
基于密度聚类算法的学情数据可视化分析研究
2022-05-25 04:48严志
现代计算机 2022年6期
严 志
(长沙民政职业技术学院软件学院,长沙 410000)
0 引言
随着高校数字化建设及信息化管理时代的到来,传统教育模式及教育方法在新技术的冲击下正在发生悄然变革,探索从海量教育数据中挖掘学生学习规律和学习方式,让真实的教学数据帮助教师实现教学工作方式转变,让管理者主动把握学生的行为特点和规律,让教学与管理实现科学化、智能化、精准化与个性化。
传统的高校教育教学工作中,对学生学习生活状态的把控和判断主要依赖相关授课老师或辅导员的经验和主观判断,随着高校信息化建设的发展,各类信息系统的运用为大数据技术分析高校学生的学习生活规律提供了数据基础,同时也为创新高校教育教学工作提供了可能性。沈贵庆利用大数据平台对学生学习行为数据进行存储,采用数据挖掘算法和云计算技术获取学生学习隐形行为。王改花等采用数据挖掘工具对网络学习者进行聚类分析,将学生群体分为4类,得出学习行为与学习效果密切相关;胡学钢等通过认知跟踪模型分析学生作答习题的得分表现,追踪学生随时间变化的认知状态,从而预测学生在未来时间的作答表现。张进良等以在线教育平台为载体构建智能化学习环境,建立以数据支持的在线学习行为研究,通过对学习行为数据的挖掘与分析,促进学生自主反思、自主发现问题,为学习者提供个性化学习服务。徐蕾等梳理归纳了国内外教育大数据在服务教师教学、辅助学生学习、优化高层决策、协助学校管理等方面的研究现状,提出了教育大数据在实时统筹学生动态发展、优化教师教学质量、动态规划资源分配、高校智能决策四方面的技术路径选择。目前,美国教育部门构建“学习分析系统”,通过数据驱动学校,分析变革教育,帮助预测学生未来的学习行为,为教育工作者提供更多、更好、更精确的信息。澳大利亚卧龙岗大学开发了社会网络可视化工具,构建在校大学生日常学习行为分析系统。
教育大数据的研究对象包括教育管理者、教师、学生和家长,其本质还是改善管理效率,优化教师教学方法以及提高学生成绩。通过学生学习生活中一系列重要的信息,使用大数据分析和可视化手段将其完整地呈现出来,为评优评先、教学质量提升及贫困生鉴别等提供服务,优化高校决策机构与教师对教育资源的配置,进一步提升教师的教学质量与学生的成长环境。教育大数据使得教学信息在高校决策者、教师、学生与家长之间完整无阻地流动,让教学效果变得可见,让决策过程有据可依,其对教学质量提升具有重大的意义。本文以教育数据为依托,构建教育可视化分析系统,通过密度聚类算法分析学情与考勤、学情稳定性,挖掘教育规律,为信息化决策提供依据。
1 学情分析系统架构设计
学情分析系统的主要原理是:将MOOC课程资源数据、第三方网络数据源搜集整理,数据经整理后以规范化的数据保存到关系数据库或文件中,对要研究的数据进行聚类分析,再使用可视化框架工具如echarts等以图形方式展示,系统的核心框架如图1所示。
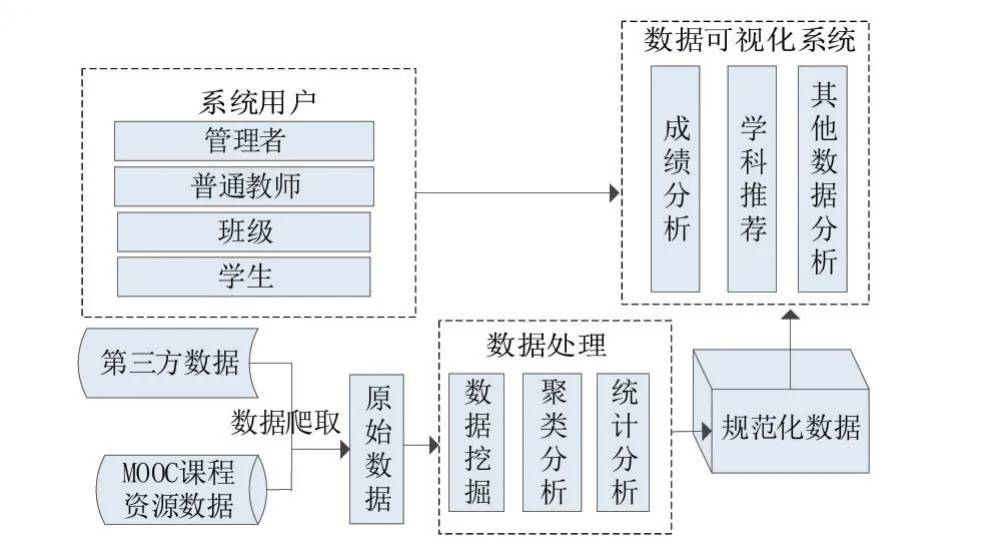
图1 系统框架
在图1所示框架中,将第三方数据和MOOC数据爬取存储到关系数据库中,然后通过SQL语句对数据进行数据挖掘,形成数据汇总分析,然后再执行聚类算法分析,形成规范化的可视化数据,并将结果显示到Web前端,系统用户通过可视化系统查看数据分析结果,方便用户查看学情效果。
以普通教师为例,通过数据可视化系统可以查看所在班级的成绩、学习帮扶推荐、班级消费、班级考勤,其主要功能如图2所示。

图2 教学管理框架
2 数据源模型
本文采用线上资源课程数据结合第三方数据源作为本系统的数据源模型,搜集整理后的数据表格包含文章表、成绩表、学生表、教师表、考勤表、考勤类别表、消费记录表等数据。物理表模型如图3所示。
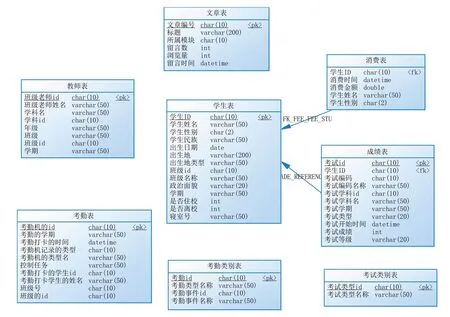
图3 物理表模型
3 DBSCAN聚类算法
给定集合,包含了个对象={,,,…,X},其中每个对象包含个维度属性,DBSCAN算法基于一组“邻域”参数(,MinPts)来刻画样本分布的紧密程度。
●-邻域:对X∈,其-邻域包含样本集中与X的距离不大于的样本,即(X)={X∈|dist(X,X)≤},其中距离函数dis(t)是欧式距离。
●核心对象(core-object):若X的-邻域至少包含个样本,即||(X)≥,则称是一个核心对象。
●密度直达(directly density-reachable):若X位于X的-邻域中,且X是核心对象,则称X由X密度直达。
●密度可达(density-reachable):对X与X,若存在样本序列,,,…,p,其中=X,p=X,且p由p密度直达,则称X由X密度直达。
●密度相连(density-connected):对X与X,若存在X使得X与X均由X密度可达,则称X与X密度相连。
如图4所示,设定=3,虚线代表-邻域,则是核心对象,由密度直达,由密度可达,与密度相连。
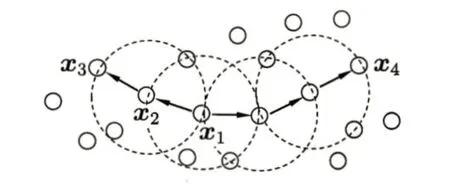
图4 DBSCAN聚类关系
DBSCAN算法在数据集中任选一个核心对象为种子,由该节点计算密度可达生成的聚类簇,遍历数据集中所有核心对象形成最终聚类簇。该算法具体过程如下所示:
输入:样本集D={,,,...,x}
邻域参数(,)
过程:
1:初始化核心对象集合:Ω=∅
2:for j=1,2,…,do

4 学情相关性分析
4.1 学情与考勤的关系
通过考勤表t_kq、学生表t_student和成绩表t_chengji三个表之间的关系,查找出学习成绩与学生考勤之间的关系,形成考勤成绩元组模型:
x={_,_,_,_};其中:考勤学生学号,:考勤方式,:考核课程平均分,:个人考试成绩。
将考勤数据形成样本集D={x,x,…,x}输入到DBSCAN密度查询算法进行聚类分析得到图5所示结果。其中纵轴0代表平均成绩,横轴代表迟到次数。通过考勤次数与学科成绩的聚类关系得出,成绩较好的学生考勤数据较好。
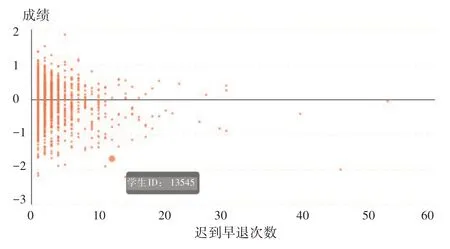
图5 考勤次数与成绩分布
图6给出了考勤数据与学生成绩的比例,从中可以看出迟到次数较少的优等生比例较高,迟到次数达到20次以上差等生的比例接近100%。

图6 考勤与成绩优劣关系
4.2 成绩稳定性探究
通过研究成绩表的各科课程平均成绩和个人标准差成绩,对学生成绩的稳定性进行探究。
选择数据元组
x={_,_,_,_},其中:课程编号,:课程平均成绩,:课程个人成绩,:学科成绩标准差。
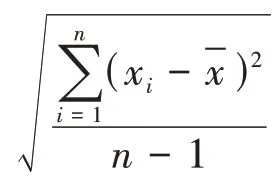
采用DBSCAN算法进行分析得到学生学科成绩的稳定性,如图7所示。标准差接近20的为非稳定成绩群体,标准差在10以内的群体为学习成绩稳定群体。

图7 学生学科成绩稳定性分析
5 结语
本系统采用前端可视化框架,数据分析使用密度DBSCAN聚类算法,数据源基于在线课程和第三方数据结合而成。通过分析系统架构及聚类算法的原理,挖掘分析成绩与考勤的关系、学生的成绩稳定性,为大数据学情分析提供了案例。由于统计的数据不够精细,以上分析不一定代表实际的结果,为使大数据更加精准地为教学服务,需要充分记录详尽数据,分析比较各类算法,得到更精准的分析结果,为服务学校管理提供帮助。
猜你喜欢
云南教育·小学教师(2022年4期)2022-05-17
快乐学习报·教师周刊(2022年4期)2022-04-25
汽车实用技术(2022年4期)2022-03-07
办公室业务(2020年3期)2020-05-07
初中生世界·初中教学研究(2020年1期)2020-04-30
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
福建基础教育研究(2019年5期)2019-05-28
科学与财富(2019年4期)2019-04-04
电子技术与软件工程(2016年23期)2017-03-06
东方教育(2016年5期)2016-10-21
