1和1*3的卷积。ENet[12]引入n*1和1*n卷积代替n*n卷积,降低了模型参数量和计算量,相较于SegNet[13]速度提升了18倍,DABNet[14]提出了DABModule,将空洞卷积和标准卷积分别进行分解,将得到的特征图进行相加融合,DABNet-Light[15]将DABModule中的标准卷积替换成了深度空洞卷积,进一步降低了复杂度。
子像素卷积:Sub-pixel Convolution是文献[16]提出的、除双线性插值、反卷积等之外的一种上采样方法,ExFuse[17]则利用Sub-pixel Convolution对特征图进行上采样,且mIoU增长了0.5%.
2 本文方法
本文提出的分解多空洞深度卷积的轻量级图像语义分割网络,由特征提取、上采样两个部分组成。特征提取部分主要包括所提出的分解空洞深度卷积金字塔模块(FADWp Module),如图1所示,该模块将金字塔结构中的空洞卷积分离为深度卷积和点卷积,然后对分离出的深度卷积进行分解。上采样部分的主要思想是在利用子像素卷积(Sub-pixel Convolution)对特征图进行上采样前,先对不同级别的特征图进行融合。

图1 分解空洞深度卷积金字塔模块Fig.1 Factorization of the atrous depthwise convolution pyramid module
2.1 分解空洞深度卷积金字塔模块(FADWp Module)
由于图像中具有行人、树、车、街道、建筑等大小不同的目标,本文利用具有不同感受野的金字塔结构对图像提取多尺度特征。
假设输入特征图为Hin×Win×Cin,卷积核的尺寸为kh×kw×Cin,卷积核的个数为Cout,输出特征图为Hin×Wout×Cout,则标准卷积的参数量和每秒浮点运算次数(此处不考虑偏置)如下:
参数量:
Parameters=kh*kw*Cin*Cout
(1)
每秒浮点运算次数:
FLOPs=Parameters*Hout*Wout=
(kh*kw*Cin*Cout)*Hout*Wout
(2)
深度可分离卷积分为Depthwise(简称DW)和Pointwise(简称PW)两个过程,参数量和每秒浮点运算次数(此处不考虑偏置)如下:
参数量:
Parameters=ParametersDW+ParametersPW=
(kh*kw*Cin)+CinCout
(3)
每秒浮点运算次数:
FLOPs=Parameters*Hout*Wout=
[(kh*kw*Cin)+CinCout]*Hout*Wout
(4)
因此,深度可分离卷积的参数量与标准卷积的参数量之比为:
(5)
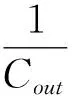
分解卷积将kh×kw的卷积核分解为kh×1和1×kw两步,参数量和每秒浮点运算次数如下所示:
参数量:
Parameters=Parameterskh×1+Parameterskw×1=
kh*Cin+kw*Cin=Cin(kh+kw)
(6)
每秒浮点运算次数:
FLOPs=Parameters*Hout*Wout=
Cin(kh+kw)*Hout*Wout
(7)
因此,分解卷积的参数量和深度可分离卷积的Depthwise过程的参数量之比为:
(8)

因此,在和空洞卷积、金字塔结构相结合时,金字塔中1×1的点卷积使用标准卷积,3×3及以上的空洞卷积使用深度可分离卷积,且其中的Depthwise过程使用分解卷积代替,这样做能够最大程度上降低参数量和计算量。
图1中的Cin、H和W表示特征图的输入通道、高度和宽度,DW表示深度可分离卷积中的Depthwise过程,Conv表示标准卷积,AConv表示空洞卷积(Atrous Convolution),1D-FConv表示分解卷积(1D-Factorized Convolution),s表示步长,r表示金字塔每一层卷积的空洞率,分别为(d-1,d,d+1),d是6次推理过程中的空洞率。为减少模型参数,在特征图进行空洞卷积前,将特征图的通道降为原来的1/4,且在金字塔结构中,只对Depthwise过程的空洞卷积进行分解,同时空洞率采用奇偶相间的值,提升像素间的相关性。
2.2 子像素卷积
子像素卷积(Sub-pixel Convolution)的本质是将低分率的特征图,按照周期性的位置,插入到高分辨率的特征图中,不需要训练调试参数就可以将R2*H*W的低分辨率特征图上采样为1*RH*RW的高分辨率特征图。如图2所示:

图2 子像素卷积Fig.2 Sub-pixel convolution
因此本文在利用Sub-pixel Convolution进行上采样前,将三个不同阶段的不同分辨率的特征图进行融合,为上采样过程提供更全面的信息。网络概括图如图3所示:

图3 网络概括图Fig.3 An overview of network architecture (图中的Downsampling和DAB module等引用自DABNet[14],FADWp Module即为本文提出的模块)
观察图3,在DABNet的基础上,将深层次处的DABModule替换成本文的分解空洞深度卷积金字塔模块(FADWp Module),并在Sub-pixel Convolution上采样前,对各阶段特征图进行融合。
2.3 实现细节
SGD优化器:初始学习率为0.1,动量为0.9,为了防止过拟合,设置权重衰减率为5e-4.
学习率衰减策略:初始学习率为0.1,连续20个迭代mIoU不增大时,执行一次衰减策略。
lr=lr*factor
(9)
公式(9)中lr为学习率,factor为衰减因子。
3 实验结果与分析
本文实验环境是线上服务器GeFore RTX 1080Ti,数据集CamVid是由剑桥大学发布的从驾驶汽车的角度得出的像素级图像语义分割数据集,共包含701张城市街道场景图。
3.1 消融实验与分析
本文对CamVid数据集进行处理,其中训练集含421张图像,验证集含112张,测试集含168张,共有11个语义类,将图像剪裁为352*352,批次设置为5.
首先,针对整个模块空洞率d展开实验,(d1,d1,d2,d2,d3,d3)分别表示本文提出模块在6次推理过程中空洞率的取值,从实验结果中可以看出当空洞率取成倍增长的偶数比非成倍增长且奇偶相间时具有更好的效果,如表1所示:

表1 不同空洞率的结果Tab.1 The results of different dilation rates
进一步地,该实验针对模块的金字塔结构中的不同空洞率进行验证,(d-1,d,d+3)分别表示在所提出的模块中,并行的三个空洞卷积的空洞率取值,当d=4时,(d-1,d,d+3)=(3,4,7),空洞率是奇数、偶数相间隔的,(d-2,d,d+2)=(2,4,6),空洞率全部都是偶数,实验证明奇偶数相间的空洞率要比全偶数的空洞率效果好。如表2所示:
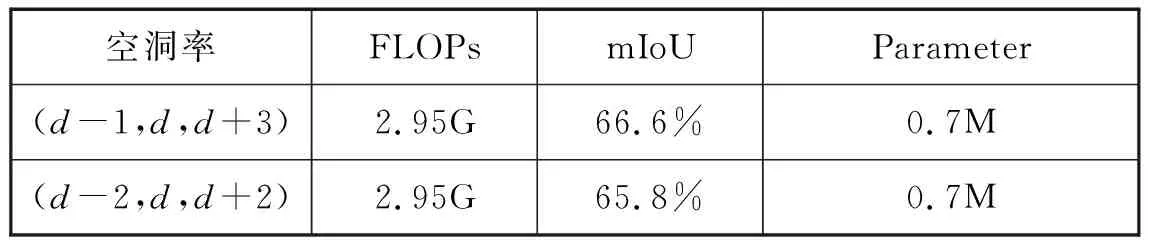
表2 金字塔结构中不同空洞率的结果Tab.2 The results of different dilation rates in the pyramid structure
最后,本文在最后上采样阶段使用Sub-pixel Convolution,实验证明Sub-pixel Convolution相较于线性插值法等常用上采样方法具有更好的表现,但计算量也较大,如表3所示:

表3 不同上采样方法的结果Tab.3 The results of different upsampling methods
3.2 与其他语义分割模型的对比分析
本文方法与ENet、SegNet和BiSeNet等9种经典方法在数据集CamVid上进行对比,评价指标包括计算量(FLOPs)、平均交并比(mIoU)、和参数量(Parameters),如表4所示:
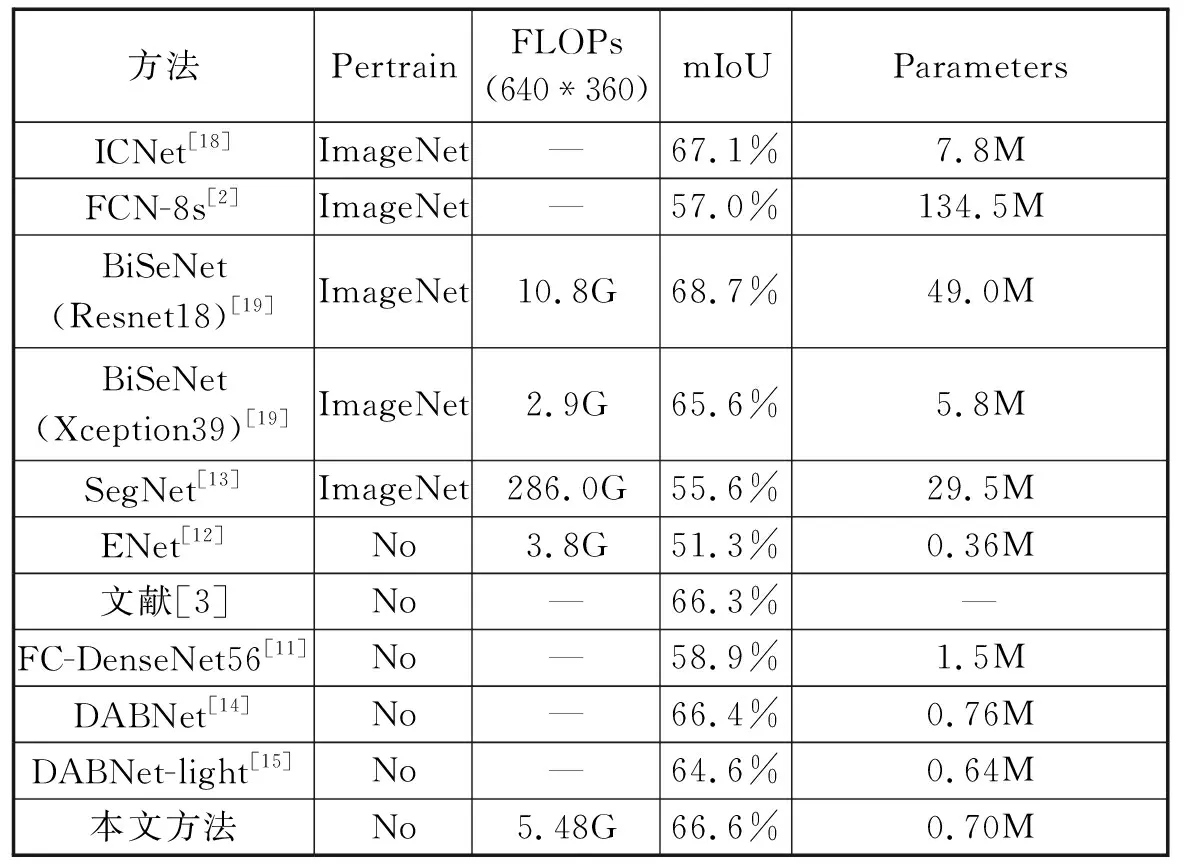
表4 各类方法在CamVid测试集上的结果Tab.4 The results of various methods on the CamVid test set
观察表4,对比在ImageNet进行预训练的5个语义分割模型,其中只有BiSeNet(Resnet18)和ICNet的mIoU超过了本文方法,分别为68.7%和67.1%,BiSeNet(Resnet18)虽然在精度上超过本文方法将近2.1%,但是另外的两个指标,无论是Parameters还是FLOPs都远远高于本文方法,ICNet的Parameters指标同样也较高,可以得出这两类方法虽得到了较好的精度但忽略了参数量和计算量,而BiSeNet(Xception39)的FLOPs虽然较低,但是参数量Parameters却相对较高,而且精度也低于本文方法。对比没有进行预训练的5个语义分割模型,其中只有ENet和DABNet-light的Parameters小于本文方法,分别为0.36M和0.64M,但是ENet的mIoU只有51.3%,低于本文方法15.3%,DABNet-light也低于本文方法2.0%,而其他方法相较于本文方法来说精度较低,参数量却较高。因此综合看来,本文提出的网络模型较好的平衡了精度和复杂度之间的关系,在保证了精度的同时,降低了模型复杂度。观察图4的可视化效果图,该模型可以较好地识别目标及轮廓。

图4 CamVid测试集可视化效果图Fig.4 CamVid test set visualization
4 结论
平衡精度和模型复杂度之间的关系是图像语义分割领域一直以来关注的问题。本文提出的分解多空洞深度卷积的轻量级图像语义分割模型,通过精简的网络结构提取了较好的语义特征,并与不同级别的特征进行融合,在保证精度的前提下降低了模型复杂度,减少了参数量和计算量。由于空洞卷积和子像素卷积导致模型在计算量上相对偏高,因此接下来将继续在提高算法的综合性能上进行研究。
猜你喜欢
环球时报(2022-09-19)2022-09-19
北京航空航天大学学报(2022年8期)2022-08-31
今日农业(2021年11期)2021-11-27
考试与评价·七年级版(2020年4期)2020-10-23
学生天地(2020年18期)2020-08-25
小学教学研究·新小读者(2017年9期)2017-10-25
故事作文·高年级(2017年2期)2017-03-01
长江学术(2016年4期)2016-03-11
长江学术(2015年1期)2015-02-27
漫画月刊·哈版(2009年10期)2009-03-26
