
基于生成对抗网络和联邦学习的非侵入式负荷分解方法
2022-06-08 14:05吴钉捷李晓露陆一鸣
电测与仪表 2022年6期
吴钉捷,李晓露,陆一鸣
(1.上海电力大学 电气工程学院,上海 200090; 2.国网上海能源互联网研究院有限公司,上海 201203)
0 引 言
在泛在电力物联网的背景下,非侵入式用电负荷感知是新一代智能电表应具有的重要功能,通过对用户的用电总量进行精细化分解,可得到负荷成分和能耗占比,不仅能够为用户提供电器级别的用电详情和建议,而且是电力公司开展营销业务和电网运维的重要依托。利用面向边缘终端设备的人工智能技术和云边协同计算来实现本地化的数据分析和挖掘,可降低对集中式数据中心的依赖。
基于智能电能表的高频和低频采样数据,可形成相应的负荷分解方法。高频采样能够提供负荷投切的暂态特征,并以此辨识出电器的启停次数[1]。文献[2]将负荷的相似特征转换为离散模糊数矩阵,根据矩阵质心评价值来辨识出最有可能的负荷投切。文献[3]将负荷投切转换为二分图寻优匹配问题,提出基于改进匈牙利算法的多重匹配策略。高频采样对电能表的硬件要求较高,可用于对特定设备的监测,但不适用于居民负荷。
由于低频稳态特征不具有明显的辨识性,多数文献会对电器运行状态和时间的先验信息进行聚类[4-5]和建立概率统计模型。文献[6]对样本电器的功率分布按工/休日进行聚类得到负荷特征,并利用遗传算法来拟合采样功率,得到最优的设备工作状态序列和对应功率。文献[7]根据历史用电数据来提取电器运行的时间概率分布和电器组合超状态,利用时间概率最大似然估计得到负荷分解结果。文献[8]构建了负荷状态和行为模板,并引入分时段状态概率因子作为负荷新特征,通过多特征遗传优化迭代实现负荷分解。然而,不同用户的非同源数据可能具有不同的概率分布,使用K-means等非监督聚类算法可能效果不好[9]。
目前,有学者将深度学习应用于负荷分解中,并充分发挥其自动特征提取的优势。文献[10]利用降噪自编码器进行负荷分解,取得了较好效果。文献[11]将电器状态进行组合编码,利用自然语言处理领域的seq2seq模型将待分解的能量信号与状态码进行映射训练,实现负荷分解。文献[12]对不同电器分别构建seq2seq模型,将分解功率的值回归问题转换为求取分解功率值在各个离散整数功率值下概率的多分类问题。文献[13]利用双向门控循环网络来挖掘负荷分解时间点与前多序列之间的时间关联特征以及电器运行状态与时间的潜在关系。
传统集中式的模型训练方法会增加数据中心的计算和通信压力,并且无法保护用户的数据隐私。为此,首先提出一种基于生成对抗网络的负荷分解模型,通过轻量化生成网络和判别网络,使其能应用于边缘终端设备。其次,提出了一种基于联邦学习的网络模型实施方案,以云边协同的方式对模型进行训练,并利用公开数据集进行了测试和验证。
1 非侵入式负荷分解模型
对于居民用户,由智能电能表采集得到的总功率信号P(t)是n个不同类型家用电器功率信号的线性叠加,负荷分解可被视为一个“去噪”任务,即试图从其他电器产生的背景噪声中恢复某个特定电器的功率信号Pi(t),如式(1)所示:
(1)
式中Pj(t)为非指定电器功率信号之和;e(t)为电能表的测量误差。
在图像去噪领域,应用较广的是卷积神经网络,通过构建自编码器[14]对原始图像进行噪声特征提取,进而生成干净图像。对于时间序列数据的处理,同样可以使用一维卷积神经网络[15],由于其具有平移不变性,在某个时段内学习到的特征可在其他时段中被识别。但卷积自编码器属于无监督学习,所生成的时间序列无法评判优劣,因此构建了基于生成对抗网络[16]的负荷分解模型,如图1所示。

图1 基于生成对抗网络的负荷分解模型
生成对抗网络由生成网络G和判别网络D两部分组成。生成网络通过学习电器的功率分布特征,生成对应的分解序列。判别网络对输入样本进行真假判别,区分真实数据和生成的数据。通过迭代训练两个网络,使生成网络生成的分解序列更加真实,而判别网络的辨识能力相应增强,两个网络相互对抗,最终达到一个动态均衡,即生成的数据已足够真实,判别网络无法辨别真伪。
1.1 生成网络
文中仅利用电表采集的有功功率数据,因此生成网络的输入为一个1×H1维的总负荷有功功率序列z,为了得到某个指定电器的功率分解序列,需要将该电器类别标签作为额外的条件输入,以指导数据生成过程。为了使标签信息不被长序列数据掩盖,通过词嵌入层(Embeding)[17]将电器类别标签转换为稠密向量,并与总功率序列相乘,得到融合序列。如图2所示,通过构建编码器-解码器结构来实现端到端的序列映射。

图2 生成网络的结构
编码器网络由多个一维卷积层(Conv)组成,对于每个卷积层l,有Kl个1×F×Kl-1的卷积核以步长Sl在输入特征矩阵Xl-1上分别进行滑动卷积来学习不同的单一特征,例如一个1 kW的功率跃变,从而得到输出特征矩阵Xl,并可计算该卷积层所需训练的参数数量Mltrad和计算代价Cltrad,如式(2)所示:
(2)
Mltrad=F×Kl-1×Kl
(3)
(4)
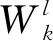
目前智能电能表的低频采样频率最高可达1 Hz,每天可采集上万个点的总有功功率序列。对于长序列数据的处理,如果将其直接作为模型的输入,则网络结构会变得更为复杂,同时参数量剧增容易导致模型过拟合,故需要对输入数据进行分段训练。为了进一步减少网络参数量,使模型能在嵌入式设备中应用,采用深度可分离卷积[18]替代部分传统卷积。
深度可分离卷积层(Conv-dw)由深度卷积和点卷积组成,利用Kl-1个1×F×1的卷积核分别对输入特征矩阵Xl-1的不同通道进行深度卷积,并在此基础上利用Kl个1×1×Kl-1的卷积核进行点卷积,所得到的输出特征矩阵Xl与传统卷积的大小一致,但网络参数Mldw和计算代价Cldw减少为传统卷积的1/Kl-1/F倍,如下所示:
(5)
(6)
Mldw=F×Kl-1+Kl-1×Kl
(7)
Cldw=(F×Kl-1+Kl-1×Kl)×[(Hl-F)/Sl+1]
(8)
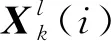
解码器网络同样利用多个一维卷积层将提取的特征转换为功率分解序列,为了使多维的特征矩阵逐步还原为初始序列的大小,需要在每个卷积层dl中增加上采样(Up-Sampling)。例如,在将1×Hdl-1×Kdl-1的输入矩阵变换为1×Hdl×Kdl的输出矩阵时,需要先在输入矩阵元素之间填充Pdl个0元素,并将其作为新的特征输入,然后再通过Kl个1×F×Kdl-1的卷积核以步长Sl进行卷积操作。Pdl的计算公式如式(9)所示:
Pdl=[Sdl×(Hdl-1-1)+F-Hdl]/2
(9)
在生成网络中的每个卷积层之后都会设置一个批标准化层(BN)和ReLU激活层。BN层通过对卷积层的输出进行标准化来避免梯度消失问题,从而加快模型收敛,提高训练速度。如式(10)所示,ReLU激活函数会使一部分输出变为0,从而形成较好的网络稀疏性,有助于缓解过拟合,并且可以防止有功功率分解时负值的产生。
ReLU(x)=max(0,x)
(10)
1.2 判别网络
判别网络的一个作用是对输入的电器功率分解序列进行真假判断,与生成网络不同,电器标签信息并不作为条件输入,而是需要判别网络额外输出所属的电器类型。增加辅助分类器Q可以检验判别网络是否正确识别出电器类型,从而保证了辨别真伪的有效性。此外,训练深度学习模型通常需要大量的带标签数据,而实际的用户数据中往往缺乏可用的标签信息,经过预训练的生成对抗网络可根据辅助分类器结果自己为数据添加标签,进而生成本地数据集,提升本地模型的训练效果。
从表1可以看出,判别网络的结构与生成网络中的编码器相似,首先通过多个卷积层进行特征提取,然后通过全局平均池化(Global-AvgPooling)进一步对序列特征压缩,最后利用两个全连接层(Full Connect)分别构建二分类器和多类别分类器。二分类器用于输出样本的真伪,使用sigmoid函数进行激活。而多类别分类器采用softmax函数来输出电器的标签预测结果。

表1 生成对抗网络的构建
1.3 损失函数
生成网络G和判别网络D采用交替训练的方式,首先保持生成网络的参数固定,利用生成的不同类别电器的分解序列G(z)与真实分解序列x来训练判别网络的辨别真伪能力,同时对辅助分类器P(C=c|·)进行训练,以识别电器类型。通过更新判别网络的参数来最小化损失函数LD,如下式所示:
Lsrc=-Ex~Pdata[logD(x)]-Ez~Pz[log(1-D(G(z,c)))]
(11)
Lcls=Ex~Pdata[logP(C=c|x))]+Ez~Pz[logP(C=c|G(z,c))]
(12)
LD=Lsrc+Lcls
(13)
式中Pdata为真实序列样本;Pz为生成序列样本;c为电器类别标签;Lsrc为辨别样本真伪的损失函数;Lcls为辅助分类器的损失函数;E(·)为数学期望,例如Ex~Pdata[logD(x)]表示真实样本判断为真的期望。
然后保持判别网络的参数不变,通过最小化生成的功率分解序列G(z,c)与真实分解序列x之间的L2距离来训练生成网络。由于判别网络已具备一定的辨别真伪能力,可加入损失函数Lgan来指导生成更接近真实的序列样本,如下式所示。
(14)
Lgan=Ez~Pz[log(D(G(z,c)))]+Ez~Pz[logP(C=c|G(z,c))]
(15)
LG=Ldis+λLgan
(16)
式中Ldis为基于L2范数的损失函数;LG为生成网络的总损失函数;λ为判别网络损失函数的权重,用于控制对生成网络的监督反馈强度。
识别真假样本通常比生成真实样本更容易,因此可能会出现判别网络的辨别能力太强而导致生成网络无法继续训练。另一方面,如果判别网络能力太差,不能分辨真假,会使生成网络生成的样本不稳定。因此,在每一轮的训练过程中,辨别网络和生成网络的迭代次数之比通常为nd:1(nd≥3)。
2 基于联邦学习的模型实施方案
传统集中式的模型训练方法需要将全部数据上传到数据中心,这会造成巨大的计算压力和传输开销,并且由于不同用户的数据通常是非独立同分布的,使得统一模型不能深入挖掘某一特定用户的数据特征。本节提出一种基于联邦学习[19]的非侵入式负荷分解实施方案,通过将深度学习模型嵌入到智能电能表等边缘节点,并与云计算中心协同完成模型的训练,可实现本地化的数据采集、存储和负荷分解,保证用户信息安全和数据隐私。
联邦学习算法的工作原理如图3所示。假设有1个云计算中心和K个边缘节点,云计算中心对一个全局的负荷分解模型L(w)进行预训练,并将其参数w下发给边缘节点,边缘节点k(k∈K)利用本地数据和接收的参数来训练本地模型,经过uk次迭代更新参数,并上传给云计算中心,如式(17)所示。
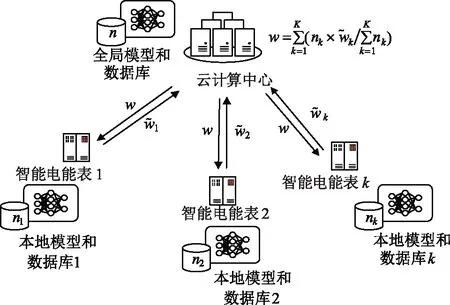
图3 基于联邦学习的模型实施方案
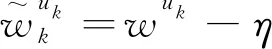
(17)
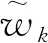
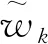
(18)
式中nk为第k个边缘节点的训练样本总量。
通过对全局模型的准确性进行评估来优化训练过程,并将更新后的全局参数保存和下发,进行下一轮的协同训练。当各边缘节点的模型准确率达到要求标准后,即可停止训练,并进行本地的负荷分解计算。
由上述训练过程可以看出,云计算中心和边缘节点之间只需进行模型参数交换,避免了数据丢失和泄露,但需要以牺牲计算量为代价来换取双方较少的通信次数,故对边缘节点设计了以下三个控制计算量的超参数。
(1)参加训练的边缘节点比例c:其取值范围为c∈(0,1],通过随机抽取c·K个边缘节点参与新一轮训练,可增加样本多样性,提高模型的收敛速度,并排除通信中断的边缘节点;
(2)样本批处理量b:每次学习的样本数量越多,则训练速度越快;
(3)训练次数e:每一轮本地模型的训练次数越多,受全局模型的影响越小,更能反映本地特征。
其中,样本批处理量b与训练次数e的关系如式(19)所示:
b=e×nk/uk
(19)
式中uk为每轮训练的迭代次数。
3 仿真分析
3.1 数据集构建
文中选取REDD数据集[20]进行模型训练与测试,其中包含6户美国家庭的用电数据,单个电器的有功功率采样间隔为3 s。对于缺失数据的处理,可参照文献[10],当出现大于2 min的间断时,可视为电器关闭,对其中缺失数据进行补零,而小于2 min的间断主要是由无线传输故障造成的,可使用线性插值法补全。
表2反映了各个家庭的数据采集情况,其电器类型和数据量差异较大,故选取常见的洗碗机、冰箱、电灯、洗衣烘干机和微波炉作为研究对象。为了构建各家庭的本地数据集,可提取某类电器每天的有功功率序列,并将剩余电器的功率序列作为噪声数据,均以50%概率进行叠加,得到总功率序列。而全局模型的数据集由所有家庭的数据组合而成,两者均以6:2:2的比例分为训练、验证和测试集。考虑到实际应用中历史数据较少,因此将本地训练集中60%的数据替换为由预训练模型生成的样本,并且随着本地模型训练准确度的提高,对生成的数据集进行更新。
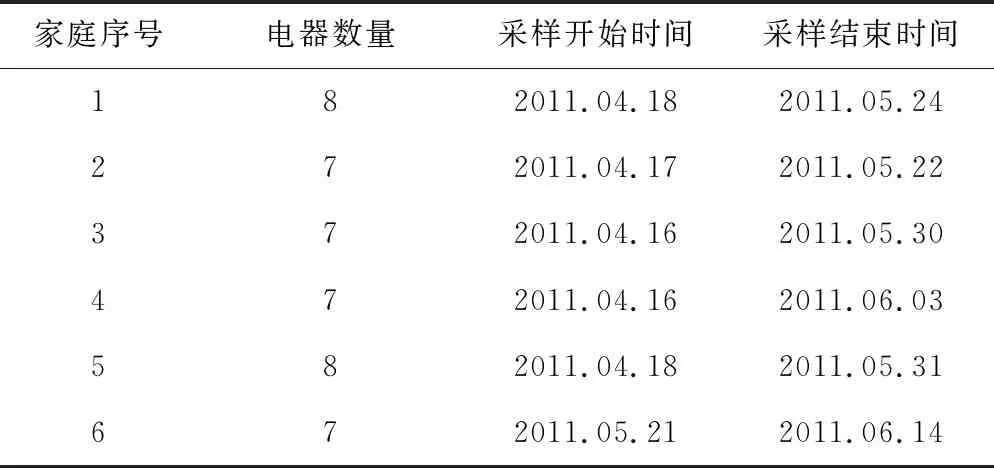
表2 各家庭的数据采集情况
3.2 模型训练
由于电表采样间隔为3 s,设置模型的输入序列长度为4 800,可跟踪长达4 h的负荷变化。根据表1可计算出生成网络的训练参数为18 736个,辨别网络的训练参数为52 128个,而利用传统卷积层构建的模型拥有454 064个参数,由此可见,经过轻量化的GAN模型更适用于边缘嵌入式设备。
使用Tensorflow搭建生成对抗网络模型进行预训练,并引入早停机制,即当在验证集上的误差开始增加后停止训练,可避免继续训练导致过拟合。
图4展示了生成网络和判别网络在预训练过程中损失函数值的变化,所呈现的大幅震荡为两者对抗训练的结果。判别网络在初期的辨别能力较弱,随着训练次数的增加,损失函数的值逐渐减小。由于判别网络的参数更新次数相对较多,在与生成网络的对抗过程中保持了一定优势,对生成样本的质量要求更高,使得生成网络的损失函数值有所上升。

图4 生成对抗网络的损失函数值变化
将全局模型的预训练参数下发给各家庭的本地模型,并基于Tensorflow-Federated框架进行联邦学习,设置协同训练50次,每轮的训练参数为c=1,b=6和e=5,并且计算各本地模型在每轮协同训练后对本地测试集的准确率Acc,如式(20)所示:
(20)
式中TP和TN分别表示电器实际处于工作状态,模型分解结果为工作和非工作状态的序列点总数;FP和FN分别表示电器实际处于非工作状态,模型分解结果为工作和非工作状态的序列点总数。
图5中曲线最左端的初始值代表了预训练模型对于各家庭的负荷分解效果,且并没有达到全局模型的基准准确率,而在经过10轮联邦学习后,部分本地模型的准确率超过了全局模型,这说明本地模型能够在全局模型的基础上更好地挖掘单个家庭的用电特征。此外,由于在第3轮训练后,各本地模型的准确率都有一定的提升,利用模型的自监督标记能力对训练集进行更新,使得之后的准确率有所降低,但随着对新数据的深入学习,最终模型的准确率超过了以往水平。

图5 联邦学习的测试准确率
3.3 负荷分解结果
以家庭1的电器为例,将基于组合优化算法(CO)[6]、因子隐马尔科夫模型(FHMM)[20]和文中提出的生成对抗网络模型(GAN)的负荷分解结果进行对比。图6和图7分别展示了洗碗机和洗衣烘干机的负荷分解结果,其都属于多状态电器,并且工作时间较长。由于CO和FHMM通过负荷特征聚类,所能表示的功率特征有限,从而形成了矩形线形,而GAN生成的分解序列具有较好的趋势跟踪效果,能够反映电器功率波动,且曲线相似度较高。

图6 洗碗机的负荷分解结果
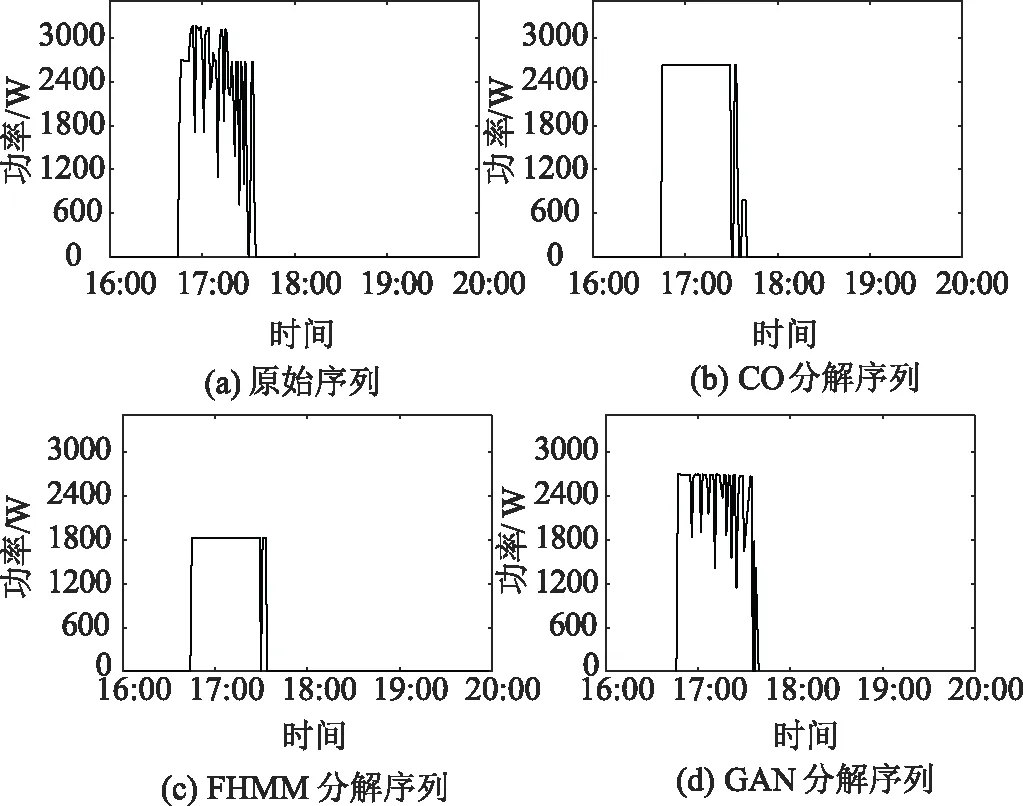
图7 洗衣烘干机的负荷分解结果
如图8和图9所示,冰箱和电灯都属于长时间跨度的电器,但不同的是冰箱为间隔性启动,而电灯多在晚间连续运行。对于冰箱,CO识别启动间隔的能力较差,FHMM会忽略出现最高功率值的时刻,而这些反复出现的负荷特征是GAN最容易学习到的,因此生成的分解序列较为真实。由于电灯的功耗较低,容易被其他大功率电器掩盖,对于其辨识和定位较为困难,CO与FHMM均出现了较大偏差。

图8 冰箱的负荷分解结果
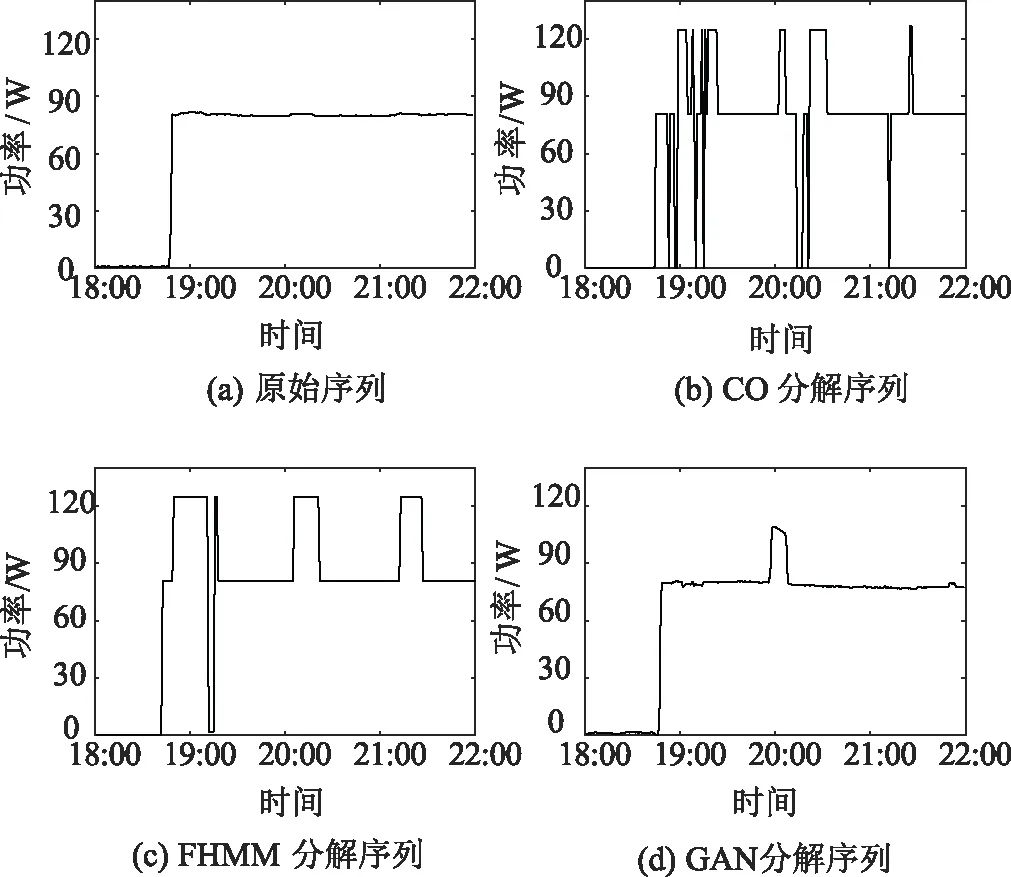
图9 电灯的负荷分解结果
从图10可以看出,微波炉的使用多集中在三餐时间,并且运行时间较短,使用频率较高。由于其功率值较大,具有良好的辨识性,三种方法均能成功识别,但对于功率值的估计,GAN最接近真实值。

图10 微波炉的负荷分解结果
为了全面评价模型的负荷分解效果,将轻量化的GAN与基于传统卷积层构建的Trad-GAN以及CO和FHMM进行比较,分别对每户家庭7天的负荷数据进行测试,选取功率分解准确率AP作为评价指标,如式(21)所示:
(21)
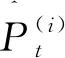
表3展示了各模型的负荷分解准确率,CO与FHMM在不同家庭的分解结果中各有优劣,并且对家庭4和家庭6的负荷分解效果较好。GAN和Trad-GAN的功率分解准确率都超过了前两种模型,虽然Trad-GAN的准确率保持领先,但考虑到训练成本和模型部署难度,轻量化的GAN牺牲了较少的准确率而大幅减少运算量,使之完全可以取代Trad-GAN,具有更大的应用前景。
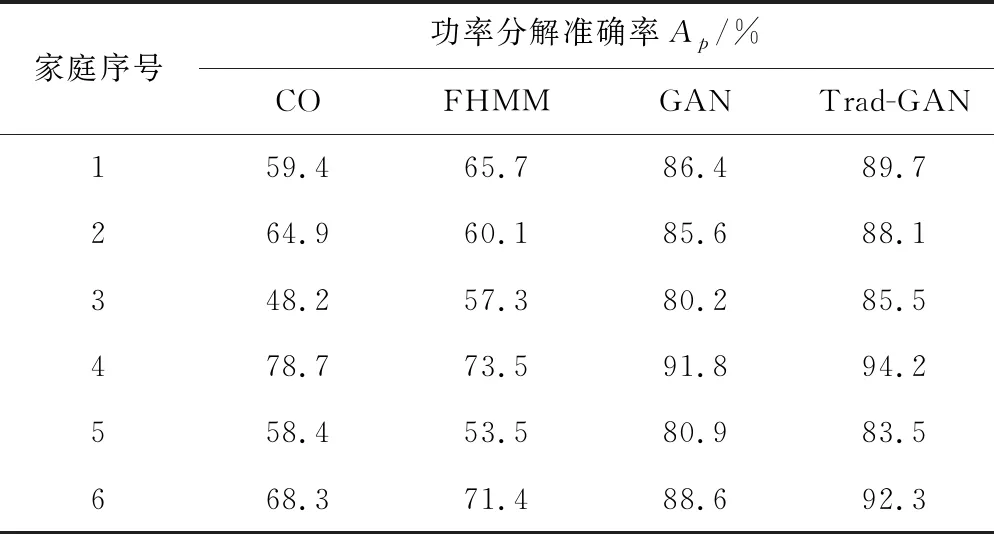
表3 各模型的负荷分解准确率
4 结束语
文中提出了一种基于生成对抗网络的负荷分解模型,利用生成网络和判别网络之间的相互对抗,使生成的功率分解序列更为真实,并且提出了一种基于联邦学习的网络模型实施方案。基于REDD数据集的测试结果表明,以云边协同方式训练的本地模型能够更好地挖掘家庭用电特征,取得了较高的负荷分解准确率。将GAN模型与不同方法进行比较,所得到的电器功率分解序列具有较好的趋势跟踪效果,并且能更好辨识和定位小功率电器。
下一步的工作是研究将联邦学习应用于多层通信网络,以实现更大范围的智能电能表等终端设备的协同训练,进而满足大规模的家庭非侵入式负荷分解需求。
猜你喜欢
文萃报·周五版(2022年14期)2022-04-12
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电子制作(2019年13期)2020-01-14
中国品牌(2019年10期)2019-10-15
电子制作(2019年11期)2019-07-04
电子制作(2018年17期)2018-09-28
