
基于半监督生成对抗网络的恶意代码家族分类实现*
2022-05-26 08:25玄佳兴韩雨桐赵丽花王旭仁
计算机工程与科学 2022年5期
王 栋,杨 珂,玄佳兴,韩雨桐,赵丽花,王旭仁
(1.国网电子商务有限公司(国网雄安金融科技集团有限公司),北京 100053;2.国家电网有限公司区块链技术实验室,北京 100053;3.中国科学院信息工程研究所,北京 100093;4.首都师范大学信息工程学院,北京 100048)
1 引言
近年来,恶意代码的数量高速增长,据著名杀毒软件测试机构AV-TEST(AntiVirus-TEST)在线统计数据显示,截止到2020年上半年,全球发现的恶意软件总量高达10.65亿,近10年一直保持着16%以上的增长速度。恶意代码的数量和种类不断增多,隐蔽能力越来越强,破坏程度越来越大。
随着互联网的发展,恶意代码呈现海量化与多态化的趋势,这使得恶意代码家族分类也面临着更大的挑战:恶意代码特征难以有效提取,采用签名的方法无法应对新产生的恶意代码变种,静态分析方法容易受到混淆手段的影响,动态分析方法又难以获得全面的样本行为。因此,恶意代码的分类成为了一个亟待研究的问题。恶意代码的分类存在2种情况:一是将代码或者样本分类为良性代码或者恶意代码的二分类问题;另一种是将恶意代码分类到不同家族的分类问题。本文讨论第2种分类问题。
应用机器学习对恶意代码进行自动化分析,首先要能自动化地提取恶意代码特征。2011年,Nataraj等[1]首次提出将恶意代码转化为可视化图像,然后进行恶意代码分析的方法。其基本思想是将每8位二进制数转化为0~255的值,作为一个像素点值,这样可把恶意代码转化为一幅灰度图。属于同一个家族的恶意代码图像之间具有很强的视觉相似性。Nataraj等采用通用搜索算法对二进制图像进行纹理特征提取,并使用K近邻KNN(K Nearest Neighbor)算法进行分类。这种将恶意代码转换为图像的特征提取方法无需手工提取特征码,也不需要对恶意代码进行脱壳分析、逆向分析和动态分析。Kancherla等[2]利用Gabor滤波器提取恶意代码图像的全局特征和小波特征,然后再进行分类研究。Ni 等[3]基于Simhash算法把恶意代码基于控制流程图的opcode特征转化为图像,使用图像分类的方法进行处理。张景莲等[4]从病毒反编译文件中提取恶意代码局部特征Opcode N-gram和灰度图纹理,并将颜色直方图作为恶意代码的全局特征,采用随机森林对恶意代码进行分类,效果显著。孙博文等[5]使用恶意代码ASCII字符信息和可移植可执行文件PE (Portable Execute)结构信息对传统恶意代码灰度化图像方法进行改进,生成彩色图像,最后借鉴图像处理领域的VGG16(Visual Geometry Group)神经网络模型对恶意代码图像进行训练。
对恶意代码特征进行分类的方法主要有支持向量机、K近邻算法、决策树和随机森林等常见的机器学习算法。近年来深度学习广泛应用在恶意代码图像或者恶意代码语义分析上。Pendlebury等[6]提出TESSERACT系统,使用3种分类器(SVM、随机森林和深度学习模型)对安卓恶意软件随时间和空间发展造成的偏差进行对比,提出时间感知性能指标。Homayoun等[7]使用长短时记忆LSTM(Long Short-Term Memory)网络和深度神经网络 DNN (Deep Neural Network)对勒索软件和良性软件进行二分类,以便进一步对勒索软件进行家族多分类。Saxe等[8]提取恶意软件运行时的4个特征,使用深度神经网络对恶意代码进行二分类。更进一步,由于恶意代码种类繁多,且人工评估的成本高、效率低,样本集往往没有标签或给出的标签较少。在半监督学习中,生成对抗网络GAN(Generative Adversarial Network)表现出了很大的潜力,即使在标签数据很少的情况下,分类器也能取得良好的检测效果。Al-Dujaili等[9]使用对抗学习提升深度学习模型在恶意代码上的检测效果;Kim等[10]将生成对抗网络在恶意代码家族分类上的应用限制于二分类任务,没有涉及到半监督学习。Salimans等[11]使用半监督生成对抗网络SGAN(Semi-supervised Generative Adversarial Network)提升深度学习模型分类准确率。上述工作取得了很多突破和进展,但是在工作整合和恶意代码分类的准确率上仍有提升空间。
本文在上述研究的基础上,综合使用GAN与恶意代码图像预处理相结合的方法,以解决恶意代码特征提取困难、样本标签缺乏等因素导致分类效果不好的问题。利用图像特征提取方法将恶意代码转换为灰度图;利用缩放算法和Gamma 校正法将图像标准化。为提高恶意代码家族分类的准确率,将半监督生成对抗网络与深度卷积网络相结合,构建半监督深度卷积生成对抗网络SGAN-CNN(Semi-supervised Generative Adversarial Network based on CNN)分类模型,对恶意代码家族进行分类。
2 相关工作
2.1 恶意代码特征提取
要对恶意代码进行家族分类,首先需要进行恶意代码特征提取。特征将直接影响分类的效果和准确率。根据恶意代码特征提取过程中是否需要运行恶意代码,可将恶意代码特征分为静态特征和动态特征。
静态特征提取方法主要有签名的方法、基于N-gram的方法和基于控制流图的特征提取方法。签名的方法在恶意代码发生变体(例如使用代码混淆、花指令等手段)时,恶意代码签名会发生变化,从而使没有及时更新的签名失效。N-gram是文本挖掘模型,N是指滑动窗口大小,使用N-gram方法可以提取二进制代码的语义特征和文本频率特征,例如PE文件的头部、代码段的特征和API调用等。但是,在恶意代码使用加密、代码重用时,N-gram方法面临挑战。基于控制流图的特征提取方法是分析恶意代码的函数、功能模块以及代码块之间的调用顺序和执行逻辑。恶意代码使用自修改、代码重用和加壳等手段使得恶意代码可读性很差或者根本不可读,增加了控制流图分析的难度。
动态特征提取方法主要是将恶意代码运行在沙箱等虚拟环境中,记录恶意代码运行时的行为序列和环境参数的变化。由于越来越多的恶意代码具备对抗沙箱能力,即检测运行环境从而绕过监控的能力,这给恶意代码的动态分析带来很大的挑战。
本文充分利用恶意代码家族图像的相似性,结合半监督深度卷积生成对抗网络SGAN-CNN,有效避免了恶意代码特征提取的问题和样本标签不充分的问题。
2.2 恶意代码图像特征处理和规范化
对恶意代码进行预处理的方式多种多样,其中一种是将恶意代码转化为可视化图像,该预处理方式耗时短。Cui等[12]使用类似双线性插值算法的三线性插值算法进行图像采样和标准化。但是,双线性插值缩放在规范化图像时有大量的信息损失。本文在不依赖反汇编的情况下,将恶意代码的每8个比特转化为目标图像的一个像素,从而将恶意代码转化为一维灰度图像。如果将恶意代码转化为二维或者高维图像,原图像中空间上分离的点会被重排到二维图像的一列或者相邻列上,后续的深度学习模型会传递这种空间局部相关性(例如池化处理),所以本文不进行维度变换。本文使用改进的恶意代码图像缩放算法IMIR(Improved Malware Image Rescaling)[13]进行图像缩放,因为处理的是一维图像,因此在水平方向上使用滑动窗口的方法对图像进行采样,将恶意代码图像缩小到4 096像素。IMIR将采样点的范围从最近的若干个点提升至整个滑动窗口内的点,从而保留窗口内所有图像信息。
2.3 生成对抗网络GAN
GAN是一种重要的对抗学习模型,主要用于深度学习下的数据增强[14]、风格迁移[15]和超分辨率[16]等任务。GAN包含1个判别器D和1个生成器G,二者进行对抗训练:生成器G尽可能生成与原始数据分布相近的数据集,使判别器D无法将其与原始数据区分;而判别器D则尽可能提升自身区分原始数据与合成数据的能力。经过一段时间的对抗训练后,生成器G能够生成接近原始数据分布的样本,用于解决由于训练样本不足导致的分类过拟合问题。
2.4 半监督生成对抗网络SGAN
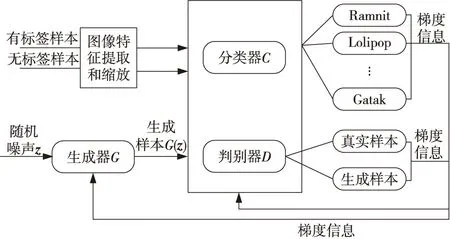
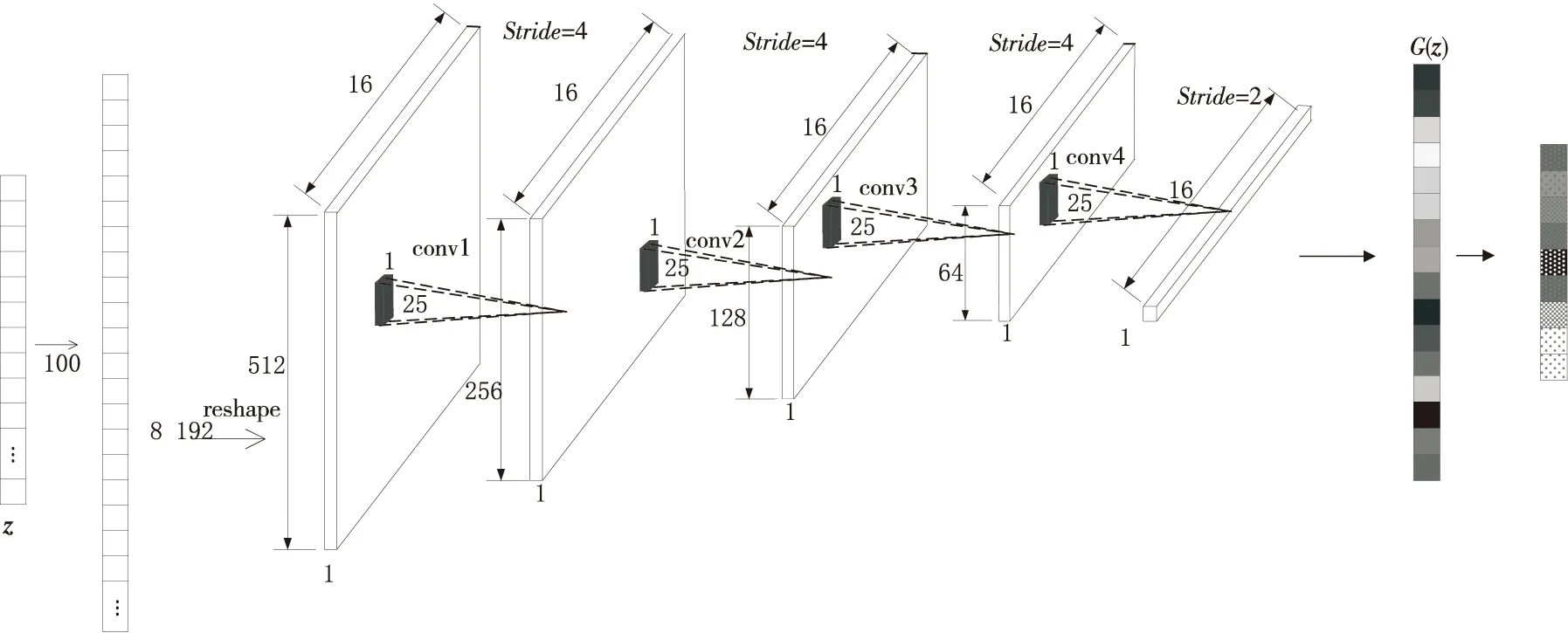
半监督生成对抗网络SGAN是生成对抗网络在多分类问题下的一种变体。单纯的生成对抗网络只处理二分类问题,无法直接进行多分类建模。半监督生成对抗网络SGAN-CNN使用CNN替代判别器,输出层使用Softmax进行多分类,实现分类器的作用。多分类任务下,分类器的输入为有标签样本、无标签样本和生成样本。有标签样本携带有多分类信息,而半监督生成对抗网络的监督单元可以直接对多分类问题建模,无监督单元可以学习无标签样本的信息,并利用对抗训练提升分类器对潜在样本的分类能力。根据文献[11],对于任意的标准K分类器,将生成器G生成的样本添加至数据集中,视为一个新类别,即第“K+1”个类别。损失函数和训练目标函数定义分别如式(1)~式(4)所示:
L=Lsupervised+Lunsupervised
(1)
Lsupervised=-Ex~labeledlnPD(y|x,y (2) Lunsupervised=-[Ex~reallnPD(y Ez~N(0,1)lnPD(y=K+1|G(z))] (3) (4) 其中,z是随机噪声向量,符合均匀分布。PD(y|x,y 为了解决恶意代码标签不足的问题,本文构建一种半监督深度卷积生成对抗网络模型SGAN-CNN。将SGAN-CNN无监督学习中判别器D再拆分为两个子功能模块:判别器D和分类器C。将高效的一维卷积神经网络作为判别器D和分类器C共享的特征提取器,从而增强分类器的分类效果。 SGAN-CNN模型工作原理如图1所示。图1中C是分类器,D是判别器,G是生成器。恶意代码样本首先经过图像特征提取和缩放,再通过深度卷积网络训练恶意样本分类器C。在训练分类器时,为了补偿标签不足的问题,通过对深度卷积网络进行误差修正,提高分类器的效果。 Figure 1 Malicious sample classification process based on SGAN-CNN图1 基于SGAN-CNN的恶意代码分类流程 生成器G根据随机噪声z产生逼近真实数据分布的生成样本G(z)。将有标签的真实样本输入到分类器C进行恶意代码家族识别。有标签和无标签的真实样本与生成样本G(z)均输入到判别器D,判别器D区分其为生成样本或真实样本,需要挖掘无标签数据中深层本质特征,然后通过损失函数反馈,最终实现提高分类器C识别性能的目的。 生成器G的结构参照经典生成对抗网络 DCGAN(Deep Convolutional GAN)[17]设计,如图2所示。由于恶意代码图像只有1个通道而非3个通道,本文将初始通道数由1 024改为 512;由于卷积方式是一维的,因此对应的卷积核也从 5*5 改为 25,对应步长改为 4。噪声z可以为正态分布或均匀分布,本文采用的是均匀分布。经过1个全连接层、4个转置卷积层的处理后,将维度为100的随机分布z映射为一个恶意代码图像,用以在对抗训练中欺骗判别器。 Figure 2 Construction of SGAN-CNN generator G图2 SGAN-CNN生成器G的构造 SGAN-CNN的监督学习完成主要的分类任务,无监督学习完成生成对抗任务。即将判别器判断为真实的样本分别归为不同的恶意代码家族,将判别器判断为生成器生成的样本归为“K +1”标签。这样,将原有判别器D拆分为判别器D和分类器C两部分。判别器D和分类器C只在最后的输出层分别输出,可以视为两个子任务。 Figure 3 Optimization diagram of SGAN-CNN discriminator图3 SGAN-CNN判别器优化示意图 本文根据VGG模型[18]设计恶意代码判别器,如图3所示,SGAN-CNN判别器包含5组伴随最大池化层的卷积层,3个使用dropout的全连接层,均使用ReLU作为激活函数以缓解梯度消失[19]问题,并提升训练速度;1个不使用dropout的全连接层;分类器C使用Softmax作为激活函数,而判别器D使用Sigmoid作为激活函数。可以看出,图3中模型训练的第1层到 Dense 256 层作为判别器D和分类器C的共享特征提取器F,即图3中的虚框部分。判别器D通过反向传播对共享特征提取器F进行误差修正,从而提升分类器C的效果。相应地,损失函数与目标函数变化如式(5)~式(7)所示: L=Lsupervised+Lunsupervised (5) Lsupervised=-E(x,y)~labeledlnPC(y|F(x)) (6) Lunsupervised=-[Ex~reallnPD(F(x))+ Ez~N(0,1)ln(1-PD[F(G(z))])] (7) (8) 分类器C只处理有标签的真实样本,因此F和C构成了1个卷积神经网络分类模型,由于输入的数据是一维的,又称为一维卷积神经网络分类模型,记为1D-CNN(one-Dimensional Convolutional Neural Network)。所有的真实样本和生成样本都经过判别器D处理,经过Dense 1全连接层和Sigmoid激活函数后,判断是真实样本(无论是否有标签)还是生成样本。因此,使用判别器D可将真实样本和生成样本区分开来。来自不同家族的真实样本(无论是否有标签)被合并为一类,而生成样本也为一类,他们之间的规模差异得到了平衡。 Microsoft Malware Classification Challenge[20]是微软于2015年在数据竞赛平台Kaggle公开的恶意代码数据集。该数据集共有10 868个样本,分为9个家族,所以类别数目K=9,如表1所示。 Table 1 Microsoft malware classification dataset表1 Microsoft Malware Classification数据集 实验评价选用了准确率A(Accuracy)、精确率P(Precision)、召回率R(Recall)和错误率Error这4个指标。具体来说,假设在被检测方法判断为家族a的样本中,实际不属于家族a的样本数量为FP,实际属于家族a的样本数量为TP;在被检测方法判断不属于家族a的样本中,实际不属于家族a的样本数量为TN,实际属于家族a的样本数量为FN。准确率、精确率、召回率和错误率的定义分别如式(9)~式(12)所示: (9) (10) (11) Error=1-A (12) 此外本文使用5折交叉验证方法来验证数据集划分的效果。 本文使用 Adam 优化器训练SGAN-CNN生成器G、分类器C和判别器D的深度学习网络,Adam能更快地到达全局近似最优解,更有利于调整模型参数。具体参数如表2所示。根据2.2节的描述,SGAN-CNN输入的样本维度是4096×8;半监督训练模型G使用图3 的方法和Adam优化器进行训练,每次迭代生成8 965个样本,共进行200次迭代。 Table 2 Model training parameters表2 模型训练参数 表3所示为不同模型在不同标记率情况下分类的准确率,标签率代表对样本数据的标记比率。在此引入两种半监督深度学习模型作为对比基线:一种是伪标签正则化[21],这是半监督学习中经典的伪标签方法在深度学习上的扩展;另一种是 Γ-Model[22]模型。 Table 3 Comparison of classification accuracy of different models under different tag rates 表3 不同模型在不同标签率下的分类准确率对比 从表3可以看出,随着标签率的提高,所有模型对恶意代码家族分类的效果也随之提升。SGAN-CNN模型在标签率为80%时,分类准确率最高达到98.81%;在标签率为20%时,分类准确率最低为98.01%。在不同标签率下,1D-CNN和伪标签正则化的效果相对其他模型最差,说明生成对抗网络对恶意代码家族分类是有促进效果的。SGAN与Γ-Model 各有优势,而相比于SGAN和Γ-Model,SGAN-CNN准确率更高。这说明对于恶意代码,当两项子任务在数据规模、标签分布和任务难度等方面不够匹配时,SGAN-CNN模型效果更好。 表3的实验结果是针对全部恶意代码进行家族分类的总体准确率。如果将各个恶意代码家族分类效果分别讨论,则样本数量越少的家族,有可能分类效果越不理想。从表1可以看出,Simda的样本数量相对于其他恶意代码样本数量,至少相差89%以上。相比数量较多的恶意代码家族,标签缺乏对小规模家族样本的影响会更加明显。为此本文进行5折交叉验证实验,并分析了实验中各家族分类的准确率与召回率,从而判断提出的SGAN-CNN模型在小样本恶意代码家族分类上是否有效。 如图4所示,图4a的样本标签率为100%,模拟标签正常的情况;图4b和图4c的样本标签率为20%,模拟标签缺乏的分类情况。从图4中可以看出,样本标签缺乏使得监督分类模型1D-CNN对大部分恶意代码分类能力都产生了负面影响,且样本数量较少的Simda恶意代码家族分类准确率下降明显。使用SGAN-CNN进行半监督学习,在提高整体分类效果的同时也修复了这种下降趋势。尤其是Simda恶意代码家族分类的准确率,在标签率仅为20%的情况下,分类准确率相对于分类模型1D-CNN提高约20%,接近1D-CNN模型在标签率100%情况下的分类准确率。图4中横坐标0~8对应9个家族,9对应所有家族平均值。 Figure 4 Histogram of detection accuracy and recall of malicious code families图4 恶意代码家族检测准确率与召回率直方图 实验中选取9个恶意代码家族的样本进行测试,验证了本文提出的基于深度学习的半监督对抗生成网络SGAN-CNN在恶意代码家族分类中的有效性,也验证了SGAN-CNN在小样本恶意代码家族分类分析中的有效性。 本文提出了恶意代码图像特征提取和规范化方法,使用一维图像而不是二维图像表示恶意代码特征,避免因为图像折叠带来的恶意代码图像特征中像素点之间不存在的局部相关性。设计了基于一维卷积神经网络的恶意代码分类器,提出了基于深度学习的半监督对抗生成网络SGAN-CNN模型。实验结果表明,SGAN-CNN可以在减少模型构建与使用的时间代价、提高分类准确率、增强时效性的同时,补偿样本标签缺乏、样本数量稀少导致的分类准确率下降,降低整体分类错误率,并重点提升包含小规模家族样本的分类效果,实现了分类准、覆盖广的恶意代码家族分类目标。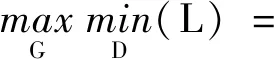
3 半监督深度卷积生成对抗网络模型SGAN-CNN
3.1 SGAN-CNN模型
3.2 SGAN-CNN生成器构造
3.3 SGAN-CNN判别器构造


4 实验与分析
4.1 实验数据集

4.2 评价指标
4.3 实验参数设置

4.4 基于SGAN-CNN的恶意代码家族分类实验

4.5 基于SGAN-CNN的小规模恶意家族样本分类实验

5 结束语
猜你喜欢
健康之家(2021年19期)2021-05-23医学食疗与健康(2021年27期)2021-05-13农业科技与信息(2021年2期)2021-03-27计算机系统应用(2021年2期)2021-02-23健康体检与管理(2021年10期)2021-01-03电子技术与软件工程(2019年18期)2019-11-18北京航空航天大学学报(2019年9期)2019-10-26电子制作(2019年15期)2019-08-27电子制作(2019年15期)2019-08-27电子制作(2018年19期)2018-11-14
