
结合注意力机制的CNN-LSTM的视频中双相抑郁症检测方法
2022-05-25 01:46穆家宝
网络安全与数据管理 2022年5期
穆家宝
(中国科学技术大学 大数据学院,安徽 合肥 230026)
0 引言
双相抑郁症(Bipolar Disorder),即双相抑郁障碍,也称躁狂抑郁症,是一种能够引起患者心情大起大落变化的疾病。患者既有躁狂表现,又有抑郁症症状表现。躁狂时自我感觉良好、精力充沛、积极乐观、思维活跃,又或脾气暴躁、行事冲动;抑郁时则情绪低落、兴趣减退、极度自卑。患者情感发作形式不限,可以是抑郁发作、躁狂发作,也有部分患者在一段时间内出现躁狂和抑郁的反复交替。
由于双相抑郁症患者会经历躁狂和抑郁两种不同的发作情况,因此它的确诊要比其他精神疾病更加困难。据统计,双相抑郁症患者的平均确诊时间高达8年。每两名双相抑郁症患者中就有一人在其一生中至少尝试过一次自杀行为,且很多患者通过自杀结束生命,年平均自杀率高达0.4%[1],是普通人群的10~20倍[2]。双相抑郁症患者的终身自杀风险高达20%[3]。
大多数双相抑郁症患者都是在躁狂发作期间自杀的,这主要是因为患者在抑郁期积攒的负面消极情绪被躁狂发作时的冲动点燃,将自杀的念头转化为自杀的行为,造成了双相抑郁症患者的高自杀率[4]。因此,如果能够开发一种算法可以自动评估双相患者此时所处的状态(Mania/Hypomania/Remission),就可以协助医生进行辅助治疗。
近年来,一些研究致力于攻克双相抑郁症的自动评估。Abdullah等人[5]使用智能手机应用程序在四个星期内被动记录的手机语音、短信和通话,应用机器学习技术来测量社会节奏指标。这个指标可以显示双相抑郁症患者在日常中的任何变化。Le等人[6]通过提取情绪唤醒度和上半身运动直方图对双相抑郁症患者进行分类,并使用深度神经网络(Deep Neural Networks,DNN)作为分类器,其实验结果显示对于女性患者达到了50%的召回率,对于男性患者达到了53%的召回率。Ciftic[7]等人使用Kaya等人[8]提出的手工面部特征提取方法,作者先选择了从视觉信息中提取的23个几何特征和从音频信息中提取的低级描述符(LLDs)作为输入特征,使用偏最小二乘法(Partial Least Squares,PLS)和极限学习机(Extreme Learning Machines,ELM)检测双向抑郁症。在2018年国际视听情感挑战赛(Audio-Visual Emotion Recognition Challenge18,AVEC2018)中,主办方提供视觉模态的面部动作单元、音频模态的梅尔倒谱系数和日内瓦简单声学参数集(GeMAPS)等底层特征作为竞赛基准特征[9]。实验表明,这些底层特征在双相抑郁症的检测中具有很重要的作用。Xing等人[10]使用底层特征(包括MFCC、eGeMAPS、FAU、眼神、每句话单词数量等)结合梯度提升决策树提出了一个多模态层级回归模型,在AVEC2018数据集上取得了不错的效果。Du等人[11]提出了一个基于音频的IncepLSTM模型,该模型通过将计算机视觉领域的Inception模块和LSTM网络相结合,从双相抑郁症患者语音的MFCC中提取多尺度的时序特征。
以上基于手工设计的底层特征检测方法虽然取得了较好的检测性能,但对病情的认知还不充分,还需要更好的方法提取特征来进行检测。
针对以上问题,近年来迅速发展的深度学习技术为检测双向抑郁症提供了新的思路[12]。随着深度卷积神经网络(Deep Convolutional Neural Network,DCNN)、长短期记忆网络(Long Short Term Memory,LSTM)等模型的出现,抑郁症检测领域利用其强大的特征提取能力得到了迅速的发展。目前,针对视频的双向抑郁症的自动检测技术相对落后,如果将深度学习技术应用到视频双向抑郁症检测中,将会有效地提高自动检测技术的性能。
因此,本文提出一个CNN-LSTM网络的混合模型,该模型从视频中提取特征去检测双相抑郁症的三个不同阶段(Mania/HypoMania/Remissionone),通过使用CNN网络提取面部特征,将面部特征输入LSTM网络,从而对双相抑郁症的不同阶段进行分类。在在AVEC2018双相抑郁症数据库开发集上的实验结果表明,该模型性能优于之前的方法。
1 数据集
Ciftci等人在AVEC2018上[7]提供了土耳其音视频双相抑郁症数据集。该数据集中的样本来自土耳其一家精神健康中心,样本均被诊断患有双相抑郁症。数据集中包含46名患者和49名健康对照组人员的音视频信息。实验规定在患者住院期间的第0天、第3天、第7天、第14天、第28天以及出院后的第3个月进行音视频数据跟踪录制,同时对患者进行杨氏躁狂量表(Young Mania Rating Scale,YMRS)和蒙哥马利-阿斯伯格(Montgomery-Asberg Depression Rating,MADRS)抑郁量表的测定。音视频在录制时,需要受试者完成7项任务,包括:
(1)讲诉来医院的原因;
(2)讲诉为什么参与录制这次数据;
(3)描述愉快的记忆;
(4)描述悲伤的记忆;
(5)从1数到30;
(6)观看梵高的画,然后根据自己的理解描述;
(7)观看丹戈尔的画,然后根据自己的理解描述。
数据集总共包含218段视频,视频长度为13 s~1019 s。每段视频都被标注了样本录制时的双相抑郁症的阶段和YMRS分数。218段视频被划分称3个部分,其中104段视频作为训练集,60段视频作为开发集,54段视频作为测试集。由于测试集的标签只在AVEC2018比赛中可用,因此本文在开发集上评估实验结果。
2 方法
本文首先将原始视频帧中的人脸部分裁切出来得到面部图片序列,然后把面部图片序列送入微调过的Resnet50模型提取面部特征序列,最后面部特征序列经过LSTM模型分类从而得到最终预测标签,整体网络框架如图1所示。

图1 模型架构图
2.1 面部特征提取
以30 Hz的帧率提取每个视频的所有帧,总计提取了约200万个视频帧。为了关注面部信息,使用dlib库的人脸检测模块[13]将每一帧图片中的人脸裁剪出来并对齐,然后将裁剪出来的人脸图片尺寸缩放至224×224像素存储。接下来,将存储的图片送进CNN网络提取面部特征。模型过拟合是深度学习中一个常见的问题,特别是在小数据集上训练模型时十分常见,常见的解决方法是使用在通用计算机视觉基准数据集(例如ImageNet和VGGFace2[14])上预训练模型的权值。ImageNet数据集是针对物体识别任务而开发的,VGGFace2数据集是针对人脸识别任务而开发的。由于本文目标与人脸属性相关,使用VGGFace2数据集上预训练模型的权值更加合适。初始化一个在VGGFace2数据集上预训练的Resnet50模型,再在FER2013plus人脸表情数据集[15]上对模型进行微调来作为面部特征提取器。具体方法为:替换预训练模型的分类器层以适配FER2013plus数据集的表情分类任务,以较小的学习率在数据集的训练集上训练模型,训练完成后的模型作为面部特征提取器。
将人脸图片输入微调过的Resnet50模型,提取模型最后一个平均池化层的2048维的输出作为面部特征向量。对所有的特征向量进行标准化处理,生成对应每一个样本的特征向量序列。
2.2 特征序列分类
CNN模型仅能提取空间信息,无法处理特征向量序列的时序信息。为了解决这个问题,使用循环神经网络来处理时序信息。LSTM是一种改进过的循环神经网络,主要解决了传统循环神经网络训练时产生的梯度消失和梯度爆炸问题。此外,还引入了门控单元控制信息传递。具体结构如图2所示。

图2 LSTM模型架构图
给定输入序列[x1,…,xt,…,xT],将输入序列映射到一个输出序列[y1,…,yt,…,yT],如下所示:


其中it表示输入门单元,ft表示遗忘门单元,ot表示输出门单元,ct表示记忆单元,ht表示隐层单元,Wab表示a和b间的可学习权重,ba表示偏置数,⊙表示哈达玛积(Hadamard Product),σ表示Sigmoid激活函数σ(x)=1/(1+e-x)。
为了使模型聚焦特征序列中与病情重点相关的片段,并减少无关片段对分类性能的影响,在LSTM模型后添加一个注意力层。注意力层首先计算不同帧特征的权重参数,然后对不同帧的特征加权求和,得到整个视频片段的特征(表示为y),最后通过Softmax分类器预测整个视频片段的所属类别。注意力层具体计算方式如下:

3 实验
(1)数据增强
训练集和开发集总共164个样本,细节如表1所示。为了增加训练样本,采用以300帧的步长切分每个样本。对于开发集上的样本采取相同的切分方法,切分前后训练集和开发集的样本数量如表1所示。
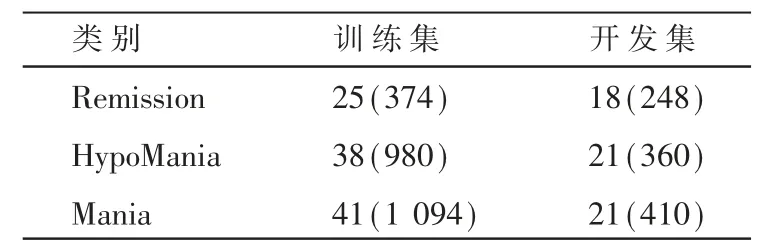
表1 训练集和开发集上三类样本数
(2)实验参数
硬 件 平 台 为:AMD Ryzen 3700x CPU,NVIDIA RTX3090 GPU;
软件平台为:Windows 1021H2,PyTorch 1.10.1+CUDA11.3。
模型训练使用结合梯度裁剪的动量SGD优化器进行训练,初始学习率设置为0.001。损失函数使用交叉熵损失函数。batch size设置为16。LSTM网络的隐层单元设置为128。
(3)性能评估
本实验采用AVEC2018比赛使用的准确率(Accuracy,Acc)和未加权平均召回率(Unweighted Average Recall,UAR)作为评估模型性能的指标。其中:

其中TPx表示该类别分类正确的样本数量,Recallx表示该类别的召回率。
(4)实验结果
表2展示了结合注意力机制方法(Resnet50+LSTM+Attention)和未加注意力机制方法(Resnet50+LSTM)的实验结果。相比之下,结合注意力机制的方法识别准确率更高,表明注意力机制能增强LSTM网络的特征提取能力,因为注意力机制能从视频帧序列中有选择地筛选出对病情有判别作用的片段,并聚焦到这些重要片段上。

表2 注意力机制的消融实验(%)
表3展示了本文工作和现有使用视觉信息检测双相抑郁症工作的对比,本文方法的平均召回率达到了61.4%,准确率达到了64.2%。实验结果表明,在面部动作单元(Facial Action Unit,FAU)、视觉词袋模型(Bag of Visual Words,BoVW)、上半身运动速度等方面,本文方法优于采用手工特征的方法。

表3 与现有工作结果的对比(%)
4 结论
本文提出了一个基于CNN-LSTM网络的混合模型的双相抑郁症检测方法。该方法从视频片段中提取特征作为输入,使用在人脸表情数据集上微调的Resnet50模型提取视频帧的空间特征,通过结合注意力机制的LSTM网络提取帧之间的时序信息来检测双相抑郁症。通过对比当前的工作,所提出的方法有更高的分类准确率。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
数学物理学报(2022年5期)2022-10-09
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
四川大学学报(自然科学版)(2021年6期)2021-12-27
现代临床医学(2021年4期)2021-07-31
粉末冶金技术(2021年3期)2021-07-28
陶瓷学报(2020年6期)2021-01-26
计算机应用(2020年12期)2020-12-31
当代陕西(2019年10期)2019-06-03
文苑(2015年9期)2015-09-10
