
基于改进蚁群算法的云计算资源分配策略研究
2022-06-07 08:56刘灯明荆俊峰房志奇
电子技术应用 2022年5期
刘灯明,荆俊峰,刘 凯,房志奇
(华北计算机系统工程研究所,北京 100083)
0 引言
现代社会进入了大数据时代,传统的计算模式存在很多局限性,不能够满足这种大数据的处理需求,因此“云计算”应运而生[1]。云计算中一个十分关键的问题就是负载均衡,负载均衡的含义是把任务平均地分配到云计算系统中的各个资源点上,所以设计出高效合理的资源分配策略非常重要[2]。目前资源分配策略的相关研究已经取得了不错的研究成果,例如:谭一鸣等人提出了一种能够降低系统能耗的资源分配策略,李安南创新性地提出了一种QoS 约束简化的资源分配策略[3]。在云计算资源分配策略中采用了各种算法,例如:蚁群算法。蚁群算法有很多优点,因此经常被应用到云计算资源分配问题上[4]。然而在实际的项目中会发现蚁群算法直接应用于云计算资源分配问题时效果不好,常常会出现负载失衡,所以本文针对蚁群算法进行了一系列改进,对蚁群算法进行改进方面的研究是本文的研究重点,改进后进行了实验,实验结果表明:对蚁群算法的改进是有效的。
1 蚁群算法
1.1 蚁群算法的原理
蚁群算法启发于蚂蚁寻找食物的过程,蚂蚁视力很差但却能够轻松地找到食物源到蚁穴的最优路径,也就是最短路径,相关研究发现蚂蚁会在路径上释放信息素来进行通信[5],某条路径上的信息素越多,对蚂蚁的吸引力就越强,蚂蚁会选择走该条信息素多的路径。与此同时,会把信息素释放在该条路径上,该路径上的信息素将得到进一步增加,反过来提升了对蚂蚁的吸引力,这里面存在一种正反馈过程,随着这个过程不断进行,最终的结果是会收敛得到某条最优路径,于是便确定了蚁穴到食物源的最短路径[6]。
1.2 蚁群算法的数学模型
根据旅行商问题(Traveling Salesman Problem,TSP)来阐述蚁群算法的数学模型,TSP 是假设有一组城市,经过每个城市一次,求最短路径和,各因子含义如下:dij是i、j 城市间的距离大小;n 是城市个数,m 是蚂蚁数量;τij(t)是t 时刻在(i,j)路径上的信息素含量;bi(t)表示t 时刻位于城市i 的蚂蚁数,于是;tabuk是禁忌表,作用是存放蚂蚁目前已经经过的城市。蚂蚁k 在t时刻从城市i 迁移到城市j 的状态转移概率为:
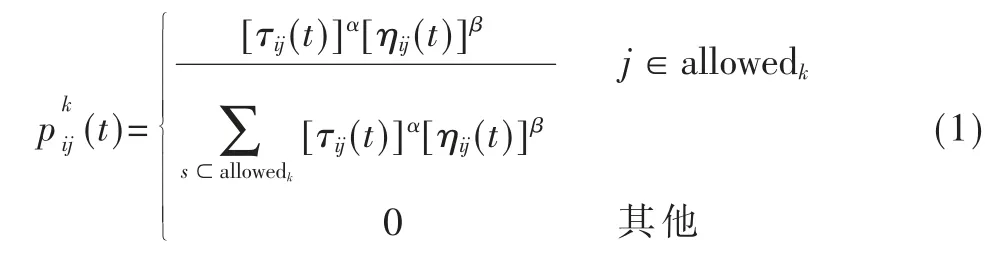
其中,C 代表所有城市组成的城市集合,allowedk={C-tabuk}代表蚂蚁k 能够迁移到的城市范围;ηij(t)代表启发因子,表示路径长短对蚂蚁的吸引力,并且ηij(t)=1/dij,dij越小,则ηij(t)越大,于是就越大;α代表信息素启发性因子,该因子的含义表示路径上累积的信息素的权重大小;β 代表期望启发式因子,该因子表示ηij(t)的权重大小[7]。随着算法的不断进行,路径上积累的信息素会越来越多,会导致启发信息被残留信息淹没,因此路径上的信息素需要持续不断地挥发,所以t+n 时刻在路径(i,j)上的信息素更新公式如下:
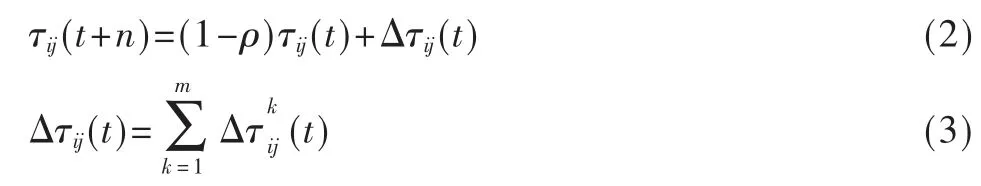
其中,ρ 表示信息素挥发系数,Δτij(t)表示信息素的增量大小,是蚂蚁k 释放在(i,j)路径上的信息素含量。蚁群算法有3 种基本的计算模型,分别是Ant-Cycle、Ant-Quantity、Ant-Density,这3 种模型的区别仅仅是采用了不同的信息素更新方式,即的计算方式不同。这3 种计算方式分别为:
(1)Ant-Cycle 模型

(2)Ant-Quantity 模型

(3)Ant-Density 模型

其中,Q 是信息素浓度大小,Lk是蚂蚁经过的路径总长。Ant-Cycle 模型表示蚂蚁经过全部城市后才更新信息素,是一种信息素全局更新方式;Ant-Quantity 模型以及Ant-Density 模型表示蚂蚁每经过一个城市就更新信息素,是一种信息素局部更新方式。通常来讲,Ant-Cycle模型求解TSP 效果最佳,所以通常都是采用Ant-Cycle模型来解决该类问题[8]。
1.3 蚁群算法流程图
蚁群算法流程图如图1 所示。
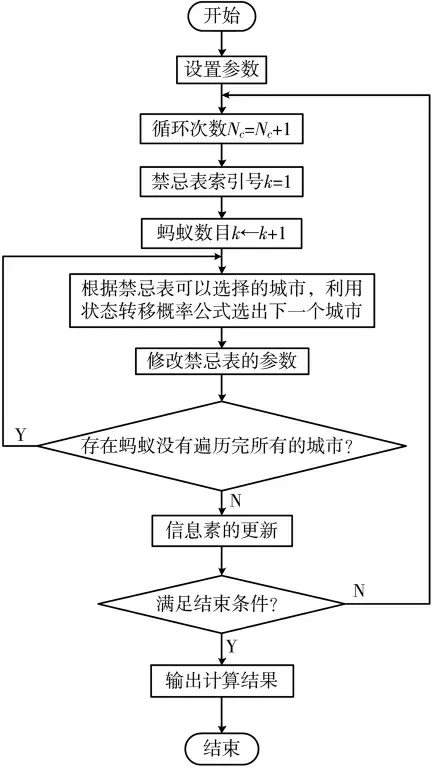
图1 蚁群算法流程图
2 蚁群算法的改进
蚁群算法比较容易陷入到局部最优解,在算法搜索的初始阶段,每条路径上的信息素都比较稀缺,使得算法在刚开始不久进行搜索时速度太慢,严重影响了算法的性能,所以有必要对算法进行一些改进[9]。本文的改进包括两个方面:(1)对蚁群算法自身进行改进,具体包括:引入伪随机比例规则,进行全局信息素强化,引入了交叉变异操作;(2)将遗传算法和蚁群算法进行融合,形成遗传蚁群算法。
2.1 引入伪随机比例规则
蚁群算法存在一个很严重的问题,就是容易陷入局部最优解。为了解决这个问题,必须扩大蚂蚁的选择范围,使得蚂蚁不仅能选择当前最优路径,还能够以一定的概率选择其余路径。因此引入伪随机比例规则:
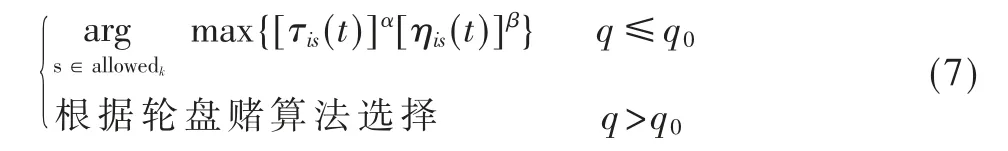
式中,q0代表一个遵循均匀分布的变量。按照信息素含量以及启发信息,可以计算出蚂蚁最优转移方式的可能性大小q0,与此同时,蚂蚁能够以1-q0的概率搜寻其他路径。为了使得蚂蚁能够选择究竟是搜寻最优路径,还是搜寻其他地方的路径,能够通过设置q0的值来控制算法对下一条路径的选择状态,把q 定义为,其中K=1,2,…,NC,假如q≤q0,就根据式(7)计算;否则采用轮盘赌方式,轮盘赌方式如下:
(1)设置参数r=rand(0,1);
(2)若s≥r,转步骤(4);
(4)算法结束[10]。
2.2 全局信息素强化
蚁群算法中蚂蚁选择路径是互不影响、相对独立的,存在一定的盲目性,这导致算法收敛速度慢,收敛准确性也低;另外当问题的规模比较大时,蚁群算法会求出很多无效路径,存储太多无效路径会使得算法效率降低。因此,本文给出了一种优化方法:用一个变量来标记每次迭代过程完成后的一条最优路径,然后对最优路径做一次信息素的加强操作,加强后,最优路径上的信息素比原来的信息素要强,这样会有效地避免求出太多无效路径,大大地加快了算法的寻优速度。因此全局信息素更新式(2)可以改成式(8)。

2.3 交叉变异操作
为了克服蚂蚁容易陷入局部最优解的缺点,本文给出了一种优化方法:该方法启发于遗传算法的变异操作,随机地在当次迭代过程中获得的解集中选择一条路径并且设置一个变异率pλ,控制pλ为一个较小的值,当满足变异率时对该路径的信息素值作一个随机的修改,这些值要在[τmin,τmax]之间,τmin代表的是信息素最小值约束,τmax代表的是信息素最大值约束,通过这种约束条件可以使得信息素含量限制在一定的区间内,有效地避免了算法因为各条路径上的信息素存在较大的差距而使得算法的搜索寻优过程出现停滞,造成陷入局部最优解的情况的发生。
从遗传算法的交叉操作中受到启发,可以设置另外一个交叉率pθ,把pθ限制为一个较小的值,随机地在该次迭代所有的解集中选择两条较优解,然后再把这两条较优解进行交叉,交叉后会得到一条新的解,然后再把这条新的解加入到解集中,新的解通常更加接近最优解,交叉操作增加了算法的随机性,避免了算法陷入到局部最优解[11]。
2.4 遗传算法结合蚁群算法
由于遗传算法在初始阶段的时候搜索能力特别强,与之相反,蚁群算法在初始阶段搜索能力特别弱,如果单独用蚁群算法进行资源分配,效率会非常低下。因此,本文将两种算法融合起来,开始用遗传算法进行搜索,然后把遗传算法搜索到的较优解变换为蚁群算法的起始信息素,后期再转入蚁群算法进行搜索。于是便出现了两个问题:第一是两种算法的融合点怎么确定,第二是怎么把遗传算法的较优解变换为蚁群算法的起始信息素。下面先简单地介绍一下遗传算法,然后再具体阐述[12]。
2.4.1 遗传算法原理
遗传算法模拟了自然界中生物的进化过程,首先通过随机的方式产生一定数量的个体,由这些个体构成起始种群,利用适应度函数求出所有染色体的适应度值,对于某个个体而言,它的适应度值越高,表示它的适应力越强,所以从中选择适应度值高的种群个体进行交叉变异,交叉变异后会得到适应力更强的个体。该过程不断迭代,满足结束条件时终止算法,遗传算法通过不断地迭代来优化问题的解[13]。
2.4.2 遗传算法流程图
遗传算法的流程图如图2 所示。
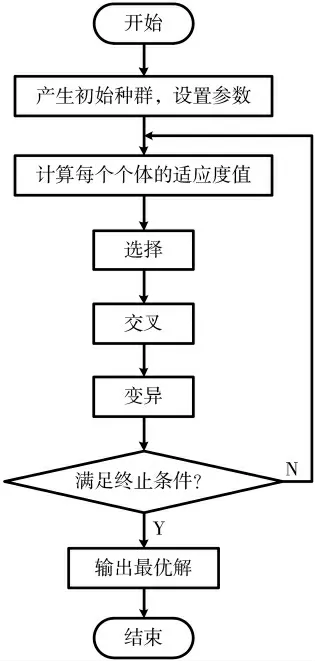
图2 遗传算法流程图
2.4.3 融合点的确定
为了将两种算法进行融合,就必须要确定两者的融合点,于是绘制了两种算法的速度时间曲线图,如图3所示。由图3 可知:0~ta时间段,遗传算法搜寻速度明显快于蚁群算法;在ta时间段以后,情况相反,蚁群算法搜寻速度明显快于遗传算法,ta时间点两种算法的搜寻速度相同,因此ta点就是融合点。确定融合点的具体思路是:设置一个最小进化率pw,倘若连续三代的进化率都比pw要小,那么该点就为融合点,于是在该点结束遗传算法,进入蚁群算法搜索阶段[14]。
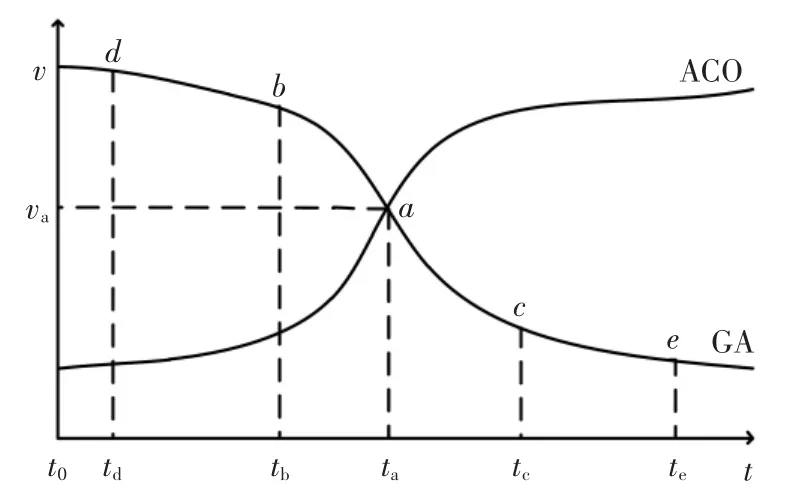
图3 速度-时间曲线图
2.4.4 初始信息素转化方法
本文将遗传算法的解变换为蚁群算法的起始信息素,具体实现过程为:在遗传算法结束后以15%的概率选择适应度值最高的个体,每个个体都代表了一个较优解;然后再将这些解变换成节点上的蚂蚁数;接着再使用信息素转化因子,将这些蚂蚁数变换成节点上的信息素。于是(i,j)路径上的起始信息素定义为:

2.4.5 融合后的算法流程图
融合后的算法流程图如图4 所示。
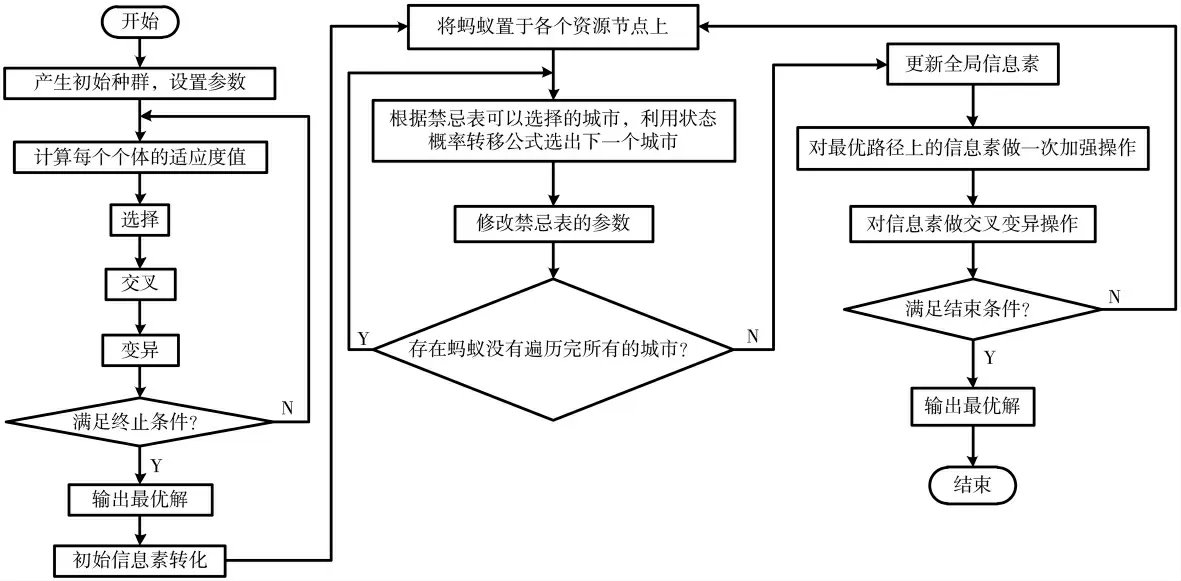
图4 融合后算法流程图
3 实验与分析
为了更加直观地验证对蚁群算法进行改进后的效果,本文分别对改进蚁群算法、基本遗传算法和基本蚁群算法进行了MATLAB 仿真实验,并把它们的实验结果进行对比分析,从任务完成时间、算法迭代次数、负载均衡效果来评价算法的改进效果,同时设置了资源点数为8 个,任务数量从20~100 个,算法的各个参数是通过以往的文献来确定的,各参数取值见表1。
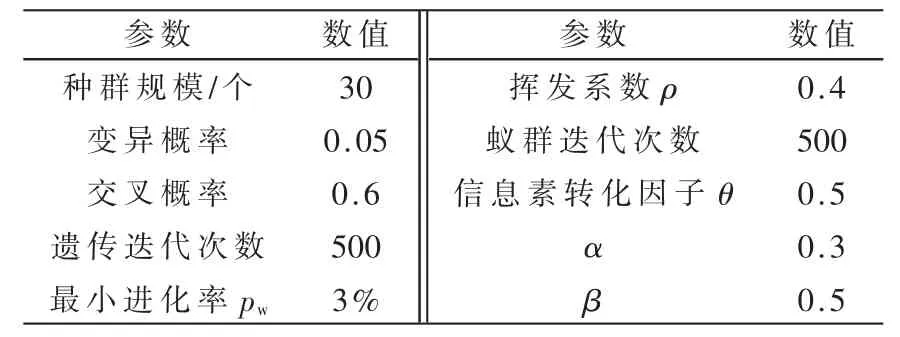
表1 各参数取值
通过实验得到实验数据并进行实验结果的对比分析,改进算法与基本蚁群算法任务完成时间对比如图5所示,改进算法与基本遗传算法的任务完成时间对比如图6 所示。迭代次数对比如图7 所示,负载均衡对比如图8 所示。
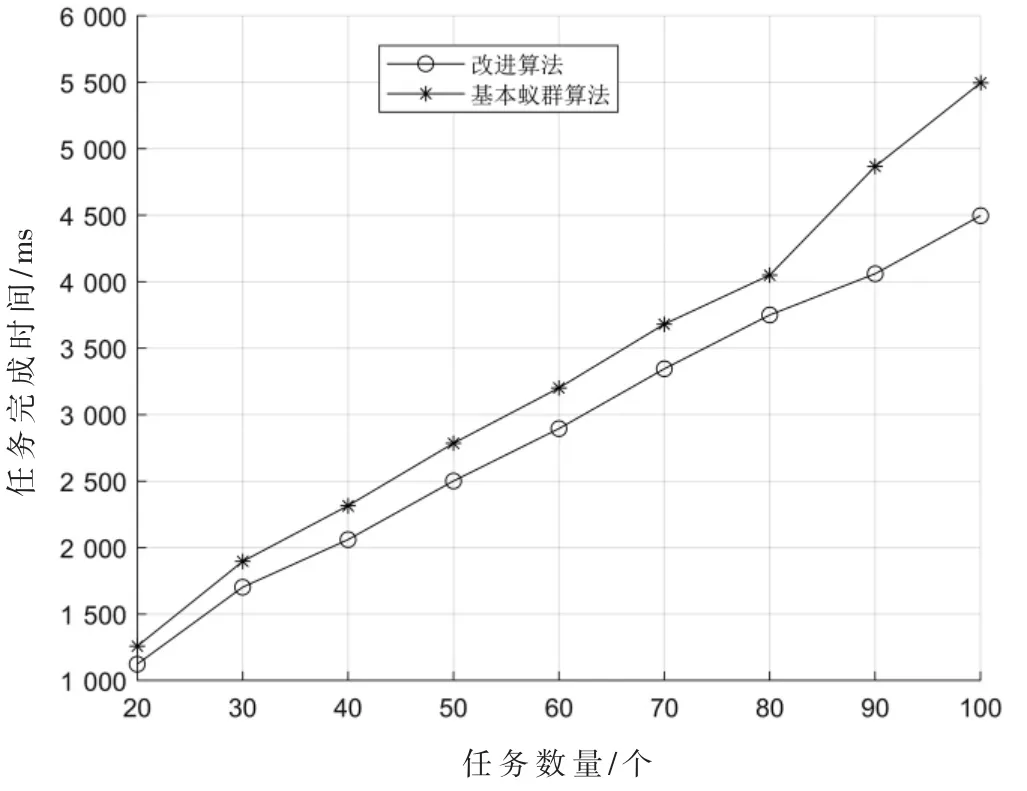
图5 改进算法与基本蚁群算法任务完成时间对比
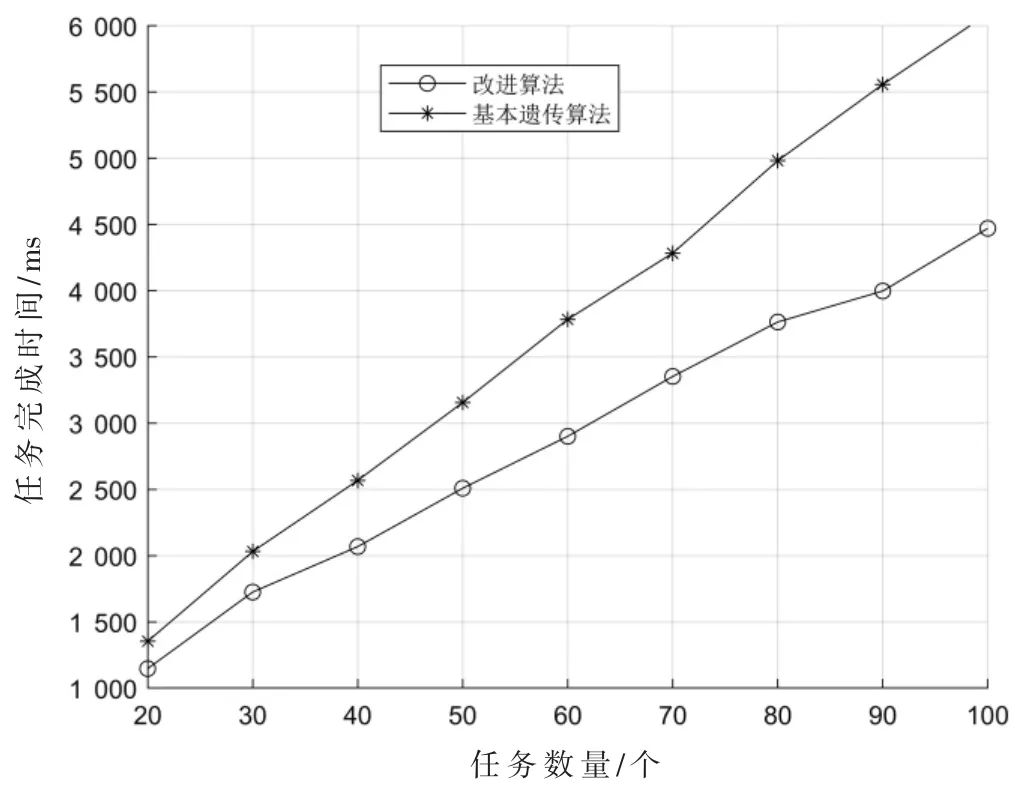
图6 改进算法与基本遗传算法任务完成时间对比
由图5 和图6 可知:改进算法的任务完成时间明显短于两种未改进的算法,且在任务数量较大时改进效果越明显,因此改进算法更加适合于大规模资源分配问题。由图7 可知:迭代次数随着任务数量的增加而增加,改进算法的迭代次数比两种未改进算法的迭代次数更少,说明对算法进行改进提升了算法的效率。由图8 可知:改进算法的负载均衡效果要好于其他两种未改进的算法,说明了对算法进行改进提升了算法负载均衡性能。
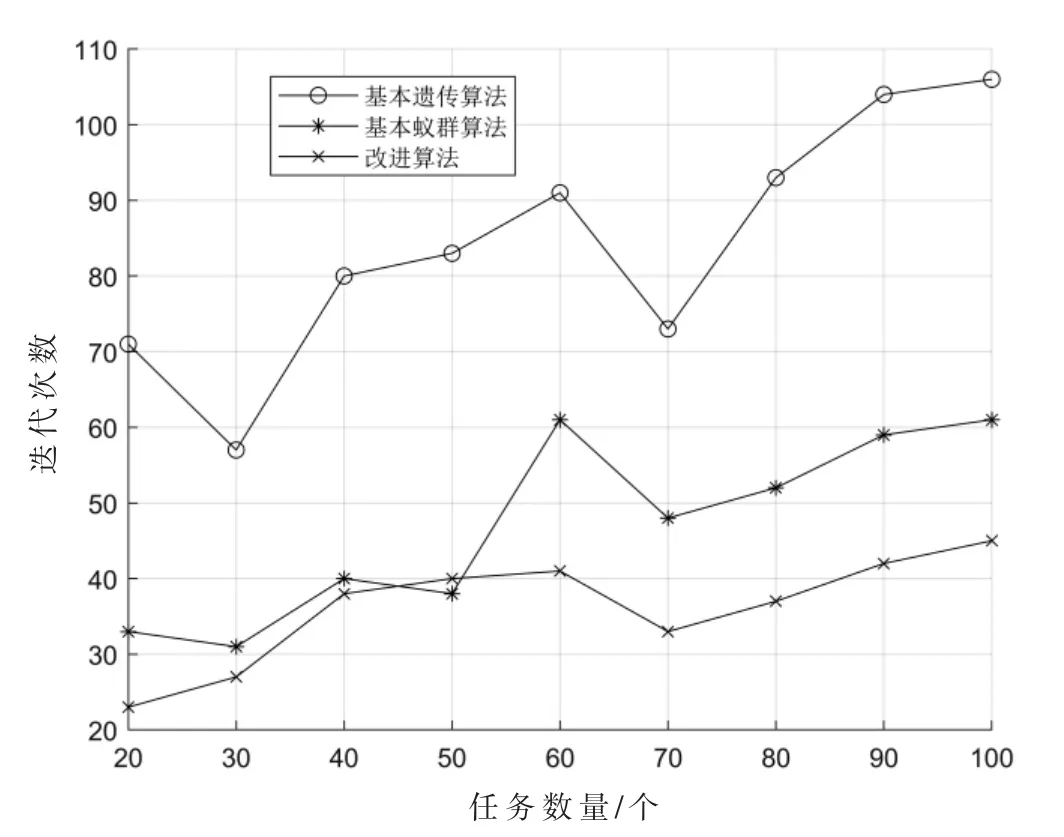
图7 迭代次数对比
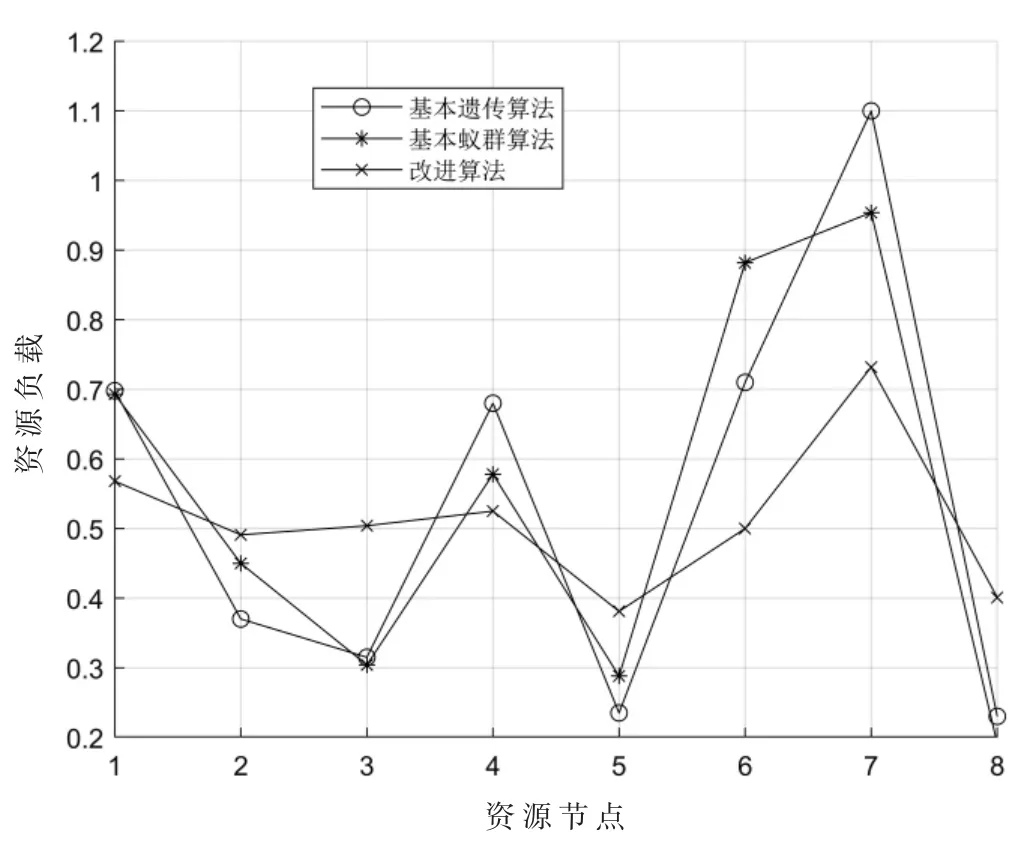
图8 负载均衡对比
4 结论
本文针对蚁群算法进行了一系列改进,并进行了MATLAB 仿真实验。实验结果表明,改进算法的任务完成时间更短,且在任务数量较大时效果越明显,说明改进算法更加适合大规模资源分配问题。改进算法的迭代次数更少,说明对算法进行改进提升了算法的效率。此外,改进算法的负载均衡效果也更好。由此可以得出结论:对算法的改进是有效的,能明显提升算法的综合性能。
猜你喜欢
百科探秘·航空航天(2022年6期)2022-06-28
今日农业(2021年12期)2021-11-28
英语文摘(2020年10期)2020-11-26
初中生世界·八年级(2019年6期)2019-08-13
计算机与数字工程(2019年4期)2019-05-07
计算机系统应用(2018年7期)2018-07-18
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
计算机应用(2016年10期)2017-05-12
小学生导刊(低年级)(2016年9期)2016-10-13
