
基于 Spark 和SimHash算法的文章原创性检测系统设计与实现
2022-06-09 01:37李昌东
计算机应用文摘·触控 2022年9期


摘要:传统的基于文本的原创性检测建立在平台的投稿机制上,无法对现存的文章进行原创性检测。文章提出了基于Spark和SimHash算法的文章原创性检测系统,利用大数据技术进行非原创文章和原创文章配对,实现动态“阅读原文”功能。
关键词:Spark ;原创性检测; SimHash
中图法分类号:TP391文献标识码:A
Design and implementation of article originality detection system based onSpark and SimHash
Li Changdong
(East China Normal University,Shanghai 200241,China)
Abstract:The traditional text-based originality detection is based on the contribution mechanism of theplatform,which can not detect the originality of existing articles.This paper proposes an article originalitydetection system based on spark and SimHash algorithm,which uses big data technology to pair non-originalarticles and original articles to realize the function of “reading the original text”dynamically.
Key words: Spark , originality detection,SimHash
1 背景
互联网内容平台是内容的聚集地。随着知识付费等创新模式的普及,很多作者希望通过文章写作的方式获取粉丝、流量、打赏、奖励等。正是因为在互联网内容平台进行文章写作可以带来收益,很多公司或者个人选择使用抄袭、改编、洗稿等手段将外部平台的优质原创内容转变成“自己的作品”,借此不断提升公司或者个人在平台内的影响力。然而,抄袭、搬运、非授权转载等手段极大地打击了原创文章作者的写作积极性和热情。
2 SimHash文本相似度计算方法
相似哈希( SimHash)是最早由谷歌于2007年的论文[1]中提出的,用于检测长文本相似度。SimHash是一种局部敏感哈希,其哈希值在一定程度上可以表示文本特征。SimHash的设计思路是将文本转化为特征向量的形式,将高维特征向量转化为低维特征向量,最终通过哈希值之间的海明距离大小判断文本间的相似性。根据谷歌论文中的结论,在64位SimHash签名场景中,当两个文本的海明距离小于等于3 時,可以被认为是相似的。依据抽屉原理,海明距离小于等于3 为相似判定标准时,在分成4 段的情况下,至少有一段签名完全相同。
从实验角度比较SimHash指纹不分段和分为4 段的执行效率,如图 1 所示。实验步骤如下:(1 ) SparkSQL读取数据库内数据,并暂存于内存中;(2)生成一个SimHash指纹,并与数据库内数据指定数据量的数据进行相似度计算,结果中仅保留海明距离小于等于3 的数据;(3)分别测量SimHash指纹不分段(Divide By 1)和分为4 段(Divide By 4)时的执行时间。
从图1 可以看出,使用分段方式筛选后,有效减少了指纹的比较数量,提升了SimHash算法相似度计算效率。
3 系统需求分析
系统的目标是使用大数据技术对内容进行原创性检测,建立原创文章和非原创文章之间的关联关系,将检测结果提供给每一个希望从互联网内容平台查看优质内容的用户,可最终实现提升原创作者利益与提升普通用户使用体验的效果。
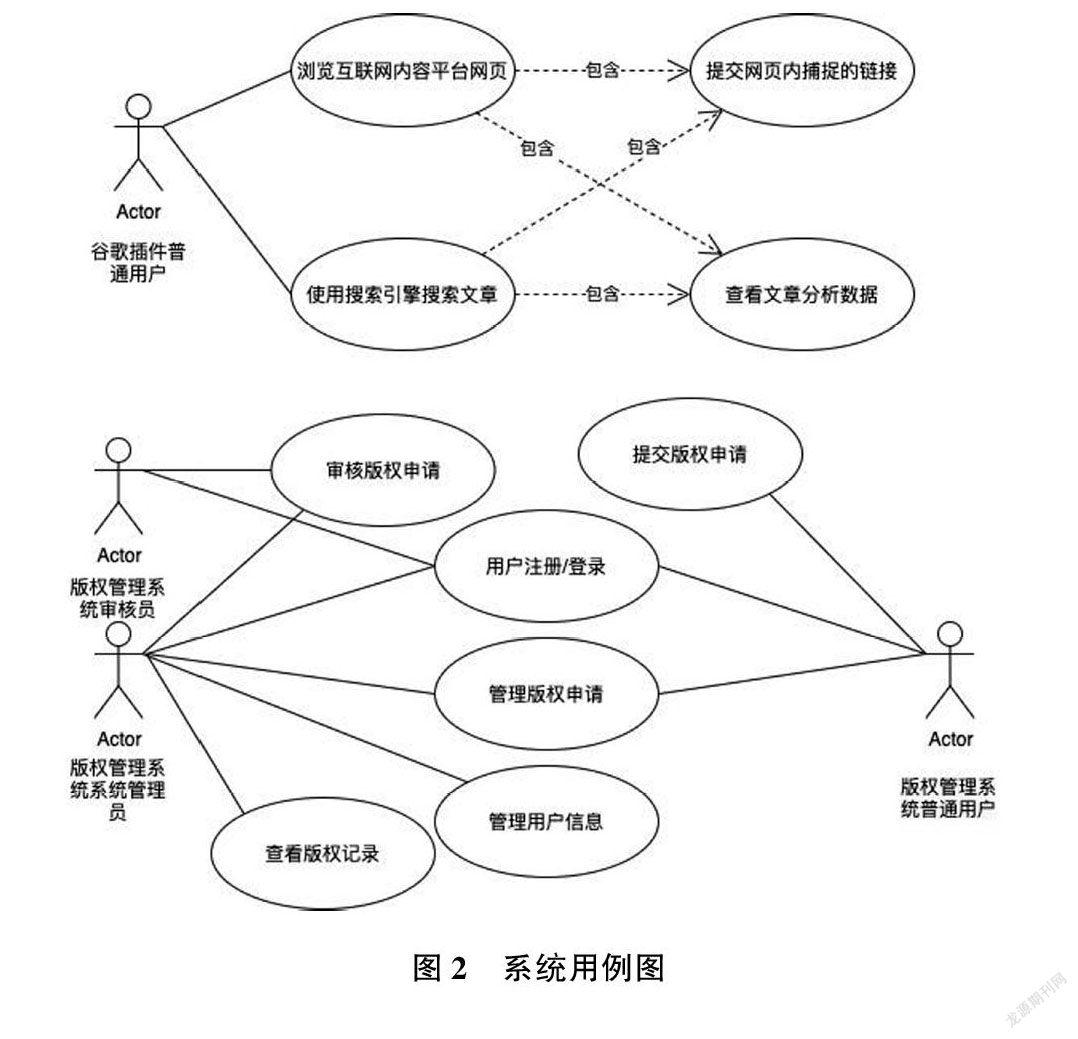
系统用户角色可以分为四类,即谷歌浏览器插件用户、版权管理服务普通用户、版权管理服务审核员、版权管理服务系统管理员。
(1)谷歌浏览器插件用户
在用户浏览搜索引擎的结果页面时,不需要打开结果链接即可知道链接关联的文章的各种分析数据,包括文章状态、文章版权说明、文章最近似的原创文章等。如果某篇文章被系统认定为非原创文章用户,可以点击谷歌浏览器插件提供的原文链接跳转到原创文章的地址。在用户浏览互联网内容平台时,谷歌浏览器插件会自动收集网页内所有链接地址,筛选出符合文章类型的网页并定时发送至后端服务。
(2)版权管理服务普通用户
普通用户可以在版权管理服务中提交已经拥有的文章版权信息,由专业审核人员进行版权信息真实性、一致性校验。在通过版权认证后,文章会在谷歌浏览器插件中显示为原创文章,并带有版权标志。
(3)版权管理服务审核员
审核员负责审核用户提交的版权申请并进行真实性、一致性校验。
(4)版权管理服务系统管理员
系统管理员负责管理普通用户信息、管理审核员信息、审核版权申请、查看审核日志。
系统用例图如图2 所示。
4 系统整体设计
本系统可以划分成五个服务,即谷歌浏览器拓展程序、爬虫服务、后端服务、版权管理服务、Spark 分析服务。本文主要介绍其中的后端服务与 Spark 分析服务。
谷歌浏览器拓展程序为用户提供实时查询最近一次文章原创性分析结果的功能;爬虫服务为系统提供文章的原始数据,包括文章发布时间、文章正文内容、文章标题等;后端服务提供 HTTP 请求接口,用于接收用户侧提交的网页地址。提交接口有两种,一种用于查询某些文章的原创性检测结果,另一种用于捕捉未被数据库收录的互联网内容平台文章链接。后端服务起到服务间沟通的作用,通过 Kafka 消息队列向爬虫服务发送爬虫任务请求并监听爬虫任务执行结果、向 Spark 分析服务发送 Spark 分析任务请求并监听 Spark 分析任务执行结果;版权管理服务提供一套人工审核文章版权信息的管理方案,用户负责提交版权申请,审核员负责审核版权申请的真实性与一致性;Spark 分析服务通过大数据方法建立原创文章与非原创文章之间的关联,通过 Kafka 消息队列接收 Spark 分析请求和发送 Spark 分析结果。D931089D-E4DB-4488-9FA4-FEED2E495A91
5 后端系统实现
后端服务是一组运行在 Docker 容器中的服务,并且以 Linux 系统中的 Open JDK11作为容器内的运行环境。后端服务对外主要提供提交接口 (路径/ submit)—用于查询一组文章的原创性检测结果和定时提交接口(路径/schedule/submit)—用于尽最大努力发现未知的链接,捕捉未被数据库收录的互联网内容平台文章链接。
后端服务的主要接口包括:后端服务提交接口和后端服务定时提交接口。
(1)后端服务提交接口
后端服务提交接口负责向用户提供最近一次的文章原创性检测结果。当用户发送一组请求链接后,所有符合条件的链接根据互联网内容平台的文章网页正则表达式规则进行匹配,并筛选出不重复的链接。匹配成功后根据响应缓存记录和爬虫任务缓存记录判断下一步的操作。如果响应缓存记录不存在,则向 Kafka 的 update 主题发送异步消息,通知更新响应缓存记录,执行 Spark 分析任务。如果爬虫任务缓存记录不存在,则向 Kafka 的spidertask主题发送异步消息,通知爬虫服务爬取文章的原始数据。
(2)后端服务定时提交接口
后端服务定时提交接口负责接收来自用户的各种链接。与提交接口类似,定时提交接口也使用正则表达式规则对链接进行匹配,并从地址中筛选出符合互联网内容平台文章网页地址特点的地址。与提交接口不同的是,定时提交接口仅通过爬虫缓存记录执行不同的操作。当爬虫缓存记录存在时不进行任何处理;当爬虫缓存记录不存在时向 Kafka 的spidertask主题发送异步消息,通知爬虫服务爬取文章的原始数据。
6 Spark 分析服务实现
Spark 分析服务通过监听 Kafka 主题sparktask获取来自后端系统的 Spark 分析任务。借助 Spark Streaming 和 Spark SQL 技术,Spark 分析服务可以定时获取并解析 Spark 分析任务的 Kafka 消息,从大数据角度进行文章原创性检测。
详细运行机制如下:(1)关系型数据库筛选并读取所有原创文章;(2)从原创文章的集合中查询所有与请求信息中文章的SimHash签名距离小于 K 的原创文章的集合;(3)从第2 步的结果集合中分别按照文本相似度优先和时间优先的多维排序规则找到相关的原创文章。
针对排序规则,实践后发现,文章发布时间的精度无法完全统一并且存在作者“一稿多投”的情況。基于此,本系统引入版权标识与文章浏览量作为额外的排序条件。通常来说,经过人工版权审核的文章一定是原创文章;未完成版权审核的文章,在平台推送机制下或者浏览器搜索排名机制下,浏览量越高的文章往往被看作原创文章。因此,只有采用多维度立体式的分析方法才能在实践中找到最贴合实际的原创文章判断的标准。
7 Spark 分析服务优化
根据新榜2019年微信公众号大数据信息,2019年发表的原创文章占2019年发表的文章总数的6%以下。根据上述信息可以推测,随着年份的增加,原创文章的增长速率远小于文章总数的增长速率,那么原创文章的数量级保持在一个稳定的范围内。读取原创文章可以最小化数据库记录读取数量,不必将所有记录全部加载至数据库。因为 Spark 分析服务 SQL查询中仅涉及排序和筛选操作,数据量非常大,符合联机分析处理(On ?Line Analytical Processing)的场景。MySQL 数据库尽管拥有价格低廉、性能稳定的特性,但是在频繁读取大量数据的场景下并不能为系统带来处理时间上的增益。ClickHouse是一款开源的列式数据库,其以优异的查询速率而闻名。在带宽相同的情况下,ClickHouse读取数据的速率远超 MySQL 等传统行式数据库。
经过实验,以100万条测试数据为例,随机传入1000条分析请求,除去读取请求的时间,ClickHouse方案平均耗时 94s ,MySQL 方案平均耗时 135s。ClickHouse方案速度快的原因如下:一方面ClickHouse数据加载速度快;另一方面数据几乎全部在内存中执行各种操作,处理一条请求的速度是 MySQL 方案的1.5倍。ClickHouse的数据库表结构如下:
数据库设计的思路是在ClickHouse内对每一个 id 维持一份最新版本的数据,所有读取到的数据都是最新版本数据。由于ClickHouse自身的结构不支持唯一主键,并且不支持数据删除,因此需要为ClickHouse设计一套适合特性的处理逻辑。ClickHouse的VersionedCollapsingMergeTree引擎可通过标识位和版本号机制实现数据版本折叠功能。在查询的时候需要执行分组与聚合操作,ClickHouse SQL 示例如下:
8 结束语
随着各类技术的不断发展,相信未来版权保护方面一定会有更新更完善的方法,让每一个拥有原创文章的创作者获益。
参考文献:
[1] Manku G S ,Jain A ,Das Sarma A.Detecting near?duplicates for web crawling [ C]∥ International Conference on World Wide Web.ACM ,2007:141.
作者简介:
李昌东(1996—) ,硕士,研究方向:大数据技术。D931089D-E4DB-4488-9FA4-FEED2E495A91
