
融合多特征的语音情感识别方法
2022-05-27 01:06王黎明柴玉梅
小型微型计算机系统 2022年6期
王 怡,王黎明,柴玉梅
(郑州大学 信息工程学院,郑州 450001)
1 引 言
语音是人类之间最快速、高效的一种交流手段.随着人工智能的发展,语音交流已不再是人类独有的专利,语音也是人机交互最自然和理想的方式之一.目前,研究表明人机交互中机器虽已实现与人类进行交流的基本功能,语音识别的能力已经得到了很大的提高,但往往忽略了语音中包含着丰富的情感信息.而机器要更加自动适应操作者的需要,关键在于能够充分理解人类的情感,因此语音情感识别技术的研究成为了人工智能研究领域非常重要的一个任务.
语音情感识别任务的挑战是找到包含情感的表示特征.语音声学信号中用于情感识别的特征可以分为3类:韵律特征、音质特征和基于谱的相关特征[1].语音情感特征提取的方式大致可分为两类:1) 使用低层次手工设计的特征(Low Level Descriptors,LLDs)来进行分类[2,3],将不同的统计函数(High-Level Statistical Functions,HSFs)(例如均值、最大值、方差等)应用于每一个LLDs,并将结果在话语层面上连接成一个长的特征向量.LLDs是在一帧的语音上进行的计算,用来表示帧级语音特征,HSFs的作用是描述不同的LLDs在说话过程中的变化,而不仅仅是短期LLDs的静态值;2) 利用深度神经网络提取深度学习情感特征进行分类.由于深度学习在视觉领域和语音识别中的成功应用,基于深度学习语音情感识别引起了研究者的广泛关注,许多研究者考虑直接将语音的频谱图输入到深度学习模型中学习情感特征,例如文献[4,5]使用频谱图在卷积神经网络(CNN)中进行语音情感识别,文献[6,7]使用长短期记忆人工神经网络(LSTM)提取语音特征进行分类,取得了很好的效果.研究表明,手工特征和深度学习情感特征从不同的角度描述了情感信息,但是对于语音情感识别任务的最优通用特征集,目前仍然没有明确的结论.
语音的情感不仅包含在声学特征中,还包含在语义特征中,以往文献考虑语义特征时采用的都是多模态信息.文献[8]使用包含强度、基频、频谱等声学特征和用传统词袋表示(Bag Of Words Representations)方式得到文本的情感向量,进而实现情感识别.Seunghyun Yoond等人使用包含MFCC、韵律特征的声学特征与文本特征进行融合,文本中每个词都被转成词向量,然后使用LSTM进行分类[9,10].文献[11]使用面部表情、语音和文本信息进行语音情感识别,使用文本输入LSTM得到输出向量,FACET模型提取面部表情特征向量,以及声学特征,然后将这3模态特征融合进行情感识别.最近有新的研究者探索语音识别(ASR)模型中包含的情感语义特征,如文献[12]检测ASR提取的语音特征中靠近语音层和靠近文本层与valence和arousal之间的关系,文献[13,14]使用端到端ASR模型将语音情感分析问题作为下游任务来解决,证明了在ASR过程中能够得到包含情感的特征.虽然多模态的效果大多数表现的比单模态好,但是在很多情况下面部表情是不能同时得到的,本文不涉及面部表情方面,所以只与语音和文本双模态作对比,而使用文本只能识别有明显的情感词的情感,在语音情感识别任务中其作用显然是不够的.
特征融合的方法在很多任务中都表现出了很好的效果,常见的特征融合方式有特征级融合和决策级融合[15].在语音情感识别领域使用的多数为特征级融合方式,将所有由语音信号得来的声学特征作为一个整体,然后再和其他特征拼接,在文献[8-10]中都是将韵律特征和MFCC整体作为一个向量,然后和文本特征向量串联得到融合后的特征.由于声学特征中的不同类别特征之间关联性比较大,差异性较小,将所有的声学特征作为一个整体会缩小它们之间的差异,放大共同的特征,并不能充分发挥所有声学特征的优势.
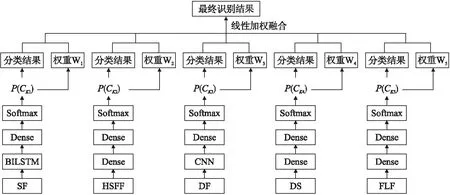
本文提出了多特征融合的语音情感识别方法,首先在声学特征中,不仅包含低层手工特征,还加入了启发性特征,其包含3部分:1)提取低层次手工特征集,并在低层手工特征集之上计算高级统计特征;2)使用DNN得到与谱相关的深度学习特征;3)使用CNN提取帧级Fliter_bank的深度学习特征,语义特征使用ASR作为特征提取器.然后对这4类特征使用特征级融合,并在其结果之上使用决策级融合进一步提升语音情感识别效果.
2 多特征提取
语音的声学特征和语义特征从不同的角度描述情感信息,这两种特征在情感识别任务中都有一定的效果.
2.1 声学特征提取
语音情感声学特征分为韵律特征、音质特征和基于谱的相关性特征.韵律特征指语音中音的高低、时长、快慢、大小等特点,包括时长相关特征、基频相关特征和能量相关特征[1,16,17],它的存在会影响我们对话语的情感判断,在很多现有的特征集中都包含韵律特征作为情感特征[18-20].音质特征是反映声音是否清晰、纯净、辨识度是高是低等[21],日常生活中人们发出的声音带有不同的声音质量,因此研究者们也把声音质量作为不同情感的代表,目前反映声音质量的语音特征有以下几种:共振峰频率、共振峰带宽等.基于谱的相关性特征:声道的形状变化和发声运动之间的联系产生了频谱相关的语音特征.本文相对其他文献中的声学特征多了启发性特征.
2.1.1 低层次手工特征集提取
目前文献中的手工特征集大部分都是使用已有的由一些专家设计的特征,如:ComParE特征集、2009 InterSpeech挑战赛特征、eGeMAPS特征集、GeMAPS特征集,这些特征集虽然具有代表性,在情感识别中取得了效果,但是由于是设计好的特征,难免会有一些多余特征或者有些特征没有考虑到,结合文献[1,16,17]的介绍和多次实验后,本文使用librosa库提取自己定义的低层次手工特征.
对每个语音进行分帧,其中帧长为25ms,帧移为10ms,得到每个语音的语音段a=(a1,…,aT),在每个语音段上提取LLDs,得到LLDs=(L1,L2,…,LT).本文提取LLDs可由:1)韵律特征:时长、短时平均能量、基频(F0)、短时能量、短时过零率、声压级;2)音质相关的特征:使用LPC求根法估计每帧前3个共振峰的中心频率及其带宽;3)基于谱相关的特征:梅尔频率倒谱系数(MFCC)特征、谱中心、谱对比度、色谱能量归一化组成.在LLDs之上使用HSFs对各个特征进行计算,得到经过统计函数之后的特征HSFF=(H1,H2,…,HT),具体的LLDs和HSFs如表1所示.

表1 低层手工特征(LLDs)及应用的统计函数(HSFs)表
2.1.2 基于谱相关深度特征提取
将谱相关的特征spectrum=(S1,S2,…,ST)提取出来,因为谱相关信息对于情感识别的贡献度更大,而为了得到更高层次的特征和便于后期做特征融合,使用DNN提取其深度特征(Deep Spectrum,DS),该DNN有3个隐藏层,每层有512个激活函数为leakly_relu的隐藏单元和权重WDS,经过验证更多的隐藏层并不会提升最后的效果.DS的计算公式如公式(1)所示:
DS=leakly_relu(spectrum,WDS)
(1)
2.1.3 基于Filter_bank的深度特征提取
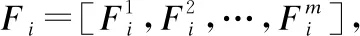
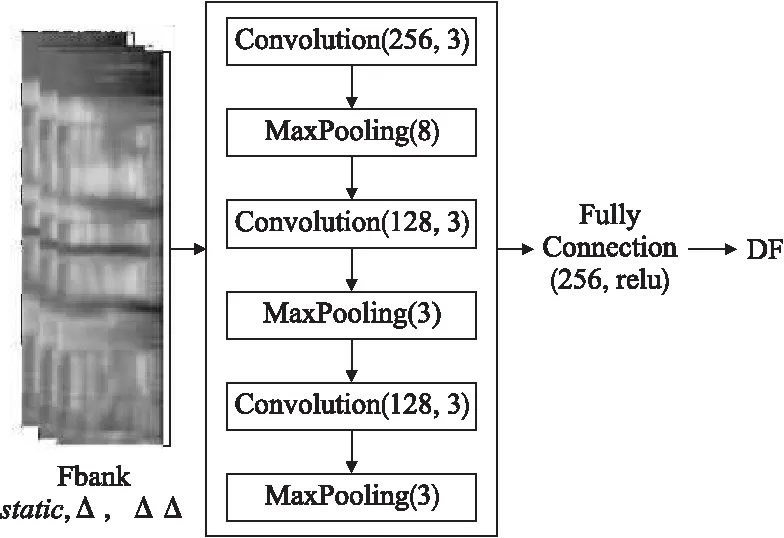
图1 Deep Fbank特征提取结构图
hi=maxpooling(convolution(Fi))DFi=relu(WDF,hi)
(2)
2.2 语义特征提取
使用文本做情感分析时只能识别带有明显情感词的句子情感,但在语音中人们往往表达的情感并不与文本完全一致.自动语音识别(ASR)中间层特征包含带有情感的语义特征,故本文使用ASR提取语义特征.文献[22]总结了语音识别中“端到端技术”的发展.本文使用端到端模型中的LAS(Listen,Attend and Spell)[23],因为它的模型简单且识别的准确率较高.
LAS模型中的encoder模块(listen)类似于传统ASR框架中的声学模型,将x=(x1,x2,…,xT)编码为短的高级别声音特征序列h=(h1,…,hj),在本文中使用的语音信号是音频文件的每一帧的39个Mel频率倒谱系数(13个MFCC+13个一阶微分系数+13个加速系数),decoder模块包含attention和spell,作为传统ASR框架中的语言模型,计算h到y的概率分布,得到字符y1,y2,…,yS[23].
Encoder端的计算公式如公式(3)所示,其中Listen使用双向LSTM金字塔结构.
(3)
Decoder端的计算包含3个步骤:
1)计算decoder当前时刻的状态si.由上一时刻的状态si-1,上一时刻的输出yi-1,上一时刻的上下文(context)ci-1计算得出.
si=LSTM(si-1,yi-1,ci-1)
(4)
2)计算当前时刻的上下文向量(context)ci,由当前时刻的状态由当前刻的状态和高级声音特征h计算得出.
Ci=AttentionContext(si,h)
(5)
3)计算概率分布
(6)
Encoder作为特征抽取器,它将语音中有用的信息编码为高级特征h1,…,j,本文将encoder端的输出提取出来作为包含情感的语义特征.该部分算法如算法1所示,结构如图2所示.由于提取出来的向量具有语义信息,为句子级别的特征,具有序列性,所以使用BILSTM来建模,然后经过Flatten之后通过全连接层,最后使用具有softmax激活函数的全连接层得到由语义特征预测的情绪类别.将带有softmax的全连接层的前一层向量提取出来作为语义特征(Semantic Features,SF).
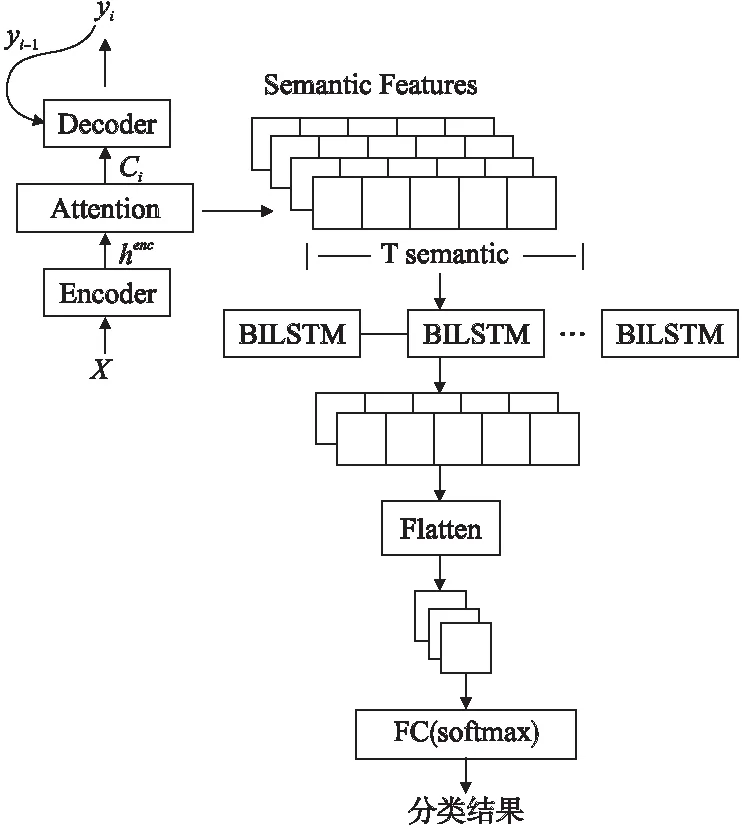
图2 语义特征提取模块图
算法1.语义特征提取算法
输入:语音A=[a1,a2,…,aT]表示原始语音数据集,由训练好的LAS模型encoder层生成的每个语音对应的hi,全局学习率,衰减速率ρ,初始参数θ,迭代次数m
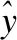
1.使用RMSProp算法更新参数,初始化模型参数和累积变量r=0
2.迭代次数epoch=0
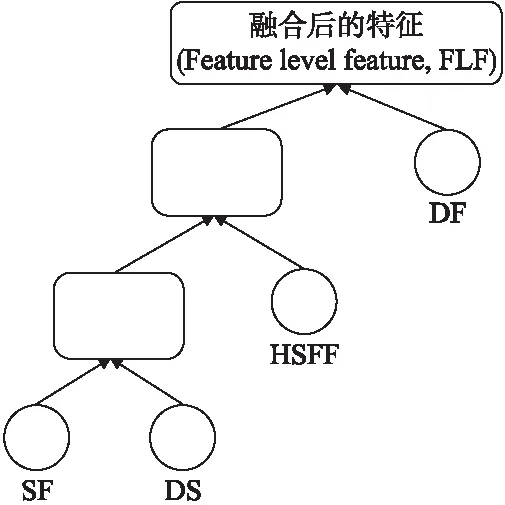
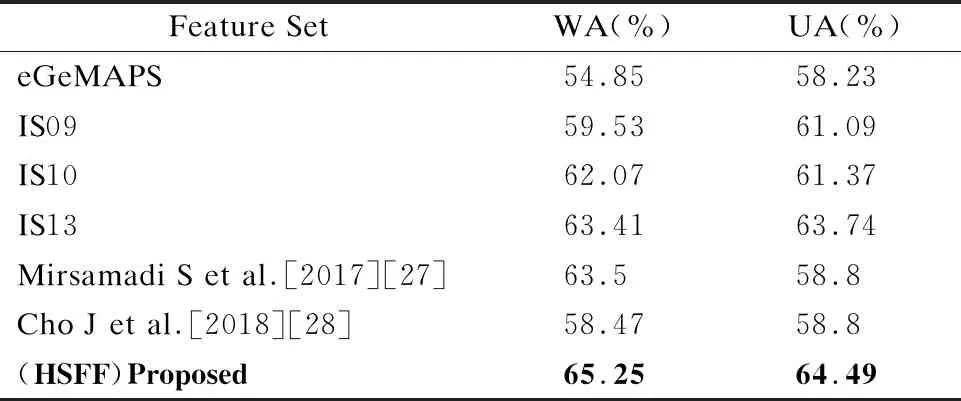
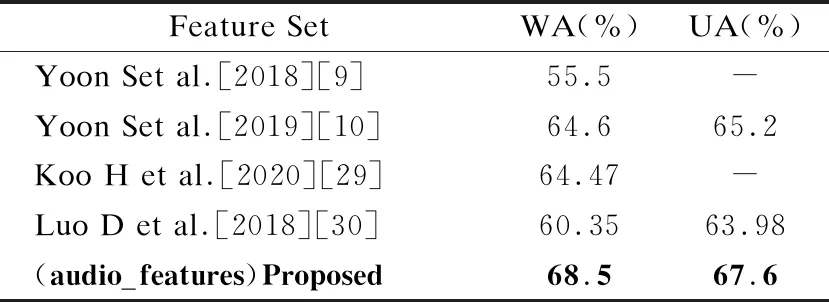
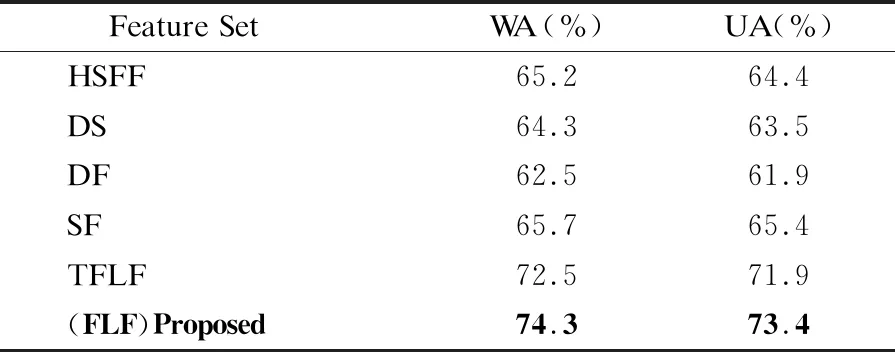
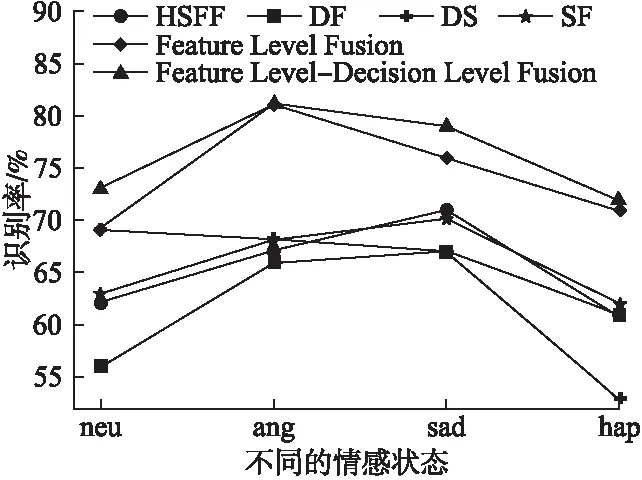
3.While epoch 4. Foraiin A: 5. 前向传播: 6.hb=[hL,hR],hL=LSTM(hi),hR=LSTM(hi) 7.H=σ(Wh+b) 9. 反向传播算法更新参数w,b: γ←ργ+(1-ρ)g⊙g 12. (对于参数b的操作和参数w相同) 13. Epoch+=1 15.End while 在很多工作中,融合不同的特征是提高分类性能的一个重要手段,由于语义特征和声学特征从不同的角度描述了语音的情感状态,并且存在于各自的空间特征中,因此这两种特征具有互补性,共同使用这两种特征能够获得更好的性能.虽然有单独探索单模态中的声学特征和单模态中的语义特征,但是还没有将两者结合起来的.本文研究了在这两者之上使用特征级融合和决策级融合的方案. 最优二叉树又称哈夫曼树,它是一类带权路径长度最短的树[24].若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权.结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积.它可应用于很多领域,常见的有利用哈夫曼树的最短带权路径长度可以减少程序中的比较次数,从而提高程序的运行速度,还可用于求得给定字符集及其频率分布的最优前缀码.已知一组叶子的权重(W1,W2,…,Wn),则构造最优二叉树的过程为: 1)将权重为(W1,W2,…,Wn)的n个结点构造为n棵二叉树(T1,T2,…,Tn),并组成森林T={T1,T2,…,Tn},其中每棵二叉树Ti仅有一个权值为Wi的根节点; 2)在T中选择两个根节点权值最小的树作为左右子树构造一棵新的二叉树,新生成的二叉树根节点的权值是两棵子树权值之和; 3)从T中删除这两棵子树,并将新生成的二叉树加入到T中; 4)重复2)3)过程直到T中只含有一棵二叉树为止,该树即为最优二叉树,即哈夫曼树. 本文为了在特征级融合时得到不同特征的融合先后顺序,采用了类似构造哈夫曼树的方法,首先得到每一种特征的情感识别准确度Accuracyi,从而得到其错误率(Error Rate,ER)ERi=1-Accuracyi,其中(1≤i≤4).将每一类特征看做叶子结点,错误率看做权重,但是新生成的二叉树根节点不是两棵子树权重之和,而是两个特征融合后得到的情感识别错误率,最终构建好的一棵哈夫曼树的根节点即特征级融合生成的特征.本文特征级融合的结构图如图3所示,图3中的叶子节点分别代表要进行特征级融合的4类特征,生成最终二叉树的根节点为要得到的融合特征,特征级融合如算法2所示. 图3 特征级融合结构图 算法2.特征级融合算法 输入:声学特征中的HSFF、DS、DF,语义特征(SF) 输出:哈夫曼树根节点t 1.得到不同特征Fi对应的ERi(1≤i≤4) 2.初始化数组HuffmanTree,将所有元素的双亲(parent)、左孩子(lchild)和右孩子(rchild)都设为-1 For j in range(0,2×i-1): HuffmanTree[j].parent=-1 HuffmanTree[j].lchild=-1 HuffmanTree[j].rchild=-1 3.将数组的前i个元素的权值设置为ERi For j in range(0,i): HuffmanTree[j].weight=ER[j] 4.循环开始合并,生成最终融合特征 For k in range(i,2×i-1): Two min(HuffmanTree,i1,i2) Fconcat=[Fi1,Fi2] HuffmanTree[k]=1-softmax(Fconcat) HuffmanTree[i1].parent=k; HuffmanTree[i2].parent=k; HuffmanTree[k].lchild=i1; HuffmanTree[k].rchild=i2; 5.Return t=HuffmanTree[2×i-1] 6.end 若只使用特征级融合直接对不同特征进行数据融合,会忽略不同特征对识别结果的贡献程度,同时也会忽略各个特征受到干扰的程度,从而导致情感识别的准确度有一定的误差,因此本文在特征级融合之后又引入了决策级融合(Decision Level Fusion,DL)来更准确的考虑不同特征的贡献程度.决策级融合方法是一种高层次的融合,通常先训练各个特征,再融合多个特征的输出结果,它的优点是抗干扰性能和容错性能比较好,多个特征的错误通常是不相关的,不会因为一种特征的识别准确度不好而导致整体的识别准确度下降,即不会造成错误结果的进一步累加.决策级融合方法主要依据相关规则,如按照均值、最大值、投票机制等进行决策融合,得到最终的情感识别结果.最简单的决策级融合方法为求每个分类结果中的最大值,如公式(7)所示,其中Pi为同一样本不同特征得到的识别结果. class(x)=argmax(Pi(x)) (7) 但是这种方法会忽略不同特征各自的结构特点,没有区分不同信号对情感状态表现上的差异性,不同的情感特征对情感状态的表现力是有差别的,故对情感状态识别率的影响也有大有小,因此本文使用带权值的投票法进行决策级融合,对于由不同特征得到同一样本的识别结果,若其识别准确度高,则其占的权重应该更大,若其识别准确度低,则其占的权重应该较小. 统计经过特征级融合后的特征以及原始4类特征(HSFF,DS,DF,SF,FLF)的识别精度,识别精度可由上一小节得出,以此作为先验知识,将其表示为投票的权重,从而进行决策级融合.决策级融合分为3个步骤: 1)分别得到4类原始特征和3类声学特征融合后的特征对情感状态的识别率,则可以得到5个融合后特征的加权矩阵Wi(1≤i≤5)为: (8) 3)基于最大值规则,得分最高的第K类情感状态即为最终识别结果,即: (9) 特征级-决策级融合的结构图如图4所示,算法见算法3所示. 图4 特征级-决策级融合结构图 算法3.特征级-决策级融合算法 输入:算法2的输出为经过特征级融合之后生成的特征(Feature Level Feature,FLF),声学特征中的HSFF、DS、DF,语义特征(SF),全局学习率,衰减速率ρ,初始参数θ,迭代次数m 1.使用RMSProp算法更新参数,初始化模型参数和累积变量r=0 2.迭代次数epoch=0 3.While epoch PCK1=softmax(W1FLF+b1) PCK2=softmax(W2HSFF+b2) PCK3=softmax(W3DS+b3) PCK4=softmax(W4DF+b4) PCK5=softmax(W5SF+b5) 4.更新参数w,b: 5.Classi=max(P(CKi))(1≤i≤5) 6. Epoch+=1 7.得到分类结果Classi(1≤i≤5) 语音情感识别任务使用的数据集为IEMOCAP[25].交互式情绪二元运动捕捉(IEMOCAP)数据库是一个动作、多模式和多峰值的数据库.它包含大约12小时的视听数据,包括视频、语音、面部运动捕捉、文本转录.它包含了10个男演员和女演员在情感二元互动过程中的数据,数据库包含即兴表演和脚本化会话.按照文献[9,10]中的使用的hap、neu、sad、ang这4种情感状态,将exc的样本合并到hap中,最终使用的数据集包含5531个话语,{ang:1103,hap:1636,neu:1708,sad:1084}.由于数据集事先没有划分训练集、验证集和测试集,且特征融合需要在同一数据集上多次运行,因此使用sklearn将数据集按照8:1:1划分为训练集、验证集和测试集,随机种子设为42.而在语音识别任务中使用的数据集是VCTK[26],它包含109名以英语为母语的本地人朗读的44个小时数据,每位朗读者读大概400句子,这些句子大部分是从报纸中选出的. 根据[9,10,27,28]文献中使用的加权精度(WA)和未加权精度(UA)来衡量模型的性能,本文也使用WA和UA作为评估.WA是传统的分类精度,即模型正确标记样本的百分比.为了避免类不平衡对WA的影响,所以展示了不同类别的平均精度UA,而ASR任务的评估指标为字错率(Word Error Rate,WER).WA、UA、WER的计算公式如公式(10)~公式(12)所示,在公式(12)中S为替换的字数,D为删除的字数,I为插入的字数,H为正确的字数. (10) (11) (12) 4.2.1 基于低层次手工提取特征的性能对比实验 本文并没有像其他文献使用现有的手工特征集,为了验证本文提取手工特征集的有效性,在相同的模型上对ComParE特征集、eGeMAPS特征、IS09_emotion特征集和IS10_emotion特征集做了对比试验.表2给出了不同手工特征下的识别性能对比,其中前4行使用的是现有的特征集,分别是eGeMAPS、IS09_emotions、IS10_emotions 、IS13_emotions,它们由用openSMILE来提取的特征集.第5、6行是和文献[27,28]使用的手工特征集做了对比,最后一行为在本文提取的LLDs的基础上使用HSFs后得到的高级统计特征(HSFF)作为模型的输入.在此次实验中用得到模型为DNN,通过不同的层数组合显示出最好的分类结果为2层的隐藏层,其中神经元个数分别为 512、512.使用的激活函数为leakly_relu,alpha的值为0.1,在输入层之后使用dropout为0.5,在输出层之前使用dropout为0.2. 表2 基于HSFF性能对比试验表 结果如表2所示,使用openSMILE提取的特征集中IS13_emotions效果表现最好,由于该特征集中特征维数有6373维,包含了大量的信息,但同时其维度太高计算起来很费时间.本文提取的手工特征经过HSFs之后虽然只包含670维的数据,但是在情感识别上的加权识别度并没有降低,相较于文献[27,28]中使用的特征集结果也有所提高. 4.2.2 基于声学特征的性能对比实验 由于本文在声学特征中提出了3类,为了验证提取声学特征的有效性,本次实验在只有声学特征的条件下和文献[9,10,29,30]做了对比,文献[9,10]使用语音和文本双模态做情感识别,其中在语音模态中使用MFCC和韵律特征作为声学情感特征,将MFCC送入到RNN中生成的特征向量与韵律特征串联之后做情感识别.文献[29]使用MFCC和韵律特征,将其输入GRU中进行语音情感识别,文献[30]使用频谱图和ComParE特征集作为声学情感特征,分别将频谱图用CNN-RNN提取特征,将ComParE特征集送入DNN中,再通过级联之后进行分类.为了有对比性,本文也将3种特征直接串联之后,送入到两层隐藏层的DNN中进行分类,每层的隐藏单元数分别为512、256.实验结果如表3所示. 表3 基于声学特征的情感识别效果表 本文提取的3类声学特征包含了在不同的角度对声学信号中的情感描述,不仅使用低级特征,还应用了高级特征和深度特征,从表3结果可看出在只使用声学信号的情况下,本文的语音情感识别准确度和文献[29]相比提高了4%左右. 4.2.3 基于语义特征的性能对比实验 为了验证了LAS模型在语音识别任务上的效果,在数据集VCTK和IEMOCAP上做了验证.LAS模型中listen模块中使用的是金字塔结构的BILSTM,每层有128个隐藏单元,spell模块使用两层LSTM,每层有128个隐藏单元,训练时的batch_size为32,使用的Adam优化器,学习率为0.001,在不同数据集上的WER结果如表4所示. 表4 VCTK和IEMOCAP在LAS模型中的识别效果表 为验证本文提取的语义特征中包含的情感信息比文本中的情感信息多,本次实验将提取到的语义特征与文献[9,10,28]中直接使用文本进行情感识别做对比.在文献[9,10]中将文本分词之后生成的300维词向量用RNN做情感识别,文献[28]使用由不同核大小的并行卷积提取不同层次上的上下文信息做情感识别.本文将提取到的语义特征使用BILSTM作为分类器,实验结果如表5所示. 表5 基于语义特征的情感识别效果表 如表5所示,使用LAS模型提取出的语义特征在情感任务中效果要略好于使用文本提取的特征,是因为在很多情况下,人们说出来的文本和表达的情感并不是一致的,这就导致只使用文本只能分别出带有显性情感词的语音情感.而本文所提取出的语义特征是语音识别模块中间层的输出,既包含声学信息,又包含文本信息,因此在情感识别效果任务上要比直接使用文本的效果好. 4.2.4 基于特征级融合的性能对比实验 首先展示了3种不同的声学特征和语义特征的各自情感识别效果.其中HSFF、DS使用带有两层隐藏层的DNN作为情感识别分类器.DF将CNN作为分类器,该CNN包括两个卷积层,卷积核个数为256,尺寸为3×3,两个最大池化层,池化核大小为3×3,两个全连接层,神经单元个数为128、4.将SF输入到BILSTM中,神经单元个数为128,后接3层全连接层,神经单元个数为512、256、4.将每个特征经过各自分类器的分类层之前的全连接层得到的向量进行特征融合.然后为了验证本文使用的特征级融合方法比传统的将所有声学特征看做一类与语义特征融合的效果好,做了两者的对比实验,实验结果如表6所示.前4行为4种特征单独的情感识别结果,第5行为使用传统特征级融合(Traditional Feature Level Fusion,TFLF)方法的结果,最后一行为本文提出的特征级融合方法结果. 表6 基于特征级融合的性能对比实验结果表 表6的结果显示本文提出的特征级融合方法比传统将所有声学特征看做一类再进行特征级融合的效果好,这是由于不同的声学特征会关注不同的声学信号情感,将3类声学特征看做独立特征之后能充分展现它们之间的差异性,而恰巧这些差异性能在不同角度提升情感识别的效果. 4.2.5 基于特征级-决策级融合的性能对比实验 本次实验首先对比了加入决策级融合之后的结果与只有特征级融合的结果.决策级融合是将特征级融合后的识别结果、以及原始4类特征的识别结果使用带权值的投票法来进行分类,每种特征在不同情感上的识别准确度如图5所示,将分类准确度作为权值.然后将本文实验结果与文献[8,10,28,31]做了对比,文献[8,10,28]使用的是语音和文本双模态信息进行语音情感识别,文献[31]是使用双层模型,情感特征为手工特征和原始频谱特征,使用LSTM处理手工特征输入,另外有两个CNN处理原始频谱图,结合两者做情感识别.对比结果如表7所示,其中前3行为双模态语音情感识别结果,第4行为最新的语音情感识别,第5行为特征级融合的效果,最后一行为加入决策级融合后的效果,特征级融合和特征级-决策级融合的识别结果也在图5中展示了出来. 表7中最后的两行对比表明了加入决策级融合之后语音情感识别效果又所提高,提高了1.9%.前5行展示了本文即使没有加入决策级融合,识别效果也比文献[8,10,29]中双模态情感识别好,比文献[10]结果高1.3%,且比文献[31]的语音情感识别结果高1.5%,而加入决策级融合之后最终结果比文献[10]中使用双模态的结果高出3.2%,在图5中也证明了本文方法的有效性. 图5 不同特征在不同情感状态下的识别率 表7 基于特征级-决策级融合的性能对比实验结果表 本文提出了融合声学特征和语义特征的语音情感识别模型.在本文中的声学特征包含低层次手工特征和深度特征,在IEMOCAP数据上的实验结果表明本文的声学特征在语音情感识别任务上有更高的准确度,同时使用LAS模型提取的语义特征与只使用文本做情感识别相比也有很好的表现.本文提出的特征级融合方法比一般的特征级融合方法更好的挖掘出各个声学特征包含的情感信息,加入决策级融合方法之后与使用语音和文本双模态相比,也有更好的情感识别效果. 本文选用的情感状态为4类,但现实语音情感状态远比4类更加复杂,并且一句话也会包含不同的情感,增加情感状态类别,并实现语音的复杂情感判断,是未来研究的方向.
3 多特征融合的语音情感识别
3.1 特征级融合
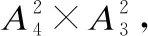
3.2 特征级-决策级融合
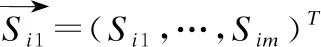
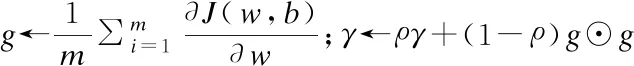
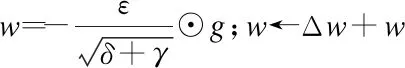
4 实验结果及分析
4.1 实验数据
4.2 实验结果与分析



5 结 论
猜你喜欢
智慧电力(2022年4期)2022-05-19意林·作文素材(2021年9期)2021-07-06南方周末(2020-01-02)2020-01-02阅读(快乐英语高年级)(2019年5期)2019-09-10阅读(快乐英语高年级)(2019年2期)2019-09-10小说界(2018年5期)2018-11-26中学生数理化·中考版(2014年5期)2016-12-22中学生数理化·中考版(2016年5期)2016-05-14长江学术(2015年1期)2015-02-27
