
基于多尺度深度注意力模型的遥感影像滑坡提取方法
2022-06-05 04:45许濒支李海峰丁雨淋
测绘地理信息 2022年3期
许濒支 朱 庆 李海峰 胡 翰 丁雨淋 陈 琳
1 西南交通大学地球科学与环境工程学院,四川成都,611756
2 中南大学地球科学与信息物理学院,湖南长沙,410012
滑坡具有隐蔽性、突发性,常发生在复杂艰险山区,人工实地详查困难,需要借助无人机航拍影像和卫星遥感影像进行排查。滑坡体向下堆积可能会造成道路中断、建筑物受损、人员伤亡,甚至引发堰塞湖等一系列次生灾害。考虑到滑坡的复杂性和危害性,获取滑坡影像后,如何快速、精准地提取滑坡至关重要。目前,传统滑坡提取方法主要包括目视解译法、特征设计法。
目视解译法是基于专家经验,人工交互地对滑坡进行识别,可以精确地确定滑坡类型及边界,但是目视解译法需要丰富的专业知识和大量人力物力,在发生突发大面积滑坡时耗时过长,无法迅速响应。基于特征设计的提取方法是根据滑坡的特点及光谱特征,人工选取滑坡纹理、色彩、色调等浅层特征,为每个特征调整合适的参数和阈值来区分滑坡与背景,适用于灾害发生后的快速灾情评估工作,此类方法可分为像素级特征设计方法和面向对象级的特征设计方法,像素级特征设计方法利用多时相遥感影像以及其他辅助数据分析遥感影像物源变化特征,设计并筛选合适的特征进行多尺度分割,实现滑坡的快速提取[1⁃4];面向对象级的特征设计方法通过探讨滑坡灾害影像多维遥感解译方法,建立对象级滑坡提取模型[5],在此基础上,选择合适的特征属性进行滑坡提取[6]。上述方法主要是通过特征设计结合传统分类对滑坡进行特征提取,可得到较高精度,但需要时序影像或者人为设置多个阈值因子,很难被应用于复杂多样的滑坡场景。
近年来,深度卷积网络在遥感影像语义分割方面取得明显突破,深度卷积神经网络通过自学习的方式从大量样本中学习语义特征,一定程度上避免了人工设计的局限性。但卷积神经网络(convolu⁃tional neural network,CNN)本质仍然是一种局部方法,通过下采样增大感受野,因此当光谱特征一致或者目标尺度差异较大时,分割结果准确率明显降低。
针对目前滑坡尺度差异大、滑坡和其他地物存在光谱混淆的问题,本文在经典残差网络(residual network,ResNet)——ResNet50的基础上,引入金字塔结构,用以融合不同尺度的特征,增强网络模型在不同尺度滑坡的特征提取能力;引入通道注意力模块(channel attention module,CAM),聚合上下文信息,筛选更有用的语义通道信息,抑制干扰信息,增强网络模型区别混淆的能力;并将两个模块嵌入Res Net50骨架模型,实现特征的深度融合,提高滑坡的识别精确度。本文以2017年8月8日九寨沟地震震后无人机遥感影像为例,构建滑坡数据集,设计对比实验,测试本文方法对滑坡影像的提取效果。
1 滑坡语义分割方法
1.1 多尺度深度注意力模型
滑坡语义分割通过CNN以自学习的方式建立影像和标签之间的一一对应关系,为滑坡影像逐像素分配语义类别,从而获得滑坡标签、位置和像元的形状。在滑坡航拍影像上,航高变化和地形起伏会导致滑坡尺度多变与滑坡体间尺度的差异,本文在Res Net50的基础上进行改进,首先嵌入金字塔池化结构,提取图像的多尺度特征,有效融合多尺度的上下文信息;其次在特征和注意力机制之间建立关联来探索全局语义关联信息,通过自学习的方式获取每个特征通道的权值(描述该特征通道的重要程度),依照这个权值筛选更有用的语义通道信息。
本文的语义分割模型整体框架见图1,L1~L5分别为Res Net50的5个模块,第5模块提取的特征通过金字塔池化得到多尺度聚合特征;再通过CAM将特征提取的卷积结果作为注意力模型的输入;最后通过L6上采样模块得到滑坡分割图。
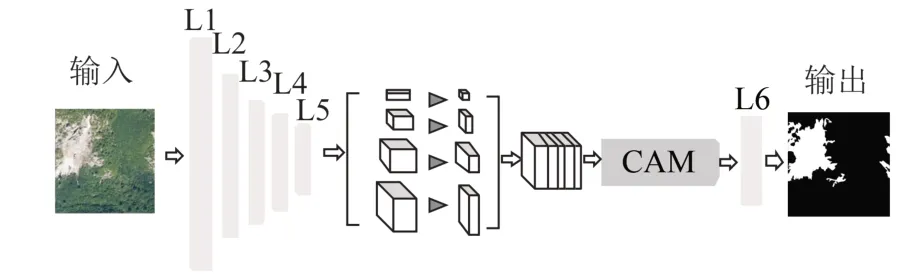
图1 本文方法Fig.1 The Proposed Method
1.2 ResNet50骨架结构
Res Net为经典的语义分割骨架网络[7],在此基础上衍生了一系列改进模型,其跳转链接结构能有效抑制梯度消失和梯度爆炸问题。通过实验发现,ResNet50系列比U⁃Net[8]更适合处理滑坡,其参数量小,运行负载低,作为骨架网络,具有更灵活的性能。ResNet50残差结构采用三层残差学习模块,适用于深层网络训练,残差结构使用跳转链接将输入x直接映射到输出端,并未增加任何其他参数,在深层次网络中,能缓解退化问题,还能有效减少计算量[7]。ResNet50结构见图2。
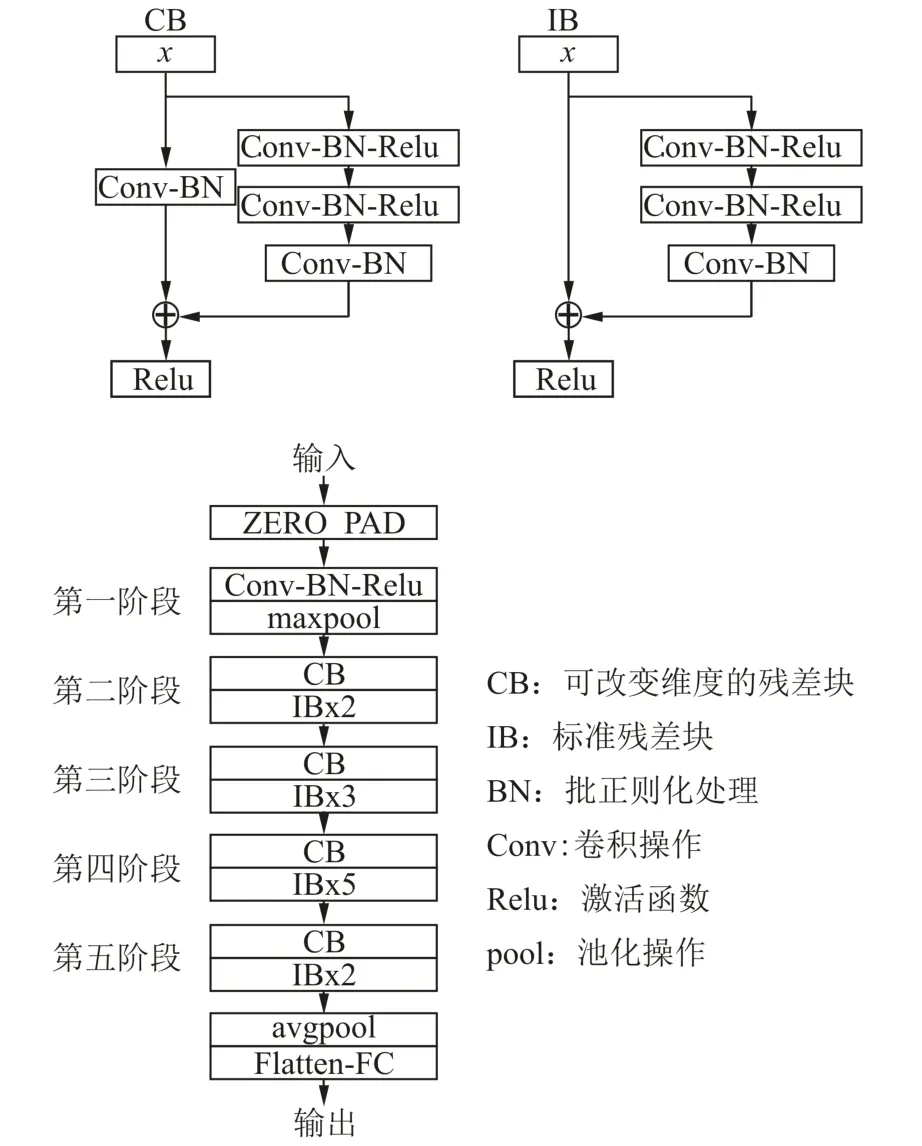
图2 ResNet50结构Fig.2 Structure of ResNet50
1.3 金字塔池化结构
在CNN中,池化层简化计算复杂度,扩大感受野,在前向传播中具有重要作用。进行池化操作时,图像丢失大部分细节信息,造成精度的损失。无人机影像中滑坡尺度差异巨大,且滑坡内部纹理单一,连续的池化操作容易漏掉一些小滑坡,或者部分大滑坡被判别为其他地物。因此,针对滑坡影像,提取图像的多尺度特征,有助于减少空间信息损失。金字塔池化结构在传统池化方式基础上,将不同区域的上下文信息结合起来,获取不同尺度上的融合特征,提升对不同尺度目标的分割效果[9]。
本文的金字塔结构分为4层:第1层直接进行全局平均池化,第2层被划分为4个子区域,第3层被划分为9个子区域,第4层被划分为36个子区域。在每一个子区域中采用全局池化的策略进行特征提取,使用1×1卷积降维对每层结果进行降维,再通过上采样和通道融合输出最终特征图。
1.4 CAM
人类观察图像常通过注意力来迅速定位物体可能存在的区域,引入注意力机制也可以帮助神经网络学习到全局信息,提升性能。在语义分割领域,自注意力[10]、non⁃local neural networks[11]、squeeze⁃and⁃excitation networks[12]已被提出并被广泛应用。针对山区滑坡影像存在上下文信息分散、滑坡尺度变化大的情况,使用注意力机制,只需判断少量潜在信息,过滤掉不重要的特征,更加关注有价值的信息,能在一定程度上克服光谱特征近似地物的干扰。因此,考虑在滑坡影像上使用CAM筛选有用的通道信息,聚焦滑坡区域。
经过卷积操作Ft得到三维(H×W×C)的特征图U,通过权重抽取Fs、权重更新Fe、权重分配Fa3个步骤的运算得到最终结果xˉc。
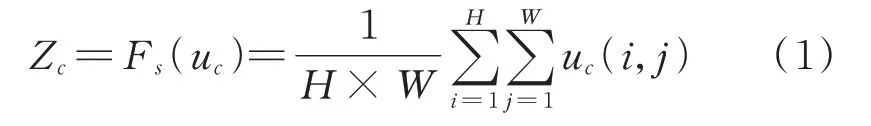
式中,i、j对应像素点的位置;uc∈RH×W,表示二维信息,其中,RH×W表示H×W的空间;Fs采用全局平局池化对uc进行压缩,得到多通道全局信息Zc。
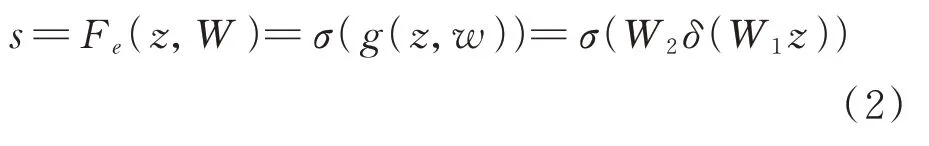
式中,σ表示Relu激活函数;δ表示Sigmoid函数;,其中,r=16;经过相乘的全连接操作和Sigmoid激活层后,再经过相乘的全连接操作和Relu激活层,得到学习后的权重s。
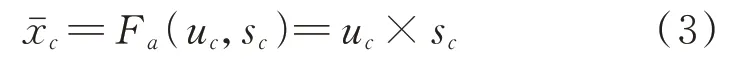
式中,sc代表权重信息。
由上述过程可知,CAM的引入有助于筛选重要信息,提高特征可辨性,增强特征指向性。
1.5 滑坡精度评价标准
本文采用精度、召回率、F1⁃score和交并比(in⁃tersection⁃over⁃union,Io U)4个指标对模型进行性能评估。精度表示预测正确的正类个数占全部预测为正的比例;召回率表示预测正确的正类个数占全部正类的比例;F1⁃score同时考虑了精度和召回率的平衡;Io U是语义分割的常用度量。计算公式如下:
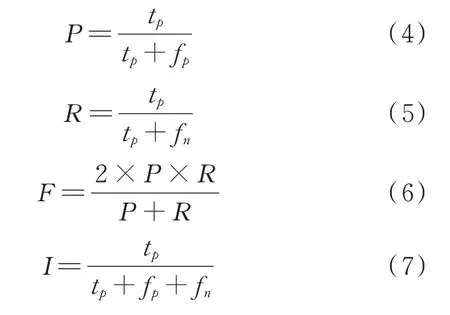
式中,P、R、F、I分别表示精度、召回率、F1⁃score、Io U;tp表示分类正确的正类;fp表示误分为正类;fn表示未分出的正类。较高的精度值表示着较少的误检,较高的召回值表示着较少的漏检,F1⁃score、Io U揭示了整体性能。
2 实验结果与分析
2.1 数据与预处理
2.1.1 实验数据
2017年8月8日,四川省九寨沟发生7.0级地震,引发大量的山体滑坡,造成严重危害[13,14]。本文实验数据为九寨沟震后获取的无人机遥感影像和生成的数字正射影像,如图3所示,分辨率为0.2 m。低空无人机获取的影像具有分辨率高的优势,可精准地确定滑坡的空间分布[15]。新生滑坡破坏原有地形,新的滑坡构造面反射率较高,由于九寨沟山区的光照特性,房屋、河流也容易出现反射效应,为无人机影像滑坡的自动提取带来了困难。在无人机影像中,滑坡呈现出大小不一、形状复杂、与周围地物交错混淆的特征。滑坡堆积物向下掩盖地物,部分滑坡靠近道路、房屋、河流,造成道路、河流堵塞、建筑物损坏,在无人机影像上造成地物混淆,滑坡解译容易产生漏分和误分。
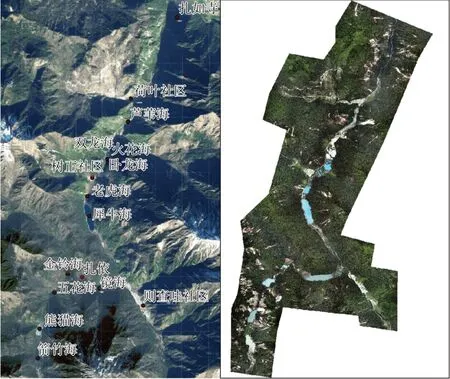
图3 研究区域及影像Fig.3 The Study Area and Images
2.1.2 实验数据集制作
对九寨沟滑坡无人机遥感影像进行标注、增强等一系列预处理操作。根据整幅影像标注相应地物标签,滑坡像素数值为255,其他地物像素数值为0。按照512×512像素大小裁剪原始影像。由于整幅影像中滑坡占比较少,用算法对滑坡旋转90°、180°、270°能保证识别到更多的滑坡形态特征。剔除过多无意义的背景切片,共得到总的数据训练集3 431张影像。本文选用两幅区域影像作为测试集,为减少拼接痕迹,使用256像素的跨幅重叠影像裁剪得到512×512像素的测试影像2 036张,部分训练集见图4。

图4 部分训练集Fig.4 Part of the Training Sets
2.1.3 实验环境
滑坡提取实验平台为Ubuntu 18.04系统;深度学习软件框架为Tensor Flow 1.9,内置的Python版本 为3.6.1;训练设备为Intel(R)Core(TM)i7⁃8700K CPU@3.70 GHz处理器;16 GB内存;显卡为NVIDIA TITAN RTX显卡。实验训练批次大小为12,迭代90轮,学习率为1×10−3。模型通过随机梯度下降对网络的权重和偏置进行更新。
2.2 实验结果
为便于将本文方法与其他方法进行比较,利用全卷积网络(fully convolutional network,FCN)[16]、U⁃Net、ResNet50和本文方法对相同的数据进行训练和测试。滑坡数据包含训练影像和测试影像,选取具有代表性的两个滑坡区域进行测试,对这两个区域的滑坡类内差别和地物混淆情况进行结果展示和分析。
2.2.1 地区1
表1中给出了各个方法在地区1测试数据上的各项对比,本文方法的F1⁃score值和Io U值分别为0.779和0.638,优于FCN⁃16s、U⁃Net、Res Net50。在图5中,地区1的地物构成复杂,包括房屋、道路、河流、农田、房屋道路附近的院落和裸地,以及与滑坡纹理相仿的河床。九寨沟训练影像相关负样本较少,造成了一定的区分难度,针对左上方农田和下方的河床,利用其他方法获取的结果中存在较多地物混淆现象,本文方法在保证召回率的情况下,对滑坡判断更加准确。
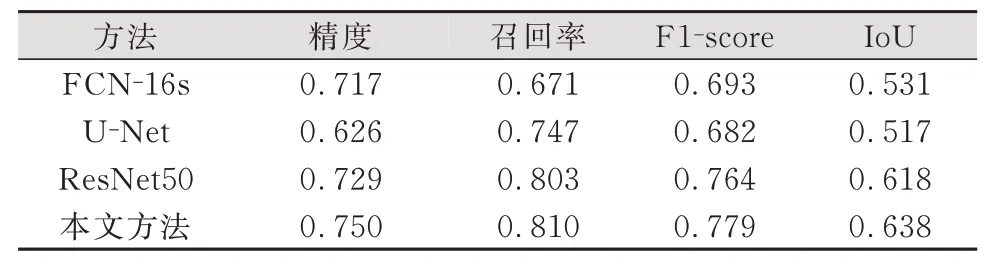
表1 地区1精度对比Tab.1 Accuracy Comparison in Region 1

图5 地区1的测试效果Fig.5 Test Results in Region 1
2.2.2 地区2
表2中给出了地区2的影像精度验证结果,本文方法的F1⁃score值和Io U值达到0.879和0.784,优于FCN⁃16s、U⁃Net、ResNet50。由图6可以看出,下方河流及河床容易出现错误识别。相较于FCN、U⁃Net和Res Net50方法,本文方法输出结果中,混淆区域的滑坡识别精度明显提高,只出现了部分错误分类结果,分割边界更加清晰并且更加规整,表明本文方法更为有效。

图6 地区2的测试效果Fig.6 Test Results in Region 2
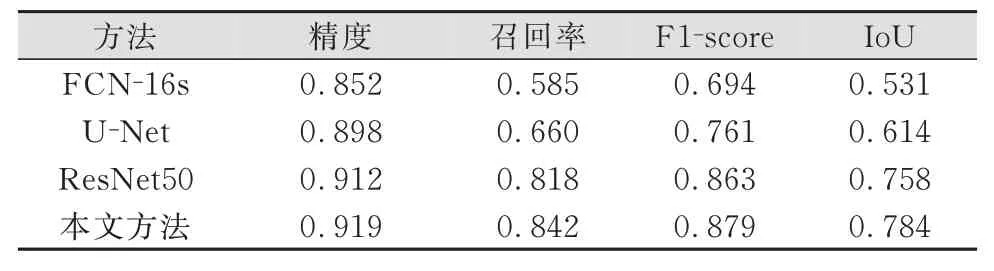
表2 地区2精度对比Tab.2 Accuracy Comparison in Region 2
由地区1和地区2的实验结果可知,FCN⁃16s、U⁃Net、ResNet50经典模型仍有局限性,导致影像中部分地物被误判为滑坡;在地区1和地区2中,本文方法的精度、召回率、F1⁃score和IoU 4个指标都达到最优,相较于其他方法,本文方法准确地判断了滑坡。
3 结束语
针对传统滑坡提取方法中滑坡尺度差异大、易混淆的问题,本文结合CNN的优势,建立了多尺度深度注意力模型,并在九寨沟滑坡数据集上,实现了滑坡的精准提取。实验结果表明,本文方法有效地提高了滑坡提取精度,为后续滑坡危险性评估、灾害详查、灾情预警等提供参考。然而,本文所获取的滑坡影像中,有效样本较少,在今后,需要建立更丰富的无人机滑坡影像数据集,并设计更为高效的网络,进一步解决滑坡和其他光谱混淆地物的有效区分问题,提高滑坡提取精度。
猜你喜欢
地球科学与环境学报(2022年4期)2022-08-25
科海故事博览·中旬刊(2022年4期)2022-04-23
同学少年·作文(2017年1期)2017-06-05
中国信息化周报(2015年1期)2015-04-09
长江学术(2015年1期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
雕塑(2000年2期)2000-06-22
