
Deep image retrieval using artificial neural network interpolation and indexing based on similarity measurement
2022-05-28 15:17:16FaiyazAhmad
Faiyaz Ahmad
Department of Computer Engineering,Jamia Millia Islamia,New Delhi,India
AbstractIn content-based image retrieval (CBIR),primitive image signatures are critical because they represent the visual characteristics.Image signatures,which are algorithmically descriptive and accurately recognized visual components,are used to appropriately index and retrieve comparable results.To differentiate an image in the category of qualifying contender,feature vectors must have image information's like colour,objects,shape,spatial viewpoints.Previous methods such as sketch-based image retrieval by salient contour (SBIR) and greedy learning of deep Boltzmann machine (GDBM) used spatial information to distinguish between image categories.This requires interest points and also feature analysis emerged image detection problems.Thus,a proposed model to overcome this issue and predict the repeating pattern as well as series of pixels that conclude similarity has been necessary.In this study,a technique called CBIR-similarity measure via artificial neural network interpolation (CBIR-SMANN) has been presented.By collecting datasets,the images are resized then subject to Gaussian filtering in the pre-processing stage,then by permitting them to the Hessian detector,the interesting points are gathered.Based on Skewness,mean,kurtosis and standard deviation features were extracted then given to ANN for interpolation.Interpolated results are stored in a database for retrieval.In the testing stage,the query image was inputted that is subjected to pre-processing,and feature extraction was then fed to the similarity measurement function.Thus,ANN helps to get similar images from the database.CBIR-SMANN have been implemented in the python tool and then evaluated for its performance.Results show that CBIR-SMANN exhibited a high recall value of 78%with a minimum retrieval time of 980 ms.This showed the supremacy of the proposed model was comparatively greater than the previous ones.
KEYWORDS Gaussian filtering,Hessian detector,image retrieval,interpolation and similarity measurement,repeating pattern
1|INTRODUCTION
The demand for digital media is increasing in the upcoming centuries because of its numerous application.More enhancements in digital image processing(DIP)are necessary for effective image seeking that is also indexed in a massive volume of databases.In general,images were extracted from three techniques as content-based image retrieval,test-tagged oriented retrieval and semantic-based retrieval[1].The reason for indexing images is that it increased the demand for digital images that are necessary for specific data representation for retrieval,and that promoted research fields.This is the reason for which image retrieval and fetching has an effective and direct role in an image that searches for a wide range of databases.An important aspect is content-based image retrieval(CBIR),which performs matching of image primitive features depending on its visual properties.By extracting features from an image CBIR system,a feature extraction processing step has been considered as a pre-processing stage [2,3].Classifying visual features into two categories,the overall characteristics are termed as global features,and the visual property of an image is termed as the local feature.Most probably the CBIR system used local and global features that consist of texture information,edges,spatial coordinates and shapes that also connect interest points in order to extract similar form of images.Neighbourhood relationships are represented by texture features that combine categorized spatial and combined pixel value into spatial as well as spectral feature.Classifying shape features into contoured and regained that are probably region-based applies colour features,with extracted shape points from the complete area of interest.In sensitized to noise,contour-based processes,the shape-dependent anchors are removed at the edges and corners of an image in noise sensitization [4,5].
However,colour histogram representations are scaleinvariant and rotation.Without representing spatial distribution using colour channels,which is a primary issue along with global features they also cannot minimize the semantic gap between them.All characteristics of the image were not shown in the global features.This is the cause for which global features were not applicable for matching partially the images that develop a retrieval system.However,the semantic gap has been reduced by local features.In order to take effect over the disadvantage of global feature removal,interest point detector(IPD) is used to show the image with its local features [6,7].Different algorithms such as the scale-invariant algorithm,affiant invariant algorithm,Harris and Hessian are dependent on interest points.By recognizing objects locally and globally,the images are combined that contribute to a high level of image content.The quality of retaining an image with respect to its resolution is important as they were frequently printed or displayed by various resolutions with output devices.Thus,images consisting of an optimal resolution for all networks,display environment and printers cannot be prepared.Because digital pictures are sampled in a 2D lattice,Jaggies are unavoidable.This issue cannot be overlooked in order to increase the quality of an expanded image since edges have a significant impact on the overall image quality [8].
The sampling function is adjusted in this approach with the neighbouring pixel values.The image retrieval procedures are divided into two methods,content-based image retrieval(CBIR)and annotation-based image retrieval (ABIR).In the first method,the image should be represented as a feature vector and then categorized.In the end,the semantic of the associated category should be propagated along with the supplied image[9,10].As a result,CBIR finds photos based on the keywords in their annotations.ABIR has various disadvantages,despite its ability to give a high retrieval performance.For example,when the content of a picture is highly abstract,it might be difficult to explain it using only a few terms.In the second method,CBIR obtains pictures related to the visual content that divides the query and convert images into vectors consisting of different methods such as texture,colour and form and then compares their similarity.Finally,as retrieval results,return an ordered collection of pictures sorted by similarity value.By relying solely on keywords,CBIR may be able to sidestep many of the issues that plague ABIR [11].As a result,CBIR [12,13] has been increasingly interested for researchers.A novel model,image retrieval,is proposed to study more issues related to these existing models.The proposed model consists of shape features and low-level features..
1.1|Contribution of the paper
❖This system captures and checks the image data consisting of an object,colour,spatial information,texture and shape,that lively generates the recovery rates and maximum precision.
❖Initiated a description model and weightless feature detection that effectively retrieves appropriate outcomes from cluttered as well as complicated datasets.
❖A method is initiated to implement the semantic variation with similarity measurement and colour mapping to highlight the objects.
❖The potential of the provided technique is to expose only the important information of the image from the anchor translation instead of complete image iterations.
❖Storage efficient,time and computation retrieval system is initiated,which retrieves the output in seconds.
The proposed model is comprised of all the above contributions.The study has been arranged in the following manner:Section 2 explains the existing work briefly,and Section 3 explains the proposed methodology.Section 4 details the experimental outcomes,and Section 5 contains the conclusion of this study.
2|LITERATURE REVIEW
In this session,some image retrieval methods that were used in previous stages are discussed,along with their drawbacks.
Liu et al.[14]have developed a visual attenuation system for content related image retrieval,initially,in visual prompt named colour volume,which consists of information related to the edge.This was combined and presented to predict saliency regions rather than using major visual features.However,this method has low discrimination values.Liu et al.[15]have provided an algorithm called micro-structure descriptor,which has minimum dimensionality and high indexing performance.Particularly there are only 72 dimensions for complete images that have very efficient time for image retrieval.However,it requires more extensions that show lower dimensionality,rather for every edge detector that was developed for grey level images that have a colour image from colour channels.Zeng et al.[16]have provided a method called image representation,which is used to characterize an image into spatiogram consisting of a general colour form histogram that colours with the help of Gaussian mixture models.Initially by quantizing colour space via Expectation-maximization from a training set of images.However,incorporating the spatiogram does not quantize using this Gaussian mixture model.Liu et al.[17] have provided a method called image feature representation such as colour difference histogram (CDH) that is used in the process of image retrieval technique.This technique has the characteristics of making count perceptually that has the same difference in colour between the two points with various backgrounds,related to colour and edge orientation.However,this technique played more focus on edge orientation,and colour that does not favour feature representation likewise was a drawback.Varish et al.[18]have proposed a hierarchical method for retrieving an image named the two-layer feed-forward architecture (FFD).Every layer minimizes the search range by filtering out them as an irrelevant image that was based on texture and colour features due to weights in texture and colour similarity values that measured the similarity distance.However,it failed to provide flexibility with respect to each user.
Kumar et al.[19]have presented an image saliency technique with the help of a space model that utilized the colour distribution part of images rather than to serve the majority of visual feature representation values,by combining local features and global feature that has a content detection method.However,this comparison of local features requires more parameters to perform this simulation.Uma Maheswaran et al.[20]have presented a composite microstructure descriptor that has a working principle similar to other CBIR systems.By integrating the multi Textron histogram and micro-structure descriptor,the multiscale features were explored in order to compute them.However,integrating the block values which have shown minimum intensity values made this image to remain in the transformed state.Srivastava et al.[21]have introduced a CBIR technique that uses the Multiscale Local Binary pattern rather than the other neighbourhood protocols,by combining eight neighbourhoods that calculated multiple scales.It captures a large scale of commanding featuresthat have certain textures insidea single scale to create a limitation of multiscale techniques.Hua et al.[22]have introduced a visual descriptor that was called along with the colour volume histogram and used in the CBIR system.Colour volume histograms that had descriptive power for spatial features,shape and texture significantly perform a local binary pattern.However,these factors like edge cue,colour affiliation and spatial layout consume a lot of time for computation.Zhang et al.[23] have presented a fine-grained image categorization algorithm that defined a picture as a spatiogram with a generic colour histogram,which was coloured using the Gaussian mixture models,initially,by using Expectation-maximization from a training set of pictures to quantify the colour space.Using this Gaussian mixture model,however,adding the spatiogram does not quantize.
Hor et al.[24]had presented a combination of local texture information derived from two different texture descriptors for image retrieval.Initially this method separated the colour channel input images.Predefined pattern units as well as evaluated local binary patterns are the two descriptors which were used for extracting the texture information.Based on the distance criteria,the similarity matching was performed once by extracting the features.Bani et al.[25] had introduced an image retrieval method for extracting local as well as global textures and colour information in two spatial and frequency domains.In this approach Gaussian filter for filtered images as well as the statistical features are extracted based on cooccurrence matrices.In this way,the noise-resistant local features were extracted.The quantized histogram is then generated in order to obtain global colour information in the spatial domain.Tuyet et al.[26] had introduced a content based medical image retrieval based on salient regions combined with deep learning.This method contained two stages such as,the first stage is based on an offline task to extract local object features and the second stage is responsible for an online take for content-based image retrieval in the database.The initial stage,based on the shape,texture and intensity of local object features in medical images were extracted using deep learning based saliency of decomposition..Second,an online job for retrieving content-based images from a database.The user enters a query image,and the system returns the topnmost comparable images by comparing similarity to a bag of code words feature values obtained in the first stage.
From the above-stated issues,image retrieval undergoes a major concern of flexibility and colour edge orientation.Thus,a method to overcome these drawbacks and perform more appropriate retrieval was necessary.
3|PROBLEM STATEMENT
From the development of multimedia databases,the importance of a huge amount of material is determined by how well it can be viewed,retrieved and relevant knowledge extracted from it while reducing the amount of time spent looking at it.Multimedia information is critical in applications like entertainment,education,e-commerce,health,and aerospace in the digital field.With the rapid growth of the Internet,consumers now have access to a massive amount of multimedia material.As a result,many digital images are generated in daily life,and if they are inspected on a regular basis,there is a wealth of helpful information available to consumers.The main goal of CBIR approach is to find images with the highest similarity score by comparing the database with the query image.The CBIR approach uses a simple way to extract local and global feature sets to make picture representation easier.The retrieval technique used here is completely dependent on calculating the distance between query and database pictures using feature vectors.As a result,the most relevant image that is closest to the query image is returned,resulting in the best possible pair of images.The fixed number of images are retrieved by the colour feature similarity measure,and the relevancy of images are found by the texture and shape features.Furthermore,to obtain more accurate retrievals,region and global features are used.Experiments are performed on RGB-near infrared databases,which consist of indoor,outdoor and ortho-imagery scene category recognition tasks.Also,due to a lack of proper retrieval techniques,the users are unable to extract the relevant information from the available databases.To overcome the drawbacks,which are explained above,a technique named Deep Image Retrieval using ANN interpolation and indexing based on similarity measurement can be introduced.
4|PROPOSED METHODOLOGY
In the CBIR system,the first step is to convert a query image to a grey level.The proposed model contains CBIR-SMANN,which is used to convert the colour image to grey level or black-white or monochrome.The grey level conversion is important because,in the grey level,the pixel contains more intensity information and also contains grey shades,which varies from black to white starting from 0 to 255 values.For maintaining luminance value and removing the Hue saturation,RGB coefficients are converted to monochrome(grey-level).A Gaussian window is used to average and smooth the point neighbourhoods.Eigenvalue depicts the gradient signal changes and it is aligned in orthogonal directions.The same level of Eigenvalues points to a corner and the opposite level of Eigenvalues represents an edge.The point of interest in the images is spotted by the corner detector in the proposed model.The importance of this method is used to detect the important points to slice the image regions for the capability of shape formation and to perform the texture analysis.The benefit of this technique is to discover the replicating model and error on the sequence of pixels,which completely conclude the dissimilarities and similarities.Hessian matrix calculation is used to detect the interest points and to find the higher value of determinant,a scheme called blob is embedded.These outcomes give a perfect scale selection in an image transformation,and it is finer than the Laplacian operator.
From Figure 1,the conversion of a query image to a grey level is the initial stage in every CBIR system.Because each pixel in a greyscale image carries intensity information,the suggested technique transformed the colour image to greyscale.These images are also called as monochrome images or black-white,and contain grey hues(black to white)with ranging values(0-255).RGB factor is transformed to monochrome(grey-level)by maintaining the luminance and removing the hue saturation.The Gaussian window is used for the average and smooth point of neighbourhoods.The eigenvalues,which are aligned in orthogonal directions,indicate the gradient signal variations.Equivalent eigenvalues point to a corner,and opposite levels of eigenvalues exhibit an edge.The corner detector is used in the proposed technique to locate the locations of interest in the pictures.This approach is useful because it combines texture analysis with the identification of prominent spots to segment picture areas for possible shape creation.The benefit of employing this method is that it allowsyou to discover repeated patterns and disruptions in a sequence of pixels,allowing you to determine similarities and differences.
4.1|Query image to grey level image
At first,CBIR starts to transform the query image to monochrome (grey-scale) as greyscale images contain intensity information in each pixel.These greyscale images are then termed as monochrome or black-white that contains grey shades (black to white) that change the values from 0 to 255.Grey level statistical feature extraction is one of the popular image texture classification strategy.Texture is observed because of the spatial variations of grey level in the image.When small cells are observed,they produce more frequent grey level changes inducing a finer texture than large cells.A granulometric texture analysis can be obtained by applying mathematical morphology operations directly on grey level images.The proposed CBIR method converts RGB factors to monochrome by removing the saturated hue images for maintaining luminance value in the image.Interest point of detection is detected by using a corner detector,and this method was developed to acquire image regions in the texture of salient image attributes.The distribution of gradient values in the neighbourhoods is shown in Equation (1)

In this Equation (1),δI,δDand Dzdenote derivative,integration scale and differentiation scale,respectively.The direction of the derivate is given asqandr,Gaussian kernel with derivatives are computed usingδD.Each and every image block is enclosed with four sub-blocks.The average monochrome of each and every sub-block at (i,j)th imageblock is explained asa0(i,j),a1(i,j),a2(i,j),anda3(i,j).The filter factors for horizontal,vertical,135-degree diagonal,45-degree diagonal,non-directional edges are labelled asfv(k),fh(k),fd(k),fd(k),andfn(k),respectively,wherek=0,…,3 represents the location of the sub block.The respective edge magnitudesmv(i,j),mh(i,j),md-45(i,j),md-135(i,j),andmnd(i,j) for the (i,j)th image block can be obtained.

Then the max is calculated as
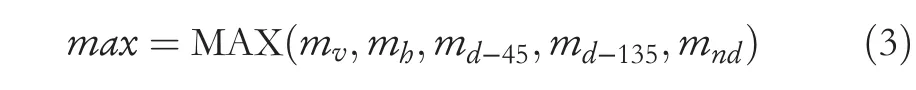
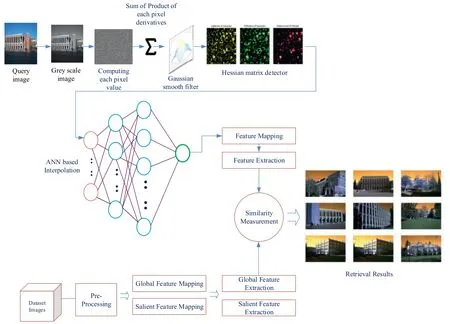
FIGURE 1 Overall architecture of the proposed image retrieval methodology
And normalise allm
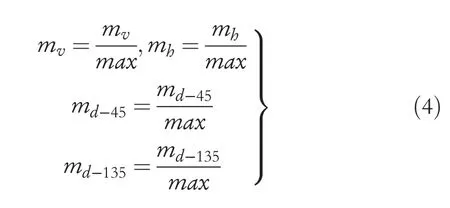
The respective edge magnitudes such as,mv,mh,md-45,md-135,mndare the obtained Image Block.mvdenotes the EdgeHisto (3),mhdenotes the EdgeHisto(2),md-45represents the EdgeHisto (4) andmd-135represents the EdgeHisto (5).The output of the unit that exports the texture's information from each Image Block is given in Equations (2)-(4) of a 6 area histogram,Each area relates to a division thus:Edgehisto (0) Non-Directional Edge,Edgehisto (1) Non Edge,Edgehisto (2) vertical Edge,Edgehisto(3) Horizontal Edge,Edgehisto (4) 135-degree diagonal Edgehisto (5) 45-degree diagonal Edgehisto.The classification of the system in an image block is in the following:At first,the model verifies if the maximum value is greater than the given threshold.This threshold defines when the image block can be sorted as a Non-texture block or Texture block Linear.
4.2|Derivatives computation and smoothing
By smoothening and averaging the point of neighbourhoods,a Gaussian Window has been utilized.Eigenvalues depict the gradient signal changes,and it is determined in an orthogonal format.Opposite levels of Eigenvalues point as edges,and equal levels represent corner.Subsequently,the value intensities generate different edges that are denoted as edge points.The square block of 20 pixels covers each detected interest,and this uses the corner detector to find the point of interest in the images.The spot points of interest in images are used for finding the potential of interest in the images.Texture analysis within the finding of important points segments the image divisions for designing a possible shape generation.Differences between corner scores are calculated for the directions presented in this method.This mechanism is used to find the replicating pattern within the disturbance for series of pixels that compute the similarity value.For detecting the interest point,approximation of Hessian matrix has been used,and similarity measurement leads to the formation of objects,by comparing the properties of colours and brightness in the covering regions and by using the integral images that are adjusted as box lets.For prompt calculation,integral images have been used within the square size convolution filters.By taking an input imageIGall aggregate pixels are represented asI∑(k)at a pointk=(x,y)Twithin a rectangular region as given in Equation (5):
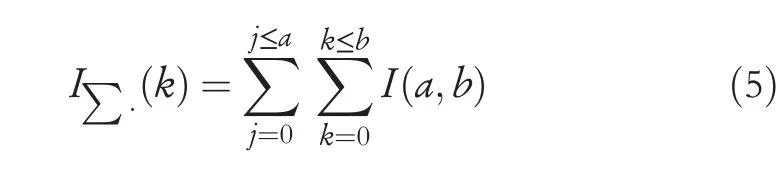
The proposed design used Hessian Matrix to obtain accuracy levels,for any pointk=(a,b) the Hessian MatrixH(k,λ)inkforλis given in the below Equation (6):

In Equation (6),Gaussian based convolution takes place with the second derivative given asCxx(k,λ),Cxy(k,λ)andCxy(k,λ).These derivatives are termed as Laplacians of Gaussians.The box filter consists of Hessian matrix approximation,which is used to check the mathematical cost and approximation for Gaussian second-order derivatives.At different scales,interest points are necessary,as scale spacing is treated in the form of pyramids.The Gaussian image is employed for frequent smoothening and also sub-samples it for making the corners reach the maximum level.Gaussian smoothing is used to perform image enhancement,and it can achieve that at many different levels.This reduces the computational cost by choosing few samples with respect to the kernel size as the final feature vectors will remain to be efficient.This dissimilarity of linear filtering over the spatial domain results in the addition of box filters to the image.By finding the average of its neighbours and generating sharpedged data,one more plus for conventional patterns is adopted along with box filtering and its same mass of attributes.An easy accumulation is produced significantly greater than the sliding window fashion algorithm.Gaussian smoothing becomes faster and suitable.Scale spacing is a technique used to monitor by enhancing the filter size rather than decreasing the image size in the following steps.By approximating Gaussian derivatives,nine squared filters give the output in the scale ofλ.Blob values are calculated at the lowest level using nine squared filters.In order to obtain the outputted layers,the images are filtered with progressive big masks.
4.3|Filtering method and Hessian matrix detector
The parametric smooth kernels with the lowest return values are applied.Scale specification is used to generate the final stage of scaling with high image data,and this can be applied because it is computed from the minimum level of axioms.Convolution is applied by highlighting a sequence of filter actions.As integral images having various attributes,a little difference of scale for the partial second-order derivative is generated in the direction of derivation.Starting and finishing of the Hessian response determine interpolation.Therefore Hessian Matrix determined the interpolation that was applied for image spacing and scaling for the heavy response calculated so,by implementing interpolation,its lesser obtained scale is found to beλ.Requirement of related entry,for each and every time entry,will increase in filter size and gets doubled.Additionally,by raising the accuracy,entries are calculated in a similar way.For calculating the particular image and filter size of the optimal first entry,improved sample rates are applied,hessian matrix maxima determine the interpolated scaling in space width.Interpolation of scale space is particularly important because it is similarly high between starting layers of entries.In the process of scale-space division,in certain cases,values of the pixels are missed and need to be assessed.Interpolation gets induced by approximating the missing intensity pixels from their neighbours.
The scale-space with the form of actual entities for accurate feature vectorgeneration,whichreaches better precision,is done by calculating the missing points from the known data.At this level,the proposed model generates a small number of reflective image signatures that discard the sample.The issues occur atsubsampling,reduction and truncation of the images are approximated using the interpolated results.By reducing the feature vector PCA (Principle Component Analysis) and size,this happens at the stage of applying the cyclic steps and the coefficients of Eigen to compute the main apparatus.An orthogonal conversion with uncorrelated factors are produced from the associated parameters.These calculated and inter-related factors are defined as principal.Maximum variance has been found in the initial component.After that,it gets minimized sequentially.The variables are orthogonal to their earlier one by posing fewer reflections.Usually,a physical model presents a thick sample of stuff,which gets reflected within the related apparatus.These are estimated in given Equation(6)by a function,
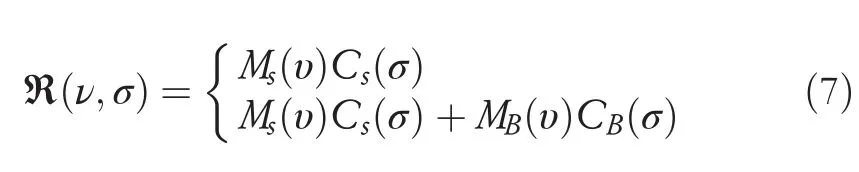
In this Equation (4),υdenotes dependency of angles,and wavelength is represented byσ.In this equation,surface reflection and body reflection are denoted as S and B.Image features are represented by RGB channels,which are the carriers of primary colours.The poposed model efficiently collects colour channel factors along with the monochrome intensities by performing spatial mapping,and these colours will exhibit deep image contents by coupling information with monochrome values that produces a maximum representation of image data.This colour data provides regular stuff,and its position contains spatial adjusts,which solves the expressive correspondence.
4.4|ANN interpolation of image pixels
Interpolation was done using ANN,and it requires low computation that is employed to moving pictures.With the help of a high-resolution image,optical image interpolation and network training have been attained.ANN is presented in the subsection as it follows the execution of image expansion using ANN.ANN is defined as an artificial network that resembles neurons of a living body and guarantees the approximation with different types and also the architecture of ANN.A neuron is a fundamental unit to work with ANN;input signals are given asx1,x2,…,xNand weights of a neuron are given as(w1,w2,…,wN).After adding inputs and weights,S is termed as signal and the neurons’output signal is termed asy.Neurons in ANN are described as given in Equation (8):
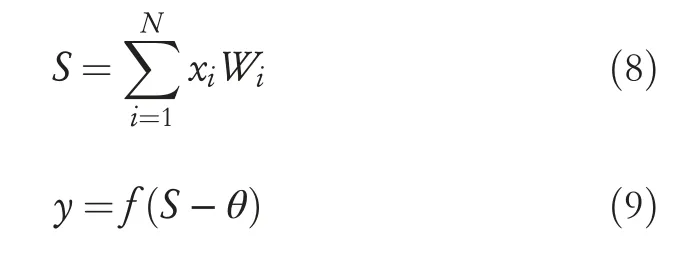
In this equation,θrepresents the threshold value,and activation function is given asf.Activation function is a nonlinear credentially,sigmoid function as shown in Equation(10):
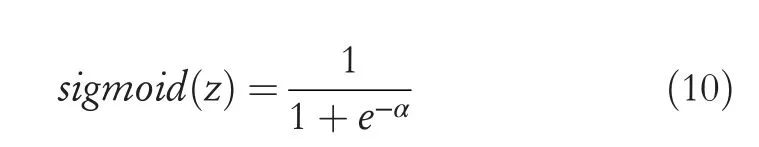
The main target for training such a neural network is to predict synaptic mass that produces the last output as close to the aim for all coaching methods.The backpropagation algorithm is used as a multilayer feedforward training of the network.This algorithm updates the synaptic mass every time when the training pattern is completed.The transformation ratios for interpolated pixels are determined by neighbouring sampled points with the help of the starfish function.The number of input networks is 64(8×8)sampled points.These 64 pixels are defined as grey circles,which are chosen as input networks.Correct values that are compared with output values are chosen from the original image which is a group of 64 pixels and four pixels in a method of coaching set.Next,the training method is produced in the same way as the training set and saved in TS file format.The ANN architecture consists of three layers an input,output layer and a hidden layer.The size of the area is varied to affect the interpolated points.The input layer,which contains a number of neurons,is varied 16(4×4),36(6 × 6),64(8 × 8).For each case,bias is added as an extra input.There are four neurons in the output layer.The number of neurons in the hidden layer fluctuates as 40,45 and 50.The sigmoid function is used as an activation function in both the output layer and hidden layer (Figure 2).
Sigmoid function is normally used to refer specifically to the logistic function also called the logistic sigmoid function.All sigmoid functions have the property where they map the entire number line into a small range such as between 0 and 1,or -1 and 1;so one use of a sigmoid function is to convert a real value into one that can be interpreted as a probability.Sigmoid functions have become popular in deep learning because they can be used as an activation function in an artificial neural network.They were inspired by the activation potential in biological neural networks.Sigmoid functions are also useful for many machine learning applications where a real number needs to be converted to a probability.A sigmoid function placed as the last layer of a machine learning model can serve to convert the model's output into a probability score,which can be easier to work with and interpret.This process consists of a TS file,which is produced in the previous step and used as a training set.The synaptic mass is saved as a WT file after training.For interpolating the pixels in the enlarged image,a process called interpolation is used,and estimation is done using the trained network.In this step,the image is divided into Red,Green and Blue planes,and these planes are estimated individually using the same trained network.At last,a 24-bit bitmap image is formed by integrating the RGB planes and saved as an IMG file.As a result,the image is enlarged twice.
4.5|Extraction of image features
Colour is one of the most important features of images.Colour features are defined as a subject to a particular colour space or model.Once the colour space is specified,colour features can be extracted from images or regions.Texture is a very useful characterization for a wide range of image.It is generally believed that human visual systems use texture for recognition and interpretation.In general,colour is usually a pixel property while texture can only be measured from a group of pixels.A large number of techniques have been proposed to extract texture features.Based on the domain from which the texture feature is extracted,they can be broadly classified into spatial texture feature extraction methods and spectral texture feature extraction methods.Shape is known as an important cue for human beings to identify and recognize the real-world objects,whose purpose is to encode simple geometrical forms such as straight lines in different directions.The most important and inborn image feature is colour that has some stability.The image gets an issue due to the change in the noise,orientation,resolution and size,but colour has a very strong sturdiness.The colour features of an image in this paper is derived from the colour moments in RGB space,and this will represent the colour distribution in each image.Colour moments have major advantages.The lower order moment mainly represents the distribution of colours.This paper consists of four moments for each colour channel (t=R,G,B) that can be connected as standard deviation (ri),Skewness (hi),average (li) and kurtosis (ci).R,G and B are the planes used to extract thefour features for RGB colour space from each plane.The formulas for the given moments are shown in Equations (11)and (12).
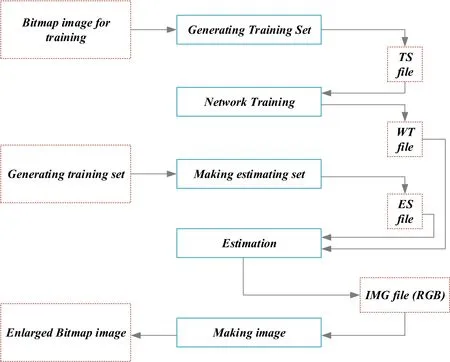
FIGURE 2 Process of interpolation using artificial neural network

wherePijis considered as the value of each colour channel atjth image pixel,the total number of pixels per image isM×N.While retrieving images,the thickness and density of an image will comparatively have a high difference.The texture feature is used as an effective method,which is called a global feature that explains the surface behaviour of an area according to the goal.The regional characteristics have greater advantages that occur only on pattern matching problems.These characteristics will not be influenced by any local deviations.Usually,it has strong sturdiness and rotational invariance for noise.The most primitive approach for extracting the feature from the texture is made by using the statistical models,and this requires a lot of computational time and storage devices.Therefore,discrete cosine transform (DCT) is used for image texture feature extraction [25].At first,the query image is converted to a monochrome version,and it is divided into 8× 8 blocks,and for each block,DCT is applied individually.The feature of the texture vector is acquired from certain DCT factors.For each pixel,the DCT calculation is shown in Equation (13).
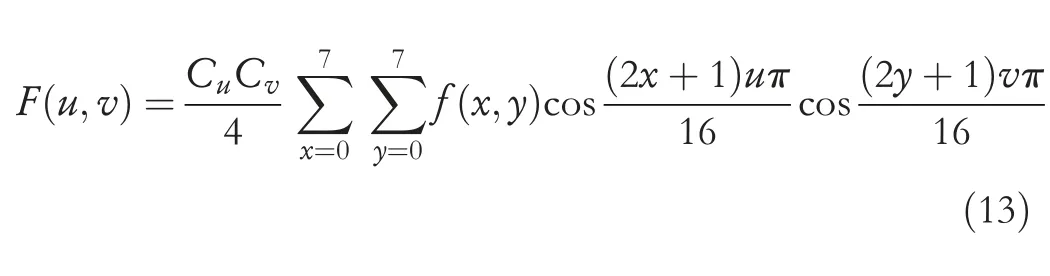
In Equation (10),f(x,y) is termed as pixel value at (x,y)coordinates the position in 8 × 8 block,F(u,v) is termed as DCT domain illustration off(x,y),uandvillustrate vertical and horizontal frequencies,respectively.
4.6|Extract salient region
An image's main content that can be roughly described by a salient area of an image is a main issue for the proposed model.After performing the process of image slicing by using the c-mean clustering depending on the colour features and texture of an image,the image will be obtained in many areas.An easy approach is used to extract the important area.Consider thatWiof theith area is given in Equation (14):
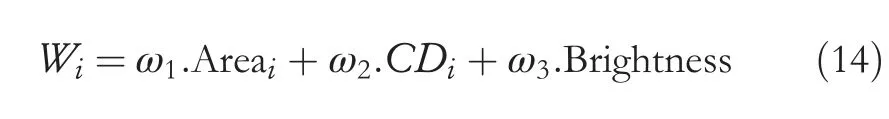
The weight of theith area is represented asWi,the area that consists of the highestWis considered as a salient area.ω1;ω2;ω3are the weights;Areai,CDiand Brightness are areas,the brightness of theith region and centre degree(CD),respectively.For calculating the similarity between salient regions,shape is an important feature.Nowadays,many systems based on image retrieval are working with shape features.However,most system performances are not satisfactory,and there are three main problems.
Shape features for the image retrieval model usually lack the absolute mathematical model.The potential of an image retrieval model is irregular for a certain period of time because of the target deformation.The shape features are represented by the target's shape information,which is not completely constant for human visual recognition.This is because of the difference between the similarities in feature space and the human visual system.So,that the proposed model is limited only to rely on shape features,and also people are not sensitive to the variation of scaling,and targets shape.The shape feature will appropriately become sturdy for transformation,scaling and rotation.This makes it difficult for similarity calculation.
4.7|Calculate similarity between the salient regions

Step1QandMbeLQandLM.These are imagined to the length of the principle axis.To check the similarities ofQandM,the value of the feature denoted asMwill be scaled according to the proportion of sizeQas well asM.Consider the scaling factor to be¼LQ=LM,Q’sshape feature value is telescopically calculated as given in Equation (15) [27]:
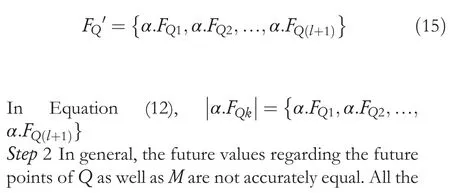
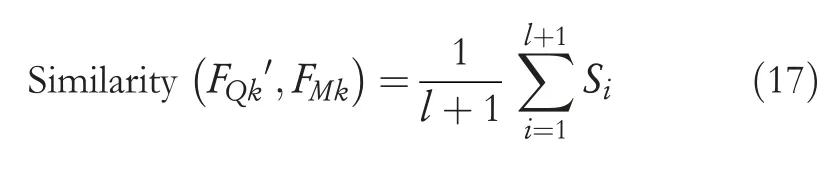
The proposed model not only uses the low-level features like texture and colour for an image to segment into many areas for extracting the important area of an image but,it can also acquire the features of the shape from an image by using the important areas (Figure 3).Calculating the shape feature from the similarities can be used to apply CBIR.The entire working procedure of the proposed work is shown in Figure 4.Steps for the research work:
1.The proposed work will capture and examine the overall image data,which contains colour,object,texture,spatial information and shape that generates the maximum recall and precision rates.
2.Introduction of a weightless feature description and detection system that effectively retrieves the related outcomes from cluttered and complicated datasets.
3.The innovative fusion method of an image is merged by arranging the spatial coordinates with earlier candidates.
4.This newly invented model performs scaling,interpolation and suppression together for obtaining the details of the vastly improved image data.
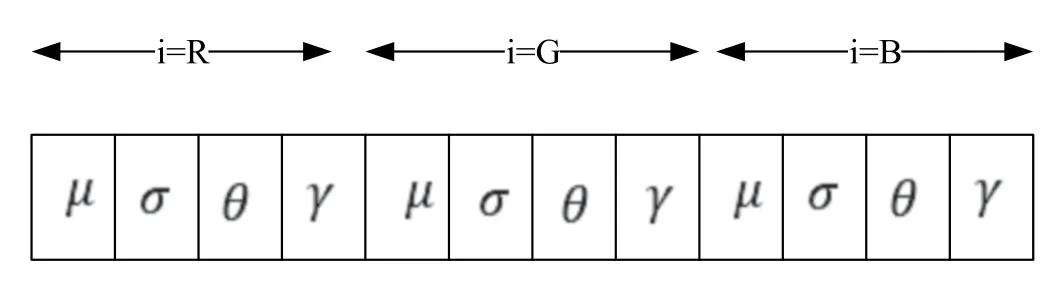
FIGURE 3 Colour vector
5.To acquire a proper difference,a novel system is produced with spatial colour mapping to point out the stuff.
6.A novel method is exhibited successfully,which gives back an extraordinary presentation on a small object,complex background objects,similar textures,enlarged/resized images,cluttered patterns,and colour dominant arrangements,mimicked,ambiguous overlay objects,cropped objects and occluded.
7.The potential of the proposed model is used to unveil the related image information from anchor translation instead of entire image repetition.
8.An ideal technique that acts over colour and grey level channels at the same time to react at the uniform data illustration method.
9.A computation,storage efficiency and time retrieval system is produced,which retrieves the outcomes in a minimal amount of time.
10.A novel invention to collect the power of a normally scaled feature,which contains a large number of words in architecture,is used to stimulate classification and indexing.


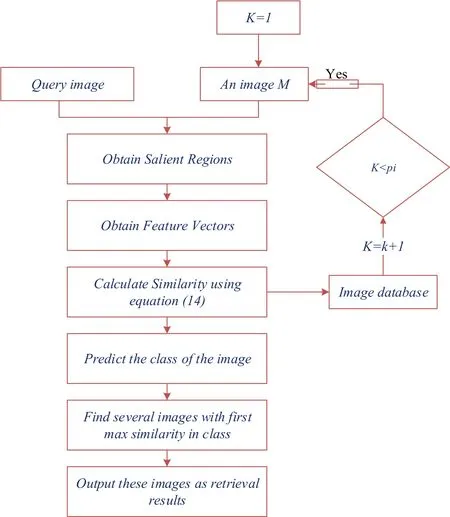
FIGURE 4 Flow chart for the proposed image retrieval system
FIGURE 5 Images from dataset

FIGURE 6 Output images from Gaussian filter

FIGURE 7 Resized images
5|RESULTS
CBIR-SMANN method initially converts query image to grayscale,then performs Gaussian filtering,;the hessian detector is used to detect corners,and an interpolation value was found using ANN.These values are set up as a class,compared with database images using similarity measurement,and then retrieved from the database.For appropriate image retrieval,choosing a dataset has been a critical task.This results in a proportional precision with image attributes such as colour,occlusion,size,quality,location and cluttering.Experiments were performed in the dataset that was a public access dataset that contains 1000 images with 15 classes.Images in this dataset are of dissimilar pixel sizes and in JPEG format.Experimentation is carried out,and its implementation is done in the working platform of Python 3.7 processor -Intel i5 with 16 GB RAM and 4 GB graphics processor.For GPU analysis,the input images are tested on an i3 processor with 4 GB RAM and NVIDIA GeForce GTX 1650.The proposed method is validated and tested outcomes are compared with the existing techniques such as IRFSM [28],Sketchbased Image Retrieval by Salient Contour (SBIR) [29],Image Retrieval Scheme using Quantized Bins of Colour Image Components and Adaptive Tetrolet Transform (IRQBCI) [30] and Greedy Learning of Deep Boltzmann Machine (GDBM)'s Variance and Search Algorithm for Efficient Image Retrieval (GDBM-IR) [31],considering metrics like accuracy,precision,recall,F-measure,and retrieval time.Some of the sample images in the dataset are displayed below figure (Figure 5).
Images are then considered from the public dataset,these images are then allowed to Gaussian filter,and these filter outputs are presented in Figures 6 and 7.
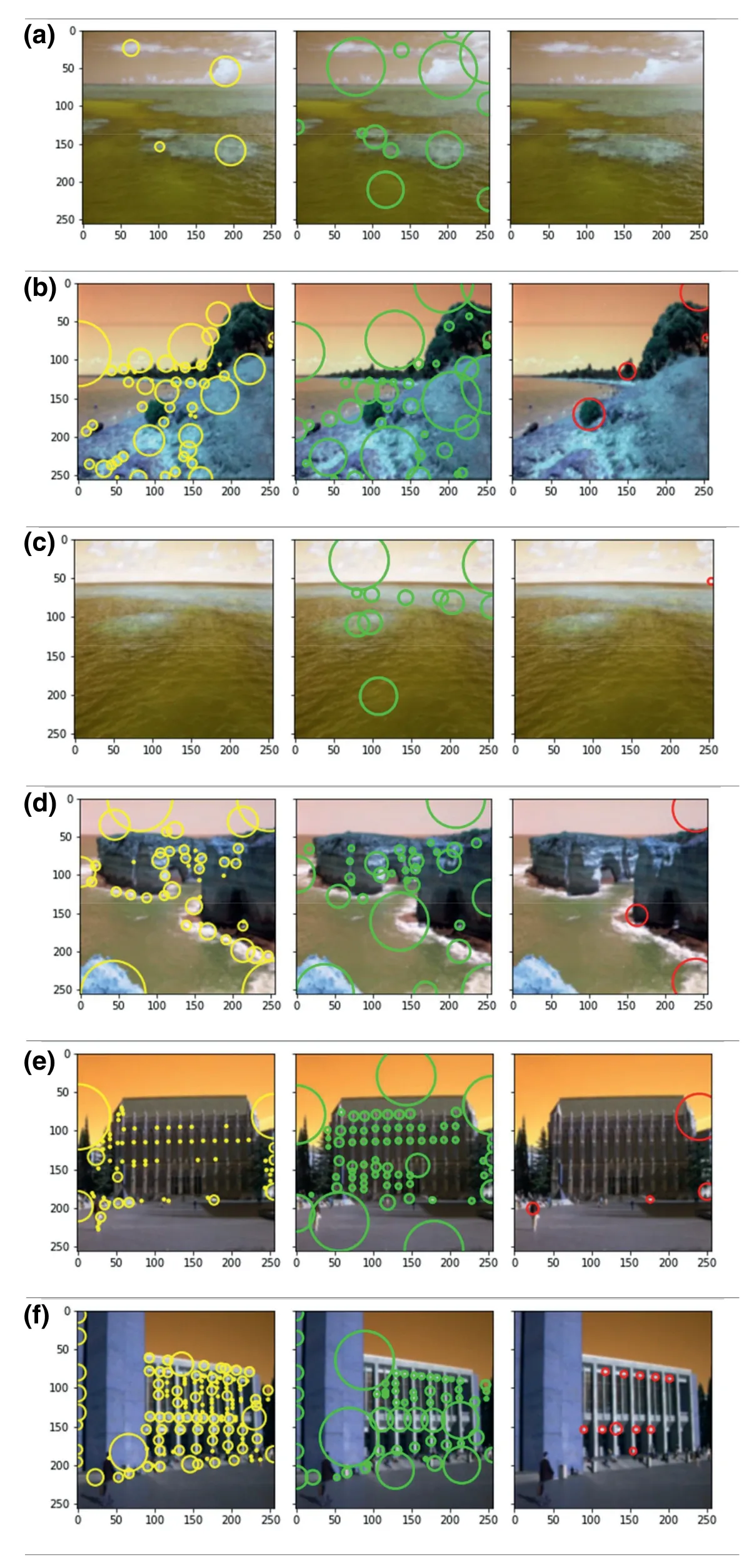
FIGURE 8 Hessian detector matrix
Images are then resized to perform classification,the classified result of ANN values are then saved to perform similarity measurement.
Hessian matrix detectors are used to perform detection in the images.These images are then compared to the query image to find the relevant images for output (Figure 8).
At the final stage,the query image that has been entered gives a customized,relevant image as output.Query image and its respective relevant images retrieved are shown in Figure 9.
Figure 9 shows the experimental result against each query image for every input.The accuracy of the proposed CBIRSMANN has been calculated by applying different measures.

FIGURE 9 Content-based image retrievalsimilarity measure via artificial neural network retrieval images

TABLE 1 Comparison table
5.1|Evaluation metrics
The efficiency of the proposed image retrieval system is evaluated based on performance attained by feature extraction,classification rate,and similarity measurement.In this sub-section,some of the major evaluation metrics like accuracy,precision,recall,and F-measure are adopted not only to validate the effectiveness of the proposed methodology but also for showing the stability of results.When the accuracy metric is around 100,the retrieval system achieves the best performance and presents the system as an ideal technique for recovering a relevant picture collection,which is assessed by the number of photos recovered properly.
Table 1 illustrates the comparison analysis of performance metrics among the proposed model as well as the existing models.The proposed technique is CBIR-SMANN that is compared with several techniques such as,IRFSM,SBIR,IR-QBCI and GDBM-IR.The retrieval time is calculated on the basis of time taken for retrieving relaxant relevant images related to query and database information.It is measured in terms of seconds,and the obtained values for retrieval time are graphically plotted in the below graph.It is a well-known fact that when the retrieval system takes less time for retrieval,then automatically,the proposed model performance will get enhanced.By accepting the given fact,the proposed model performs well by acquiring the smallest retrievalvalue.The proposed model attained a retrieval time of 980 ms and the IRFSM model attained a retrieval time of 2000 ms and the SBIR model attained a retrieval time of 1800 ms and the IR-QBCI model attained a retrieval time of 1150 ms and the GDBM-IR model attained a retrieval time of 1100 ms.
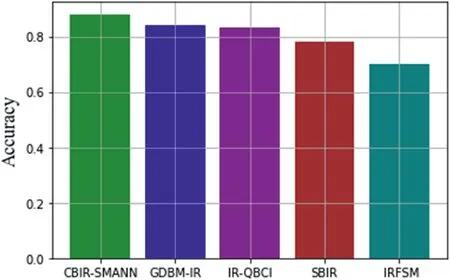
FIGURE 10 Accuracy level of retrieval
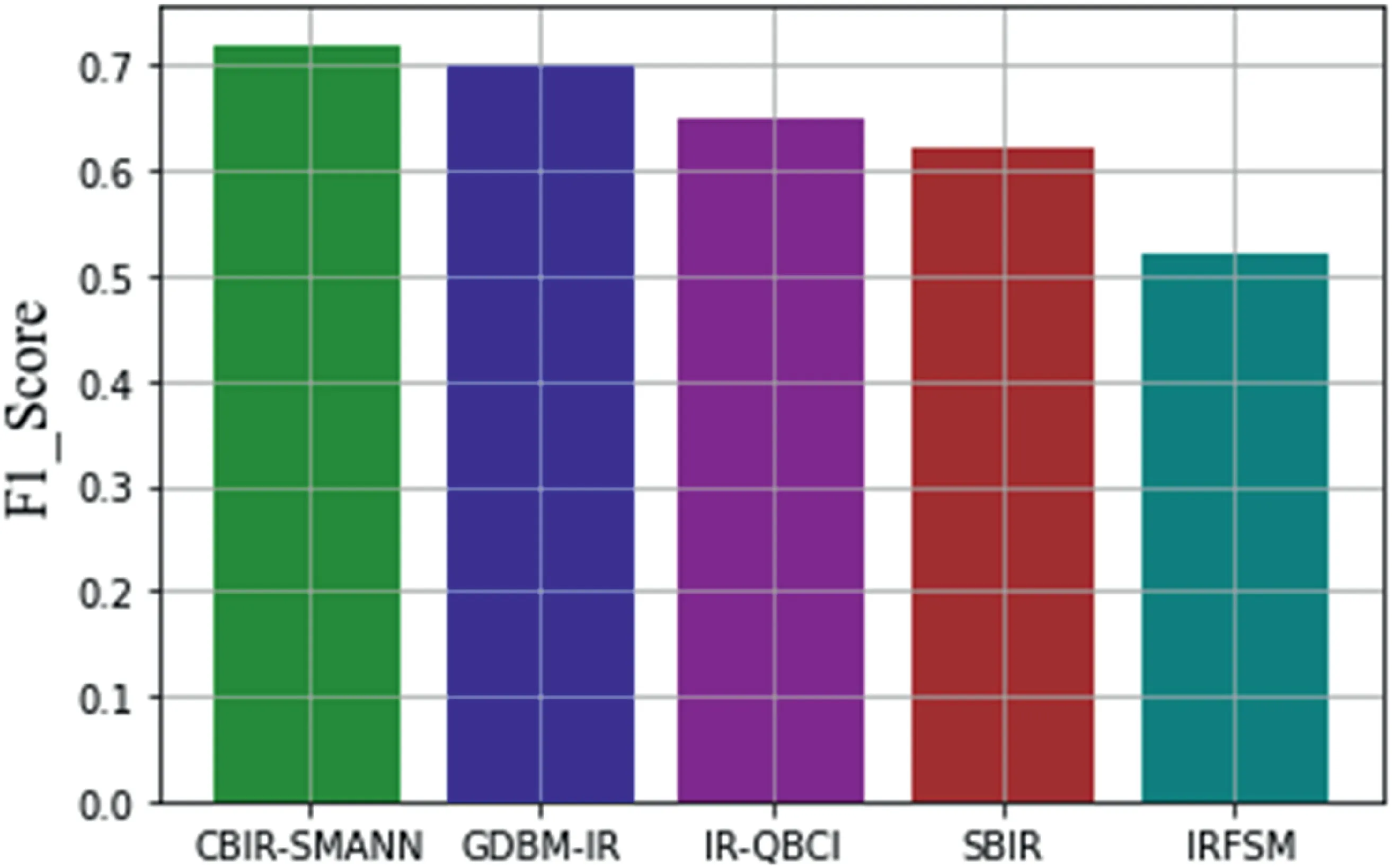
FIGURE 11 F1_score level comparison with previous techniques

FIGURE 12 Error value comparison graph
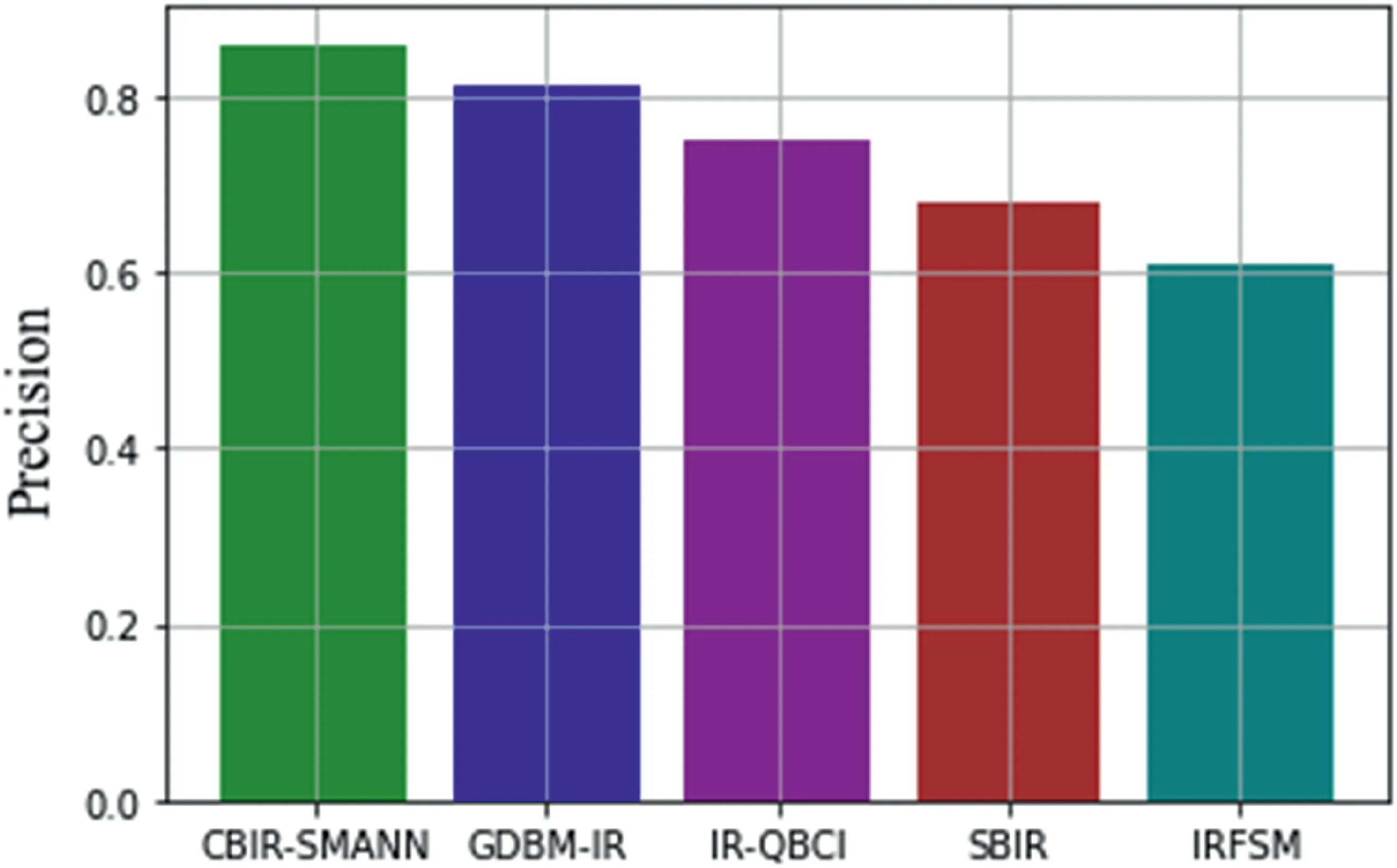
FIGURE 13 Precision value comparison with previous techniques
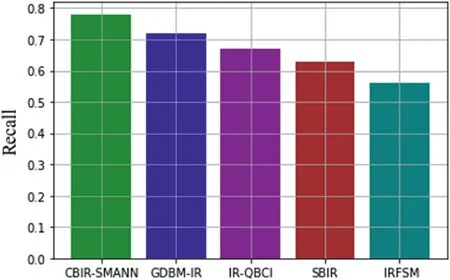
FIGURE 14 Recall value comparison with previous techniques
From this Figure 10,it has been seen that the proposed CBIR-SMANN has given a high level of accuracy than that of previous techniques.Previous methods such as GDBM-IR,IR-QBCI,SBIR and IRFSM are given accuracy levels below the proposed model.As CBIR-SMANN achieved 88% of accuracy due to the use of ANN to find an interpolation technique,GDBM-IR gives 82%,IR-QBCI attained 81.5%,SBIR attained 79% and IRFSM attained 70% of accuracy level due to its low capacity of retrieval of images.The obtained f-measure function attained is higher for the proposed approach;hence it shows a better outcome for the proposed retrieval system.Likewise,the calculated loss function is provided in the subsequent section.
From Figure 11,it can be seen that the proposed CBIRSMANN have given a high F1 score value.These values are in the range of 71% which are also higher than that of the previous techniques.GDBM-IR is given a value of 70% of F1_score,IRFSM shows lower values than any other previous methods such as,GDBM-IR which gives 70%,and IR-QBCI attained 65%,SBIR attained 62% and IRFSM attained 53%of F1_score.Thus the proposed CBIR-SMANN value performed better than the other methods.
Comparing the error values shows that the proposed CBIR-SMANN has given minimum error values during execution (Figure 12).Previous methods such as GDBM-IR have given an error value of 16%,IR-QBCI gives an error value of 17%.SBIR gives a high value of 23%,and finally,IRFSM gives a very high error value of 30%.Finally the proposed model gives an error value of 11% that was an efficient one.
The ratio of recovered relevant images to the total retrieved image query is known as precision.Precision measurements are compared with previous methods shown in Figure 13.
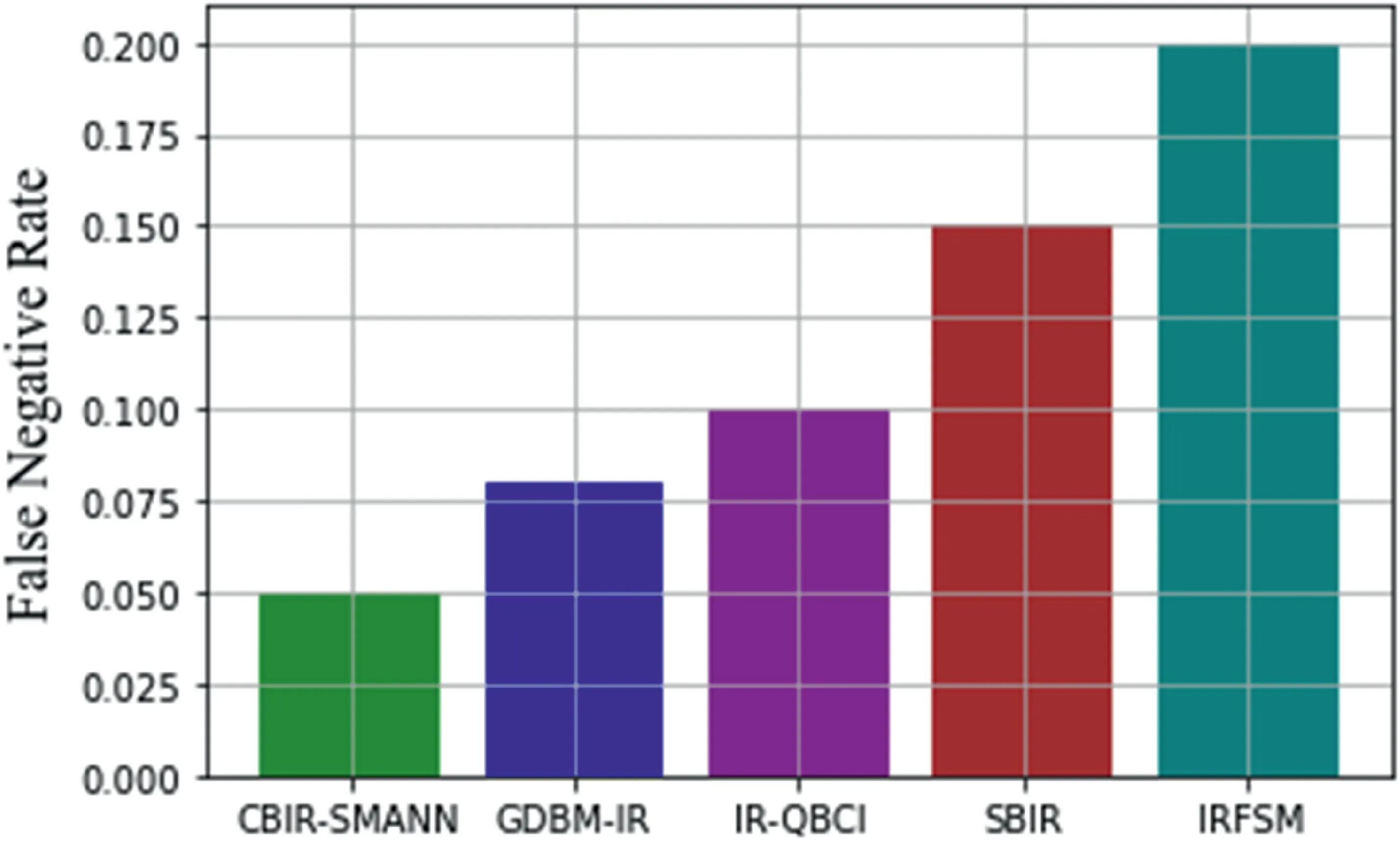
FIGURE 15 False Negative rate comparison with previous techniques
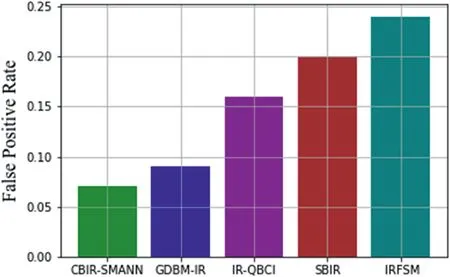
FIGURE 16 False positive rate comparison with previous techniques
From Figure 14,it has been seen clearly that the proposed CBIR-SMANN has given a high precision value than that of other methods.GDBM-IR has given a low range of precision values which ranged from 81%,IR-QBCI has given a precision value of 70%.SBIR continued to give a precision value of 70%.IRFSM showed the minimum value of precision that is 60%.Overall,CBIR-SMANN gives a higher precision value of 82%.
In image retrieval,recollect is termed as the proportion of recovered related images to the complete database images.Recall values show the efficiency of the system,as for proposed CBIR-SMANN have given the recall values at a range of 78%,GDBM-IR has retrieved images with respect to recall value of 68%.SBIR gave a recall value of 62%,and the least recall values are given for the IRFSM technique at a range of 53%.Proposed CBIR-SMANN succeeds in a high recall value that has been shown in Figure 14.
A false negative error,often known as a false negative,is a test result that implies that a condition does not exist when it does not.From Figure 15,it has been clearly visible that the CBIR-SMANN has taken a false negative rate of 0.050,GDBM-IR has shown a false negative rate of 0.075 value.IRQBCI has taken a false negative little greater than 0.100 value,and also SBIR took a greater value of 0.150 value.Finally,IRFSM has taken a greater value of 0.200 range.Thus,proposed methodology has given a minimum false-negative rate value.A false positive occurs when a test result mistakenly shows the existence of a condition,such as an image,when the query relevancy is not present as shown in Figure 16.
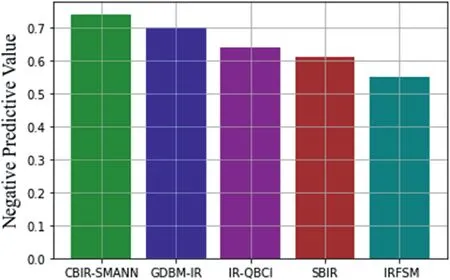
FIGURE 17 Negative predictive value compared with previous techniques
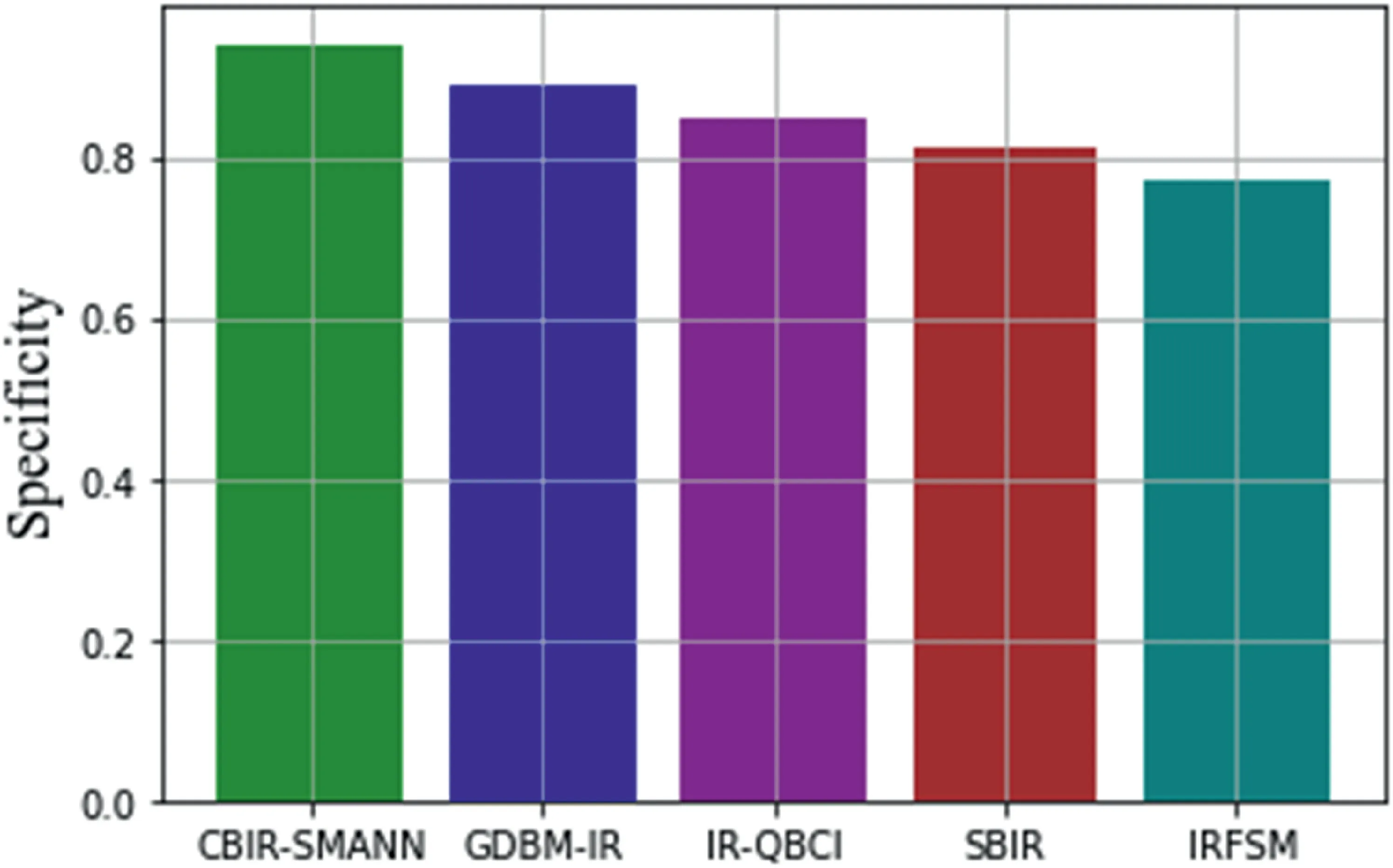
FIGURE 18 Specificity value comparison with previous techniques
The average results of each/all queries are used to measure the performance.It is carried out at four different schemes to guarantee a fair comparison.The chance that images with a negative screening test do not have the disease is known as a negative predictive value,as shown in Figure 17.Figure 17 shows that once again,the proposed CBIR approach outperforms other approaches.
From Figure 17,it has been understood that the negative predictive value for the proposed model has been high than other previous techniques.CBIR-SMANN gives 75%of negative prediction that has been healthy than other methods.Others like GDBM-IR and IR-QBCI give 70%and 62%of the value.SBIR techniques have given a negative predictive value of 61%,then IRFSM showed a negative predictive value of 55%.
The proportion of people who do not have the respective image as determined by the one who obtained a negative response on this test is referred to as specificity.From Figure 18,it has been compared with previous methods that CBIR-SMANN gave specificity values of 91%that were higher than GDBM-IR,SBIR,IRFSM and IR-QBSI.Thus the proposed CBIR-SMANN has succeeded to produce high specificity values at the end.Finally,the overall performance evaluation shows that the proposed CBIR-SMANN have better performance than other conventional ones.
6|CONCLUSION
CBIR-similarity measure through artificial neural network interpolation (CBIR-SMANN) is a technique proposed in this study.The pictures are scaled,then subjected to Gaussian filtering in the pre-processing step,and finally,the interesting points are gathered by allowing them to pass through a Hessian detector.The mean,kurtosis,and standard deviation characteristics were retrieved using Skewness and then passed to ANN for interpolation.The interpolated results are saved in a database and may be retrieved at any time.During the testing step,a query picture was provided,which was preprocessed and featured extracted before being supplied to the Similarity measuring function.As a result,ANN aids in the retrieval of comparable pictures from the database.CBIRSMANN had a high recall value of 78% and a minimal retrieval time of 980 ms,according to the results.The specificity values of 91% give 75% of negative prediction that was higher than the previous ones.The outcomes of the experiment result in highly acclaimed benchmarks,which explains that the provided method yields a great performance when it is compared to benchmark descriptors and research approaches.This results in shape features,and fused spatial colour can specifically retrieve the images from colour,shape,object datasets and texture.An addition to the provided work will be integrating the convolution network to acquire more enhanced outcomes.
CONFLICT OF INTEREST
There is no conflict of interest between the authors regarding the manuscript preparation and submission.
DATA AVAILABILITY STATEMENT
Data sharing is not applicable to this article as no new data were created or analysed in this study.
ORCID
Faiyaz Ahmadhttps://orcid.org/0000-0002-2222-3307
 CAAI Transactions on Intelligence Technology2022年2期
CAAI Transactions on Intelligence Technology2022年2期
- CAAI Transactions on Intelligence Technology的其它文章
- Matrix‐based method for solving decision domains of neighbourhood multigranulation decision‐theoretic rough sets
- Feature extraction of partial discharge in low‐temperature composite insulation based on VMD‐MSE‐IF
- Wavelet method optimised by ant colony algorithm used for extracting stable and unstable signals in intelligent substations
- Efficient computation of Hash Hirschberg protein alignment utilizing hyper threading multi‐core sharing technology
- Improving sentence simplification model with ordered neurons network
- Demand side management for solving environment constrained economic dispatch of a microgrid system using hybrid MGWOSCACSA algorithm