
基于CNN-BiLSTM-HAN 混合神经网络的高校图书馆社交网络平台细粒度情感分析
2022-05-21 10:53:26李洪莲
农业图书情报学刊 2022年4期
李 博,李洪莲,关 青,刘 杨
(哈尔滨商业大学图书馆,哈尔滨 150028)
1 引言
随着Web2.0 技术的深入应用,微博、微信、短视频平台以及论坛等社交网络服务(Social Network Service,SNS)平台用户规模日趋增长。高校师生普遍使用社交网络工具进行学习、科研、工作上的交流[1]。用户体验图书馆服务的渠道和方式也日趋多样化和移动化,微信公众平台、微博等社交网络平台已经成为高校图书馆数字化服务的主要方式和手段。纷繁多样的社交网络平台引发了互联网信息呈现出指数级增长[2],用户产生的文本信息数据体量随之增大,这其中又存在大量的带有情感倾向的评论,这些资源中蕴含的情感信息一定程度上表征了用户的信息需求、数据需求以及潜在想法等。如何从纷繁多样的文本信息中高效、快捷、高质量地进行文本情感分析,判断情感倾向,提取出其蕴含的潜在价值及隐性内容,成为了目前学术界研究的一个热点话题。
情感分析研究也是目前国内外图书馆情报领域人工智能研究热点问题[3],不同于图像等数据的高稠密性,文本数据维度较高,数据结构呈现稀疏,并且语义复杂,文本数据分析过程中易产生分析粒度过粗,非结构化评论信息难以向量化以及无法捕捉上下文语义环境。对篇章级或句子级的整体倾向进行判断,精准度较低,很难准确判断真实具体的情感倾向,忽略了更细粒度级的信息,容易造成关键的、有价值的信息丢失;例如:“图书馆的学习氛围强,但是厕所异味太大,而且总有大声打电话的”,这句话就无法从整句上面来判断用户的真实情感究竟是积极的还是消极的,通过更细粒度的分析之后得出,用户对“学习氛围”这个维度持积极态度,对“空气质量”和“秩序”这两个维度持消极态度。
为了解决上述问题,本文采用基于深度神经网络学习的自然语言处理技术,充分利用卷积神经网络、循环神经网络和层次化注意力机制的优势,提出一种基于CNN、BiLSTM 和Hierarchical Attention 机制的高校图书馆社交网络细粒度情感分析模型,并在真实数据集进行实验,通过与基准模型的对比验证本模型的有效性。
2 相关工作
情感分析(Sentiment Analysis),又称情感分类(Sentiment Classification)、倾向性分析(Orientation Analysis),是运用自然语言处理、文本分类等技术自动抽取或分类文本中的情感[4],属于信息检索、自然语言处理和人工智能的交叉研究领域[5]。情感分析的目的是让计算机理解人类的喜怒哀乐等情绪,随着人工智能技术的发展,社交网络数据采集日益方便[1],情感分析可以有效地探索用户的舆论导向和隐性需求,了解用户的真实想法和潜在意见,为高校图书馆个性化服务决策提供指引和支撑。
2.1 基于传统机器学习方法的情感分析
有关情感分析的研究,在近年来呈现出井喷式地增长,受到诸多专家和学者的关注和青睐。PANG 等[6]首次利用传统机器学习方法解决电影评论的情感二分类问题,为情感分析研究提供了思路。BARBOSA 等[7]提取了文本数据中的具有特殊含义的关键信息,包括表情符号、话题、链接以及首字母大写的单词数目等Twitter 文本特征,利用有监督方法进行情感分类。张文亮等基于读者的视角,抓取大众点评网上用户对省级公共图书馆的评论和评分,通过抽取高频关键词绘制词云图揭示用户主要的关注点,利用SnowNLP 进行情感值的判断[8]。毕达天等对情感短语进行量化、分类,对比了不同场景下正负向情感的波动性变化,探讨了影响移动图书馆用户信息接受体验的情境因素和场景因素[9]。曾子明等[10]采取了文档主题生成模型(Latent Dirichlet Allocation,LDA),借助AdaBoost 算法利用主题特征、情感特征和句式特征变量构建5 种不同组合模型,识别微博评论情感倾向分析,着重研究各特征变量对情感分类效果的影响。朱茂然等基于PageRank 算法,结合社交网络的用户交互,利用LDA模型通过SVM 算法分类分析汽车论坛用户交互内容的情感倾向,识别出具有正面形象的专业意见领袖。
2.2 基于深度学习方法的情感分析
上述研究采用的主要方法是传统机器学习中的有监督学习,需要大量的特征选择提取工作,人工投入量较大。深度学习方法依托其机制的优势,具有稠密层,能够根据多次迭代自动进行特征的提取,已逐步发展成为近年来情感分析领域的主流方法。卷积神经网络CNN 是一种前馈神经网络,KALCHBRENNER等[11]针对不同长度的文本的处理,提出了一种动态人工神经网络,将CNN 引入自然语言处理。KIM[12]利用CNN 完成了句子级的英文文本分类,并将文本数据提前进行了向量化处理。BENGIO 等[13]最早利用神经网络构建语言模型。周锦峰等[14]提出了一种多窗口多池化层的卷积神经网络模型,该模型使用多个并行的卷积层提取不同窗口大小的上下文局部语义来解决语义距离依赖性和语义多层次性问题,语义特征更加丰富。卷积神经网络在文本分类中取得了较好的效果,但卷积神经网络更加关注局部特征,从而忽略了上下文语义信息,这在一定程度上影响了文本分类的准确率。
循环神经网络(RNN)可以很好地处理时序数据,在文本分类、情感分析等研究中使用非常广泛[15-19],但梯度消失和梯度下降问题影响了分析结果的准确性,长短期记忆单元[20]的出现有效地解决了以上问题。WANG 等[21]将注意力机制引入LSTM 网络,进行细粒度情感分析研究。余本功等[22]基于特征强化双向门限递归单元模型对汽车论坛网站口碑文本评论数据进行属性粒度的情感量化,提出了一种特征强化双向门限递归单元模型(Feature Bidirectional Gated Recurrent Unit,F-BiGRU),该模型在GRU 方法的基础上引入视觉卷积窗口进行强化特征信息提取,通过卷积和池化操作,修正短文本语义特征不明显及口语化明显等情况。胡荣磊等[23]提出了基于长短期记忆网络和注意力模型的网络结构,通过在中文酒店评价语料集进行实验表明,在文本情感倾向分析方面,较之卷积神经网络结合注意力机制的模型表现更佳。考虑到自然语言处理在分析用户情感方面仍存不足的情况,尤其是从文本、句法结构等角度展开的相关研究忽略了深层次的语义信息。郝志峰等[24]抽取属性实体,融合了文本的依存关系和词性等特征属性,用BiLSTM 构建基于序列标注的细粒度意见分析模型,判断文本情极,基于多特征融合与双向RNN 的细粒度意见分析。BAHDANAU 等[25]最早提出了注意力机制理论,将其首先应用到了机器翻译领域并取得了不错的效果,随后被应用于谷歌神经网络机器翻译系统。
不难发现,虽然现有研究针对情感分析问题已经在多角度、多层面进行开展,但采取的方法普遍较为单一。传统机器学习技术受算法等方面特点的限制,在进行有监督学习时,大量特征提取的工作耗费人力资源,并且浪费目前算力资源的配置。深度学习方法目前受到广大研究人员的青睐,但各种类型的深度神经网络各有所长,面对具体问题的研究也不能单纯依靠模型的简单堆叠和各类模型的变种。在情感分析问题研究方面,需要通过对各种深度神经网络的充分了解选取合适的方法进行深入分析。
3 基于C-BiLSTM-HAN 的情感分析模型
从相关工作的概述中可以看出,集成模型已经用于情感分析研究中的多种问题,并且比单个模型的性能更加出色。本文在以上研究的基础上,提出一种基于CNN-BiLSTM-HAN 模型的情感分析方法,面向的对象是高校图书馆社交网络平台。在CNN 基础上添加BiLSTM,弥补了RNN 梯度消失、梯度爆炸的不足[26],进行平行局部特征抽取,对过去和未来的双向长距离依赖信息进行特征提取,充分考虑每个词语信息前后的影响,做到细粒度分析,在此网络基础上添加HAN,关注重点词特征[27],对从中间层输出的信息进行不同程度的聚焦,采用Dropout 策略防止过拟合,最后通过Softmax 分类器进行结果分类输出,通过与基准模型进行对比实验,证明了此模型针对高校图书馆社交网络平台文本分类的准确性和有效性,图1 为模型的网络流程。

图1 CNN-BiLSTM-HAN 模型网络流程图Fig.1 CNN-BiLSTM-HAN model network flow chart
本文以判断高校图书馆社交网络平台产生的中文文本数据情感极性为出发点,提出了一个由CNN 模块,BiLSTM 模块以及引入层次化注意力机制形成的HAN 模块构成集成模型CNN-BiLSTM-HAN,用来进行高校图书馆社交网络平台细粒度情感分析。将经过人工标注并利用Python 语言的jieba 库分词后的中文语料数据通过Word2vec 转换为词向量的形式作为模型的输入层。在以下小节中,我们将分别介绍所提出的CNN 模型、BiLSTM 模型和HAN 模型。
3.1 CNN 模型
CNN 是一种前馈神经网络,因其具备良好的分类性能而备受广大研究人员青睐,能够提取有助于分类任务的重要且相关的特征。本文中我们首先建立一个CNN 模型来进行文本情感极性的预测。该模型由3 个并行的CNN 子模型组成。每个CNN 子模型,都有一定的滤波器大小s 和滤波器数目m。从每个滤波器获得的特征映射大小为n-s+1,其中n 是文本中的词语的数量。然后,我们对获得的特征映射进行最大池化操作。这将产生一个大小为m 的向量。我们在3 个子模型中使用相同数量的滤波器。将3 个子模型的输出连接起来,生成一个大小为3m 的向量。接下来添加一个具有ReLU 激活函数的全连接层。增加一个Dropout层,使网络正则化,以避免过拟合。最后,使用带有3个输出单元的最大Softmax 层来进行情感极性预测,图2 为CNN 模型的网络结构图。
综上所述,在胃癌根治术中,应用单纯全麻,会使患者的应激反应增强,不利于医护人员的手术操作,全麻药物作用量大,且术后患者会有明显的疼痛症状产生,而应用全麻联合硬膜外麻醉可以双向的阻滞受伤区域的神经感受器传导及中枢神经的敏感度,从而降低患者的术后疼痛及不良反应,同时术中能够减少茶氨酚的释放,降低患者应激反应,使循环系统趋于稳定,有利于手术的顺利进行[3]。并且全麻联合硬膜外麻醉的药物使用灵活,用量少,易控制患者的应激反应,有利于降低患者的术后疼痛,提高了患者的满意度,有临床推广的价值。
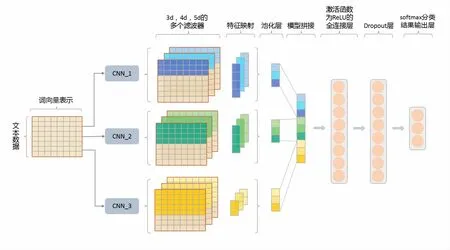
图2 CNN 模型网络结构图Fig.2 CNN model network structure diagram
3.2 Bi-LSTM 模型
LSTM 是为了解决梯度消失和梯度爆炸问题而衍生的一种变种循环神经网络,普通的LSTM 模型是简单的单向传播神经网络,无法学习反向特征,缺失了上下文特征的利用,限制了情感极性分类的性能。标准的LSTM 结构如图3 所示。
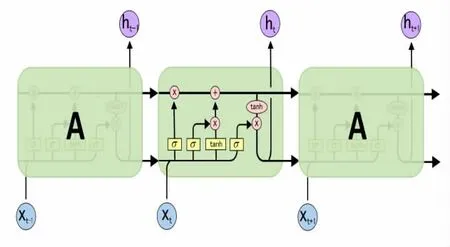
图3 LSTM 结构模型图Fig.3 LSTM structural model diagram
标准的LSTM 单元计算如下:
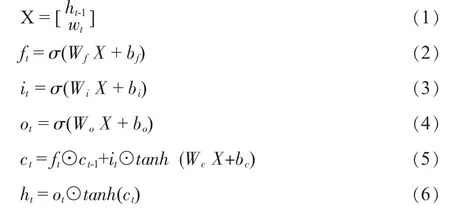
其中⊙表示对应元素点积;σ 是神经网络中的sigmoid 函数;Wf、Wi、Wo、Wc是隐藏层的权重矩阵,bf、bi、bo和bc是偏差向量,ht是在t 时刻的输出,ct为最终记忆单元。
BiLSTM 是对LSTM 的一个重大改进,它有效地解决了LSTM 无法学习反向特征的问题。因此我们采用双向BiLSTM 模型用于细粒度级别的情感极性分类,一个LSTM 保存前一个词的上下文,另一个保存下一个词的上下文。文本数据的向量表示首先传递给每个LSTM,每个LSTM 的大小为h。每个LSTM 的最终输出连接起来,生成一个长度为2h 的向量。然后将这个向量通过ReLU 激活函数传递到一个完全连接的层。在LSTM 层之后放置Dropout 层防止过拟合,在全连接层之后放置另一层Dropout。最后,添加了一Softmax 层,给出了文本的情感识别分类标签。图4 显示了BiLSTM 模型网络结构图。
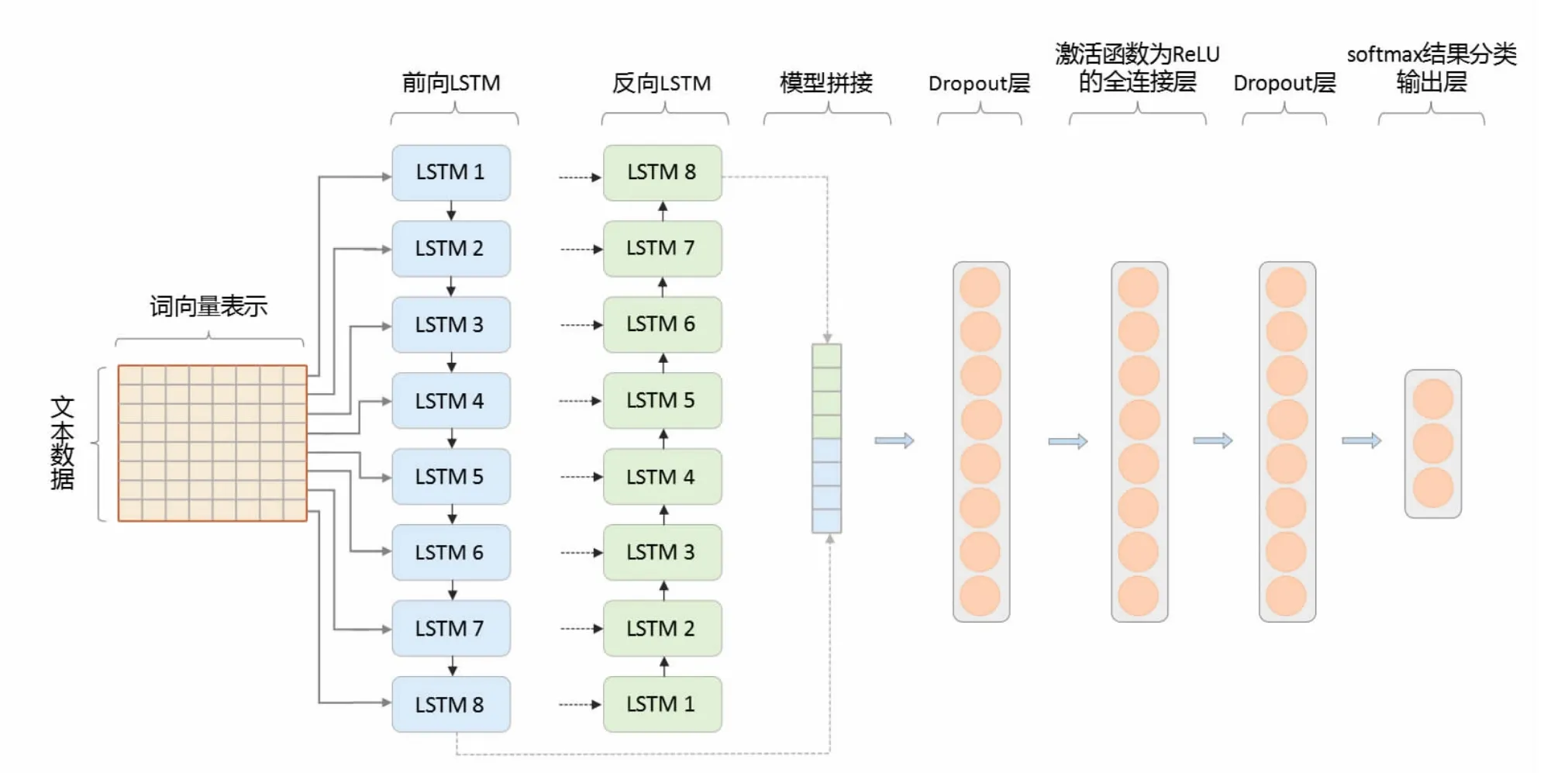
图4 BiLSTM 模型网络结构图Fig.4 BiLSTM model network structure diagram
3.3 HAN 模块
对于文本情感极性判断,在考虑上下文语义关系的同时,需要关注部分词语对句子情感表达的重要影响,层次化注意力机制会捕捉更多重点信息,因此,本文增加HAN 模块,加强对重点词的关注。
层次化注意力网络表达能力强的主要原因之一是它们能够区分重要的句子或词汇,HAN 模块将不同的注意力权重分配给语义编码,从而对向量语义编码的重要性进行筛选,提高分类的准确率。它假设对于一个特定的分类任务,有些词比其他词更重要,简单地说,有些句子比其他句子更重要。将BiLSTM 处理后的输出结果输入到HAN 层能够有效提升分类精度,计算方法如式(7)、(8)、(9)所示。
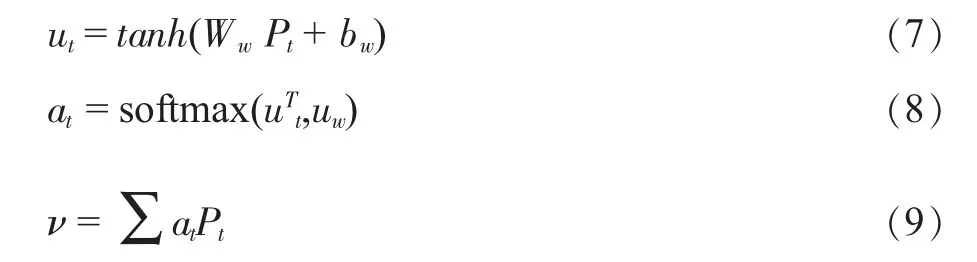
3.4 本文集成模型
本文集成模型网络架构由CNN 模块、BiLSTM 模块和HAN 模块组成,第一层为输入层,主要负责将输入的预处理后的中文文本数据进行词向量的映射,转换为词向量序列矩阵。第二层CNN 模块对文本矩阵进行卷积操作和最大池化操作,卷积操作精准提取每条数据的特征,获得每个词的字符级特征;最大池化操作将小邻域内的特征点进行整合处理,从而得到新的特征,加快训练速度。将经过CNN 模块处理后的每个词的字符向量拼接组合后的混合向量作为第三层神经网络模块BiLSTM 的输入序列,使模型同时关注已经过去和即将来到的双向重要信息,拼接两个方向的LSTM 的输出作为隐含层的输出。然后利用第四层Attention 模块通过加权求和对词语重要性进行计算,将第三层的输出解码出一个最优的标记序列,最后通过全连接层、Dropout 层输入到Softmax 分类器中对中文文本数据进行情绪分类输出,集成模型网络架构如图5 所示。
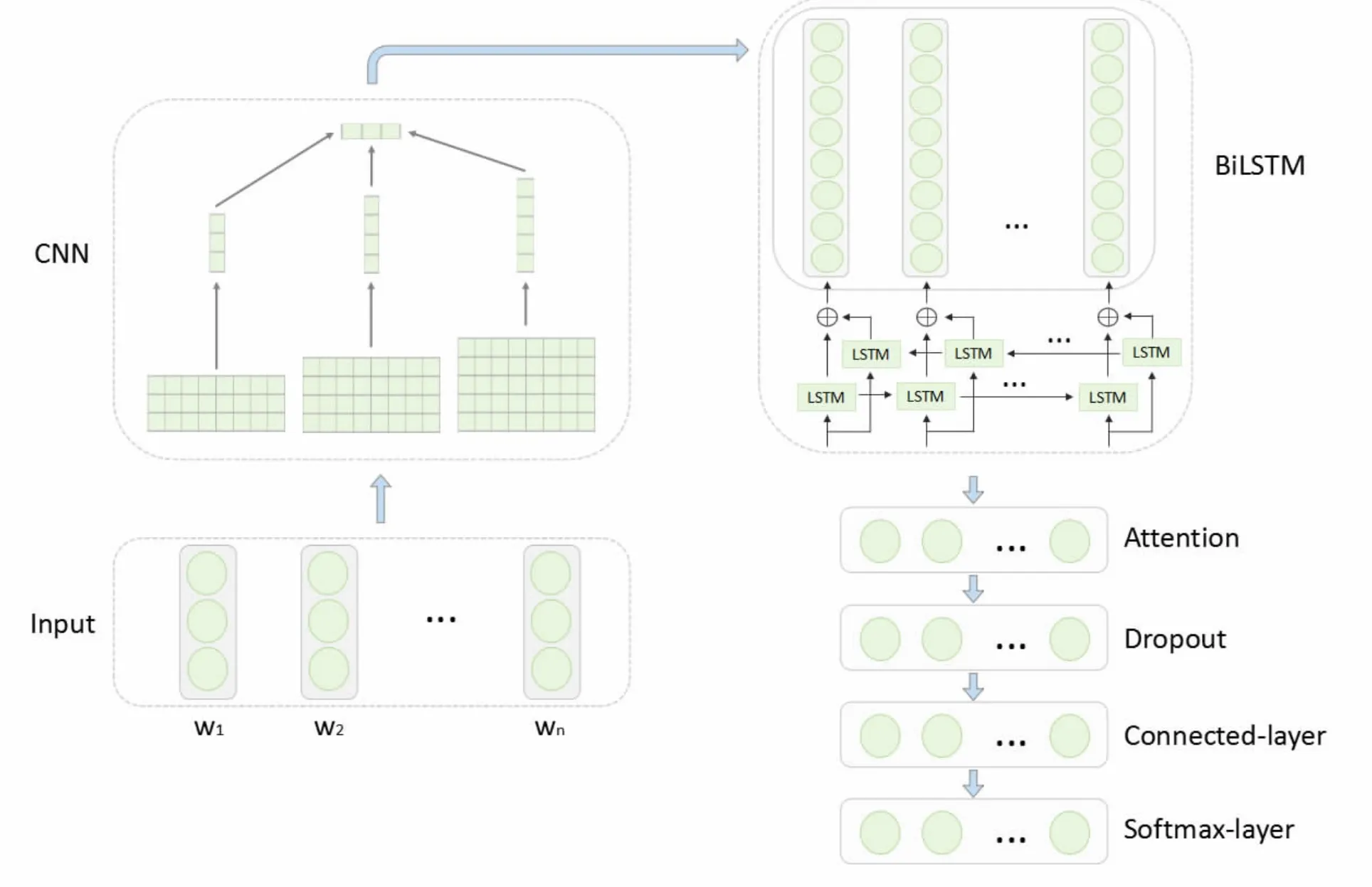
图5 CNN-BiLSTM-HAN 模型网络架构图Fig.5 CNN-BiLSTM-HAN model network architecture diagram
本文模型使用Mini-batch 梯度下降方法进行模型训练,快速训练模型,提升计算效率,防止产生局部最优,使模型能够更为鲁棒地收敛。目标函数为损失交叉熵函数,如式(10)所示,模型训练的目标是预测输出值和实际样本值的交叉熵。

其中,L 为损失值,x 为样本,n 为样本数,y 为样本实际值,为模型预测输出值。
本文利用Python 编程语言以及开源人工智能系统TensorFlow、Keras 构建CNN、BiLSTM,并引入HAN机制,采用Dropout 策略以避免过拟合,模型部分核心代码如下所示。

4 实验结果与分析
本文的实验环境为Windows 7 操作系统,采用Python 编程语言,利用基于Python 的高级人工神经库Keras 来实现模型网络的搭建,以Tensorflow 作为后端,Keras 底层通过调用Tensorflow 框架来实现本文实验环境的搭建,对比实验中的机器学习方法,采用Python 的第三方机器学习库Scikit-learn 来实现传统机器学习的分类方法。
4.1 实验数据
由于没有公开标注的高校图书馆社交平台相关的语料数据,为保证实验结果的可靠性,通过爬虫技术对国内高校图书馆论坛、留言本以及微信公众平台留言等评论数据进行采集,数据采集的范围包括上海交通大学图书馆、西南石油大学图书馆、西安交通大学图书馆、哈尔滨商业大学图书馆等15 所国内高校的论坛、留言板系统以及微信公众平台。获取原始数据26 896 条,经过数据清洗,分词等预处理步骤,剔除过短留言、垃圾评论等无效数据,拆分较长评论,得到短文本评论句子集,共21 091 条。其次,一方面抽取部分数据进行人工标注,手工编码标记正类、中性以及负类,形成一个具有正面评论、中性评论以及负面评论的数据集,用于训练和测试本文模型。如表1所示,其中正面语料数据量为8 033,中性语料数据量为4 355,负面数据量为8 703。

表1 数据集示例Fig.1 Trend of applying for RV red
4.2 参数设置
参数设置与模型的最终分类效果关系密切,表2中列出了相关参数的设置。

表2 模型的超参数Table 2 The hyperparameters of the model
4.3 评价指标
本文选用准确率A(Accuracy)、精确率P(Precision)、召回率R(Recall)、F1 值(F-measure)作为模型效果评价指标。准确率代表正确识别积极情感分类占所有正确识别出的积极情感分类的比例,召回率代表正确识别的积极情感分类反应占实际积极情感分类的比例,F1 值(F-measure)是精确率和召回率的加权调和平均,用于综合评估模型的识别性能。公式如下所示。


其中,TP(True Positives)表示正确地识别为积极情感实体的数目,TN(True Negative)表示正确地识别为消极情感实体的数目,FP(False Positives)表示错误地识别为积极情感实体的数目,FN(False Negative)表示错误地识别为消极的数目。
4.4 实验结果与分析
为了验证CNN-BiLSTM-HAN 模型在情感分析上的有效性,本实验选择了其他模型来进行对比实验,包括传统的机器学习模型支持向量机(以下简称SVM),深 度 学 习 模 型LSTM、CNN、BiLSTM、CNN-BiLSTM 共5 个模型;将本文模型在相同环境下与SVM、LSTM、CNN、BiLSTM、CNN-BiLSTM 等模型进行对比实验,实验结果如表3 所示。通过实验结果,可以看出在处理高校图书馆社交网络文本情感分析问题上,CNN-BiLSTM-HAN 模型具有较好的效果。采用准确率、召回率和F1 值来评估模型的性能,表3 中列出了不同方法进行情感分类这一任务的结果。
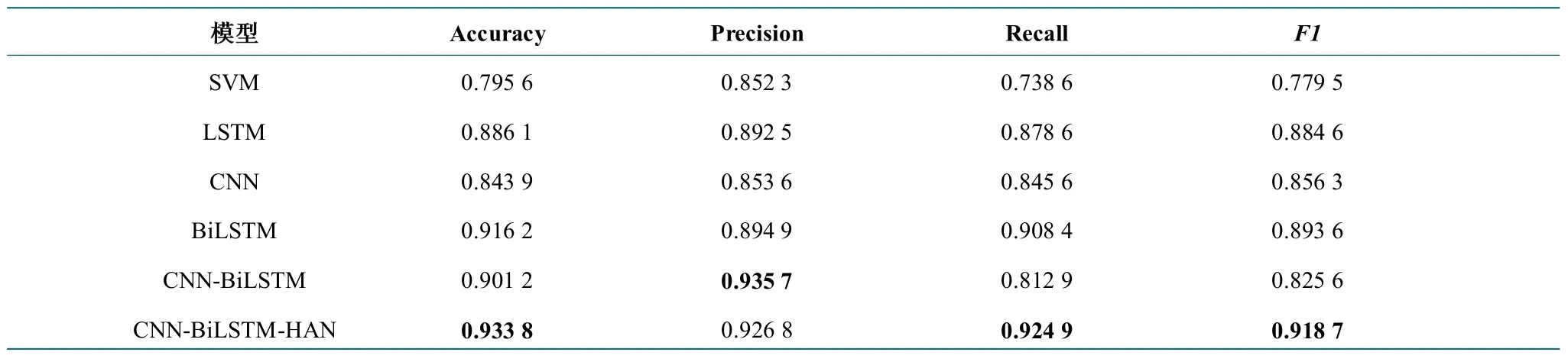
表3 模型对比结果Table 3 Model comparison results
如表3 所示,传统机器学习模型SVM 各项实验结果指标中,只有Precision 一项的值达到了0.852 3,其他各项指标值均偏低,而所有深度学习模型,包括单一模型和集成模型的各项指标值均优于SVM 模型。实验结果表明,深度学习模型相较于传统机器学习模型SVM 在性能各方面具有明显优势。由于CNN 在训练的过程中没有提取语境中上下文语义关联,因此,CNN 模型取得了0.843 9 的准确率,而LSTM 模型则取得了0.886 1 的准确率,相较于LSTM,CNN 模型不能更加精确的分析具备上下文语境关系的语料数据。虽然LSTM 擅长处理时间序列和学习数据表示,但在实验中,简单地使用LSTM 仍然没有学习到数据流的最深层次,从指标数据上对比能够看出,与BiLSTM模型相比不占主导地位。而总体来看,仅仅使用单一深度学习模型的分析性能明显不如集成模型CNN-BiLSTM和CNN-BiLSTM-HAN,无法很好提升模型预测效果。使用本文模型进行情感分类的方法普遍优于其他方法,因为HAN 模块执行了特征权重分配功能,使模型对不同等级权重特征进行了学习,有利于模型准确迅速的获得等级较高的权重信息,提出的CNN-BiLSTM-HAN模型相比于未引入HAN 机制的模型准确率提升3.3%,说明引入HAN 机制的模型在准确率提升方面优于简单集成模型和传统单一神经网络模型,引入的HAN 机制起到了分析目标和上下文之间的相互作用。在召回率和F1 值指标上也均优于其他模型,充分证明了本文提出的方法在高校图书馆社交网络平台细粒度情感分析上的有效性。
5 结语
本文提出了一种基于CNN-BiLSTM 网络引入HAN 机制的混合神经网络深度学习模型,用于进行高校图书馆社交网络平台情感分析。通过在真实数据集进行实验,结果证明了CNN-BiLSTM 网络引入HAN机制方法的有效性。本文模型旨在更精确地挖掘高校图书馆社交网络平台用户情感倾向,为高校图书馆开展服务过程中用户留言关键词提取及情感极性判断提供了一种启示、思路和方法,为高校图书馆了解用户真实诉求、针对性地改进服务质量提供科学依据。对高校图书馆社交网络平台进行情感分析,可以有效发现用户对高校图书馆价值是否具有认同感,能够促进高校图书馆自我提升服务质量,拓宽服务范围,帮助图书馆自我定位资源及服务的长处和不足,有助于图书馆提升自身形象,增强用户满意度,整体高质量发展。本研究实验过程中采用的数据集体量相对较小,未来会进一步扩充数据集规模。另外,由于模型较为复杂,参数较多,导致模型训练用时较长,并且表情符号信息没有得到有效利用。在未来研究中,参数的设置、模型的优化和表情符号信息的利用将是下一步研究方向,未来考虑加入BERT 模型,提升模型识别能力及泛化能力。
猜你喜欢
英语世界(2023年6期)2023-06-30 06:28:28
意林彩版(2022年2期)2022-05-03 10:25:08
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
第一财经(2020年4期)2020-04-14 04:38:56
电子制作(2019年19期)2019-11-23 08:42:00
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
文苑(2018年17期)2018-11-09 01:29:28
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
重型机械(2016年1期)2016-03-01 03:42:04
