
基于小波预测的超分辨率素描人脸合成方法
2022-05-23 07:25王鑫玮朱希安张本奎杜康宁郭亚男
计算机工程与设计 2022年5期
王鑫玮,朱希安,张本奎,杜康宁,郭亚男
(1.北京信息科技大学 光电测试技术及仪器教育部重点实验室,北京 100101; 2.北京信息科技大学 信息与通信工程学院,北京 100101; 3.中国科学院空天信息创新研究院 地理与赛博空间信息技术研究部,北京 100080)
0 引 言
素描人脸合成旨在根据输入的光学人脸图像合成一张素描人脸图像。在进行素描人脸合成时,若输入光学人脸图像分辨率较低、质量较差,合成图像的质量会显著降低。若能对输入的低分辨率光学图像在进行素描人脸合成的同时恢复其高频信息,则能显著提升素描人脸合成图像的质量。因此根据低分辨率光学图像合成高分辨率素描图像有着重要的实际意义。
目前的素描人脸合成算法在处理低分辨率图像方面的能力较差,在仅有低分辨率光学图像的条件下无法合成高质量素描图像。为了解决上述问题,本文提出了一种超分辨率素描人脸合成方法。具体地,在输入低分辨率光学人脸图像后,根据低分辨率图像特征预测高分辨率图像的小波包分解系数,通过该系数重建一张高分辨率光学人脸图像,并通过重建图像合成相应的高分辨率素描人脸图像。实验结果表明,本文方法合成的素描图像的质量较高,合成图像的噪声较少,合成高质量图像的能力更强。
1 相关工作
目前最先进的素描人脸合成算法大体可分为两类:基于数据驱动的素描人脸合成方法和基于模型驱动的素描人脸合成方法。基于数据驱动的方法首先从训练的光学图像块中搜索相似的候选块,并通过对候选块进行线性组合重构目标光学图像,再通过同样的方式组合对应的素描块获得最终的素描图像。基于数据驱动的素描人脸合成方法可分为贝叶斯推理、稀疏表示和子空间学习等方法。
基于贝叶斯推理的方法使用概率图形模型对候选图像进行融合。Zhang等[1]提出了一种鲁棒的素描人脸合成网络,该网络能通过一个素描模板合成任意风格的素描人脸图像。然而,由于融合时去除黑色区域的能力有限,当输入光学人脸图像存在多余的阴影时,输出图像会产生多余的伪影。在稀疏表示领域[2],Zhang等[3,4]提出了基于稀疏表示素描人脸合成方法,该方法的特点是在搜索过程中用稀疏系数代替照片块的像素值。然而,由于缺少局部约束,合成的素描人脸图像往往会丢失部分信息。基于子空间学习的方法[5]侧重于候选图像融合。Zhang等[6]提出了一种基于低秩表示(DLLRR)的方法,该方法通过挖掘潜在的素描信息,能在训练数据较少时稳定地恢复图像基本结构。然而,当输入光学人脸图像存在多余的阴影时,输出图像也会产生多余的伪影。
基于模型驱动的方法学习光学人脸图像和素描人脸图像之间的映射关系,并使用学习到的映射将光学人脸图像转换为素描人脸图像。在基于模型驱动的方法中,基于深度学习的相关算法研究最为广泛。Gatys等[7]提出了一种素描生成器,能生成特定风格的素描图像,但是网络容易丢失细节信息。Zhang等[8]提出了一种具有生成损失的全卷积网络。由于神经网络的结构过于简单,当输入图像的光照条件较差时,输出图像包含了大量的噪声。具有生成器和判别器的生成对抗网络[9]能在进行素描合成时减少部分输出图像的噪声,但是当训练图像和测试图像的光照条件相差较大时,输出图像的面部会产生扭曲。Zhu等[9]提出了一种CycleGAN,在光学图像与素描图像不配对的情况下实现素描合成。Wang等[10]将多对抗性网络引入了CycleGAN合成素描图像,称为PS2MAN。由于基于条件生成对抗网络(cGAN)在素描人脸合成任务中的出色表现,许多研究人员对cGAN进行了进一步的研究。例如,Zhang等[11]提出一种基于多领域对抗性学习的素描人脸合成方法。该方法没有建立光学域和素描域之间的映射关系,而是利用cGAN来学习光学域和素描域的内在联系。Zhu等[12]通过将协同损失与cGAN结合提出了协同cGAN(Col-cGAN)。Zhang等[13]将cGAN引入双传输框架,将高频信息从光学域传输到素描域。
单幅图像超分辨率重建技术主要分为3类:第一类是基于差值的方法,该类方法由于操作简单、速度快的特点被广泛应用于图像处理领域。但是,简单的插值规则会使重建图像出现不同层次的锯齿效应,导致重建质量较差。第二类是基于重建的方法,该类方法虽然可以重建相对清晰的图像,但存在计算量大、高频细节易丢失等问题。第三类是基于学习的方法,基于学习的图像超分辨率算法通过研究低分辨率图像与对应高分辨率图像间的映射关系对输入图像进行超分辨率重建。Dong C等[14]通过一个卷积网络直接学习低分辨率图像与对应的高分辨率图像之间的映射,根据学习到的映射实现图像的超分辨率重建。目前基于深度学习的超分辨率重建算法性能已有较大提升,Kim J等[15]参照VGG网络提出了VDSR算法,网络层数达到了20层。DRRN[16]在超分辨率算法中引入RNN[17],由于其网络层共享参数,网络深度进一步增加到52层。Tong T等结合DenseNet[18]的网络结构提出了64层的SRDenseNet[19]。Lim B等[20]提出增强型网络EDSR,网络层数达到65层。RDN算法[21]通过将ResNet[22]和DenseNet结合到一起,提出了一个网络深度为149层的网络,大大改善了网络的性能。对于超分辨率问题,已经有许多基于小波的方法被提出[23-25]。在单幅图像的超分辨率重建方面,Gao等[26]提出了一种混合小波卷积网络,他们使用小波来提供一组稀疏编码[27]和一个用于稀疏编码的卷积网络,Mallat等[28]的研究表明使用小波变换来分离数据在不同尺度下的变化能保证数据的线性化和可分离性。
2 本文方法
2.1 整体网络架构
本文提出了一种端到端的超分辨率素描人脸合成网络,整体网络架构如图1所示。整个网络结构由4个模块组成,其中嵌入模块提取输入图像的特征,小波预测模块根据提取特征预测输入图像对应的高分辨率图像的小波包分解系数,重建模块将预测得到的小波包分解系数重建为高分辨率图像,最终通过素描合成模块得到最终输出的高分辨率素描人脸图像。
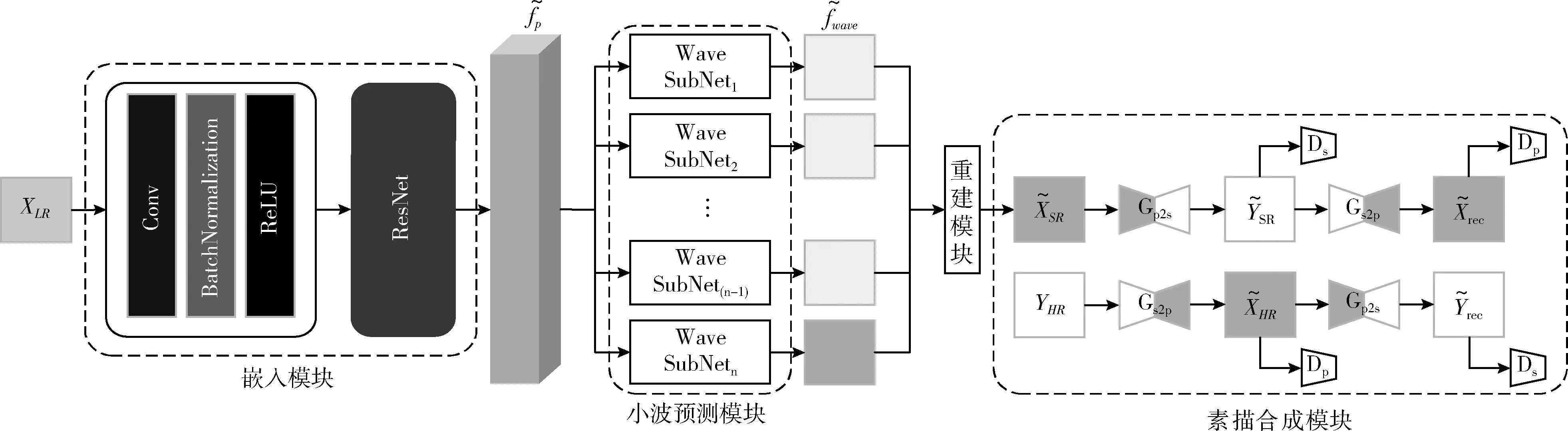
图1 网络结构
2.2 网络结构
2.2.1 嵌入模块
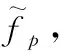
2.2.2 小波预测模块
由于小波变换[30]在处理多分辨率图像的高度直观性和高效性,本文选择在小波域对图像进行处理。本文方法使用Haar小波包变换[30,31],在计算复杂度最低时充分描述不同频率的面部信息。
在小波包分解等级为n(放大倍数为2n)的条件下,可以将小波预测模块分为多个独立的小波预测子模块。每个子模块将嵌入模块的输出的特征作为输入,生成相应的小波系数。与嵌入模块相同,所有卷积层的卷积核大小为3×3,stride为1,pad为1,因此预测出的每个小波系数都与输入大小相同。另外,由于Haar小波变换系数之间的高度独立性,使得信息不允许在每两个子模块之间流动,使得模块具有可扩展性。预测模块中子模块数目的不同,对应实现不同超分尺度的放大。例如,Nw=4和Nw=16分别表示放大2倍和4倍。
在该模块中采用小波损失对网络进行优化。小波损失包括小波预测损失和纹理损失。
小波预测损失定义如式(1)所示

(1)
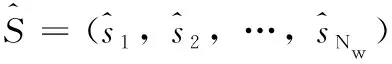
纹理损失定义如式(2)所示
(2)
该损失应用于原始光学小波包分解系数和预测光学小波包分解系数的高频系数之间,用来保证高频小波系数不随训练衰减到0,从而防止纹理细节信息的丢失。其中γi是平衡权重,用于平衡纹理损失对不同等级小波包分解系数的影响。α和ε为松驰因子,用于控制纹理损失的大小。在实验中,参数设置为γi=1,α=1.2和ε=0。
2.2.3 重建模块
重建模块能根据预测网络的输入得到最终重建的高分辨率光学人脸图像。它包括一个卷积核大小为2n×2n,stride为2n的反卷积层(r为放大倍数),虽然反卷积层的大小取决于放大倍数2n,但它可以通过恒定的小波重构矩阵进行初始化,并在训练中固定。因此,它对整个网络的可扩展性没有影响。
2.2.4 素描合成模块
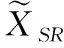
在训练过程中使用素描合成损失对网络进行约束。素描合成损失包括对抗损失和循环一致性损失。对抗损失定义如式(3)、式(4)所示
lGp2s=Ey~Pdata(y)[logDs(y)]+Ex~Pdata(x)[log(1-Ds(Gp2s(x)))]
(3)
lGs2p=Ex~Pdata(x)[logDp(x)]+Ey~Pdata(y)[log(1-Ds(Gs2p(y)))]
(4)
其中,x和y分别为原始光学图像和原始素描图像,Gp2s(·)和Gs2p(·)分别表示素描生成器和光学生成器,Dp(·)和Ds(·)分别表示光学判别器和素描生成器。对抗损失应用在光学图像映射为素描图像的过程,本文采用的对抗损失为原始的交叉熵损失。由于仅使用对抗损失会使生成网络中存在多余映射问题,从而导致生成数据的稳定性降低。为了减少其它多余映射关系,提高重建图像与输入图像之间的匹配程度,因此引入循环一致性损失。
循环一致性损失定义如式(5)所示
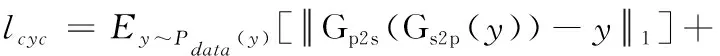
(5)
素描合成损失最终定义如式(6)所示
lfeature=lGp2s+lGs2p+σlcyc
(6)
σ为循环一致性损失权重,用于控制生成图像的结构一致性。
合成完成后,在输出素描图像和原始素描图像间引入图像MSE损失,用以平衡重建图像的平滑与锐化程度,提高生成图像的质量。
图像MSE损失定义如式(7)所示
(7)
2.3 损失函数
综上,总损失函数定义为如式(8)所示
ltotal=lwavelet+μltexture+υlfeature+ρlfull-image
(8)
其中,μ、υ、ρ为控制相关损失项重要性的权重参数。
3 实 验
3.1 数据集
由于本文方法用于实现高分辨率的素描合成,因此本文采用经典素描人脸数据集CUHK学生数据集来评估本文方法的性能。
CUHK学生数据集由香港中文大学(CUHK)学生数据库的188张面孔的光学素描图像对构成,包含134名男性和56名女性。其中88对图像作为训练集,剩余的100对图像作为测试集。
3.2 实验设置
本网络采用端到端的训练方式,数据集原始图像大小为256×256,训练时根据超分倍数分别获取其对应等级的小波包分解低频分量和双三次差值下采样图像作为输入进行联合训练。该训练方式可以提高网络应对不同下采样方法得到的低分辨率图像的鲁棒性。设置迭代周期为500,初始学习率为0.0002,从第100个周期开始线性衰减,到最后一个周期衰减到0。采用参数设置为beta1=0.5,beta2=0.999的Adam优化器更新网络参数。在网络初始化方面,卷积层权重采用正态分布随机初始化,bias初始化为0。训练时,网络批处理大小设置为1。为了客观评价生成图像的质量,本文采用图像质量评价标准结构相似性(structural similarity index,SSIM)和峰值信噪比(peak signal to noise ratio,PSNR)对图像整体进行质量评估。PSNR用于评价生成图像着色的真实程度,其值越大,表示失真越少;SSIM用于衡量目标间结构的相似程度,SSIM测量值越大,表示两张图像相似度越高。
3.3 实验结果与分析
3.3.1 消融实验
为了验证本文方法各个模块在超分辨率素描人脸图像合成的有效性,在CUHK学生数据集进行消融实验。首先,使用Bicubic对低分辨率素描人脸图像进行放大,然后通过CycleGAN网络对放大的低分辨率光学人脸图像进行素描合成得到素描人脸图像;其次,在非端到端的框架下,先使用小波超分网络对输入低分辨率光学人脸图像进行超分辨率重建,再使用CycleGAN网络对超分辨率重建结果进行素描合成。
在进行实验结果对比时,首先对比小波超分网络+CycleGAN和Bicubic+CycleGAN的实验结果,验证在素描合成过程中引入超分辨率重建网络是否能够提升素描合成图像的质量。其次,对比本文方法与小波超分网络+CycleGAN的实验结果,验证端到端条件下进行超分辨率素描合成能否进一步改善素描合成图像的效果。
图2表示超分倍数为4时高分辨率素描人脸图像的消融实验结果,其中图2(a)为输入光学图像,图2(b)为Bicubic+CycleGAN结果,图2(c)为小波超分网络+CycleGAN结果,图2(d)为本文方法结果,图2(e)为原始素描图像。图2结果表示,图2(b)、图2(c)方法输出结果的视觉效果较为杂乱,边界整体较为模糊,部分五官细节信息丢失,眼睛和嘴部等结构信息也存在一定扭曲,图像面部和背景区域相较图2(e)生成了过多阴影。因此,仅通过素描合成网络或通过非端到端的方法合成的高分辨率素描人脸图像质量较差。而图2(d)方法输出结果边界清晰,细节完整,面部结构信息与原始素描较为相似,整体质量较高。

图2 超分倍数为4时消融实验结果对比
此外,通过计算图像的峰值信噪比(PSNR)和结构相似度(SSIM)对消融实验结果进行了定量分析,结果见表1。表1结果表明,仅引入超分辨率重建网络在非端到端条件下合成素描图像虽然可以提升合成图像的质量,但提升效果有限。而本文方法提升合成图像质量的效果较好,验证了本文方法的有效性。

表1 消融实验性能指标
3.3.2 对比实验
为了进一步验证本文方法的高分辨率素描合成效果,本文使用CUHK学生数据集在超分倍数为2和4时的条件下进行了两组对比实验。首先,超分辨率对比实验使用不同超分网络对低分辨率光学人脸图像进行超分辨率重建,然后通过CycleGAN网络对重建的低分辨率光学人脸图像进行素描合成得到对比实验结果;其次,素描合成对比实验使用小波超分网络对低分辨率光学人脸图像进行超分辨率重建,然后使用不同素描合成网络进行素描合成得到对比实验结果。对比实验过程中,除本文方法外,均在非端对端框架下,使用经现有超分辨率重建方法重建后的高分辨率光学图像作为输入图像,使用素描合成网络进行素描合成得到最终的对比图像。对比实验用以验证不同超分辨率重建网络和不同素描合成网络在非端到端时参与高分辨率素描人脸图像合成的效果。
超分辨率对比实验结果如图3和图4所示。图3为超分倍数为2时不同超分辨率重建网络合成图像,图4为超分倍数为4时不同超分辨率重建网络合成图像,图(a)为光学输入图像,图(b)为EDSR合成图像,图(c)为MetaSR合成图像,图(d)为RCAN合成图像,图(e)为RDN合成图像,图(f)为本文方法合成图像,图(g)为原始素描图像。在图3和图4结果中,由于图(b)~图(e)方法均是非端到端的,与消融实验类似,输出结果同样存在边界较为模糊,面部和背景区域存在较多的阴影和伪影,嘴部和眼睛等位置出现结构扭曲等问题。图(f)方法生成图像则较为清晰,细节与结构信息完整,整体视觉效果较好。

图3 超分倍数为2时不同超分辨率方法实验结果对比

图4 超分倍数为4时不同超分辨率方法实验结果对比
表2定量分析了超分辨率对比实验结果的峰值信噪比(PSNR)和结构相似度(SSIM),结果表明本文方法性能在多个超分倍数上优于其它超分辨率对比方法。
素描合成对比实验结果如图5和图6所示。图5为超分倍数为2时不同素描合成网络合成图像,图6为超分倍数
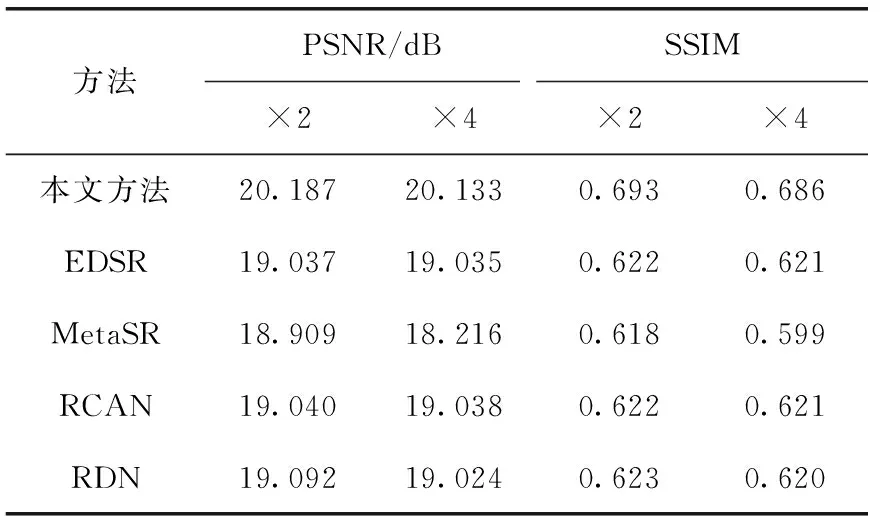
表2 超分辨率对比实验性能指标

图5 超分倍数为2时不同素描合成方法实验结果对比

图6 超分倍数为4时不同素描合成方法实验结果对比
为4时不同素描合成网络合成图像,图(a)为光学输入图像,图(b)为FSW合成图像,图(c)为MDAL合成图像,图(d)为PS2MAN合成图像,图(e)为本文方法合成图像,图(f)为原始素描图像。图5和图6结果显示,图(b)~图(d)方法生成的图像大多边缘模糊,且在背景和面部等信息量较少的位置存在伪影。图(b)方法合成的素描风格与原始素描不匹配,图(c)方法结果存在较多伪影,图(d)方法结果存在细节失真的问题,图(e)方法生成结构清晰,细节完整,对比其它方法整体质量较高。
表3定量分析了对比实验结果的峰值信噪比(PSNR)和结构相似度(SSIM),结果表明本文方法性能在多个超分倍数上优于其它素描合成对比方法。

表3 素描合成对比实验性能指标
此外,在对比实验中统计了对不同性能指标下不同方法合成图像的分布,统计结果如图7、图8所示。横轴代表性能指标大小,纵轴代表图像数量占比,曲线上点的纵坐标表示合成图像中性能指标(PSNR或SSIM)大于其横坐标数值的图像数量与总合成图像数量的比值。分布图表明,本文方法在不同超分倍数的条件下,合成的高质量图像数量占比高于其它对比方法,合成高质量图像的能力更强。
4 结束语
本文提出了一种超分辨率素描人脸合成方法,根据低分辨率光学人脸图像合成一张高分辨率素描人脸图像。该方法在素描合成网络中引入了超分辨率重建模块,通过预测高分辨率图像小波包分解系数的方式提高了图像的分辨率的功能。以端对端的方式统一训练多个模块,并使用小波预测损失、素描合成损失和图像MSE损失对网络进行整体约束,实验结果表明,本文方法较其它方法在主观视觉和客观量化等方面都取得了更好的评价,能够获得细节完整,轮廓清晰的高分辨率素描人脸图像。

图7 超分辨率对比实验图像分布

图8 素描合成对比实验图像分布
猜你喜欢
红外技术(2022年11期)2022-11-25
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
歌剧(2020年4期)2020-08-06
计算机应用(2020年7期)2020-08-06
雨露风(2020年8期)2020-04-26
动漫星空(2018年9期)2018-10-26
艺术科技(2018年2期)2018-07-23
时代英语·高一(2017年5期)2017-11-14
读者(2016年23期)2016-11-16
