
融合规范化判断的双向循环神经网络诊疗预测模型
2022-05-27 00:41闫玉芳曹吉龙高延军
小型微型计算机系统 2022年6期
赵 奎,闫玉芳,曹吉龙,高延军
1(中国科学院 沈阳计算技术研究所,沈阳 110168)
2(中国科学院大学,北京 100049)
3(中国医科大学 附属第四医院,沈阳 110032)
1 引 言
宫颈癌是仅次于乳腺癌的女性高发疾病之一[1],其临床诊疗过程复杂.专家设计的宫颈癌临床诊疗路径(如图1所示)是基于循证医学构建的标准化、程序化诊疗模式,其核心为“在恰当的时间进行恰当的诊疗项目”,临床路径往往将宫颈癌的诊疗过程分为若干阶段,每个阶段都有所需的诊疗项目.采用规范化的诊疗过程,能够有效提升治疗效果、降低医疗成本、规范诊疗行为.但是,专家制定的宫颈癌临床路径在很长一段时间内固定不变,难以适应不同医院以及情况复杂多变的宫颈癌患者的需求,导致临床路径的变异率极高.与此同时,医生在为宫颈癌患者制定每一阶段的治疗方案时需要考虑多方面的信息,例如:宫颈癌分期、是否保留生育功能、淋巴脉管间隙浸润、影像学分期等多种因素,其决策过程复杂,医生往往基于历史经验,或者将当前患者与相似的历史病历建立关联,在临床诊疗规范的指导下做出决策.显然,医生在为宫颈癌患者制定诊疗方案的过程受自身医疗水平的影响,具有极强的主观性,并且很难在症状多变的情况下按照临床诊疗规范进行诊疗,影响宫颈癌患者的预后.同时,对于经验不足的年轻医生而言,很难在短时间内做出准确的决策,影响治疗的效果.
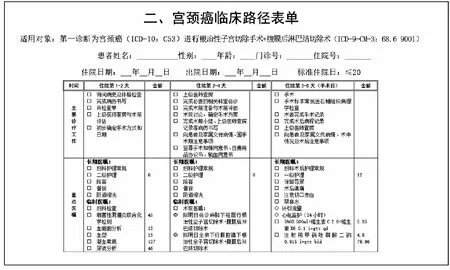
图1 宫颈癌诊疗规范
随着人工智能技术的发展,以及海量医疗数据的积累,越来越多的研究人员在医疗领域展开了研究.
为了提高医疗质量、规范医生的诊疗行为,一些研究人员在模式挖掘方面做了深入的研究.徐啸等人,提出了一种基于优化主题模型的临床路径挖掘算法,保证了相似诊疗日具有相似的主题分布,从而挖掘出高质量的诊疗模式[2].黄浩未等人,提出了一种基于条件概率的临床事件打包算法,用条件概率衡量事件之间的关联程度,将达到一定关联程度的事件进行打包,简化了挖掘的诊疗过程模型[3].李抒音等人,提出了一种带权重的规则挖掘算法,调节了规则集的数量和复杂程度,使得算法的精度更高.
在诊疗预测方面,王露潼等人,基于LSTM建立了FT-LSTM模型,在传统LSTM的基础上添加了时控门,以更好的捕获临床事件之间的潜在关系,从而更准确的对临床事件进行预测[4].Lu Wei-jia等人,基于LSTM提出了临床预测模型以预测临床事件,临床事件间的时间间隔不同是时间序列预测任务的极大挑战,文中采用果蝇优化算法对该任务中的参数进行优化,提高了网络的训练效率和预测精度[5].吕晴等人,提出了一种图像与文本结合的预测方法,相较于仅基于文本或图像进行预测,模型的准确率和召回率均有明显的提升[6].张驰名等人,提出了基于迁移学习的预测方法,针对医疗数据缺失问题,提出渐进式微调策略[7].
然而,大多数研究人员在进行诊疗项目预测时,只是基于历史诊疗记录进行诊疗项目预测,未考虑历史诊疗过程是否符合规范的诊疗模式.研究表明[8],在对宫颈癌患者实施临床路径规范后,降低了医生出差错的概率,能够有针对性的对医生在诊疗过程中出现的问题进行预防.
针对过往研究中所存在的不足,本文提出了一种基于Bi-GRU的诊疗预测模型.在对未来诊疗项目预测前,首先判断历史诊疗过程是否规范,将符合规范诊疗模式的诊疗记录输入到诊疗项目预测模型中,预测未来诊疗项目发生的概率,辅助医生制定诊疗方案.
本文提出的预测方法在以往的研究成果的基础上,主要贡献如下:
1)宫颈癌患者的住院数据具有部分时序性特征,对于同一天的诊疗记录不区分发生的先后顺序,本研究中对同一天的诊疗记录采用加权池化的方式处理;
2)宫颈癌患者住院过程的诊疗记录时间分布不均匀,本研究在原有数据的基础上融入了时间间隔,提高了诊疗项目预测精度;
3)提出了两段式模型,在规范的宫颈癌诊疗数据集中挖掘诊疗模式,满足了临床路径的个性化需求,以此作为衡量历史诊疗过程是否规范的标准,达到了规范医生诊疗行为的目标.预测诊疗项目之前,首先对历史诊疗过程进行规范化判断,针对规范的诊疗过程预测诊疗项目发生的概率,辅助医生制定下一步的诊疗方案.
2 宫颈癌诊疗项目预测流程
2.1 相关定义
定义1.诊疗项目:将电子病历中的用药、医嘱和实验室检查项目称为诊疗项目.
定义2.诊疗日:在患者住院过程中,将存在诊疗项目的日期称为诊疗日.
定义3.诊疗记录序列:发生在同一诊疗日的诊疗项目构成诊疗记录集合,住院过程中全部诊疗记录集合构成诊疗记录序列.用vi表示诊疗日的第i个诊疗项目,et={v1,v2,v3,…,vn}表示第t个诊疗日的诊疗项目集合.用E={e1,e2,e3…,eT}表示诊疗记录序列,即患者一次完整的住院过程.
2.2 预测流程
基于Bi-GRU的宫颈癌诊疗项目预测流程如图2所示.
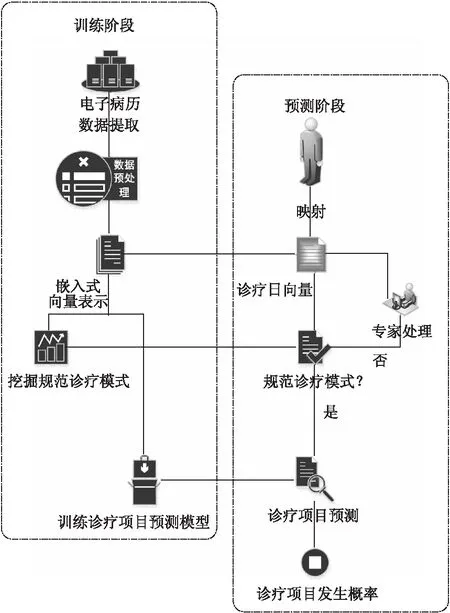
图2 预测流程图
在训练阶段的具体步骤为:
1)数据提取:在宫颈癌患者的电子病历中提取出诊断记录、用药、医嘱以及实验室检查项目,其中用药、医嘱以及实验室检查项目作为诊疗项目;
2)数据预处理:统计所有诊疗项目的数量,按照独热码的形式对诊疗项目进行编码,对发生在同一诊疗日的项目进行加权池化处理,表示为诊疗项目集合;
3)嵌入式向量表示学习:用Skip-gram算法学习不同诊疗日之间诊疗项目集合的潜在关系,将每一个诊疗日的诊疗项目集合转化成诊疗日嵌入式向量表示;
4)挖掘规范诊疗模式以及训练诊疗项目预测模型:从诊疗记录序列的嵌入式向量表示中挖掘规范的诊疗模式,并训练诊疗项目预测模型.
在预测阶段的具体步骤为:
1)将待检测的诊疗记录序列利用Skip-gram算法转化成诊疗日的嵌入式向量表示;
2)然后判断待检测的诊疗记录序列是否符合规范的诊疗模式,即以待检测的诊疗记录序列和规范的诊疗模式之间的余弦相似度作为判断标准;
3)若待检测的诊疗记录序列符合规范的诊疗模式,将待检测的诊疗记录序列输入到诊疗项目预测模型中,预测下一阶段的诊疗项目,得到诊疗项目发生的概率;否则交由专家处理.
3 模型结构
3.1 基于Skip-gram的向量表示模型
收集的电子病历中的数据无法直接用于挖掘规范诊疗模式以及诊疗项目预测任务中,本研究用Skip-gram[9,10]算法将电子病历中的记录转化成具有临床意义的向量,其模型如图3所示.
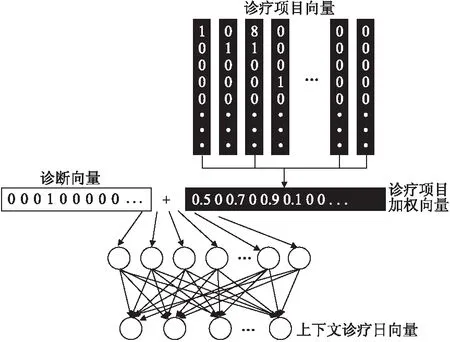
图3 向量表示模型
由于宫颈癌患者的住院数据具有部分时序性的特征,发生在同一天的诊疗项目不区分先后顺序,因此对同一天的诊疗项目采用加权池化的方式进行处理,同时和诊断向量拼接得到诊疗日向量e′t,如式(1)所示:
(1)
其中,n表示一个诊疗日内诊疗项目的数量,vi表示诊疗日的第i个诊疗项目,wi表示该诊疗项目对应的权重,dt表示第t个诊疗日的诊断向量.
在诊疗记录序列中采用滑动窗口的方法,依次选择目标诊疗日向量,利用Skip-gram算法预测其上下文诊疗日向量,将隐藏层的权重作为目标诊疗日的向量表示,即目标诊疗日向量由其时间上紧密共现的诊疗日向量表示,从而更有效的提取出诊疗日向量中隐含的丰富的医学信息.
Skip-gram算法的目标是最大化对数似然函数,如式(2)所示:
(2)
其中,T表示诊疗记录序列的长度,即诊疗日的天数,w表示滑动窗口的大小,条件概率p(e′t+j|e′t)用softmax函数定义,如式(3)所示:
(3)
其中,V(e′i)表示e′i的嵌入式向量表示,N表示诊疗项目总数.
3.2 基于二分K-means算法的诊疗模式挖掘方法
3.2.1 诊疗模式挖掘方法
由专家制定的临床路径,即规范的诊疗模式,难以满足临床的个性化需求,变异率非常高,不能作为判断诊疗过程是否规范的标准.因此本研究在已规范化处理的数据集中挖掘宫颈癌的诊疗模式,以此为基础,来判断患者的诊疗过程是否规范.
本研究中采用二分K-means算法挖掘规范的诊疗模式,该算法用无监督的方法将规范化的诊疗记录序列划分为多种诊疗模式,每一种诊疗模式由特征相似的诊疗记录序列组成.诊疗模式挖掘算法见算法1.
算法1.诊疗模式挖掘二分K-means算法
输入:M条规范化的诊疗记录序列构成的数据集,X={E1,E2,E3,…,EM}.
输出:K个簇
ClusterList ← X;ClusterCount ← 0
whileClusterCount < K :
lowest_SSE ← inf;
foreachCi∈ClusterListdo:
对当前簇Ci进行K-means聚类(K=2);
计算划分后的cur_SSE;
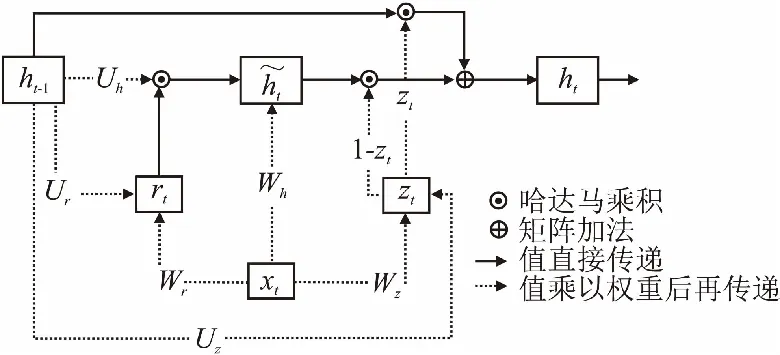
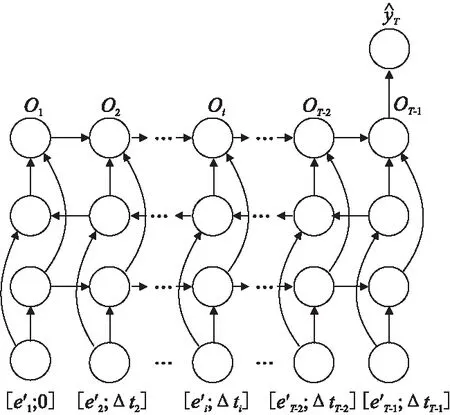
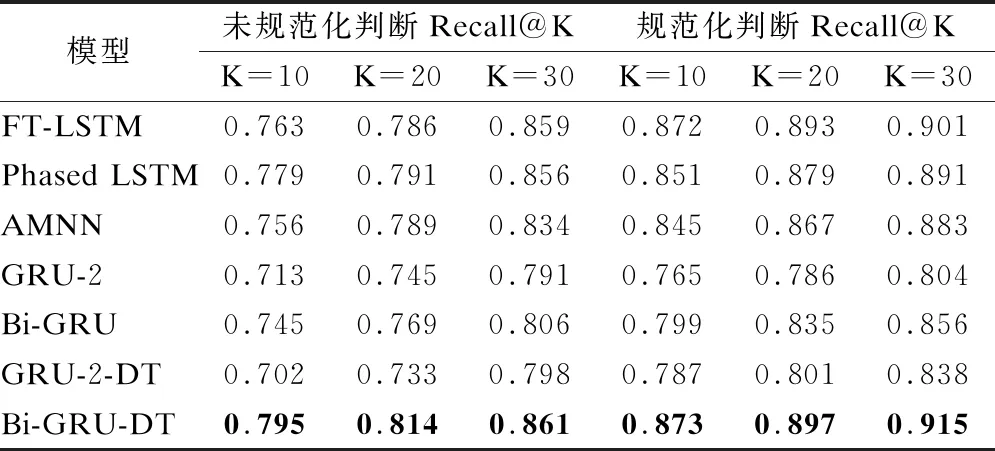
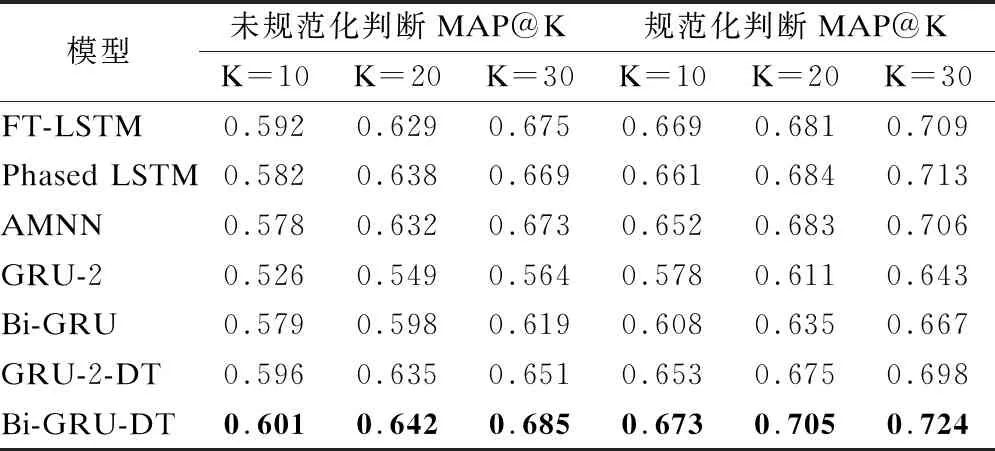
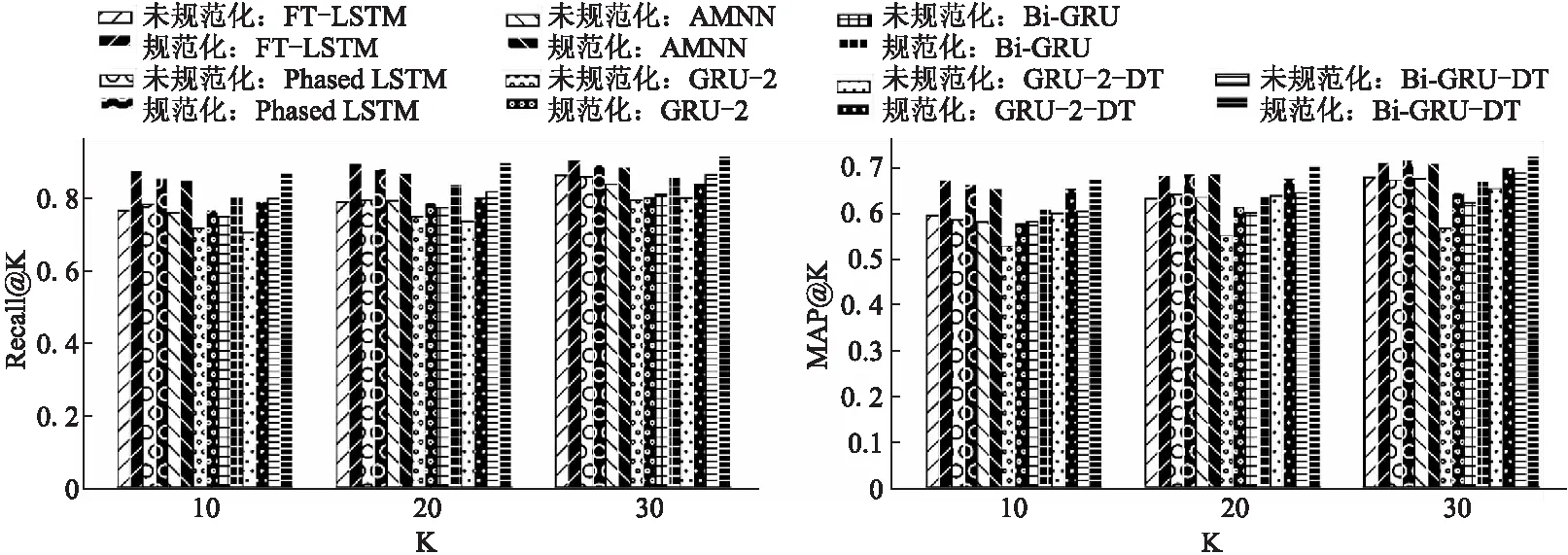
ifcur_SSE lowest_SSE ← cur_SSE; 保存当前簇Ci和聚类后的簇; endif; endfor; 将保存的簇更新为聚类后的簇; ClusterCount ← ClusterCount+1; endwhile. 算法1中,用误差平方和(Sum of Squared Errors,SSE)作为簇中样本相似程度的度量标准,SSE表达式如式(4)所示: (4) 其中,k表示当前簇表中簇的个数,ci表示簇Ci的质心,E表示簇Ci中的样本,dist(ci,E)表示簇的质心和簇中样本的距离,考虑到住院数据具有部分时序性特征,本研究中用余弦相似度表示二者的距离,其表达式如式(5)所示: (5) 其中,T表示诊疗记录序列的长度,即诊疗日的天数,cos (6) 其中,P是和样本E同维度的全1列向量,⊙表示矩阵的哈达马乘积,×表示矩阵乘法. 利用二分K-means算法将规范化的诊疗记录序列划分为K个簇,即K种诊疗模式,将这K个簇的质心作为规范的诊疗模式序列,即衡量诊疗过程是否规范的标准. 3.2.2 诊疗过程规范化判断 在对诊疗过程进行规范化判断时,考虑到诊疗记录序列具有部分时序性的特征.因此,采用余弦相似度来衡量两个诊疗记录序列不同诊疗日之间的相似性. 以K个簇的质心作为规范诊疗模式序列,将待检测的诊疗记录序列与规范诊疗模式序列的余弦相似度作为衡量诊疗过程是否规范的标准,其表达式如式(7)所示: (7) 其中,D表示待检测的诊疗记录序列,c表示规范诊疗模式序列,P是和待检测的诊疗记录序列D同维度的全1列向量.cos 3.3.1 GRU 门控循环单元(Gate Recurrent Unit,GRU)[11]是循环神经网络(Recurrent Neural Network,RNN)[12]的一种,能够很好的解决RNN的梯度消失问题,其基本原理和长短记忆神经网络(Long Short-Term Memory,LSTM)[13]相似,但结构更加简单,所构造的模型的性能更好.GRU结构如图4所示. 图4 门控循环单元 GRU有两个门控单元,重置门rt和更新门zt,重置门控制当前输入如何与之前时刻的记忆相结合,更新门控制之前的记忆保存到当前时刻的量,这两个门的设计使得GRU有效的控制历史信息的保存、重置和更新,同时能够处理长时间依赖问题.由于宫颈癌诊疗记录的数据量巨大,医生很难基于过往的诊疗情况在短时间内做出准确的判断,GRU的这一特征对辅助医生诊疗提供了极大的帮助. GRU模型的表达式见式(8)~式(11): zt=σ(Wzxt+Uzht-1+bz) (8) rt=σ(Wrxt+Urht-1+br) (9) (10) (11) (12) (13) 3.3.2 诊疗项目预测模型 本研究采用基于Bi-GRU(Bidirectional Gate Recurrent Unit)[14]的算法进行宫颈癌诊疗项目的预测,正反双向GRU不仅能考虑到过去诊疗日的诊疗记录,还能捕捉到后续诊疗日的信息,即每个诊疗日的诊疗项目由其上下文的诊断结果和诊疗项目共同决定.临床诊疗记录序列中,由于诊疗日的时间间隔不一致,间隔时间越长的诊疗日之间相互影响越小,因此,时间间隔是诊疗项目预测任务的重要特征.本研究中将诊疗日向量e′i和相邻两个诊疗日之间的时间间隔Δti进行拼接,Δti表达式如式(14)所示,其中,ti表示诊疗项目实际发生的日期,第一个诊疗日时间间隔记为0,即Δt1=0. Δti=ti-ti-1 (14) 图5 诊疗项目预测模型 (15) 其中,OT-1表示患者的状态表示,Ws为权重矩阵,bs为偏倚量. (16) 本文设计4组模型进行对比研究,为了突出模型的优益效果,分别在是否融入时间间隔、是否进行诊疗模式规范化判断以及单向GRU和双向GRU的情况下进行实验.同时,和现有的研究方法进行对比,进一步验证了模型的性能. 本研究所用的数据集来源于某医院电子病历数据库中2013年4月~2019年8月期间13,000名宫颈癌住院患者脱敏处理后的诊疗记录,数据集中包括患者的诊断记录、用药、医嘱以及实验室检查项目等信息,一共518,000条数据.在数据集中筛选出不少于两条诊疗记录的患者,共11,990名患者,516,039条数据,平均每人诊疗记录数43次,统计情况如表1及图6所示. 表1 数据集统计 图6 患者诊疗记录次数统计 为了验证模型的性能,本文从不同的角度进行了对比实验,实验模型如下: 1)GRU-2:以诊疗日向量作为模型的输入,两层单向GRU构成模型的基本结构; 2)Bi-GRU:以诊疗日向量作为模型的输入,正反双向GRU构成模型的基本结构; 3)GRU-2-DT:以诊疗日向量和相邻诊疗日之间的时间间隔作为模型的输入,两层单向GRU构成模型的基本结构; 4)Bi-GRU-DT:以诊疗日向量和相邻诊疗日之间的时间间隔拼接后的向量作为模型的输入,正反双向GRU构成模型的基本结构; 5)FT-LSTM[4]:在经典LSTM的基础上,为LSTM细胞增加3个时控门,以同时捕获时间信息和诊疗记录信息; 6)Phased LSTM[15]:通过增加一个时间门来扩展LSTM细胞,以控制不同时间间隔的诊疗日向量; 7)AMNN:对诊疗日向量进行聚类以确定样本的中心,对每个部分采用BP神经网络[16]; 在模型的训练过程中,将数据集的70%作为训练集,20%作为测试集,10%作为验证集,用验证集的结果调整模型的超参数. 本研究中采用Recall@K和MAP@K作为模型的评价标准. Recall@K表示模型的召回率,模仿了医生对患者治疗时的行为,即医生采用最有可能的诊疗项目对患者进行治疗.其表达式如式(17)所示: (17) 其中,n′表示患者诊疗项目的数量,m′表示预测结果的前K个记录中有m′个正确的诊疗项目.Recall@K的值越高,模型的性能越好. MAP@K(Mean Average Precision)表示模型的平均准确率,反映了模型的预测性能,其表达式见式(18)、式(19): (18) (19) 其中,r表示等级,m′表示等级为r时诊疗项目中有m′个正确的诊疗项目,n′表示患者诊疗项目的数量,P表示患者的数量,N′表示样本数.其值越高预测结果中,预测正确的诊疗项目越靠前,模型的预测效果越好. 本文将4种不同的模型和基线模型对比实验,分别在规范化和未规范化判断的情况下计算Recall@K和MAP@K,在K=10,K=20以及K=30的情况下评估模型的预测性能.实验结果如表2、表3及图7所示. 表2 不同K值下模型的召回率 表3 不同K值下模型的MAP 图7 不同K值下模型的召回率和平均准确率 通过分析实验结果可以看出,相比未规范化判断的情况下,Recall@K平均提高了6.4%,MAP@K平均提高了5.3%,体现出规范化判断的必要性.相比未考虑时间间隔的情况下,Recall@K平均提高了3.3%,MAP@K平均提高了6.3%,提升了模型的预测性能.对比发现,本研究提出的模型Bi-GRU-DT在进行规范化判断的情况下,模型的预测效果最好,其预测效果优于基线模型,Recall@K平均提高了2%,MAP@K平均提高了1.4%. 本研究提出了一种基于Bi-GRU的两段式宫颈癌诊疗预测模型.在第1阶段,用二分K-means算法挖掘规范的诊疗模式,以此作为诊疗过程规范化判断的标准;在第2阶段,我们用正反双向GRU构建诊疗项目预测模型,预测未来诊疗项目发生的概率.对于本研究中使用的住院数据而言,住院数据具有部分时序性特征,本文将同一诊疗日的数据采用加权池化的方式处理,用Skip-gram算法学习不同诊疗日之间的潜在关系并将诊疗日以向量的形式表示;考虑到住院数据时间分布不均匀,将相邻诊疗日的时间间隔拼接到输入数据中,提升了模型的预测性能.实验结果表明,相比直接预测诊疗项目的模型,Bi-GRU-DT模型的预测效果最好.3.3 基于Bi-GRU的诊疗项目预测模型
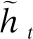
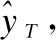
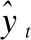
4 实验结果及分析
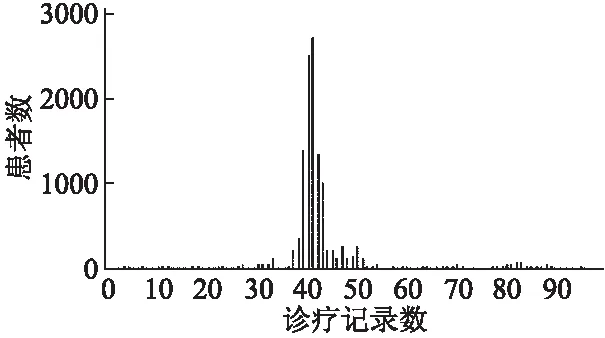
4.1 数据集

4.2 模型设置
4.3 实验结果及分析
5 结束语
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
新高考·高一数学(2022年3期)2022-04-28
海峡姐妹(2020年2期)2020-03-03
保健与生活(2019年3期)2019-08-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
中国民族民间医药·下半月(2014年4期)2014-09-26
中国民族民间医药·下半月(2014年4期)2014-09-26
金点子生意(2014年4期)2014-04-10
