
融合ReFPN结构与混合注意力的小目标检测算法
2022-05-25 08:16赵一鸣王金聪任洪娥赵龙
哈尔滨理工大学学报 2022年2期
赵一鸣 王金聪 任洪娥 赵龙



摘要:基于深度学习的小目标检测研究对于如小人脸识别、遥感图像检测等任务的优化与提升都具有极为重要的意义。但由于图像中的小目标所占像素较少,分辨率低,包含的特征信息不明显,现有方法对小目标的检测效果并不理想。针对此问题,提出一种基于反馈的特征融合网络ReFPN用于YOLOv4算法,两次利用骨干网络提取的原始特征层,加强小目标特征信息,对其进行更精确的位置回归。同时提出混合注意力机制Co-AM充分提取小目标的细节特征信息,抑制无效特征,进一步提高小目标的检测精度。实验结果表明,此文提出的方法使YOLOv4算法在MS COCO数据集上平均精度AP提高了1.9%,小目标平均精度AP提高了3.3%,检测效果优于现有小目标检测算法,证明了此文提出方法的有效性。
关键词:深度学习;小目标检测;特征融合;注意力机制
DOI:10.15938/j.jhust.2022.02.011
中图分类号: TP751.1
文献标志码: A
文章编号: 1007-2683(2022)02-0085-07
A Small Object Detection Algorithm Integrated with ReFPN
and Compound Attention Mechanism
ZHAO Yi-ming WANG Jin-cong REN Hong-e ZHAO Long
(1.College of Information and Computer Engineering, Northeast Forestry University, Harbin 150040, China;
2.College of Mechanical and Electrical Engineering, Northeast Forestry University, Harbin 150040, China;
3.Heilongjiang Forestry Intelligent Equipment Engineering Research Center, Harbin 150040, China)
Abstract:The research of small target detection is of great significance for the optimization and improvement of tasks such as small face recognition and remote sensing image detection. However, the small target in the image occupies fewer pixels, lower resolution, unobvious feature information, resulting in the effect that existing methods for small target detection is not ideal. To solve this problem, a feedback-based feature fusion network (ReFPN) for YOLOV4 algorithm was proposed. The original feature layer extracted from the backbone network is used twice to enhance the feature information of small targets and position regression performs more accurately. At the same time, the compound attention mechanism (Co-AM) was proposed to more fully extract the detail feature information of small targets, suppress invalid features, and further improve small targets’ detection accuracy. Experimental results show that the method improves the AP of YOLOV4 algorithm on MS COCO dataset by 1.9%, and the AP by 3.3%. The effectiveness of our method is proved, and the detection effect of small target detection is better than the existing algorithms.
Keywords:deep learning; small object detection; feature fusion; attention mechanism
0引言
目標检测作为图像理解和计算机视觉的基石,是解决图像分割、目标追踪、图像描述等更复杂更高层次视觉任务的基础,广泛应用于无人驾驶[1]、安全系统和微小瑕疵检测等领域[2]。近年来迅猛发展的深度学习技术是一类能自动从数据中学习特征表示的强大方法,为机器学习和计算机视觉等领域带来了革命性的进步,显著改善了目标检测的表现。
基于深度学习的小目标检测研究对于诸多领域如小人脸识别、目标跟踪、人体关键点检测、遥感图像检测等任务的优化与提升都具有极为重要的意义。而卷积神经网络[3](Convolution Neural Networks, CNN)具有多层网络结构自动学习的特点,主要由输入层、输出层、卷积层、下采样层和全连接层组成。浅层的卷积层用于提取丰富的局部特征,深层的卷积层将这些局部特征进行结合,从而学习到更加抽象的特征。卷积神经网络提取的抽象特征对图像分类以及图像中物体粗略位置的定位很有效。早期的目标检测框架大多数是针对通用目标来进行检测的。但小目标像素偏低,所包含的特征信息较少,易被算法当做背景信息忽略掉,导致检测精度偏低,小目标检测在深度学习卷积神经网络模型中一直是个难题。
随着深度学习与卷积神经网络[4]的快速发展,科研人员提出了基于区域提取的R-CNN(Region-CNN)、Faster R-CNN[5]等两阶段检测方法,在产生目标候选框的基础上对候选框做分类与回归,仍无法很好地解决小目标检测问题。在端到端的单级目标检测算法中,Liu 等[6]提出一种SSD(Single Shot MultiBox Detector)算法,该算法兼顾了检测速度和检测精度。但是其存在特征提取不充分的问题,从而对小目标检测的效果一般。Redmon等[7]提出了YOLO(You Only Look Once)算法,它的第三个版本——YOLOv3[8]将高级网络与低级网络连接起来,从高层特征与低层特征图中的细粒度信息中获取信息。这种信息融合方式在一定程度上提高了小目标的检测性能,但没有充分利用低层特征信息。因此,它在检测小目标方面很弱。YOLOv4[9]在YOLOv3的基础上提高了目标检测精度,使速度与精度达到了最优平衡,目前对通用目标的检测效果较好,但在小目标检测精度方面仍有很大提升空间。
针对YOLOv4算法在MS COCO数据集上对小目标的检测效果不够理想的问题,本文在YOLOv4算法结构的基础上提出以下方法来提升小目标的检测效果:①针对小目标在图像中像素少、分辨率低的本质问题,提出了一种基于反馈的特征融合网络ReFPN用于YOLOv4算法,通过两次利用原始特征层,加强算法对小尺寸目标特征的学习,对小目标进行更精确的位置回归。②针对小目标本身所包含信息因素少,容易被非检测目标因素影响的问题,提出混合注意力机制Co-AM,搭建在CSPDarknet53后,充分提取小目标的特征信息,增强有效特征,避免小目标被当做背景信息。实验证明本文提出的方法模型对小目标的检测精度有较大提升,得到了更优的检测效果。
1特征融合结构ReFPN
低层网络特征图携带更多目标的位置形状等信息,故为加强算法对小尺寸目标特征的学习,获得更多的低层特征信息,本文提出一种基于反馈的特征融合结构(retroaction feature pyramid networks, ReFPN),如图1所示。虚线框部分为FPN[10]结构,由自底向上和自顶向下2个路径组成。自底向上的路径是提取特征的卷积网络,特征层由低到高的空间分辨率以2倍递减,同时检测到更多的高层语义信息。自顶向下的融合路径通过对所提取每步卷积特征层进行上采样处理,将高层的特征图放大到上一步的特征图一样的大小,保证维度相同。为了将高层语义特征和低层特征的精确定位能力结合,利用横向连接将上一层经过上采样后和当前层分辨率一致的特征,通过相加的方法进行融合。既利用了高层较强的利于分类的语义特征,又利用了低层利于定位的高分辨率信息,丰富了融合后的特征图所包含的信息。
成功的目标检测器都表现出了信息的反复利用和提精[11]。故ReFPN的后半部分将来自FPN(Featu-re Pyramid Networks)层的特征通过反馈连接合并到自下而上的骨干层中,将FPN的反馈信息集成到骨干网络上,再次利用原始特征图,使骨干网络重新训练来自FPN的带有梯度的特征,实现了两次思考的顺序设计,增强了FPN的特征表示,丰富了特征融合的表现能力。再经过自下而上的特征融合路径,在低层用准确的定位信号来增强整个特征分层,缩短低层和高层特征之间的信息路径,获得更多的低层特征信息,对小目标的位置形状等信息的检测更有利。
反馈连接使用空洞空间金字塔池化(atrous spatial pyramid pooling, ASPP),为图1横线圆部分,采用不同采样率可以有效地捕获多尺度上下文信息,模块结构如图2所示。在此模块中,以FPN的特征图作为输入,有4个并行分支,其中3个分支中的卷积层配置如图2所示,后跟ReLU层,输出通道数是输入通道数的1/4,最后1个分支使用全局平均池化层来压缩特征,然后使用1×1卷积层和ReLU层将压缩后的特征转换为1/4输入通道数的特征。最后,调整大小并与其他3个分支的特征连接在一起,以多个比例捕捉图像的上下文,实现特征金字塔的级联连接。
使用融合模块如图3所示。此模块用来融合FPN输出特征f与整体特征融合后的输出特征f’,为图1竖线圆部分,通过1×1卷积层和Sigmoid运算来计算注意力图,然后将结果注意力图用于计算更新后的加权和。
ReFPN通过两次利用原始特征层,加强了算法对小尺寸目标特征的学习,并利用ASPP作为反馈连接提升整合多尺度信息的能力,获得更多的低层特征信息,更有利于小目标的定位检测。
2混合注意力机制Co-AM
深度学习中的注意力机制[12]的核心目标是从众多信息中选择出对当前任务目标更关键的信息,最早由DeepMind为图像分类提出,让神经网络在执行预测任务时可以更多关注输入中的相关部分,更少关注不相关的部分。Woo等[13]基于一个有效的体系结构同时利用空间和通道注意模块来关注更多信息,取得了很好的效果。徐诚极等[14]将注意力机制引入到YOLO算法中,提高了检测精度。
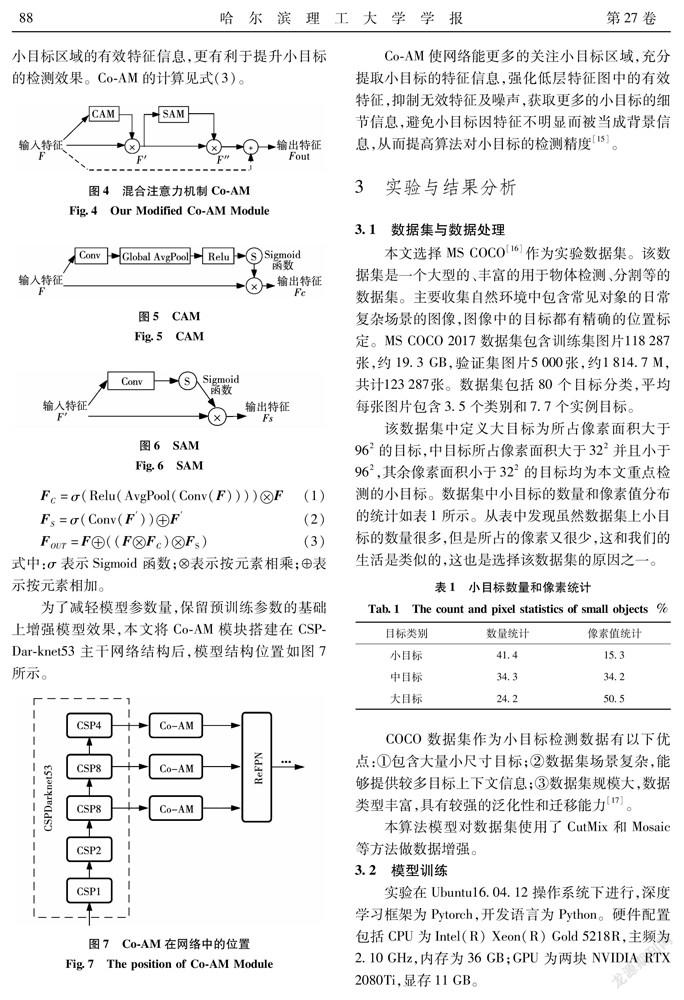
受此启发,针对小目标因包含特征信息不明显而易受到背景信息因素的干扰的问题,本文提出混合注意力模块(compound attention mechanism, Co-AM),用于YOLOv4算法的主干网络CSPDarknet53后,来更多的关注小目标的特征信息。Co-AM的模块结构如图4所示。其中,通道注意力模块CAM如图5所示,输入特征F依次经过卷积层、全局平均池化层以及ReLU和Sigmoid运算,得到的特征图再与F相乘输出特征F,关注输入的图像是否有检测目标的特征,对不同通道的特征重新进行了加权分配。通道注意力的计算见式(1)。
空間注意力模块SAM如图6所示,输入特征F′ 通过卷积层与Sigmoid运算,得到的特征图再与F′ 相乘输出特征F,关注目标所在位置的特征信息,是对通道注意力的补充。空间注意力的计算见式(2)。
分别在空间和通道2个维度,学习并提取特征中的权重分布,依次推断得到注意力特征图。将注意力特征图与原特征图相乘进行自适应特征优化,再次与原特征图相加,如图4中虚线箭头,二次增强小目标区域的有效特征信息,更有利于提升小目标的检测效果。Co-AM的计算见式(3)。
为了减轻模型参数量,保留预训练参数的基础上增强模型效果,本文将Co-AM模块搭建在CSPDar-knet53主干网络结构后,模型结构位置如图7所示。
Co-AM使网络能更多的关注小目标区域,充分提取小目标的特征信息,强化低层特征图中的有效特征,抑制无效特征及噪声,获取更多的小目标的细节信息,避免小目标因特征不明显而被当成背景信息,从而提高算法对小目标的检测精度[15]。
3实验与结果分析
3.1数据集与数据处理
本文选择MS COCO[16]作为实验数据集。该数据集是一个大型的、丰富的用于物体检测、分割等的数据集。主要收集自然环境中包含常见对象的日常复杂场景的图像,图像中的目标都有精确的位置标定。MS COCO 2017数据集包含训练集图片118287张,约19.3GB,验证集图片5000张,约1814.7M,共计123287张。数据集包括80个目标分类,平均每张图片包含3.5个类别和7.7个实例目标。
该数据集中定义大目标为所占像素面积大于96的目标,中目标所占像素面积大于32并且小于96,其余像素面积小于32的目标均为本文重点检测的小目标。数据集中小目标的数量和像素值分布的统计如表1所示。从表中发现虽然数据集上小目标的数量很多,但是所占的像素又很少,这和我们的生活是类似的,这也是选择该数据集的原因之一。
COCO数据集作为小目标检测数据有以下优点:①包含大量小尺寸目标;②数据集场景复杂,能够提供较多目标上下文信息;③数据集规模大,数据类型丰富,具有较强的泛化性和迁移能力[17]。
本算法模型对数据集使用了CutMix和Mosaic等方法做数据增强。
3.2模型训练
实验在Ubuntu16.04.12操作系统下进行,深度学习框架为Pytorch,开发语言为Python。硬件配置包括CPU为Intel(R) Xeon(R) Gold 5218R,主频为2.10GHz,内存为36GB;GPU为两块NVIDIA RTX 2080Ti,显存11GB。
为了获得更好的结果,模型选择了具备自适应调节步长能力的Adam方法作为优化算法,其中学习率初始值设置为0.0026,batchsize设置为128,训练过程中将128张图一次性加载进内存,前向传播后将128张图的loss累加求平均,再一次性后向传播更新权重。subdivisions设置为16,一个batch分16次完成前向传播,即每次计算8张。为了防止模型出现过拟合,模型中使用了类别标签平滑,并且在训练阶段加入了系数为0.0005的权重衰减正则项。
输入图片大小为608×608,以上述模型训练参数为基础训练出3个改进后的模型,分别为改进特征融合的模型,加入混合注意力的模型以及两改进点共同作用的模型,用于后续检测的消融实验。
3.3检测效果分析及算法性能评价
本文方法在MS COCO数据集上进行了多组实验以验证小目标的检测效果,实验中发现,影响检测效果的因素主要是错检和漏检。检测效果如图8所示,图中共标注44个待检目标,图8(a)为YOLOv4模型的检测效果,检测出22个目标,错检3个目标,漏检22个目标;图8(b)为加入ReFPN后模型的检测效果,检测出28个目标,错检3个目标,漏检16个目标;图8(c)为加入Co-AM后模型的检测效果,检测出27个目标,错检3个目标,漏检17个目标;图8(d)为本文综合改进模型后的检测效果,检测出31个目标,错检3个目标,漏检13个目标。本文算法在数据集上有效提高了对小目标的检测效果,下一步将研究依旧存在错检和漏检的原因并通过改进来提高算法的检测效果。
为对比评价YOLOv4模型和本文训练出的3个模型对于包含小目标的COCO数据集的检测精度,采用AP(average precision)作为评价指标。AP是指P-R(precision-recall)曲线与坐标第一象限围成的面积,通常在实际应用中并不会直接对P-R曲线计算AP,而是对P-R曲线进行平滑处理操作,即对P-R曲线上的每一个点,都选择该点右侧最大的那个精确率值,然后使用平滑后的精确率值计算AP,计算AP的计算式为式(4)、(5)。
各项实验数据如表2所示。选取Pytorch版本的YOLOv4算法作为对比基线模型,可以看出,相较于YOLOv4算法在COCO数据集上目标检测的精度,本文中加入ReFPN的模型平均精度AP提高了1.1%,小目标平均精度AP提高了2.4%;加入Co-AM的模型平均精度AP提高了1.4%,小目标平均精度AP提高了1.8%;综合改进后的模型平均精度AP提高了1.9%,小目标平均精度AP提高了3.3%。结果表明,本文提出的方法有效提取了小目标的特征信息,提高了YOLOv4算法的目标检测精度,尤其对小目标的检测效果提升明显。
为了便于比较各算法性能指标,表3列出了最新小目标检测算法中的Bi-SSD[18]、FIENet[19]、CPNet[20]和IENet[21]在MS COCO数据集上的具体检测结果。综合表中各精度数据来看,在MS COCO数据集的目标检测中,除本文算法模型外,IENet算法模型的性能表现最优,其次是CPNet,然后是FIENet和Bi-SSD。本文算法精度均优于其他算法。从平均精度方面来看,本文算法的AP值相比于其他算法有所提升,达到51.5%;中等尺寸和大尺寸目标的平均检测精度AP和AP分别都有提升,說明本文算法在提升小目标的检测精度的同时没有损失其他目标的检测精度;小尺寸目标的平均检测精度AP提升较大,达到35.4%,整体检测效果均优于其他算法,说明本文算法在COCO数据集上具有更好的目标检测能力。
4結论
YOLOv4算法在通用数据集中对小目标的检测不够理想,根据小目标分辨率低、携带信息少、容易受到背景因素影响等特点,本文提出一种基于反馈的特征融合网络ReFPN,利用ASPP作为反馈连接提升整合多尺度信息的能力,两次利用骨干网络提取的原始特征信息加强小目标特征信息,对其进行更精确的位置回归。同时提出混合注意力机制Co-AM来充分提取小目标的细节特征信息,强化低层特征图中的有效特征信息,抑制无效特征,进一步提高小目标的检测精度。实验结果表明,改进的YOLOv4模型在MS COCO数据集上对目标的检测平均精度AP提高了1.9%,小目标平均精度AP提高了3.3%,证明了本文提出的方法可以有效提升小目标的检测效果。与其他最新小目标检测算法相比,该算法达到了较好的检测性能,但仍有提升空间,下一步将参考本文方法尝试寻找构建最优的网络模型用于图像及视频中的小目标检测,获得进一步性能的提升。
参 考 文 献:
[1]丁博,王水凡. 基于混合预测模型的交通标志识别方法[J].哈尔滨理工大学学报,2019,24(5) :108.DING Bo, WANG Shuifan. Traffic Signs Identification Based on Mixed Forecasting Model[J]. Journal of Harbin University of Science and Technology,2019,24 (5): 108.
[2]WU X, SAHOO D, HOI S C H. Recent Advances in Deep Learning for ObjectDetection[J]. Neurocomputing, 2020, 396: 39.
[3]LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based Learning Applied to Document Recognition[J]. Proceedings of the IEEE,1998,86(11):2278.
[4]刘忠伟,戚大伟.基于卷积神经网络的树种识别研究[J].森林工程,2020,(1):33.LIU Zhongwei, QI Dawei. Study on Tree Spiecies Identification Based on Convolution Neural Network[J]. Forest Engineering,2020,36(1): 33.
[5]REN S, HE K, GIRSHICK R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137.
[6]LIU W,ANGUELOV D,ERHAN D,et al.SSD: Single Shot Multibox Detector[C]//European Conference on Computer Vision.2016: 21.
[7]REDMON J, DIVVALA S, GIRSHICK R, et al. You Only Look Once: Unified, Real-time Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779.
[8]REDMON J, FARHADI A. Yolov3: An Incremental Improvement[J]. arXiv preprint arXiv:1804.02767, 2018.
[9]BOCHKOVSKIY A, WANG C Y, LIAO H Y M. Yolov4: Optimal Speed and Accuracy of Object Detection[J]. arXiv preprint arXiv:2004.10934, 2020.
[10]LIN T Y, DOLLR P,GIRSHICK R, et al. Feature Pyramid Networks for Object Detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 2117.
[11]QIAO S, CHEN L C, YUILLE A. DetectoRS: Detecting Objects with Recursive Feature Pyramid and Switchable Atrous Convolution[J]. arXiv, 2020.
[12]SANTORO A, FAULKNER R, RAPOSO D, et al.Relational Recurrent Neural Networks[J]. arXiv preprint arXiv: 1806.01822, 2018.
[13]WOO S, PARK J, LEE J Y, et al. Cbam: Convolutional Block Attention Module[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 3.
[14]徐诚极,王晓峰,杨亚东. Attention-YOLO:引入注意力机制的YOLO检测算法[J].计算机工程与应用,2019,55 (6):13.XU Chengji, WANG Xiaofeng, YANG Yadong.Attention-YOLO:YOLO Detection Algorithm that Introduces Attention Mechanism[J]. Computer Engineering and Applications, 2019, 55(6) :13.
[15]刘芳,韩笑.基于多尺度深度学习的自适应航拍目标检测[J].航空学报, 2022, 43(2):325270.LIU Fang, HAN Xiao. Adaptive Aerial Object Detection Based on Multi-scale Deep Learning[J]. Acta Aeronautica et Astronautica Sinica, 2022,43(2):325270.
[16]LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO : CommonObjects in Context[C]// European Conference on Computer Vision. Springer International Publishing, 2014.
[17]梁华,宋玉龙,钱锋,等.基于深度学习的航空对地小目标检测[J].液晶与显示,2018,33(9):793.LIANG Hua, SONG Yulong, QIAN Feng, et al. Aeronautical Small Target Detection to Ground Based on Deep Learning[J]. LCD and Display, 2018,33(9) : 793.
[18]汪能,胡君红,刘瑞康,等.基于 Bi-SSD 的小目标检测算法[J].计算机系统应用,2020,29(11):139.WANG Neng, HU Junhong, LIU Ruikang, et al. Small Target Detection Algorithm Based on Bi-SSD[J]. Computer Systems & Applications,2020,29(11):139.
[19]劉建政,梁鸿,崔学荣,等.融入特征融合与特征增强的SSD目标检测[J/OL].计算机工程与应用:1 [2021-03-12].LIU Jianzheng, LIANG Hong, CUI Xuerong, et al. SSD Visual Target Detector Based on Feature Integration and Feature Enhancement[J/OL]. Computer Engineering and Applications, 1[2021-03-12].
[20]DUAN K, XIE L, QI H, et al. Corner Proposal Network for Anchor-free, Two-stage Object Detection[J]. arXiv preprint arXiv:2007.13816, 2020.
[21]LENG J X, REN Y H, JIANG W, et al.Realize your Surroundings: Exploiting Context Information for Small Object Detection[J]. Neurocomputing,2021,433:287.
(编辑:温泽宇)
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
