
基于改进的CNN喷码式不规则字符识别与提取方法
2022-05-31 09:02王太学苗相彬李柏林郭彩玲
唐山学院学报 2022年3期
王太学,苗相彬,李柏林,郭彩玲
(1.西南交通大学 唐山研究生院,河北 唐山 063000; 2.西南交通大学 机械工程学院,成都 610031; 3.唐山学院 a.机电工程学院,b.河北省智能装备数字化设计及过程仿真重点实验室, 河北 唐山 063000)
0 引言
在信息化快速发展的时代,字符识别是一种重要的录入与转化信息的方法,在车牌识别[1]、邮政编码识别[2]、食品喷码识别[3]等领域有着非常广泛的应用。利用字符识别系统代替传统的人工录入,可以节约大量人力物力,提高工作效率。
目前字符识别的方法有很多,Vaishnav等[4]结合OCR利用模板匹配法完成了对车牌的识别;Zhang等[5]利用CNN(卷积神经网络)中传统的LeNet-5结构实现了对验证码的识别;Alghazo等[6]提出了一种基于结构特征的多语言字符识别系统,通过提取数字的局部特征,对多种语言的字符完成了高精度识别。
字符识别是在字符分割的前提下进行识别的,字符分割的方法有很多种。Khamdamov等[7]提出了一种基于轮廓分析的字符分割方法,通过识别特定字符的局部特征实现了车牌字符的分割;Wang等[8]提出了一种基于字符定位和投影分析相结合的字符分割方法,先通过AdaBoost算法训练级联分类器来定位,然后基于关键字符信息预测其他字符,最后通过垂直投影完成对字符的分割;Peng等[9]提出了一种基于连通域算法和滴水算法相结合的字符分割方法,通过BP神经网络进行预分类,对无粘连字符利用连通域算法进行分割,对粘连字符利用滴水算法进行分割,但是分割准确率不是很高。
上述研究表明一些字符识别方法在车牌等字符识别方面取得了较好的效果,但是对喷码字符中出现的两个及两个以上字符粘连情况的识别,准确率则不高。
鉴于乳制品纸包装上生产批号在喷码过程中常由于各种原因部分喷码字符出现粘连或缺失的现象,影响字符的自动化识别,本文提出了一种基于字宽与投影法相结合的字符分割方法,先利用投影法将双行字符分割为单行字符,再基于字宽完成对粘连字符的分割。在基于字宽进行分割的过程中,有少量字符存在分割损坏的现象,但这并不影响后期CNN的训练过程,相反,这些被分割损坏的字符增加了训练的泛化性,有利于提高对不规则字符的识别准确率。
1 相关工作
1.1 字符识别步骤
基于改进的CNN的不规则字符识别步骤如图1所示。首先,利用yolov3算法对生产日期区域进行提取;其次,对图像进行预处理;再次,通过一种基于字宽的分割算法结合投影法,利用相邻字符间的像素差异实现对粘连字符的分割;最后,对分割后的单个字符利用改进的CNN进行多标签分类训练得到模型,得出并显示识别结果。
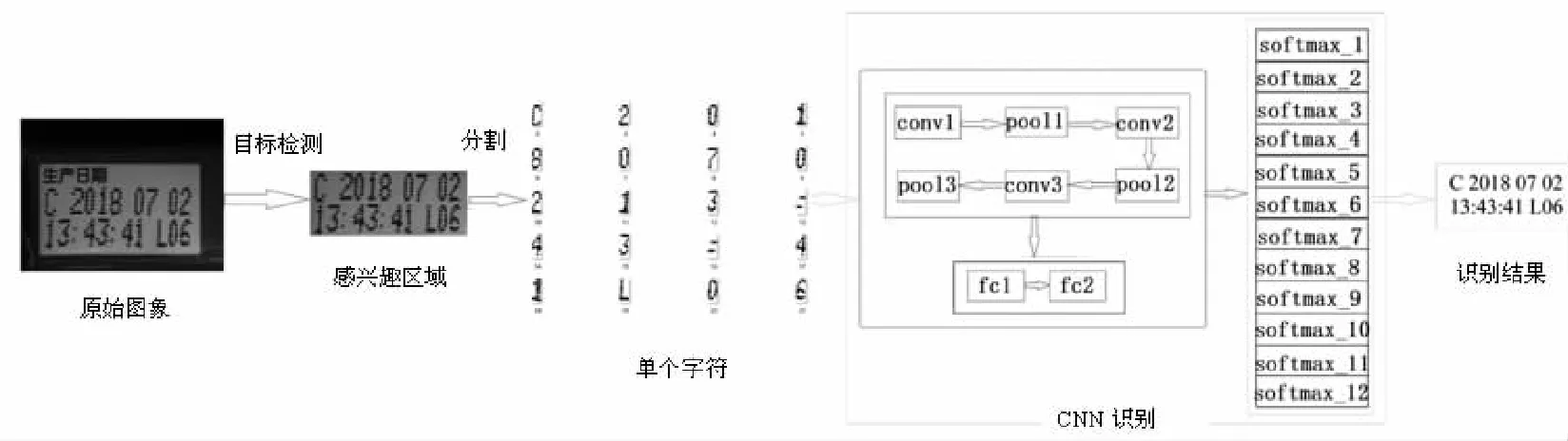
图1 字符识别步骤
1.2 图像获取
乳制品纸包装上生产批号的喷码图像(如图2所示)通过工业相机采集,工业相机包括硬件系统和软件系统。硬件系统由工业相机、光源、相机镜头、传送装置和触发装置组成;软件系统为图像采集系统,由图像格式模块、采集控制模块、连续存储模块组成。

图2 工业相机获取的图像
1.3 感兴趣区域的获取
感兴趣区域(目标区域)提取的方法有很多,如基于深度学习的目标区域提取[10]、基于结构纹理特征的目标区域提取[11]、基于SIFT特征的目标区域提取[12]。本文鉴于图像中字符位置坐标的不确定性,选择基于keras深度学习框架下的yolov3算法[13]进行目标区域的提取。通过labelImg图像标注软件对1 000张样本图进行目标区域标定,图像中标定的目标区域为生产日期区域。把这1 000张标定的图像作为模型的训练集,选定不包含训练集的120张图像作为测试集。经过卷积神经网络训练后得出目标区域预测模型,通过测试集测试后得出模型,符合目标区域预测要求。对其中一张测试图像进行目标区域预测并提取后得到的图像如图3所示。

图3 感兴趣区域的提取结果
1.4 图像预处理
1.4.1 去噪
图像中的噪声点对图像处理造成困扰,需进行去噪处理。因为图像中不均匀的黑点为椒盐噪声[14],所以选取中值滤波[15]进行去噪处理。中值滤波的原理是将一个5×5的矩阵中的25个像素点进行排序,并将矩阵的中心点赋值为这25个像素的中值。中值滤波函数去噪原理如下:
设f(x,y)为中值滤波前的像素值,g(x,y)为中值滤波后的像素值,则有如下关系:
g(x,y)=medA[f(x,y)]。
(1)
式中,med表示用中值代替所有像素值f(x,y),A为5×5的二维区域。
通过5×5的二维窗口进行非线性平滑去噪,对窗口数值重新排序,用中间值代替原窗口的中间值。中值滤波后的效果如图4所示。

图4 中值滤波图
1.4.2 二值化
选取最大类间方差法进行自适应阈值二值化[16],该方法是一种基于全局的二值化算法,能够根据图像灰度特征将图像分为前景和背景,从而获取最佳阈值。最大类间方差法的原理如下:
设背景和前景的分割阈值为T;将前景像素点数占整幅图像像素点数的比重记为ω1,平均灰度为μ1;将背景像素点数占整幅图像像素点数的比重记为ω2,平均灰度为μ2。图像的平均灰度为μ,类间方差为g。假设图像大小为M×N,将图像中像素灰度值小于阈值的像素个数记作N1,将像素灰度值大于阈值的像素个数记作N2,那么有:
(2)
(3)
N1+N2=M×N,
(4)
ω1+ω2=1,
(5)
μ=ω1μ1+ω2μ2。
(6)
将式(5)代入式(6)得:
g=ω1ω2(μ1-μ2)2。
(7)
对全图进行遍历,即能得到最大类间方差法的阈值T。
利用上述算法对图4进行遍历得到最佳阈值T为94。令图4像素N有如下关系:

(8)
根据式(8)就可以得到二值化后的图像,如图5所示。对于不同亮度的图像区域,算法能够根据每一区域的灰度值自适应计算出最佳分割阈值,并取其平均阈值进行迭代,最大化保留相应区域内的所有信息。

图5 二值图
1.5 字符分割
1.5.1 行分割
在获得二值图后,需要进行字符分割,分割后的图像用作后面卷积神经网络训练的样本。因两行字符之间有明显的像素差,故基于水平投影直方图将两行字符分割成单行字符。
1.5.2 列分割
通过行分割得到两张单行字符的图像后,要进行单个字符的分割,但由于有的二值图中出现两个字符粘连的情况,仅利用投影法无法将其分割成单个字符,因此本文提出了一种基于字宽分割的算法,并与投影法结合进行字符分割,如图6所示。

图6 粘连字符分割示意图
本文分割算法如下:
设出现字符像素的起始点为x1,字符像素的终止点为x2。对要分割的字符宽度进行如下定义:
经过行分割后得到的单行字符图像宽度为b1,要进行列分割的单行字符图像宽度为b2,其中b1≠b2,分割后单个字符的宽度为b3。
(9)

因此起始分割位置为x1-k1,终止分割位置为x2+k1,要分割的单行字符图像宽度为:
b2=x2-x1+2k1;
(10)
分割后单个字符的宽度为:
(11)
基于以上算法,从起始分割位置x1-k1以宽度b3进行12等份分割,可得到单个字符分割的图像。
1.6 改进的CNN LeNet-5模型
CNN[17]是一种前馈型神经网络,在图像处理方面表现较好,被广泛应用于图像分类、定位等领域。LeNet-5模型[18]是Yann Lecun教授于1998年提出的,是一种应用于手写字符识别的卷积神经网络。传统的LeNet-5模型在手写字符识别中表现出色,但由于点阵字符的不连通性,导致其对喷码字符识别适用性较差。因此,本文提出的改进的CNN LeNet-5模型增加了各个层中特征图的数量及大小等参数,并对卷积层、池化层、全连接层和输出层作了改进,选取三层卷积层与三层池化层、两层全连接层和一层输出层构成神经网络。改进后的CNN LeNet-5模型网络结构图如图7所示,模型结构如表1所示。
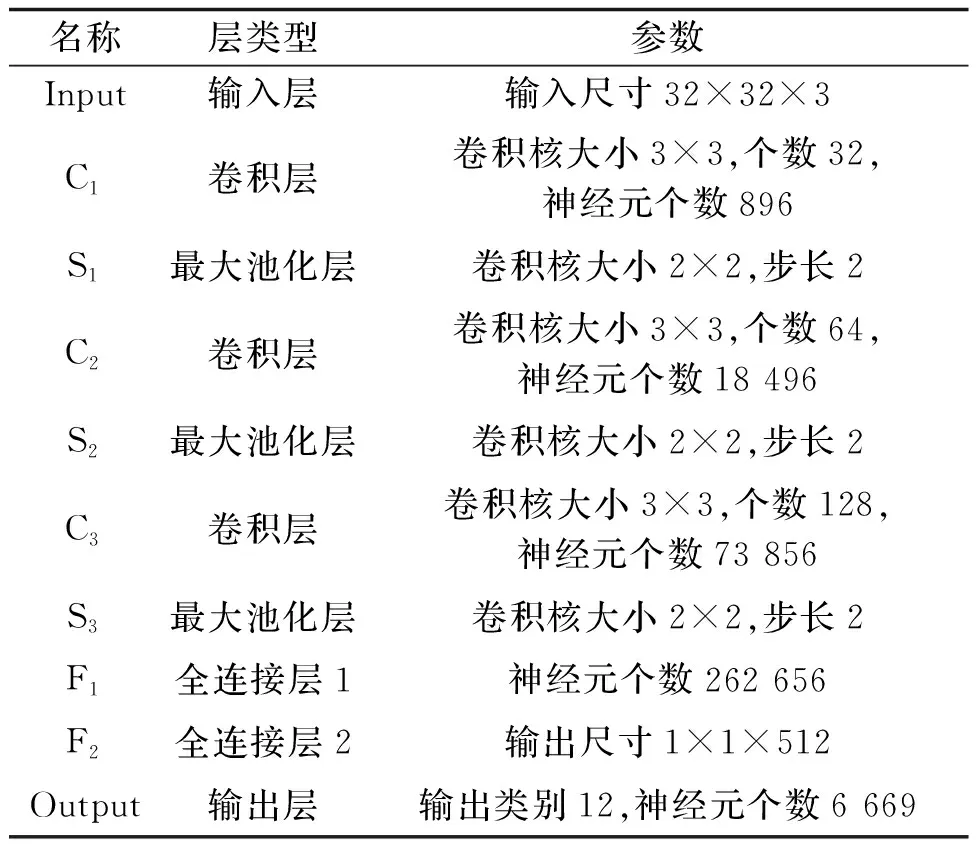
表1 改进后的CNN LeNet-5模型结构

图7 改进后的CNN LeNet-5模型网络结构图
输入层是32×32×3(高×宽×通道)的点阵字符图像,包含字符0-9,C和L共12类。
卷积层共三层,分别为C1层、C2层、C3层。C1层共有32个特征卷积核,每个卷积核的大小为3×3,因此能够得到32个特征图,每个特征图的大小为30×30,有896个神经元共享卷积核权值参数。C2层共有64个特征卷积核,卷积核的大小也是3×3,每个特征用于加权和计算的卷积核为13×13。C3层共有128个特征图,也是用3×3的卷积核进行运算,卷积核的种类有128种,可训练的参数为73 856个,卷积后形成的图形大小为4×4。
池化层共三层,分别为S1层、S2层、S3层。S1层卷积核的大小为2×2,步长为2,输出矩阵的大小为15×15×32;S2层采样卷积核大小为2×2,步长为2,输出矩阵的大小为6×6×64;S3层卷积核大小为2×2,步长为2,输出矩阵的大小为2×2×128。
F1层为全连接层,神经元个数为262 656。F2层也为全连接层,其输出尺寸为1×1×512维向量。
Output层为输出层,共12个节点,每一个节点代表一个标签种类,标签分别为字符0-9,C和L。
为了使模型提取的特征更加精细,改进的CNN LeNet-5模型的网络结构包含输入层共11层,与传统的LeNet-5模型的区别是在第三层卷积层后面增加了池化层,池化层的类型为最大池化,即选取图像区域的最大值作为该区域池化后的值,进一步减小了特征空间信息的大小,提高了模型的运算效率;并且增加了Dropout层,舍弃了一半神经元,使每次迭代可随机更新网络参数,以增加网络的泛化能力,防止训练时产生过拟合。在每一层卷积层之后采用的激活函数为ELU函数,ELU激活函数的形式如下:
(12)
相对于ReLu函数,ELU函数的优点是不会出现Dead ReLu问题,输出平均值接近于0,并且可以通过减少偏置的影响使正常梯度更接近单位自然梯度,从而使均值向0加速学习;ELU在较小的输出下会饱和到负值,因而可以减少前向传播的变异和信息。输出层的激活函数采用的是softmax函数,softmax函数定义如下:
(13)
式中,f(aj)为第j个输出值;n为输出值,即label值的个数,本文n为13。
softmax层的损失函数使用的是对数函数,定义如下:
Li=-logf(am)。
(14)
式中,m为样本的标签,即对应输出的具体label。
根据softmax函数可以进一步得到损失函数的具体表达式,如下:
(15)
通过损失函数,可以计算出输出标签的损失值,进而预测出每一个标签的概率,从而得到模型对待测字符的预测准确率。
2 实验与结果分析
2.1 实验设计
为了评估改进的CNN LeNet-5模型性能,利用本文分割算法得到的数据集进行实验。本文的代码使用python语言编写,基于keras学习框架进行训练。硬件环境为2.20 GHz Core i7 5200 GPU,操作系统为Win10 64位,运行内存为32 GB。样本训练时采用固定学习率,学习率为0.001。在相同的实验环境下,分别对传统的LeNet-5网络、改进的LeNet-5网络、文献[19]和文献[20]中的神经网络进行训练,并用相同的样本集进行模板匹配法的测试,通过比较它们的识别准确率来评估本文模型的性能。其中,文献[19]利用卷积神经网络fast R-CNN和非最大值抑制卷积神经网络(NMS)对管脚字符进行识别,字符识别准确率达到97%以上;文献[20]利用yolov3微网络对车牌进行检测,利用K-means算法进行聚类,通过改进的卷积神经网络结构进行实验,得到车牌字符的识别准确率为99.53%。
2.2 数据集
数据集包含了训练集和测试集。利用本文分割算法,得到了单张字符图像11 000张,共计12个类别,从每个类别中选取200张共2 400张作为测试集,剩余的8 600张为训练集。部分分割的单个字符图像如图8所示。从图中可以看出,在分割后的字符中,部分字符是半字符或残缺字符,将一部分半或残缺字符与正常同类别字符列为同一样本集进行训练,能够增加训练模型的泛化能力,提高模型的鲁棒性。

图8 字符部分训练样本
2.3 实验结果
2.3.1 粘连字符和半或残缺字符的识别
图9是对点阵字符的识别结果,从图中可以看出,后半部分字符经过预处理后会存在部分字符粘连和缺失或全部缺失的情况,利用本文分割算法,对后半部分字符分割后进行分标签训练,增加模型鲁棒性,提高了该类字符的识别率。

图9 字符识别结果
2.3.2 测试识别准确率
本文以学习率为0.001设置不同的迭代次数来检测模型的收敛效果,不同迭代次数的损失值和识别准确率如图10所示。从图中可以得出,当迭代次数达到4 000次时,模型已基本收敛。

图10 损失值和识别准确率
为验证本文算法的性能,将本文的模型与两种鲁棒性较好的字符识别模型(文献[19]和文献[20]中)和传统的LeNet-5模型、模板匹配法进行了实验对比,实验数据分别为粘连字符图像、半或残缺字符图像和正常字符图像。其中,文献[19]中模型训练的学习率为0.001,文献[20]中模型训练的学习率为0.000 1。结果如表2所示。

表2 不同算法的字符识别准确率 %
从表2的实验结果可以看出,模板匹配法和传统的LeNet-5模型对粘连字符和半或残缺字符识别能力较差,文献[19]和文献[20]相较于前两种方法虽有所提高,但识别准确率仍相对偏低。模板匹配法只能对规则字符进行准确识别,而对于不规则字符的识别适应性较差;文献[19]中的算法由于采集的训练集数据过少,且基于人工数据进行训练集的合成,缺少对真实环境中数据存在境况的考量,加之算法的复杂性,使识别的准确率和效率降低;文献[20]中的算法模型只能用于特定格式的训练,缺乏对数据集测试的通用性,导致对粘连字符的识别准确率较低;传统的LeNet-5模型对于手写字符的识别准确率较高,而对于喷码字符的识别鲁棒性较差。
为探讨文献[19]和文献[20]与本文算法的识别准确率之间的差异,在获得整体识别准确率的基础上测试实验数据每个字符的识别准确率,测试结果如图11所示。从图中可以看出,文献[19]和文献[20]中的算法对字符2,5,7,9的识别准确率较低,导致整体的识别准确率较低。原因是在上述数据集中所涉及的字符多为粘连字符和半或残缺字符,文献[19]和[20]中的算法对其适应性较差,导致识别准确率较低。而本文算法相较于这两种算法适应性较好,识别准确率相对较高。

图11 不同算法数据集各类样本测试精度
3 字符识别系统
字符识别系统[21]是通过机器视觉系统采集图像,通过算法来对生产日期进行识别的一个端对端的在线集成系统。通过工业相机将实物信息变成图像信息,经过字符分割、字符识别再将图像上的生产日期信息转换为字符信息,这大大减少了人工识别所带来的成本以及降低了检测误差,提高了识别的准确率。
3.1 系统设计
本文设计的字符识别系统以pycharm为开发平台,利用python语言进行设计,能够应用图像处理技术实现对喷码字符的自动识别。识别过程中需要数字图像处理、python程序设计等相关知识相结合,做出识别系统,实现对生产日期图像的预处理及自动分割和识别。识别系统的原理是采用python编程开发,封装成独立可执行程序,并能够实现手动图像输入识别。
为了使系统中的识别结果能够清晰地呈现出来,采用python中的pyqt5和Qt designer[22]工具制作图像用户界面,通过GUI界面将整个设计呈现为四个模块,主要包括图像读取模块、目标区域获取模块、字符分割模块和字符识别模块。
3.2 在线识别
图像读取模块主要是对工业相机拍摄的原始图像进行读入,点击读取图像可以打开对应文件夹,选择要识别的生产日期图像,然后图像会显示在相应位置。该模块如果用在工业生产线上,可以直接把工业相机拍摄的图像传入到下一模块。
目标区域获取模块直接将yolov3训练的模型嵌入目标区域按钮下的函数中,该按钮下的函数能够直接将生产日期区域进行裁剪并重新生成适合界面的图像尺寸。点击目标区域提取按钮,会将图像中生产日期的部分截取出来。
字符分割模块用Qt designer设计好单个字符显示的位置,通过相应的函数将目标区域模块中裁剪得到的目标区域进行去噪二值化,并利用投影法和字宽相结合的方法完成字符的分割。点击字符分割按钮,字符分割结果将会显示在界面相应的位置。
字符识别模块是利用卷积神经网络将预先分割好的单个字符进行训练,得到一个训练模型。将该训练模型直接用于字符分割模块分割后的单个字符识别,识别结果是将字符分割模块分割后的图像转换为相应的标签输出到界面上。
通过字符识别系统,将图像信息转换成字符信息,能够有效快速地完成生产日期的检测,有利于工业生产效率的提高。
4 结论
本文针对图像中存在的字符粘连问题,提出了一种基于字宽分割算法,并与投影法相结合,通过比较相邻字符间的像素与所设阈值的大小关系,进而选定相应算法进行分割,对存在粘连字符的图像有较好的分割效果。模型训练时,丢弃部分神经元,并增加不规则字符的样本比例,从而增加了模型的泛化性,提高了粘连字符和半或残缺字符的识别准确率。基于上述方法设计的字符识别系统,可以对生产日期进行在线实时检测,加快了工业流水线的运转效率。
本文虽然关注了流水线上不规则字符的识别率问题,但是未考虑生产线上字符识别的速度问题,而流水线上字符的高速识别,能够提高企业的生产效益。今后的研究重点是在保证识别准确率的前提下提高识别速度,使字符识别系统同时满足高准确率和高速度的要求。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
红领巾·萌芽(2019年8期)2019-08-27
数字通信世界(2019年3期)2019-04-19
中国与非洲(法文版)(2017年10期)2017-11-23
软件导刊(2016年11期)2016-12-22
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
CHIP新电脑(2016年3期)2016-03-10
