
数据驱动下的综合能源系统短期多元负荷预测
2022-05-23 07:25王愈轩刘尔佳黄永章
计算机工程与设计 2022年5期
王愈轩,刘尔佳,黄永章
(华北电力大学 电气与电子工程学院,北京 102206)
0 引 言
综合能源系统(integrated energy system,IES)通过能源协调管理,在满足系统多元化用能需求的同时提升了能源利用效率[1,2]。随着IES深入发展,系统在源、网、荷各环节的能量耦合关系加深,加之新型负荷的不确定性因素影响系统稳定运行[3,4]。因此,在考虑能量耦合及多元负荷的背景下,如何实时、准确、可靠地实现多元负荷预测成为当前重要的研究课题。
针对上述问题,目前已有不少国内外学者开展了相关研究。文献[5,6]针对区域级IES负荷预测问题,分别基于深度结构多任务学习和改进的熵值法,构建了短期电、气、冷、热负荷预测模型。文献[7]利用灰色关联理论对环境因素输入属性进行主控因素关联度分析,建立了多元负荷的特征聚类预测模型。文献[8,9]基于小波包分解与循环神经网络算法,建立电冷热综合能源系统短期负荷预测模型。上述文献均为IES单一负荷预测模型,为进一步提高预测精度,组合预测被广泛应用于负荷预测问题当中。文献[10]采用BiLSTM神经网络和MLR方法组合构建了超短期电力负荷预测模型。文献[11]基于长短时记忆网络(long short-term memory,LSTM)、极端梯度提升(extreme gradient boosting,XGboost)模型组合构建了短期电力负荷预测模型。组合预测常见的权重分配方法有算术平均法、误差倒数法、均方差导数法、Shapley值法等[12]。
综上所述,现有研究未考虑IES多元负荷之间耦合相关性问题,难以满足实际园区综合能源系统多元负荷预测需求[13,14]。为解决上述问题,本文提出了数据驱动下的综合能源系统短期多元负荷预测方法。
1 IES多能耦合互补特点
近年来,随着综合能源的不断发展,园区综合能源示范工程在全国范围逐步加大推广,其典型能源结构如图1所示。园区内开展多能互补、源网荷协同的用能方式、应用综合能源智慧化服务管理体系[15],能有效保障安全供能的前提下园区的综合能源利用效率。
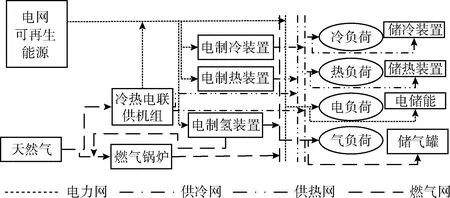
图1 园区综合能源系统
从图1可以看出,一方面,园区用能系统结构复杂,耦合环节较多,如冷热电联供(CCHP)机组既能发电也能同时供冷、热,储能装置既能在发电高峰存储部分电能,又能在用电高峰释放电能,冷热电气负荷供能方式多元,这为园区开展多能互补提供可能。另外一方面,园区能源供应侧电源能量特性不一样,电力网传输速度接近于光速,显然在供应速度上电能要快于供冷、供热、供气网,这是由冷、热、气因其固有的能源传输特性决定,具有较大的延时性。
园区能源互补特性明显,大大增加了用户用能的灵活性,同时也增加了负荷预测的难度,多元负荷预测除了和用户需求有关,还受天气温度、季节的影响。能源耦合使得负荷之间存在着复杂的非线性关系,本文采用最大信息系数(maximal information coefficient,MIC)[16]来判断冷、热、电、气负荷、温度之间的非线性关系,该方法能有效得出特征之间的非线性关系,详细计算过程见3.2小节。
2 LSTM-XGboost组合预测模型
组合预测方法被广泛应用于各类预测问题当中,本文基于LSTM、XGboost构建组合预测模型,该模型主要包括LSTM预测模型、XGboost预测模型、组合模型方法。
2.1 LSTM预测模型
LSTM被广泛应用于时序预测问题当中,LSTM的预测模型有3个门,分别是遗忘门、输出门和输入门[17],其原理结构图如图2所示。遗忘门控制信息保留,输入门控制信息输入,输出门控制信息输出。LSTM深度学习网络训练过程如下
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
ot=σ(Wo·[ht-1,xt]+bf)
(3)
ct=ftct-1+ittanh(Wo·[ht-1,xt]+bc)
(4)
ht=ottanh(ct)
(5)
式中:σ为激活函数;ft为遗忘门输出,it为输入门的输出,ot为输出门输出,ct为当前时刻神经单元状态,ht为t时间步下的LSTM记忆单元的输出;Wf为遗忘门权重矩阵,Wi为隐藏输入门权重矩阵,Wo为单元到输出门权重矩阵,bi为输入门参数矩阵;xt为当前t时间步的输入,bf为当前隐藏层遗忘门的偏差值,bi为当前隐藏层输入门的偏差值,bc为当前隐藏层记忆单元的偏差值。

图2 LSTM模型原理
总的来说,LSTM模型通过控制3个门,从而在每一个时间步下对记忆单元进行修改,即在每个时间步下决定保留多少上个时间步的状态信息,以及将多少的状态信息继续往下一时间步传输,从而得到较为准确的预测结果。
2.2 XGboost预测模型
XGboost是经过优化的分布式集成模型,其内部决策树使用的是梯度提升树。模型通过不断添加树,不断地进行特征分裂添加新的树,去拟合上次预测的残差。预测结果是每棵树的预测结果的累加和[18]。假设存在M棵决策树,其模型输出的预测结果为
(6)
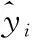
定义XGboost的目标函数
(7)
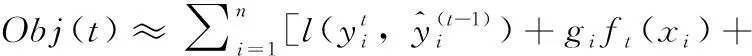
(8)
树模型的复杂度Ω(ft) 计算公式如下
(9)
其中,T表示叶子节点数,ωj表示第j个叶子节点的权重。
将式(8)代入式(9),目标函数转化为
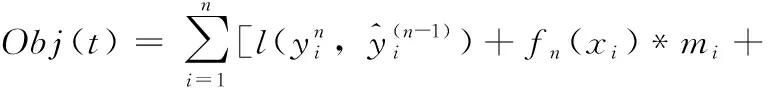
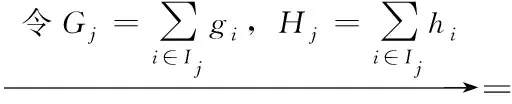
(10)
由式(10)可知,目标函数为一元二次函数,对ωj求导等于0,可以得到ωj最优值
(11)
将其代入目标函数得到最优目标函数值
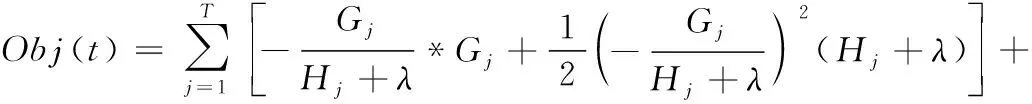
(12)
由式(11)、式(12)可以看出,预测模型在迭代过程中,通过不断计算节点损失值,得到ωj和目标函数的最佳值,选择增益损失最大的叶子节点,进而得到最优预测模型。
2.3 组合模型方法
采用误差倒数法对LSTM、XGboost模型预测结果进行加权组合,δt为组合预测误差。其中,λ1t、λ2t分别为LSTM和XGBoost预测值,ε1,ε2分别为的LSTM和SXGBoost的预测误差
(13)
由式可知,组合方法是将较大权值赋予给预测误差小的模型,从而使得整体预测误差趋于变小,进而提升模型的预测精度。
3 数据驱动下的多元负荷预测流程
本文主要基于LSTM-XGboost构建多元负荷短期预测模型,其预测流程如图3所示。其中LSTM、XGboost及组合模型构建过程已在上节说明,在此不再赘述,本节重点介绍其它步骤的研究内容。
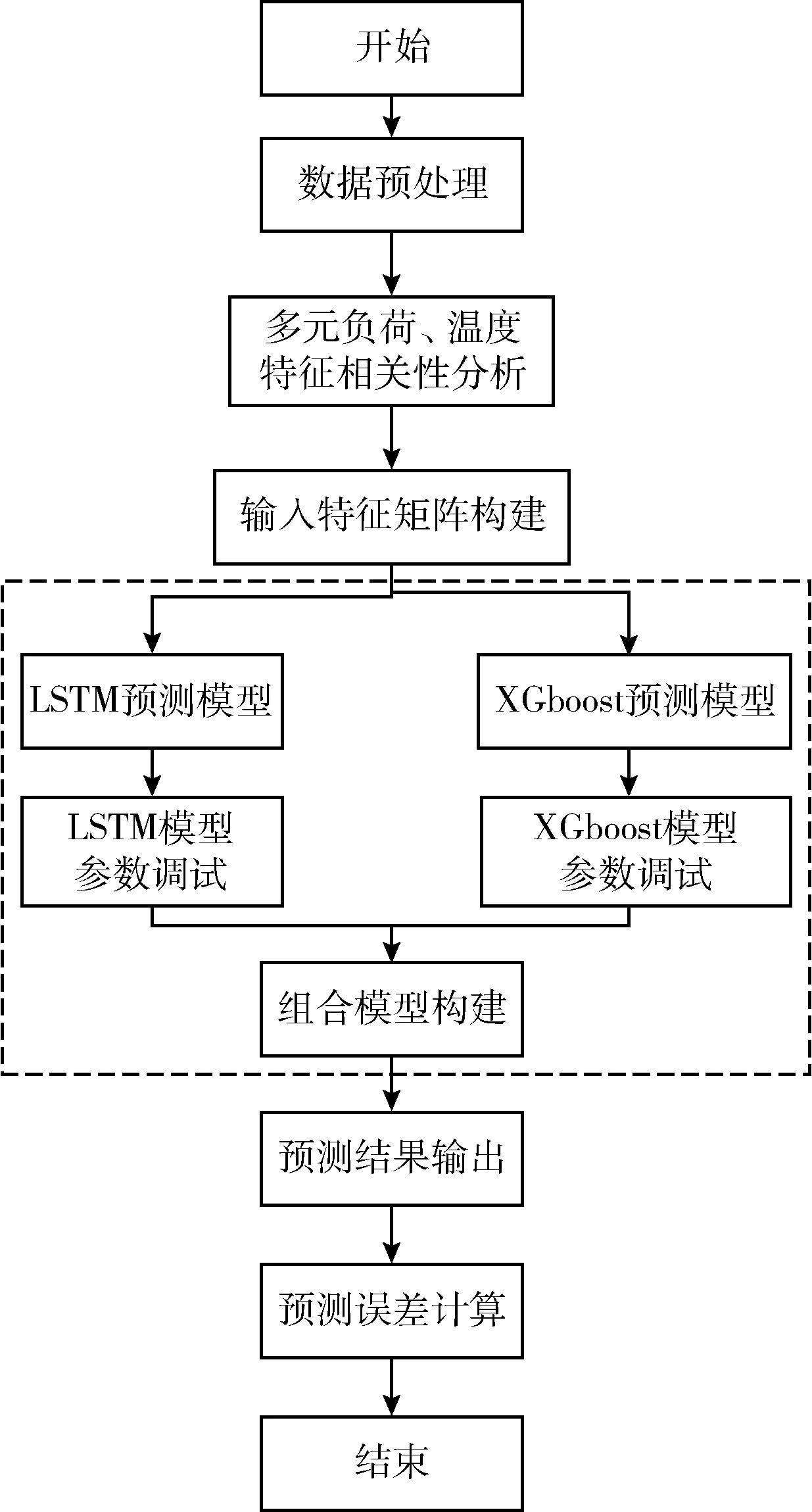
图3 多元负荷预测流程
3.1 数据预处理
数据预处理通常是指对多元负荷数据进行坏数据剔除和数据归一化处理。园区负荷数据采集设备可能因外在不良因素在采集过程中出现一些坏数据。需在模型训练测试前进行剔除,否则影响负荷预测精度。多元负荷数据特征在由于单位量纲不一,需进行标准化处理将特征数据值映射到0~1之间。
(1)坏数据主要包括数据缺失、数据极值、数据毛刺。数据缺失:某时刻的数据由于故障未能记录下来。
(2)数据极值:数据值超过了设定的最大最小阈值,或者数据的波峰波谷值超过了相邻几日对应的波峰波谷值。
(3)数据毛刺:数据值得突增突降超过了一定的阈值。
本文采用分别从横向与纵向对坏数据进行自动识别。
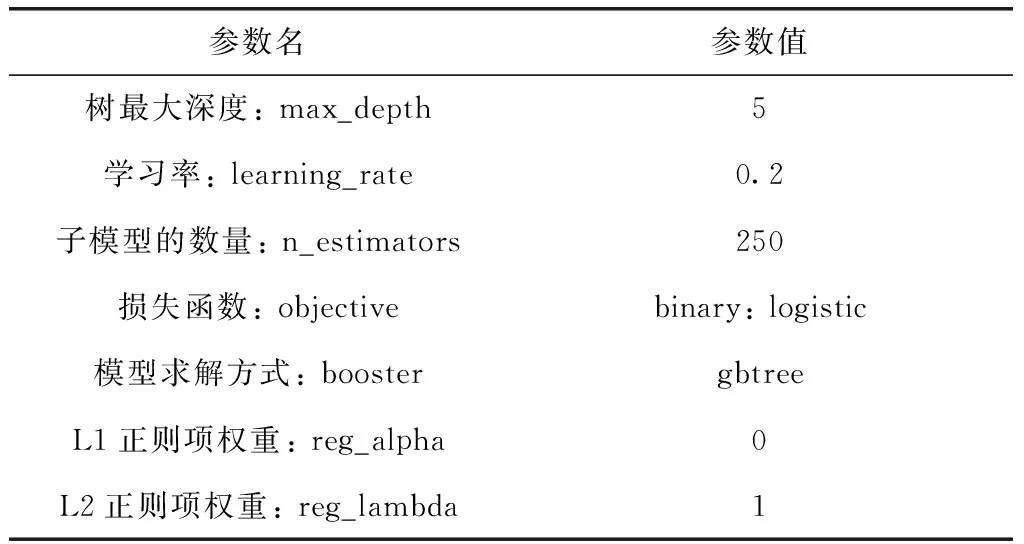
横向识别:假设样本某一时刻的数据与相邻时刻的数据相似,若两者的数据差值过大则认为是坏数据
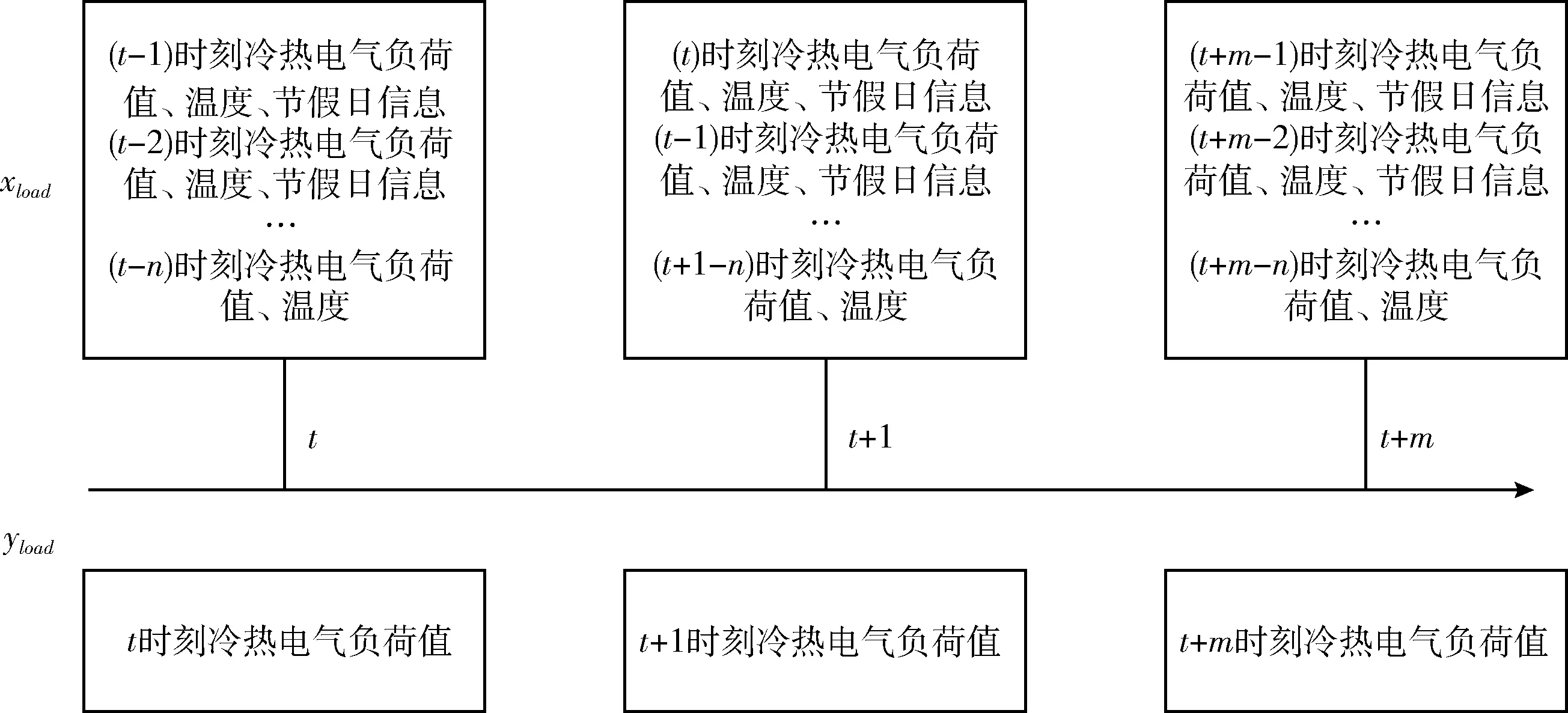
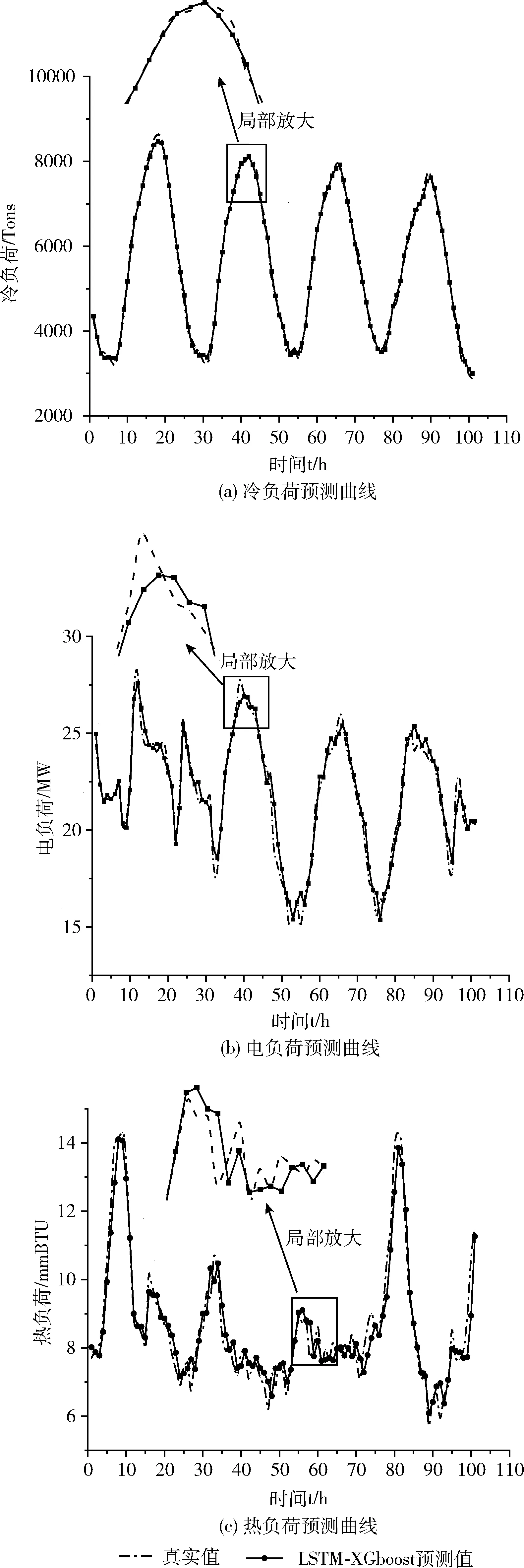
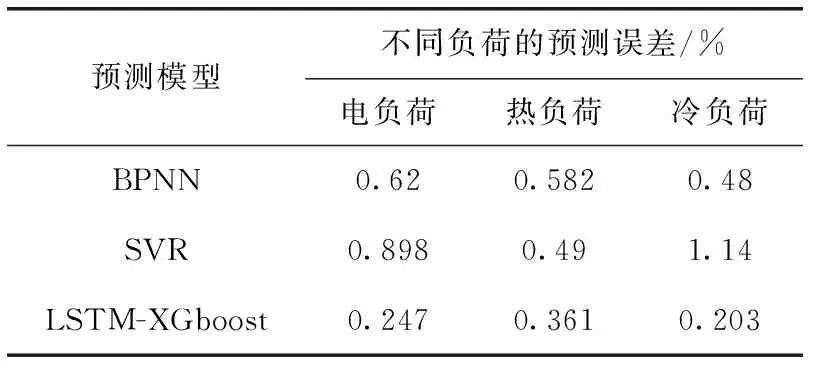
max(|xn,t-xn,t+1|,|xn,t-xn,t-1|) (14) 式中:xn,t为第n天t时刻的负荷数据,a(t) 为t时刻的横向误差阈值函数。若在n天t时刻的数据值不满足式(14),则被认定为坏数据。 纵向识别:时序数据具有一定的周期性,假设样本时刻的数据与附近相似日的同时刻的数据相似。先计算出所处每个时刻的序列均值与方差 (15) (16) (17) 识别出坏数据之后,计算坏数据所处时刻的前m个同类型日同时刻数据值的加权平均值来进行数据修正 (18) 式中:xn-m,t为前第m天t时刻的负荷数据,λm为权重系数,不同的xn-m,t对应不同的权重系数λm, 对xn,t的影响权重也不同,b为决定系数λm的平滑系数。 (19) 式中:z为原始数据集,z′为标准化之后的数据集,zmin、zmax分别为该类数据集的最小、最大值。 传统负荷预测主要为单一负荷预测(电负荷预测),综合能源园区冷热电气用能同时存在,此时多元负荷存在耦合,负荷之间的相关关系容易忽略,分析多元负荷之间的相关性有利于判断不同负荷之间的影响程度。本文采用最大信息系数(maximal information coefficient,MIC)[14]来判断冷、热、电、气负荷、温度之间的相关关系,该方法能有效得出特征之间的非线性关系。具体计算方法如下: 将变量x和y组合成一个平面上的二元数据集D∈R2, 记为D={(a1,b1),…,(an,bn)}, 其中n代表所选变量的样本大小。将D划分为i行j列的网格,记为Gi,j。 计算数据集D在Gi,j网格上的概率分布Dax,y以及最大互信息max{I(Gi,j)}, 再对其进行标准化便得到了最大信息标准化值micx,y (20) (21) 式中:p(x,y) 为变量x和y的联合概率,p(x),p(y) 分别为向量x和y的边缘概率。micx,y取值范围介于0,1之间,micx,y值越接近1,则两变量之间的相关性越强;micx,y值越接近0,则表示两变量之间的相关性越弱。 本文主要研究对象是综合能源系统短期多元负荷预测,短期负荷走势主要依赖近期的用能变化,因此在预测模型输入特征中着重看看前一周的数据变化特征。短期多元负荷预测特征矩阵为X=[num,steps,feature], 其中num代表步长内的样本数量,steps代表待预测时刻前一周的时间步长,feature代表所选取的综合能源系统需求侧冷、热、电、气负荷以及温度节假日特征。数据输入特征矩阵的构建方法如图4所示,t时刻的标签值由前n个时刻的特征值来映射,下个时刻特征-标签映射关系利用滑动窗口的方式向后推动一个时间步长获得 (22) 式中:xe、xc、xh、xt、xd分别代表电、冷、热负荷以及温度,节假日信息的数据值。ye、yc、yh分别代表电、热、冷负荷以标签数据。 图4 特征输入矩阵构建 将多元负荷数据集按比例划分成训练集、测试集。训练集的数据用于预测模型的训练,然后把训练之后的模型放到测试集的数据中进行测试,经过模型参数调试观测预测误差的变化,选择合适的参数得到较为精确的预测模型。 LSTM模型参数主要包括学习速率(learning_rate)、深度LSTM的层数、输入层数据长度与维度、各隐藏层的神经元个数(hidden layer units)、输出层序列长度与维度、批量大小(batch size)、迭代次数(epoch)等。 XGboost模型参数主要包括树最大深度(max_depth)、学习率、子模型的数量(n_estimators)、损失函数(objective)、模型求解方式(booster):L1正则项权重(reg_alpha)、L2正则项权重(reg_lambda)等。 本文采取平均绝对百分误差EMAPE来计算预测结果的误差,下文中的预测误差均按下式计算 (23) 本文选取美国某大学园区综合能源系统Campus Metabolism项目实际运行数据验证上述预测模型的有效性[19]。大学园区位于美国西南,天气较为炎热。原始数据来源于大学园区小时级的电、热、冷负荷时间序列,天气数据来源于weather underground气象网站[20]凤凰城天港国际机场观测点相应时间点的温度数据。计算平台配置为win10系统,Intel i7-10700@ 2.9 GHz,RAM 16 GB,采用Python语言编程实现LSTM-XGboost短期多元负荷预测。 首先,为确定LSTM预测模型的网络结构,设置不同隐藏层及其神经元个数观察模型训练误差与测试误差的大小,选取误差较小的网络结构,测试结果见表1。 从表1可知,取第一层隐藏层64个神经元,第二层32个神经元为预测效果最佳,此时,LSTM模型其它参数见表2。 同理,设置不同XGboost模型参数,通过搜索寻优观察模型训练、测试误差值的变化得到最优XGboost模型参数见表3。 采用3.2小节提出的MIC方法对多元负荷特征进行相 表1 不同LSTM网络结构下的预测结果 表2 LSTM模型参数 表3 XGboost预测模型参数 关性分析,得到该园区春夏秋冬四季冷、热、电、温度的相关关系,结果见表4。 从表4可知,夏季冷负荷和电负荷相关度较高,电制冷比例较大,冷负荷受温度影响较大。冬季热负荷和电负荷相关度较高,电制热用能增多,热负荷受温度影响较大,春秋两季各负荷相关度较小,负荷之间用能相对分散独立。 表4 春夏秋冬多元负荷相关性 由相关性分析可知,不同负荷之间存在一定的相关关系,因此在模型输入时,需要将多元负荷作为整体进行输入,冷热电负荷可作为单独输出。基于第3节所述的预测模型及预测流程,以100小时作为预测时长,分别得到冷、热、电短期负荷的预测曲线,各负荷预测结果如图5所示。 图5 冷、热、电多元负荷预测曲线 为验证深度LSTM-XGboost组合模型预测方法的优越性,本文选择BPNN神经网络模型、支持向量回归(SVR)模型与之进行对比。各模型的预测误差对比结果见表5。 从表5中可以看出,相较于BPNN神经网络、SVR两种单一预测模型,LSTM-XGboost组合模型的预测精度更高。传统BPNN神经网络缺乏对时序数据的记忆能力,在预测精度以及预测时间上没有优势。相较于传统BPNN神经网络模型,组合模型的冷、热、电负荷预测误差分别降低了60.16%、37.97%、57.7%;相较于SVR模型,冷、热、电负荷预测误差分别降低了72.49%、26.32%、82.19%。 为了验证多负荷预测相比于单负荷预测的优越性,检验负荷用能耦合特性对于预测精度的影响,采用相同的原始数据集以及神经网络结构,将多负荷整体特征输入与单负荷特征输入分别进行预测对比实验,预测误差结果见表6。 从表6可知,多元负荷预测精度明显高于单一负荷预 表5 各模型预测误差对比 表6 单一负荷输入与多元负荷输入EMSE预测误差对比 测,多元负荷预测相较于单一负荷预测包含更多的负荷之间相关性信息,输入特征信息的增多使得模型预测精度更高。因此,针对园区综合能源系统负荷预测问题,因其用能耦合特性,将多元负荷特征作为预测建模输入,更易于提高负荷预测精度。 本文针对园区综合能源系统多元负荷短期预测问题,考虑了园区用能耦合特性,采用MIC方法分析了多元负荷与温度的相关性。基于数据驱动理念,构建了LSTM-XGboost组合的多元负荷短期预测模型,结果表明: (1)本文提出的LSTM-XGboost组合预测模型具有更高的预测精度,相较于传统BPNN神经网络模型,组合模型的冷、热、电负荷预测误差分别降低了60.16%、37.97%、57.7%;相较于SVR模型,冷、热、电负荷预测误差分别降低了72.49%、26.32%、82.19%。 (2)LSTM-XGboost组合方法充分结合二者模型的预测优势,进一步提高了模型整体的预测精度。因此,组合模型适用于解决园区综合能源系统多元负荷预测问题。 (3)多元负荷预测精度明显高于单一负荷预测,这充分反映了多元负荷之间相关性对于预测精度的影响。因此,针对园区综合能源负荷预测问题,多元负荷特征输入有利于提高负荷预测精度。 未来随着电力市场的发展,园区内可能开展综合能源市场交易,能源交易价格对于多元负荷预测的影响是未来重点考虑的研究方向。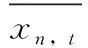
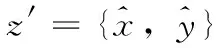
3.2 特征相关性分析方法
3.3 特征矩阵的构建
3.4 数据集划分
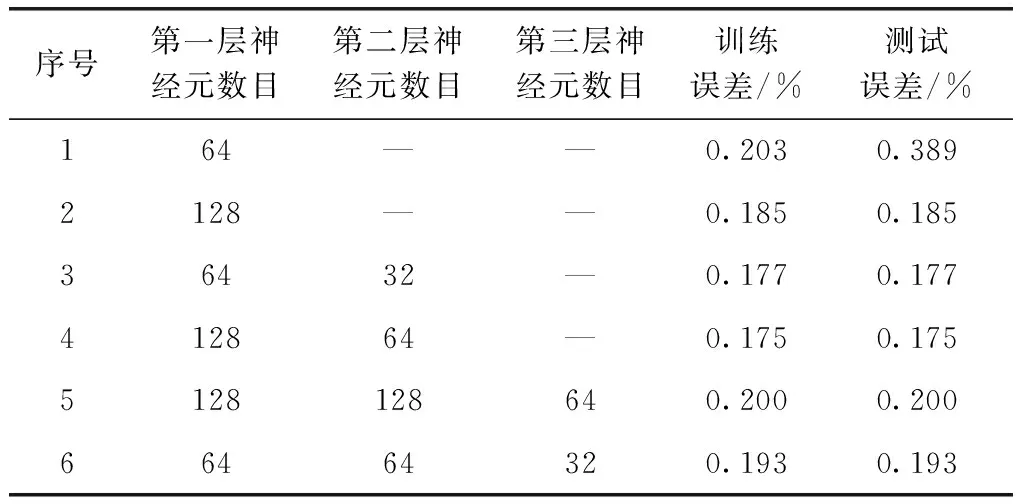
3.5 模型参数调试
3.6 预测误差分析
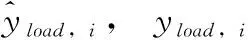
4 算例分析
4.1 数据源和计算平台
4.2 模型参数设置
4.3 结果分析


5 结束语
猜你喜欢
纺织标准与质量(2022年2期)2022-07-12
煤气与热力(2022年4期)2022-05-23
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
长江大学学报(自科版)(2021年6期)2021-02-16
华人时刊(2019年19期)2020-01-06
商周刊(2018年24期)2019-01-08
商周刊(2018年12期)2018-07-11
股市动态分析(2015年49期)2015-09-10
小学阅读指南·高年级版(2014年2期)2014-05-27
