
多源异构签到数据中改进RNN的POI推荐
2022-05-23 04:03杨立身
计算机工程与设计 2022年5期
高 丽,杨立身
(1.郑州经贸学院 计算机与人工智能学院,河南 郑州 451191; 2.河南理工大学 计算机科学与技术学院,河南 焦作 454003)
0 引 言
在基于位置的社交网络(location-based social networks,LBSNs)[1]中,兴趣点(point-of-interest,POI)推荐已逐渐成为推荐系统领域的活跃学术研究重点[2]。很多现有POI推荐方法主要考虑某一个或者某几个影响因素[3],很少综合考虑社交、顺序、地理、时间对POI推荐的影响,限制了POI取得更好的推荐效果。此外,日常生活中签到行为的稀疏性也在一定程度上制约了POI推荐精度[4]。
为了实现智能化、可扩展的多源异构信息,进行更加准确的POI推荐,基于多源异构签到数据,提出了一种利用改进型RNN的POI推荐方法。创新点总结如下:
(1)引入因子分解机对多源异构签到数据进行处理,有效降低了数据稀疏性带来的POI推荐不准确问题。
(2)提出了MMBE模型融合社交关系、顺序、时间、地理位置4种因素的矩阵,计算出多源异构数据的POI影响因子。
(3)将时间、顺序、地理位置、社交关系因子用于循环神经网络选定候选状态,避免了传统RNN对较远时间记忆能力的丧失,同时将其它影响POI推荐的重要因子也考虑进来,提高推荐POI的质量。
1 相关工作
本节从影响推荐的多源重要因素(社交关系、顺序、地理位置、时间)介绍相关的兴趣点POI推荐,同时介绍RNN算法。
1.1 考虑因素
文献[5]将用户相似性信息作为正则化项并入矩阵分解或张量模型中,取得了不错的POI推荐效果,同时也验证了社交关系对POI的影响。文献[6]将顺序对POI的推荐的影响考虑进来,提升了推荐效果。文献[7]将地理影响纳入加权的正规化MF模型中,取得了不错的POI推荐效果。文献[8]中首先提出了不均匀性,这种不均匀性表示用户的签到偏好随时间的变化,将时间因素考虑进来,也验证了时间对POI推荐的影响,提升了推荐效果。
综合上述研究可以看到,影响POI推荐的主要因素有社交、顺序、地理位置和时间。现有方法主要考虑上述两种或者3种因素进行融合以此进行兴趣点推荐。文献[9]融合社交关系和位置影响的地点推荐算法(location recommendation algorithm combined with social relationships and geographic influences,LRACWSRAGI)将社交关系和地理位置进行融合,推荐精度优于传统单一因素的推荐;文献[10]基于地理-社会-评论关系的典型化兴趣点推荐方法(geo-social-comment relationship-based typical point-of-inte-rest recommendation approach,GRTPRA),融合了地理位置、社会、评论关系信息,推荐多样性和准确率都有较大提高。文献[11]融合多因素的兴趣点协同推荐方法研究(study on point-of-interest collaborative recommendation method fusing multi-factors,SOPCRMFM),融合了地理位置、社交关系、情感等因素,准确率和召回率也都一定程度有所提高。所提方法主要与上述3种方法进行对比实验。
1.2 循环神经网络
循环神经网络是特意用来处理时序数据样本的一种神经网络,其主要的表现形式是记忆网络在签名时的信息,并用于当前所输出的计算中,也就是说隐藏层之间的节点是相互连接的,且隐藏层的输入中包含有输入层的输出以及上一时刻隐藏层的输出。
文献[12]通过存储时间信息,获得更长的信息,获得了较好的推荐准确度。文献[13]采用循环神经网络建模用户偏好和项目特征化的演化,提出了一种循环推荐网络来预测用户轨迹。取得了较好的预测效果。文献[14]用门控循环单元模型对时间和相关距离信息进行建模,提取用户兴趣特征偏好,对用户进行推荐,取得了较好的推荐效果。
可见,循环神经网络不仅能处理时间序列的样本,而且能融合其它影响因子,共同提升推荐精度。
1.3 本文工作与以前的研究之间的区别
使用更加异构的信息来构建智能POI推荐模型已经成为推荐系统领域的科学共识,尽管这使模型变得更加复杂。先前的大多数研究都利用上述一种或多种因素来构成它们的POI推荐模型。但是,它们缺乏对这些因素对用户签到行为的共同影响的综合分析,这可能是由于难以对异构信息进行建模以及难以以统一的方式发现跨异构工作流活动的多种类型的行为模式所致。此外,影响用户兴趣点的因素还存在稀疏性问题,RNN能够对签到的时间序列进行记忆,但是随着时间的变化,记忆会丧失。因此,使本文的工作与以往的大多数研究区别最大的地方在于利用因子分解机,缓解数据稀疏性对POI推荐的影响,提出了融合上述4个因素的统一框架即MMBE框架,学习了他们之间的内在联系,得到多源异构数据的影响因子。传统方法改进RNN网络,一般只考虑时序、距离以及上一个时刻候选状态对候选状态的影响,很少考虑到社会关系。本文通过MMBE模型,统一对上述4种因素建模,改进RNN(将得到的多源异构因素以及上一个时刻的候选状态,共同作用于候选状态的选定),所得推荐更加可靠。
2 问题描述
首先,表1列出了模型中使用的所有参数符号。
其次,将一些初步概念定义如下:
定义1 POI:POI是与地理位置相关的项,例如餐厅或电影院。
定义2 网络:网络G=(U,E) 被定义为基于位置的社交网络的拓扑结构,其中U是用户的集合,E是用户之间的关系的集合。
定义3 签到活动:签到活动是一个四元组 (u,v,lv,t), 表示用户u在时间t访问POIv。为了调查这项工作中嵌入在日常模式中的功能,将一天划分为多个时隙,这些时隙的持续时间以小时为单位。
定义4 用户文档:对于每个用户u,定义一个用户文档Du,该文档是与该用户关联的一组签到活动。
定义5 主题:对于Du中的每个签到活动,使用相应的主题z来建模用户的兴趣或偏好,该主题z是签到时间t。

表1 模型中使用的参数符号
定义6 区域:对于Du中的每个签到活动,均使用相应的区域r对用户的空间移动性模式进行建模,该区域r是POIs位置上的多项分布。
第三,对POI推荐问题影响因子进行了定义。
给定一组用户签到活动D和目标用户u(u∈U) 及其当前位置lu和时间tu,所提模型能够预测t时刻,用户u对兴趣点v(v|u,lu,tu) 的兴趣度p(v|u,lu,tu)v∈V)。 该因子能够反映社交、顺序、地理位置、时间协同对兴趣点的影响。
3 提出的POI推荐方法
为了模拟社会、顺序、地理和时间因素对用户签到行为的协同影响,针对POI推荐提出了一种多模态贝叶斯嵌入模型(MMBE)。
3.1 模型框架
图1显示了MMBE的图形表示,其中N、K和R分别表示用户、主题和区域的数量。MMBE的输入数据(即用户的签到记录,包括用户嵌入、POIs嵌入、签到时间和签到位置被设置为观察到的随机变量(请参见图1中的4个灰色圆圈)。在MMBE的图形表示中,方框是复制品的“板”。最大的板块表示用户文档,而最大的板块中的内部标牌表示文档中潜在变量(即z和r)和观察变量(即t,fv和lv)的重复选择。此外,外板代表Dirichlet分布或正伽玛分布的参数,如本节稍后部分所述。(模型参数的符号请参见表1)。
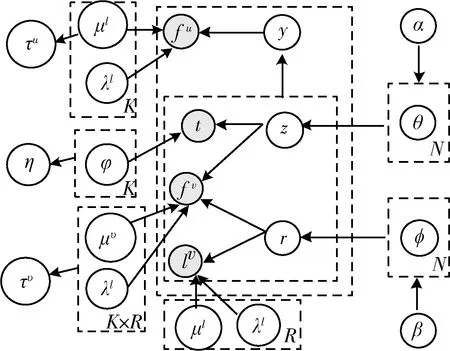
图1 MMBE模型
为了对社会因素和顺序因素进行建模,MMBE学习一个共享的潜在主题空间,以在两个不同的嵌入空间中生成基于网络的用户嵌入和基于序列的POI嵌入。更具体地说,在本文使用Skip-gram[15]模型和DeepWalk[16]分别学习编码顺序影响的基于序列的POI嵌入和编码社会影响的基于网络的用户嵌入。然后,MMBE将预先训练的用户嵌入和POI嵌入作为输入。
受早期用户兴趣和空间移动性建模的启发[17],假设用户的签到行为主要受其兴趣和空间移动性模式的影响。为了对地理影响和时间影响建模,MMBE定义了两种类型的潜在变量,即主题和区域,分别表征用户兴趣和空间移动性模式。更具体地来说,即用主题z和区域r共同定义主题变量(即POI主题z和用户主题y)和区域变量r,以形成与POIs上的分布相关联的联合潜在因子主题区域。它们负责同时生成用户的签到时间,连续的POI嵌入和POI位置。同时,用于生成基于网络的用户嵌入的潜在变量yu(用于用户u)是从Du中所有POIs主题中统一提取的。式(1)是用户u关于主题z和主题y在区域r的联合概率计算公式
(1)
式中:Mu表示Du中签到活动的数量, 1(·) 表示指标函数,s是拉普拉斯平滑的平滑参数。
在MMBE中,使用Dirichlet分布[18](由Dirichlet()表示)作为变量z、r和t的先验,这与LDA(潜在Dirichlet分布)中使用的多模态技术相似。对于用户嵌入和POIs嵌入,本文的模型扩展了高斯LDA以对多个模态进行建模,并通过使用先验的正态伽马分布(由NormalGamma()表示)在两个单独的空间中生成连续的嵌入。尽管有可能从多元高斯分布中提取嵌入量,但本文还是从单变量高斯分布中分别提取每个嵌入维数。该处理更实用且更具成本效益。根据LBCPSNs上的空间聚类现象,即用户最有可能访问仅限于某些特定地理区域的大量POIs,所有讨论的POIs在地理位置和签到密度方面都属于R区域。本文假设每个区域r的高斯分布和POIv的位置正态分布并用lv~N(μl,λl) 表示,其概率正态分布公式如式(2)所示
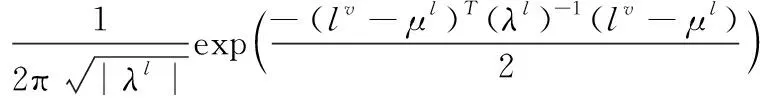
(2)
3.2 因子分解机(FM)
上一节介绍了MMBE模型,考虑了社交关系、顺序、时间、地理位置对兴趣点的协同影响,但是影响兴趣点的因素存在稀疏性,例如,使用热码方式对时间进行特征编码,一年有12个月,1月可以表示为 <1,0,0,0,0,0,0,0,0,0,0,0>, 传统方法对这种高维稀疏的矩阵,无法很好地处理,因子分解机(FM)的出现改变了这种情况,FM算法是一种很高效的模型,可以在线性时间内完成模型的训练,最大的优势是能够对稀疏数据进行很好的学习。通过交互项可以学习特征之间的关联关系。
因子分解机能够对高度稀疏的数据进行参数学习
(3)
式中:w0是全局偏量,wi表示第i个变量的强度,
W=V·Vt
(4)
其中,W为系数矩阵,且满足正定性。
(5)
使用两个矢量的点乘来替代Wi,j, 其中v为N*K大小的矩阵。通过这样的处理,即可以解决数据稀疏带来的参数难以学习的问题。
3.3 改进循环神经网络
在兴趣点推荐算法中,对于连续时间因素方面的研究并不多。在兴趣点推荐中,每一个POI都有自己的地理位置属性,且用户的行为是拥有时序性的,即具有时间和顺序性。循环神经网络(RNN)能够对序列模式进行建模。但是仅仅考虑用户时间和顺序影响是不够的,因为兴趣点还被当前地理位置以及社交关系影响。在兴趣点推荐算法中,一个用户访问兴趣点,易受好友影响,同时访问兴趣点具有时间规律以及存在先后顺序。此外当前所在地理位置也会对接下来要访问的兴趣点产生影响,因此在进行兴趣点推荐时需要综合考虑社交影响、时间影响、顺序影响以及地理位置影响。本文借鉴RNN模型的变种模型,提出了改进循环神经网络(relation-order-situation-time neural network,ROSTNN),模型结构如图2所示。
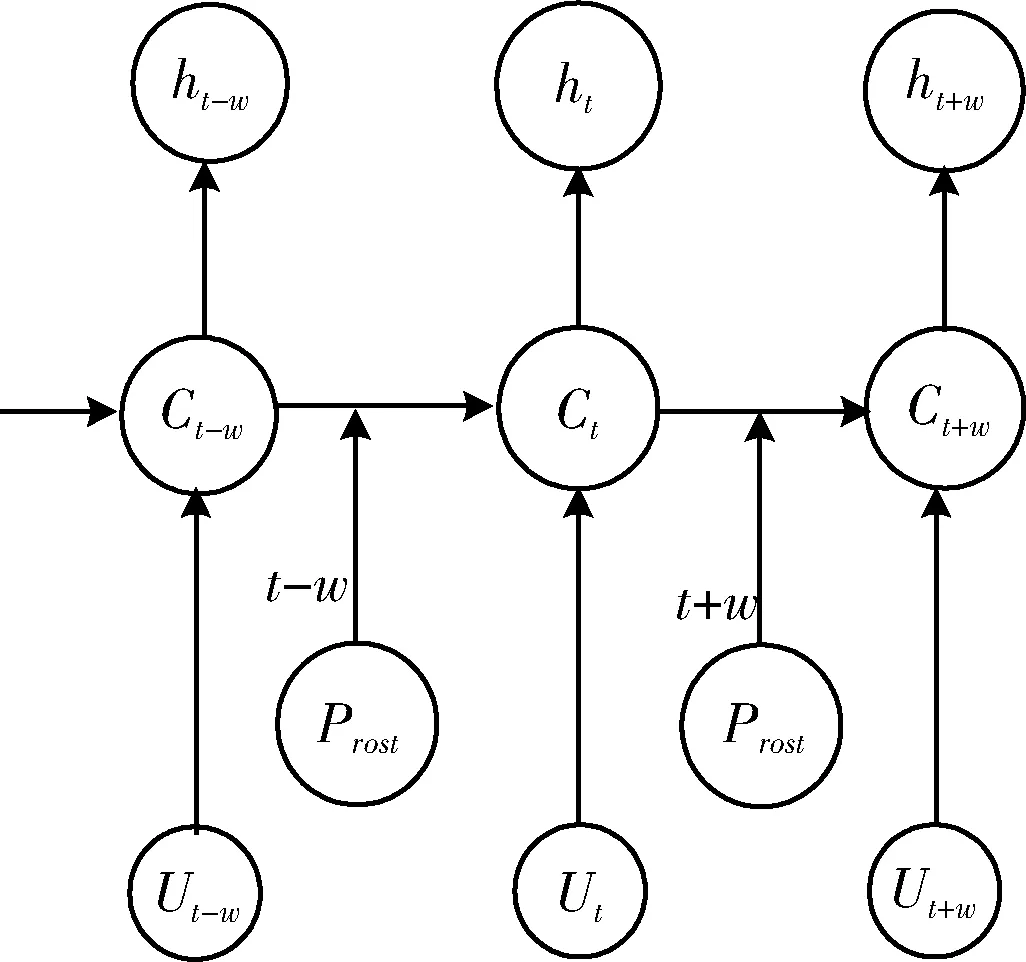
图2 改进型ROSTNN模型
新候选状态在t时刻的表示为
(6)
式中:Wc1、Wc2均表示的是模型参数,在lt位置点的嵌入由Ult进行表示,重置门开关记为ft, 上个输出的嵌入记为ht-1, 偏置矢量记作bc。
首先,通过MMBE模型可以得到社交关系、顺序、地理位置、时间的影响因子Prost(社交关系R、顺序O、地理位置S、时间T),则上述公式可变换为
(7)
若用户访问历史的时间较短,或是需要在历史最开始的部分对隐藏状态进行计算时,则t时刻的候选隐藏状态更改为
(8)
式中:初始状态由h0表示,每个用户都具有相同的初始状态,并且在这种状态下是不会有用于进行个性化预测的行为数据的。

(9)
式中:更新门的开关用it来表示,分素乘积记为*。以下为更新门与重置门开关的计算公式
it=σ(Wi1Ult+Wi2hlt-1+bi)
(10)
ft=σ(Wf1Ult+Wf2hlt-1+bf)
(11)
其中,更新门与重置门的参数分别由Wi1、Wi2、Wf1、Wf2来进行表示,更新门的偏移矢量记为bi,重置门的偏移矢量记为bf,在t时刻的输出表示为
ht=tanh(Ct)
(12)
用户u在特定时间和空间下动态的兴趣点所发生的变化由ht进行捕获。直到现在,本文对用户访问兴趣点的局部偏好和连续时间序列中的周期性变化特征的提取,是通过采用TD-GRU模型来完成的。
通过提取用户访问特征点的偏好,对于给定兴趣点l计算出用户对该兴趣点的预测值
(13)
3.4 基于改进RNN的推荐算法
图3为改进RNN算法的流程,首先通过因子分解机,构建时间矩阵T、地理位置矩阵S、顺序矩阵O和社交关系矩阵R,使用因子分解机的思想对稀疏数矩阵进行处理,去除数据的稀疏化。然后,使用MMBE模型对多源异构因素(社交、顺序、地理位置、时间)进行建模,得到影响权重,将影响权重协同上一时刻的状态,获得该时刻的状态,使用式(12)和式(13)求得给定任意兴趣点l的预测值p。最后,将其最高的前K个兴趣点推荐给用户。
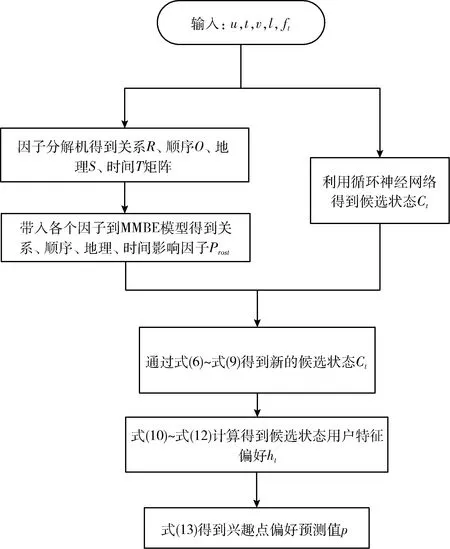
图3 改进RNN算法的流程
4 实验与结果
4.1 实验数据集
实验使用两个公开可用的LBSN数据集,即Gowalla和Brightkite。这两个数据集提供了用户关系和用户签到记录。其中签到记录包含位置ID和相应的签到时间戳。这两个数据集中的所有签到记录均被视为用户序列。两条连续的签到记录之间的间隔大于6个小时的每条轨迹都被细分为多个部分。还对两个数据集执行了预处理步骤,以过滤掉不活跃的用户和不受欢迎的POIs。例如,从Gowalla原始数据集中排除了签到记录少于16个且位置覆盖少于21次访问的用户。由于Brightkite中数据集的大小很小,因此,仅删除了签到少于11个好友的用户和签到少于16个位置的用户。表2列出了预处理数据集的统计信息。
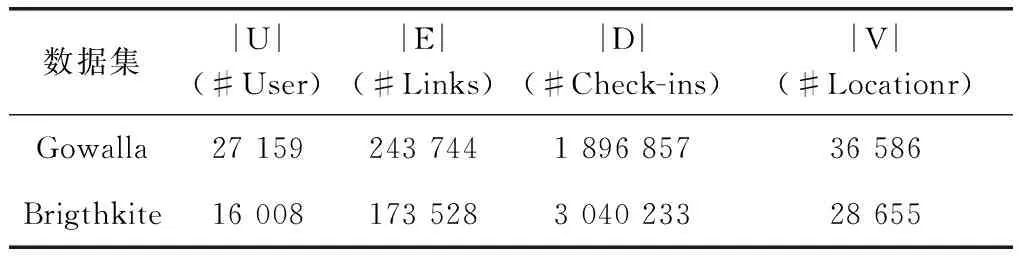
表2 预处理数据集的统计信息
4.2 性能指标
利用两种广泛使用的指标,即Recall@k(召回率)、Precision@k(精度),同时使用了F1指标,来衡量不同POI推荐方法的性能。其中F1指标是准确率和召回率的加权平均和,能够避免准确率和召回率相互制约的缺点,更好评价算法稳定性。这3个性能指标定义为
(14)
(15)
(16)
其中,Su(k) 是推荐给用户u的前k个POIs的集合,而vu是用户在测试集中访问的位置的集合。
4.3 实验描述
为了验证所提方法的有效性,将其与3种对比方法进行比较。每个数据集都被划分为一个训练集和一个关于签到时间的测试集,即,先前签到记录的80%被用作训练集,其余的为测试集。实验中所有程序都使用C++实现。尝试了运行Windows Server 2012的服务器,该服务器配置了Intel GRTPRA i7 CPU(3.6 GHz)和32 GB存储器。
4.4 参数分析
调整模型参数(例如主题数(即K)和区域数(即R))对于ROSTNN的性能至关重要。因此,以Gowalla为例,研究调整模型参数对ROSTNN性能的影响。首先,本文测试了超参数α、β、η、tu和tv改变时ROSTNN的性能,并且ROSTNN对超参数的变化不敏感。根据经验,为这些超参数设置固定值,即α=50/K,β=50/R,η=0.01,μu=μv=0和λu=λv=1E-3。 其次,进行了一个额外的实验来测量嵌入维数对POI推荐的影响。当嵌入维数为50~200时,模型的性能相对稳定。此外,嵌入维度越多,表达能力越强,也可能导致过度拟合。因此,嵌入维数被设置为100。
通过改变主题和区域的数量,随后进行了测试ROSTNN推荐前十个POIs的性能。如表3和表4所示,ROSTNN的推荐精度和召回率随着K的增加呈类似的上升趋势,当K大于50时趋于稳定。值得注意的是,对于R有类似的观察,即ROSTNN的推荐精度和召回率也随着区域数的增加而增加,当R大于40时趋于稳定。
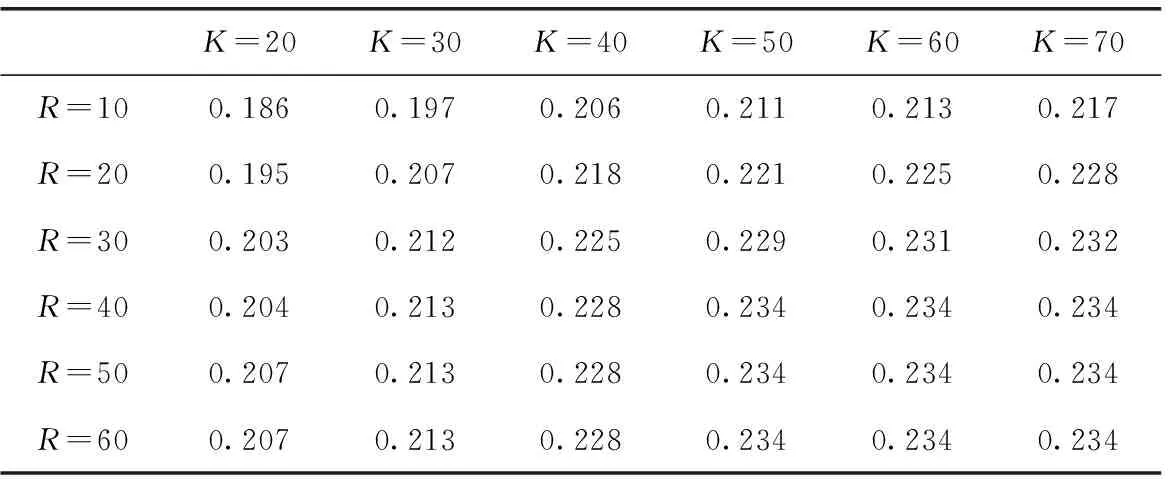
表3 Gowalla上的POI推荐精度@10
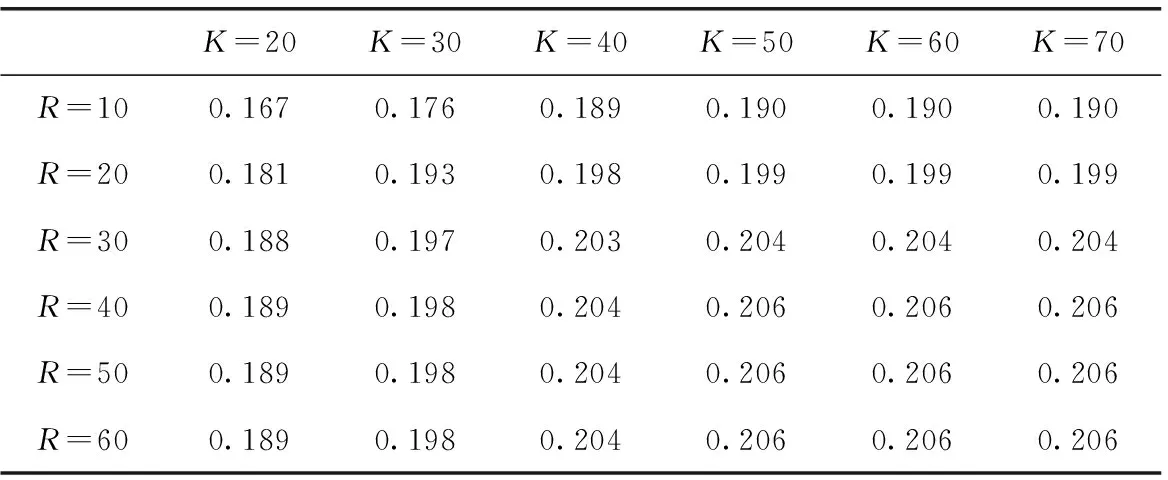
表4 Gowalla上的POI推荐召回@10
从主题和区域两个方面本文都获得了一致结果,这在很大程度上归因于K和R对模型复杂性。因此,仅仅增加K和R来改善模型性能没有太大帮助。换句话说,当预测使用ROSTNN的签到行为时,应该考虑是有效性优先还是效率优先。
4.5 对比结果与分析
将所提ROSTNN方法与LRACWSRAGI、GRTPRA、SOPCRMFM方法进行对比,在精度、召回率和F值方面的对比结果如图4~图9所示。

图4 ROSTNN在Gowalla上精确度对比实验
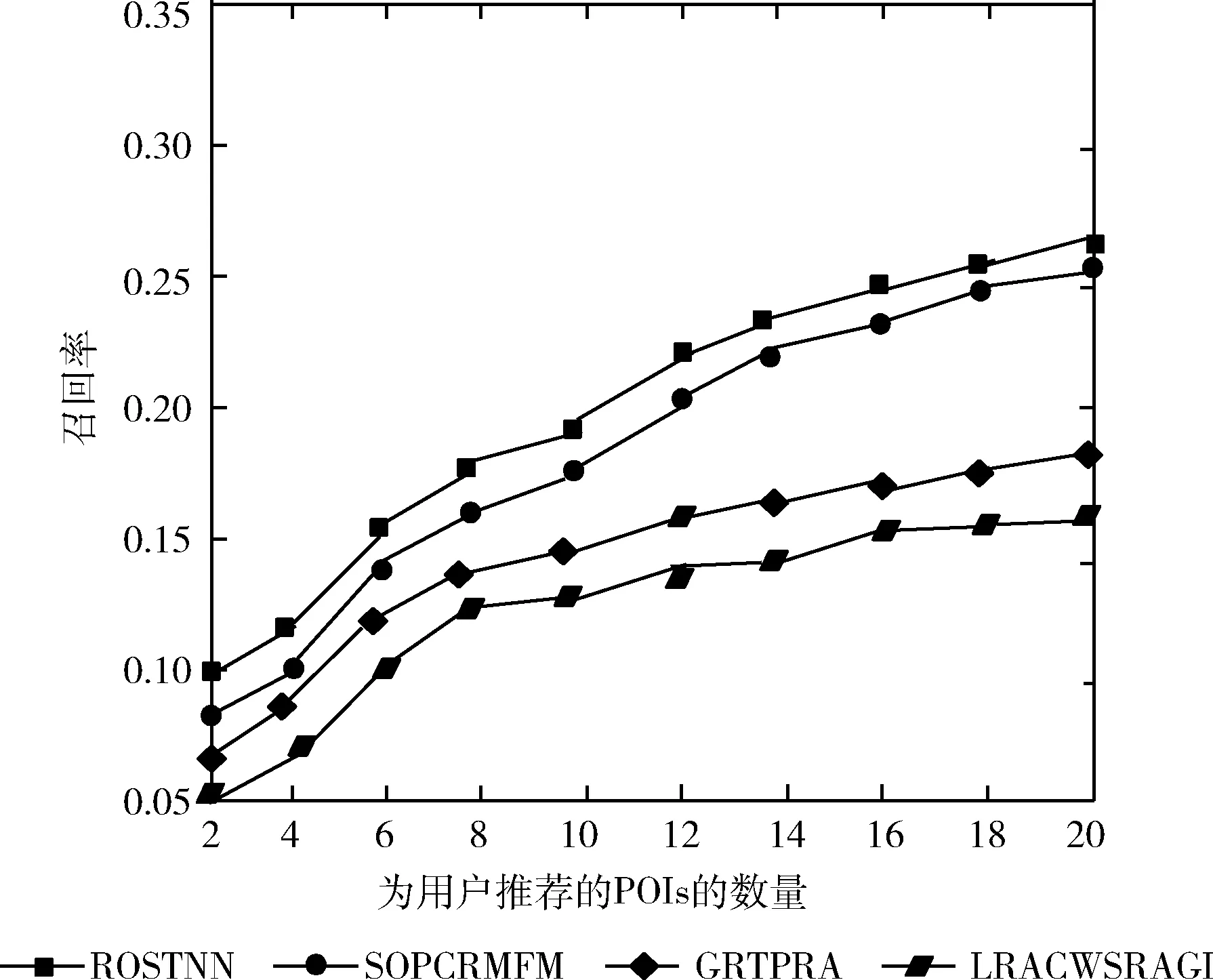
图5 ROSTNN在Gowalla上召回率对比实验
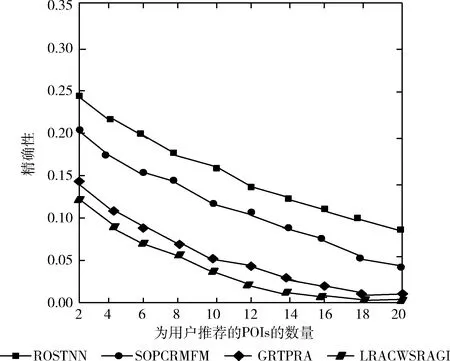
图6 ROSTNN在Brightkite上精确度对比实验

图7 ROSTNN在Brightkite上召回率对比实验
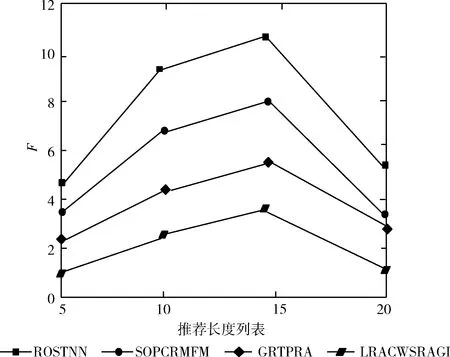
图8 几种方法在Gowalla数据集上F值对比结果
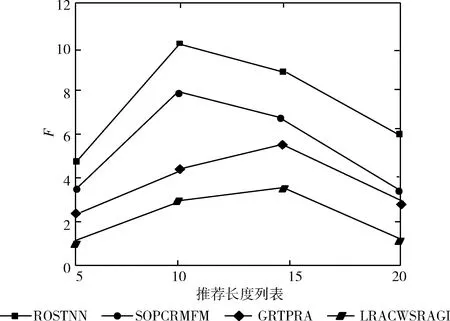
图9 几种方法在Brightkite数据集上F值对比结果
从图4到图7可以看到,所有方法在两个数据集上的精确度都比较低,这是由于两个数据集中用户的签到数据比较稀疏,因此,所讨论的所有4种方法的推荐准确性都相对较低。在两个数据集,本文的方法(ROSTNN)在评估指标方面优于其它3种对比方法。一方面,ROSTNN和SOPCRMFM的性能优于LRACWSRAGI、GRTPRA,这表明综合多源异构数据的优势。另一方面,ROSTNN比SOPCRMFM更好,因为本文的方法还考虑访问兴趣点的顺序,考虑顺序能够缩小兴趣点的范围,减小无用兴趣点。本文的方法对于两个数据集的精度值平均都有较大幅度增加。同样,本文方法的召回率值平均也都是最大的。在两个数据集上,本文方法更优,这是由于ROSTNN融合了社交、顺序、地理、时间4种主要的影响兴趣点推荐的因子,所以精度和稳定性最好。
从图8和图9可以看到,4种对比方法,在Gowalla数据集上推荐长度为15时F值达到最高。在Brightkite数据集上推荐长度为10时F值达到最高。表明不同数据集上,不同推荐长度对推荐结果也有影响。
综上可知,所提方法在两种数据集上都能取得最好的推荐效果,这是由于所提方法融入了多源异构数据,综合考虑了影响POI推荐的4个重要因子,避免了仅考虑单一或者某几个因子而忽视其它重要影响因子,带来的推荐准确性问题,较大程度上提高了推荐的精度。此外,使用的因子分解机,缓解了数据稀疏性带来的问题。实验结果表明,所提方法的性能更加稳定,同时推荐效果更好。
5 结束语
为了向LBSNs系统中的目标用户推荐更多相对准确的POIs,在异构工作流活动中,综合考虑了社交、顺序、地理和时间因素对单个用户签到行为的共同影响,提出了一种改进RNN的POI推荐方法。该方法通过因子分解机降低了各个维度数据稀疏性的问题,通过MMBE对4种影响POI推荐的因素进行融合,最终和改进RNN结合计算出兴趣点的预测值,有效提升了推荐性能。实验结果表明,所提方法在评估指标(精度和召回率)以及F1值方面优于其它3种对比方法。
未来将通过整合语义信息和隐式反馈等信息来扩展和丰富所提模型,以提高其预测性能和可扩展性。
猜你喜欢
西北林学院学报(2022年5期)2022-10-04
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
中等数学(2020年1期)2020-08-24
第一财经(2020年4期)2020-04-14
文化创新比较研究(2020年8期)2020-01-02
文苑(2018年17期)2018-11-09
商用汽车(2016年11期)2016-12-19
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
