
基于改进YOLOv5网络的内窥镜息肉检测
2022-05-30 16:28:17司丙奇王志武姜萍萍颜国正
中国新通信 2022年11期
司丙奇 王志武 姜萍萍 颜国正


摘要:结直肠癌是常见的恶性肿瘤,定期进行内窥镜诊断发现并及时切除癌前息肉,可显著降低患者死亡率。目标检测算法能够提高内窥镜检查的临床表现。本文通过标注临床病例的镜检图像和收集公开的息肉图像数据,建立了包含多来源、多中心的胃肠道内窥镜息肉数据集。接着,基于YOLOv5算法,利用注意力机制重构了特征提取网络的C3模块,提出了三种改进模型。为验证改进的检测效果,对多种目标检测算法在自建的息肉数据集上进行了对比实验。测试结果表明,改进模型SE-YOLOv5的准确率为94.7%、召回率为79.5% ,相比YOLOv5算法分别提升了0.6%、2.8%;模型的平均预测速度为50FPS,达到了实时检测的水平,研究对于开发计算机辅助诊断系统具有技术参考价值。
关键词:目标检测;息肉数据集;息肉识别;注意力机制; YOLOv5
2020年新增确诊的结直肠癌病例约193万,占所有新增确诊病例的10.0%,仅次于乳腺癌(11.7%)和肺癌(11.4%);结直肠癌患者的死亡率为51%,占癌症总死亡人数的9.4%;总体而言,结直肠癌在发病率方面排名第三,但在死亡率方面排名第二[1-2]。
结直肠镜检是当前最主要的CRC检测筛查手段,能够检测并移除病变。但是,检测效果受多种因素的制约,比如患者前期的肠道准备、肠道内的息肉数量与所在部位;此外,镜检过程需要内镜医师保持注意力高度集中的状态,过度疲劳将导致更高的误诊率与漏诊率。
为了应对这些困难,研究人员开发了计算机辅助诊断(Computer-aided Diagnostic, CAD)系统。文献[3]提出了ColonSegNet网络模型,预测结果平均准确率80.0%,平均交并比(IoU)为81.0%,在检测速度与预测精度间实现了更好的平衡。文献[4]中基于深度学习算法DenseNet-201开发了CAD系统,对NBI结肠息肉图像准确预测结直肠息肉组织,诊断性能与内窥镜检查专家相当。文献[5]提出了一种轻量级的无anchor的卷积神经网络(CNN)结构,使用紧凑的堆叠沙漏网络,在ATLAS Dione和Endovis Challenge数据集上分别以37.0FPS的速度获得了98.5%的mAP和100%的mAP,实现了RAS视频中手术器械的实时检测。文献[6]提出了一个将Faster RCNN与Inception Resnet相结合的深度学习模型,在2015 MICCAI数据集[7]上的检测准确率91.4%、召回率71.2%,但是每帧图像的检测处理时间约为0.39秒,不能满足结肠镜检的实时性要求。
受制于医学伦理等因素的制约,目前公开的数据集较少且杂乱,部分公开的息肉图像没有经过专业医生的筛选和标注处理,不具备使用价值。为了能够保证深度学习模型网络训练的质量,本文自建具有去中心化、来源丰富的数据集,并提出了基于YOLOv5网络的改进模型SE-YOLOv5;与原模型相比,改进模型具备实时检测性能,检测效果提升明显。
一、 改进型YOLOv5算法
(一) YOLOv5算法原理
2020年,Utralytics团队提出YOLOv5,在精度和速度方面都优于以往的所有版本。YOLOv5利用宽度、深度控制因子来调整骨干网络的通道宽度和网络深度,从而得到YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个版本的模型,四个模型的参数量大小与检测精度依次递增。其中,YOLOv5s是结构最简单的版本,检测速度最快。
本文主要实现病灶目标的实时检测,更关注模型的检测推理速度,选取YOLOv5s v5.0版本作为改进的基础模型。
YOLOv5是由Backbone和Head两部分构成,如图 1所示,Backbone是由Focus,CBS(Conv-Batch Normalization-SiLu),C3和SPP(Spatial Pyramid Pooling)模塊组成。Head是由PANet(Path Aggregation Network)和Detect两个模块组成。
在Backbone部分,Focus模块包含四个平行的切片层来处理输入图像,在图片进入Backbone前,使用Focus模块对图片进行切片操作,每隔一个像素点取出一个像素值,如图2所示。切片操作后得到的四张子图位置互补,没有信息丢失,将宽度、高度的信息包含在通道空间中,输入通道扩充4倍,最后通过卷积操作,得到无信息丢失的二倍下采样特征图,提升了处理速度。
CBS模块包含卷积层(Convolutional Layer)、BN层(Batch Normalization)、SiLu激活函数层。C3_n模块包含CBS模块、n个残差连接单元(BottleNeck),参照CSPNet网络结构[8]将同一stage中基础层的特征图分成两部分,跨阶段使用拆分与合并策略,有效降低信息集成过程中重复的概率。YOLOv5针对CSPNet结构加以改进,根据是否存在无残差边,设计两种CSP模块:CSP-False/True,通过shortcut的取值为False或True进行选择。
加入的SPP模块[9]主要包含三个最大池化层,三者在多个尺度上进行池化操作,适用于处理不同的比例、大小和长宽比的图像数据,可以大幅度提高感受野,提取出最重要的特征,同时有效降低了由于图片伸缩操作导致信息失真的可能性。
Head部分包含三个头部分支,分别负责检测大中小三个尺度的目标,预测信息包括对象坐标、类别和置信度信息。检测头部对高层特征进行上采样操作,自上而下地传递给底层特征,实现了高层语义信息向底层的迁移;底层特征经过stride为2的卷积与张量拼接操作,自下向上传递给高层特征,实现了底层强定位特征向高层的迁移,从而三个分支的特征信息相互融合,实现了PANet(Path Aggregation Network)[10]操作。
(二)注意力机制模块
使用注意机制可以提高神经网络特征图的表征能力,使得模型更加关注重要特征并抑制不必要的特征。
1. CBAM模块
CBAM(Convolutional Block Attention Module)[11]是Sanghyun Woo等人在2018提出的一种简单而有效的前馈神经网络注意力机制模块。如图3所示在给定中间特征图时,CBAM模块沿通道和空间两个独立的维度依次进行注意力特征图的推断,然后将注意力特征图与输入特征图相乘,以进行特征图微调。
2. SE模块
3. ECA模块
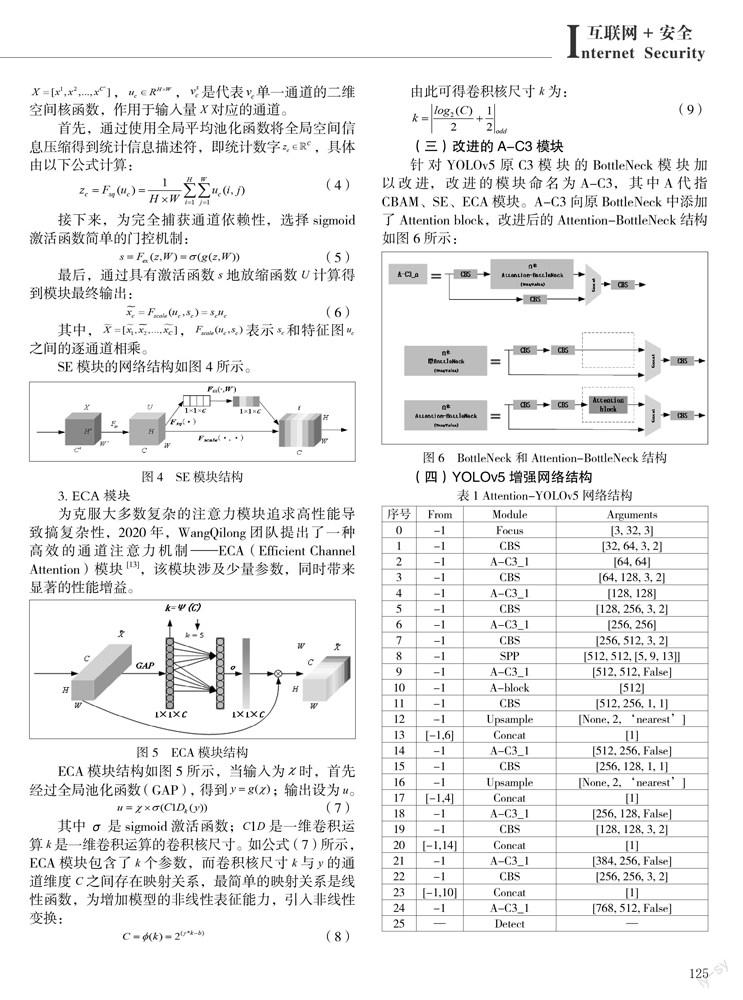
(三)改进的A-C3模块
二、实验及结果分析
(一)实验环境
所有模型的训练和测试任务均在一台配置为Intel(R) Xeon(R) Platinum 8163@ 2.50GHz×12核CPU处理器和NVIDIA Tesla V100 GPU的服务器上进行。相关的硬件和参数配置如表2所示。
(二)数据集
1.数据集构成
在当前的内窥镜病灶研究领域,有一些用于不同研究目的的公开数据集,例如用于内窥镜视觉挑战赛子赛事胃肠图像分析(GIANA)的MICCAI 2017[14],用于常规镜检的胃肠道病变数据集(GLRC)[15],CVC colon DB结肠镜视频数据集。此外,还有一些通用胃肠镜检的内窥镜大型数据集,如Hyper-Kvasir[16]、Kvasir-SEG[17]等。Hyper-Kvasir[16]是通用的消化道内窥镜数据集,涵盖23种不同类别消化道病灶图像和视频,包括息肉、血管扩张等。
在收集的公开数据集基础上,使用LabelImg软件对Hyper-Kvasir数据集的息肉图像中的目标手动标注目标框(ground truth box),自行制作的数据集作为补充,丰富了息肉检测数据集多样性。自建数据集包含165个息肉检测视频序列,合计37899张图像。
2. 数据集划分
对于普通的检测目标,可以基于图像进行数据集划分。如果按照这种方法划分,同一个息肉目标会同时包含在训练集、验证集和测试集中。由于模型在训练阶段已经学习了某息肉图像的特征,将导致模型在测试时对该息肉目标的检测效果偏高。因此,需要按照视频序列对数据集进行划分,分别随机选择 65%、20% 和15% 的视频序列来形成训练、验证和测试集。对不同来源、不同类型的数据构成的数据集进行随机划分,起到了数据集去中心化[18]的效果,有效降低了由于数据的固有选择造成的偏差。训练集、验证集、测试集的图像数量分布如图7所示:
(三)模型评价指标
(四)实验结果及分析
1.参数收敛情况
本文将准确率Precision、召回率Recall、AP@.5、AP@.5:.95指标作为判别模型是否收敛的主要参数。各模型参数的变化情况如图8所示。各参数均能够随训练迭代次数平稳地收敛,各模型准确率最终收敛在94.0%附近。其中,SE-YOLOv5的召回率、AP@.5、AP@.5:.95指标均能达到最优。
2.不同网络的对比实验
为了直观地体现改进算法的性能优势,将各改进模型与YOLOX[19]、YOLOv5、Scaled-YOLOv4[20]、YOLOv3[21]、SSD[22]、Faster RCNN[23]、RetinaNet[24]几种先进的同类算法在测试集上进行测试,各模型性能对比情况如表3所示。加粗字体为所有模型该项对应的最优指标。从表中数据可知,SE-YOLOv5的检测精度略低于CBAM-YOLOv5,但是其召回率(Recall)、AP@.5、AP@.5:.95指標均达到或接近最优;scaled-YOLOv4的召回率、AP@.5、AP@.5:.95指标与其接近,但是准确度过低,而且模型复杂度过高。从检测速度方面来看,SE-YOLOv5平均推理速度为50FPS,快于基础模型YOLOv5,测试结果大于30FPS,能够满足对内窥镜视频序列检测的实时性要求。
息肉检测任务中,召回率直接反应了病人漏诊的情况,由于漏诊的严重性,召回率成为最重要的评价指标。综合考虑检测精度和速度,选取F2分数最高的SE-YOLOv5模型作为最优模型。实际检测结果如图9所示,表明在不同光照条件、噪声干扰、不同角度的情况下,模型依然能够取得良好的检测效果。
三、结束语
本文以内窥镜图像中的息肉病灶检测为研究目标,通过收集公开数据集与自行标注,建立了用于训练与检测任务的息肉数据集;基于YOLOv5算法,使用SE注意力机制重构了原C3模块,获得改进模型SE-YOLOv5。
与原模型相比,改进模型在不明显增加计算复杂度的情况提升了模型的检测性能,并且优于其他同类型的优秀检测算法,实现了针对内窥镜图像病灶的实时检测。
临床诊断需要检查多种异常病变,如溃疡、出血、炎症和血管疾病等,而公开数据集杂乱且匮乏,需要收集与制作更多类别的胃肠道内窥镜病灶数据集。另外,当前所有模型都是在性能优秀的服务器上完成训练与测试任务的,对硬件配置要求较高。为了能够顺利地部署在嵌入式系统上,需要压缩检测模型的尺寸以减少参数量。因此,建立包含更多病灶类别的数据集与模型小型化将是下一步的研究内容。
作者单位:司丙奇 王志武 姜萍萍 颜国正 上海交通大学 电子信息与电气工程学院 上海智慧戒毒与康复工程技术研究中心
参 考 文 献
[1] SUNG H, FERLAY J, SIEGEL R L, et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries[J]. CA: a cancer journal for clinicians, 2021, 71(3): 209-249.
[2] VANESSA B , KAREN S . Colorectal cancer development and advances in screening[J]. Clinical Interventions in Aging, 2016, Volume 11:967-976.
[3] JHA D, ALI S, TOMAR N K, et al. Real-time polyp detection, localization and segmentation in colonoscopy using deep learning[J]. IEEE Access, 2021, 9: 40496-40510.
[4] Song E M , Park B , CA Ha, et al. Endoscopic diagnosis and treatment planning for colorectal polyps using a deep-learning model[J]. Scientific Reports, 2020, 10(1):30.
[5] LIU Y, ZHAO Z, CHANG F, et al. An anchor-free convolutional neural network for real-time surgical tool detection in robot-assisted surgery[J]. IEEE Access, 2020, 8: 78193-78201.
[6] Shin Y , Qadir H A , Aabakken L , et al. Automatic Colon Polyp Detection using Region based Deep CNN and Post Learning Approaches[J]. 2019.
[7] BERNAL J, TAJKBAKSH N, SANCHEZ F J, et al. Comparative validation of polyp detection methods in video colonoscopy: results from the MICCAI 2015 endoscopic vision challenge[J]. IEEE transactions on medical imaging, 2017, 36(6): 1231-1249.
[8] WANG C Y , LIAO H , WU Y H , et al. CSPNet: A New Backbone that can Enhance Learning Capability of CNN[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). IEEE, 2020.
[9] HE K , ZHANG X , REN S , et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. Pattern Analysis & Machine Intelligence IEEE Transactions on, 2015, 37(9):1904-1916.
[10] LIU S , QI L , QIN H , et al. Path Aggregation Network for Instance Segmentation[J]. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
[11] WOO S, PARK J, LEE J Y, et al. Cbam: Convolutional block attention module[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 3-19.
[12] HU Jie, Li Shen , SUN Gang, et al. Squeeze-and-Excitation Networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, PP(99).
[13] WANG Q , WU B , ZHU P , et al. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2020.
[14] BERNAL J , TAJBAKHSH N , SANCHEZ F J , et al. Comparative Validation of Polyp Detection Methods in Video Colonoscopy: Results from the MICCAI 2015 Endoscopic Vision Challenge[J]. IEEE Transactions on Medical Imaging, 2017, 36(6):1231-1249.
[15] MESEJO P , PIZARRO D , ABERGEL A , et al. Computer-Aided Classification of Gastrointestinal Lesions in Regular Colonoscopy[J]. IEEE Transactions on Medical Imaging, 2016, 35(9):2051.
[16]BORGLI H, THAMBAWITA V, et al. HyperKvasir, a comprehensive multi-class image and video dataset for gastrointestinal endoscopy[J]. Scientific data, 2020, 7(1): 1-14.
[17] JHA D, SMEDSRUD P H, RIEGLER M A, et al. Kvasir-seg: A segmented polyp dataset[C]//International Conference on Multimedia Modeling. Springer, Cham, 2020: 451-462.
[18] YANG Y J. The future of capsule endoscopy: The role of artificial intelligence and other technical advancements[J]. Clinical Endoscopy, 2020, 53(4): 387.
[19] GE Z , LIU S , WANG F , et al. YOLOX: Exceeding YOLO Series in 2021[J]. 2021.
[20] WANG C Y , BOCHKOCHKOVSKIY A , LIAO H Y M . Scaled-YOLOv4: Scaling Cross Stage Partial Network[C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2021.
[21] REDMON J , FARHADI A . YOLOv3: An Incremental Improvement[J]. arXiv e-prints, 2018.
[22] LIU W , ANGUELOV D , ERHAN D , et al. SSD: Single Shot MultiBox Detector[J]. 2015.
[23] REN S , HE K , GIRSHICK R , et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
[24] LIN T Y , GOYAL P , GIRSHICK R , et al. Focal Loss for Dense Object Detection[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP(99):2999-3007.
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
科学与财富(2016年28期)2016-10-14 23:45:18
电脑知识与技术(2016年5期)2016-04-14 13:48:16
