
基于贝叶斯优化的SVM玉米品种鉴别研究
2022-06-06 10:06冯瑞杰陈争光衣淑娟
光谱学与光谱分析 2022年6期
冯瑞杰,陈争光, 2*,衣淑娟
1.黑龙江八一农垦大学信息与电气工程学院,黑龙江 大庆 163319 2.黑龙江省现代农业物联网技术创新中心,黑龙江 大庆 163319 3.黑龙江省水稻生态育秧装置及全程机械化工程技术研究中心,黑龙江 大庆 163319
引 言
作为世界的三大作物之一,玉米对于我国经济发展和社会稳定具有非常重要的战略意义。玉米品种繁多,同一地区种植的部分玉米品种外观极其相似,很难通过肉眼区分,给农民的采购和市场的监管带来了一定的困难。因此,需要一种快速检测技术对玉米品种进行识别。
随着化学计量学和仪器测量技术的飞速发展,光谱分析已经被广泛应用于农业[1-2]、食品[3-4]、医药[5]等领域。近红外光谱分析具有分析速度快、分析效率高、分析成本低、对样品无损害、便于实现在线分析等优点。近年来,近红外光谱在农产品品种鉴别和产地溯源等方面得到广大科研工作者的重视。李杰等[6]利用近红外光谱结合无监督的主成分分析和有监督的线性判别分析方法分别构建茶叶品种鉴别模型,采用标准正态变量变换结合一阶导数预处理方式并结合无监督的主成分分析法实现绿茶样品种类鉴别分析,准确率达到75%,采用有监督的线性判别分析方法处理原始光谱数据,准确率可达到100%。高慧宇等[7]应用近红外光谱结合偏最小二乘判别分析建立转基因大豆的快速鉴别模型,通过选择样品形态、波长范围和光谱预处理方法对鉴别模型进行优化,提高模型鉴别正确率。有研究探索了近红外光谱结合BP神经网络建立北方粳稻种子快速鉴别模型,通过小波变换对全谱进行数据降维,分类准确率可达100%。
基于高维数据的分类方法很多,其中采用二分类的支持向量机由于其优越的表现得到广泛的应用。支持向量机(surport vector machine, SVM)是机器学习中分析数据的监督式学习算法,被广泛应用于农业[8]、医疗[9]、工业设备故障检测[10]及图像分类[11]等领域。SVM的核心思想是将低维空间中不可分的数据点映射到更高维的空间维度中,在高维空间中进行分离。为了简化计算过程,引入核函数定义从低维到高维空间的映射,以确保原始空间的变量可以很容易地计算内积。在SVM中,惩罚因子C和径向基核函数(radial basis function, RBF)参数γ两个参数决定SVM模型性能,因此参数寻优对SVM模型性能的表现至关重要。常用的参数寻优方法如网格搜索(grid search, GS)、遗传算法(genetic algorithm, GA)等普遍存在寻优时间长,针对非凸问题易陷入局部最优等不足。本研究采用贝叶斯优化(Bayesian optimization, BO)对SVM模型的惩罚因子C和RBF核参数γ进行寻优,以5种玉米种子作为研究对象,选择模型十折交叉验证识别准确率最高时对应的参数建立SVM玉米品种鉴别模型,为农产品的快速分类提供一种参考方法。
1 实验部分
1.1 样本与仪器
试验所用玉米种子购买于种子市场,包括郑单958、先玉335、京科968、登海605和德美亚五个品种。每个品种取200粒作为一个样本,5个品种分别有22,23,63,85和100个样本,共计293个样本,去除有破损、瘪粒的样本。将玉米样本放置于近红外光谱实验室24 h之后进行光谱扫描。
光谱采集设备是德国Bruker公司生产的TANGO品牌的近红外光谱仪,测量波长范围为11 520~4 000 cm-1,测量样本的方式为漫反射和透射,分辨率为8 cm-1,每个样本扫描32次取平均值作为样本的光谱数据。将每类样本按照6∶1的比例随机划分训练集和测试集,全部293个样本最终划分为251个训练集样本和42个测试集样本。
1.2 建模方法及评价指标
1.2.1 支持向量机
SVM的基本思想是结构风险最小化,通过核函数将数据从原始特征空间映射到高维特征空间,使线性内积运算非线性化,然后在高维特征空间建立使分类间隔最大化的最优超平面。惩罚因子C和RBF核函数参数γ是SVM中两个重要的参数。惩罚因子C>0,C越大对错误分类的惩罚越大,但容易出现过拟合;C越小则对错误分类的惩罚减小,模型的复杂度降低,容易出现欠拟合。γ决定数据映射到新特征空间后的分布,γ越小,支持向量越多,模型平滑效应增大,容易欠拟合;γ越大,支持向量越少,对未知样本分类效果很差,模型容易过拟合。支持向量的个数影响模型训练与预测的速度,因此在使用SVM建立判别模型时,惩罚参数C和核函数参数γ的选择至关重要。
1.2.2 贝叶斯优化
SVM模型参数C和γ与模型性能之间呈现黑箱特点,即模型的性能与参数C和γ之间无法使用表达式描述,只能根据通过遍历离散的自变量取值得到最优SVM模型。贝叶斯优化[12]是一种十分高效的全局优化算法,主要用于机器学习调参,贝叶斯优化是一种不需要计算导数的系统化调优算法,采用高斯过程建立概率代理模型,考虑之前的参数信息,不断更新先验,使用采集函数来确定下一个评估点,可以在较短的时间内确定最佳参数。概率代理模型和采集函数是贝叶斯优化算法的两个核心组件。高斯过程是随机变量的集合,用以代替目标优化函数。在本研究中,高斯过程用于优化的SVM的参数组合,高斯过程的表达式如式(1)
f(x)~GP[m(x),k(x,x′)]
(1)
式(1)中,均值函数m(x)=E(f(x)),代表样本f(x)的数学期望。协方差函数k(x,x′)=E{[f(x)-m(x)][f(x′)-m(x′)]},高斯过程根据已经搜索的点估计其他点处目标函数的均值和方差,通过均值和方差构造采集函数,用于决定下次迭代时的采样点位置。
常见的超参数优化算法包括网格搜索、遗传算法,这些算法除了非常耗时之外,在遍历下一个离散参数时不考虑之前的参数信息,针对非凸问题容易陷入局部最优。而贝叶斯优化侧重于减少评估代价,迭代次数少,速度快,而且考虑之前的参数信息,针对非凸问题不易陷入局部最优。本研究选择贝叶斯优化作为SVM模型的参数寻优算法。
贝叶斯优化算法的过程如下:
(1)在SVM模型的C和γ的设定搜索范围中随机选取n0个采样点,以十折交叉验证的平均测试准确率为目标函数f,模型的不同参数组合作为自变量x,构成代理模型框架,得到目标函数的初始分布和采样点集D;
(2)通过最大化采集函数选择下一个采样点xt,得到采样点函数值f(xt);
(3)将新的采样点[xt,f(xt)]添加到采样点集D中,更新高斯过程代理模型,使得代理模型更加贴合目标函数的分布;
(4)设定一个最大迭代次数,当迭代次数达到最大次数时,停止算法迭代,输出最优采样点以及对应的目标函数最优值,即SVM模型的最优参数C和γ。
1.2.3 评价指标
本研究基于混淆矩阵,引入f1评价指标作为模型的评价标准。f1评价指标的计算公式如式(2)
(2)
式(2)中,recall和precision分别叫做查全率和查准率,其定义如式(3)和式(4)
(3)
(4)
式(3)和式(4)中,TP为将正类预测为正类的个数;FN为将正类预测为负类的个数;FP为将负类预测为正类的个数。查全率(recall)越高,说明模型对正样本的识别能力越强;查准率(precision)越高,说明模型对负样本的区别能力越强。f1是两者的综合,f1越高,说明所建立的分类模型越稳健。recall和precision任何一个数值减小,f1的值都会减小。
本研究还选择识别准确率作为玉米品种判别模型的评价指标。识别准确率是指正确预测的样本数占总预测样本数的比率,不考虑预测的样本是正类还是负类。
2 结果与讨论
2.1 数据预处理
为了降低光谱数据中谱带重叠、噪声信号对建模的干扰,在建模前需要对采集的原始光谱进行预处理。采用标准正态变量变换(standard normal variate transformation, SNV)对光谱数据进行预处理。SNV主要用来消除固体颗粒大小、表面散射以及光程变化等因素对光谱数据的影响。图1(a,b)分别为样本的原始光谱曲线和SNV处理后光谱曲线为全部玉米样本光谱数据经过SNV变换前后的光谱曲线。

图1 玉米种子原始近红外光谱图(a)及SNV处理后的光谱图(b)
2.2 不同优化方法下模型性能对比
在SNV预处理后的数据基础上,使用10折交叉验证分别建立GS-SVM,GA-SVM和BO-SVM模型,三种模型的参数以及性能指标如表1所示。表1的结果表明,BO算法对SVM参数调优表现相比于GS和GA算法表现不佳,分析认为贝叶斯优化依赖于高斯过程建立概率代理模型,高斯过程作为一种概率分布,是事件最终结果的分布。高斯过程中的协方差函数k(x,x′)控制采样点的探索程度,对应于全局搜索,k(x,x′)的计算依赖于已有样本的协方差矩阵。在高维数据的情形下,要使样本点布满整个搜索空间,需要大量的样本,有限的样本点在高维空间中的距离都会比较远,数据样本稀疏,会导致k(x,x′)近乎为无效函数。因此贝叶斯优化在高维数据中失去了其通过协方差函数进行探索的意义,近乎于完全随机搜索,算法不能通过采集函数进行高效的探索,有可能导致SVM模型陷入局部最优,模型表现不佳。说明在高维数据寻优方面,BO算法并不是一个好的选择。
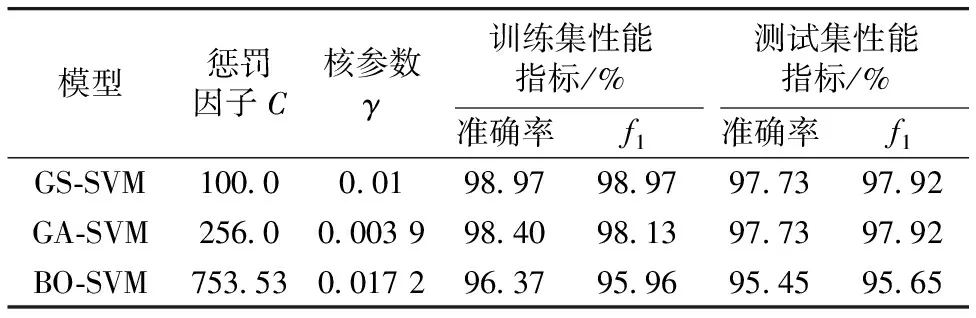
表1 不同优化算法下的SVM模型性能对比
2.3 PCA降维对贝叶斯优化及模型性能的影响
光谱数据经过PCA处理后,消除了数据特征间的共线性,去除了数据中不重要的特征,使得各个维度之间的数据相互正交,降低了数据的复杂性,并且大幅降低算法的计算开销。为了验证PCA降维对贝叶斯优化算法的影响,将高维度玉米近红外光谱数据利用PCA降维处理后保留10个主成分,前10个主成分的累计贡献率达到了99.9%,在此基础上使用贝叶斯优化,对SVM模型参数C和γ进行优选并建立PCA-BO-SVM模型。采用十折交叉验证,计算模型的平均测试准确率,得到SVM模型的全局最优参数。同时在PCA降维的基础上建立PCA-GS-SVM和PCA-GA-SVM两种模型,三种模型性能参数如表2所示。由表2可知,对光谱数据使用PCA降维处理后,使用GS寻优得到的SVM模型核参数γ相比于GA以及BO算法寻得的核参数γ较大,模型出现轻微的过拟合,导致在测试集上表现不佳。对于SVM模型这样的连续型参数,GS算法无法通过遍历所有C与γ可能参数组合去验证SVM参数空间中的所有参数,为了得到较优的参数组合,GS算法必须加大网格搜索的密度,加之GS算法需要进行的交叉验证次数十分惊人,因此GS搜索方法耗费的时间成本巨大。

表2 降维后三种模型性能指标对比
GA算法的本质是随机性搜索,其调参的效果依赖于采样次数,采样次数越多,越有可能找到模型的全局最优参数,但随机采样点不容易落到最优参数组合上,并且GA算法无法利用之前采样点的评估效果进行主动寻优,寻优效率较低[13],寻得的参数不一定是全局最优参数。BO算法可以在很短的时间内寻得SVM的全局最优参数,这是因为BO算法使用采集函数,通过采集函数,在探索不确定区域和关注已知具有较优目标值的区域之间进行权衡,来确定下一个评估点。使用采集函数,可以使模型避开许多无用采样点的评估,准确描述出目标函数的分布,从而高效找到模型的最优参数组合。与PCA-GS-SVM和PCA-GA-SVM模型相比,PCA-BO-SVM模型在测试集上的准确率和f1值均达到100%,说明经BO算法寻优后的SVM模型惩罚因子C和核参数γ均为全局最优参数,模型性能优于其他两种模型。
2.4 样本数量对训练模型的影响
四种模型在测试集上分类结果的混淆图如图2,由混淆图可以看到,图2(a)PCA-GS-SVM,图2(b)PCA-GA-SVM和图2(c)BO-SVM三种模型的识别错误率均与郑丹958有关,图2(d)中PCA-BO-SVM模型在测试集中均可以正确识别各类玉米样本,识别效果优于其他三种模型。BO-SVM模型的识别错误率与先玉335有关,这可能是由于郑丹958和先玉335样本数量较少导致模型对该样本的训练不够,在测试集上表现不佳所致。
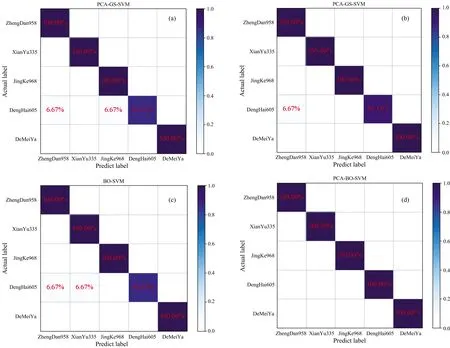
图2 模型在光谱测试集上的混淆图
为了验证这一猜想,剔除数据集中样本数量较少的郑丹958(22个样本)和先玉335(23个样本)两类样本,将剩余的248个玉米近红外光谱样本仍然按照6∶1的比例随机划分为训练集和测试集,使用PCA-GS-SVM,PCA-GA-SVM,BO-SVM和PCA-BO-SVM四种模型在训练集上建模,在测试集上进行玉米种类的识别,得到四种模型在三类玉米样本上的分类性能指标(表3)。

表3 去除小样本后模型性能指标对比
由表3可以得出,在去掉郑丹958和先玉335两类小样本之后四种模型的训练集和测试集上的识别准确率均有显著提高,在测试集上的识别准确率均达到100%。说明在类间数据量不平衡的模型训练过程中,模型对样本数据量较多的类别拟合的更好,对该类的分类准确率较高[14],但模型的泛化性能较弱。某种类别数据量越多,对模型参数的修正就越细腻,使模型更能刻画该类别的分布,对该类别数据的分类效果越好。
3 结 论
利用贝叶斯优化算法对SVM模型的两个超参数C和γ进行优化,结果表明,针对非凸优化问题,相较于网格搜索和遗传算法寻优,贝叶斯优化通过概率代理模型和采集函数来达到寻找模型全局最优参数的目的,充分利用完整的历史信息,避免不必要的参数评估,实现参数的高效优化,从而提高SVM模型的性能,基于贝叶斯优化的SVM模型的性能达到最优。由于贝叶斯优化适用于低维数据的模型参数优化,SVM适合于小样本分类和回归,因此,数据降维能显著提高SVM模型的性能。此外,某类样本数量偏少会影响SVM模型的分类效果,导致模型的泛化性能减弱。本文利用PCA,BO和SVM构建了玉米品种的判别模型,为玉米品种的快速鉴别提供了一种新的方法。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
健康之家(2021年19期)2021-05-23
空间科学学报(2021年1期)2021-05-22
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
法律方法(2021年4期)2021-03-16
中国生物医学工程学报(2019年6期)2019-07-16
中国交通信息化(2018年5期)2018-08-21
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
中国光学(2015年5期)2015-12-09
