
基于 FinBERT-CNN 的股吧评论情感分析方法
2022-06-01 02:31姜青山蒋泓毅胡金帅
集成技术 2022年1期
刘 薇 姜青山 蒋泓毅 胡金帅 曲 强
1(中国科学院深圳先进技术研究院 深圳 518055)2(中国科学院大学深圳先进技术学院 深圳 518055)
3(厦门大学 厦门 361005)
1 引 言
我国的股票交易市场整体呈现出非有效性,舆论和政策对股票市场有较大影响[1]。根据行为金融学理论,投资者并不都是理性投资者,在投资的过程中会出现受他人情绪影响而改变投资倾向的现象[2]。随着网络的普及,越来越多的网民在以“东方财富网-股吧”(https://guba.eastmoney.com)为代表的金融网站上进行信息交流和传播。这些股票评论在传递大量市场信息的同时,还影响投资者的交易决策。因此,通过研究金融平台上的股票相关评论,分析投资者的情感倾向,对了解股票市场变化有重要意义。
情感分析是指利用自然语言处理和文本挖掘技术,对带有情感色彩的主观性文本进行分析、处理和抽取的过程[3]。国内外学者在股票评论情感分析领域的研究方法分为 3 种:基于词典的方法[4-5]、基于机器学习的方法[6-9]和基于深度学习的方法[10-14]。 基于词典的方法是指以情感词典作为情感倾向判断依据,该方法虽然对情感倾向判断简单,但是对词典依赖较高,且目前缺乏公开的股票情感词典。基于机器学习的方法是指利用评论信息特征进行情感分析,但是分析效果受评论特征的构建和训练语料影响较大。目前,基于深度学习的方法在计算机视觉、自然语言处理等领域应用广泛[15],然而,对于金融评论情感分析,仍缺乏优质的金融评论标注数据集用于模型的训练。
本文通过研究股吧评论情感分析方法,构建更具准确性的情感分类模型,并对股票市场与股吧评论情感之间的关联性进行验证。具体地,针对真实的股吧评论数据,首先通过预训练模型FinBERT 学习股吧评论的语义特征,然后采用卷积神经网络提取股吧评论的局部特征,最后利用“上证 50”成分股数据集验证股票市场与股票评论情感之间存在关联。
2 股票评论情感分析方法的研究现状
2.1 基于词典的股票评论情感分析方法
基于词典的方法的核心在于情感词典的构建,通过将评论数据与情感词典的正负情绪词进行匹配,得到情感倾向分类结果。Maqsood 等[4]利用英文情感词典 SentiWordNet,将从 Twitter 股票相关评论数据中提取的 5 000 余个英文单词分为积极、中性和消极 3 类情感词,从而实现对英文股票评论进行情感分析。陈雷[5]提出一种基于情感词典的股票评论情感分析方法,首先通过对几种公开的情感词典合并去重后得到基础词典,然后引入股票情感词典对基础词典进行扩充。但是,目前在股票评论分析领域,缺少公开的股票情感词典,且该词典构建难度大、成本高,并且模型受情感词典的影响较大。
2.2 基于机器学习的股票评论情感分析方法
基于机器学习的方法,通过选择特征项、构造特征对评论数据进行特征提取,实现利用机器学习模型进行情感分类。Alkubaisi 等[6]利用一种混合朴素贝叶斯分类器的方法对 Twitter 股票评论数据集进行情感分析,并取得了较高的情感分类准确率。Yazdani 等[7]讨论了分别利用二进制编码、词频和词频-逆文本频率指数对金融新闻文章进行特征提取,并利用具有不同核函数的支持向量机作为分类器对金融文本进行情绪分类,实验结果表明,特征选择和特征加权在情感分类中起到重要作用。Salles 等[8]针对股票评论数据具有高维噪声的特点,提出延迟随机森林分类模型,通过最近邻样本投影得到与待分类样本相似的特征,具有较高的分类准确率。张对[9]通过对新浪股吧中的股评数据进行分词和过滤停用词,将剩下的名词、动词和副词等作为特征项进行词频统计,然后利用 SVM 分类器对股评数据进行情感分类。但是,基于机器学习的情感分析方法对特征项选取和特征构建的质量依赖较高,且缺少优质的股票评论标注数据集用于训练。
2.3 基于深度学习的股票评论情感分析方法
基于深度学习的方法,首先把输入映射到不同的特征空间来进行特征提取,然后持续地修正神经网络权重以学习评论特征。Jiang 等[10]将基于门控和关注机制的双向长短期记忆神经网络模型用于处理股票新闻和微博的情感分析任务,首先利用门控机制整合字符级别和单词级别的嵌入,然后利用双向长短期记忆神经网络组件将目标相关信息嵌入语句,最后利用线性回归层进行情感分类。Rao 等[11]提出将基于两个隐层的长短期记忆网络模型用于股票评论情感分析,其中,第一层用于学习句子语义,第二层用于学习句子关系。Sohangir 等[12]将长短期记忆网络和卷积神经网络这两个模型进行对比,结果表明,卷积神经网络在股票评论数据集上表现更好。Akhtar 等[13]利用卷积神经网络和词向量模型对股评数据进行情感分析——利用词向量模型将股评数据转化为向量,并通过卷积神经网络得到分析结果。直接采用卷积神经网络对股评数据进行情感分析能够实现自动提取特征,修正学习输出,但缺少优质的股票评论标注数据集用于卷积神经网络的训练,且卷积神经网络无法处理股评数据中的专业词汇。
Liu 等[14]提出基于 BERT 的预训练模型FinBERT,并采用一个大型通用的金融语料集对其进行训练。FinBERT 首先在 TRC2-financial 语料库上训练语言模型,然后利用其权重初始化金融评论情感分析模型。FinBERT 由编码器和解码器堆叠形成的 Transformer 组成,每个 Transformer利用编码器的多头自注意力机制将任意位置的词之间建立联系。FinBERT 能够解决目前金融领域缺乏优质股票评论数据集的问题,且能够解决无法处理金融专业领域词汇的问题,但是使用FinBERT 仅能提取到股票评论的语义特征,而缺少股票评论的局部特征和空间特征。
针对现有模型存在缺少优质股票评论标注数据集用于模型训练,无法处理专业词汇,特征提取过于单一等问题,本文提出一种基于 FinBERTCNN 的股吧评论情感分析方法,利用 FinBERT预训练模型提取股吧评论语义特征和卷积神经网络模型来捕捉评论的局部特征和空间特征。
3 基于 FinBERT-CNN 的股吧评论情感分析方法
基于 FinBERT-CNN 的股吧评论情感分析方法将爬虫采集的股吧评论数据预处理后,分别利用 FinBERT 预训练模型提取语义特征,卷积神经网络提取局部特征和空间特征,最后使用全连接层输出情感倾向分类结果。基于 FinBERT-CNN的股吧评论情感分析方法主要包括数据预处理和基于 FinBERT-CNN 的股吧评论情感分析模型 2个部分,流程如图 1 所示。
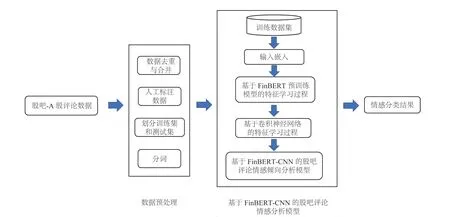
图1 基于 FinBERT-CNN 的股吧评论情感分析方法Fig. 1 Sentiment method for Guba reviews based on FinBERT-CNN
3.1 数据预处理
利用 Scrapy 爬虫框架对“东方财富网-股吧”上所有 A 股股票的评论数据进行爬取,直接获取的股吧评论存在大量无用信息和冗余,需对其进行预处理。数据预处理包含以下 4 个步骤:
(1)数据去重与合并。由于增量式爬虫会引起数据重复问题,所以在情感分析之前需进行评论去重。若评论正文和标题都没有内容则直接删除;若标题或正文没有内容,则合并标题与正文;
(2)人工标注数据。在股吧评论数据集中随机选取 15 747 条股票评论并由金融专业人士对其标注情绪标签:“看涨”记作 1、“看跌”记作-1,中性记作 0。看涨是指投资者表达价格将上涨的情绪,一般包括对当前股市积极的评价和对未来股市走势上涨的判断。看跌是指投资者表达价格将下跌的情绪,一般包括对当前股市的消极评价和对未来走势下跌的判断。标注数据示例如表 1 所示;

表1 标注数据示例Table 1 Examples of data annotation
(3)划分训练集和测试集。将步骤(2)获得的标注数据按照 7:3 的比例划分训练集和测试集;
(4)分词。为了保持中文评论信息的完整性,对于通过步骤(3)得到的训练数据以字作为划分单位进行分词。首先将股吧评论数据转为Unicode 格式编码,然后将其与 Unicode 特殊字符进行匹配,去除评论数据中的不合法字符和多余空格,最后判断数据中的每个字符是否为中文字符,若为中文字符就在字符后添加空格,否则就根据标点和空格对其进行分词。
从“东方财富网-股吧”上提取的 5 亿多条数据经预处理后,用于模型验证的数据共 15 747条,用于基于股吧评论情感的股票市场关联分析的数据共 2 027 077 条。
3.2 基于 FinBERT-CNN 的股吧评论情感分析模型
基于 FinBERT-CNN 的股吧评论情感分析模型结构如图 2 所示,其中输入为预处理后的股吧评论数据,其包含数据嵌入层、FinBERT 预训练模型、特征整合、卷积层、池化层、全连接层、dropout 层和 Softmax 层,流程分为以下 3个步骤:
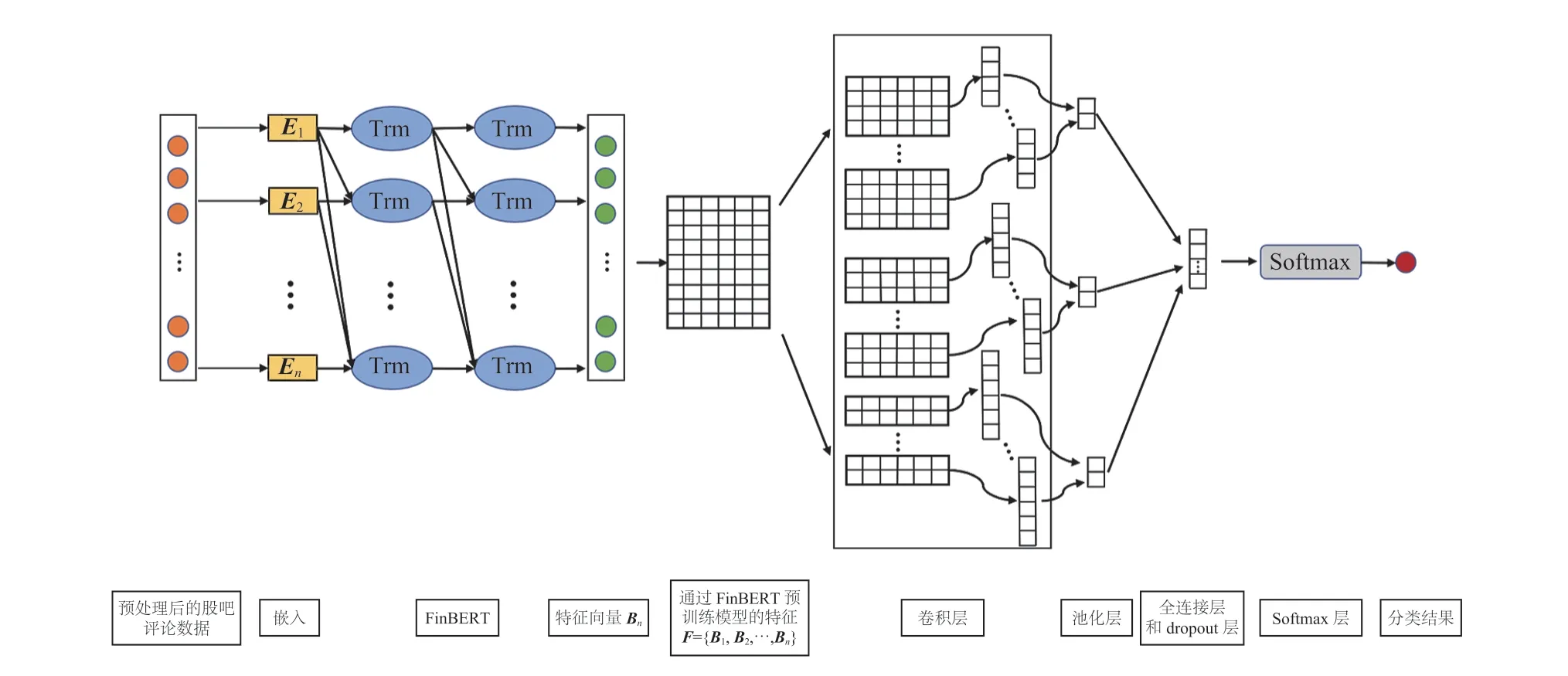
图2 基于 FinBERT-CNN 的股吧评论情感分析模型Fig. 2 FinBERT-CNN-based sentiment analysis model for Guba data
(1)基于 FinBERT 预训练模型的特征学习过程:将预处理后的股吧评论数据经嵌入层输入FinBERT 预训练模型,输出特征向量B,经过整合后得到语义特征F;
(2)基于卷积神经网络的特征学习过程:对步骤(1)中得到的语义特征F进行局部特征提取,通过卷积层、池化层、全连接层和 dropout层输出特征向量H;
(3)情感倾向分析过程:对步骤(2)中得到的特征向量H,通过 Softmax 层得到情感倾向分类结果。
3.2.1 基于 FinBERT 预训练模型的特征学习过程
本文使用 FinBERT 预训练模型学习股吧评论数据的语义特征,其具体分为以下 3 个步骤:
(1)评论数据嵌入处理。对预处理后的股吧评论数据进行嵌入处理,即将文本数据向量化,其分为以下 3 个部分:
①token 嵌入:每条经过预处理分词后的股吧评论数据即为一条 token,将得到的 token 在词汇表中进行索引匹配得到 token 嵌入向量。在中文预训练模型 FinBERT 的词汇表中包含约 30亿条 tokens。一条经过预处理后的股吧评论数据有w个字符,检查这w个字符在词汇表中是否出现。对出现的字符进行索引匹配,得到表示该字符的向量;对于未出现的字符,则生成新的字符索引。token 嵌入将每个字符用n维的向量表示,那么评论数据经 token 嵌入转换为w×n×1的张量T。为了得到模型进行分类任务的输入表示,在 tokens 的开始([CLS])和结束([SEP])处添加特定的 tokens;
②片段嵌入:本文输入评论数据的片段嵌入对应片段嵌入表的索引为 0 的向量,将其转换为n维的向量后得到w×n×1 的张量S;
③位置嵌入:每个字符的位置信息编码都可用一个向量来表示,从而得到w×n×1 的张量P,P可表示因不同位置而带来不同语义信息的差异。
将这 3 个部分相加,得到股吧评论数据向量化表示,即:
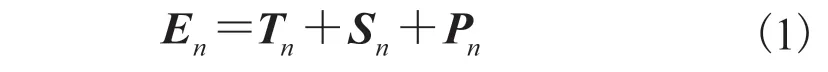
其中,En为股吧评论数据的嵌入;Tn为 token 嵌入;Sn为片段嵌入;Pn为位置嵌入。最后对股吧评论嵌入E进行维度变换,使其成为大小为ms×n×b的张量,b为一次训练选取的样本量,ms为股吧评论的最大长度。
(2)特征提取。将股吧评论数据嵌入E作为 FinBERT 预训练模型输入,并在隐藏层对其进行语义特征提取。一个隐藏层包括一层注意力层,两层线性映射层,两层正则化和 dropout层,一层非线性映射层。首先对E通过注意力层后的输出EA进行维度变换,使其与嵌入维度n一致;然后通过 dropout 层后将E和EA相加,输入正则化层得到EN并经过维度变化,使其与嵌入维度n一致;接着通过 dropout 层得到ED;最后将EN与ED相加,输入正则化层得到语义特征B。
(3)特征整合。输入股吧评论数据嵌入E经过一层隐藏层后得到股吧评论数据语义特征B,每层隐藏层的输出都作为下一层隐藏层的输入,那么 FinBERT 预训练模型中 12 层隐藏层可得到12 个输出,将其进行组合和维度变换后,通过一层池化层得到语义特征F,作为卷积神经网络的输入。
3.2.2 基于卷积神经网络的特征学习过程和情感倾向分类
本文使用的卷积神经网络分为输入特征层、卷积层、池化层、全连接层、dropout 层和Softmax 层。卷积层有 3 种大小的卷积核,每种大小的卷积核有 128 个卷积滤波器进行F的局部特征学习。由于股吧评论数据为一维数据,假设输入特征层为d×n×1 的张量,那么其卷积操作如公式(2)所示[16]:
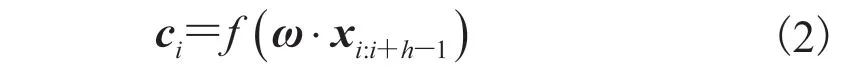
其中,ci为卷积运算的结果; 为卷积核;为第i行到第组成的滑动窗口;f为非线性函数。卷积核的宽度和语义特征B的维度一致,卷积核的高度h代表每次滑动窗口覆盖用于卷积的词数。 和维度一致,即的大小为h×n×1。经过卷积层输出的特征向量大小为
池化层采用的是最大池化方法,首先在保持特征的情况下进行参数的压缩,然后将这些特征拼接起来用向量表示,最后通过全连接层对池化层的输出进行整合。为了防止过拟合,加入dropout 层和正则化层,再通过 Softmax 分类器得到分类结果,其计算公式如公式(3)所示[16]:
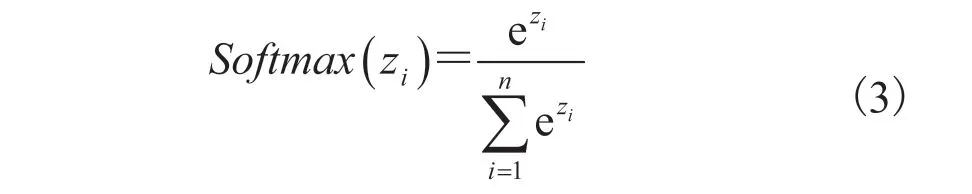
其中,Softmax为分类函数; 为第i个节点的输出值;n为输出节点的个数;e 为自然底数。损失函数采用的是交叉熵损失函数,其计算公式如公式(4)所示[16]:
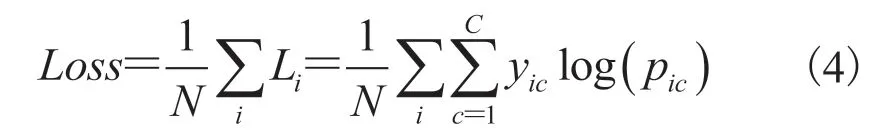
其中,Loss为损失;N为样本个数;i为第i个样本;Li为第i个样本的损失;C为类别个数;c为第c类;yic为分类准确性,若样本i的类别和样本i的真实类别相同则为 1,否则为 0;pic为样本i属于类别c的概率。
4 股吧评论情感分析结果与评估
4.1 数据集与评价指标
“东方财富网-股吧”是国内金融领域最活跃的股票讨论平台。首先从“东方财富网-股吧”的股票评论中随机选取 15 747 条评论,然后经金融专业人士对其进行标注后用于测试和训练。本文使用 4 种常用的评价指标:准确率(Accuracy,Acc)、查准率(Precision,P)、召回率(Recall,R)和 F1 值[17],其中查准率、召回率和 F1 值均为宏平均。评价指标的计算公式如公式(5)~(8)所示[18]:
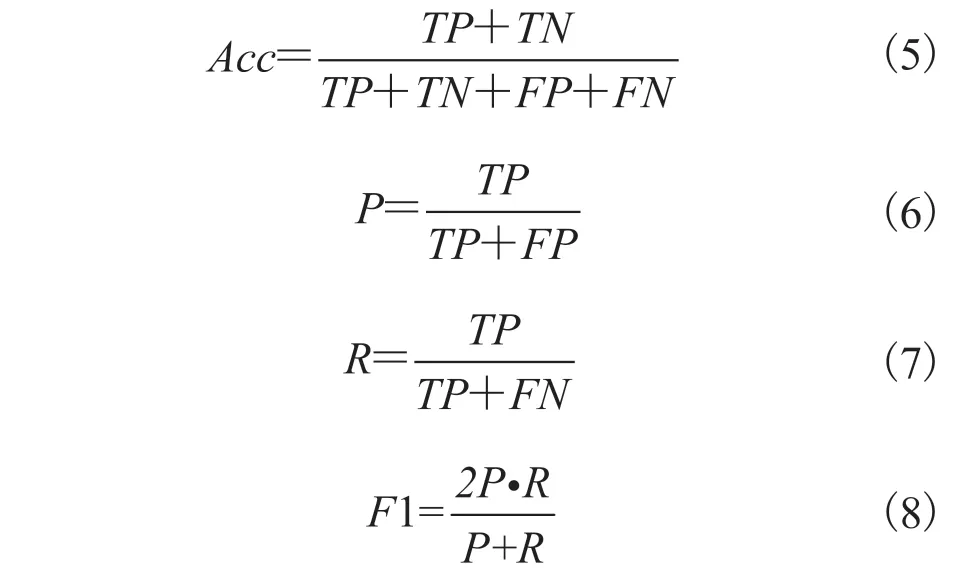
其中,Acc为准确率;P为查准率;R为召回率;F1 为 F1 值;TP为真阳性的数量;TN为真阴性的数量;FP为假阳性的数量;FN为假阴性的数量。查准率、召回率和 F1 值的宏平均计算公式如公式(9)~(11)所示[17]:
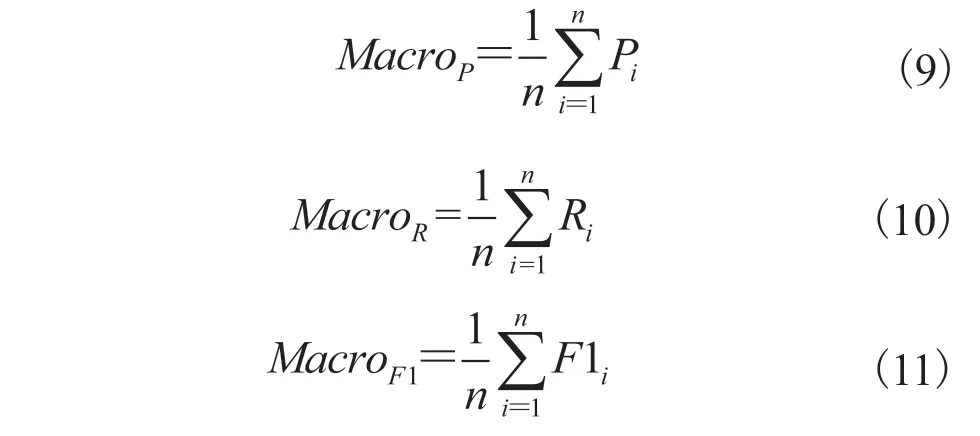
其中, 为查准率的宏平均; 为召回率的宏平均; 为 F1 值的宏平均;n为目标任务的类别数。
4.2 实验结果
本实验首先使用股吧评论标注数据集进行模型参数敏感性和有效性分析;然后将批大小、丢弃率、学习率、卷积核个数、训练次数和隐藏层个数作为变量,探究模型对其的敏感性以及其对模型的性能的影响;最后选择 5 种针对金融领域评论数据情感倾向分析的方法模型与基于 FinBERT-CNN 的股吧评论情感分析方法进行对比,包括基于词典的方法[5]、SVM[9]、TextCNN[16]、BERT[19]和 FinBERT[14]。本实验基于 FinBERT 和卷积神经网络的集成模型,模型搭建基于 TensorFlow 框架利用 Python 语言进行程序编写,程序运行环境为 Linux Ubuntu 18.04。
图 3 是在固定丢弃率为 0.5、卷积核个数为128、隐藏层层数为 128 的条件下,训练轮数和批大小对模型的损失和准确率的影响结果示意图。模型训练轮数越多,学习数据特征就会越充分,但是可能会因为过度学习训练数据特征而产生过拟合现象,训练轮数太少则可能会出现学习数据特征不充分的情况[18]。批大小最大可以选择整个数据集的大小,但是可能会导致运行内存不足等问题,反之则可能导致数据不收敛[17]。
由图 3(a)和图 3(b)可知,训练轮数越多,训练集损失越小,测试集损失越大;训练集、验证集和测试集的准确率均随着训练轮数的增加而略有提升。由图 3(c)可知,训练集损失随着批大小的增加而增大,而测试集损失在批大小为 256 的时候最小。由图 3(d)可知,批大小越小,训练集准确率越高,而测试集准确率在批大小为 64 时最高。
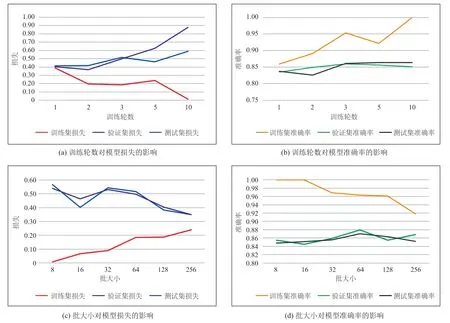
图3 训练轮数和批大小对模型的损失和准确率的影响Fig. 3 The eあects of batch size and epochs on the model loss and accuracy
表 2 为丢弃率、卷积核个数、隐藏层层数对模型的影响结果。当改变丢弃率时,固定卷积核个数为 128,隐藏层层数为 128;当改变卷积核个数时,固定丢弃率为 0.5,隐藏层层数为128;当改变隐藏层层数时,固定丢弃率为 0.5,卷积核个数为 128。从表 2 中可以看出,丢弃率为 0.5 的时候,模型的效果最好;卷积核个数为128 的时候,模型效果最好;隐藏层层数为 128的时候,模型效果最好。这 3 个参数均和模型拟合程度有关[17],由表 2 可知,当模型丢弃率为0.5、卷积核个数为 128,隐藏层层数为 128 时模型效果最好。
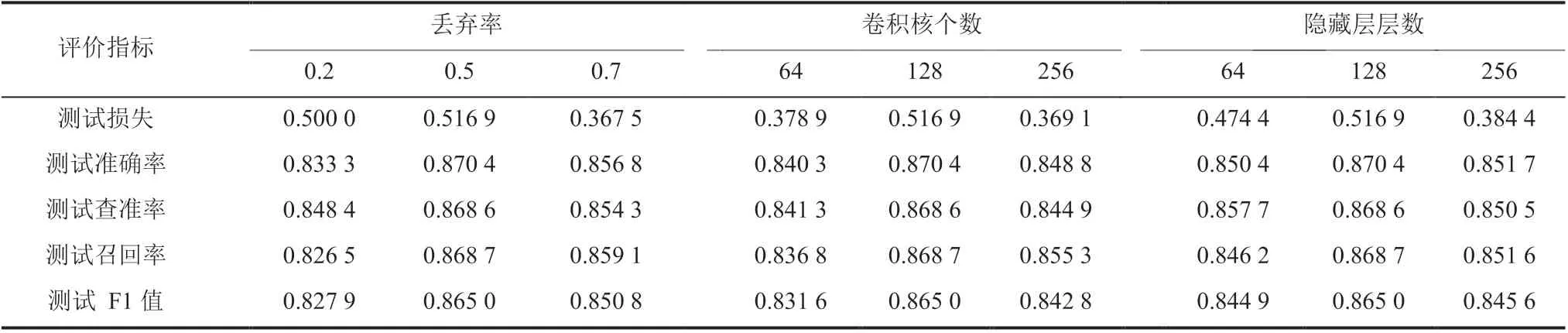
表2 丢弃率、卷积核个数和隐藏层层数对模型的影响Table 2 The influence of dropout, kernel number and hidden layer on the model
表 3 为不同情感分析方法的测试数据集结果,其中 FinBERT-CNN 方法的测试参数为:批大小为 64,丢弃率为 0.5,卷积核个数为 128,隐藏层层数为 128,训练轮数为 3 轮,卷积核的大小分别是 2、3、4。
由表 3 可知,基于词典的方法效果最差,4 个指标均不到 0.5,究其原因是其没有公开全面的高质量股票情感词典。SVM 的实验结果与基于词典的方法相比准确率提升大约 0.3,但由于其依赖特征质量,且需要已标注的数据,所以仅优于基于词典的方法。TextCNN 相较于基于词典的方法和 SVM 在 4 个评价指标上均有大幅提升,但稍逊于 BERT 和 FinBERT。FinBERT-CNN在所有的模型中表现最好,相较于基于词典的方法准确率提升大约 0.4;与 BERT 和 FinBERT 的实验结果相比,FinBERT-CNN 的效果略有提升。
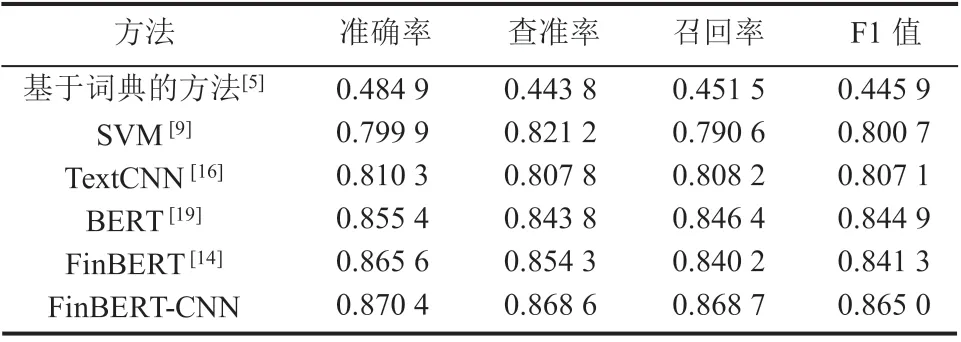
表3 不同情感分析方法的测试数据集结果Table 3 Results of different methods
5 基于股吧评论情感的股票市场波动关联分析
国内外已有大量研究[22-28]表明投资者情感对股票收益变化具有一定影响,且对股市波动具有一定的预测作用。通过对投资者评论情感的有效分析,能够更好地了解我国股票市场波动。目前,国内外针对股票评论情感和市场波动之间的相关性研究,主要基于 A 股市场,缺乏对单只股票的研究。本文以“上证 50”成分股的股吧评论情感和市场波动为研究对象,探究单只股票的评论情感与市场波动之间的关系。
5.1 基于单只股票的股吧评论情感与股票波动关联分析
第 4.2 节验证了基于 FinBERT-CNN 的股吧评论情感分析方法的有效性,利用该模型对“上证 50”成分股的评论进行投资者投资情感倾向分析,并对分析结果进行市场波动关联讨论。“上证 50”,即挑选上海证券市场最具代表性的 50只股票组成样本股,经一定规则计算后得到能反映上海证券市场的最具有市场影响力的一批龙头企业的整体状况指数[20]。本文选取 2018 年 1 月1 日~2019 年 12 月 31 日作为研究时间,针对该时间段内“上证 50”成分股的股评和股票行情数据进行关联分析。其中,股评分析包括发帖量(CA)、情绪指数(BI)和意见分歧度(DI)3 个方面;股票行情数据统计包括收盘价(CP)、前一日收盘价(PCP)、交易量(Vol)、成交总额(Am)和涨跌幅(pctChg)6 种。发帖量代表了这只股票的评论热度。情绪指数采用 Antweiler & Frank 情绪指数构建方式[21],计算公式如下:
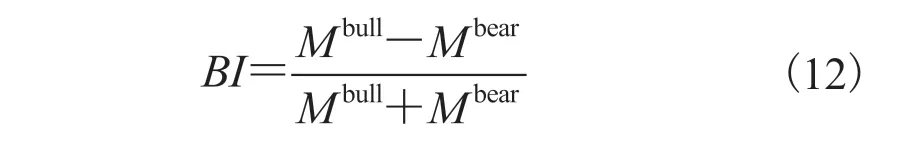
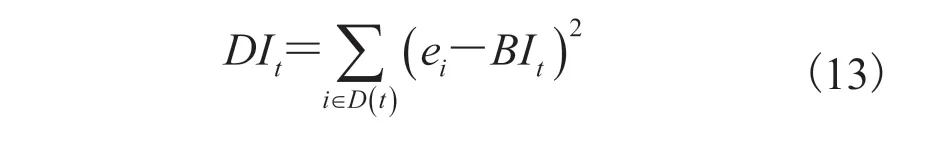
其中,DIt为t日的意见分歧度; 为交易日t的评论发表时间集合;ei为第i时间的评论的情感情绪;BIt为第t日的情绪指数;i为评论发表的时间;t为交易日。
图 4 为发帖量、情绪指数和意见分歧度与股票行情数据之间的相关性热力图。图中颜色越接近红色,表明变量间的正相关性越强,反之则表明负相关性越强。从图 4 中可以看到,每日发帖量与交易量和成交总额之间呈强正相关性,与每日涨跌幅之间存在负相关性;情绪指数与涨跌幅存在强正相关性,意见分歧度与交易量和成交总额之间存在正相关性。
以贵州茅台(600519)为例,在 2018 年 1 月 1日~2019 年 12 月 31 日期间共计发帖数为 88 542条。该时间段内贵州茅台吧的每日发帖量、情绪指数和意见分歧度统计结果如图 5 所示,由图 5(a)可知,在 2018 年 10 月 29 日和 2019 年11 月 29 日发帖量剧增,分别达到了 4 659 条和4 021 条。由图 5(b)可知,在 2018 年 8 月 11 日情绪指数达到最高,而在 2018 年 11 月 24 日投资者们的情绪最为低落。由图 5(c)可知,在2018 年 10 月 22 日投资者们意见分歧最大。
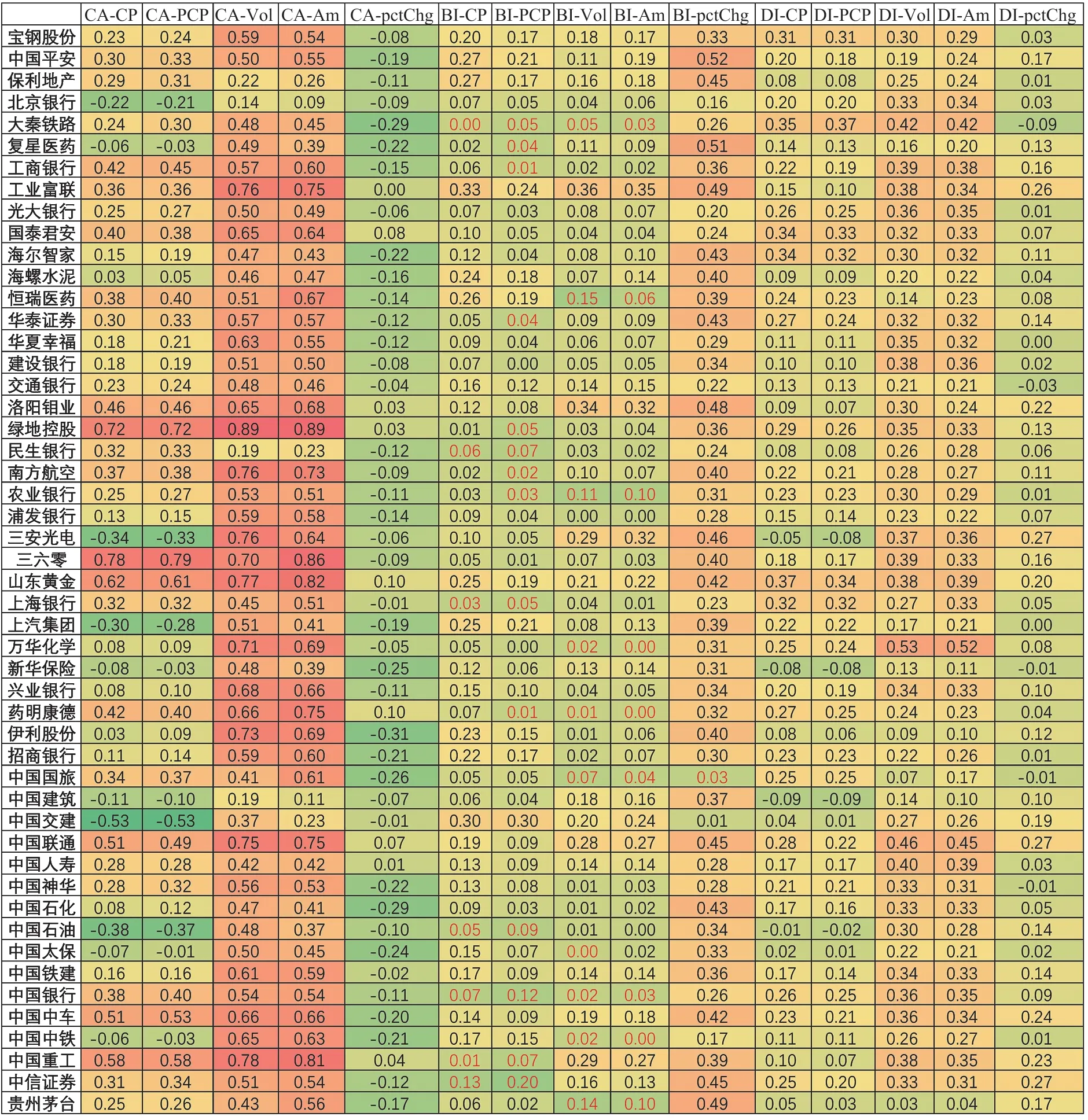
图 4 发帖量、情绪指数和意见分歧度与股票行情数据之间的相关性热力图Fig. 4 Heap map of correlations between three indexes and stock data
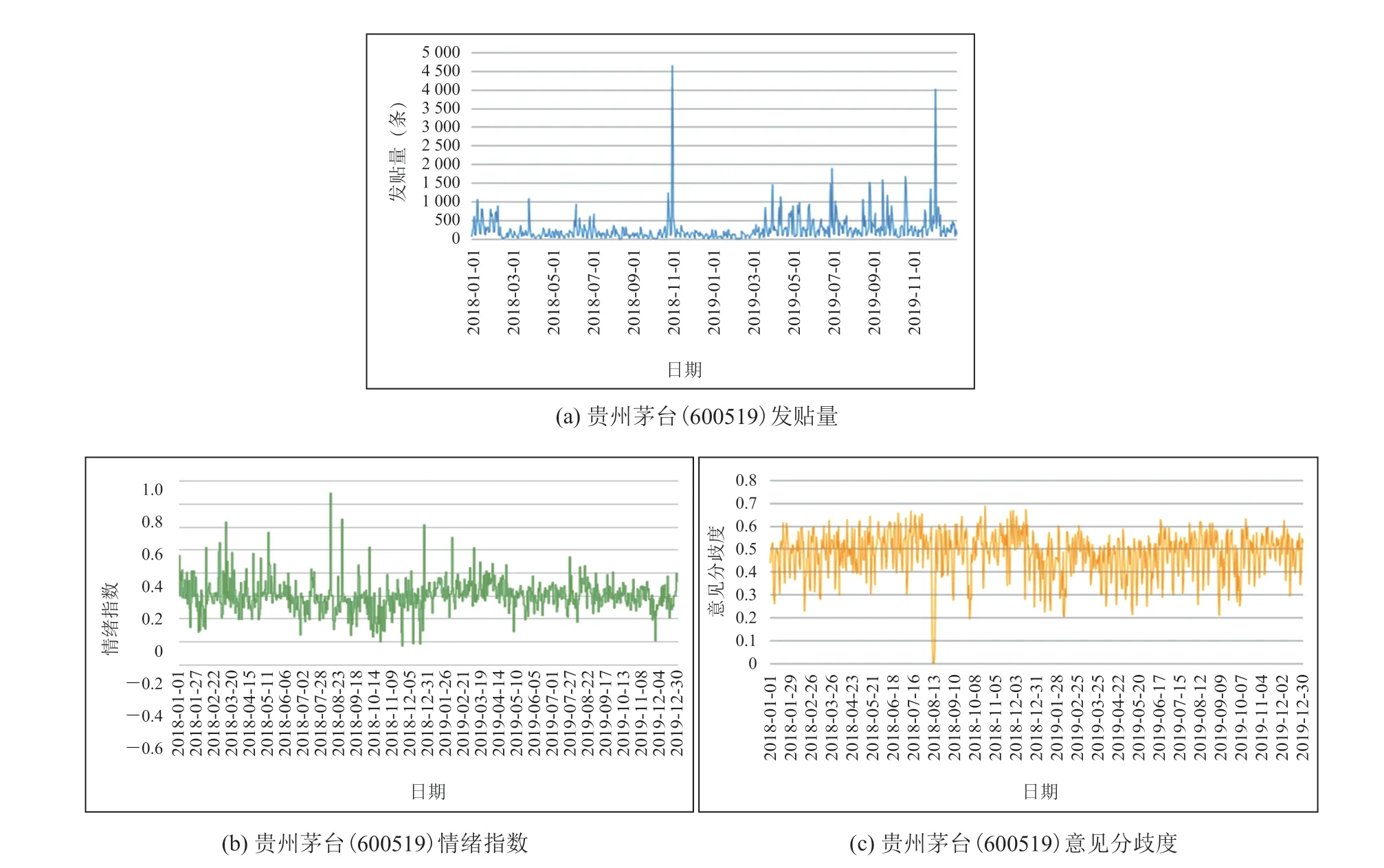
图5 贵州茅台吧的每日发帖量、情绪指数和意见分歧度Fig. 5 Daily posts, BI and DI of Guizhou Moutai
表 4 为贵州茅台吧在 2018 年 1 月 1 日~2019年 12 月 31 日期间的发帖量、情绪指数和意见分歧度与股票变动的相关系数表。由表可知,成交总额与发帖量正相关性最强,其次是情绪指数与涨跌幅,而涨跌幅与发帖量呈负相关性。
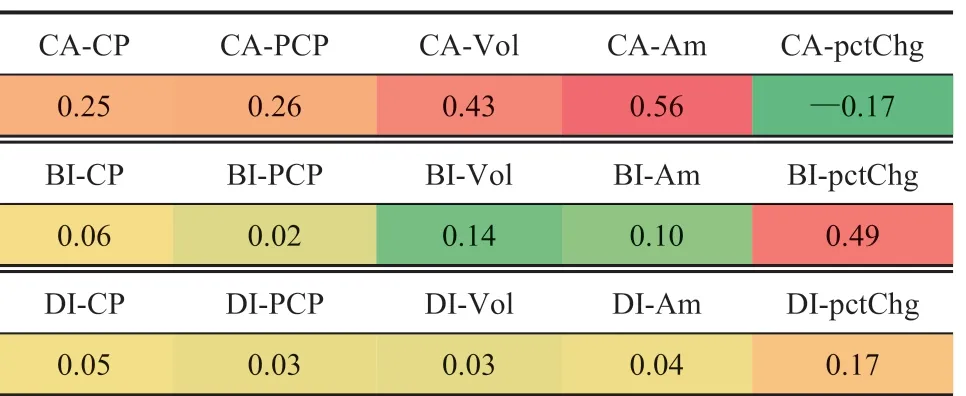
表4 贵州茅台吧的发帖量、情绪指数和意见分歧度与股票变动的相关系数表Table 4 Correlation coefficient table of correlations between three indexes of Guizhou Moutai
综上所述,股市的波动与股吧发帖量具有强相关性,其中,股票的交易量和成交总额与发帖量呈正相关,涨跌幅与发帖量呈负相关。股票每日的涨跌幅与情绪指数和意见分歧度具有比较明显的相关性,而收盘价、前一日的收盘价、成交量和成交总额与情绪指数和意见分歧度的相关性并不大。
5.2 讨论与分析
实验结果表明,本文提出的基于 FinBERTCNN 股吧评论情感分析方法能有效解决现有模型缺少优质的评论标注数据集用于训练、难以处理专业词汇和提取特征不全面的问题。与现有情感分析方法相比,该模型能够自动学习股吧评论中的语义特征和局部特征,处理股票评论中的专业词汇,全面地学习股票评论特征,从而提高对股吧评论情感分类的有效性。目前,针对投资者情感与股市波动关系的研究大多基于 A 股市场,本文则以“上证 50”成分股评论情感作为研究对象,证明了单只股票投资者情感与股市波动也存在相关性,为研究投资者情感对股票市场预测、股票交易策略的构建等任务具有重要意义的结论提供了佐证。
6 结 论
本文针对现有模型存在缺乏优质的股票评论标注数据集用于模型训练,无法处理专业词汇,特征提取过于单一等问题,提出一种基于FinBERT-CNN 的情感分析方法对股吧评论进行投资者情感分析。系统首先利用预训练模型FinBERT 对评论提取语义特征,然后利用卷积神经网络提取局部特征,最后通过 Softmax 分类器输出情感倾向。实验结果表明,基于 FinBERTCNN 的情感分析方法的准确率达到了 0.870 4,均优于现有模型。此外,本文还对单只股票评论情感与市场波动的相关性进行了验证。在下一步的研究中,将结合股票评论数据情感分析结果进行股票交易方法的构建,并提出高效的股票交易策略方法。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
股市动态分析(2016年23期)2016-12-27
股市动态分析(2016年22期)2016-12-27
股市动态分析(2016年7期)2016-09-29
股市动态分析(2016年4期)2016-09-29
