
自杀意念原因抽取中的标签增强方法
2022-05-27 00:41刘德喜邱祥庆赵凤园
小型微型计算机系统 2022年6期
付 淇,刘德喜,邱祥庆,赵凤园
1(江西财经大学 信息管理学院,南昌 330013)
2(江西科技师范大学 通信与电子学院,南昌 330013)
3(江西财经大学 数据与知识工程江西省高校重点实验室,南昌 330013)
4(福建江夏学院 电子信息科学学院,福州 350108)
1 引 言
社交媒体的兴起为心理科学的发展和应用提供了新的契机,也为自杀意念的监测以及原因分析提供了新的渠道.心理危机主体往往表现出对传统精神卫生服务和机构的不信任和抵触心理,而社交媒体的优势在于它提供了一个匿名、安全、不受地域限制、易访问、低成本和不受人歧视的环境,用户可以无压力地在这种环境中分享、倾诉,以及听取心理专家或具有类似经历的人的意见,获得帮助、支持或慰藉.研究表明,心理危机主体更倾向于从社交媒体等非正式资源中寻求帮助和安慰,而不是向心理专家寻求治疗[1].已有大量研究成果证实,利用Twitter、Facebook、微博等社交媒体预测自杀意念是可行且有效的[2],也有少量研究者开始利用社交媒体数据分析心理健康问题产生的原因,甚至利用社交媒体平台进行自杀风险干预[3]和自杀意念原因的自动抽取或提取工作[4].
本文延续Beck等人[5]的观点,将自杀意念定义为想自杀的愿望或计划,但没有任何自杀尝试,它是评估自杀危险因素的一个重要指标.本文以社交文本为研究对象,并在构建自杀意念原因数据集的基础上,研究自杀意念原因抽取的方法.
自杀意念原因即社交文本中产生想自杀的意愿或想法的原因,它包含在单个句子内或者多个句子中,它可以以显式或隐式的形式存在于文本中,其中显式呈现出明确的语义表达,隐式一般隐藏在语义逻辑中.本文将自杀意念原因自动抽取问题定义为“在社交文本中利用计算机科学的方法自动抽取在语义上表达自杀意念原因的子句或更细粒度的词、短语”.如图1,在“走饭”(1)走饭,本名马洁,女,90后,南京高校学生,2012年3月17日凌晨上吊自杀,于3月18日通过定时的时光机发出告别微博.微博中,框中的内容即为待抽取的关于自杀原因的表述.

图1 “走饭”微博中关于自杀原因的表述(框中的内容)
基于中国科学院心理研究所标注的自杀意念数据集[3],标注自杀意念中的原因.在人工标注的过程中,本着“简明扼要”的原则,往往只标注反映自杀意念原因的最小词串或短语,但是由于个人的理解不同,人工标注中还是存在一些不可避免的主观因素问题.例如图1中的3条帖子,黑色框中的内容为人工标注的自杀意念原因.然而,“抑郁症”或“我有抑郁症”;“不强大”、“一点点都不强大”或“我一点点都不强大”;“孤立无依”、“觉得孤立无依”或“我就觉得孤立无依”都可能被人工标注为自杀意念原因.因此,标注存在主观因素导致边界模糊的问题.
同时,人工标注困难,较费时费力.在13013条中文微博帖子中仅标记出5994条有原因的帖子(文本),标注的样本集较小,而训练数据不足往往会导致模型产生不稳定或依赖于数据集的浅层特征等问题,从而影响模型的抽取效果.
数据增强方法可以利用转换或改变来增加标注训练集的大小,解决数据样本量偏少的问题.用于NLP任务的数据增强,特别是中文文本的数据增强研究还处于探索阶段.目前还未检索到在文本序列标注问题上探讨标签增强的工作,即针对人工标注中由主观因素造成的标注边界模糊和误差现象进行数据增强.此外,从数据增强相关文献所使用的数据集和应用背景来看,极少有针对社交文本(比如微博数据集)的数据增强研究,更没有应用在原因抽取或提取方面的相关成果.这些都鼓励本文在基于序列标注的自杀意念原因抽取任务中,针对人工标注困难、样本较少且标注边界模糊的情况,开展相关数据增强的研究.
针对标注的边界模糊和样本量较小的问题,本文提出一种满足增强保证性假设的数据增强(Data Augmentation,DA)方法,拟通过数据增强的方法,扩充数据量,同时模拟人工标注时标注边界模糊的现象,提高模型的泛化能力.
本文的主要贡献包括:1)对基于社交文本的自杀意念原因抽取问题进行定义;2)提出基于标签窗口缩放的标签增强方法LWS(Label Window Scaling),通过设计标签窗口缩放概率、缩放尺度、标签增强率等参数及其应遵循的原则,较好地解决了人工标注时边界模糊或存在误差的问题;3)实验对比了LWS和EDA(Easy Data Augmentation)数据增强前后的抽取结果,并详细分析了参数的影响.
本文的结构安排如下:第1节引言部分,介绍基于社交媒体的自杀意念原因自动抽取研究和引入数据增强的背景;第2节相关研究,总结自杀意念原因和近几年数据增强的相关研究成果;第3节介绍基于标签窗口缩放的标签增强方法LWS和基于EDA的数据增强方法;第4节介绍实验数据并对评测结果进行分析;最后在第5节进行总结与展望.
2 相关研究
2.1 自杀意念原因
目前对自杀意念产生原因或自杀原因的分析主要来自心理学或社会学领域,研究方法也多为案例分析或实证分析.情绪或情感与自杀意念有一定的关联性,而情绪或情感原因的自动抽取是情感分析研究的问题之一,正受到学者们的高度关注.
自杀意念的产生与人口经济学及社会心理行为等诸多因素相关,它涉及自杀意念个体的内外环境,包括生物、遗传、心理、社会、环境、文化、外在压力等多种因素的直接和间接的综合作用,具体因素包括:学业、人际关系、环境、突发事件、种族宗教、学习压力、精神心理、婚姻状态、经济状况、健康问题等等.传统关于自杀意念原因的研究可以归纳为理论研究和实证研究两个方面.
理论研究主要从生物、心理和社会等视角出发,探索各个因素之间错综复杂的关系,主要研究成果包括“应激-易感”模型[6]、聚合优化模型(2)Cernat V.A Coherence Optimization Model of Suicide,http://cogprints.org/1081/1/coherencesuicide.htm.2000,5.、自杀意念与行为的压力脆弱性模型[7]、自杀意念的生物社会心理医学模型[8]等.很多研究者还运用精神分析理论(3)精神分析理论于西格蒙德·弗洛伊德(Sigmund Freud)在19世纪末20世纪初创立.、生物学理论[9]、社会学理论[10]、逃避自我理论[11]、进化理论[12]、依恋理论[13]、人格发展阶段理论[14]、自杀人际理论[15]、压力不协调理论[16]等来研究自杀意念产生的原因.理论研究大多都是从各自学科的角度对自杀意念提出研究观点,关注点较狭窄,且缺少实证分析.
实证研究主要结合自杀意念的相关量表开展以调查问卷为主的研究,采用统计方法分析单因素和多因素的逻辑回归关系,从样本数据中探讨自杀态度与影响因素之间的关系.近几年也有研究者们运用结构方程模型(Structural Equation Modeling,SEM)来克服统计方法中无法分析的潜变量和多变量之间复杂交互作用的问题.实证研究中,样本的地域偏倚性、代表受限性、时间跨度较小、被试者的刻意掩饰、量表的信效度等问题仍然存在.
传统关于自杀意念原因的研究,无论是在理论研究方面,还是实证研究方面,自杀原因的获取都来自问卷、访谈或者研究者对患者的分析.尽管也有研究者利用社交媒体数据研究自杀意念的原因,但其中自杀意念原因的抽取与分析仍是基于手工开展的.根据对文献的检索,目前还没有研究工作利用计算机技术从患者发布的文本(日记、遗书、微博等)中自动抽取自杀意念产生的原因,因此患者样本的选择规模难以扩大,对患者的持续跟踪也难以维持,这也鼓励了本文对这个问题进行深入研究.
2.2 数据增强
在机器学习中,数据增强特指对有限的训练数据通过某种变换得到更多数据的过程.在深度学习中,数据增强的目的主要有两个方面,一是扩充数据量,二是提高数据质量.具体在实现时,它保留类的标签,利用一些特定于任务的转换或改变来增加标注训练集的大小.
数据增强技术早期应用于图像处理的研究中.由于训练样本数量不足,容易造成深度神经网络模型在训练数据集中过拟合,模型难以具备较优的泛化能力.为了能够让模型学习多样性的数据特征,在图像处理中通常采用旋转变换、镜像变换、缩放变换、平移变换、尺度变换、颜色对比度变换、噪声变换等方法,来构造更加多样性的训练数据,且这些变换通常不会改变样本的类别.
由于文本数据中基本数据单元(字或词语)之间存在着较强的上下文相关性,直接迁移图像数据的增强方法到文本数据上,容易产生大量的噪音数据,影响整条文本数据的语义信息.文本数据的语义、语法和语境的多样性都使得其数据增强的研究更具挑战性.
自然语言处理中的文本数据增强也是近几年发展起来的,尚处于探索阶段.早期的文本数据增强侧重于样本的形式改变,这类方法主要对整个句子或句子局部(词或短语)做某种形式改变,生成新句子,同时保留原始句子类标签.虽然文本数据增强在目前仍然具有极大挑战性,但也有一些国内外学者取得了一定的成果.现从文本增强的粒度和其采用的技术手段来梳理近几年文本数据增强的相关工作.
2.2.1 词语级文本增强
词语级文本增强是最早提出的文本数据增强方法,包括同义词替换(Synonym Replacement,SR)、词向量变换、上下文增强CA[17](Contextual Augmentation)、简易数据增强EDA[18](Easy Data Augmentation)等方法.
基于同义词库的同义词替换SR.SR是一种简单而直观的数据增强方法,通过将文本中一些词语用其同义词进行替换的方式来生成新的数据,SR的优点在于不会破坏文本信息,但生成的文本与原文本之间极度相似,造成大量数据冗余.
词向量变换.采用预训练好的词向量,如Word2Vec、GloVe、FastText、Sent2Vec,并利用两个词语之间的相似度,使用词向量空间中最近的单词替换句子中的某些单词,如基于Word embedding的词向量余弦距离方法[19]和基于k-近邻(KNN)的方法[20].后者将KNN分类器与Word embeddings和WordNet词典相结合,使用KNN分类器生成一个单词替换词典.词向量变换方法易实现且提供的候选词比SR更丰富,但候选词与原词往往只是具有比较相似的词向量,因此有时候未必可以真正起到扩充的作用.
上下文增强CA[17].与SR类似,CA也是通过替换文本中部分词语来进行数据增强.但CA并不使用同义词来替换词语,而是根据文本的上下文信息和文本的标签来生成可用的候选词.CA相较SR而言,可生成更多样化的数据,因为生成时考虑了上下文,其生成的文本在语法上也更加连贯.然而,CA采用了更复杂和繁琐的算法,且其在实际中的应用并不友好,需要额外的超大语料库的支持.
简易数据增强EDA[18].它包括同义词替换SR、随机交换(Random Swap,RS)、随机插入(Random Insertion,RI)和随机删除(Random Deletion,RD),后3种为EDA首创.EDA通过随机修改或删除文本中一定数量的词语来生成新文本数据,对于小数据集来说,EDA性能提升较明显,可显著地提高性能并减少过度拟合.但由于EDA随机性较强,因而容易破坏文本的原意,且原文本与生成的新文本之间冗余性较大.综上所述,SR中同义词具有较相似的词向量,实际上对数据集并没有特别有效的扩充,在数据扩充的多样性上也会受限.RS实质上并没有改变原句的词素,对新句式、句型、相似词的泛化能力提升很有限.RS和RI会让原数据的语义结构和语义顺序发生改变,且RI中插入词随机性强没有侧重句子里的关键词.RD中也没有关键词的侧重,若随机删除的词刚好是分类时特征最强的词,那么不仅语义信息可能被改变,标签的正确性可能也会存在问题.
2.2.2 短语级文本增强
词是最小的能够独立运用的语言单位,短语是由句法、语义和语组合起来的没有句调的语言单位,它是大于词而又不成句的语法单位.对于中文语料来说,常出现一词多义的现象,仅对词进行数据增强,容易造成歧义的问题,而短语保存了词语与词语之间的搭配关系,往往能够表达比词更丰富和生动的语义.短语级文本数据增强加入了语法结构的信息,就目前的文献来看,主要针对句子里的状中短语、定中短语[21]等进行增强.
状中短语主要包括状语和中心语两部分.状语常出现在动词或者形容词前,用于修饰、限制动词或形容词,表示动作的状态、方式、处所、时间或程度;中心语则是被修饰的动词或形容词.例如:很小心、谨慎地研究.状中短语的数据增强方法主要包括针对状语的同义变换、针对中心语的同义变换或状语和中心语同时的同义变换方法.
定中短语主要包括定语和中心语两部分,定语从领属、范围、质料、形式、性质、数量、用途、时间、处所等方面修饰、描写或限制中心语,中心语则是被修饰的名词或代词.例如:纯净的空气、鲜艳的旗帜.定中短语的数据增强方法主要分为4种,针对定语的同义变换、针对中心语的同义变换、针对定语和中心语的同义变换、针对中心语的模糊化以及定语的同义变换等.
2.2.3 句子级的文本数据增强
词语级或短语级数据增强主要是从词义或形式上的角度,对文本句子只进行局部更改,产生与原始句子结构相似的句子,从而造成较低的语料库可变性.而最近较流行的文本数据增强方法大多是从句子级的生成角度,即生成完整的句子,丰富了生成文本的语义和句法特征,而不是进行一些简单的局部更改.这些方法大都基于深度生成网络,目的是从一组样本中学习数据分布,从而从所学习的分布中进一步生成新的样本.这些方法包括使用变分自动编码(Variational AutoEncoder,VAE)、基于生成性的对抗网络(Generative Adversarial Network,GAN)、回译、文本复述以及重写或改写[22]的方法.它们还包括数据噪声技术,如改变自编码网络输入中的单词以生成不同的句子,或者在Word embedding里引入噪声.
基于变分自动编码VAE.VAE试图捕获输入数据的分布并对其进行编码,具体工作如基于VAE的VAEHD[23],它可以使得模型模拟人的自主写作能力,从而可以生成更加具有区分度的数据.Malandrakis等人[24]提出一个基于条件VAE的模型CVAE(Conditional Variational Auto-Encoder),该模型能够生成同时兼具较好准确性、多样性和新颖性的短语.其他基于VAE的文本数据增强工作还来自Moreno-Barea等人[25].
基于生成对抗GAN.GAN则基于在两个网络之间产生对抗的思想,其中生成器的任务是创建模拟原始数据分布的数据,而判别器的任务是区分来自真实分布的数据和来自生成器的合成数据.Kang等人[26]提出利用GANs和WordNet进行自然语言推理的数据增强.Li等[27]基于GANs构建了多个生成式对抗网络结构,解决特征和不同主体间都存在的分布不匹配问题.同时,为了保证潜在空间的表示能保留输入空间的信息和局部数据重建损失的最小化,在整个输入空间数据集上保持稀疏重建(语义)关系.Kober等[28]采用GANs来创建合成向量,并从中选择与训练数据中单词最相似的向量.
基于回译(Round-Trip Translation,RTT).RTT是另一种流行的数据增强方法,它是将一个词、短语或文本句子翻译成另一种语言(正译),然后将结果翻译回原语(反译)的过程.回译可以保证新旧数据之间的核心内容不变,且彼此又有足够的差异,这个方法已经成功的被用在Kaggle恶意评论分类竞赛中.回译的方法相比替换词来说,往往能够增加文本数据的多样性,有时还可以改变句法结构等,并保留语义信息.但是,回译的方法产生的数据依赖于翻译的质量,且回译需要数据集有多种语言的版本,因而通用性不强,只适用于特定任务如机器翻译.
基于文本复述、改写或重写.有学者将文本数据增强视为文本复述、改写或重写任务,如Kumar等人[29]提出使用子模块化的多样化翻译(DIPS,Diverse Paraphraser using Submodularity)模型,通过最大化专门为改写设计的子模块目标函数来生成高质量的改写,这种基于子模块函数的方法能够在不影响保真度的情况下产生多样化的改写.赵小兵等人针对藏文语料稀缺的问题,在藏汉双语、藏文单语文本改写检测任务中使用数据增强的方法,在一定程度上解决了低资源语言训练语料规模小的问题,使得藏文单语言文本改写检测模型的检测结果与人工标注的结果达到了强相关程度.Liu等人[22]将问题数据增强任务视为一个有约束的问题重写问题,提出基于可控重写的问题数据增强(Controllable Rewriting based Question Data Augmentation,CRQDA).CRQDA利用Transformer自动编码器将原始离散问题映射到一个连续的向量空间,然后使用预训练的机器阅读理解(Machine Reading Comprehension,MRC)模型,通过基于梯度的优化迭代地修改问题表示.最后,将修正后的问题表示映射回离散空间,作为附加问题数据.
基于深度学习的预训练语言模型也经常被用于文本数据增强.例如,Wu等人[30]提出条件BERT上下文增强,条件BERT可以预测与句子标签相关联的词,再用预测词替换masked词后,生成与原句子具有相似上下文和相同标签的新句子,然后将新句子添加到原始数据集中.Anaby-Tavor等人[31]提出的LAMBADA数据增强方法建立在GPT-2之上,通过向微调模型提供类作为输入,并为给定类生成示例.Liu等[32]通过修改GPT-2来实现条件生成器生成文本数据,类似的工作还有最近提出的文本增强框架Data Boost[33].Staliu-naite等人[34]则使用GPT-2来生成干扰词使文本因果推理模型更稳健.Kumar等人[35]探索了3种不同类别的数据增强预训练模型,包括自动编码器(Auto Encoder,AE)语言模型BERT、自回归(Auto Regressive,AR)语言模型GPT-2和预训练Seq2Seq模型BART,并探讨了不同预训练模型的数据增强方法在数据多样性方面的差异,以及这些方法如何很好地保留类标签信息,并将生成的数据应用于3种不同的NLP任务.实验证明,3种基于预训练模型的数据增强都是有效的,预训练Seq2Seq模型在低资源环境下优于其它数据增强方法.
综上所述,词语级或短语级数据增强主要是从词语的词义、形式或语法的角度,对文本句子进行局部的直接更改,产生与训练集结构相似的样本,但语料库可变性较低且数据冗余性较大.句子级文本数据增强方法生成完整的句子,丰富了生成文本的语义和句法特征,生成样本的保真度和多样性达到一种平衡,但是代价是需要更复杂和繁琐的算法,而且通用性较差,比如回译依赖翻译软件的质量和翻译语言库,只适用于特定任务如机器翻译.预训练语言模型由于深度学习以及其预训练模型的不同,可解释性和通用性较差,也很难直接理解此情形下模型生成的数据是如何变化的,以及如何影响下游模型性能的.
3 基于标签增强的自杀意念原因抽取模型
3.1 自杀意念原因抽取
给定训练数据集D={d1,d2,…,d|D|},|D|为蕴含了自杀意念的文本数量,即帖子数.d={c1,c2,…,c|d|},|d|为帖子中子句的数量,每个子句ci包括若干个单词,即ci={w1,w2,…,w|ci|},|ci|为子句中单词的数量.本着“简明扼要”的细粒度抽取思想,自杀意念原因抽取任务定义为抽取d中的自杀意念原因片段集合,X={x1,x2,…,xm},其中x是不跨越子句且由1个或多个连续词组成的片段,即x⊆ci⊆d,x={wj,wj+1,…,wj+l-1},(1≤j,j+l-1≤|ci|),l为原因片段的长度(以词为单位).使用能反映自杀意念原因的最小词串来界定原因,比粗粒度的子句或事件类的原因抽取更加具体、明确,该片段称为自杀意念原因短语.
3.2 基于标签窗口缩放的标签增强方法LWS
针对人工标注时由于主观性或误差而导致的标签边界不确定问题,提出一种基于标签窗口缩放(Label Window Scaling,LWS)的标签增强方法.LWS的基本思想是:随机对原因短语进行缩放,即在原因短语边界内外(左侧或右侧)选择若干个词,删除或扩充到原因短语中.要求缩放后的原因短语满足连续、不跨越子句、原因短语间不重叠.如果所选择的用于扩充的单词个数为负数,则表示对初始的原因短语进行裁剪或收缩.采用缩放概率和缩放尺度两种变量来定义LWS,其遵循以下原则:
1)扩充(收缩)概率:原因短语越长,其扩充(收缩)的概率越小(越大);原因短语越短,其收缩(扩充)的概率越小(越大);
2)扩充(收缩)长度:为了保持数据不被过度修改,扩充或收缩的长度不应过长,因此,扩充或收缩的长度越大,相应的扩充或收缩的概率越小.
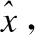
1)根据缩放概率p与原因短语的长度l的关系原则,构造缩放概率p如公式(1)所示,其中,p+代表“放”即扩充的概率,p-代表“缩”即裁剪的概率,λ<1为缩、放操作的总概率,r为调节系数.
p+=e-rl,p-=λ-p+=λ-e-rl
(1)
2)同理,定义缩放长度△l对缩放概率p的影响程度如公式(2)所示,其中r′为调节系数.
(2)
综合式(1)和式(2),缩放概率p可写成公式(3):
(3)
设r′=r,并引入原因短语增强率ε,调节原因短语增强的比例,在保持满足缩放概率及尺度遵循的原则下,将式(3)写为式(4):
(4)
根据式(4),当△l≥0时,l越大,扩充的概率p越低;△l越大,扩充概率p也越低.当△l<0时,l越大,收缩的概率p越高;|△l|越大,收缩的概率p越低,满足缩放概率以及缩放尺度遵循的原则.
具体算法描述如算法1所示.
算法1.基于标签窗口缩放的标签增强方法LWS
输入:原文本训练数据集D={d1,d2,…,d|D|}(|D|=4794,约为原因数据集的80%),原因短语增强率ε,原因短语最大长度MaxL,以及缩放概率p定义中的r、λ
输出:数据增强集合D′
1.D′=D,对于D中的每个帖子d,以及d中的每一个原因短语x={wj,…,wj+l-1},x⊆ci(1≤j,j+l-1≤|ci|),l为原因短语的长度,执行2-6;
2.产生一个随机数k∈[0,1],如果k≤ε,则执行3-6的增强操作;
3.随机产生一个缩放长度△l,-l<△l≤MaxL-l;
4.通过公式(4)计算标签缩放概率p;
5.产生一个随机数q∈[-1,1]表示缩放方向,即标签的左侧(q<0)或右侧(q≥0);
标签增强方法LWS的实例如表1所示.

表1 LWS增强前后实例
标注的字母表示:B:原因的首部;E:原因的尾;M:原因的中部;S:只包含单个词的原因
3.3 基于EDA的数据增强
2019年Wei等人提出的EDA[18]是一种典型的文本数据增强方法.EDA包括的4个子方法:同义词替换(SR):从句子s中随机选择n个非停用词,随机选择同义词词典里的同义词进行替换;随机插入(RI):在句子中随机找到一个非停用词的同义词,将其插入句子的任意位置,并重复做n次;随机交换(RS):在句子中随机选择两个单词交换它们的位置,并重复做n次;随机删除(RD):以概率p随机删除句子中的某个单词.在上述4个方法中,n表示s中被修改的词语的数量,且有n=αT,α为系数,代表s中被修改的词语与总词数T的比例.特别地,对于RD,令p=α.α的取值与数据集的大小有关,对于样本数超过5000的数据集,EDA推荐设定α=0.1.
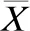
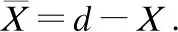
在同义词替换SR中,同义词词典采用哈尔滨工业大学信息检索研究中心的同义词词林(扩展版)(HIT-CIR Tongyici Cilin(Extended))(4)http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm.随机插入RI和随机交换RS在本文的数据增强上效果不好,这将在下一节实验分析中分析其可能的原因,因此此处不再详细介绍其算法,本文基于EDA的数据增强算法描述如算法2所示.
算法2.基于EDA的数据增强
输入:原文本训练数据集D={d1,d2,…,d|D|}(|D|=4794,约为原因数据集的80%),帖子增强率α和每个帖子生成的增强帖子数num
输出:数据增强后的训练数据集D″,仅采用RD操作的增强数据集D″RD,仅采用SR操作的增强数据集D″SR
1.D″RD=D″SR=D″=D,对于D中的每一个帖子d,执行2-7的增强操作num次;
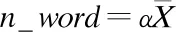
3.随机选择一个操作,RD或者SR;
4.if RD:
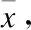
6.else:
使用EDA进行数据增强的实例如表2所示.

表2 EDA增强前后实例
4 实验评测与分析
4.1 实验数据和评测指标
本研究采用“简明扼要,不做推理,原因连续,类别唯一”的自杀意念原因标注原则.“简明扼要”指只标注能反映自杀意念原因的最小词串;“不做推理”要求标注时仅从字面意思出发,不进行猜测或推理,不考虑间接原因;“原因连续”要求同一个原因覆盖的词串必须连续,不间断、无跨度;“类别唯一”指每个原因仅属于一个原因类别(本文实验中不区分原因的类别).标注符号参照黄昌宁等人的经典4词位(4-tag,B:Begin,原因的首部;E:End,原因的尾;M:Middle,原因的中部;S:只包含单个词的原因)的标注方法.
自杀意念原因的标注工作由4位研究生共同完成,标注人员经过了心理知识培训和试标注并检验合格.标注结果经过互相校对,对不一致的标注进行讨论并投票确定,仍有争议的标注请心理专家进行仲裁.原因标注的一致性检测采用标准Kappa值,4个标注者两两之间的平均Kappa值为0.617.这说明对自杀意念原因的人工判断存在差异,加之中文微博中的非正式表达,加重了语义理解的复杂性和歧义性.最终,在13013条帖子中标记出5994条有原因的帖子,随机按约8∶1∶1的比例将其分成训练集、验证集、测试集,统计信息如表3所示.数据增强主要从现有的训练样本生成新的训练样本以增加初始训练集的大小,本文数据增强实验是在4794条训练集上开展的.
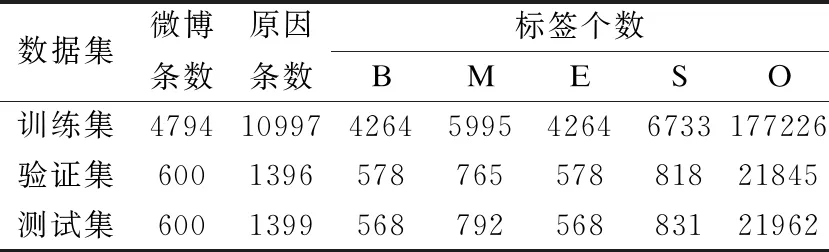
表3 自杀意念原因数据集分布表
实验评测指标使用精确度(Precision)、召回率(Recall)和F1值(F1-score).由于自杀意念原因可能包含多个词,为了更详细地考察数据增强对模型性能的影响,本文在判断模型抽取结果是否正确时,根据评测粒度和匹配精度设计了两类共4种评测指标.
1)评测粒度为原因短语
(1)完全匹配法(Complete Match).
对于一条包括多个词的自杀意念原因短语,要求原因各个词的标签(B,M,E)都完全标注正确.对应的精确度、召回率和F1值分别记为C_P,C_R,C_F.
(2)局部匹配法(Partial Match).
只要模型标注的原因与理想标注之间有重叠,即视为标注正确.该指标主要考察模型是否能定位到原因短语上.对应的精确度、召回率和F1值分别记为P_P,P_R,P_F.
2)评测粒度为词
(1)精确匹配法(Exact Match).
以自杀意念原因中的词作为评测粒度,不考虑整个原因短语是否整体标注正确.对应的精确度、召回率和F1值分别记为E_P,E_R,E_F.
(2)模糊匹配法(Fuzzy Match).
与精确匹配法不同的是,模糊匹配法不区分标签的类别B、M、E或S,即视标签只有“原因”和“非原因”两类.对应的精确度、召回率和F1值分别记为F_P,F_R,F_F.
4.2 参数设置
本文在将数据增强算法应用于自杀意念原因抽取模型时,基准模型采用Char-BiLSTM-CRF模型.Char-BiLSTM-CRF模型不需要特征设计,在词性标注、词语词组分块、命名实体识别等序列标注任务均取得了较好的效果.
Char-BiLSTM-CRF采用3层架构的神经网络模型:1)Char层.Char层增加字向量的输入,将字向量和词向量拼接作为模型的输入层,可以表示词的内部结构信息,相比单纯的词向量能更准确地表达语义,也弥补了中文分词错误或训练数据不足给词向量带来的偏差;2)BiLSTM层.双向长短时记忆网络BiLSTM可以捕捉到句子中词的长距离依赖关系,能够较好地考虑词的上下文信息;3)CRF层.CRF层是对输出序列的优化.当前词的标签不仅受到词本身特征和上下文特征的影响,还受到上下文标签的影响.比如,在表示自杀意念原因的标注中,标签“M”的前面必须是“B”或“M”,“E”的前面必须是“M”或“B”,这些标签之间是相互制约的.BiLSTM不能充分考虑标签之间的依赖关系,可能产生不合规则的标签序列.而CRF层可以学习整个句子的标签转移概率,充分地考虑上下文标签间的依赖关系.本文中Char-BiLSTM-CRF模型使用的超参数设置如表4所示.
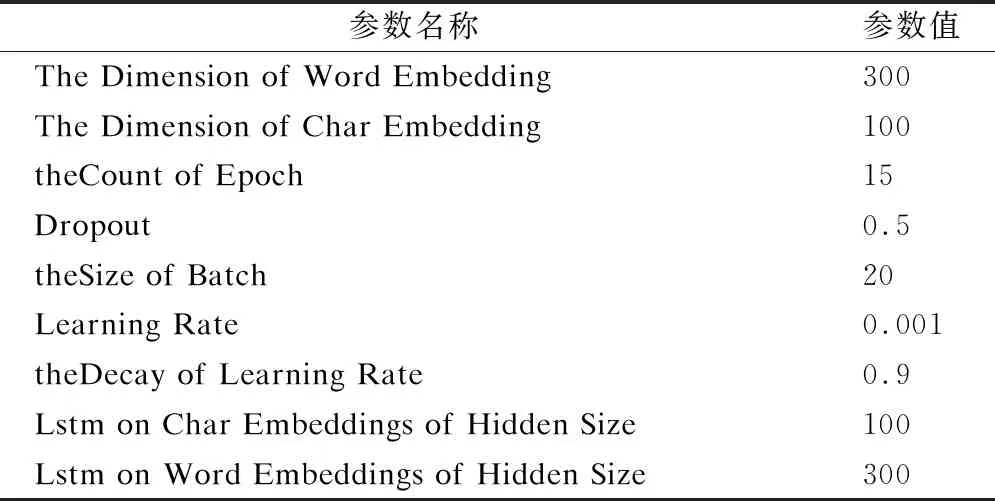
表4 Char-BiLSTM-CRF模型的超参数
本文还对比了3种词向量模型,分别是Word2vec、ELMo和BERT.Word2vec用中文维基百科做预训练;ELMo用13013条有自杀意念的微博数据集来预训练,且使用Word2vec静态词向量完成文本表示的初始化,Word2vec和ELMo词向量维度都设为300.ELMo模型的主要训练参数如表5所示.

表5 ELMo词向量训练参数
词向量采用BERT模型时,进一步增强了词向量模型的泛化能力,充分提取字符级、词级、句子级甚至句间关系特征,更好的解决Word2vec中无法解决的一词多义的问题.BERT词向量使用“BERT-As-Service”工具(5)https://github.com/hanxiao/bert-as-service/,它是腾讯AI Lab开源的一个BERT服务,让用户可以以调用服务的方式使用BERT模型而不需要关注BERT的实现细节.由于本文语料是中文文本,因此使用“BERT-Base,Chinese”版本,其预训练使用了33亿单词以及25亿维基百科和8亿文本语料,词向量维度设置为768,同时再使用BiLSTM获得词的字向量拼接时,dim_char设为256.
标签增强方法LWS里包括标签增强率ε、原因短语最大长度MaxL(当l≥MaxL时,不进行扩充),以及缩放概率p定义中的r共3个参数.通过网格搜索,最后设置的参数值为ε=0.27,MaxL=6,r=1.基于EDA的数据增强包括帖子增强率α和增强帖子数num共2个参数,单独使用RD或SR增强时,α=0.2,num=3,而同时运用RD和SR增强时,α=0.1,num=3.
4.3 对比模型
1)BiLSTM:采用中文维基百科语料训练好的Word2vec词向量作为输入层,中间的隐藏层采用经典的BiLSTM模型[36],最后一层全连接,使用softmax归一化得到分类结果.
2)BiLSTM-CRF:采用Huang等人[37]的模型,由于BiLSTM不能充分考虑标签之间的依赖关系,可能产生不合规则的标签序列.后接入的CRF层可以学习整个句子的标签转移概率,充分地考虑上下文标签间的依赖关系.
3)Char-BiLSTM-CRF:采用Ma等人[38]的模型,在BiLSTM方法的基础上,添加一层字向量BiLSTM训练层,字向量与预训练的Word2vec词向量拼接作为BiLSTM的输入,最后一层再接入CRF层.
4)Char-BiLSTM-CRF(ELMo):将Char-BiLSTM-CRF中的Word2vec词向量替换成ELMo词向量[4].
5)Char-BiLSTM-CRF(BERT):将Char-BiLSTM-CRF中的Word2vec词向量替换成BERT词向量[4].
4.4 实验结果和分析
各模型在测试集上的实验结果如表6所示.表6显示,增加字向量和CRF层都能显著改善自杀意念原因抽取效果,词向量采用BERT时提升性能较明显.因此,使用Char-BiLSTM-CRF(BERT)模型考察基于标签增强LWS和基于EDA的数据增强效果.结果显示,使用数据增强后,Char-BiLSTM-CRF(BERT)模型在各个评测指标上都显著优于其它对比模型,如使用LWS增强后(+LWS),Char-BiLSTM-CRF(BERT)模型在评测指标C_F、P_F、E_F和F_F上比BiLSTM模型分别提高了17.4%、9.6%、11.5%和10.2%,比Char-BiLSTM-CRF(Word2vec)分别提高了9.3%,6.2%,9.6%和8.0%,比不使用增强数据时的Char-BiLSTM-CRF(BERT)分别提高了1.1%、1.2%、1.9%和2.1%;使用EDA增强后(+RD+SR),Char-BiLSTM-CRF(BERT)的C_F、P_F、E_F和F_F比BiLSTM分别提高了17.2%,9.0%,11.6%,10.1%,比不使用增强数据时的Char-BiLSTM-CRF(BERT)分别提高了0.9%、0.6%、2.0%和2.0%.
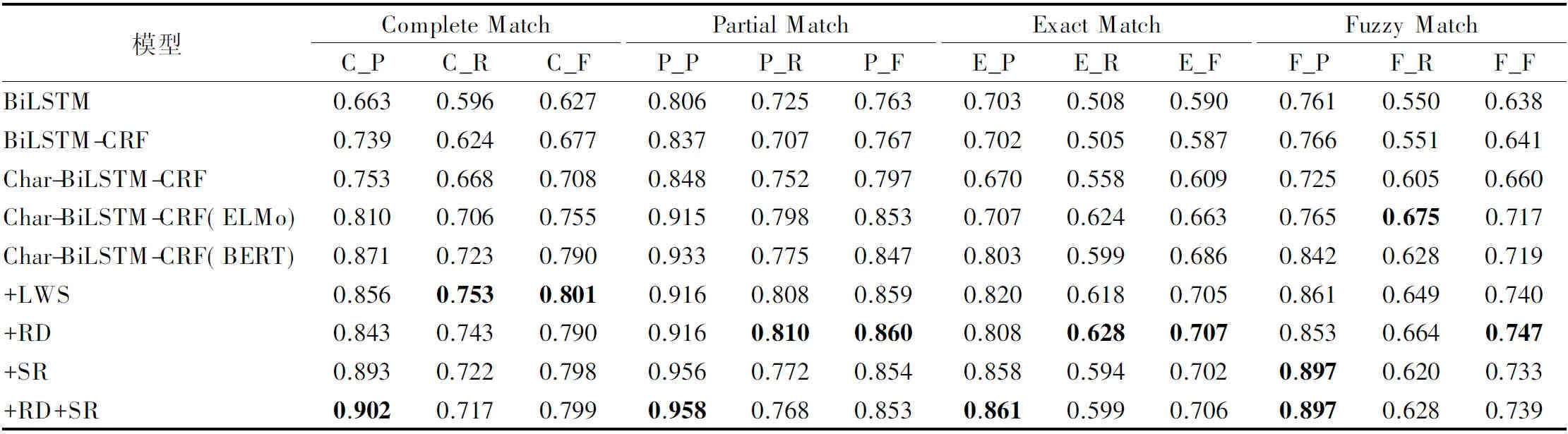
表6 实验评测结果
下面对这两种数据增强算法的实验结果进行分析.
4.4.1 标签增强方法LWS的实验分析
使用标签增强方法LWS进行数据增强后,Char-BiLSTM-CRF(BERT)的C_F、P_F、E_F和F_F分别提高了1.1%、1.2%、1.9%和2.1%.
LWS数据增强前后,训练集中自杀意念原因短语的统计信息如表7所示.表7中,m_train为训练集中帖子数量,n_causes为其中的原因数量,未增强前原训练集包括4794条微博帖子,共11653个原因短语.以词为单位,其中最长的自杀意念原因短语为20,最短的为1,平均长度约为2.而长度小于或等于6的原因短语占总数的97.6%,说明原训练集中大多数原因短语人工标注较短,因此本文LWS增强只采用扩充的方法.LWS增强后,训练集增强至5449条帖子,增加了13.7%,包括13926个原因短语,增加了19.5%.

表7 训练集的自杀意念原因短语统计表
1)参数MaxL的影响
如图2所示,在恰当的扩充长度下,4种评测结果都得到了提升,其中局部匹配法P_F对MaxL变化不太敏感.这说明,利用LWS随机缩放的标签增强方法在局部匹配评测法中表现较好.这不难理解,局部匹配法相对其他评测方法较宽松,只要模型标注的原因与理想标注之间有重叠,即视为标注正确,而大多数标签标注太短,在对标签进行扩充,使得模型会得到更长的原因短语,从而与人工标注重叠的机会更大.
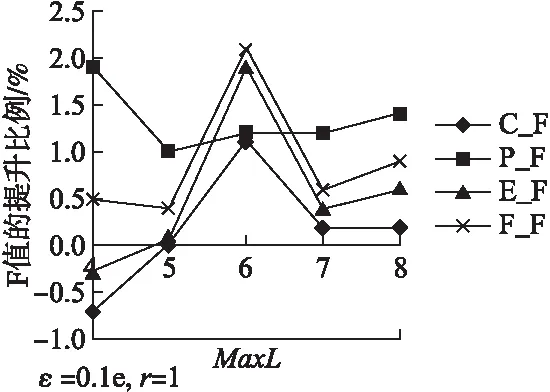
图2 LWS参数MaxL变化时评测结果对比图
其他评测指标对MaxL变化较敏感,并且,当MaxL=4时精确匹配法E_F和完全匹配法C_F值甚至低于没有进行标签扩展的原始训练集.在4种评测指标上,完全匹配法C_F的提升最低,因为C_F要求原因短语的各个词的标签(B,M,E)都完全标注正确,评测要求较苛刻的原因使得提升不明显.
2)参数ε的影响
不同参数ε扩充得到的帖子数量如表8(MaxL=6,r=1),m_train为数据增强后训练集中帖子的数量,m0_train为原训练集中帖子的数量,△m为不同ε取值下,相对原训练集新增的帖子数量,△m/m0_train为新增的比例.不同标签增强率ε时的评测结果如图3所示.

表8 使用不同的ε增强后的帖子数量
图3中,在不同的ε值下,只有局部匹配法P_F始终优于原训练集,而其他3种评测方法均在ε>0.1×e后开始下降.其中,完全匹配法C_F和精确匹配法E_F甚至在ε≥0.2×e时就低于在原训练集上的评测结果,而模糊匹配法F_F则在ε>0.3×e时开始低于在原训练集的评测结果.
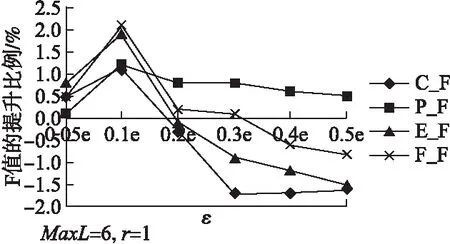
图3 ε对评测结果的影响
当标签增强率ε=0.1×e时带来的收益最高,增强效果达到最优,此时样本数量增加了10%左右.这说明,LWS针对样本中较小比例的标签加入干扰或噪声时,增强的效果较好,这也与其他数据增强研究结果一致,比如,EDA指出小数据集中小α带来的改善是好的,并推荐设定帖子增强率α=0.1.通过增强得到的帖子随着ε的增大而增多时,会严重损害增强的表现,这说明增加太多的相关数据样本不但不能提高模型的抽取性能,反而会降低性能.
3)参数r的影响
不同参数r扩充得到的帖子数量如表9所示(ε=0.1e,MaxL=6),m_train为训练集中帖子的数量,m0_train为原训练集中帖子的数量,△m为不同r取值下,LWS对Char-BiLSTM-CRF(BERT)的训练集新增的帖子数量,△m/m0_train为新增帖子数量占原训练集数量的比例.不同参数r时的评测结果如图4所示.

表9 使用不同的r扩充后的帖子数量
图4中,LWS的参数r=1时4种评测结果的F1值都得到最好的提升,而在r>1时,增强效果开始急剧下降.由于参数r是缩放概率p与原因短语长度l和缩放长度△l的比例系数,r=1时,p随着l和△l的增加而较平缓地下降,产生较长或较短原因短语的高概率得到了一定的保持.相反,随着r增大时,得到较长或较短原因短语的概率会急剧地下降,使得标签仅在已有原因短语上做更细微的变化,达不到标签扩展的目的.
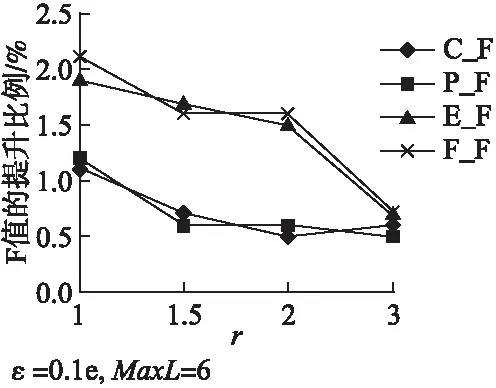
图4 参数r对评测结果的影响
以原因短语为评测粒度的完全匹配法C_F和局部匹配法P_F在r≥1.5后趋于平稳,且相比原训练集都只有约0.5%的提升,这说明,此时扩充得到的训练数据集,标签只在原始原因短语上做了很细微的补充或删除,几乎没有增强的效果.在以词为评测粒度的精确匹配法E_F和模糊匹配法F_F上,评测结果在2≥r≥1.5时较平稳,但在r≥2开始下降,一个主要的原因是,当原因短语的标签在头尾部小幅度调整后,加入的头尾部边界外的词属于非原因类的概率加大,导致模型在以词为评测粒度时的评测结果下降.
4.4.2 基于EDA的数据增强实验分析
基于EDA的数据增强尝试了RD、SR、RI和RS 4种方法.仅使用RI或RS时效果不好.当α=0.2,num=3时,单独使用RD增强后的Char-BiLSTM-CRF(BERT)的评测结果分别提高了{C_F:0%;P_F:1.3%;E_F:2.1%;F_F:2.8%};单独使用SR增强后的Char-BiLSTM-CRF(BERT)的评测结果分别提高了{C_F:0.8%;P_F:0.7%;E_F:1.6%;F_F:1.4%}.同时运用RD和SR(参数发生改变,α=0.1,num=3)数据增强后,Char-BiLSTM-CRF(BERT)的评测结果分别提高了{C_F:0.9%;P_F:0.6%;E_F:2.0%;F_F:2.0%}.
1)参数α的影响
帖子增强率α={0.1,0.2,0.3,0.4,0.5,0.6}时的评测结果如图5所示.图5中,基于EDA的数据增强操作并不都有助于提高模型的抽取性能.当α≤0.2时,使用RD或SR增强后四种评测结果都呈现线性上升.当α≤0.4时,P_F、E_F和F_F都超过了原训练集的评测值,而当α>0.3时4种评测结果基本均呈下降趋势,甚至α>0.4时评测结果开始低于原训练集的评测结果,说明数据增强在比较小的改变中效果较好.这4种评测结果里依然是完全匹配法C_F提升最小.有趣的是,基于EDA的数据增强在E_F和F_F上表现较好,说明基于EDA的数据增强对于原因短语里面单个词的识别度在提升.
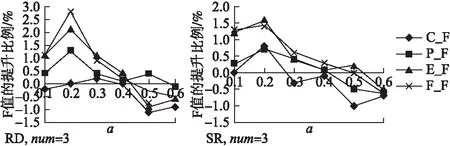
图5 参数α对评测结果的影响
具体来说,RD增强方法在α=0.2时的整体平均得分最高,比增强前的评测结果分别提高了{C_F:0%;P_F:1.3%;E_F:2.1%;F_F:2.8%}.C_F提升较缓慢,且在α=0.3时继续提高了0.2%.但在高α值时,数据增强的表现会受到严重影响,可能的原因是,一条帖子里如果删除太多的单词,句子的语义就不再完整,很可能导致模型无法理解.对于SR来说,也是α=0.2时性能增益最好,比增强前的评测结果分别提高了{C_F:0.8%;P_F:0.7%;E_F:1.6%;F_F:1.4%},但高α时评测值也会急剧下降,可能是因为在一条帖子中替换太多的单词会改变整个帖子的同一性和影响语义的流畅性.总的说来,α=0.2是实验得到的最佳参数.
2)参数num的影响
当参数num={1,2,3,4,5,6}时,基于EDA的数据增强的评测结果如图6所示.当num≤3,RD和SR都是有效的,num=3增强性能达到最优,但当num>3时,4种评测结果开始趋近于稳定,不再明显提升.说明num较小时数据存在某种程度的过拟合,因此一定的数据增强会提高性能.当num增加到一定程度时,训练集中已经存在足够的数据能让模型较好的学习,提升趋近饱和,这也同时说明数据增强的提升只能在一定范围内有效.
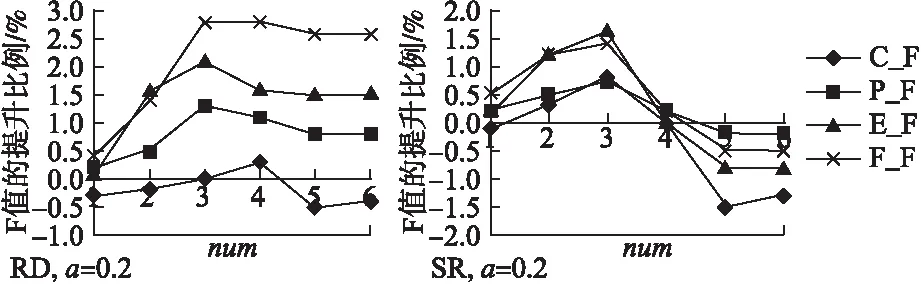
图6 参数num对评测结果的影响
当同时运用RD和SR时,α=0.1,num=3时,4种评测结果达到最优,比Char-BiLSTM-CRF(BERT)的评测结果分别提高了{C_F:0.9%;P_F:0.6%;E_F:2.0%;F_F:2.0%}.
使用EDA进行数据增强时,原帖子的语法结构和语义可能发生改变,这种情况会随着增强率的增加而加剧.如表10实例所示(整条帖子除原因短语共有17个词).当使用SR增强时,随机替换较多的词后(α=0.3,替换5个词),语义发生了极大的改变,如“撤出”和“找”两个含义完全不同的动词出现在相邻的位置.当使用RI增强时,即使随机插入较少的词(α=0.1,插入2个词),语法结构和语义也可能遭到破坏,如“相当”插入在“多”的后面.

表10 EDA增强后语义改变实例
本文还对RI和RS的增强效果进行了实验,但它们在不同的α值下的收益都较差,甚至低于原训练集上Char-BiLSTM-CRF(BERT)的评测结果,可能是因为本研究以中文词为单位,进行随机插入和随机交换后,在某种程度上会改变原帖子的语法结构,使得语义发生了改变,丧失了原训练数据的语义结构和语义顺序.
此外,本文还将LWS和基于EDA的两种增强方法同时用于训练集中,模型的抽取效果反而下降,也再次说明数据增强在增强操作较少时效果较好.过多的数据增强操作会破坏句子的语义,损害模型的性能.
5 总结与展望
文本数据增强的研究是近几年在图像数据增强的基础上发展起来的,但文本数据之间存在着较强的上下文语义相关性,以及整条文本语法和语义信息的完整性,使得文本数据增强的研究仍具有一定的挑战性.从数据增强相关文献所使用的数据集和应用背景来看,目前还未检索到在文本序列标注问题上探讨标签增强的工作,也极少有针对社交文本(如微博数据集)的数据增强研究,更没有应用在原因抽取方面的相关成果.本文主要探讨自杀意念原因抽取研究中关于文本序列标注的标签增强问题,即针对人工标注中由主观因素造成的标注边界模糊和误差现象,以及样本量较小的问题进行数据增强.生成随机性和多样性的训练样本,避免过拟合现象,提高自杀意念原因抽取模型的健壮性和鲁棒性.
本文尝试了两种数据增强算法:1)基于标签窗口缩放的标签增强方法LWS;2)基于EDA的数据增强,包括同义词替换SR、随机插入RI、随机交换RS和随机删除RD四种方法.实验结果表明,在LWS中,当ε=0.1e,MaxL=6,r=1时,LWS 4种评测结果相对达到局部最优,Char-BiLSTM-CRF(BERT)的评测结果比数据增强前分别提高了{C_F:1.1%;P_F:1.2%;E_F:1.9%;F_F:2.1%}.在基于EDA的数据增强中,α=0.2,num=3时增强性能达到最优.说明使用数据增强方法在训练集内进行比较小的改变时,性能增益较好,引入的干扰太多和过多的数据增强甚至会损害模型的性能.
本文的数据增强属于词语级或短语级的数据增强,主要从标签、词义或形式的角度,对文本即微博帖子进行局部更改或拼接,产生与原始文本结构相似的文本.方法易用性、通用性、可解释性较好,它不需要预训练语言模型,也不需要外部数据集和额外的超大语料库的支持,但生成的增强文本数据集多样性和可变性也不大.下一步工作将从句子级生成的多样性和知识迁移等方面来开展,并可尝试将心理学和语言学两种先验知识引入到标签增强中.
猜你喜欢
诗潮(2021年12期)2021-12-23
海外星云(2021年6期)2021-10-14
初中生学习指导·中考版(2020年5期)2020-09-10
现代养生·上半月(2020年5期)2020-05-15
微型计算机(2009年4期)2009-12-23
现代计算机(2009年9期)2009-12-02
移动信息(2009年4期)2009-06-18
数码世界(2009年3期)2009-04-26
精武(1999年12期)1999-06-13
