
GPU虚拟化相关技术及研究
2022-06-07 07:42梁桂才巫耀中
数字通信世界 2022年5期
梁桂才,巫耀中
(1.广西机电职业技术学院,广西 南宁 530007;2.上海榕湖投资管理有限公司,上海 200122)
十多年来,高性能计算(HPC)程序员和研究人员采用了一种新的计算范式,该范式结合了两种架构:具有强大和通用核心的多核处理器和多核加速器,例如图形处理单元(GPU),具有大量的简单核,在加速算法具有高度的数据并行性,在这方面很有优势。尽管核数量不断增加,多核处理器设计仍然旨在通过使用复杂的控制逻辑和大的缓存内存来减少顺序程序中的延迟。相反,GPU试图通过数千个简单内核和高内存带宽架构来提高并行应用程序的执行吞吐量。GPU在云计算中的作用非常重要。包括亚马孙和阿里巴巴在内的大多数顶级云服务提供商已经将GPU资源引入到他们的基础设施即时服务解决方案中。这些GPU资源通常以整个物理GPU的粒度提供给每个客户端。然而,在许多实际情况下,一小部分物理GPU就足以完成渲染任务,这导致了资源利用不足的问题。提出了GPU虚拟化技术(例如,API重定向和中介传递)来解决资源利用率不足的问题。然而,这些技术只关注本地主机。瘦客户端架构的出现,允许人们通过互联网享受硬件加速器和GPU虚拟化技术,以扩大用户范围。然而,现有的框架倾向于将所有的工作负载归因于服务器端,让客户别无选择。受API重定向技术启发设计的一个新的框架,云边缘集成,似乎解决了这一限制。
随着AI技术的发展,AI运算迫切需要大规模的并行计算。随着图形处理单元GPU的出现使得并行计算算力得到很快提高。2006年,英伟达的集成架构CUDA诞生了。GPU迅速从单一图形处理发展成为具有AI运算的算力资源。图形处理单元(GPGPU)上通用计算的快速发展极大地简化了GPU编程。在这种环境下,越来越多的应用程序尝试使用GPU强大的并行计算能力来得出结果。在并行计算方面GPU相比CPU有明显的优势,无论是在算力还是内存带宽、功耗和成本方面。GPU的结构不同,它使用大量晶体管作为ALU计算单元,而CPU主要是做逻辑运算,它使用的晶体管作为复杂的控制单元和缓存来优化串行代码。GPU专注于大量、快速、低延迟地实施特定操作。21世纪以来,很多大型集群系统都采用了CPU+GPU异构计算模型,这代表CPU+GPU异构计算模型向大数据计算领域发展。
1 GPU虚拟化方法
1.1 API 重定向
API重定向首先作为一种GPU虚拟化技术而出现,重点是提高GPU利用率的问题。与其他技术不同,包括与特定硬件紧密耦合的中介传递,A PI重定向技术可以在不需要硬件支持的情况下存在。因此,A PI重定向系统具有健壮的可伸缩性。随着GPGPU设计的成熟,GPU的功能不再局限于图形加速。因此,远程API重定向系统不仅关注转发渲染命令,而且还关注与GPGPU相关的命令。
当谈到API重定向技术时,它们可以分为两类:本地机器上的本地API重定向系统和将用户区域从本地主机扩展到云的远程API重定向系统。由于远程API重定向技术要求服务器和客户机之间的合作,我们称之为云边缘集成框架。在下面的部分中,我们将简要描述这两种技术之间的差异、本地技术的局限性和远程技术的独特优势。本地API重定向系统(例如SRIOV6、7和共享渲染)将每台服务器上的隔离单元(虚拟机或容器)作为客户机。尽管这种技术增加了GPU的利用率,但将所有功能归因于服务器端会给服务器机器带来很大的压力。此外,多个应用程序之间的资源共享加剧了服务器端的压力。因此,远程API重定向系统似乎解决了这个问题。
1.2 硬件辅助虚拟化
以前的虚拟机因为GPU异构化和供应商锁定,不能直接使用主机的 GPU,若要使用就必须通过设备仿真来实现 GPU 并行运算的基本功能。Younge等人使用PCI直通技术和SHOC基准测试评估了XenVM基础设施的性能。作者发现,在最坏的情况下,在支持开普勒K20mgpu的虚拟机中,只有1.2%的性能损失,而API远程方法会产生高达40%的性能开销。在最近的研究中,他们使用SR-IOV的PCI传递评估了虚拟化集群中的HPC工作负载。SR-IOV是一种硬件辅助的网络虚拟化技术,它在虚拟机内提供10 Gbps连接的近本地带宽。GPUDirect通过支持无限波段互连上的GPU之间的直接RDMA,降低了跨GPU的数据传输开销。为了进行评估,他们使用了两种分子动力学(MD)应用程序。作者观察到,使用MPI和CUDA的MD应用程序可以在接近本地的性能下运行,而LAMMPS和HOOMD的管理率分别仅为1.9%和1.5%。
现在有些商业云直连将GPU部署到云平台。但是只是保证了与本地设备的GPU能被虚拟机调度使用,它不适合共享。多用户在云计算场景、专业化方面,GPU的利用率低,在执行计算能力不足的任务时浪费计算资源,没有所需的维护和监控,不支持虚拟机等高级功能。
1.3 全GPU虚拟化
设备仿真方式只能仿真简单的硬件,性能较差。API 重定向可以实现接近本机硬件的性能,但需要更改主机 VM 库。该设备的直接方法提供了出色的性能,但被广泛共享。最近的完整GPU虚拟化提案结合了上述解决方案,以提供对访客VM使用情况的完全透明。这种方法对寄存器等硬件上下文信息使用软件仿真,允许直接连接的硬件设备在上下文切换后充分利用 GPU。完全的GPU虚拟化意味着您可以使用GPU 而无须更改虚拟机驱动程序,即无缝。全 GPU虚拟化比共享直连设备要好得多,但同时,它不需要对主机 VM的驱动程序进行任何修改,并且在性能上远优于设备仿真。这是有史以来最好的 GPU虚拟化解决方案。孔田等人提出了gVirt来实现完全虚拟化的 GPU 图像渲染解决方案并进一步优化系统,并提出了gHyvi和gScale。在通用计算领域,YusukeSuzuki 等人提出了一个vm GPU系统,它通过修改一个完全虚拟化的VMM来实现一个GPU。gVirt 的示意图如图1所示。
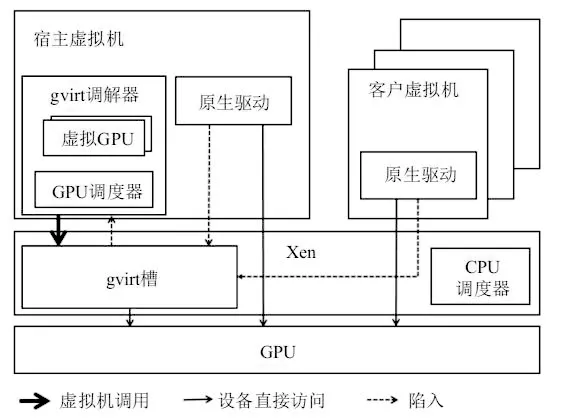
图1 gVirt框架结构示意图
在通用计算中,GPUvm的全GPU虚拟化实现得更充分,更改仅在 Xen中进行。与 gVirt一样,GPUvm使用 GPU幻像页表机制来隔离视频内存。每个虚拟机访问自己的虚拟机。另外,CPU和GPU之间发送命令的队列是虚拟化的,这意味着每个虚拟机都有自己的队列结构,当虚拟机发生更改时,命令队列也会相应更改。GPUvm使用宽带支持,非抢占式调度算法允许您在虚拟机之间平衡 GPU。
2 GPU资源池
目前,因为GPU异构化和供应商锁定,集群中的GPU资源结构复杂多样,群集的GPU有多个品牌、多种架构,它们的处理能力又各同样,节点上的GPU数量也很不统一。怎么样才能在这些差异化资源上实现调度任务、资源负载均衡、系统资源充分利用,是一个GPU资源池化亟待解决的问题。如果像CPU虚拟化一样,GPU虚拟化也可以实现对CPU资源进行集中高效的管理,然后再进行动态分配。但是CPU天生就容易实现虚拟化,面GPU却不容易实现,所以真正高效的GPU虚拟化管理系统迟迟没有出现。为了实现GPU资源池动态管理、动态分配,满足不同资源需求,应实现软硬件解耦和GPU资源共享的目标。
GPU资源池在虚拟化服务层维护多个GPU计算资源,并将不同品牌、不同型号、不同速率的物理GPU计算资源化整为0,统一管理动态分配。根据虚拟机客户端的需求,将不同的计算资源池化并动态分配,实现GPU硬件资源的“分离、分区、整合”。图2为gRemote的详细架构图,该框架利用了API重新定向技术,在资源调动整合方面有着很大的优势。
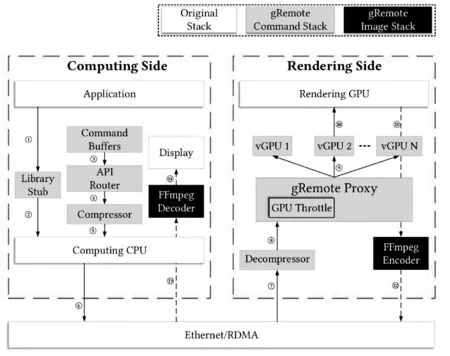
图2 gRemote框架示意图
隔离性体现在提供给虚拟机客户端的GPU计算资源不能相互影响,即使是在同一个物理GPU上。GPU资源池会实时更新服务器的UPG资源的使用状态,实时同步虚拟机客户端的虚拟GPU的使用情况,某一虚拟机没有释放GPU之前不能再使用该资源,避免虚拟机之间的相互干扰。在虚拟机客户机上,都有自己独立的GPU资源,但GPU资源池会动态地被分配给各个虚拟机,因为通常每一个虚拟机的使用率都不会太高,据不完全统计,使用率在20%左右,这样使得GPU资源池的资源可以超分。虚拟机上有自己完整的GPU资源。这种拆分体现在提供给虚拟机客户端的GPU是GPU资源池中实际物理硬件的一个子集。虚拟机根据用户的需要,实时分配GPU,动态划分物理GPU资源空间,提供相应的资源给虚拟机客户端。在GPU资源池端,将服务线程动态分配给不同的客户端,实现GPU资源共享,多个虚拟机客户端共享单个图形卡并允许使用多个图形卡。这种融合体现了传统的硬盘池和内存池技术,可以将多个物理GPU资源映射到单个虚拟GPU,合理分配GPU资源给虚拟机客户端,也可以将一个物理GPU资源映射到多个虚拟机使用。GPU资源池是资源提供者角色,虚拟机客户端是资源使用者角色,GPU资源池维护两端的角色,中间件消耗池中的GPU资源,并将其提供给虚拟客户端。GPU资源池跨越整个虚拟集群。随着GPU资源加入虚拟集群,由GPU资源池监控,统一调度。从集群中移动GPU资源时,资源池及其子对象中的资源不可用。GPU虚拟资源池以资源分配、占用、释放、回收模式运行,而不是分配销毁模式。GPU资源池不仅可以灵活扩展以满足用户需求,还具有统一动态监控调度和分配的能力。这样可以实现资源的快速分配或回收,根据系统需求灵活执行调度功能,动态调整GPU资源。
3 结束语
在过去的几年中,异构计算作为一种新的计算范式获得了广泛的关注,它有潜力为HPC和云平台提供更高的性能、更高的资源利用率和更低的运营成本。在云数据计算中,GPU虚拟化是在多个用户之间有效共享GPU设备的关键技术。本文对GPU虚拟化技术及其调度方法的研究工作进行了深入的研究,通过对GPU虚拟化的代表性研究,介绍了该领域的关键研究贡献,这些研究包括API重定向和全虚拟化以及硬件辅助虚拟化;此外还讨论了在异构云计算中实现公平有效的GPU共享的GPU调度方法;最后提出了一些未来的研究方向,并推进GPU虚拟化的实践状态。■
猜你喜欢
新作文·高中版(2022年5期)2022-11-22
新作文·高中版(2022年5期)2022-11-22
——稳就业、惠民生,“数”读十年成绩单
人民周刊(2022年17期)2022-10-21
科学技术创新(2021年18期)2021-06-23
微型电脑应用(2019年10期)2019-10-23
电子制作(2019年10期)2019-06-17
电子制作(2018年14期)2018-08-21
计算机测量与控制(2017年12期)2018-01-05
计算机技术与发展(2017年12期)2017-12-20
电子制作(2017年7期)2017-06-05
