
基于网络拓扑的电网资源挖掘推荐模型构建
2022-05-30 03:39程伟华吴小虎
能源与环保 2022年5期
赵 越,程伟华,赵 申,吴小虎
(1.国网江苏省电力有限公司,江苏 南京 210000; 2.江苏电力信息技术有限公司,江苏 南京 210000)
电能在人们生活与社会生产中发挥重要作用,因此保证电网安全运行极为关键[1]。电网规模迅速扩大,使电力资源数量呈现出爆炸式增长趋势,加大了数据分析与管理的难度。传统数据挖掘方法不能满足电网资源获取需求,一些电力工作者已经体会到从海量资源中获得想要的信息尤为困难。此外,电网资源在一定范围内很难实现信息共享。这会使区域电网变得孤立,工作人员不能准确得到相关运行数据,容易发出错误指令,造成电力事故。因此,电力资源挖掘决定了电网能否健康运行,电力工作者也越来越需要一种能够快速获取电网资源的方法[2-4]。
但是随着电网系统复杂性的提高,传统的电网资源挖掘推荐方法逐渐显现出响应时间长,推荐不精准的弊端。由于网络拓扑在电网的运行分析中起到关键作用,一些网络资源的挖掘推荐,都是在电网拓扑计算结果基础上实现的[5]。为此,本文构建一种基于网络拓扑的电网资源挖掘推荐模型。此种方法实质是将网络拓扑当作知识描述方式,将海量电网资源和它们之间存在的联系变成网络拓扑形式,并结合爬虫技术,设定通信协议栈,构建智能挖掘推荐模型。
1 电网资源系统结构探究
1.1 电网系统架构
电网系统具有监测电器设备、负荷能效管控与运行优化等功能。主要由网关、处理器与大数据服务器构成。电网系统架构如图1所示。

图1 电网系统示意Fig.1 Schematic diagram of power grid system
智能测试终端是电网系统中数量最多的信息采集设备,可对电流、电压等信息进行采集,并将这些数据保存到资源库[6-8]。现阶段,大部分终端均使用基于事件驱动的通信机制,可大大缩短信息采集与传输时间。
1.2 电网资源数据库
数据库可以为电网运行分析与决策提供数据基础,主要工作就是电网数据的在线收集,并通过专业管理系统实现资源整合。电网数据库主要包括自上向下、自下向上与混合形式3种设计模式。其中自上向下与混合形式均缺乏一定灵活性,达不到最优设计,因此多数情况下使用自下向上模式[9-11]。
通过电力综合查询系统明确信息源,对数据源做综合提炼,构建资源库,通过不断扩充,逐渐完善资源库[12-13]。还需结合既定主题实现数据源集成,电力资源库的层次结构如图2所示。
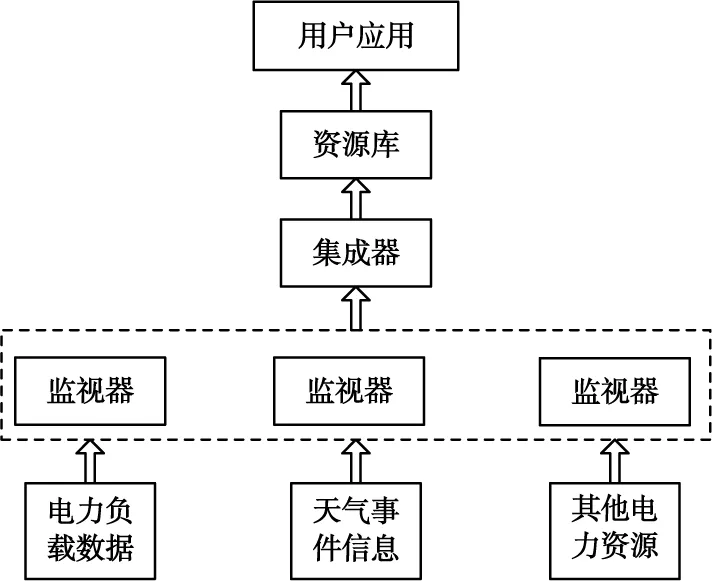
图2 电力资源库层次结构Fig.2 Hierarchical structure diagram of power resource library
如图2所示,电网资源库中主要包括电器负载数据、时间与天气数据以及一些常用的基础数据。这些信息必须通过处理才能保存到资源库中,且需通过集成器不断更新[14]。集成器主要负责捕捉电力数据并做综合转换处理,保证数据的格式正确,形成有价值的资源,供用户使用。
2 电网资源挖掘推荐模型构建
2.1 网络拓扑表示
电力系统的网络拓扑可通过有向图G=(V,E(s))来描述,V为节点集合,E为有向边,s能够体现出边的状态,包括连通与断开2种。
本文通过邻接矩阵方法来表示有向图。针对任意一边(u,v),设置A[u][v]=true。在电网拓扑中,通常用0描述节点断开,1表示连通[15-16]。
利用二维矩阵能够清晰地表现出2个节点之间的状态,其中黑色实心圆点是开关分位,白色空心圆点是开关合位。例如拓扑结构中存在N′个节点,此时可通过N′维矩阵表示节点断通情况,如图3所示。图3中,共有9个节点与8条支路,通过下述邻接矩阵来描述相邻节点存在的关系:从矩阵中可以看出网络拓扑中随机两节点之间存在的连接关系,减少推荐过程中的资源传输时间。
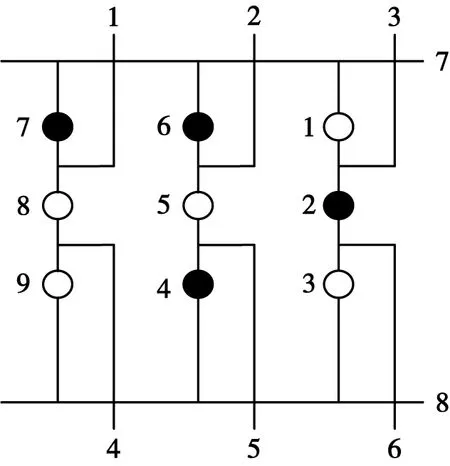
图3 节点连接线示意Fig.3 Schematic diagram of node connection line

(1)
2.2 电网资源的标准化处理
资源标准化处理是为了减少冗余数据对挖掘推荐结果的影响,通过数据清洗与调节操作,使资源更加符合推荐需求[17]。
冗余数据包含噪声数据与离群值等,聚类方法可以在海量含噪数据中获取正常数据,同时对自身异常的信息也非常敏感。但是异常信息会导致错误分类,因此在聚类之前需要对所有资源进行归一化处理[18]。
(1)资源归一化处理。电网资源的归一化处理就是将传感器采集的资源和输出资源变换在[0,1]范围内,变换公式如下:
(2)
式中,xmax与xmin分别为资源集合中负荷信息的极大值与极小值,是真实负荷信息,是经过归一化的数据。归一化处理过程如图4所示。
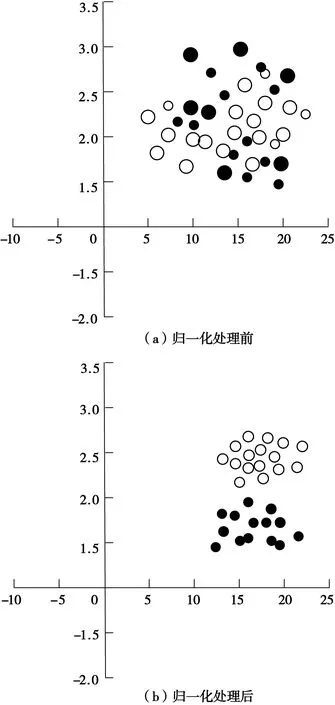
图4 归一化处理过程Fig.4 Normalization process diagram
(2)k—均值聚类。聚类就是将具有相似特征的数据根据已知的距离测度将其汇聚成“簇”的过程。也就是将整体的数据库分割为多个簇,保证每个簇中的资源均具有相似性,但又和其他簇不相似。要想保证较好的聚类结果,必须最大限度地调整聚类中心之间的距离[19-20]。
k—均值聚类是一种常用的简便聚类方式,将欧式距离当作测度,计算公式:
(3)
通常利用下述均方差当作基准测度函数,计算公式如下:
(4)
式中,c为类,k为需要聚类的数目,nj为第j个样本具有的样本数量,mj为样本平均值,也是该数据集合中心:
(5)
k—均值方法的整体流程可描述为:从n个资源目标中选取k个目标当作原始聚类中心,针对资源库中其余信息,获得这些信息到聚类中心的欧式距离,并将它们放入最近的类中;重新获取全部新的聚类中心,经多次迭代处理,直至测度函数符合要求再停止。
由上述过程可以得出,聚类参数k是需要人工设置的,针对复杂资源集合的聚类处理,该值的选取较为困难。因此必须结合初始聚类中心确定该值,同时对初始分割进行优化处理,确保获得精准的聚类结果。
2.3 资源挖掘推荐模型建立
通过上述数据预处理过程,确保电网资源库中的信息符合挖掘推荐需求,再通过网络爬虫技术经过权限匹配、聚类谱排序以及资源传输等过程完成挖掘推荐模型的构建。
(1)挖掘权限匹配。电网资源的挖掘权限匹配主要包括最优解获取和相似度计算2个步骤。在确保资源校验和推荐信息价值最大化条件下,假设全部待挖掘的信息都处于较为封闭的集合内,同时此集合内全部元素因子均具有匹配权限。如果表示待挖掘资源的平均参量值,则通过f′可设定权限匹配的阈值为:
(6)
式中,p′为资源参数总量;w′为因子系数;e′为权限匹配的相关条件;t′为一个常量因子;u′描述平均挖掘标准;max说明挖掘权限的最大化形式。
通过下述公式可计算出最大挖掘权限的最优解:
χ=i1/2(Qa-Qb)
(7)
式中,Qa与Qb分别为电网资源库的最大与最小容量。在确保全局最优解成立前提下,假设r′和y′分别为描述相似度的最大与最小分时值,d′为探索周期,g′为挖掘探索量,则电网资源挖掘的最大权限相似度计算公式为:
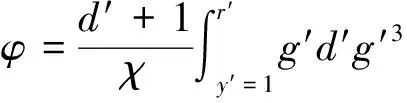
(8)
(2)聚类谱排序。挖掘权限的良好匹配为爬虫聚类谱的资源层次结构布置奠定基础,设置合理的抓取规则对全部聚类谱做排序处理,确保挖掘推荐的资源可以顺利传输到用户端。符合抓取规则的聚类谱需根据排序规则排列,首层为信息层,第2层则是物理层,最后一层为应用层。
其中信息层是爬虫聚类谱和通信协议栈连接的关键单元,可以对物理层传输挖掘推荐的电网资源。而应用层属于末端环节,能够促进资源快速传输。
(3)推荐数据传输。设置数据传输模式是资源推荐的重要步骤,理想情况下的电网资源系统分为处理层、传输层与指令层。处理层是爬虫协议的重要存在单元,其中全部待挖掘的资源都形成点状排列,但在爬虫协议控制下,这些资源能够快速构成集合,便于传输层的调用。
指令层能接收推荐的电网资源,经过对数据的组合方式的调节,使挖掘推荐效果达到最佳。结合上述2个步骤,即可完成电网资源挖掘推荐模型的顺利应用。基于网络拓扑的电网资源挖掘推荐模型如图5所示。

图5 基于网络拓扑的电网资源挖掘推荐模型Fig.5 Grid resource mining recommendation modelbased on network topology
3 现场应用
3.1 测试现场与实验参数设置
为了验证本文构建的基于网络拓扑的电网资源挖掘推荐模型在实际应用中的有效性,进行一次仿真实验分析。通过电力实验室获取电网资源数据,如图6所示。

图6 电力实验室获取数据现场Fig.6 Field data obtained by power laboratory
通过测试现场设置实验参数:实验时间为70 min;数字化电网运行参量为0.94;电网资源挖掘参量为0.86;预设单位时间为15 min;未占用资源上限为8.27×1010T;单位时间内电网资源挖掘极限为7.3×109T。
电网资源挖掘推荐算法的性能主要体现在响应时间与推荐精度两方面。由于电力用户通常为工作人员,当紧急故障出现时,等待时间有限,因此推荐速度必须要快。此外,用户一般想要得到更加专业的信息,所以推荐结果中尽量不显示其他信息。
3.2 数据预处理性能分析
本文使用了聚类算法对海量电网资源进行预处理,仿真实验中选取一个随机数据集,该集合是以点(-2,-2)和(2,2)为中心生成的,初始数据分布情况如图7所示。通过实验对本文方法的数据预处理效果进行测试,测试结果如图8所示。

图7 初始数据分布Fig.7 Initial data distribution

图8 本文方法聚类结果Fig.8 Clustering results of method in this paper
由图8能够看出,所提聚类方法可以将相同类型的数据精准的聚集在一起,本文通过此种数据预处理方式将电网资源进行聚类处理,为资源挖掘推荐奠定良好基础。
3.3 推荐延迟分析
推荐延迟就是响应时间,一个高效的推荐策略在用户提交申请后表现出的响应速度非常重要。选定一个电网资源集合作为延迟分析目标,同时以5 s/次的频率向该集合内添加500条新增信息,1 min后停止。记录下推荐资源数量和延迟推荐数量,实验结果见表1。

表1 延迟推荐数量Tab.1 Delay recommended quantity
由表2可知,随着数据集合的不断更新,本文方法推荐的信息数量也在稳定增长,在新增信息数量到达2 500条时才会出现延迟推荐现象,并且延迟推荐量较小,实现了电网资源的实时挖掘推荐。这是因为方法在明确网络拓扑情况下,掌握各节点的连接状况,减少资源传输时间,进而提高响应速度。
3.4 推荐精度分析
本文利用平均绝对误差来衡量推荐结果是否满足用户需求,即推荐精准性。该值越小,推荐效果越好。构建一个预测的用户评分集{p1,p2,…,pn},而真实评分集合为{q1,q2,…,qn},则平均绝对误差表达式为:
(9)
在电网资源库中选取2 000条数据为实验目标,其中包括600个用户与1 400条知识。从这些数据中随机选取3/4当作训练集,剩余数据作为测试集。本文方法的推荐平均绝对误差结果如下,用户数量分别为5,10,15,20,25,30,35时,对应的MAE分别为0.64,10.62,0.65,0.61,0.67,0.66,0.65。
可以看出,随着用户数量的不断增加,本文方法的平均绝对误差始终在0.6~0.7,没有快速增加。由于本文方法使用的爬虫技术可以获得电网资源挖掘推荐的全局最优解,因此无论信息量增加多少,都不会对挖掘精度产生影响。
4 结论
信息技术的发展使电网系统进入大数据时代,用户面对着从海量资源中挖掘出有用信息的困境。为提高挖掘精度,减少等待时间,提出基于网络拓扑的资源挖掘推荐模型研究。在建立网络拓扑前提下,促进推荐资源快速传输,并通过爬虫技术,获得最大挖掘权限,确定全局最优解,实现挖掘推荐模型构建。经过对比实验,证明了该算法的优越性。但是该方法在延迟推荐量上还有进步空间,在后续研究中,可进一步提高响应速度,确保电力工作者迅速做出决策。
猜你喜欢
网络安全与数据管理(2022年2期)2022-05-23
学前教育(幼教版)(2022年3期)2022-04-29
武术研究(2021年2期)2021-03-29
电子制作(2018年23期)2018-12-26
知识文库(2018年13期)2018-05-14
汽车维修技师(2017年7期)2017-12-05
电子制作(2017年10期)2017-04-18
雷达学报(2017年6期)2017-03-26
汽车维修技师(2017年10期)2017-03-17
互联网天地(2016年1期)2016-05-04
