
人口普查多报估计研究
2022-06-02 10:45:24胡桂华刘誉环
人口与经济 2022年3期
胡桂华,刘誉环,文 婷
(1.重庆工商大学 数学与统计学院,重庆 400067;2.重庆工商大学 经济社会应用统计重庆市重点实验室,重庆 400067)
一、引言
每个国家的人口普查都会不同程度地发生多报与漏报,使普查登记人口数偏离实际人口数。多报包括重报与误报。重报指普查员登记了普查目标总体内的人一次以上。误报指普查员登记目标总体外的人。目标总体是指人口普查对象,即应该在本次普查中进行登记的那些人的集合。漏报指普查员未登记目标总体内应该登记的人。一般来讲,漏报比多报严重,但也有特例。本文只研究多报,对漏报感兴趣的读者,请见胡桂华等作者发表的相关论文。
普查多报是一个客观存在的问题,应当采取恰当的方法进行研究。人口普查多报估计工作由各国政府统计部门采取抽样调查方法实施。为使研究成果服务于政府统计部门需要,提高其普查多报估计水平,本文采取抽样调查中的分层二重抽样技术构造普查多报率指标体系中的各个指标的估计量及其抽样方差估计量。
本文研究目标是,在深度剖析现行普查多报估计方法所存在的若干缺陷的基础上,建立起一套全新的人口普查多报率指标体系及其估计理论体系,以及设计普查误报人口、重报人口识别及其计数程序。
本文学术价值体现在三个方面:其一,针对普查多报的具体情况,建立起与之相适应的普查多报率指标体系。该体系由重报人次率、重报案例率、误报率和总多报率四个指标构成。对重报,从两个视角来考察:一是重报人次,二是重报案例人数。一个目标总体的人在普查中登记了 3 次,那么重报人次为 2,重报案例人数为 1。其二,每个指标的估计量使用线性估计量和比率估计量构建。在分层二重抽样下,各个指标估计量构成元素的估计量使用双重扩张估计量构造。其三,采用分层刀切抽样方差估计量近似计算各个多报率估计量的抽样方差、偏差和均方误差。
本文应用价值也体现在三个方面:一是对如何识别普查重报人口和误报人口,以及构建普查多报率指标体系及其估计量提出了具体操作方法。这对政府统计部门制定普查多报估计方案具有一定的参考价值。二是有望应用于我国2030年及以后人口普查多报估计,提高其估计精度。三是可拓展到其他相关领域。例如,估计农业普查和经济普查的多报率、户籍登记系统的多报率,等等。
二、文献综述
自1982年到2020年,我国采用质量评估抽样调查估计重报人次率,从未估计重报案例率和误报率。这与未在普查表中设置项目“出生或死亡年月日时点”有关。2021年5月11日发布的2020年人口普查的净漏报率为0.05%。净漏报率不是多报率,是漏报率与多报率之差。我国只对外发布净漏报率,所估计的漏报率和多报率作为内部参考使用。
从1950年起,美国开始正式的人口普查质量评估。美国普查局对外发布的2010年全国总多报人口数为10041千人,总多报率为3.339507%。其中,重报人次为8521千人,重报人次率为2.833693%;误报人数1520千人,误报率为0.505482%。
现在,世界各国都在人口普查质量评估中估计普查多报。然而,各国的做法尚有若干缺陷亟待改进。主要存在以下四个方面的问题。
第一,尚未构建完整的人口普查多报率指标体系。人口普查多报率指标体系应该包括四个指标:①重报人次率;②重报案例率;③误报率;④总多报率。然而所有国家到目前为止,都未估计全部普查多报率指标。南非和澳大利亚等国家只估计总多报率,加拿大等国家只估计重报人次率。除美国等少数国家外,其他国家都未估计误报率。至于重报案例率,则所有国家都未估计。
第二,对普查多报的界定不尽合理。联合国统计司在其撰写的《人口普查质量评估手册》中,把地址登记错误当作普查多报。虽然地址登记错误是一种错误,但如果相应于这个登记的人属于普查目标总体,并且在普查中只登记一次,就应该认定这个登记不是多报。将地址登记错误当作普查多报,不符合普查多报的本质特征,虚增了普查多报人数。
第三,对重报考查对象未作明确规定。审查人口普查登记结果,要把目标总体内的登记和目标总体外的登记区别开来。这是第一层次的甄别。其他次级层次的甄别只能在这两个部分中分别进行。可是有些国家违背了这个原则。如加拿大和美国把目标总体内的重复登记(重报)和目标总体外的重复登记都当作重复登记。这是两种不同性质的重复登记,应该分别处理。其中,前者作为重报,后者作为误报。
第四,不恰当地使用间接推算法估计总多报率。如瑞士使用“普查登记人数估计量与普查正确登记人数估计量之差”与“普查登记人数估计量”的比值来间接推算普查总多报率。进行人口普查多报估计,不只是要算出总多报率,还要从本次普查的多报现象中总结经验教训,提高下一次人口普查工作质量。基于此种目的,需要收集目标总体外的误报人员以及目标总体内重报者的原始数据以及相应的活动情况。在这样的要求下,总多报率指标自然应该用原始数据直接估计,而不应该间接推算。
通过上面的综述可以看出:①目前所有国家在人口普查多报估计中均存在这样或那样的问题;②如何估计人口普查多报率,各国并未达成共识;③对这一领域中的错误观点和错误做法,并未有人提出异议,导致这一领域的科学研究长期处于停滞状态。
三、人口普查多报估计理论
该理论由五部分构成:设计普查多报率指标体系;构造每个指标的线性多报率估计量和比率多报率估计量;计算这些估计量的抽样方差;计算比率多报率估计量的偏差;抽取样本及采集样本多报数据。
1.设计人口普查多报率指标体系
为了评估人口普查多报,需要建立全面系统的普查多报率指标体系,体系中的每一个指标要相互关联,各自承担自己的任务。也就是说,每一个多报率指标要有独立的功能,确切的含义、概念、空间范围和计算方法。
我们以“率”的方式建立普查多报率指标体系。该体系包括四个指标:一是重报人次率,定义为普查目标总体内人口重复登记的人次与原始普查登记人口数的比值。二是重报案例率,定义为普查目标总体内发生重报行为的人口数与原始普查登记人口数的比值。三是误报率,定义为普查目标总体外的误报人口数与原始普查登记人口数的比值。四是总多报率,定义为普查目标总体内的重报人口数与普查目标总体外的误报人口数之和与原始普查登记人口数的比值。在这四个多报率指标中,重报人次率是核心指标。相比误报率,重报人次率更大。核心指标不是固定不变的,它取决于许多因素。
每个指标的计算范围不同。重报人次率和重报案例率的计算范围是目标总体内的普查登记,误报率的计算范围是目标总体外的普查登记,总多报率的计算范围是普查目标总体内外的普查登记。每个指标的计算方法是线性多报率指标估计量和比率多报率指标估计量。每个指标均是时点指标,而不是时期指标。这四个指标之间的数量关系是:总多报率为重报人次率和误报率之和。
(1)重报人次率。有些人在本次普查中除了应该登记的那一次之外,还多登记了几次,形成了重报人次。它虚增了普查登记人数。通过重报人次率指标,可以获悉重报的程度。如加拿大等国家在每次人口普查质量评估中,从普查登记人数中剔除估计的重报人次,以及添加估计的漏报人数,进而得到修正后的普查登记人数。
(2)重报案例率。该指标虽然不影响普查登记人数,但它提供一个重要信息,即在本次普查中总共有多少人重复登记过。通过普查表,可以获悉重报者的年龄、性别、文化程度、户籍所在地、现住地、婚姻状况,以及重报的原因,即是否有多个住处,在各个住处都进行了普查登记,或者在居住地和工作地同时进行了普查登记,如普查期间在外流动,在流出地和流入地分别进行了普查登记。
(3)误报率。误报人数与重报人次一样,会虚增普查登记人数。不过,相比重报人次,误报人数少许多。由于这个原因,中国、乌干达、南非和加拿大等一些国家在普查多报估计中忽略误报人数,从而低估误报率和总多报率。如美国每次普查多报估计,都把误报估计纳入其中,并且将误报和重报分开列示。这么做的理由是误报与重报的来源不同:误报来源于普查目标总体外,而重报来源于目标总体内;除了来源不同外,误报与重报的发生机制也不同:误报是普查员错误登记了不应该登记的人,而重报是多登记了应该登记的人。
(4)总多报率。这个指标是重报人次率与误报率的总和。美国、瑞士等国计算这个指标。加拿大和中国分别在2016年和2010年计算重报人次率,把重报人次率当作总多报率。
2.构造普查多报率指标估计量
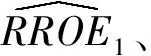
在分层二重抽样中,用表示第一重样本抽样层的总层数,为任意层,为层的普查小区总数,为从层抽取的样本普查小区总数。用表示从层抽取的样本普查小区进一步分层得到的总层数,为层的普查小区集合,为层的样本普查小区集合,为层的普查小区总数,为层的样本普查小区总数。用表示示性函数,如果第一重样本普查小区属于层,那么=1,否则=0。用表示另外一个示性函数。如果第一重样本普查小区进入,那么=1,否则=0。为进入第二重样本的样本普查小区的抽样权数。
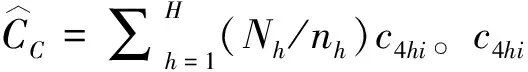
辅助变量是抽样调查中需要用到的一个变量。在抽样调查中,变量按具体作用可分为主变量和辅助变量两种。辅助变量指的是和主变量具有统计相关或相依关系的变量,可以是已知数,也可以是估计值。在能够获得这种辅助变量资料的条件下,如果能够把它利用起来,往往可以提高估计值的抽样估计精度。辅助变量的作用比较多。例如,用它来分层,提高样本对总体的代表性,用它来构造比率估计量,用它来构造回归估计量,用它来做不等概率抽样,等等。其中,前四个估计量的计算公式如下:
比率重报人次率估计量:

(1)
比率重报案例率估计量:
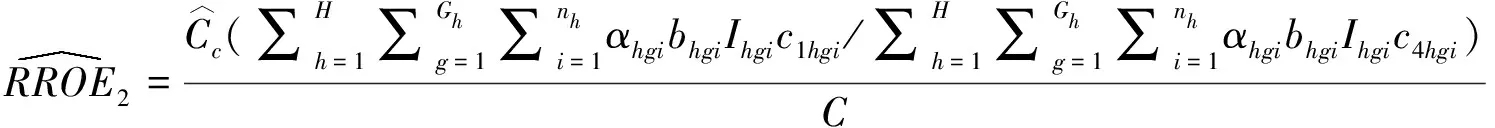
(2)
比率误报率估计量:

(3)
比率总多报率估计量:

(4)
在将式(1)—式(3)代入式(4)后,式(1)—式(4)有两个共同特征:第一,等号右边的每一项都是估计量,其中比率中的分子或分母均是较为复杂的线性估计量,各自有2个示性函数、1个抽样权数及样本普查小区的多报人口数。第二,各个多报率估计量采用的辅助变量都是总体的普查项目登记完整人数的估计值。
后四个估计量的计算公式如下:
线性重报人次率估计量:
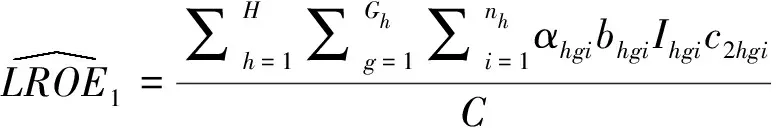
(5)
线性重报案例率估计量:

(6)
线性误报率估计量:

(7)
线性总多报率估计量:

(8)
式(1)—式(8)中的为第二重样本普查小区的抽样权数。如果第一重和第二重抽样均采取简单随机抽样,那么=()()。
3.普查多报率估计量的方差估计
相比式(1)—式(4),式(5)—式(8)形式上相对简单一些。中国、南非和乌干达等发展中国家采用线性多报率估计量提供多报率估计值。如果将式(5)—式(8)中的分层二重抽样换成简单随机抽样或分层抽样,其抽样方差可以采用精确抽样方差公式计算。在式(5)—式(8)实际上采取分层二重抽样(两次分层变量不同)的情况下,其抽样方差无精确公式计算。抽样理论指出,虽然估计量简单,例如,简单随机抽样下的均值或总体总值估计量,但如果抽样方式复杂,即抽取的是复杂样本,那么基于复杂样本的简单估计量也变得相应复杂,其抽样方差也只能近似估计。由于式(1)—式(8)具有类似性,为节省篇幅,只给出式(1)的分层刀切抽样方差估计量公式。


(9)

(10)
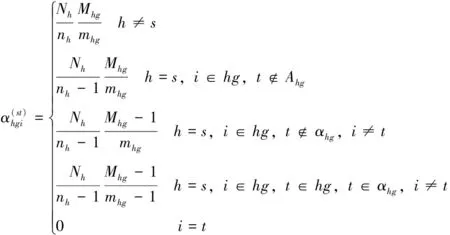
(11)
4.比率多报率估计量偏差及均方误差估计
式(1)的偏差计算公式为:

(12)


(13)
5.样本的抽取及样本多报人口的识别与计数
(1)抽取样本的方法。本文采取分层二重抽样抽取普查小区样本。在抽取第一重样本前,对研究总体的普查小区按照其所属的社区和行政村分层,在社区层和行政村层,分别独立抽取第一重样本。对从社区层和行政村层抽取的第一重样本,按照调查难度再分层,在每个新层,仍然以普查小区为抽样单位抽取第二重样本。在普查多报估计中采取分层二重抽样,基于两个理由:一是确定第二重抽样的分层变量;二是压缩第一重样本,节约成本和调查时间。
(2)样本小区普查多报人口的识别与计数。这包括三方面内容:一是普查目标总体外误报人口的识别。二是目标总体内重报人口的识别。三是目标总体内重报人口的计数。
首先来看目标总体外误报人口的识别。样本普查小区的普查表可能填写普查标准时点前死亡和之后出生的人口,或者登记暂时停留在中国境内的外国人。这类人口是误报人口。如果普查表设计了项目“出生或死亡的年月日时点”,而普查表又登记了标准时点前死亡和之后出生的人口,就很容易识别误报人口。然而在实际中,几乎所有国家的普查表都未设置项目“出生或死亡的年月日时点”,这就难以判断普查表是否填写了误报人口。为判断普查表是否登记了误报人口,可以考虑比较同一样本普查小区的普查表与出生医学证明登记册和死亡医学证明登记册。这两个登记册清晰地记录了每个人具体的出生及死亡时间。如果出生医学证明登记册显示某人在本次普查标准时点之后出生,而普查表又登记了他,就将其作为误报人口。同样,如果死亡医学证明登记册显示某人在本次普查标准时点之前死亡,而普查表又登记了他,也将其作为误报人口。由于误报人口较少,使用出生医学证明登记册和死亡医学证明登记册判断误报人口工作量并不大。当然,获得这两个登记册需要当地卫生健康委员会的配合与支持。另外,要从出生医学证明登记册和死亡医学证明登记册分离出本样本普查小区的出生和死亡人口。为便于进行第七次全国人口普查及其质量评估抽样调查,中国国家统计局从国家卫生健康委员会取得了全国各个省(自治区、直辖市)的出生和死亡医学证明登记册的使用权。
再来看目标总体内重报人口的识别。现代社会一些人有多个住处,流动性大,在普查期间也是如此。这使得同一人可能在多个地方接受普查登记。也有些人替代别人填写普查表,导致别人在普查中登记两次或两次以上。为识别样本小区的重报人口,可采取以下五种方法:一是在全国人口普查微观数据库寻找,看能否找到与样本普查小区同样的人,以及有多少个与其相同的人。这种方法的优势能查找到所有重报人口,缺陷是工作量很大,只有政府统计部门才有能力这么做。美国和加拿大在每次重报估计中都是在全国范围查找重报人口。中国尚未在全国范围识别重报人口。二是在每个样本小区及其周围区域识别,这可能发现一定数量的重报人口,毕竟在全国各个地方有住处的人不多。三是在样本小区内识别,这是目前许多国家采用的方法。这种方法优势是便于找到重报人口和构造重报估计量,缺陷是识别到的重报人口数目有限。四是在质量评估抽样调查表设计项目“您在普查中登记的次数”及“您在普查中登记的地点”。如果答复一次以上,就是重报者。这种方法快速便利。如果答复者提供真实答复,并且在答复之前,询问其朋友及家人是否在普查中登记过他,是能够获得重报的准确次数的。五是比较同一样本小区的行政记录人口名单与普查人口名单。人口行政记录在识别难以发现的重报人口方面有独到作用。例如,某人有两个名字,一个是现在的名字,另外一个是曾用名。他在一个地方的普查表中填写的是现在的名字,在另外一个地方的普查表中填写的是曾用名。该人的个人档案填写了这两个名字。如果只是通过查询普查表,就很可能把这两个名字当作不同的人,其实是同一人,其中一个名字是另外一个名字的重复,但如果比较普查表和行政记录,就能判断这两人是同一人,在普查中登记了两次,其中一次是重复登记,另外一次是应该登记的。
最后来看目标总体内重报人口的计数。必须制定出一个科学、明晰的对普查重报的计数规则,否则所进行的计数很可能会发生重复或遗漏。这是一项困难的工作。对这项工作,拟从全面调查的情景入手来厘清思考路径。假定人口普查的质量评估抽样调查是对全国所有普查小区的全面登记。为了观察重报现象,需要对普查登记中属于目标总体的每一个人在全国范围内进行查重。经过这项工作,可以一个一个地罗列出全国所有的重报案例。假定其中一个案例是这样的:一个属于目标总体的人,他分别在全国的四个普查小区进行了普查登记。无疑,在这四个登记中,必须要选定其中的一个登记为“有效登记”,即用这个登记来参加全国人数的计数;而另外的三个登记则是“无效登记”,属于普查重报人数。那么,应该把哪一个登记选为有效登记呢?假若这个人进行登记的四个小区中,有一个是他的常住地,即按照人口普查的规定,他本来就应在这个小区进行人口普查登记,那么就把他在这个小区的登记选定为有效登记;假若这个人进行登记的四个小区,全都不是他的常住地,那么就选择这四个小区中他居住时间最长的那个小区的登记为有效登记。于是,这个人在选定为有效登记的那个小区,应该向质量评估抽样调查员报告:“我做了三个无效登记”;而在该人进行无效登记的那三个小区,则对该人的无效登记不予理会(对这三个登记视而不见)。进行抽样调查的时候,如果这四个小区进入样本,就这样计数:在该人进行有效登记的小区,按该人的报告,记重复登记人数为3,与此同时,记重复登记案例数为1;在该人进行无效登记的小区,不进行有关该人的任何计数。显然,如果该人进行有效登记的小区未进入样本,则该重复登记案例在样本中也就看不到了,即便是该人进行无效登记的小区进入样本,也仍是如此。依照这样的思路,规定普查重报的数据采集途径和计数规则就不困难了。
四、实证分析
1.样本及样本数据
实证对象为一个行政区。实证目标为估计该行政区2010年11月1日零时的重报人次率、重报案例率、误报率和总多报率。实证数据来源于该行政区的人口普查办公室,以及对其部分普查小区的再调查。为便于讨论问题,未考虑样本数据缺失问题。抽样方法为分层二重抽样。采用的估计量为线性多报率估计量和比率多报率估计量,以及近似计算它们方差的分层刀切抽样方差估计量。本行政区2010年普查登记人口数为560025人。使用第一重样本估计的普查项目登记完整人口数为557016人,使用第二重样本估计的普查项目登记完整人口数为559055人。
该行政区按照行政性质分为两层,即社区层和行政村层,分别用=1和=2表示。社区层共有普查小区1000个,行政村层共有普查小区1100个。从社区层和行政村层,采取简单随机抽样分别抽取10个和9个小区。按照调查难度,将第一重样本小区分为三层,即调查难度较小层、调查难度中等层及调查难度较大层,分别用符号=1,=2和=3表示。所有样本小区及其个人100%提供答复。此时,样本个人抽样权数等于样本小区的抽样权数,否则要根据调查答复率调整样本小区抽样权数,以得到样本个人抽样权数。抽样层、抽样权数及样本数据见表1和表2。其中,和分别表示层的普查小区总数及样本小区数,和分别表示层的小区数及从中抽取的第二重样本小区数,表示样本小区。表1和表2中的(2)表示第一重样本小区进入到第二重样本。为最终样本小区的抽样权数。第二重样本小区数12个,其中社区层和行政村层各6个。表2中的样本数据依据普查多报人口所在样本小区的现住地来确定的。
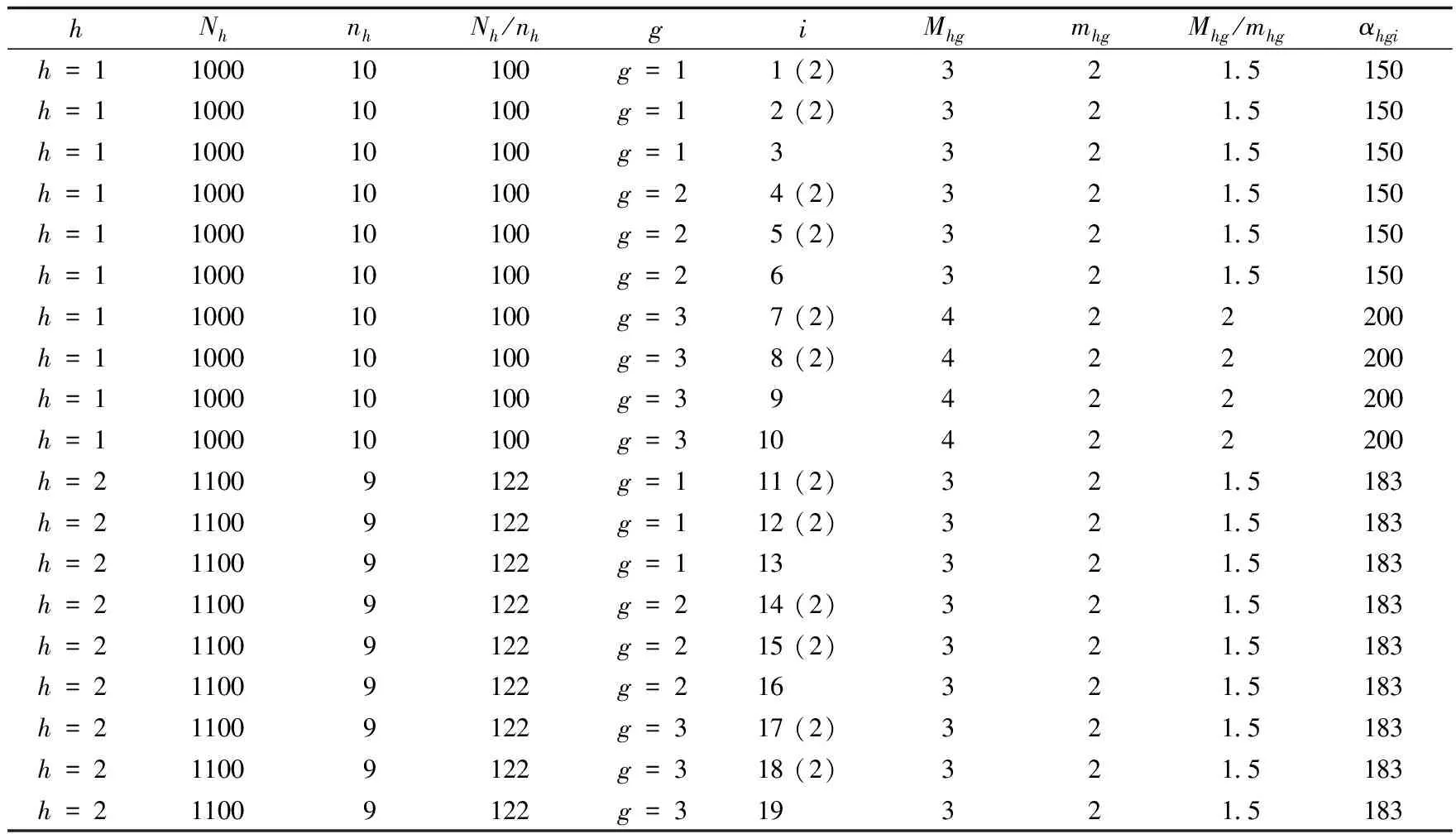
表1 抽样层及样本普查小区的抽样权数

表2 样本普查小区的未加权数据
2.普查多报率估计值
依据表1和表2数据,使用式(1)—式(8)得到重报人次率、重报案例率、误报率和总多报率,见表3。
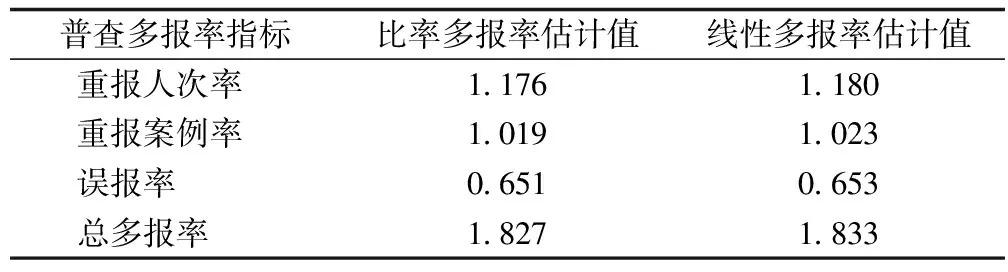
表3 普查多报率估计值 %
从表3可以看出如下两点重要信息。
第一,线性多报率估计量与比率多报率估计量计算的重报人次率、重报案例率、误报率和总多报率差异小。这表明它们都适合于普查多报率估计,估计结果可信度较高。这一方面表明分层二重抽样技术对普查多报率估计有比较好的适应性,另一方面也说明虽然线性多报率估计量未利用辅助变量,在抽样估计精度上有所欠缺,但仍然可以应用于普查多报率估计。这也是许多国家一直使用线性多报率估计量的原因,也是本文研究线性多报率估计量的重要考量。对许多国家的政府统计部门来说,它们更关注的是估计值,而不是估计值的抽样方差。一些国家在发布人口普查多报率、漏报率和净覆盖误差率时,往往并不提供估计值的抽样标准误差。中国2020年在发布净漏报率为0.05%时,也并未提供它的抽样标准误差(即抽样方差的平方根)。
第二,①从重报人次率来看,使用比率多报率估计量估计的结果是1.176%,表明100人中有1.176个人是重报登记,是不应该在普查中登记的,虚增普查登记人口数1.176人;而使用线性多报率估计量估计的结果是1.180%,表明本次普查每100人中就有1.180个人是不应该在普查中登记的,使普查登记人口数虚增1.180人。②从重报案例率来看,采用比率多报率估计量估计的结果是1.019%,这意味着每100人中有1.019人在本次普查中发生了重复登记。虽然重报案例人口数不影响普查登记人口数,但计算这个指标还是很有实际意义的,其可以发现重报者的特征及发生重报行为者的广度,即有多少人在本次普查中登记一次以上。③从误报率来看,使用比率多报率估计量估计的结果是0.651%,表明每100人中有0.651人是普查目标总体外的人,例如普查标准时间点前死亡者或之后出生的婴儿,虚增普查登记人口数0.651人。忽视误报人口,不只是掩盖了误报人口的存在,而且虚减总多报率,这不利于下次普查操作方案的改进及普查登记数据质量的提高。④从总多报率来看,使用比率多报率估计量估计的结果是1.827%,它是重报人次率1.176%和误报率0.651%的总和,表明每100人中有1.827人是不应该在本次普查中登记的,虚增普查登记人口数1.827人。
3.普查多报率估计值的抽样标准误差、偏差及均方误差平方根
利用表1—表3数据,使用式(9)—式(13),得到每个多报率估计值的抽样标准误差、偏差及均方误差平方根,见表4。表4传递出如下五点信息。

表4 普查多报率估计值的抽样标准误差、偏差及均方误差平方根 %
其一,使用抽样调查方法估计普查多报率,不只是要计算每个多报率估计值的抽样方差,还要计算其偏差,抽样方差与偏差的平方之和是均方误差。为了说明估计值的抽样估计精度,需要使用抽样标准误差、偏差及均方误差平方根。线性多报率估计量为无偏估计量,其均值与真值相等,偏差为零。比率多报率估计量为有偏估计量,需要计算其偏差。
其二,偏差所要传递的信息是估计量系统性地低估或高估实际值。对重报人次率而言,0.0085%表明采用比率多报率估计量估计的结果1.169%系统性地高估总体的重报人次率为0.0085%。
其三,除误报率估计值外,使用比率多报率估计量计算的其他多报率估计值的均方误差平方根,均小于采用线性多报率估计量估计的其他多报率估计值的均方误差平方根。例如,比率重报人次率的均方误差平方根0.2792%小于其线性多报率的均方误差平方根0.2837%。这表明,比率多报率估计量在多目标(估计四个多报率)抽样调查中拥有更高的抽样估计精度。均方误差平方根和抽样标准误差是衡量样本代表性或估计量优劣的重要标准。多目标抽样调查不要求估计量对每个目标指标的抽样方差都小,只要在主要目标指标(重报人次率)或绝大部分估计目标指标上抽样标准误差或均方误差平方根较小即可。
其四,在采用比率多报率估计量还是线性多报率估计量这个问题上,要根据各国人口普查质量评估的能力,对普查多报率估计精度的要求,进行抽样估计精度比较的需要综合权衡。
其五,相较于抽样标准误差,偏差小许多。这就是为什么各国政府统计部门在人口普查质量评估中只计算抽样标准误差,而不计算偏差的原因。美国普查局使用双系统估计量估计总体实际人口数及净覆盖误差,从未计算过偏差及均方误差平方根,只计算抽样标准误差。
五、结论与建议
通过前面的理论研究和实证研究,得出一些重要结论,并对我国政府统计部门在人口普查多报估计中提出若干建议。
第一,普查目标总体是判断人口普查多报的重要标准。对一个普查登记,需要关注的是,这个登记是否属于目标总体,而不是这个登记的地点是否正确。采用登记者是否属于目标总体这一标准,可避免普查多报误判,也体现了普查多报的本质特征。如果在普查中登记一次以上,就把其中的一次当作有效登记,其他几次作为无效登记。有效登记是指发生在应该登记地点上的普查登记。如果能够确切知道一个人的应该登记地点,就把发生在这个地点上的有效登记计作重报案例人数,其他地点的无效登记也计作这个地点的重报人数,其他地点不做任何统计。如果无法获悉一个人的确切应该登记地点,就采取简单平均法,在其登记的各个地点平均计算重报案例人数和重报人次。建议国家统计局深入研究普查多报人口的认定问题,将是否属于普查目标总体作为判断多报人口的核心标准,合理确定普查多报人口的计数地点,避免虚增普查多报人数。
第二,不能忽视普查目标总体外误报人口的存在,在普查多报估计中应该单独估计。即使误报人员数为零,也要在研究报告中列示,并且说明为什么为零。事实上,这个数不可能为零。为估计误报人数,需要在普查表设置“出生或死亡年月日时点”,使用出生或死亡医学证明判断普查标准时点前后出生或死亡的人是否属于误报人口。我国在历次人口普查质量评估中,只估计重报,忽视误报,从而低估总体普查多报人数或多报率。建议国家统计局既要估计重报人数,还要估计误报人数。
第三,在重报估计中,要设置重报人次率指标和重报案例率指标。普查重报指标考察目标总体内人员的重报。这一规定为重报指标制定了统计标准,规范了这一指标的口径范围,杜绝了把不属于目标总体人员的多次登记混入普查重报人次的歧义计数。重报案例率指标的设置,增加了对普查重报现象的考查视角。目前各国普遍使用的重报人次率考察重报行为的发生频次,而增加的重报案例率则是考察重报行为人的广度。考察后者,有助于发现重报者的特征,为下次普查避免重报提供依据。建议国家统计局改变一直以来只估计重报人次率,而忽视重报案例率估计的做法,将我国重报估计水平提升到一个新的高度。
猜你喜欢
中学生数理化·八年级物理人教版(2021年11期)2021-12-06 06:44:34
煤气与热力(2021年6期)2021-07-28 07:21:40
作文大王·低年级(2021年5期)2021-05-13 08:21:47
现代营销·学苑版(2016年12期)2017-01-23 13:00:14
中国质量监管(2016年10期)2016-07-10 10:24:23
乐活老年(2016年10期)2016-02-28 09:30:39
电测与仪表(2015年6期)2015-04-09 12:00:50
数学物理学报(2014年3期)2014-03-11 18:34:27
中共党史研究(2013年9期)2013-04-27 14:32:16
统计与决策(2012年4期)2012-07-24 09:33:04
