
基于关键点的混合式漏洞挖掘测试用例同步方法
2022-05-25 07:45:22蒋可洋曹彭程
工程科学与技术 2022年3期
赵 磊,辉 涛,蒋可洋,曹彭程
(1.武汉大学 空天信息安全与可信计算教育部重点实验室,湖北 武汉 430000;2.武汉大学 国家网络安全学院,湖北 武汉 430000)
在自动化的漏洞检测和挖掘相关工作中,模糊测试技术是一项高效且简洁的测试解决方案,其优势在于在未知被测程序或系统相关先验知识的条件下,可以自动化地进行测试工作。模糊测试技术的核心思想是给程序提供大量的特殊或随机的测试用例,通过监控程序运行过程中的异常情况,定位软件中的潜在漏洞位置,从而协助安全研究者快速发现程序的潜在漏洞点。
如今,AFL及其拓展等模糊测试工具正在被广泛地应用于各个漏洞挖掘领域中。但是,随机生成的测试用例往往难以突破程序中的复杂条件约束,如程序中广泛存在的“magic number”或者“checksum”的检测。这使得模糊测试技术通常只能对程序的浅层代码进行检测,而难以访问被复杂条件保护的程序深层代码区域。
在漏洞挖掘领域中,符号执行也是一项重要的技术,得益于其求解复杂条件约束的能力,常被用于漏洞的条件分析;针对模糊测试的不足,模糊测试与符号执行相互协作的混合式漏洞挖掘方法被提出,旨在利用符号执行中的约束求解来突破程序中复杂条件的限制,引导模糊测试进入程序的深层代码逻辑。目前,围绕着模糊测试模块与符号执行模块之间不同的协作方式,研究人员实现了不同的混合式漏洞挖掘工作:Pak等使用符号执行模块收集路径约束,并且将满足约束的输入转移给模糊测试模块。Stephens等提出了工具Driller,其侧重于利用模糊测试模块探索大部分路径;而当模糊测试模块进入停滞状态时,会启动符号执行模块来求解可以通过约束的输入。Wang等提出用一个最优策略模型来评估路径约束求解的花销来指导混合式漏洞挖掘的路径选择,但是该评估模型本身占用了大量资源。Haller等使用静态分析和污点分析来指导混合模糊测试中的符号执行模块。Yun等提出了工具QSYM,在混合式漏洞挖掘中实现更细粒度的、指令级的符号模拟。Huang等提出了增量混合模糊测试框架,通过优化混合式漏洞挖掘方法中缓存和重用的计算结果很少的问题,在符号执行模块中实现了更有效的突变和约束求解。
现有的这些混合式漏洞挖掘的研究工作,主要集中在如何提高符号执行模块的性能,以及如何在模糊测试模块和符号执行模块中传递更适合的测试用例,忽略了两个模块由于原理与实现上的差异所带来的实际信息同步中的问题。具体来说,当前的混合式漏洞挖掘方案通常仅将符号执行模块生成的测试用例简单地传递给模糊测试模块以进行信息同步。这种简单的处理方式并不能很好地同步符号执行模块在探索程序状态时的运行时信息,造成了符号执行模块生成测试用例的导入数量少和模糊测试模块对符号执行模块生成的测试用例使用不当的问题,并进一步制约了混合式漏洞挖掘的漏洞挖掘效率。
为了更好地优化混合式漏洞挖掘方案中符号执行模块和模糊测试模块的同步问题,本文提出了一种基于程序关键点的测试用例同步方法(Sol-QSYM)。该方法挖掘了符号执行模块执行过程中被忽略的程序关键点信息,并基于关键点来增强符号执行模块中的测试用例生成和指导模糊测试模块中测试用例调度与变异过程,在两个模块之间实现了更细粒度的测试用例同步,进而提升了整体的漏洞挖掘效率。
1 混合式漏洞挖掘测试用例同步问题
混合式漏洞挖掘框架可以分为模糊测试和符号执行两个模块。两者所做的工作均是基于给定的测试用例所对应的程序状态来探索未知的程序状态,但是,两个模块进行探索的方式、工作流程及对于测试用例的利用方式是不同的。模糊测试模块执行速度快,但不易求解出特殊路径约束,适合于快速探索解空间大的路径;符号执行模块求解速度慢,但能够生成沿特定路径执行的输入,适合于探索解空间小的路径。
图1为本文总结现有混合式漏洞挖掘工作的流程框架图。由图1可知:现有混合式漏洞挖掘工作中模糊测试模块与符号执行模块的协同方式是通过测试用例的同步和交换实现的。模糊测试模块作为程序测试的主体,在得到一个测试用例后,先经过测试用例执行状态检测、测试用例调度、测试用例变异这3个主要步骤,再对目标程序进行测试,并返回当前的代码覆盖率信息来指导接下来的测试过程。当测试过程陷入瓶颈无法发现新的代码覆盖率时,会将种子集合中的一个测试用例和当前已经测试得到的程序状态同步提供给符号执行模块。符号执行模块先根据得到的测试用例和代码覆盖率信息,经过路径分析与约束求解后会得到一些触及此测试用例执行路径上的其他分支路径的求解结果;再根据这些求解结果构造相应的测试用例,提供给模糊测试模块来为测试过程引入新的代码覆盖。

图1 混合式漏洞挖掘流程图Fig. 1 Workflow of hybrid fuzzing
但是,由于模糊测试与符号执行在实现方式上的差异,单纯依靠测试用例进行模块间协同的方式会使模糊测试模块难以同步符号执行求解的程序空间。这就导致了符号执行模块消耗了大量系统资源的同时,无法将所得信息全部提供给模糊测试模块来辅助漏洞挖掘,进而影响了软件测试效率。具体来说,现有测试用例的同步方式不能很好地同步符号执行模块得到的信息,该问题体现在两个方面:
1)符号执行模块生成测试用例的导入数量少
导入数量指的是符号执行模块生成的所有测试用例中被模糊测试模块接收并使用的数量。由于模糊测试模块中对于测试用例的使用是以程序执行状态为首要的检测标准,在测试过程中只会使用能够使程序以正常状态退出的测试用例。但是,符号执行模块受限于对于外部环境的模拟及约束求解的能力问题,其只是简单地通过求解与分支相关的部分输入,再在原有基础上以替换的方式来生成新的测试用例。这导致符号执行模块得到的测试用例大部分是不完整的,而这些不完整的测试用例会由于无法满足程序状态检测而在模糊测试模块中被丢弃,即符号执行模块生成的测试用例只有很少一部分被模糊测试模块导入。
为了量化分析该问题,本文从模糊测试和混合式漏洞挖掘相关研究工作所广泛使用的测试程序集中,随机选取了12个开源的Linux应用程序。针对经典混合式漏洞挖掘工具QSYM实验统计了其模糊测试模块对于符号执行模块求解结果的利用情况,实验结果可见表1。从表1中可以看出,QSYM中模糊测试模块对于符号执行模块求解结果的利用率普遍较低,整体的符号执行求解结果的导入率仅为7.19%。
表1 QSYM中符号执行模块生成测试用例利用情况
Tab. 1 Utilization of testcases generated by symbolic execution module in QSYM
被测程序 求解结果个数 导入个数 导入率/%cjpeg 153 22 14.38 exiv2 517 35 6.77 infotocap 1 638 15 0.92 jhead 955 57 5.97 nm 56 3 5.36 objdump 313 1 0.32 pdfimages 891 53 5.95 pngfix 739 222 30.04 readelf 1 458 153 10.49 size 24 2 8.33 tiffdump 368 5 1.36 xmlwf 1 082 21 1.94平均 682.83 49.08 7.19
2)对符号执行模块生成的测试用例使用不当
当前混合式漏洞挖掘方案中,模糊测试模块并不会特殊对待符号执行得到的测试用例,而采用与随机变异得到的测试用例同样的处理方式。
由于忽略了符号执行自身的特点,这种测试用例处理方式并不是最佳的。一方面,根据混合式漏洞挖掘的工作流程,符号执行模块生成的测试用例有更大可能突破当前模糊测试的瓶颈,这种不加区别的处理方式会让符号执行模块的优势被削弱。另一方面,测试用例中不同部分对于被测程序的状态影响是不同的,符号执行模块生成的测试用例中往往包含了能影响程序决定分支的关键字信息,而不加区别的处理方式会浪费并破坏掉这些信息。
2 基于关键点的测试用例同步方法
针对上述测试用例的同步问题,本文提出了基于程序关键点的测试用例同步方法,旨在提高混合式漏洞挖掘对符号执行模块所得信息的利用效率,并进一步提升漏洞挖掘效果。
基于程序关键点的测试用例同步方法基本思想在于充分利用符号执行的求解结果来构造出更完整的覆盖程序潜在分支的测试用例,并利用程序关键点信息指导模糊测试的测试用例调度与变异过程,使得符号执行的求解信息得到区分与利用。改进的测试用例同步方法流程如图2所示,主要分为3部分内容:关键点与关键分支信息提取、基于关键点的测试用例生成和程序关键点引导的测试用例处理。
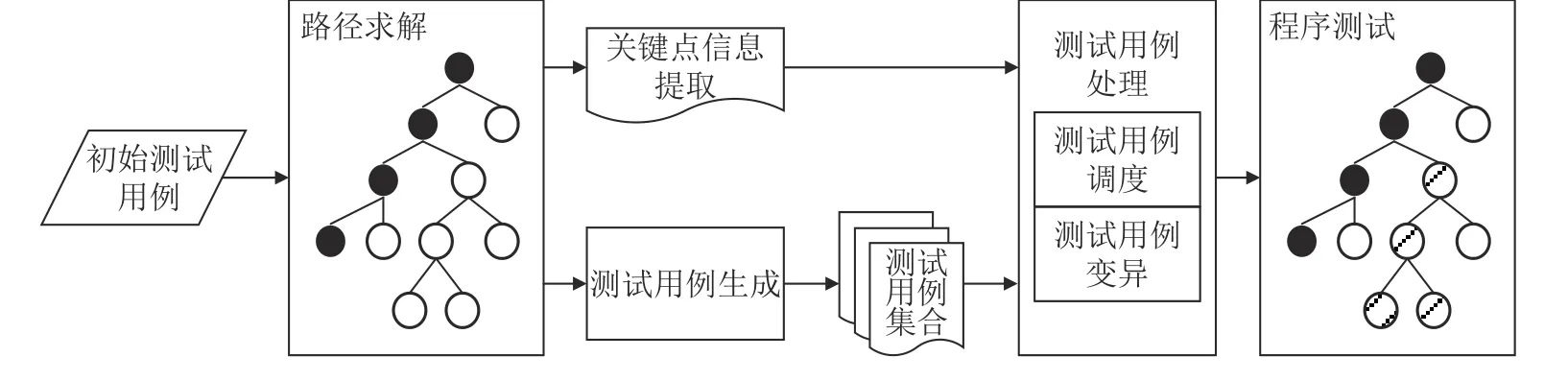
图2 基于关键点的测试用例同步方法流程Fig. 2 Workflow of testcase synchronization method based on keypoints
2.1 关键点与关键分支信息提取
本文对关键点与关键分支的定义如下:如果一个程序分支的约束条件对应的解空间很小,在符号求解中花费较多的资源,那么,将该程序分支路径当成一个关键分支,此分支的前驱节点及对应的变量集合为程序关键点。程序的关键分支具备如下两个特点:一是,符号执行能够求解出满足该条件分支的具体解;二是,当前的测试用例到达了关键点下的其他分支路径。
在符号执行模块探索过程中对关键点和关键分支信息进行提取,具体地,符号执行模块通过判断该分支是否满足上述两个特点从而进行关键分支的识别。下文基于关键点的测试用例生成与程序关键点引导的测试用例处理均是针对关键点与关键分支进行。
2.2 基于关键点的测试用例生成
为了充分利用符号执行得到的求解结果,受文献[17]启发,本文利用信息组合的思路设计了新的测试用例生成方法。该方法通过组合不同程序分支对应的变量值来生成新的测试用例。由此得到的测试用例集合会携带更多的符号执行求解信息,并且在实际执行中更容易到达被求解的程序分支。这样能够在不引入新的符号执行求解操作的前提下,更好地挖掘符号执行求解结果的利用潜力。
求解信息组合思路如图3所示。
图3中: φ为符号执行中的约束集合,每个方框代表了与分支相关的某一程序的变量; σ为给定的初始化求解对象,代表了当前约束集合 φ的一个求解结果;方框中,1代表了该变量的符号约束被求解,而0则代表了没有。
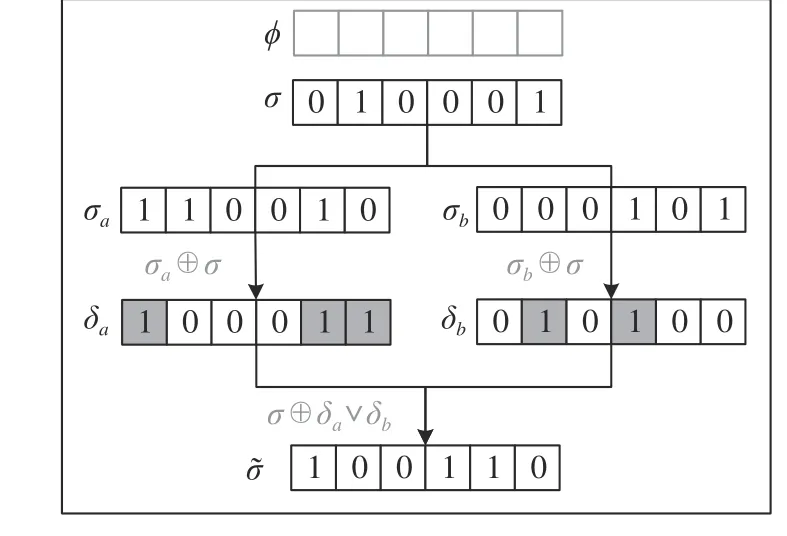
图3 求解信息组合Fig. 3 Idea of solving results combination
若将约束集合 φ对应的所有程序分支集合表示为V
。对于集合V
中的任意分支v
(v
∈V
),则能到达该分支的求解结果为 σ。 σ为由符号执行在初始解 σ基础上仅针对特定分支的约束求解得到的结果,求解结果也只与该分支相关的变量有关。将针对分支v
求解过程中涉及的变量集合定义为 δ。 δ也就是 σ 与σ的差异部分,表达式为 δ=σ⊕σ 。通过 δ,建立了程序状态分支与程序变量集合的对应关系。对于给定的初始解 σ,通过上述操作,将V
中的分支v
的求解结果作为基础的变异集合,如图3中的δ和 δ。之后,将关键变量进行进一步匹配组合,具体表现为变量集之间的或操作,即 δ∨δ。这样,在现有求解结果的基础上,只需计算 σ ⊕δ∨δ,可以得到一个全新的解 σ˜, 而 σ˜ 相 较于 σ 同 时包含了 δ和 δ的求解信息。求解信息组合的基本思想在于,既然 δ和 δ中分别包含了针对分支a
与b
的 求解信息,那么 σ˜很有可能同时满足分支a
与b
。利用上述思想,符号执行求解引擎只需要求解得出基础的变异集合,通过随机的简单变异组合就能得到新的解集合,而不再需要符号执行模块重新对程序的路径约束进行符号化,然后求解。这些生成的测试用例及对应的关键分支信息会被提供给模糊测试模块。
2.3 程序关键点引导的测试用例处理
模糊测试模块在得到测试用例与关键点信息后,需要解决的问题是如何让携带关键点信息的测试用例引导测试过程进行特定区域的探索,如何根据关键分支信息为不同测试用例中不同类型的变量与对应的输入区域分配不同的变异策略,使得变异过程中在当前测试用例的基础上能更高概率地生成有效的测试用例。
本文在现有混合式漏洞框架的基础上对模糊测试模块的测试用例调度算法与变异算法进行了改进,帮助模糊测试模块更好地利用符号执行模块中得到的关键点信息。
2.3.1 测试用例调度算法改进
在模糊测试模块中,随着测试用例规模的不断增大,在有限的时间和资源内需要对测试用例进行调度,以帮助模糊测试模块选择最有价值的测试用例进行测试。当前的模糊测试工具,如AFL,为了挑选出有价值的测试用例来进行变异,会为每一个已覆盖的程序分支e
挑选出最优的测试用例s
,并保存在测试用例集合T
中。即T
记录的是每条分支对应的最优测试用例。对于保存的测试用例集合T
,先要满足覆盖目前已知所有的程序状态,在此基础上AFL会优先选择那些体积更小、测试速度更快的测试用例。但仅采用T
无法区分符号执行模块得到的带有关键分支信息的测试用例与普通的测试用例。因此,本文引入符号执行模块在路径求解时候得到的覆盖率信息,来指导模糊测试模块挑选测试用例。具体来说,改进后的方法将关键分支对应的最优测试用例保存到一个符号执行对应的测试用例集合S
中,并且由符号执行模块同步更新。在对一个测试用例进行测试的过程中,如果一个测试用例s
覆盖了S
所记录的分支信息e
,并且该分支e
是第一次被该测试用例s
所覆盖,那么S
会指定目前分支e
最优的测试用例为s
。在改进之后的测试用例挑选过程中,会遍历S
记录的所有测试用例信息,将其中未被测试过的测试用例挑选出来放入待测队列,并优先在接下来的变异和测试过程中使用。同时,为了保证不丢弃目前已覆盖的程序状态信息,在处理完S
记录的测试用例之后,测试用例挑选过程会根据完整的覆盖率信息从T
中挑选出覆盖剩余程序状态的测试用例放入测试队列。2.3.2 测试用例变异算法改进
模糊测试模块在原有测试用例的基础上,对测试用例进行随机的变异,以产生更多的测试用例并达到更多的程序代码覆盖效果。现有的混合式漏洞挖掘框架,如QSYM,在测试用例变异过程中对模糊测试模块本身和来自符号执行模块的测试用例采用了相同的变异操作。这导致了现有的测试用例变异过程并不能充分发挥符号执行模块在探索程序状态的优势,忽略了符号执行模块得到的能影响程序决定分支的关键字信息。
因此,本文对测试用例的变异算法进行了改进。改进后的算法主要是在变异对象的选择与变异操作的分配上进行了优化。具体来说,改进后的变异算法先利用符号执行求解的程序分支获得与程序状态对应的变量信息,再针对不同的测试用例变异位置来分配不同的变异权重。改进后方法的目的在于,对可能产生新的代码覆盖分支变量上进行重点变异;与程序状态无关的,比如一些数值类的输入,在其对应位置上减少变异操作,使得变异更容易生成能产生新代码覆盖的测试用例。改进后的测试用例变异算法主要有两个阶段,即非随机性变异阶段和随机性变异阶段,算法伪代码如下。
算 法
改进后的测试用例变异算法输入:种子集合Queue
、覆盖率accCov
、S
;输出:变异的测试用例集合Testcases
;

t
为当前需要变异的测试用例对应的覆盖率信息。如果t
中存在符号执行求解过的某些程序分支,首先会根据S
确定测试用例q
中对应的变量位置,接下来会对测试用例相应位置应用预先定义的非随机性变异操作,最后通过模糊测试中的状态判断函数Save_if_interesting判断是否生成了有效的测试用例。通过应用上述策略,非确定性变异阶段可以针对性地对测试用例中的关键位置进行变异,以减少无效的操作。算法的16~23行是随机性变异阶段。由于随机性的变异操作会大幅修改测试用例的内容,无法根据程序的结构信息设置具体的变异位置与变异操作,因此采取与AFL相同的处理方式,即AFL定义的随机性变异阶段的操作流程。但与AFL不同的是,针对从符号执行模块导入的测试用例,改进后的方法会分配更多的变异轮数与变异时间。
3 方法实现与实验评估
基于混合式漏洞挖掘框架AFL+QSYM,本文实现了基于关键点的测试用例同步方法,并构建了系统原型Sol-QSYM。为了兼容AFL和QSYM的处理过程,其核心算法分别使用了C和C++实现。
3.1 实验环境与数据
为了验证本文基于程序关键点的混合式漏洞挖掘测试用例同步方法的有效性,本文从相关研究工作广泛使用的测试数据集中,随机选取了12个程序进行实验,选取的所有程序见表2。
表2 测试程序数据集
Tab. 2 Datasets in test
程序名 程序版本 空间大小/kB输入格式 测试命令cjpeg libjpeg-9b[18] 672 jpeg cjpeg @@exiv2 exiv2-0.25[19] 3 147 exif eixv2 @@ /dev/null infotocap ncurses-6.1[20] 253 text infotocap @@jhead jhead-3.00[21] 85 text jhead @@nm binutils-2.26.1[22] 5 791 elf nm-AD @@objdump binutils-2.26.1[22] 5 791 elf objdump-fdDh @@pdfimages xpdf-4.00[23] 1 677 pdf pdfimages @@ /dev/null pngfix libpng-1.6.36[24] 978 png pngfix @@readelf binutils-2.26.1[22] 5 791 elf readelf-a @@size binutils-2.26.1[22] 5 791 elf size-At @@tiffdump libtiff-4.0.10[25] 23 tiff tiffdump @@xmlwf libxpat-R.2.2.5[26] 258 xml xmlwf @@
本文设计了AFL、QSYM、Sol-QSYM共3组实验,其中,前两组为对照组,第3组为实验组。每组的配置方式均采用1个主fuzzer、两个从fuzzer的配置结构,测试时间统一为12 h。本文中所有的被测程序、系统实现、对比实验均在统一的实验环境下进行。具体的实验环境为:Ubuntu 16.04 LTS 64位系统,Intel(R)Core(TM) i7-8700K CPU @ 3.70 GHz,16 GB RAM。
3.2 评估标准
实验分别针对测试用例同步方法的两部分进行评估。对于测试用例生成方法的效果,通过导入数量进行评估;对于测试用例处理方法的效果,由于难以单独进行评估,通过整体的代码覆盖率提升与程序崩溃状态挖掘数量来进行评估。
3.3 实验结果
3.3.1 符号执行求解结果的导入情况
表3为改进前后的测试用例同步方法中符号执行模块测试用例的导入结果对比。
表3 QSYM与Sol-QSYM测试用例导入结果对比
Tab. 3 Comparison of testcases import results for QSYM and Sol-QSYM
测试程序 QSYM Sol-QSYM 导入数提升比例/%测试用例数 导入数 测试用例数 导入数cjpeg 153 22 368 25 13.64 exiv2 517 35 782 41 17.14 infotocap 1 638 15 1 744 18 20.00 jhead 955 57 961 66 15.79 nm 56 3 61 4 33.33 objdump 313 1 369 2 100.00 pdfimages 891 53 926 55 3.77 pngfix 739 222 797 234 5.41 readelf 1 458 153 1 644 179 16.99 size 24 2 27 2 0 tiffdump 368 5 387 6 20.00 xmlwf 1 082 21 1 473 32 52.38平均 682.83 49.08 794.92 55.33 12.73
表3中,测试用例个数是指最终提供给模糊测试模块的测试用例数量。对于原方法,该数量为符号执行模块求解生成的测试用例数量;而对于改进后的方法,指的是符号执行求解生成的测试用例加上改进后方法生成的测试用例的数量。
从表3可以看出,相同的时间内,改进方法比原始方法得到了更多的测试用例,并提高了成功导入模糊测试模块的测试用例数量。对于不同的程序,由于程序结构的不同,导入数提升比例差异很大。总的来说,12个程序的平均测试用例导入数提升比例为12.73%。
3.3.2 代码覆盖率情况
代码覆盖率是评估漏洞挖掘方法的一个综合性指标,它衡量了一定时间内漏洞挖掘工具所能到达的程序空间。
统计了相同时间内12个被测程序在使用AFL和QSYM、Sol-QSYM方法挖掘漏洞时的代码覆盖率信息,如表4所示。从表4中可以看到,本文方法能很好地提高漏洞挖掘的代码覆盖率,特别地,相较于QSYM的平均效率提升为9.07%。同时结合表2可以发现,当被测程序的程序规模大小不同,本文方法的提升的代码覆盖率比例也不同。一般来说,当被测程序规模较大时,相较于AFL与QSYM,本文方法能够提升较多的代码覆盖率。
表4 AFL、QSYM和Sol-QSYM的代码覆盖率对比
Tab. 4 Comparison of code coverage rates for AFL, QSYM and Sol-QSYM
测试程序 归一化的覆盖率信息/% Sol-QSYM相较于QSYM提升比例/%AFL QSYM Sol-QSYM cjpeg 2.63 2.65 2.69 1.51 exiv2 12.73 17.55 19.42 10.66 infotocap 4.45 4.48 4.58 2.23 jhead 0.76 1.67 1.86 11.38 nm 6.08 6.52 6.83 4.75 objdump 1.00 1.08 1.35 25.00 pdfimages 4.19 4.20 4.27 1.67 pngfix 4.48 4.93 5.02 1.83 readelf 9.58 9.70 11.52 18.76 size 5.61 6.57 7.52 14.46 tiffdump 0.71 0.79 0.81 2.53 xmlwf 7.38 7.45 7.85 5.37平均 4.97 5.63 6.14 9.07
同时,给出AFL和QSYM、Sol-QSYM方法的代码覆盖率随时间变化曲线,如图4所示。由图4可看到,应用本文方法后,相同时间内相较于AFL和QSYM,Sol-QSYM能更快地探索到更多的程序代码空间。
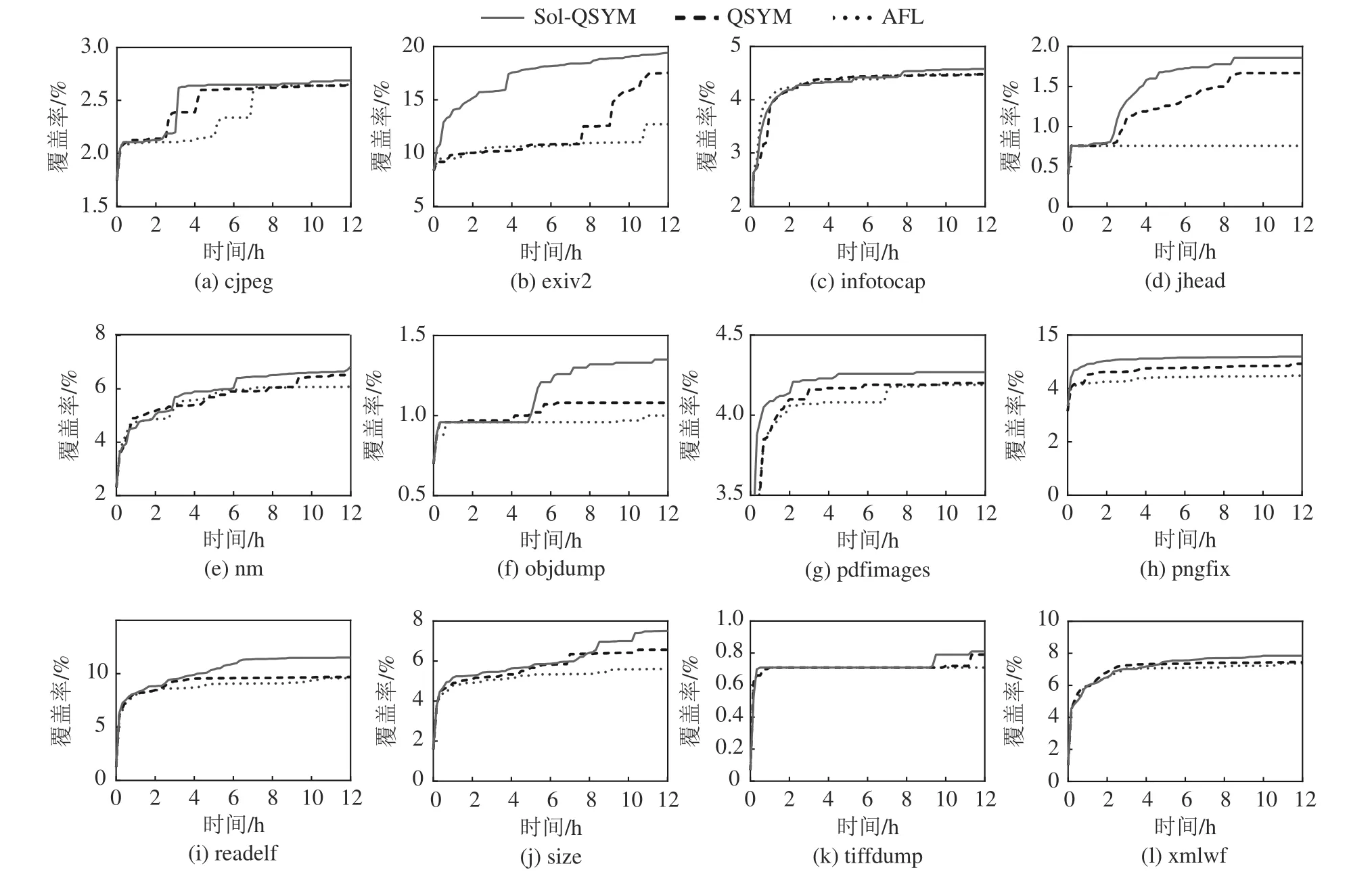
图4 AFL、QSYM和Sol-QSYM的代码覆盖率随时间变化曲线Fig. 4 Curves of code coverage rates for AFL, QSYM and Sol-QSYM with time
3.3.3 触发程序崩溃情况
收集统计了在相同时间和相同资源情况下,AFL、QSYM和Sol-SQYM分别触发目标程序崩溃即Crash的测试用例数量,结果见表5。
表5 AFL、QSYM和Sol-QSYM的程序崩溃状态挖掘结果
Tab. 5 Crash mining results for AFL, QSYM and Sol-QSYM
测试程序 Crash个数AFL QSYM Sol-QSYM cjpeg 16 21 30 exiv2 0 0 0 infotocap 86 110 137 jhead 0 0 0 nm 0 0 0 objdump 8 17 18 pdfimages 0 1 1 pngfix 0 0 0 readelf 0 0 0 size 1 1 2 tiffdump 0 0 0 xmlwf 0 0 0总计 111 150 188
由表5可知,使用本文改进后的测试用例同步方法发现的Crash总数为188个,高于AFL和原有混合式漏洞挖掘方法QSYM发现的111、150个。该结果说明本文改进后的测试用例同步方法能够提高漏洞挖掘能力。
4 结 论
本文分析了现有混合式漏洞挖掘工作中模糊测试与符号执行模块间的测试用例同步方法存在的问题,提出了基于程序关键点的测试用例同步方法。在混合式漏洞挖掘工具QSYM的基础上,实现了新的测试用例同步方法及系统原型Sol-QSYM,并针对12个现实程序展开了实验评估。实验结果表明,相较于以往的混合式漏洞挖掘方法中的测试用例同步方法,改进后的测试用例同步方法能够提高模块测试模块对符号执行模块生成测试用例的导入率,并能帮助混合漏洞挖掘方法更快且更深地探索程序的代码空间,同时能发现更多的程序崩溃状态。这些结果表明改进后的测试用例同步方法可以很好地提高混合式漏洞挖掘对符号执行模块得到信息的利用效率。
在未来的研究工作中,将继续对混合式漏洞挖掘中的模块间信息同步方式进行研究,探索符号执行模块得到的测试用例中的程序结构信息与状态信息,用于指导模糊测试。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
铁道通信信号(2020年6期)2020-09-21 09:23:22
学生天地(2019年28期)2019-08-25 08:50:54
传感器与微系统(2018年7期)2018-08-29 00:44:18
数学物理学报(2018年1期)2018-03-26 08:16:36
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01 02:54:29
中国卫生(2014年2期)2014-11-12 13:00:16
语文知识(2014年7期)2014-02-28 22:00:26
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
