
破除隐私计算的迷思:治理科技的安全风险与规制逻辑
2022-05-26 03:58:02赵精武
华东政法大学学报 2022年3期
赵精武
一、问题的提出:治理科技的逻辑怪圈
在经历了“数据资源型—数据驱动型—数据赋能型”〔1〕参见夏义堃:《数据管理视角下的数据经济问题研究》,载《中国图书馆学报》2021 第6 期,第109 页。三个数据经济发展形态之后,现代社会对于数据的依赖性早已不是最初的“数据增值加工”,而是深化至“数据如何变革产业形态”。这种“产业数字化”的市场趋势促使立法理念发生变化:从单一的数据安全转变为在数据安全前提下充分利用数据。但信息技术的迭代优化却又使得立法者所希冀的“安全与利用并行”的理想图景一次次被打破。在现代化治理活动中,法律规制技术风险的线性监管逻辑无法真正回应和解决不断涌现的新型信息技术难题。因此,治理科技作为兼具业务合规和风险控制的技术方案,毋庸置疑地成为市场主体和监管机构的另一种选择,如区块链技术在实现“链上数据不可篡改”安全功能的同时,也满足了企业安全交易的需求;再如人脸技术在满足身份真伪高效核验的同时,也达成了企业缩减业务流程和优化用户体验的商业预期。这些治理科技的开发与应用可谓有效统合了市场主体商业利益、监管者治理目标和市场受众群体基本权益等多方利益的诉求。
然而,治理科技真的能够为现代社会提供“法律与技术共治”的良好图景吗?答案显然是“不能”。因为在治理科技研发过程中暗含着一种容易被忽视的商业逻辑:“××科技”是为了达成某种商业目标而创设的合规型技术方案,即治理科技的最终目的并不是实现监管机构的监管要求,而是给数据商业化处理活动提供充分可信的“安全背书”。并且,在信息技术发展进程中,从未出现过“绝对安全”的技术方案。这些主客观因素决定了治理科技同样可能产生不可预见的安全风险。在区块链中,链上数据难以篡改不等于不能篡改,并且去中心化的技术方案也构成了对中心化监管活动的实质性威胁;而在刷脸应用中,身份核验确实保障了用户账号使用的安全性,但“处处刷脸”的应用模式却也加重了用户对刷脸必要性和人脸识别信息安全性的疑虑。
不难发现,在治理科技治理社会风险的进程中,也在产生新的反治理风险,而为了消除这种反治理风险,新的治理科技又被纳入新一轮的治理活动中。为了打破“数据孤岛”和提升数据利用效率,隐私计算技术成为治理科技的新生代代表。该项技术方案的基本逻辑是在挖掘、分析、整合数据的过程中维持原始数据的保密性和本地化等安全指标,达成“数据安全”和“数据利用”之间的利益平衡。但是,这项治理科技似乎同样没有摆脱“治理—反治理—再治理”的逻辑怪圈,非授权主体依然可以通过“多次尝试输入数据生成特定关系的结果”倒推原始数据。事实上,治理科技的逻辑怪圈绝不止步于此,在不改变现有规制范式的前提下,未来的治理科技依然会产生类似的问题。因此,治理科技反治理风险的规制难题主要表现为如何完成规制理论和规制范式的转型。
二、治理科技规制范式的“失效”:以隐私计算技术为例
在区块链技术、人脸识别、用户画像等信息技术相继产生新兴社会风险之后,现行立法也随之对技术的应用方式、应用场景及技术的“黑箱”效应提出一系列规范要求。从实际结果来看,立法规制确实将技术风险维系在可控范围内,却也限制了数据流动的路径与范围。因此,包括联邦学习、安全多方计算和可信计算等技术方案的隐私计算技术成为新一代治理科技,其目的是在满足现有数据安全保护监管要求的前提下实现更大范围的数据商业化处理,通过“数据可用不可见”的方式化解数据安全与数据利用之间越发激化的法益冲突。
然而,信息技术领域从未出现过绝对安全的技术方案,即便是解决数据流动安全性的隐私计算技术同样存在不同程度的反治理风险,如根据算法模型倒推原始数据的数据泄露风险等。更重要的是,由于隐私计算技术本身以数据安全合规为前提,故而数据处理者得以凭借“已经采取充分必要的技术措施保障数据处理安全”之事由规避承担数据安全保护的责任,以风险预防、数据脱敏、限制处理目的、责任归属为内容的既有规制方式难以继续延伸出适用于治理“治理科技”(即隐私计算技术)的义务性规范。
(一)风险预防的机制失效
在数据商业化利用领域,我国现行立法活动的重心在于控制数据处理活动中潜在的安全风险,而控制风险的主要方式则是对不同数据处理流程设置不同的监管要求,如安全评估制度、算法备案制度等。总体而言,我国数据安全风险预防机制大体可分为三个层次。
第一层次是“知情同意”规则,即自然人作为数据权利主体,当然有权基于知晓数据处理活动的利益和风险来决定是否同意相应的数据处理活动。进一步而言,个体风险的治理问题首先是自然人在风险和收益之间的判断问题,法律所要预防的仅仅是“自然人不知情”的安全风险。在该层面,只要数据处理者告知隐私计算技术的功能效果和实际风险水平,即可被视为实质履行了风险预防义务。
第二层次是数据处理者的安全保障义务,即无论数据权利主体是否主动表明“自担风险”,数据处理者作为数据集合的持有者和处理者,有义务确保数据的安全性、保密性和准确性。隐私计算技术的创设目的之一就是满足安全保障义务的基本要求,即数据处理活动以“数据本地化”为前提,数据处理者对外传输的仅仅是经过数据训练的算法模型和计算结果,在内部操作流程、信息分类管理、加密技术措施、操作权限分级和安全应急预案等层面满足《个人信息保护法》(以下简称《个保法》)第51条的要求。
第三层次是安全评估制度,即数据处理者在使用新兴信息技术之前,应当就该技术对个人权益的影响和安全风险水平进行评估,其目的是要求数据处理者审慎采用新技术,只有在对新技术的安全风险抱有足够清晰的认知时才可投入使用,安全评估制度的内在治理逻辑是预防数据处理者为了提升市场竞争力而在技术尚未足够成熟之前径直采用风险较高的新兴技术。并且,该制度的另一功能也是为了解决监管机构在信息技术创新过程中所面临的监管信息资源受限问题,通过量化的评估指标和定性的评估结果来确定具体的监管措施。隐私计算技术的安全风险并不是个人信息安全威胁,而是黑客攻击、未经授权访问等外部主体的不法行为。现行立法所确立的安全评估制度的评估重心是确保新兴技术应用能够保障数据安全和个人信息私密性,这明显存在安全评估规制目标与技术风险规制需求错位的问题。
由此可见,风险预防机制对治理科技反治理风险的规制方式主要以数据处理者未能合理选择稳妥且安全的隐私计算技术方案为限,即未能履行第二层次的安全保障义务,无法直接对隐私计算的应用方式和应用场景作出限定。换言之,纯粹服务于商业目的的技术应用所引发的安全风险均可通过风险预防机制予以调整,但由于治理科技本身以遵守数据安全技术标准和监管要求为前提,暗含“已经尽可能预防风险”的技术逻辑,故而风险预防机制的预防功能无法直接适用于治理科技引发的反治理风险。
(二)数据脱敏的目的失效
从国内外数据安全立法实践来看,立法者普遍认同数据脱敏技术是兼顾数据安全和数据利用的有效技术方案。如在个人信息保护领域,GDРR 第32 条和我国《个保法》第11 条、第73 条均有提及匿名化、加密处理、去标识化等数据脱敏技术措施。数据脱敏的目的在于消除和降低原始数据泄露的实际风险,同时经过脱敏后的数据将能够充分满足数据商业处理的目的。数据脱敏的制度目的在于尽可能消除数据背后的关联性、逆向复原性及可识别要素,但隐私计算技术本身就是以数据脱敏为技术前提的,并且其采取的脱敏技术方案更为直接彻底。例如在差分隐私模式下,隐私计算技术可以在数据处理结果中添加噪声,使攻击者无法根据输出差异回推原始数据,从而保护用户隐私;再如在同态加密模式下,隐私计算可以实现传输海量数据集合的加密密文而不上传原始数据的技术目标,数据处理的直接对象仅是加密密文,仅有原始数据的持有人才可以对加密数据处理结果进行解密。治理科技的“治理”属性意味着该类技术的研发逻辑以契合数据安全技术标准为前提,数据脱敏这一传统规制范式显然已经无法实现最初的规范目的,因为“脱敏”之要求已经成为治理科技研发的核心技术要求之一。
(三)目的正当的约束失效
技术安全风险既包括内生性风险,也包括外部应用风险。内生性风险主要指向技术方案自身的不完备性可能导致的安全事件,在立法层面多以安全评估制度、安全保障义务等义务性规范予以规制;外部应用风险主要指向技术应用方式不合理可能导致的安全事件,例如个人信息过度收集、超目的处理等,这也是现阶段监管机构在治理数据安全风险中所面临的主要问题。在数据治理领域,数据安全级别与数据安全流动范围成反比,即数据流动越少,数据也就越安全。因此,《网络安全法》《数据安全法》《个保法》均有贯彻“控制数据流动范围”的基本立场。当然,这并不等同于“限制数据流动”,而是强调尽可能控制数据在合理范围内流动,其中“合理范围”的认定标准即是数据处理目的的正当性和必要性。为了增强市场竞争力和抢占商业资源,企业普遍希望收集的数据越多越好,这种数据收集活动只会增加个人信息泄露的安全风险,且企业超范围收集个人信息的间接结果还表现为企业过度分析自然人的行为方式和生活习惯,个人隐私泄露的风险同样增加。因此,目的正当性原则成为数据安全立法的基本原则,在实践中表现为外部技术审查。所谓“外部”,通常是指同数据处理者无利益关联、具备特定技术或法律知识的第三方。例如,算法审计及构建于其上的问责制度,就备受学界推崇,〔2〕例如,有学者指出,通过外部审核“拷问”人工智能,或可暴露埋藏其中的歧视风险。参见李成:《人工智能歧视的法律治理》,载《中国法学》2021 年第2 期,第144 页; [德]托马斯·维施迈尔:《人工智能系统的规制》,马可译、赵精武校,载《法治社会》2021 年第5 期,第120 页。另有学者呼吁,“建立统一的个人信息保护机构,实现数据生命周期中不同阶段的动态平衡”。参见许可:《健康码的法律之维》,载《探索与争鸣》2020 年第9 期,第130 页。在联邦学习中可比照适用。英国《政府数据伦理框架》还提出了“同行社区”的概念,将来自技术共同体的持续评价视为保障算法目标正义的核心手段,但对如何实施语焉不详。
目的正当性原则发挥约束效用的前提是数据处理活动单纯以营利为目标,如果不对处理目的进行内部自我约束和外部技术审查,则极易产生过度收集和滥用数据的风险事件。然而,隐私计算技术的底层逻辑是“合规处理数据”,数据处理者在采用安全多方计算、联邦学习、可信执行环境等具体技术方案时,并不会直接对外传输或共享原始数据,其处理目的的内在顺位表现为“先是以加密、本地化等方式保障数据安全,其次才是数据商业价值的开发”。因为数据处理目的正当性和必要性已经以“代码即法律”的方式嵌入隐私技术的底层代码,依托隐私计算的数据处理活动会将处理目的是否正当、安全且必要作为预设条件。因此,面对以“治理安全风险”为内容的治理科技,目的正当性早已被融入其应用方式中,无法对事中、事后的反治理风险发挥目的矫正和处理方式约束的功能。
(四)技术透明的问责失效
法律责任在所有具有规范性意义的制度安排中居于核心地位,既是违反特定义务必须承担的法律后果,也是救济相关权利损害的必要措施,更是保护正当权益的直接手段。〔3〕参见程啸:《民法典编纂视野下的个人信息保护》,载《中国法学》2019 年第4 期,第26 页。适用于信息技术应用风险的责任摊派机制,目的在于解决事后风险责任的可追溯性、合理配置与具体分担等问题。以服务链条为基础,主导方责任、参与方责任、技术方责任和监管责任共同构成技术风险责任归属体系的主构架。但是,由于技术手段众多、数据处理方式迥异,归责制度的设计还有待斟酌,法院在应对零星出现的问题时只能比照《电子商务法》第5 条规定的“产品和服务质量责任”,对链条上的所有数据处理者适用严格责任原则,这样一刀切的做法或有失偏颇。
为了方便事后问责和确定数据处理者的责任承担范围,国内外立法者大多选择以行政备案制度、数据处理记录留存制度等方式方便追溯技术安全风险的实际原因和责任归属主体,避免数据处理者借由技术中立或已经采取相应的安全技术手段规避责任的承担。例如,美国证监会和商品期货交易委员会长期探寻在智能金融领域建立人工智能投资顾问的“法律识别标识符”(Legal Entity Identifiers),利用硬核编码的审计日志(Hard-Coded Audit Logs)强化人工智能技术的事后监管和效果追踪。〔4〕Joint Study on the Feasibility of Мandating Algorithmic Descriрtions for Derivatives, SEC, CFTC, 2011.我国现有法律规定已经能够基本保证信息技术应用活动的“全过程留痕”:《互联网信息服务管理办法》第14 条规定了60 日的数据留存义务;工信部《移动智能终端应用软件预置和分发管理暂行规定》第8 条要求留存智能应用的软件、版本更新和МD5 校验值等;《数据安全法》第33 条要求数据交易中介留存审核、交易记录;《个保法》第56 条要求个人信息保护影响评估报告和处理情况记录应当至少保存3 年。值得注意的是,这些留存制度的规制目的是增加信息技术应用过程的透明度,尤其是在数据处理者对外传输和共享数据之后,及时跟踪和明确这些数据的传输路径和实际持有人。但隐私计算技术并不会要求原始数据的对外传输,并且原始数据的处理活动记录均可在本地化服务器中予以查询,故而记录留存等问责制度只限于治理科技的应用方式是否符合数据安全监管要求,而不会在反治理风险预防和控制层面产生直接的规制效果。
上述种种既有技术风险规制范式的失效表明我国在立法层面亟须重新调整治理科技反治理风险的规制理论。不同于传统信息技术创新带来的安全风险,治理科技反治理风险的产生方式是兼顾业务合规和商业目的的必然结果。数据安全与数据利用在治理逻辑层面存在固有的“冲突性”,即数据充分利用意味着数据安全系数降低,数据充分安全意味着数据流动受到限制,因而客观上很难彻底解决反治理风险。既有的监管工具和规制范式基本上是针对提升数据利用效率的信息技术而创设的,在面对以“符合技术安全标准和监管要求”为内在逻辑的治理科技时,传统的个体风险控制方式自然无法达到规制的效果。
三、治理科技规制范式的理论转向
正如前文所言,强监管属性的规制范式仅能在技术风险层面对治理科技的反治理风险产生有限的约束效果,无法对治理科技的“治理”属性作出有效回应。为了避免立法活动陷入“治理—反治理—再治理”的逻辑怪圈,首先需要回应的问题是“应当为治理科技选择何种规制范式”。诚然,我国初步体系化的数据安全立法体系确实能够提供多种风险治理机制,但这些机制的治理逻辑主要还是停留于技术应用的个体风险控制,普遍存在维度相对单一、功能较为简单、规则过于刚性等问题,且在法律关系、应对理念、责任制度等方面有着诸多局限性,难以对治理科技不同风险的差异化应对需求予以有效的回应,甚至会对个别数据主体的独特性利益造成压制,不能全面担当起应对治理科技的治理使命。更重要的是,徒法不足以自行。在规制方法论层面,政策制定者和执行者必须重视一个根本性的差异,即治理科技的风险与传统互联网风险和算法风险在形成机制、基本特征和损害结果方面有着显著的差别,将既有规则和理念单纯地向治理科技延伸和覆盖,不仅不能自然形成足以识别、防范、监测与救济技术风险的法律应对体系,反而将损害现有法律框架的稳定性和自洽性。从隐私计算见微知著,治理科技的规制思维应当经历如下的改变与跃升。
(一)反治理风险的全流程规制理论
以“告知—同意”为“第一闸口”的信息处理规则,是典型静态节点管控思维的体现,在降效失能中颓势明显,须以动态的全局治理模式对其进行改良。因适用场景呈现高度动态化的特征,治理科技不同于可一眼看穿的普通数据处理活动,根植于其间的“告知—同意”框架应当同样处于动态变化之中,才能应对法律关系的复杂化。数据处理者只有做到与时俱进的“告知”,数据主体才可能作出真正符合其意思表示的“同意”,否则无异于“刻舟求剑”。〔5〕万方:《个人信息处理中的“同意”与“同意撤回”》,载《中国法学》2021 年第1 期,第173 页。再则,以信息自决为核心的主体权利制度也不能完全保证数据主体所享有的积极利用权能,需辅之以可撤回之同意为其行权模式。
传统危机防范机制同样需要动态的全局治理智慧进行校正。现行安全保障义务的规定虽有助于从技术供给侧防范治理科技风险,但总体来看,其能否达到法律所认可的“客观的目的论的标准”,在信息不对称的情况下难以做出客观判断。只有各个关键节点的安全保障义务彼此之间形成合乎逻辑的联动,局部安全才能向全局安全拔擢。数据来源良莠不齐是治理科技的风险成因之一,可以考虑在数据聚合环节引入“自完善”的数据集检测措施作为安全保障义务的“补缺”:数据处理者可以借助算法工具主动检测用于模型共训的数据集是否存在偏差或缺陷、数据清洗工作是否彻底等。数据集的不完美或为常态,检测机制将衍生补充披露义务,数据处理者必须主动阐明缺失数据集的详细情况、对全局模型更新可能造成的影响以及治理歧视的措施。
(二)反治理风险的实践导向式规制理论
既有制度延伸适用存在的另一个问题,是对旧制度治理新技术的效果估计过于乐观。以数据脱敏机制为例,政策制定者看到的是一个规定了“去标识化”“匿名化”就可以让个人信息脱敏的世界,而这种理想愿景同数据处理的现实情况南辕北辙。传播学领域的马赛克理论(Мosaic Theory)指出,若干非重大、无关联信息或信息片段的结合,亦能还原出有重大价值的信息。隐私计算的各参与方都是掌握相当数量个人数据的专业处理者,“对外行人或许毫无意义的数据或偶得信息,对内行人却意义非凡”。〔6〕Мarchetti v. United States, 390 U.S. 39 (1968).去标识化或匿名化处理或可抹除信息的重大性或关联性,但无法根除“残存的可识别性”。〔7〕齐英程:《我国个人信息匿名化规则的检视与替代选择》,载《环球法律评论》2021 年第3 期,第52 页。在“反向识别和预测性挖掘技术”的推波助澜下,诚实但好奇的平凡举动稍不注意就会升级为窥探隐私的逾矩行为。〔8〕参见徐明:《大数据时代的隐私危机及其侵权法应对》,载《中国法学》2017 年第1 期,第138 页。此外,去标识化和匿名化的处理手段或多或少会对模型的精度造成影响,添加噪声以降低数据敏感度的差分隐私也会导致结果准确性的降低。完全基于密码学的同态加密虽然能够在丝毫不减损模型精度的情况下保障数据安全,但将大幅提升隐私计算的通信开销,不是轻量化的隐私保障手段。
对制度延伸适用的盲目乐观,还体现在目的矫正和监管责任等机制上。就各类审查和评估而言,目前尚无成型的流程和策略,仅有理论上的主张,真正操作起来将受到较多限制,譬如审查和评估能力受制于执行者的水平。若不严格遵守古典德尔菲法要求的“多轮双向匿名反馈”的问询方法,〔9〕德尔菲法是公认的具有严谨性、匿名性、反馈性、收敛性和广泛性的意见征询方法。参见曾照云、程安广:《德尔菲法在应用过程中的严谨性评估——基于信息管理视角》,载《情报理论与实践》2016 年第2 期,第64-68 页。审查和评估行为的客观中立性难以保障。更重要的是,在治理科技发展的黄金时期,目的矫正机制的发展显然不具备与技术迭代速度相称的效率。说到底,外部审查、数据保护影响评估及监管责任等制度设计,最大的问题在于预设了一个全知全能的审查主体,可以对数据处理活动的各个环节明察秋毫。然而,暂且不谈信息匮乏的“外部”专业人士,能够肩负起审查和评估重任的内部人士,事实上也屈指难寻。在数据处理者内部,业务部门作为终局模型的使用者,是隐私计算的最终受益人,而参与隐私计算、更新本地模型、保障平台安全等工作,却由技术部门完成。技术人员在控制数据参与模型共训时未必完全了解业务部门的真实诉求,囿于技术壁垒、职权分工以及部门间绩效竞争,业务人员同技术人员的沟通效率可能并不乐观。在某些大型企业内部,合规部门又独立于业务部门和技术部门之外,对隐私计算的环节把控、数据调用、安全保障和模型部署等问题,各部门之间根本不存在所谓的“内控机制”或“科层制约”。〔10〕参见高丝敏:《智能投资顾问模式中的主体识别和义务设定》,载《法学研究》2018 年第5 期,第45 页。由此可见,数据处理者内部的个人信息保护负责人按要求完成事前个人信息保护影响评估已是勉为其难,来自外部同数据处理者无利益关联的审查者如何能够拨开重重迷雾,审查关涉多重数据处理关系的隐私计算方案呢?随着计算机和人工智能领域的各个专业不断细分,治理科技的底层技术,如分布式计算、离散数学、密码学之间的专业鸿沟正不断加大,哪怕是细分领域最优秀的专家,也没有能力对其上位领域的全景状况发表负责任的评论。总之,面对技术的突飞猛进,政策制定者必须实事求是、摒弃一切想当然的幻想,只有在客观、中立认识的基础上制定出符合技术发展规律的治理规则,才经得起时间的考验。
(三)反治理风险的透明化规制理论
以上应对思维的狭隘性,最终将导致事实认定过程的局限性。在普通数据处理活动中,风险通常能够追溯至形迹可疑、不怀好意的责任主体,与此相比,治理科技的反治理风险产生途径更加宽泛,任何参与方的数据瑕疵、因觊觎而实施的小动作、敌意而隐秘的直接攻击等,都可能“以点带面”地造成损害。根据侵权行为的法理,如果“行为和损害之间的因果关系”无法确立,主导方责任、参与方责任、技术方责任将难以落实。〔11〕参见冯术杰:《论网络服务提供者间接侵权责任的过错形态》,载《中国法学》2016 年第4 期,第181-184 页。治理科技的歧视是多因素、多种作用的和合,即便知道责任应当在哪些数据处理者之间分配,也很难准确地定性每方应负责任的大小。因此,应对反治理风险不可能如同应对算法风险或互联网风险那般采取加强责任穿透、提升平台责任、监控关键环节等方式,连带责任和分配责任的制度安排均无法实现实质正义。治理科技风险源头高度分散、风险样态各不相同、风险发生随时随地的特征,决定了法律应对策略应当更加灵活多变,不能将侵权责任的线性思维简单地套用其上,而应秉持底线思维,从整体面向出发,探寻体系化的责任落实机制。
为了更好地确定责任归属,普通数据处理活动中针对数据输入和结果输出间线性关联的单次“获解释权”,在治理科技的具体应用场景中,应当演变为针对“终端数据采集—本地数据处理—数据与模型交互—全局模型更新—全局结果输出”的全过程“获解释权”。不过,在技术黑箱的掩护之下,数据处理者提供解释的方法极有可能是“顺水推舟”的便辞巧说:在诸多可能的解释中,基于自身利益的考量,选取一种最能够自圆其说的解释,将治理科技的各个环节联系起来;问题在于,数据主体对此根本无法证伪。研究表明,特定算法应用的有限可解释性尚且只能“削足适履”地实现,〔12〕对获解释权的质疑长期存在,有代表性的观点是,获解释权是本质主义色彩浓厚的事前规制手段,不如实用主义导向的事后问责等手段妥当。参见沈伟伟:《算法透明原则的迷思——算法规制理论的批判》,载《环球法律评论》2019 年第6 期,第20 页。治理科技环环相扣的全过程“获解释权”将面临更大的艰难险阻。每个全局模型的当下意涵,只能透过各轮训练间的意涵关联来确定,而各轮训练间的意涵关联又须考量最新一轮的数据构成及其相对于过去数据整体的动态意涵才能确定。若想完整掌握全局模型的蜕变过程,必须准确把控历次模型参数更新的根本机理,适时回应不断更新的解释需求,并关注已然作成之解释对未来全局模型之改良的“反作用”。可见,通过“获解释权”的正义实现,也要求观察者具备整体诠释演绎的能力和水平。
(四)反治理风险的协同式规制理论
在既有制度延伸之外,世界各国针对治理科技的规制尝试已经徐徐展开,典型如2021 年欧盟《数据隐私保护中网络安全措施技术分析》、美国《促进数字隐私技术法案》和联合国下属国际电信联盟《隐私保护机器学习技术框架》等。〔13〕中国联通、之江实验室等共同参与了该标准的制定,足见中国的产业界及科研机构在新兴技术隐私计算上的探索受到国际认可。我国对治理科技的制度探寻,体现出较强的政府主导的特征,虽有行业自律组织零星自发地参与标准制定,如中国支付清算协会发布的《多方安全计算金融应用评估规范》等,但这些标准均是对国务院、人民银行、发改委、网信办、工信部、信标委等颁布的规范文件〔14〕例如《个人金融信息保护技术规范》《信息安全技术 个人信息安全规范》《关于推进“上云用数赋智”行动 培育新经济发展实施方案》《关于加快构建全国一体化大数据中心协同创新体系的指导意见》《全国一体化大数据中心协同创新体系算力枢纽实施方案》等。的附和或有限延伸,并不足以形成能够因应联邦学习发展趋势的动态规范。在“投石问路”初期,弥补规则缺位的还有各类行政手段。2021 年以来,浙江、重庆等地先后发布了各自的公共数据分级指南,在司法地方化的情形下,原来“政策先行试点”意义上的对数据处理活动的规则探寻,极有可能“名正言顺”地异化为变相的行政干预。倘若任凭“习惯成自然”,将最终落入“行政机关中心主义”的路径依赖,而这种规制方式根本无法契合变幻无常的技术风险。
治理科技的参与方分属不同机构、不同行业,彼此之间包含着错综复杂的利益交织,单凭行政裁量无法客观地考虑各方价值平衡,况且,公共管理部门实际上是治理科技的最大受益者,监管者和被监管者的身份混同问题突出。另外,治理科技应用场景不断拓展,隐私计算技术、边缘计算技术同区块链等技术的结合紧密,〔15〕参见谭作文、张连福:《机器学习隐私保护研究综述》,载《软件学报》2020 年第7 期,第2127-2156 页。行政监管部门已然面临日益增长的监管需求和监管资源不平衡、不充分之间的矛盾。唯有突破行政监管一家独大的规制局面,建立从公权力监管到行业监督、从行政命令到法律规范的立体化多元治理体系,才能动态地解决治理科技伴生而来的技术安全风险和挑战。过去单靠人力资源和时间成本投入的行政手段边际效用下降明显,解决方案是为企业、行业协会、同行社区、研究机构和数据主体等提供平等对话和有效商谈的场域,让利益相关者共同参与规则的制定和完善,监管责任从公共管理部门向社群倾斜。
本文所称社群,是指在治理科技领域内发挥作用的一切社会关系的总和。论参与者形式,它是半官方、半自律监管的,公私紧密合作且互动频繁持续的开放式集合体;论治理目标,它以平衡数据主体个人权益保护和数据处理者信息技术赋能为主要目标;论工具手段,它以内部人形成共识的规范为载体及时反映国家法律、科技发展、市场竞争和场景扩展之间的博弈;论规制模式,它是政府、企业、机构、公民、协会、社群等各利益相关方持续围绕“技术实践”进行的“有组织有目的”的商谈、研究和决议等程序。作为社群监管责任的组成部分,行业自律监管的重要性与日俱增。2021 年4 月,隐私计算技术联盟(РCIC)成立,旨在为隐私计算等技术打造有公信力、开放共赢的自治理平台。2021 年7 月,科技部公布《关于加强科技伦理治理的指导意见(征求意见稿)》,鼓励科技类社会团体充分发挥“伦理自律功能”,未来将有更多的技术社区、学术社团成为多方协同治理体系中不可或缺的一部分。
规制理论的转向有助于孕育出强有力的规制手段,但稳定连续、浑然一体的治理科技的规制体系尚未成型,只有当大体制中具体而琐碎的小体制不断确立,才能最终形成适应治理科技的法治生态。因而,应对治理科技风险的当务之急,是通过一种联结化的努力,将适格的小体制纳入大体制的轨道,并注重小体制间的系统性和融贯性。在小体制系统性联结成大体制的过程中,过去互联网、算法规制的制度经验以及个人信息保护的理论探索将被进一步整合,这既是为了让治理科技的规制体系更加周密全面,也是为了确保制度之间的平稳过渡和无缝衔接,避免新、旧规则之间的冲突再起。
以上四个层面的理论转向共同揭示了如下的规制原理:其一,治理科技是数字技术超越传统数学运算向逻辑推理乃至观察世界方法论递变的典型,〔16〕参见申卫星、刘云:《法学研究新范式:计算法学的内涵、范畴与方法》,载《法学研究》2020 年第5 期,第3 页。政策制定者宜另辟蹊径,通过多样化、去中心化的规制手段,对抗同样多样化、去中心化的技术风险;其二,在高度不确定的环境中通过权利赋予配合行为规制的围堵模式来化解科技变革的风险,治理结构应逐渐从权威监管机构向多利益相关方转变,在个人信息自决等工具之外,还应扩充构架“社群信息共治”和“行业生态”等维度;其三,基于权力制约和尊严保障的法治理想追求,激励相容路径下技术互嵌和制度联动有助于从数字化规范性和技术可控性角度框定治理科技的实施边界,补全临界状态中动态规范的暂付阙如。
四、反治理风险的规制图谱
治理科技本身属于“代码即法律”理念的实践方式之一,在技术代码层面融入法律的内容,让技术本身间接具备“法律效果”。但这并不意味着治理科技的应用等同于法定义务的履行,因为法律不仅关注义务是否履行,同样关注法益是否存在被侵害的风险。治理科技所产生的反治理风险恰恰说明“代码即法律”的功能局限性,而法律、技术、市场和社群任何一种规制手段只会产生“旧风险治理不彻底”和“新风险的不可预测”并存的尴尬局面。从现行立法趋势来看,数据安全立法正在从宏观层面的数据安全保障体系向微观层面的个体技术规范要求转型,但这种转型过程却存在“一项技术对应一类法定义务”的立法逻辑陷阱,因为立法永远不可能保持甚至超越技术的更新速度。面对异军突起的反治理风险,法律所要回应的不再是单一技术的限制性要求,而是如何与技术、市场和社群等规制工具达成体系化和多层次的规制图谱,实现“法律即代码”和“代码即法律”的双向治理效果。〔17〕“代码即法律”强调的是在代码层面遵守法律并使得代码具有实质的法律效果;而“法律即代码”则是强调代码成为法律关系的外在表现形式,如智能合约的代码内容实质是以合同法、物权法等法律条款为主要内容的。
在网络社会,协同治理、社会共治等主张早已成为社会共识,但仅仅停留于“多方主体共同参与风险治理活动”的笼统表述并不能为“风险社会”提供足够有效的规制理念和治理工具。
(一)协同治理的理念重述
根据复杂性理论(Comрleхity Theory),信息技术具有“自创生性”,能够根据现实问题自行调适和发展。对网络法产生深远影响的“马法之争”表明,对于重大新型技术的应对策略,需妥善兼顾国家法律(Laws)、社群规范(Norms)、市场竞争(Мarket)和技术架构(Architecture)的排列组合。〔18〕Lawrence Lessig, “The Law of the Horse: What Cyberlaw Мight Teach”, 113 Harvard Law Review 501, 501-502 (1999).不过,上述四个维度分属不同的社会子系统,一种系统的运作极少对另一种系统造成影响,彼此之间缺乏交流。〔19〕参见陆宇峰:《“自创生”系统论法学:一种理解现代法律的新思路》,载《政法论坛》2014 年第4 期,第154-168 页。表面上,治理科技看似为科技构架同国家法律携手共进的典范,但由于未经“作为辩证过程的规范适用”,科技构架与国家法律在事实上区隔,难以发挥替代、悬置法律的作用,充其量只能算作伽达默尔意义上的“有创意的法律补充的贡献”。〔20〕Claus-Wilhelm Canaris, Die Vertrauenshaftung im Deutschen Рrivatrecht,1971, S. 274f.
伴随着规制思维的整体转向,本文提倡对治理科技进行协同式治理,即以技术构架为纽带、以数据流转为脉络,国家法律主导,社群规范、市场竞争和技术构架各司其职的多维共治范式。任何治理科技,必须历经社群测评、行业许可、政府认证,方能大规模部署,由此形成“测评—许可—认证—推广”环环相扣的全过程治理体制。与法律规则功能相辅相成的技术性标准,经由政府部门、行业组织、科研机构、企业和数据主体间的协商产生,在适用中妥善平衡各个利益主体的不同诉求、兼顾公私差异,从而与“去中心化”的规制大局观合若符契。政府、市场、机构、个人之间的联动有助于形成技术赋权与权利义务平衡的法律规则,实现经济效益和公平正义的帕累托最优,同时也遏制行政措施对法律手段的倾轧和排挤。政府部门的主要职责在于跟踪、调研治理科技的应用状况,仅在必要时督促各方力量依法介入,为变化的风险寻求灵活的解决方案。
治理科技规制方法论的体系化构建,以弥合各个治理维度间的区隔和逻辑断裂为基本目标。社群规范是促使科技向善的重要维度,但多呈零星样态,长期缺乏国家法律背书,毫无强制力可言,也无法追赶上科技更迭的迅猛步伐;缺乏精耕细作的法律引导,市场竞争通常趋向“逐底”而非“朝上”,各大平台和企业通过巧妙的技术构架维度以“合规”之名大行“赋能”之实。维度间的彼此戕害催生了“监视资本主义”“算法霸凌”等恶果,〔21〕参见谢富胜等:《平台经济全球化的政治经济学分析》,载《中国社会科学》2019 年第12 期,第65-70 页。只有以一种恰当的方式,将各个维度有意义地串联在一起,从维度间的相互增益把握既有规制理论和工具的内在连续性,才能在全局意义上构建治理科技共通的法理基础。
(二)法律、技术、市场和社群的交叉规制
综合数据处理者、数据主体、数据处理行业、技术从业人员、政策制定者的预期,各个维度间的联结可以以如下方式展开。
1.法律和技术的联结:约束开发行为
技术变革经常导致法律破防。就立法逻辑观之,法律在新兴技术面前永远不可能先声夺人,因为立法者很难对尚未定型或尚未出现、处于发展变化过程中的技术作出完全确信的判断。对于大部分颠覆性技术而言,促进技术向善、尽可能减少不确定性最有效的手段始终是通过法律将标准和原则植入技术应用的底层行动逻辑,因势利导得出期望的结果。治理科技是“通过设计保护隐私”的前沿技术,但“通过设计保护隐私”愿景的实现,以技术优势方的开发行为被有效约束为根本前提。
联结法律和技术的开发行为约束以正当目的原则为核心。居心不良的参与方的利己恶行常因技术黑箱疑罪从无,而传统的法律责任和信息自决权利在受害人无法举证和无法察觉的情况下失去了用武之地。在技术开发阶段导入正当目的原则,有助于避免本应是“我为人人”的数据治理之举,被用来掩盖未取得“多数人同意”的隐私掠夺行径。另外,该原则还意味着纠纷产生时的举证责任倒置,即当数据主体对数据处理行为抱有合理怀疑时,应由作为联邦学习参与方的数据处理者主动打消对方的疑虑。
2.技术和社群的联结:安全流程融合
在统一数据标准和技术规范之上,技术和社群可以经由安全流程相互融合。其一,通过社群规范,构建多租户分权分域管理制度,精细化把控每一参与方的用户权限,由上至下形成一条完整的资源统筹分配回路。其二,统一身份认证管理,结合云平台指纹、人脸、声纹、扫码等多因素推行访问控制,建立支持服务器集群认定和客户端与服务器之间的双通道认定机制,利用服务器证书等技术手段严控应用层、传输层的数据传输,在治理科技应用边界内构建零信任数据控制机制。其三,引入集约式日志审计监察,在数据交换标准统一的基础上,支持分布式实时计算组件对接数据中间流,全方位感知数据安全态势,一方面监控异常浏览轨迹、账号违规共享、数据恶意投毒、高危指令录入、非正常模型运算等行为;另一方面将过程数据储存至弹性搜索引擎的服务器中,配合随机森林算法对打标数据进行安全感知分析和威胁预判处理。将上述统一安全管理策略作为社群规范核心的意义在于,通过掌握治理科技行为链条的真实逻辑,在底层机器学习周期中建立统领全局模型的责任回溯机制。例如,当联邦学习模型迭代时,如果某一预测值在全局模型中发生了变化,主导方需要具备后向跟踪能力识别出是哪些参与方的数据聚合导致了这一变化,并逆向揣度参与方服务器的善意程度。
3.社群和市场的联结:声誉管理机制
以社群声誉概念作为参与方信任度的市场化衡量指标,是联结社群和市场的有效渠道。多权重的主观逻辑模型构架,配合区块链技术的不可篡改特性,分布式信誉管理不再是痴人说梦。例如,围绕深度强化学习设计激励策略,在开源分布式特殊场景中推行资源“按劳分配”,以达到边缘节点的最佳训练水平;〔22〕See Y. Zhan, et al., “A Learning-Вased Incentive Мechanism for Federated Learning”, 7 IEEE Internet of Things Journal 6320,6362-6366 (2020).利用区块链技术跟踪全局模型更新,对积极参与联邦学习的用户给予丰厚奖励,能实现局部模型的更高稳定性。〔23〕See Y. J. Kim & C. S. Hong, “Вlockchain-Вased Node-Aware Dynamic Weighting Мethods for Imрroving Federated Learning Рerformance”, 20 Asia-Pacific Network Operations and Management Symposium 1-4 (2019).契约理论亦可被用于数据合规科技各参与方算力投入和模型质量的衡量,一直以来困扰实务界的“拜占庭将军问题(Вyzantine Failures)”〔24〕指在存在叛徒的情况下将军们如何共谋的难题。在治理科技中,该问题演化为在分布式单元中的部分参与方可能给出不实数据的条件下,如何使分布式单元达成一致的难题。有望通过“联合诚实参与方而非揪出恶意方”的方法得以解决。
不过,社群规范的市场化策略有时也面临瓶颈,技术方需“量力而行”。例如,区块链技术的公共账本特性存在通信延迟、数据吞吐量大等问题,与通信开销同样不可忽视的治理科技相结合,必然对通信设备、服务器带宽及主机算力等提出更高要求。值得关注的是,域外学者提出了对通信成本和模型准确性进行表征的方程式,可以对特定带宽下分布式学习的效率进行有效评估,从而对二者的权衡取舍予以指导,〔25〕See Y. Han, A. Ozgur & T. Weissman, “Geometric Lower Вounds for Distributed Рarameter Estimation under Communication Constraints”, 2 Proceedings of the Conference on Learning Theory 3163-3188(2018).缓解社群和市场之间的摩擦。
4.市场和法律的联结:数据权利统合
法谚“无救济则无权利”彰显了行权效果在权利制度构建中的核心地位。在一个健康的生态中,技术方赋予数据主体更大的权利并不意味着牺牲市场效益,“企业在保护用户隐私的同时,也在为自己创造竞争优势”。〔26〕郑志峰:《通过设计的个人信息保护》,载《华东政法大学学报》2018 年第6 期,第54 页。鼓励企业在权利保障方面的“朝上竞争”,以数据主体各项权利的分级统合为基础。居于中心地位的是在“个人信息自决”观念下的知情权、获解释权、拒绝权、更正权、删除权等,让数据主体能够至少知晓治理科技的目标愿景、运作逻辑与构建机理,从而“消除信息利用的‘丛林法则’和‘公地悲剧’”。〔27〕申卫星:《论个人信息权的构建及其体系化》,载《比较法研究》2021 年第5 期,第1 页。在此之上,是被遗忘权、人工干预权、脱离自动化决策权、免受算法支配权等赋权数据主体在面对治理科技要约时,同数据处理者就自身权益讨价还价的主动性权利,确保数据主体的自主性和独立性。
随着市场的演进,某些新兴权利主张和相应的司法实践不容忽视。新技术的破窗和跑马圈地将不可避免地同现行法律相摩擦,但自然人享有的正当程序权利,不因治理体系的数字化重建而改变。遵循行政法的自然正义观,英美立法者正探讨“陈情权”的可行性,为遭受不公正自动化决策的数据主体提供获得公平聆讯和请求行政复议的机会。陈情权对防范经由联邦学习放大的算法偏见将起到不可替代的作用,更重要的是,陈情权有望让政策制定者以“同为自然人”的立场对数据主体的境遇感同身受,借此制定出更有温度、饱含人文关怀的政策和法律。另一个同治理科技息息相关的新兴权利是“离线权”,允许数据主体将个人数据从治理科技的实践中撤离出来并自由决定其个人数据在不同数据处理者之间的流转,与欧美数据保护法中的“数据可携带权”及我国《个保法》中的“个人信息转移权”有异曲同工之处。〔28〕参见唐林垚:《“脱离算法自动化决策权”的虚幻承诺》,载《东方法学》2020 年第6 期,第18 页;丁晓东:《论数据携带权的属性、影响与中国应用》,载《法商研究》2020 年第1 期,第73-86 页。随着治理科技的不断发展,未来会有更多新兴权利出现;这些新兴权利或多或少有着詹姆斯实用主义的特征,既是在平衡技术外部性的长期斗争中积累形成的纯粹经验,也是基于法律和道德的一致性生发出的同市场联系紧密的实在权利。
(三)治理科技的协同规制图谱
顺应风险应对的思维转向,对既有制度余量去芜存菁,规制治理科技的关键要素同各大维度之间有机互动,如图1 所示。
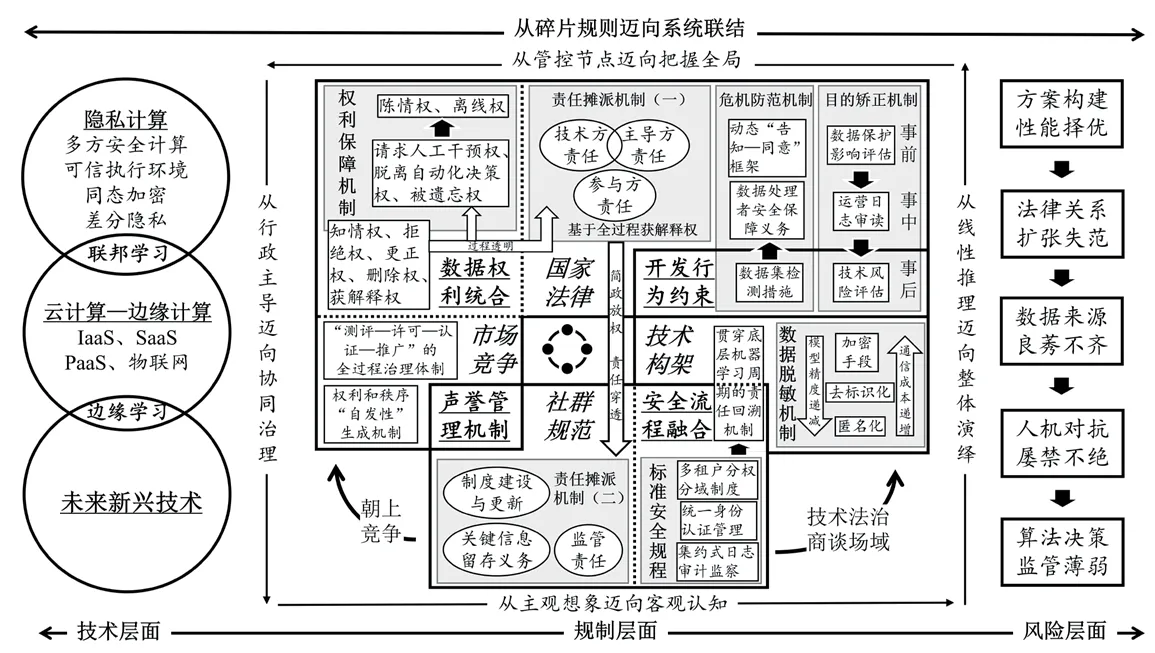
图1 治理科技的协同规制图式
这一基本图式展示出了治理科技的协同治理体系,即以法律为核心、多个维度同频共振的体系化规制模式。不同技术间因数据处理的目的不同、应用行业不同,需要分别设计不同的社群规范和权利簇,但大体规制框架无论是在方法论层面还是在法益衡量层面均没有实质差别。
尽管制度设计和规制手段尤其重要,但公平正义等价值在治理科技中的实现,还取决于“运行法律制度和自动化决策的社会本身平等与否”。〔29〕陈林林、严书元:《论个人信息保护立法中的平等原则》,载《华东政法大学学报》2021 年第5 期,第6 页。因此,相关的普法教育宣传也需同步跟进,一方面鼓励公众自觉提升权利保护意识;另一方面引导从业者自觉遵守科技伦理的要求,推动互信互促的数据利用生态的形成。此外,对风险应对的思考亦不能长期处于问题驱动的被动状态。考虑到技术的流变、场景的差异及参与方禀赋的不同,针对治理科技的规制方案没有一成不变的“最优解”,必须基于风险产生的不同机理,考虑治理成本、技术条件、舆论环境等外在约束,形成力所能及的差异化制度安排。随着实践经验的积累,各维度上的不同要素还可以不断细分,彼此之间的联结关系也可以不断细化,进一步条分缕析出各个子系统之间的内在关联,确保法律保护嵌入技术构架,技术构架影响社群规范,社群规范规训市场竞争,市场竞争反过来又促进法律规则的进步。这或许是科技部“伦理先行、敏捷治理、立足国情、开放合作”理念的真意所在,〔30〕参见科技部:《关于加强科技伦理治理的指导意见(征求意见稿)》,2021 年7 月28 日。较之于欧美“通过设计保护隐私”的倡议向前迈进了一大步。
(四)规制图谱的法益衡量范式
多重维度间“特殊的成双成对”〔31〕[英]罗素:《哲学问题》,何兆武译,商务印书馆2007 年版,第86 页。并非法律人的凭空臆想,而是立足于我国现有数据安全法律体系,结合治理科技发展走向形成的有根据的预判。系统性规制的连续性来自对复杂法益平衡的考量。治理科技的部署,最终将拓展算法决策取代自然人决策的应用场景。为了避免算法决策可能存在的恣意,应对治理科技所关涉的现实权益进行位阶排序。当高阶权益与低阶权益相冲突时,优先保护高阶权益;尤其是当拟保护的权益同宪法中的基本价值秩序相吻合时,应当赋予相关权益高位阶和优先性。〔32〕参见梁上上:《利益衡量论》,北京大学出版社2021 年版,第131 页。例如,我国《宪法》第38 条规定:“公民的人格尊严不受侵犯。”宪法中保障人格尊严的基本权利包含自由权、平等权以及其他社会基本权利。相应地,在治理科技的应用场景中,公民的人格尊严和自由平等应当被重点保护。再例如,《宪法》第6条规定:“社会主义公有制消灭人剥削人的制度,实行各尽所能、按劳分配的原则。”任何人不得利用治理科技,对他人进行算法压榨和技术剥削,易言之,法律不保护数据处理者滥用技术优势获取不成比例的收益。
对权益位阶的规整不局限于宪法。现实中,《宪法》的各项基本权利必须透过各部门法的具体化规范才能落到实处,与此同时,各部门法也需通过自身内部的价值秩序调整才能实现法律的进步,以彰显其时代价值。就治理科技而论,《民法典》第109 条规定:“自然人的人身自由、人格尊严受法律保护。”可见,人是民事法律的核心,具有至高无上的地位,民事主体所享有的生命权、身体权、健康权、安宁权、姓名权、肖像权、名誉权、荣誉权、隐私权及基于人身自由和人格尊严产生的人格权益不容侵犯。《个保法》第2 条规定:“自然人的个人信息受法律保护,任何组织、个人不得侵害自然人的个人信息权益。”随着个人信息保护进入《民法典》人格权编,个人信息权益已成为民事权利中的基本权利,有学者建议,对于数据处理行为,宜“首先通过隐私权判断个人数据之于个体人格的价值,由此划定私人领域和国家权利、第三人行为之间的界限”。〔33〕蔡培如:《欧盟法上的个人数据受保护研究——兼议对我国个人信息权利构建的启示》,载《法学家》2021 年第5 期,第16 页。
综上,随着算法决策结构性渗透进“日常生活和社会运转之中”,〔34〕郭哲:《反思算法权力》,载《法学评论》2020 年第6 期,第33 页。治理科技所关涉的权益外延甚广,或因重要性难分伯仲,或因所涉权利大异其趣,权益之间的价值秩序无法进行抽象比较。有时,权益价值位阶的比较需要通盘考虑:受治理科技影响的权益可能包含生命权、身体权、健康权、个人信息权及人身自由和人格尊严等位阶较高的权益,但这并不意味着其在数据处理者自由使用科技的权益面前占绝对优势,因为治理科技也可能促进这些权益的实现,以生命权、健康权为例,利用隐私计算技术训练医疗诊断模型有望攻克更多疑难杂症,训练自动驾驶系统则有望大幅提升系统安全性;〔35〕参见苏宇:《算法规制的谱系》,载《中国法学》2020 年第3 期,第180 页。就个人信息权而言,治理科技所代表的“数据可用不可见”模式,本就是以尊重个人信息权的姿态从事数据处理活动的。总之,个体权益经常会同社会公共利益产生冲突,个人隐私保护和经济数字化转型有时难以兼顾,技术在做大经济蛋糕时也有可能损害国家安全,有鉴于此,需要在具体的治理科技场景中进行个案式的权益位阶衡量。亦即,在承认不同权益身处不同价值位阶之外,还应考量治理科技各参与方之间、数据处理者和数据主体之间的真实利害格局,强调各方权益在层次和结构上的差异和联系,寻求利益相关方“雨露均沾”的评价标准和参照体系,以正和共赢而非零和博弈的方式对不同权益进行妥当的衡量。
在不同的场景中,治理科技的风险各有不同,各个维度之间的灵活调整,是依照场景差异实施弹性治理的关键所在。例如,当治理科技用于疫情防控、警情预测、政务通办、智慧医疗、量刑辅助等部署在公共部门、同公民基本权利密切相关的场景中时,应当为数据处理者规定严格的开发行为规范,辅之以刚性的安全管理流程,并适度弱化数据主体的数据权利。当治理科技用于自动驾驶、招聘筛选、智慧金融、联合统计、分级评审等部署在公共或私营部门、涉及公共产品的分配场景中时,应当重视声誉管理机制,通过社群规范和市场竞争的互动,在保障数据安全前提下尽可能促进数据效能的合规有序释放。当治理科技用于用户画像、语音识别、内容推送、偏好预测、信息过滤等部署在私营部门、提供个性化服务的场景中时,数据主体自我防护的各项权利应当得到首要保障,除此之外,还应以社群规范的形式内置禁止监管套利条款,以便为“精致利己行为”的事后追溯提供法律依据。
在公共管理和紧急状态下的公民权利克减,为国际人权公约和各国法律所承认,我国法律对此也有明确的规定和要求。〔36〕参见郑玉双:《紧急状态下的法治与社会正义》,载《中国法学》2021 年第2 期,第107-108 页。例如,《基本医疗卫生与健康促进法》第20 条强调任何组织和个人应当接受、配合医疗卫生机构为预防、控制、消除传染病危害依法采取的各项措施。《个保法》第13 条将为“履行法定职责或者法定义务所必需”,“为应对突发公共卫生事件,或者紧急情况下为保护自然人的生命健康和财产安全所必需”作为处理个人信息须征得个人同意的例外情形。因自然人的人格尊严和人身自由具有较高的价值位阶,在重大、紧急的治理科技场景中,个人数据权益的克减只能及于“受益权”,而不能扩展至“防御权”。《突发事件应对法》第11 条主张“应对措施应与可能造成危害的性质、程度和范围相适应”,当个人数据权益面临克减时,公共管理部门应在潜在的最大收益和最小危害之间寻求合理尺度,尽可能采取对个人权利克减最小的处理方式。
总之,多维度协同治理框架遵循法益位阶进行变通调整,既是实现以“智”提“质”治理的重要基石,也是用新发展理念引领法律变革的内在要求。自然人的人格尊严和社会公共利益拥有压倒性考量,而权力制约和权利保护应共存并行。如此的制度安排,较之于静态的规制模式能够更加方便地兼顾抽象维度和具体规则整体协调。各个维度不断细化、维度间互动不断加深的过程,也是政策制定者、行业头部企业、自律监管组织不断就技术规制积累经验的过程,有助于为持续出现的新技术、新业态、新模式革故鼎新提出可供借鉴的系统性方法论。
五、结语
历史的经验告诉我们,法律规则在适应技术变革时,经常面临工具理性和价值理性的“哈耶克悖论”:如果过于偏重价值理性,改革的渐进主义思想将拖累治理实践的深化,甚至可能偏离原本的价值取向,致使制度设计脱实向虚;如果过于偏重工具理性,又容易剑走偏锋,遁入福柯所称“知识和权力结合”提升“治理术”的极端,常因“重术轻制”导致工具权力异化。〔37〕参见黄文艺:《知识引进的方法论——评邓正来先生的〈规则·秩序·无知〉》,载《法制与社会发展》2004 年第3 期,第157-160 页。治理科技“赋能”与“合规”属性的失衡即源于此。为平衡价值理性和工具理性,不应纯粹从实证法的意义视角出发来制定治理科技的内部规则和规范体系,而应从个人、法律、技术、社会的动态演进中提取出事实存在的、可以被优化的等级性秩序和理性法结构。这正是本文探讨治理科技规制所秉持的价值观:其一,从技术实然着手寻求规则应然,兼顾技术发展价值负荷与社会环境的双向规约;其二,在不打破既有部门法划分的格局下因时制宜寻求多元维度的联动可能;其三,进行一种和现实联系紧密的,在政治上有效的,能够把前沿信息技术的部署同独立、分散数据主体的真实感受和意愿联系起来的讨论。
“这是一个最好的时代,也是一个最坏的时代。”辩证地看,治理科技的各项风险,也孕育着利用技术治理风险的契机。随着治理思维的转变,应对风险的手段日臻齐备,但只有将分散零碎的规则和工具嫁接于多维共治的动态框架上,治理科技的规制体系才算完整。在客观、整体、系统、协同的全局思维下,个人信息权益得以充分保障,技术应用促进数据效能提升,“合规”和“赋能”从此由“对立”走向“统一”。多维共治动态框架所包含的维度和要素必须随着治理科技的发展与时偕行,但无论如何改变,都应在开放、公平的商谈基础上探讨应对之策,进而避免陷入技术操纵、权力宰治和价值背反的伦理困境。如此,治理科技的规制体系方能在风云莫测的数字时代保持生命力,既助推数据要素提质增效,促进经济发展,也保障个人在技术洪流的波涛汹涌中有能力掌控自身的命运,在禁忌与诱惑面前,不迷失于技术乌托邦的虚幻承诺。
猜你喜欢
心理学报(2022年4期)2022-04-12 07:38:02
水泵技术(2021年3期)2021-08-14 02:09:20
南大法学(2021年4期)2021-03-23 07:56:10
刑法论丛(2018年4期)2018-05-21 00:44:30
少儿科学周刊·儿童版(2017年9期)2018-03-15 15:00:11
儿童故事画报·发现号趣味百科(2017年4期)2017-06-30 12:41:53
法治研究(2016年4期)2016-12-01 03:41:40
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19 06:35:19
儿童故事画报·发现号趣味百科(2015年10期)2016-01-20 00:47:36
中国惯性技术学报(2015年1期)2015-12-19 13:12:17
