
大数据背景下机器学习在数据挖掘中的应用
2022-06-09 12:40上海警备区殷倩倩申鑫欣夏祎
数字技术与应用 2022年5期
上海警备区 殷倩倩 申鑫欣 夏祎
在互联网信息技术飞速发展的今天,互联网信息化技术已经渗透在人们工作、学习与生活的方方面面,促进了社会生产力水平的显著提升。在信息技术应用过程中,会形成海量的数据信息,为加强对各项数据信息的管理与利用,需要采用科学、高效的数据处理技术对其价值进行全面发掘。故此,本文针对现阶段大数据背景下机器学习在数据挖掘中的应用情况展开分析,首先介绍了大数据应用背景,然后对机器学习与数据挖掘技术进行简要介绍,最后就大数据背景下机器学习在数据挖掘中的应用展开一系列分析,希望对于大数据技术的发展有所助力。
数据挖掘技术的应用和大数据的发展是相辅相成的,在发展过程中,通过对数据挖掘技术的有效应用可以逐步提高系统对各种数据信息的处理能力,同时还能够进一步降低数据信息管理成本的投入。但是,随着各行业的发展与数据规模的暴增,对于数据挖掘技术的应用也提出了更为严格的要求。机器学习作为一门交叉学科,应用计算机处理技术对人类行为进行智能化模拟,以此进行知识和技能的获取,同时还能够不断进行知识结构的调整和优化,将机器学习应用在数据挖掘中可以进一步提高大数据处理效率,因此得到广泛应用。为了能够在数据挖掘中充分发挥机器学习的应用价值,相关从业人员还需对机器学习的应用问题展开深入分析,使其更好地助力社会的进步与发展。
1 关于大数据背景的介绍
近年来,随着互联网信息化技术的应用和发展,每天所生成的海量数据需要采用更加高效的管理措施进行处理,提高数据信息的管理质量。但是,随着信息化技术应用的加深,生成的各种数据类型更为丰富,信息数据也更加庞大,显然采用传统的处理方式已经无法适应当前的数据处理需求。在这种情况下,需要采用更为先进的数据处理方式以满足各行业的数据信息处理工作需求,大数据技术则应运而生。与传统的数据处理技术相比,大数据技术下的信息储存、分析等方式发生了明显变化,在数据的运算方面也采用了更为先进的处理方式,为数据处理和决策系统提供了更大的助力。大数据的主要特点在于其数据信息内容丰富及种类繁多等,同时还有着更为快速的信息传输速率,因此得到了更为广泛的应用与深入的发展。
2 数据挖掘与机器学习概述
2.1 数据挖掘
在数据挖掘技术中,机器学习和统计算法均为重要组成内容,其中机器学习属于人工智能技术的一种,能够在样本集训练与学习中快速地明确其中各项参数与运算模式[1]。而统计算法则为通过对概率等数据的分析以及数据相关性等进行运算,对于不同的研究领域需要应用不同的算法也不尽相同,在实际应用中还可以结合其计算目标选择各种算法的单独应用或者结合应用。对于机器学习而言,其中的人工神经网络技术得到了广泛的应用,其具有高效的自主学习能力与数据处理能力,同时,其对于各类型的数据能够进行快速、精准的识别。通过对数据挖掘的应用能够结合具体情况进行科学建模,且模型具有精度高及描述能力强等特点。但是在训练数据时需要花费较多时间,对数据进行理解时也不是很智能,伸缩性和开放性仍存在一定的提升空间。
2.2 机器学习
2.2.1 主要任务分析
作为现代信息化技术体系当中的重要内容,机器学习的重要任务主要体现在以下几点:(1)数据的快速分类。在系统运行中,可根据数据信息的处理要求进行数据建模,在此过程中实现对数据的快速、高效分类处理。(2)数据的回归分析。通过技术手段对各种类型的数据变量及其相互间的关系进行全面性的护理与总结,在此基础上获得表现数据关系的公式。在数据处理工作当中,通常需要对统计学相关知识加以应用,借此进行数据的估测等,继而实现数据挖掘效率的提升。(3)数据的关联规则。无论是在任何一种行业领域当中,都会面临对于事务型数据信息的处理需求,在此方面,可以通过机器学习实现数据样本空间的建立,便于对将来某些事件的发生情况进行科学预测。(4)数据的聚类。这里我们所说的聚类主要指将数据按需聚集到各自的数据簇中。
2.2.2 大数据中对于机器学习的应用优势
传统机器学习算法的应用需依赖内存容量,在存储数据信息时,计算机无法对PB与TB级别的数据信息予以存储,所以,部分算法是无法满足大数据背景下的数据挖掘需求的,在这种情况下,就需要加强实践并逐步进行算法的优化,进一步满足数据处理要求。人工神经网络为大数据背景下机器学习计算方法中的一种,能够通过人工神经网络模型的构建而体现出多元化的描述能力,并且其数据处理精度较高。在当今时代对大数据技术应用日益深入的环境下,对于机器学习的应用也提出了更加个性化的要求。一方面,随着各行业的发展,所生成的数据信息更为海量,数据类型也更为繁复;另一方面,在系统运行过程中,各类型数据的分布情况较为复杂,若是始终应用传统的机器学习方式根本无法全面满足数据信息的独立与分布需求。通过对机器学习的有效应用能够使得大数据的功能性显著强化,且将数据分类器设置在数据样本分布较为密集的区域可以进一步提高数据分类处理工作质量[2]。在当前大数据背景之下,机器学习显然已与传统的概念发生脱离,且不断向知识学习及处理的复杂化方向演变,成为数据挖掘技术不断优化的重要途径。
2.3 机器学习的算法
2.3.1 朴素贝叶斯算法
常规条件下,该算法可细化分为以下几个步骤:(1)按照特定的操作指令去采集数据信息的样本,并且标记好集合中的不同元素,为后续操作中元素的提取做好铺垫。(2)进行数据信息样本的统计,借此明确数据集合中各类别所出现的概率,便于后续进行分类器的获取。(3)将待处理的样本置入分类器内,借此获取样本处理结果。该算法虽然目前得到了广泛的应用,但其在应用过程中也体现出一定的缺陷,例如,该算法认为分类的样本特征本身与其他特征值不相关,所以无法进行样本各个特征间的相关性计算。而该算法在计算应用中具有显著的便捷性特点,可有效提升计算速度。
2.3.2 K-Means法
在机器学习算法当中,该算法具有较高的普及度。与其他算法相比,该算法的应用较为方便,K-Means法需以对距离度量算法的应用作为基础,因此,在数据聚类的条件之下,若数据样本数量越多,那么该算法应用的错误率则会降低,若数据聚类的训练集越大,该算法也就会显示出更为明显的分类性特点。
设k是K-Means聚类算法的输入参数,表明算法在数据集中进行k个聚类簇目,并且输出计算结果的聚类簇目。数据集合是由n个模式组成,模式也代表数据点的意思。在K-Means聚类算法数据初始化时,依据输入参数k随机地从n个模式{i1,i2,…in}中找出k个原型{W1,W2,…Wk}。因此Wj=it,j∈{1,2,…,k},t∈{1,2…,n}。Cj是第jth个聚类,Cj的值是输入模式即数据点之间互不相交的子集,而想要对其结果展开质量评价则需以下述函数进行:
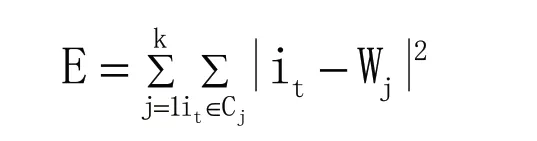
在该函数中,E即为各数据点和簇的质心距离和,因此,若E的数值较小,那么簇的紧凑性就越大,所以,在机器算法的应用中需通过E这一数值的优化以获取更优的数据类聚方案,直至E的数值极小,其所获得的方案可行性则为最佳。
2.3.3 决策树算法
该算法在应用中实则为对于数据输入空间的分割,通过分割获得若干区域,而各个区域都具有各自相对独立的参数。在算法的实际应用中,通常是以数据的树形模型为基础而展开相应的分析,其中全部的数据叶子节点以及根节点均为分类化的路径规则,并且其中所有的叶子阶均为一种判断类别。在该算法的应用中,通常是先对数据样本实施分割处理,使其划分为样本的子集,随即再进行分割的递推,从而使得所有的子集均可以得到同类数据样本并进行其类别的预测。与其他类型的算法相比,该算法的突出特点在于其结构相对简单,对于数据信息的处理速率较高。
3 数据挖掘中对于机器学习的应用原理分析
机器学习的类型具有一定的丰富性,其涉及的内容也比较广泛,结合以下几方面领域的应用情况对数据挖掘的应用原理展开分析:
3.1 人工神经网络
机器学习的主要应用原理为通过特定的算法展开数据建模,借此来模拟人类的大脑系统,并对其中所有神经系统的作用进行分析,同时明确各神经所处位置,从而明确各个神经系统在大脑中的运行过程。在进行建模的过程中,机器学习通过对不同的神经单元进行处理而形成相应的数据信息层级序列[3]。在上述过程当中,其应用的逻辑原理主要为:通过对特定算法的应用进行模拟刺激,在系统接收到刺激信号之后,对数据信息进行筛选和处理而得到的最终结果。
3.2 向量机
向量机也是数据挖掘技术中的重要组成部分,在进行向量机的应用中,对各项数据的处理均需用到数学思维,利用回归算法来处理各种数据信息问题,借此推测相应的未知结果。利用算法的有机结合与三维空间的数据多维分析来进行特定算法的推演。
3.3 推荐算法
在数据挖掘的机器学习当中还存在一种被广泛应用于商务领域的算法,也就是推荐算法。该算法可以将系统用户的浏览信息为条件对其感兴趣的信息进行分析,例如淘宝,在淘宝用户进行各种商品的浏览时,即可通过推荐算法的运行对用户在平台中的商品浏览频率等对其商品购买偏好等信息进行分析,确定用户喜欢的商品种类。
4 数据挖掘中对于机器学习的应用
4.1 对于向量机的应用
在进行向量机的应用中,主要是通过其定位理论原则对待处理数据信息加以分类,完成待处理数据的区域化选择,该部分的大体流程为:(1)对锁定区域的经纬度实施首次定位,明确具体位置后再对其进行划分,实现该位置的栅格化。(2)完成位置的划分后,还需将其根据具体的位置信息细化为两部分,并对二者展开精确计算。但是,这两部分的数据信息计算方式存在一定差异,其中一部分在计算中需对待测数据样本实施向量计算,而另一部分则应以回归函数计算方式对数据样本进行计算分析。借助对差异算法的应用得到个性化的定位方案。但是需要注意的问题是,在对向量机进行应用时应严格遵循最小化原则。除此之外,在通过向量机来采集数据样本的时候,一定要做好多维度的点积计算,只有这样才能够充分保证其中非线性问题的妥善解决。在人们的日常生活方面,向量机多被用在各行业领域的人脸识别系统以及汽车发动机的故障问题检测等方面。
4.2 对于卷积神经网络的应用
卷积神经网络可以利用算法学习对海量的数据进行特定的处理,并且可以展开高效的自我学习。卷积神经网络的主体结构和常规性的神经元大致相同,具体而言,卷积神经网络在计算层级上先是通过对数据输入的求和,然后再利用函数计算来展开神经网络系统建模。在对卷积神经网络进行实际应用中一定要注意其中的三个重要参数,即数据区域大小、神经元之间的联系以及神经元的数量。现阶段卷积神经元多用于计算机自然语言数据信息的处理方面以及计算机视觉语言的处理方面,在计算机识别过程中,通过对该网络系统的应用可以实现光谱特征以及光谱建模的可视化。前馈神经网络CNN作为一种深度学习方法,可以使用没有经过光谱预处理的原始光谱进行建模,改进了光谱分析的流程,比如卷积神经网络可用于分析实验室中山羊角水解过程中的拉曼光谱。
5 结语
随着时代的进步与科技的迅速发展,大数据时代悄然而至,在大数据技术在各行业领域的应用逐步深入的背景之下,想要充分发挥大数据技术的应用优势,对于数据挖掘技术的掌握、研究与应用是必不可少的。机器学习作为当前数据挖掘中的重要内容,通过对其应用能够更加准确、快速地处理各种复杂性问题。对此,相关人员还需加强对机器学习的应用实践与深入研究,加强技术应用与优化,进一步发挥机器学习在数据挖掘中的应用优势,为社会的进步与发展提供更大的助力。
引用
[1] 黄心依.机器学习在数据挖掘中的应用研究[J].信息记录材料,2021,22(8):121-123.
[2] 谭成兵,周湘贞,朱云飞.基于Weka和协同机器学习技术的数据挖掘方法研究[J].长春大学学报(自然科学版),2020,30(6):5-9.
[3] 戴惠丽.大数据背景下机器学习在数据挖掘中的应用研究[J].吕梁教育学院学报,2019,36(3):20-21.
猜你喜欢
环球时报(2022-07-13)2022-07-13
心理学报(2022年4期)2022-04-12
环球时报(2022-03-14)2022-03-14
水泵技术(2021年3期)2021-08-14
电影(2018年8期)2018-09-21
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
中国惯性技术学报(2015年1期)2015-12-19
电子设计工程(2014年18期)2014-02-27
测绘科学与工程(2013年3期)2013-03-11
