
基于层次化表示的电力文本命名实体识别和匹配算法
2022-06-02 06:35李慧斌
计算机与现代化 2022年5期
杨 政,蔡 迪,李慧斌
(1.云南电网有限责任公司电力科学研究院,云南 昆明 650217; 2.西安交通大学数学与统计学院,陕西 西安 710049)
0 引 言
随着5G、物联网、大数据、人工智能等新一代信息技术对电力行业数字化转型的赋能,传统需要人工处理的任务,如电力领域科技项目申请书与评审专家的匹配工作,可进行智能化升级,进而提升管理效率。电力领域科技项目申请书和评审专家的匹配可看作是一种匹配任务,即通过提取有效特征来对项目文本与专家信息的有效匹配,最终得到合理的输出[1]。对电力文本的处理涉及自然语言处理(Natural Language Processing, NLP)中的命名实体识别(Named Entity Recognition, NER)这一关键技术,即识别出文本中自定义的专有名称并对其进行分类[2]。在命名实体识别概念出现的早期,命名实体识别的研究工作大多是基于人工构建的规则。基于规则的实体提取方法代表性工作是Rau[3]提出的基于复杂的语言学规则判断字符串是否为专有名称实体,这也是命名实体识别正式成为一项文本处理任务的标志;此后,Collins等人[4]提出使用机器自动发现规则并进行实体识别的方法。基于规则的方法通常准确度较高,但构建的规则往往领域性较强且模型复杂度较高。近年来,可迁移性更强的基于机器学习的方法受到了广泛关注,具体体现在识别实体边界与序列化标注2个方面[5]。识别实体边界方面,Li等人[6]使用了BdryBot框架对命名实体的边界进行检测,该框架是一种指针网络,可有效克服输出词汇长度不固定与实体边界标记稀疏的问题。序列化标注方面,当前综合效果最好的方法是先使用双向长短期记忆循环神经网络[7](Bi-directional Long Short-Term Memory, BiLSTM)学习序列之间的顺序信息,再使用条件随机场(Conditional Random Field, CRF)学习标签之间的依赖关系,该类方法可更合理地学到序列与其对应实体标注之间的关系。近年来,另有学者相继提出结合局部与全局信息来构造更合理的词语表示[8-9]、采用更有效的模型框架[10-11]或结合未登录词[12]等策略来改善模型的识别效果。
本文使用基于机器学习的方法进行电力项目文本和电力领域专家文本的命名实体识别,提出融合词语、句子、文档3个方面信息的层次化语义表示的研究思路,以期获得更加合理的词嵌入向量,这种融合文档、句子和词语的文本层次化表示的提出是受文献[13-14]等工作的启发,Akbik等人[13]提出将文档级别的全局嵌入与字符级别的局部嵌入相融合的方法,在一系列序列标注任务中均可达到最优效果。Liu等人[14]指出了传统RNN隐藏状态之间的浅层连接对于全局信息建模的不足,提出了融合句子层级与文档层级的文本语义表示框架,在没有利用预训练模型的前提下,对于序列标注任务达到了当时最优的效果。对于文本语义信息的层次化表示类似于视觉任务中的图像多尺度表示,具有普遍意义。在得到层次化表示的词嵌入向量后,将得到的词向量输入到BiLSTM-CRF模型中实现命名实体识别。在此基础上,针对电力文本与电力领域专家的实体匹配问题,提出了一种基于双特征空间映射的方法,即将实体分别映射到语义空间与象形空间中进行匹配。
1 Attention-RoBerta-BiLSTM-CRF模型
本文提出的算法流程如图1所示,输入数据为电力项目文本与电力专家文本,输出为电力项目与电力专家的匹配结果。算法分为2个部分:第一部分为基于ARBC模型的命名实体识别模块;第二部分为基于语义-象形双特征空间映射的电力项目与电力专家实体匹配模块。
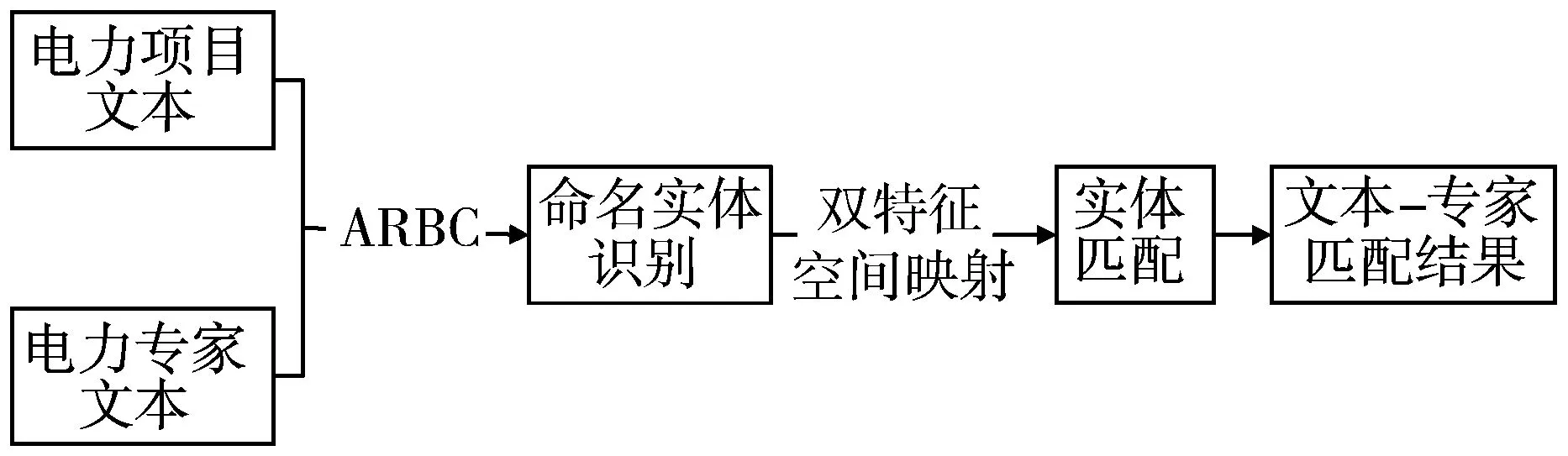
图1 电力项目与电力专家命名实体识别与匹配流程
在命名实体识别部分,使用ACBC模型对输入的电力项目文本与电力专家文本进行相关实体的提取。在对电力项目文本与电力专家文本的命名实体识别前,首先对相关实体进行定义。具体而言,对电力项目文本提取“使用方法”与“涉及领域”这2个实体,对电力专家文本提取“研究方向”与“研究方法”这2个实体(见表1)。对于项目与专家的匹配模块,本文采取双特征空间映射的方法,分别将识别出的电力项目本文实体与电力专家文本实体映射到语义空间与象形空间,并使用余弦相似度度量实体匹配得分,最终将得分最高的项目文本与专家文本作为结果输出。
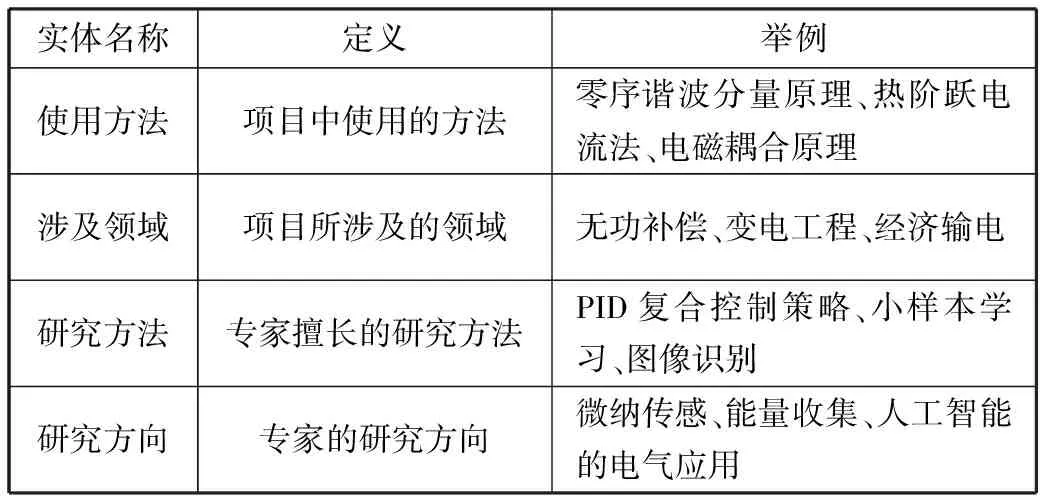
表1 实体定义
本文提出的基于层次化表示的命名实体识别模型框架如图2所示。由3个部分构成,分别为基于层次化表示的词嵌入模块、BiLSTM模块和CRF模块。基于层次化表示的词嵌入模块首先通过预训练模型罗伯特[15](A Robustly Optimized BERT Pretraining Approach, RoBerta)得到词语的嵌入向量;再将词语的词频-逆文档频率值(TF-IDF)作为Attention权重信息,与词语表示向量相乘并相加,得到包含了文档层面注意力机制的句子表示;接着将词语嵌入向量与其对应的句子向量进行线性加权融合,最终得到词语的层次化表示向量。BiLSTM模块和CRF模块输入为由词向量组成的句向量矩阵,通过BiLSTM模块学习词语的序列关系以及CRF模块学习词语对应实体标签的关系,进而得到概率最大的标签序列以及每个词语对应的实体标签。
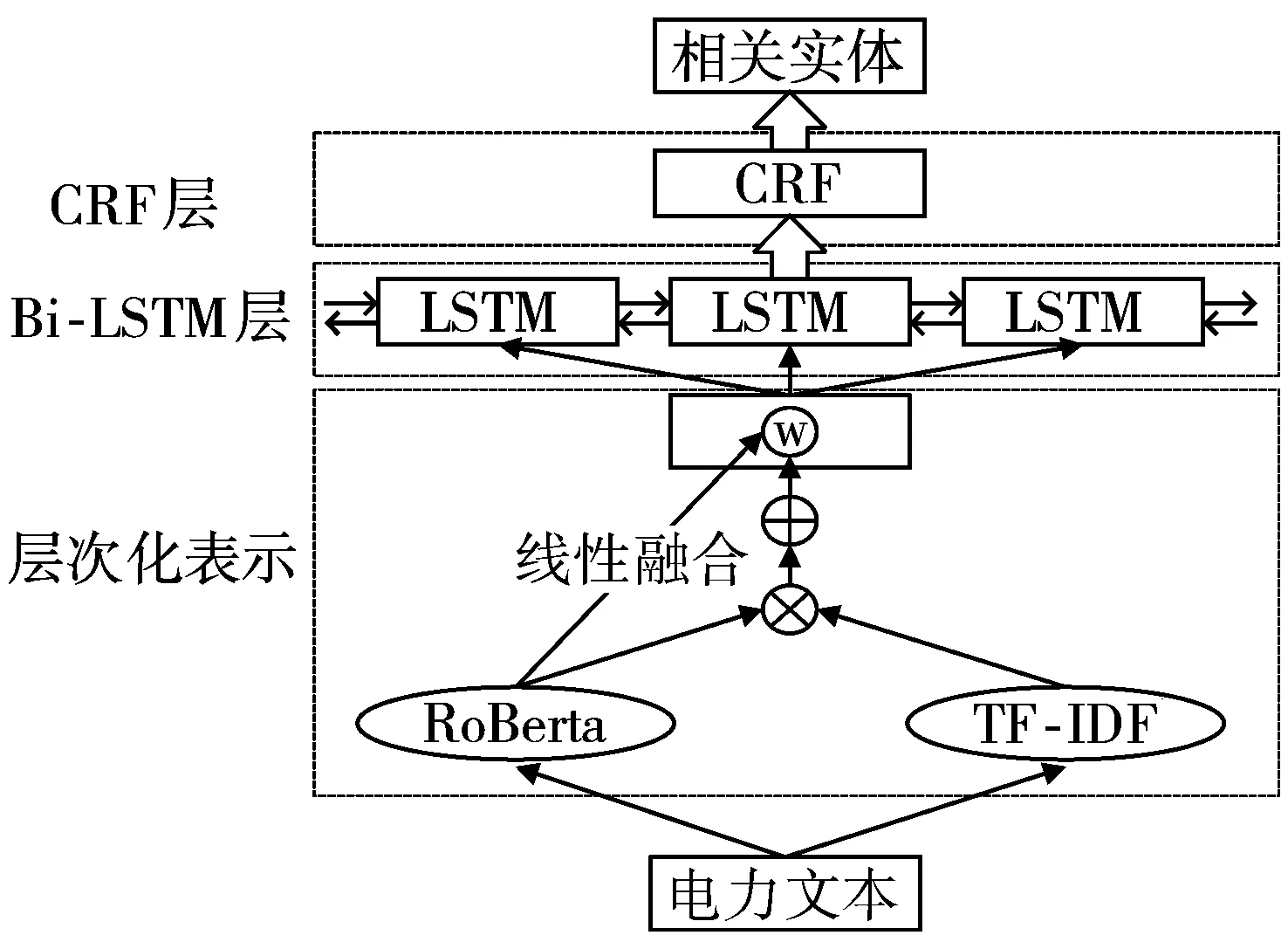
图2 基于层次化表示的命名实体识别模型框架
1.1 基于层次化表示的词嵌入模块
词嵌入模块由2个部分构成:一部分是使用预训练模型RoBerta得到词语嵌入向量,如公式(1)所示;另一部分是通过使用RoBerta与TF-IDF得到的句向量,如公式(2)和公式(3)所示。将词向量与句向量进行线性加权融合,作为电力文本词嵌入模块的层次化表示输出,如公式(4)所示。TF-IDF是一种常用的信息检索与数据挖掘的加权技术,可以有效捕捉到词语之于文档的重要程度,本文采取TF-IDF加权词向量,得到的句向量可以有效包含文档级别信息。
wi=R(xi)
(1)
αi=TFIDF(wi)
(2)
(3)
ti=k1×wi+k2×si
(4)
其中,xi为输入词语的独热编码向量,R为RoBerta预训练模型,wi为模型输出的词向量;αi为该词向量对应的TF-IDF权重,N为该词语所属句子的长度,si为整个句子的嵌入向量,词语的最终嵌入向量ti为词嵌入向量和句子嵌入向量的线性加权融合。
RoBerta是预训练语言模型Bert的一种变种,结构如图3所示。
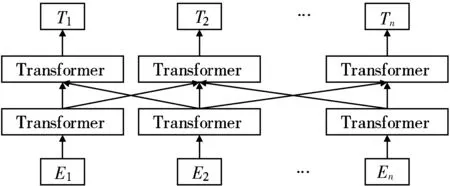
图3 RoBerta预训练语言模型的网络结构图
由图3可见,RoBerta预训练语言模型的特征提取器为双向Transformer[16],与传统的循环神经网络(Recurrent Neural Network, RNN)相比,这种结构可以充分利用上下文信息,捕捉到更长距离的依赖关系。
RoBerta预训练语言模型的输入如图4所示,模型输出为该句子所有词语经自注意力编码器编码后的词嵌入矩阵。
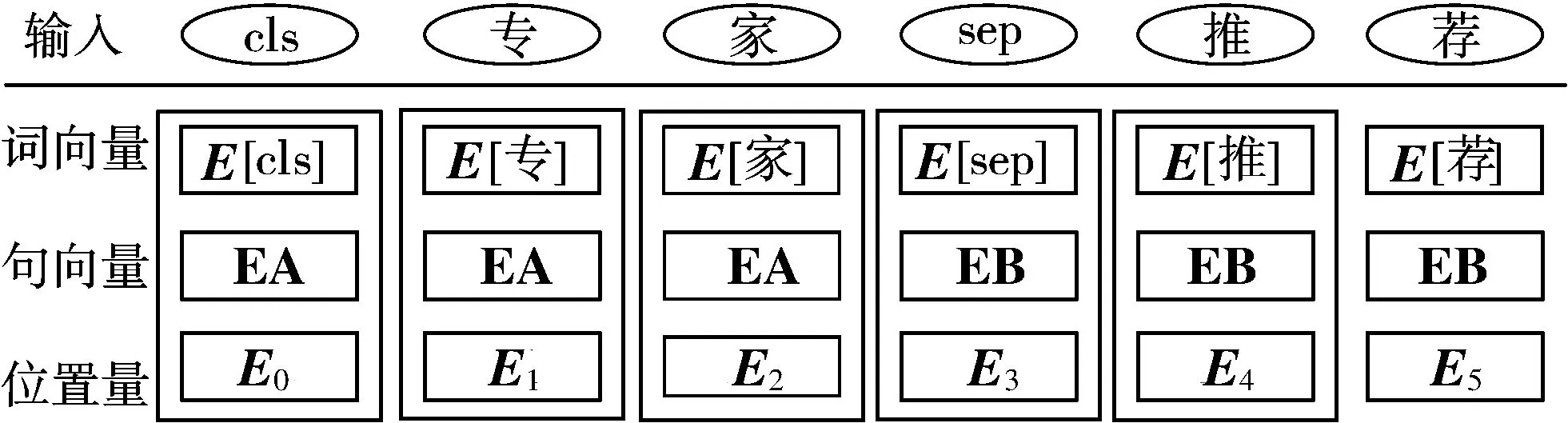
图4 RoBerta预训练语言模型输入示意图
如图4所示,模型输入E由词向量、句向量和位置量3个部分构成。词向量中E[cls]和E[sep]分别为类别符和分隔符的编码向量;句向量为用来区分不同句子的编码向量;位置量为句子中不同词语对应位置的编码向量。
RoBerta与经典的Bert[17]预训练语言模型的区别体现在以下几个方面:增大了Batch size、引入了动态Masking机制、扩大了训练样本、移除了损失函数中NSP(Next Sentence Predict)项的约束。特别是模型的Batch size由256增大到8000,并采用10种不同的Masking方式,使得不同epoch中样本不会被固定的Masking掩盖,训练数据由13 GB变为160 GB。
RoBerta预训练语言模型主要构成为Transformer结构,Transformer的每个单元由自注意力层(self-Attention)、前馈神经网络(Feed Forward Network)以及归一化层(Add&Normalization)构成,具体结构如图5所示。
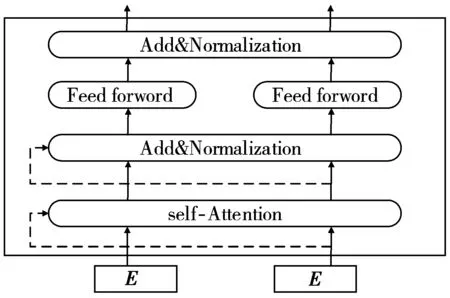
图5 Transformer结构
1.2 BiLSTM模块和CRF模块
循环神经网络[18](RNN)是序列关系学习任务中应用最为广泛的神经网络,BiLSTM为RNN的一种变种,其自带双向时序性特征与特有的门控结构,可以有效解决梯度消失和爆炸问题。
BiLSTM每部分包含3种门控系统,分别为输入门it,遗忘门ft和输出门ot。每部分的输入为t-1时刻隐藏层对应的值ht-1与t时刻输入的词语编码xt,3种门控系统的迭代公式如下:
it=σ(Wixxt+Wihht-1+bi)
(5)
ft=σ(Wfxxt+Wfhht-1+bf)
(6)
ot=σ(Woxxt+Wohht-1+bo)
(7)
其中,W为权重矩阵,b为偏置项,σ为Sigmoid激活函数。3个门控系统中,it负责对历史信息的选择性记忆,ft负责对t-1时刻隐藏状态的遗忘,ot负责当前信息的输出,在得到3个门控系统的输出值后就需要更新迭代细胞状态ct与隐藏层ht,迭代公式如下:
gt=tanh(Wcxxt+Wchht-1+bc)
(8)
ct=it×gt+ft×ct-1
(9)
ht=ot×tanh(ct)
(10)
其中,gt为需要选择的历史信息,ct为当前的隐藏细胞状态。
BiLSTM模型将每个词语与标签的得分矩阵作为输出,称为“发射矩阵”A,具体为:将词语隐藏层向量经线性层(即用BiLSTM做分类的最后一步,将隐藏状态映射为得分)映射后的值作为该词语对应标签的得分矩阵。条件随机场[19](CRF)是一种常用的序列标注算法,本文选择线性CRF来学习序列中标签之间的内在关系,即预测输入序列对应的标签。给定输入词语序列S(s1,s2,…,sn)及其对应的标签序列L(l1,l2,…,ln),令其满足马尔科夫假设[20],即:
P(li│S,l1,l2,…,li-1,li+1,…,ln)=P(li│S,li-1,li+1)
(11)
令词语与标签之间转移得分矩阵为T,则任意词语与标签之间的得分R(S,L)为:
(12)
求解时使用Softmax函数最大化每个标签的概率:
(13)
训练时用极大似然对数得分函数求解P(S|L)的最大后验概率:
(14)
本文在训练和求解最优路径时采取了维特比算法Viterbi[21]。
给定电力项目文本和电力专家文本,通过本章提出的基于层次化表示的词嵌入模块、BiLSTM模块以及CRF模块,最终得到电力项目文本中的“使用方法”和“涉及领域”命名实体以及电力专家文本中的“研究方向”和“研究方法”命名实体。
2 基于双特征空间映射的实体匹配
本章的主要任务是对电力项目文本的2类实体(“使用方法”和“涉及领域”)与电力专家文本的2类实体(“研究方向”和“研究方法”)进行有效匹配。为此,本文提出基于象形-语义双特征空间映射的匹配策略,具体流程如图6所示。

图6 基于象形-语义双特征空间映射的实体匹配流程
给定待匹配的实体,具体匹配流程为:
1)将4种实体分别通过象形层面的Cw2vec[22]模型与语义层面的Roberta模型映射为特征向量。
2)将电力项目文本的“涉及领域”实体与电力专家文本的“研究方向”实体在象形特征空间和语义特征空间内进行全排列的余弦相似度计算,将2个空间上的匹配得分相加,得到研究方向实体匹配得分。对电力项目文本的“使用方法”实体与电力专家文本的“研究方法”实体做相同的操作,得到研究方法实体匹配得分。
3)将电力项目文本和电力专家文本的方法实体匹配得分与方向实体匹配得分按0.3与0.7的权重加权相加,得到电力项目文本与电力专家文本的综合匹配得分。
4)将综合匹配得分最高的专家作为该电力科技项目申请书的评审专家。
对于象形特征空间映射,参考了蚂蚁金融提出的中文词汇象形特征词嵌入Cw2vec的思想;另外,对于语义空间映射则采取RoBerta预训练语言模型提取实体的词嵌入向量。Cw2vec的核心思想是首先将中心词拆分为多个笔画,随后通过不同笔画的n-gram信息组合来表示该中心词所对应的上下文词,达到充分提取中心词象形信息的效果。令当前中心词的笔画特征向量c与其上下文词的笔画特征向量w的相似度为:
(15)
其中,K为w通过n-gram产生的n元笔画特征向量数量,wi为w的n元笔画特征向量。假定已知上下文词笔画特征向量w,出现中心词笔画特征向量c的概率,如式(16)所示。
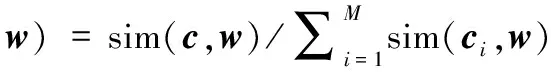
(16)
其中,M为语料库中所有词语的数量,ci为语料库中的词语笔画特征向量。此时由于语料库中的词语数量较多,导致分母的计算量过大,于是引入负采样操作[23],即通过让每个训练样本仅修改一小部分权重而不是全部权重,从而达到加快模型训练速度的效果。最终可以得到对数目标函数L,如式(17)所示。

(17)
其中,V为语料库中所有词语的笔画特征集合,T(w)为当前上下文词笔画特征向量w的n-gram笔画集合,α为负采样操作得到的负样本个数,E为求期望,neg为负采样操作得到的新样本特征向量。最终通过梯度下降优化目标函数,并更新上下文词向量,可以得到基于字符信息的词嵌入w。
3 实验结果与分析
3.1 实验数据
对于电力项目文本数据,本文从中国南方电网有限公司云南电力科学研究院科技项目申报数据库中选取2000篇文档作为语料库。研究主题主要包括:高电压与绝缘技术、电机与电气以及电力系统及自动化等。本文对项目申请书摘要进行分词和去除停用词操作,并进行命名实体的标注。由于所提方法对长序列不敏感,采取将项目申请书摘要按句号断开,同时保证预处理后的数据集中含有所需命名实体标注的句子与不含所需命名实体标注的句子数比例为8∶1,总共的语句数约为10000句。
对于电力专家文本数据,从某高校电气工程学院爬取了24名专家的个人主页数据,研究方向可分为:高电压技术、工业自动化、电机与电器等。具体做法如下:
1)在知网检索专家姓名及所在学校关键词,爬取其已发表论文的摘要,并运用本文提出的ARBC模型进行命名实体识别,提取出论文中所使用的方法,作为专家的研究方法实体。
2)对专家个人主页中所描述的研究方向进行提取,作为专家的研究方向实体。
对于爬取的电力专家文本研究方向实体进行人工筛选,对电力专家文本研究方法实体采取与电力项目文本同样的预处理步骤。
由于电力专家文本的数据量较小,同时电力专家文本的研究方法实体与电力项目文本的使用方法实体具有可比较性,因此本文对电力专家文本的研究方法实体采取与识别电力项目文本的使用方法实体相同的模型。
数据集划分方面,本文将10000句电力项目文本按8:1:1的比例划分为训练集、验证集与测试集。
数据标注方面,本文采取经典的BIO三段标注法[24],即对于每个实体,将第一个字标注为“B-实体名称”,后续为“I-实体名称”,非本文需要的实体则标注为O,标记效果示例如下,不同下划线用于区分不同实体(使用方法:XXXX;涉及领域:XXXX)。
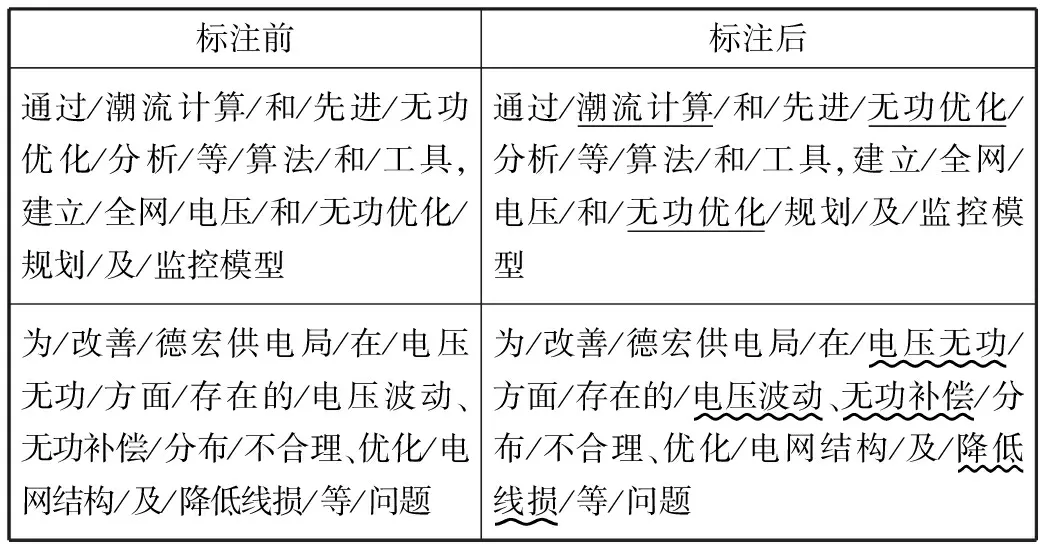
表2 标注效果展示
3.2 模型参数设置
在基于层次化表示的词嵌入模块,本文使用RoBerta预训练语言模型将词语映射为1024维向量,公式(4)中对于词向量与句向量的线性加权融合权重参数和分别设置为0.8与0.2。对于BiLSTM模块与CRF模块,将单个句子最大长度设置为150,训练批次设置为8,优化器为AdamW[25],学习率设置为2×10-6,BiLSTM模块的层数为2,CRF模块的全连接层类别参数设置为2。
3.3 电力项目文本命名实体识别
为了验证本文提出方法Attention-RoBerta-BiLSTM-CRF的有效性,选取BiLSTM+CRF为baseline在电力项目文本上做相关消融实验,结果如表3所示,电力项目文本识别效果的可视化展示(部分)如图7所示。
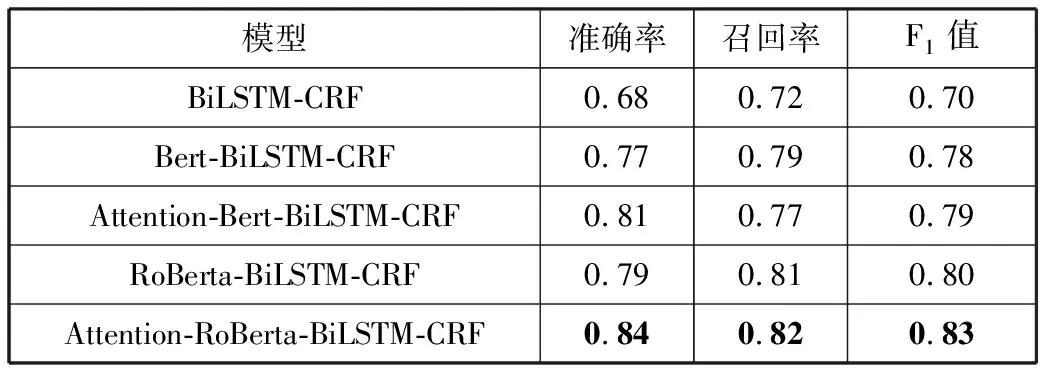
表3 电力项目文本命名实体识别结果
由表3结果可知,在对BiLSTM-CRF模型加入Bert预训练模型后,F1值提升了8个百分点,将Bert模型替换为RoBerta模型后F1值提升了2个百分点,表明预训练模型能够较好地进行词嵌入表示,进而在实体识别任务上可以获得良好的效果,帮助模型更准确地理解句子内部的语义信息。特别地,本文提出的基于注意力机制的层次化表示学习方法进行命名实体识别的效果达到了最优,表明本文提出的层次化表示机制可以有效地获得词语在隐空间上更合理地表示,进而提升模型效果。值得注意的是,在使用了Attention机制后,不论是结合预训练模型Bert或结合预训练模型RoBerta方法,最终的模型效果都有一定提升,表明在电力文本的处理中,Attention机制能捕捉到文本中更多隐含语义关系。
图7中展示了部分从电力项目文本中提取的“使用方法”实体和“涉及领域”实体。从图7(a)中可以看出,识别出了脉冲电流法、等值电路数学模型、集成学习等较为合理的“使用方法”实体,从图7(b)可以看出,识别出了变压器检修、变电工程、清洁电力共享等“涉及领域”实体。综上所述,本文提出的基于层次化表示的ARBC模型能够有效提取电力项目文本的相关实体。

(a) “使用方法”实体 (b) “涉及领域”实体
为了进一步验证层次化表示对于电力文本命名实体识别的优势,对采用融合特征与仅采用词语层面特征的实体识别效果进行实例比较分析,结果如表4所示。

表4 使用层次化表示与使用词向量表示的实体识别效果对比(以“使用方法”与“研究方向”实体为例)
从表4可知,对于实体描述有歧义的序列,使用层次化表示方法的ARBC模型比使用词向量表示方法的模型识别更为准确。使用层次化表示方法的ARBC模型通过句子以及文档层级的信息有效捕捉到序列内部隐含关系,从而识别出有一定歧义的“缺陷精确定位关键技术”实体,进而提高实体识别精度。
3.4 电力项目与电力专家命名实体匹配
为验证本文提出的基于象形-语义双特征空间映射匹配算法的有效性,本文针对3.3节从2000篇电力项目文本中得到的实体与从24位电力专家文本中得到的实体,做了3组对比实验,分别为语义空间映射+余弦相似度匹配、象形空间映射+余弦相似度匹配与象形-语义双特征空间映射+余弦相似度匹配。对于电力项目实体和电力专家实体匹配的效果如图8所示。
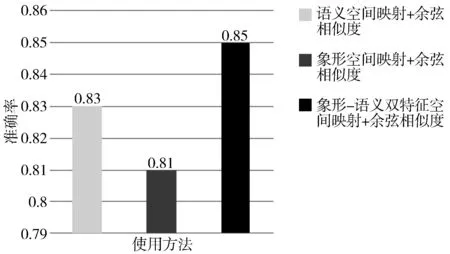
图8 电力项目与电力专家命名实体匹配效果比较
从图8中可以看出,本文提出的双特征空间映射的方法是有效的,在2000篇电力项目文档与24位电力专家文本进行匹配的准确率达到了最高的0.85。实验结果表明象形空间和语义空间可以捕捉到词语语义与象形层面的信息,2种特征空间具有较强的互补性,对实体进行匹配比使用单一特征空间映射用到的实体信息更加充分。同时,本文针对使用双特征空间映射的有效性进行实例比较分析,其中,“使用方法”实体为:零序谐波分量原理、电磁耦合原理、有限元法,“研究方向”实体为:电转气、电-气耦合系统、协同优化规划,具体如表5所示。

表5 单特征空间映射与双特征空间映射的匹配效果比较(以“使用方法”与“研究方向”实体为例)
从表5中可以看到,2个模型均认为“电磁耦合原理”与“电-气耦合系统”是申请书与专家匹配时的最高得分实体。但是在仅使用语义空间映射匹配时,模型认为“电磁耦合原理”与“电-气耦合系统”在隐空间关联度非常低,对项目申请书和专家的匹配给出了较低得分;而对于引入了象形特征的双特征空间映射模型,则可以有效捕捉到“电磁耦合原理”与“电-气耦合系统”在象形层面是非常接近的,最终得出和人工判断一致的结果,对项目申请书和专家的匹配给出了较高得分。综上所述,本文提出的基于层次化表示学习的电力文本与专家文本的命名实体识别与匹配算法是一种准确高效的方法。
4 结束语
本文实现了一种对电力科技项目文本与相关电力专家文本进行基于层次化表示与双特征空间映射的智能匹配算法,有效地解决了电力科技项目申请书与专家之间复杂的匹配问题。后续笔者将着眼于在词嵌入过程中更好地融入文档层级与句子层级的权重信息,进而得到更有效的层次化文本嵌入表示,进一步提升命名实体识别模型的精度。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高一数学(2022年3期)2022-04-28
吉林大学学报(信息科学版)(2022年1期)2022-01-14
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
