
手部姿态估计方法综述
2022-06-09 07:38:02梁晓辉
山西大学学报(自然科学版) 2022年3期
梁晓辉
(北京航空航天大学 计算机学院,北京 100191)
0 引言
手部姿态估计是一项基础的计算机视觉任务,其估计手部模型的参数,确定手的姿态以服务于手势交互应用,如虚拟手术、自动驾驶、体感游戏、增强现实导航等。手部姿态估计在这些应用中发挥的作用可以归纳为两类,一类是用于人机交互的手势指令,一类是用于人机交互的三维操控。
(1)用于人机交互的手势指令;手势指令指预定义一组静态手势或动态手势及相应命令,触发系统产生特定响应。手语识别、自动驾驶手势控制、体感游戏等应用场景都需要手势指令。手部姿态估计提供了手部姿态参数,有助于准确地识别手势,提升人机交互的体验感。
(2)用于人机交互的三维手势操控;三维手势操控指用户通过手有目的地操作虚拟物体,如平移、旋转、缩放等,以改变虚拟物体的状态。虚拟手术、虚拟拆装等VRAR应用都需要具备三维手势操控功能,如虚拟手术中用户使用三维手势操作手术钳。手部姿态估计可以获取每个时刻的手部姿态,进而得到手部姿态的改变量以影响虚拟物体的状态,实现三维手势操控。
手部姿态估计一直是一项研究热点,至今,该领域已取得了大量研究成果[1-3]。本文梳理了近年来手部姿态估计相关文献,对现有的手部姿态估计方法分类与总结。本文的第1节介绍了手部姿态估计相关基本概念,如手的组成、手部模型的表示方式、手部姿态估计的难点,并将现有的手部姿态估计方法分为徒手交互场景下的手部姿态估计方法和手物交互场景下的手部姿态估计方法;第2节介绍了徒手交互场景下的手部姿态估计方法和未来的研究方向,第3节介绍了手物交互场景下的手部姿态估计方法和未来的研究方向;第4节进行了总结。
1 相关基本概念
1.1 定义
手是由多个表观相似的指节和手掌铰接而成的多关节刚体。手关节的存在使得手具有自由度(Degree of freedom,DOF),不同位置的关节具有不同的自由度。如图1所示,手的自由度为26。手部姿态估计的目的是从手部数据中准确地估计手的姿态参数。手部数据的来源可分为接触式和非接触式;前者利用附着在手表面的接触式传感器获取手的运动数据,如数据手套,采集的数据形式为一维的传感器信号;后者利用非接触式传感器采集手的运动数据,如RGB相机或深度相机等,采集的数据形式为彩色图像或深度图像。相比于接触式数据,采集非接触式数据成本低,且不受设备约束;因此,在手部姿态估计研究中,研究者大都采用非接触式数据。本文主要讨论面向非接触式数据的手部姿态估计方法。

图1 手的自由度[4]Fig.1 The freedom of a hand
1.2 手部模型的表示方式
为了直观地表示手的姿态,国内外研究者通过抽象化建模提出了多种手部模型的表示方式,常用的表示方法主要包括三类,一类是三维表面表示法,一类是骨架表示法,一类是点云表示法。三维表面表示法通常利用几何体或二次曲面精确地刻画手形或皮肤表面,可细分为四个子方法,如图2所示;第一个是网格表示法,如Heap等[5]提出的可变形网格模型、Reme⁃ro等[6]提出的参数化模型MANO;第二个是几何体表示法,如Oikonomidis等[7]提出的利用简单的球体和柱体表示手;第三个是二次曲线表示法,如Stenger等[8]提出利用39个截断的二次曲线建模手;第四个是纹理表示法,该方法在手的三维网格上附加了皮肤的纹理贴图,使得手模型更真实,如Qian等[9]提出的参数化手纹理模型。其中,因MANO模型参数量较少,该表示是三维表面表示中采用较多的方式。
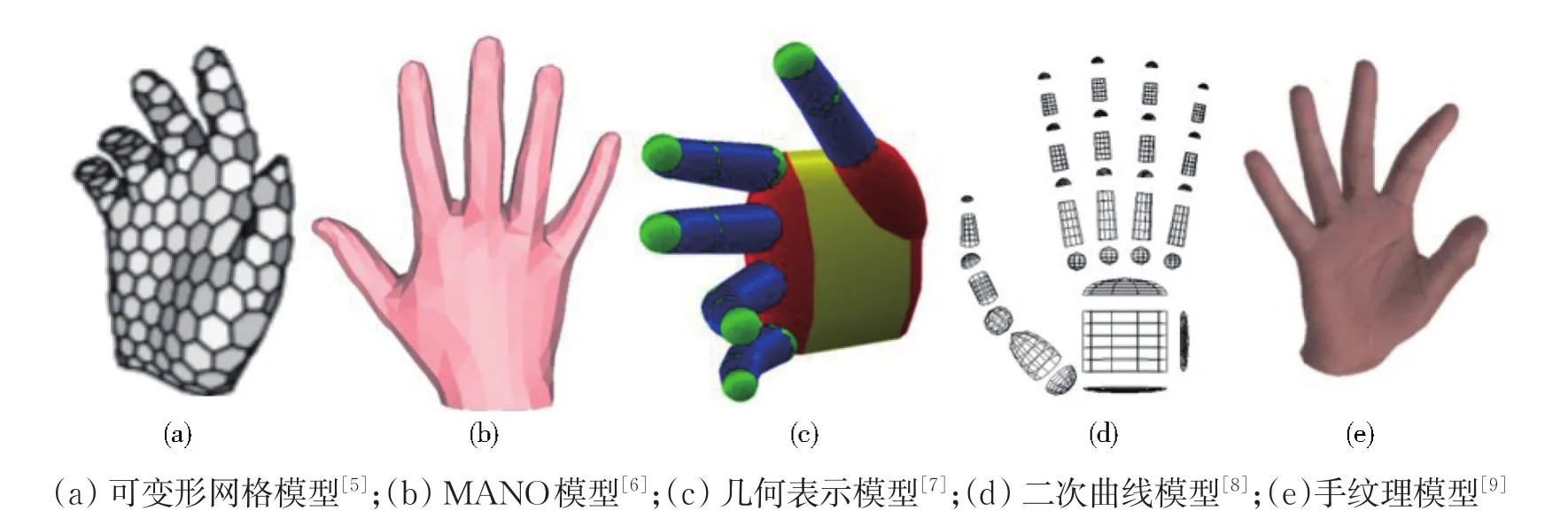
图2 手部模型的三维表面表示Fig.2 Three-dimensional surface representations of hand models
骨架表示法一般描述每个手关节的空间位置,如 Zimmermann等[10]将手模型表示为一组关节点的三维坐标,Cheng等[11]也采用了同样的表示方法,如图3所示。此外,点云表示法也是比较常用的表示方法,该方法用点云表示手,同样刻画了手形和大小,如图3所示。

图3 手部模型的其他表示Fig.3 Other representations of hand models
1.3 手部姿态估计的难点
手部姿态估计是一项具有挑战性的研究任务,主要体现在以下几个方面:
(1)遮挡问题:用户利用手势产生交互时,不可避免地为手部姿态估计带来遮挡问题,包括自遮挡问题和手物遮挡问题。首先,在单一视点下,位于视线前方的指节会遮挡视线后方的指节,使得难以获得被遮挡部分的信息。再者,手物遮挡问题发生手物交互场景下。当用户手持物体,物体不可避免地遮挡部分指节或手掌,同样增大了手部姿态估计的难度。
(2)自相似问题:一般来说,手是由五个手指和手掌组成的肤色均匀的人体器官,每个手指又由三个指节组成。这些指节的表观相似,计算机难以区分。
(3)高自由度问题:手是一个具有26自由度的多关节刚体。在高自由度条件下,如何估计符合生理约束的手势是一个难点。
(4)环境问题:复杂环境、环境光照变化等环境问题影响手部姿态估计的效果。一方面,复杂环境下可能存在与手肤色、形状相似的物体;另一方面,环境光照变化带来的过暗或者过亮会使得手难以分辨。
(5)异常运动问题:手可能发生多种异常运动,如快速移动、震颤等。这些异常运动影响手部姿态估计的鲁棒性。比如,手的快速移动直接影响相机捕获的手部图像,使得图像出现模糊。另外,手也会经常抖动,即震颤,比如疲劳或疾病因素下的抖动。
除此之外,手部姿态估计还存在手形多样、大小多样、实时性等问题亟待解决。为了解决以上难点,国内外研究者已提出相当多的手部姿态估计方法,为用户提供更自然的手势交互体验。按照手势交互的场景,本文将手部姿态估计方法分为徒手交互场景下的手部姿态估计方法和手物交互场景下的手部姿态估计方法,并在接下来的两节中详细介绍这两种方法在近年来的发展情况。
2 徒手交互场景下的手部姿态估计方法
徒手交互场景指用户空手作出相应手势,完成手势交互的场景。本小节主要介绍了近年来徒手交互场景下的手部姿态估计方法的研究现状。最早于 1996年,Shimada等[13]已经开始研究徒手交互场景下的手部姿态估计问题。此后,越来越多的研究者关注此问题。按照手势的生成方式,可以分为三类:生成式手部姿态估计方法、判别式手部姿态估计方法和混合式手部姿态估计方法。
2.1 生成式手部姿态估计方法
生成式手部姿态估计方法利用预定义的手的三维模型,如三维网格模型等,在输入的手部数据中搜索匹配,最大化相似度目标函数以得到符合最优拟合误差的手的三维模型。早期,Oikonomidis等[14-15]将手部参数所定义的手的三维几何模型渲染得到合成图像,通过约束合成图像的手部轮廓与真实图像的手部轮廓之间的误差能量函数,结合粒子群优化算法求解出模型参数。该模型包含一个手掌和五个手指,手掌由一个椭圆柱体和两个椭球体构成,大拇指由两个椎体和三个球体组成,其他手指由三个锥体和四个球体组成,如图2(c)所示。2016年,Tkach等[15]提出了 sphere-meshes模型作为手的新型几何表示,同时为模型定义了非刚性约束,优化目标函数使得模型产生非刚性形变以拟合一系列手势,运行时间可以达到60 Hz。2017年,Romero等[6]定义了 MANO 手模型,通过最小化目标函数,优化模型的形状参数、姿态参数等。2019年,Pavlakos等[16]提出了SMPL-X模型作为手的模型表示,并根据手部图像的二维特征优化模型参数。2020年,Shen等[17]面向Hololens等移动设备提出了一种类似三角网格模型的Phong表面模型来表示手,并利用基于Lifting的优化方法实时拟合模型。
2.2 判别式手部姿态估计方法
判别式手部姿态估计方法不需要预先定义人手三维模型、复杂的目标函数与优化求解算法,直接从输入的手部数据中提取具有判别力的特征即可,并学习特征与姿态空间的映射。早期的判别式手部姿态估计方法大都采用机器学习,如随机森林;Keskin等[18]为了估计手部姿态参数提出了一种多层随机决策森林算法,首先利用一个随机森林对手部形状分类,然后针对每个类别分别通过随机森林对输入的深度图像作像素级分类,最后计算出每个类别区域的中心以作为人手关节坐标。随着深度学习在特征表示与学习方面表现出不凡的性能,越来越多的研究者研究基于深度学习的手部姿态估计方法。按照神经网络的类型,基于深度学习的判别式手部姿态估计方法可以分为基于卷积神经网络的方法和基于图神经网络的方法。
2.2.1 基于卷积神经网络的方法
Tompson等[19]是将卷积神经网络应用到手部姿态估计的先驱者,他们搭建了简单的卷积神经网络提取手部图像特征,并为21个手部关节生成热图,然后利用逆向运动学原理由热图和特征推断出准确的手部姿态。随后,手部姿态估计领域涌现出诸多基于卷积神经网络的手部姿态估计方法。按照输入数据的类型,将基于卷积神经网络的手部姿态估计方法分为面向单张彩色图像的方法、面向单张深度图像的方法和面向三维数据的方法。
面向单张彩色图像的方法 2017年,Zim⁃mermann等[20]提出了一个三阶段的网络从单张彩色图像中估计手部姿态,首先使用语义分割网络提取手部区域,然后采用卷积网络定位手部关节点的位置,最后根据2D关节点位置和先验知识估计出3D关节位置。2018年,Mueller等[21]基于循环生成网络构建了合成的手势数据集,并以此训练了现有的卷积神经网络,提升了现有方法的泛化性。2019年,Zhang等[22]提出了一个端到端的手部姿态估计方法,该方法由三部分组成,第一部分估计手部关节点的二维热度图,第二部分以热度图为输入迭代地回归估计手模型参数,第三部分则利用手模型参数生成相应的手模型。2020年,Fan等[23]为了解决手部姿态估计中精度与效率难平衡的问题,提出了Adaptive Computationally Efficient(ACE)网络,该网络利用基于高斯核的门控模块动态地在轻量型网络和复杂网络中切换。Spurr等[24]针对三维手势数据集标注费时费力的问题,提出了一个基于弱监督的方法,设计了基于生物力学的损失函数,将输入手部图像的二维姿态拟合为三维姿态。Kulon等[25]提出了网格卷积解码器,该解码器将从手部图像中学习到的特征解码为手的三维网格。Zhou等[26]提出了面向多模态数据的方法,除了手部图像,输入数据可以是手部姿态的二维标注、三维标注或三维动画。
2021年,Spurr等[27]针对个体间手的肤色多样的问题,提出了一种弱监督的对比学习方法,该方法在真实场景下有较好的泛化性。Tang等[28]为了实时准确地估计手部姿态,提出了一个三阶段网络,第一阶段估计手的掩膜和关节点坐标,第二阶段估计粗糙的三维网格模型,第三阶段利用图卷积网络将图像与网格模型对齐。Chen等[29]为了估计高精度、高保真的三维手部模型,提出了I2UV-HandNet方法,该方法首先估计输入图像对应的UV贴图,然后将该贴图重建为高分辨率的UV贴图,最终得到准确的三维手部模型。Zhang等[30]考虑了多种任务之间的相关性,设计了一个级联的多任务学习框架,联合手的骨架模型估计任务、手的分割任务和手的三维网格模型估计任务。Chen等[31]也基于多任务学习提出了S2hand方法,同时估计手的三维姿态、手的形状、手的纹理和相机视点。
面向单张深度图像的方法 2017年,Ge等[32]提出了3D卷积神经网络以从单张深度图像中估计手部姿态。2018年,Wu等[33]认为每个关节的热度图对遮挡问题更鲁棒,提出了利用每个关节的热度图引导堆叠式网络估计手部姿态。2019年,Xiong等[34]提出了 Anchor-to-Joint(V2J)方法,在关节点上设置了可以捕获空间上下文信息的锚点,以精确地估计每个关节的位置。2020年,Wan等[35]提出了一个双阶段的二维全卷积网络以估计手的三维网格模型,第一阶段估计深度图像到三维网格的稠密对应,第二阶段则由可微操作得到一组三维坐标点,最后采样这组点得到三维网格模型的顶点。Malik等[36]针对从单张深度图直接估计三维网格模型存在透视失真的问题,提出了HandVoxNet的同时估计手的体素化网格和手的表面模型,最后将两者对齐以得到准确的三维网格模型。
面向三维数据的方法 2018年,Ge等[37]提出Hand PointNet直接处理采集的手的点云数据,捕获复杂的手部结构,估计出一组手的关节坐标。Moon等[38]认为从二维图像中直接回归三维姿态是一个高度非线性问题,提出了V2V-PoseNet,以体素化数据为输入回归手关节的三维坐标。2019年,Chen等[39]针对手势数据集标注费力的问题,基于自组织网络,提出了SO-HandNet以学习手部点云的特征并估计手部姿态。Li等[40]针对体素化计算花费较大等问题,以手部点云数据为输入,利用置换不变层学习点特征,提出了一种基于投票机制的手部姿态估计方法。2021年,Cheng等[11]提出了HandFoldingNet,该方法以手的点云数据为输入,将预定义的手的骨架模型嵌入到网络中引导网络估计准确的手部姿态。
2.2.2 基于图神经网络的方法
因图神经网络在结构化数据上表现了较强的建模能力[41-44],已有研究者尝试利用图神经网络解决手部姿态估计问题。2019年,Cai等[45]利用图神经网络建模手关节间的时空约束,学习二维姿态到三维姿态的映射。2020年,Fang等[46]为了建模关节间的依赖关系,提出了基于图推理模块的图卷积网络,从深度图像中稠密地估计U-V-Z三个方向的偏移。Kong等[47]将手按照骨架的连接方式定义为一个图,图节点的特征表示为关节的二维热度图,提出了SIA-GCN方法来学习关节间的关系。
2.3 混合式手部姿态估计方法
混合式手部姿态估计方法将生成式和判别式方法组合到一个框架,一般先使用判别式方法的结果作为生成式方法的初始化,由于前者提供了比较好的初始化,后者更容易优化求解得到更好的效果。Ye等[48]提出了一种基于运动学分层策略的手部姿态估计方法,该方法将提出的策略应用到基于空间注意力机制的判别式方法的输入空间,及基于层次粒子群优化的生成式方法的优化过程。Sridhar等[49]提出了一种新颖的检测引导优化策略,增加了姿态估计的鲁棒性和速度。在检测步骤中,随机决策森林将一个个像素分为手的部件;在优化步骤中,使用一种新的目标函数,该目标函数组合手部件标签和高斯混合特征来表示姿态的深度。后来,Sridhar等[50]又提出了3D关节高斯混合对准策略来实现手部姿态估计,适用于快速姿态优化,对准能量函数使用正则化器来解决手和物体接触产生的遮挡问题。Panteleris等人[51]提出手部姿态估计三步走的路线,首先使用现有的、效果比较好的手部检测器定位分割手部,然后用预训练好的OpenPose判别式网络模型估计手部关节点的2D位置,最后用非线性最小二乘法将2D姿态拟合为3D姿态。2017年,Mueller等[52]利用两个卷积神经网络定位手和关节,结合对应的深度值,回归手关节的三维位置。2018年,Wan等[53]将手部姿态参数分解为2D热度图、3D热度图和三维方向向量场,并设计了级联的多任务网络回归这三项,最后利用启发式方法拟合手部姿态参数。
2.4 未来的研究方向
前文已介绍了近年来徒手交互场景下的手部姿态估计方法,结合近年来的研究热点,未来徒手交互场景下的手部姿态估计可在以下几个方面进行进一步的研究:
(1)面向单张彩色图像的手部姿态估计更具挑战性 相比于深度图像和三维数据,单张彩色图像缺少三维信息,遮挡问题尤为突出。如何从二维图像信息中准确地估计与图像一致的三维手部姿态是面向单张彩色图像的手部姿态估计要解决的基本问题。
(2)估计更符合生理约束的手部姿态 手是一个复杂的生理器官,如何建模手的生理结构约束是一个难点问题。已有研究者尝试设计多分支的卷积神经网络、时空图卷积网络等来捕获手关节间的结构关节,但性能仍存在一定的提升空间。
(3)泛化性更强的手部姿态估计 现有的手部姿态估计方法大都是在现有的大规模数据集上训练的,其在真实环境下泛化性较差。但标注真实环境下手部的三维姿态信息费时费力,无法为现有方法提供真实环境下的标注数据以供训练。目前一些研究者已提出基于半监督或无监督的方法来解决这个问题,但如何减小手部姿态估计方法对数据集的依赖,且提升方法的泛化性仍是待解决的问题。
3 手物交互场景下的手部姿态估计方法
手物交互场景即用户手持物体或操作物体的场景,该场景主要出现在AR/VR应用中,如用户手持物体作出悬空手势。在该场景下,遮挡问题、握姿合理化等问题是手部姿态估计面临的挑战。近年来,深度学习在各个领域发挥重要作用,已有研究者可以提出基于深度学习的方法来解决手物交互场景下的手部姿态估计问题。
3.1 现有的方法
因卷积神经网络在徒手交互场景已表现出较好的性能,现有的手物交互场景下的手部姿态估计方法大都也基于卷积神经网络。2019年,Hasson等[54]设计了生成式网络分别地生成手部和物体的姿态参数。Tekin等[55]将手部姿态估计、物体姿态估计、物体识别和活动识别四个任务整合到一个框架中,利用任务间的相互关系估计手部和物体的姿态。2020年,Has⁃son等[56]提出以光流和手部掩膜来约束手部和物体的姿态。Karunratanakul等[57]提出利用距离场来约束手部和物体的姿态。2021年,Cao等[58]针对手物交互下数据集难标注的问题,提出了一个双分支网络,利用二维数据训练网络,分别估计手的姿态和物体姿态,建模了手物交互关系,有效地解决遮挡问题。Yang等[59]将手物交互建模为弹簧质子模型,提出了交互势场的概念来表示手物交互力,并设计了MI⁃HO框架来建模手物交互关系,同时估计手和物体的姿态。Zhang等[60]首先训练了一个联合学习网络估计手关节的三维位置,同时分割手和物体,然后利用手的深度信息、物体的深度信息及手关节的三维位置联合优化,以重建手物交互。
因图神经网络能够建模复杂的结构关系,一些研究者将图神经网络引入手物交互方法中。2020 年,Doosti等[61]先用现有的基于卷积神经网络的方法估计手部和物体的二维姿态,然后利用图神经网络学习二维姿态到三维姿态的映射,以得到最终的手部和物体的三维姿态。该方法的优越性在于图神经网络建模的结构关系解决了手物交互的遮挡问题。但是,该方法将手部和物体定义为一个图,忽略了手部和物体的差异性。近来,Transformer在各个领域表现突出,已有研究者将其应用到手物交互场景下的手部姿态估计。2020年,Huang等[62]提出了基于Transformer的HOT-Net来捕获手的关节点和物体角点的关系。2021年,Liu等[63]提出了一个联合学习框架同时估计手和物体的姿态并基于Transformer设计了上下文推理模块以建模手物交互关系。
3.2 未来的研究方向
前文已介绍了近年来手物交互场景下的手部姿态估计方法,结合近年来的研究热点,未来手物交互场景下的手部姿态估计有以下几个方面值得进一步研究:
(1)建模手物交互关系。手与物体交互时,不可避免的产生相互作用力、摩擦力等。结合手的生理结构与物理原理,如何基于现有的图神经网络、Transformer等先进的网络结构,设计建模手物交互关系的网络模型是未来的一个研究方向。
(2)数据集标注方法。现有的方法大都依赖大规模的数据集,然而,在手物交互场景下,手物遮挡增大了标注数据集的难度。结合半监督学习、迁移学习等理论,自动化地标注手物遮挡下的手势数据集是未来需要解决的问题。
(3)生成合理的握姿。合理的握姿指符合手生理结构约束的、抓取位置恰当的抓取姿态。如何设计生成式网络,根据不同的物体,生成可指导机械手作出类人抓取等合理的握姿是一个新的研究热点。
4 结论
手部姿态估计是一项基础的计算机视觉任务,可应用到多种场景,如虚拟现实、增强现实、自动驾驶、机器人控制等。从早期基于机器学习的方法,到现在基于深度学习的方法,手部姿态估计领域已展现出蓬勃的发展趋势。本文梳理了近年来的手部姿态估计方法,根据手势交互的场景,创新地将手部姿态估计方法分类为徒手交互场景下的手部姿态估计方法与手物交互场景下的手部姿态估计方法,并对这些方法梳理总结,归纳了其在未来的研究方向。
猜你喜欢
实用手外科杂志(2022年2期)2022-08-31 09:48:02
学生天地(2020年3期)2020-08-25 09:04:16
红领巾·萌芽(2019年9期)2019-10-09 03:42:56
小学科学(学生版)(2018年12期)2018-12-19 05:13:50
汽车观察(2018年9期)2018-10-23 05:46:40
中国自行车(2018年8期)2018-09-26 06:53:44
小学阅读指南·低年级版(2017年6期)2017-06-12 01:39:24
实用手外科杂志(2015年4期)2015-08-27 01:54:14
中华皮肤科杂志(2014年4期)2014-12-19 12:56:00
中国药业(2014年21期)2014-05-26 08:56:48
